AI创作人性化指南:先判断该润色、重写还是披露 AI 协作
这不是一篇教你“绕过检测”的旧式教程,而是一份面向品牌内容、学习申请与高风险审核场景的 AI 协作稿人性化指南。先判断该轻润色、深度重写,还是保留证据链。
Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
AI创作人性化指南:先判断该润色、重写还是披露 AI 协作
如果你现在手里有一篇 AI 起草的博客、邮件、申请文书或品牌稿, 信息不一定错, 句子也不一定差, 但整篇看上去像同一个模板里倒出来的, 真正的问题通常不是“它能不能骗过检测器”, 而是“它到底像不像你写的”。 更具体一点说,很多人卡住的不是不会改句子,而是不知道先做哪一步。 这篇稿子只是语气太平,还是连判断、结构和证据都不够? 它适合用 humanizer 做一轮轻润色,还是应该直接人工重写关键段落? 如果场景涉及课程作业、学习申请、客户验收或公开署名, 是不是除了改文, 还要把版本记录、来源说明和 AI 协作边界一起准备好? 这就是这篇更新版和旧式“降低 AI 痕迹技巧帖”的区别。 我不会先教你换几个更像口语的词,也不会把目标设成“轻松绕过检测”。 我会先帮你判断:你手上的内容, 到底该轻润色、深度重写, 还是进入需要证据链与披露的高风险流程。
TL;DR
- 如果稿子事实可靠、结构完整、只是语气太整齐,先做轻润色,不要急着整篇推倒重写。
- 如果稿子缺案例、缺判断、段落平得像模板,直接进入深度重写,而不是先跑一轮同义词替换。
- 如果场景涉及课程作业、申请材料、客户审核或外部署名,除了改文,还要保留版本记录、来源说明和必要的 AI 协作披露。
- Google 关注的是内容是否有帮助、可抓取、可验证,而不是你有没有专门做“AI SEO”(Google Search Central,2026-03-18)。
- AI detector 最多只能做风险信号,不能替代人工判断;Turnitin 和 Grammarly 都明确写明它不应被当成唯一依据(Turnitin Guides,2026-03-18;Grammarly,2026-03-18)。

为什么这篇指南必须重写:别再把目标设成“绕过检测”
旧版本这类文章最常见的问题,
是把“更像人写的内容”简单等同于“更难被检测出来的内容”。
这在 2024 年可能还能吸引点击,但现在已经不是最有价值的写法了。
一方面,AI 协作写作本身已经很常见。
Ahrefs 对 90 万个新网页的研究显示,71.7% 的页面属于 AI 与人工混合创作,纯人工为 25.8%,纯 AI 为 2.5%(Ahrefs,2026-03-18)。
这说明今天真正的现实不是“你有没有用过 AI”,
而是“你有没有做过足够的人工增值”。
另一方面,主流平台也已经把叙事从“躲检测”转向“负责地使用 AI”。
Grammarly 在自己的 detector 页面直接写明,没有任何 AI detector 是 100% 准确的,检测结果不应该单独决定结论(Grammarly,2026-03-18)。
Turnitin 也明确说明,
AI Writing Report 可能误判,
不应作为对学生采取不利处分的唯一依据(Turnitin Guides,
2026-03-18)。
这两个官方信号很重要。
它们的意思不是“检测器没用”,而是“检测器不是终点”。
如果你把全部精力都放在“怎么把分数压低”,
你很容易漏掉真正决定内容质量的东西:事实是否站得住,
结构是否在回答问题,
判断是否像一个真实作者做出的选择。
更现实的一点是,
今天很多 humanizer 工具页依然会把“100% human”“bypass detection”当成首屏承诺,
但更可信的一手来源给出的方向恰好相反:
检测结果会误判,
生成式 AI 内容要优先保证准确、相关和对读者有帮助,
