OpenAI Agent Builder 完整指南:何时用可视化工作流,何时转向 Agents SDK
如果你正在评估 OpenAI AgentKit,这篇文章帮你判断 Agent Builder、Agents SDK 和 Responses API 的适用边界,并给出从可视化工作流迁移到代码化集成的触发信号。
Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
如果你现在正准备做一个真正要上线的 AI agent,最容易踩的坑不是“不会拖节点”,而是太早把 Agent Builder 当成长期架构。很多团队第一次接触 AgentKit 时,往往会被可视化工作流吸引,先把 demo 搭出来;真正的决策难点却会在一两周后出现: 这个流程以后要不要进 Git、要不要接后端权限、要不要接入现有应用、要不要跑自动化评测、要不要交给多个工程师协作维护。
这篇文章不是再把发布页重述一遍,而是直接回答更具体的问题: 什么时候继续留在 OpenAI Agent Builder,什么时候应该转向 Agents SDK,什么时候干脆直接用 Responses API。从这个角度看,Agent Builder 不是“更高级的 no-code 工具”,而是 OpenAI agent stack 里一个很适合验证工作流的入口,但它并不自动等于你的最终交付形态。

TL;DR
- AgentKit 已于 2025 年 10 月 6 日发布,其中 ChatKit 与新的 agent evals 已对开发者可用,而 Agent Builder 当前仍处于 beta,Connector Registry 也是分批 beta rollout(OpenAI Introducing AgentKit,2026-03-18 核验)。
- OpenAI 当前明确给出三条构建路径:
Responses API、Agents SDK、Agent Builder(OpenAI Agent Builder docs,2026-03-18 核验)。选错路径的代价,不是功能少一点,而是后面会不会返工。- 如果你最需要的是快速把业务流程画出来、给产品和运营一起调逻辑、尽快验证 agent 体验,先用 Agent Builder。
- 如果你已经要把 agent 接进现有应用、走代码评审、接服务端密钥、做 CI 或多环境发布,应该把核心执行层迁到 Agents SDK 或 Responses API。
- 这篇文章最重要的结论不是“Builder 很强”,而是“Builder 适合什么阶段,以及什么时候不该继续硬撑”。
先把产品关系讲清楚
OpenAI 现在的 agent 平台不是只有一个入口。官方文档已经把构建 agent 的方式拆成三条: 直接用 Responses API、用 Agents SDK、或者用 Agent Builder(OpenAI Agent Builder docs,2026-03-18 核验)。这件事很关键,因为它意味着 Agent Builder 并不是一个孤立的新产品,而是和代码接口、SDK、评测、UI 工具一起组成的平台层。
从官方发布页来看,AgentKit 这次把几个原本容易分散理解的部分放进了一个统一叙事里: Agent Builder 负责可视化工作流,ChatKit 负责对话 UI,新的 evals 负责评测与调优,Connector Registry 负责受管连接器(OpenAI Introducing AgentKit,2026-03-18 核验)。如果你之前只是把它理解成“一个拖拽式搭 agent 的页面”,那会低估它的真实位置;如果你反过来把它理解成“以后所有 agent 都应该从 Builder 开始”,又会高估它的适用范围。
结合官方文档可以做一个更实用的判断: Responses API 是底层调用面,Agents SDK 是工程化编排面,Agent Builder 是可视化工作流面,ChatKit 是交互界面面。 这句话里,后两层是基于官方关系的工程化归纳,不是官方原句,但它能帮助团队在架构讨论时少走弯路。
另一个需要尽快纠正的旧认知是: 不是所有 AgentKit 组件都已经完全同等开放。当前官方状态是 ChatKit 与新的 agent evals 已面向开发者提供,Agent Builder 仍是 beta,Connector Registry 也是分批 beta rollout,并带有组织与管理条件(OpenAI Introducing AgentKit,2026-03-18 核验)。所以你在做选型时,应该先把“我能不能用”与“这个能力适不适合长期承担核心执行层”分开看。
你该选 Agent Builder、Agents SDK,还是 Responses API
真正有价值的选型,不是对着功能表逐项打勾,而是先问: 你现在卡在哪个工程阶段。下面这个矩阵,比“哪个更强”更重要。
| 你的当前状态 | 更适合的选择 | 原因 | 先注意什么 |
|---|---|---|---|
| 你要在几天内把流程跑通,让产品、运营、业务方一起看逻辑 | Agent Builder | 可视化节点、调试和评测更适合共同对齐流程 | 不要过早把它当成永久后端 |
| 你已经有现有应用,要把 agent 接到后端、鉴权、日志和发布流程里 | Agents SDK | 更适合进入代码仓库、评审、测试和服务端治理 | 需要工程团队接手抽象和部署 |
| 你已有自己的 orchestration 层,只想直接调模型与工具 | Responses API | 控制粒度最高,最适合已有平台能力的团队 | 需要自己承担更多编排与状态管理 |
| 你要尽快交付一个面向最终用户的聊天界面 | ChatKit 配合 Builder 或 SDK | ChatKit 是 UI 层,不是工作流替代品 | 先确认核心执行层放在哪一侧 |
| 你需要受管 SaaS 数据连接器 | Connector Registry 视权限可用性决定 | 它能减少自建连接器成本 | 先确认组织权限与 beta 可用性 |
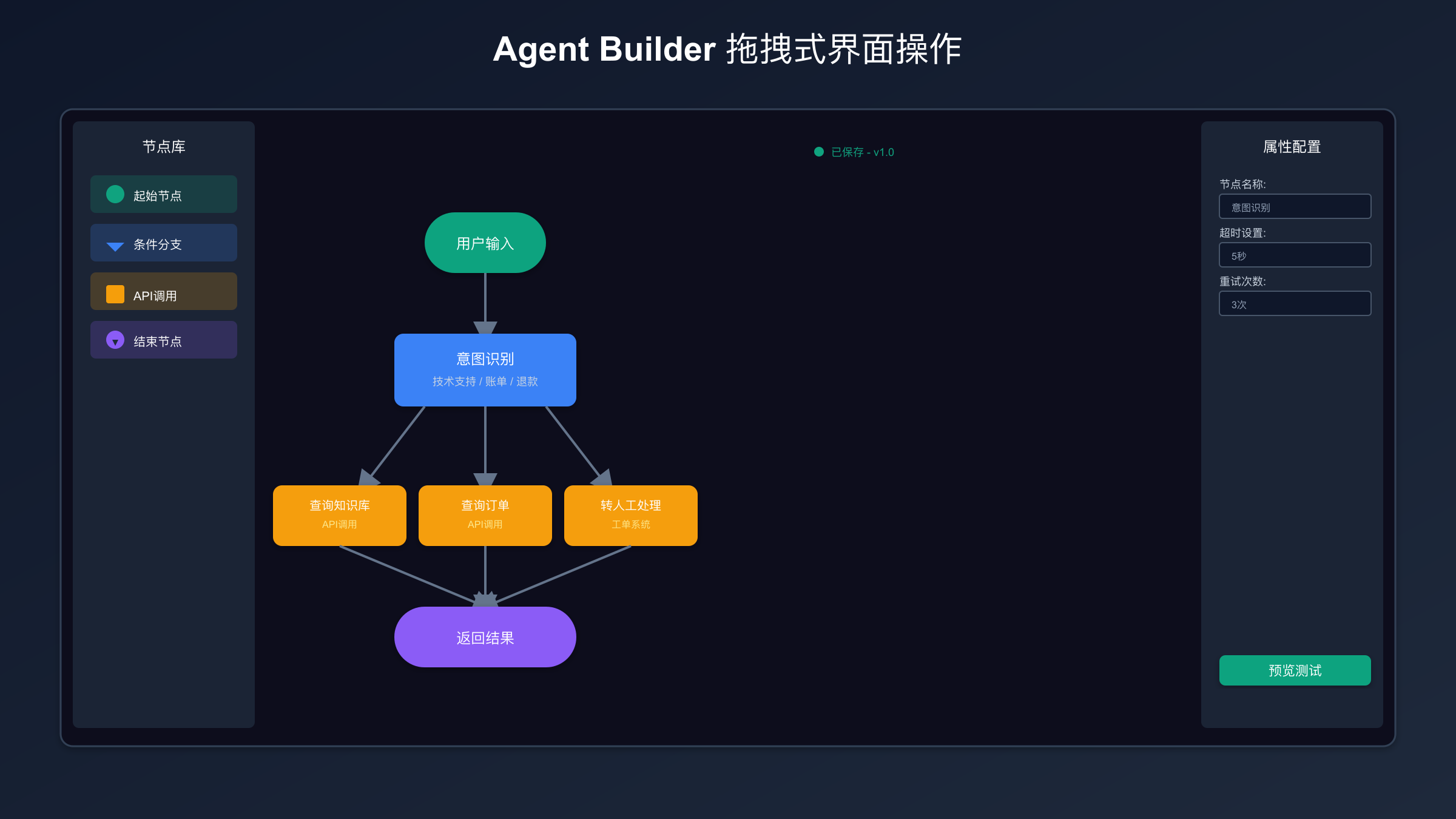
这张表真正想解决的是一个常见误判: 许多团队在 demo 阶段选了 Builder,因为它最容易开始;等到要进生产时,才发现团队真正缺的不是“再多几个节点”,而是版本控制、服务端 secrets、可重复发布、自动化测试和应用内集成。那时再整体迁移,就会觉得 Builder “不够用”;但更准确的说法是,它在你项目的当前阶段已经完成使命了。
所以我的建议很直接。只要你还在验证业务流程、提示词结构、工具调用顺序,Agent Builder 通常是效率最高的入口。只要你已经开始讨论多环境配置、审核流、回滚、权限边界、Webhook、后端监控或审计要求,就应该预期自己会走向代码化路径。把这件事提前想清楚,能省掉后面最贵的返工。
当前官方能力边界: Builder、ChatKit、Evals、Connector Registry 各管什么
Agent Builder 的价值不是“让不会写代码的人也能做复杂系统”,而是把一个还没稳定下来的 agent 流程先可视化。官方文档强调它适合视觉化地 build、test、evaluate 和 deploy agent workflow,而且可以发布到 ChatGPT 或 API(OpenAI Agent Builder docs,2026-03-18 核验)。这意味着它最强的阶段,是你还在改流程,而不是你已经确信流程长期稳定。
ChatKit 则应该被看作交互层。官方文档把它定位成用于构建、定制和部署 AI agent 对话 UI 的工具包,并包含预构建组件、starter app、无框架依赖的 Web Component、文件上传、引用展示、语音、认证和自定义 actions 等能力(OpenAI ChatKit docs,2026-03-18 核验)。这对产品团队很重要,因为很多项目真正拖慢进度的不是 agent 本身,而是“agent 做出来后,前端还要补一轮聊天体验”。如果你已经决定 agent 要面向终端用户,ChatKit 的价值往往比再多一个节点更直接。
新的 agent evals 是另一个很容易被低估的部分。很多团队以为“评测”是上线之后再补;但对 agent 来说,评测其实是在决定你是否能迭代。没有评测,Builder 里的流程只是一个会动的 demo;有评测,才有资格叫做可以持续优化的工作流。也正因为如此,我更建议把 Agent Builder 看成“验证和打磨工作流”的地方,而不是全部交付都放进去。
Connector Registry 的边界则更要谨慎理解。它的价值在于减少重复做连接器、权限管理和受管接入,但当前并不是所有团队都能默认拥有同样的开放状态(OpenAI Introducing AgentKit,2026-03-18 核验)。如果你的项目规划已经高度依赖某个连接器,先确认权限、组织管理要求和 rollout 状态,再把它写进里程碑,否则最容易在上线前临门一脚卡住。
一个不容易返工的上手路径
如果你现在要带团队从零开始做一个 OpenAI agent,我更推荐把工作拆成四步,而不是一上来就决定“我们未来全部都用 Builder”。
第一步,用 Agent Builder 把业务流程画清楚。这里的目标不是把系统做完,而是把决策节点、工具调用顺序、错误回退路径和人工介入点暴露出来。只要团队里还有人对“这一步到底该查知识库还是直接调用系统”“失败后回退给谁”说不清,Builder 就值得用,因为可视化会强迫大家把模糊逻辑显性化。
第二步,在这个阶段就把评测放进来。一个最常见的失误是团队只做 happy path 演示,却没有故意喂给 agent 异常输入、权限不足、数据缺失和工具超时场景。没有这些测试,你上线前看到的是成功流程;上线后遇到的才是真实用户。Builder 和 evals 放在一起,最大的收益不是“更先进”,而是更早暴露失败模式。
第三步,尽早决定前端与后端的分工。如果你的场景是内部团队试用、短期验证或低风险运营支撑,Builder 加 ChatKit 往往就已经能让你迅速交出一个可试用版本。可一旦这个 agent 需要进入现有产品、跟组织登录态打通、受业务事件触发,或者进入统一监控和审计体系,你就不该把全部未来都押在可视化界面里,而要开始准备 SDK 或 API 接管核心执行层。
第四步,把“迁移”当作预设动作,而不是失败信号。很多团队对迁移有心理负担,仿佛从 Builder 切到 SDK 代表前面做错了。实际上,最健康的路径往往就是先在 Builder 把工作流磨对,再把稳定部分迁进代码仓库,把仍在高频变动的部分继续放在可视化层。这不是推翻重来,而是阶段切换。
什么时候该从 Builder 切到代码
下面这 6 个触发信号,是这篇文章最重要的决策工件。如果你已经连续满足其中 2-3 项,就应该认真评估把核心执行层迁到 Agents SDK 或 Responses API。

第一种信号是你已经需要 Git 审核和多人协作。一旦团队开始要求 PR review、代码所有权、变更记录和可回滚部署,工作流就不再只是“配一下”。这时 Builder 依然适合做草图,但核心逻辑最好进入代码仓库。
第二种信号是你开始需要服务端 secrets 和细粒度权限。比如不同租户、不同角色、不同环境使用不同凭证,或者某些工具调用必须经过后端签名。可视化工作流可以表达逻辑,却不一定应该承载全部安全边界。
第三种信号是你需要自动化测试和 CI。当 agent 不再只是一个演示流程,而是要跟着版本迭代一起测试、一起发布,代码化集成的收益会迅速超过可视化修改的便利。
第四种信号是你需要和现有应用事件深度耦合。如果 agent 的触发来自订单状态、CRM 事件、审批流回调或内部任务队列,而不是单纯的对话输入,那就说明执行层已经进入产品系统边界,SDK 或 API 会更顺手。
第五种信号是你开始需要自定义编排和长期状态。Builder 很适合把流程说清楚,但当你需要自己维护更多状态机、缓存策略、复杂重试和跨服务追踪时,代码化会更稳。
第六种信号是你必须控制未来迁移成本。如果项目一开始就注定会走多环境发布、可观测性、审计和组织治理,那么越早把稳定核心迁入代码,后面的重做成本越低。
这里还有一个官方信号值得一起看。如果你手上还有旧的 Assistants API 项目,OpenAI 当前迁移指南已经建议转向 Responses API(OpenAI Assistants migration guide,2026-03-18 核验)。这意味着平台本身也在鼓励团队把 agent 能力放到更统一的新接口体系里,而不是继续押在旧抽象上。对正在评估 Builder 的团队来说,这个信号的意义是: 别把“先可视化”误读成“以后就不需要代码接口”。
一个典型团队的三阶段路线图
如果你想把上面的建议转成真正可执行的项目路线,我建议把 OpenAI agent 落地拆成三个阶段。这样做的好处是,每个阶段都只解决当前最贵的问题,而不是一开始就试图同时解决流程设计、前端交付、权限治理和长期维护。
第一阶段是 discovery。这个阶段最适合用 Agent Builder,因为你需要快速判断业务流程是否成立,哪些节点应该调用工具,哪些场景必须转人工,哪些输入会让 agent 失真。此时最重要的产出不是“一个看起来完整的系统”,而是对失败模式的认知。
第二阶段是 integration。到了这一步,你通常已经知道 agent 值不值得做,问题开始从“逻辑对不对”转向“怎么进产品”。这时最常见的动作是把稳定下来的核心流程迁到 Agents SDK 或 Responses API,同时决定 ChatKit 是继续承担用户界面,还是由你自己的前端体系接管。对大多数团队来说,这一步才是真正的工程分水岭。
第三阶段是 scale。只有当 agent 已经要承担更强的业务责任时,你才需要把关注点放到多环境发布、观测、成本管理、权限边界、连接器治理和迁移成本上。这个阶段继续停留在纯可视化思路里,往往会让团队觉得“每一项都还能勉强做”,但维护复杂度会越来越高。更健康的方式,是让 Builder 继续承担探索职责,而把长期稳定核心交给代码化层。
部署前必须补齐的治理检查
到了要上线的阶段,很多团队还是会把问题问成“Builder 能不能做”。更正确的问法应该是“我们的治理要求已经到了哪一步”。如果下面这些问题还没被回答,技术路线往往定得太早。
首先是权限与组织边界。Connector Registry 当前带有组织与管理条件,这说明 OpenAI 的 agent 平台并不是单纯的个人试验工具,而是正在进入受治理场景(OpenAI Introducing AgentKit,2026-03-18 核验)。所以在你决定依赖某个连接器之前,先确认谁有权限接入、谁负责审批、谁管理数据访问,而不是等业务已经承诺了再回头补制度。
其次是评测和回滚。很多 agent 项目死在“上线前看起来挺聪明,上线后没有人知道哪里坏了”。这不是模型问题,而是缺评测、缺回滚、缺失败路径定义。Agent Builder 和新的 evals 能帮你更早做这件事,但责任仍然在团队,不会因为工具存在就自动完成。
最后是 UI 与执行层的拆分。ChatKit 的官方定位非常清楚,它是对话 UI 工具包,而不是后端工作流系统(OpenAI ChatKit docs,2026-03-18 核验)。如果你的团队把 UI、工作流和系统集成都绑成一个“Builder 方案”,后面几乎一定会出现职责不清的问题。更稳的做法是尽早认清三件事: 用户看到什么、agent 如何推理、系统如何执行,最好分别设计。
常见问题 FAQ
OpenAI Agent Builder 和 Agents SDK 是竞争关系吗?
不是。更准确地说,它们解决的是不同阶段的问题。Agent Builder 更适合把流程快速可视化、测试和沟通;Agents SDK 更适合让这个流程进入工程体系。很多团队最终会同时使用两者,只是承担的职责不同。
我能不能一开始就直接用 Responses API,不碰 Builder?
可以,而且对已经有成熟平台能力的团队来说,这往往是更直接的路线。尤其当你已经有自己的状态管理、鉴权、日志、任务调度和前端体系时,Responses API 提供的控制粒度会更高。只是代价也很明确: 你需要自己承担更多编排和调试工作,而不是把这些前期探索成本交给可视化工具。
ChatKit 是不是只有配合 Agent Builder 才有意义?
不是。官方文档把 ChatKit 定位为构建、定制和部署 AI agent 对话 UI 的工具包,它的价值在于缩短界面交付时间,而不是规定你必须用哪种执行层(OpenAI ChatKit docs,2026-03-18 核验)。如果你的 agent 已经在 SDK 或 API 一侧成熟,ChatKit 仍然可以是前端加速器。
现有 Assistants API 项目要不要整体重做?
不一定要“整体重做”,但应该认真看官方迁移方向。当前 OpenAI 的迁移指南已经把 Responses API 作为推荐路径(OpenAI Assistants migration guide,2026-03-18 核验)。这意味着更稳妥的做法通常不是继续在旧抽象上叠需求,而是评估哪些能力可以逐步迁过去,尤其是准备长期维护的项目。
Connector Registry 值不值得作为路线前提?
只有在你已经确认组织权限、beta 可用性和所需连接器覆盖范围时,才值得把它写进路线前提。否则更好的做法是把它当成“可能加速的能力”,而不是里程碑里的硬依赖。对上线项目来说,最怕的不是功能少,而是关键前提直到后期才发现拿不到。
非工程团队能不能只靠 Agent Builder 把项目做成?
如果目标是内部试用、业务验证或低风险流程,答案通常是可以做到相当远。但如果目标是可持续运营的产品能力,最终还是会碰到权限、审计、部署、测试和监控问题。Agent Builder 可以让非工程团队更早参与设计,这很有价值;但它不太可能永久替代工程化交付。
结论
OpenAI 这次真正提供的,不只是一个“拖拽搭 agent”的新页面,而是一套从工作流、评测、UI 到连接器逐渐成形的平台能力。理解这一点以后,Agent Builder 的价值反而会更清楚: 它最适合拿来快速验证流程、暴露失败模式、让跨职能团队一起对齐,而不是默认承担全部长期架构。
如果你现在还在验证业务逻辑,就先用 Builder,把流程跑顺;如果你已经进入应用集成、权限治理、自动化测试和多环境发布,就提前规划 SDK 或 Responses API 的接管。最好的路线通常不是二选一,而是把 Builder 用在它最有价值的阶段,然后在合适的时候把稳定核心迁入代码。