必要时还要把 AI 协作边界讲清楚(Google Search Central,2026-03-18;Grammarly,2026-03-18;Turnitin Guides,2026-03-18)。
Google Search Central 现在对 AI features 的说明也很直接。
它没有要求你为 AI Overviews 或 AI Mode 额外做一套“特殊 AI 优化”。
真正仍然重要的,
还是文本可抓取、内链清晰、页面体验好、图片质量高,
以及内容是否 genuinely helpful(Google Search Central,
2026-03-18)。
这也是为什么一篇真正强的“AI创作人性化指南”,不能停留在换同义词和打乱句长。
它必须先让读者做对判断。
如果你更关心“检测器该怎么用、哪个工具适合中文和多语言内容”,可以配合阅读AI内容检测工具指南。 但如果你现在的问题是“手里的稿子怎么改”,先把这篇看完更重要。
先做判断:AI 协作稿人性化四层决策矩阵
很多文章一上来就教你改句子。 我建议反过来。 先判断这篇稿子属于哪一层,再决定改法。 因为只要层级判断错了,后面的力气基本都会花偏。

| 你手上的稿件 | 常见场景 | 最大风险 | 第一动作 | 最终建议 |
|---|---|---|---|---|
| 事实基本可靠,结构完整,只是语气太平 | 社媒文案、团队邮件、低风险博客草稿 | 看起来像模板,缺少节奏 | 轻润色 | 先改语气和节奏,不必整篇重写 |
| 结构有了,但没有作者判断和案例支撑 | 品牌博客、知识库文章、官网内容 | 像“任何品牌都能套”的空泛稿 | 深度重写关键段 | 补判断、补案例、补取舍逻辑 |
| 段落顺得过头,结论全是套话,案例也泛 | 营销长文、落地页、对外发布稿 | 品牌可信度受损 | 整体重写 | 不要先丢给 humanizer,先重构结构 |
| 涉及课程、申请、审核、合同验收 | 学术场景、学习申请、客户验收 | 诚信争议和误判风险 | 保留证据链 | 改文同时保存版本记录、来源说明,必要时披露 AI 协作 |
这张表真正要解决的问题,是把“人性化”从一个模糊审美词,变成一个具体动作选择。 第一层:轻润色。 适用于你已经知道这篇内容方向没错, 信息也够, 只是句子太齐、段落太平均、语气太像默认模板。 这种情况下, 最有效的动作不是全面重写, 而是局部调节节奏、减少空泛连接词、把几个关键句改得更像真实人在说话。 第二层:深度重写。 适用于稿子有骨架,但没有判断。 最典型的信号是:它什么都说到了,但哪怕读完你也不知道作者到底推荐什么。 这种稿子即使用 humanizer 润一轮,也只是“更自然地空泛”。 第三层:整体重写。 适用于内容的根问题不在语言,而在思路。 如果稿子所有段落都一样平, 例子都是“企业可以…用户可以…平台可以…”, 那它的问题不是“像 AI”, 而是“根本还没形成作者视角”。 这时不应该做表面处理, 而应该直接重写首屏、关键判断段、结论段和至少一个决定读者动作的核心章节。 第四层:证据链与披露。 这是很多 humanizer 页面不会认真讲的部分。 一旦内容进入学习申请、课程作业、研究摘要、外部客户验收、公开署名等高风险场景, 改写本身就不是全部工作。 你还需要同时准备版本记录、来源清单、修改痕迹, 以及在规则要求下的 AI 协作披露。
这一步做对,比把 detector 分数再压低 7 个点更重要。 如果你只想记住一句话,可以这样判断: 低风险稿件优先考虑“怎么改得更像你”; 高风险稿件优先考虑“怎么证明这份内容经过了你的真实判断和编辑”。
先改哪一层:事实、结构、判断、语气的四步编辑顺序
大多数改坏的 AI 稿,都是因为编辑顺序反了。 很多人先去换词、缩句、加口语,然后才发现后面整段逻辑都不成立。 正确顺序应该是先把“不能错的”处理掉,再去处理“像不像人写的”。
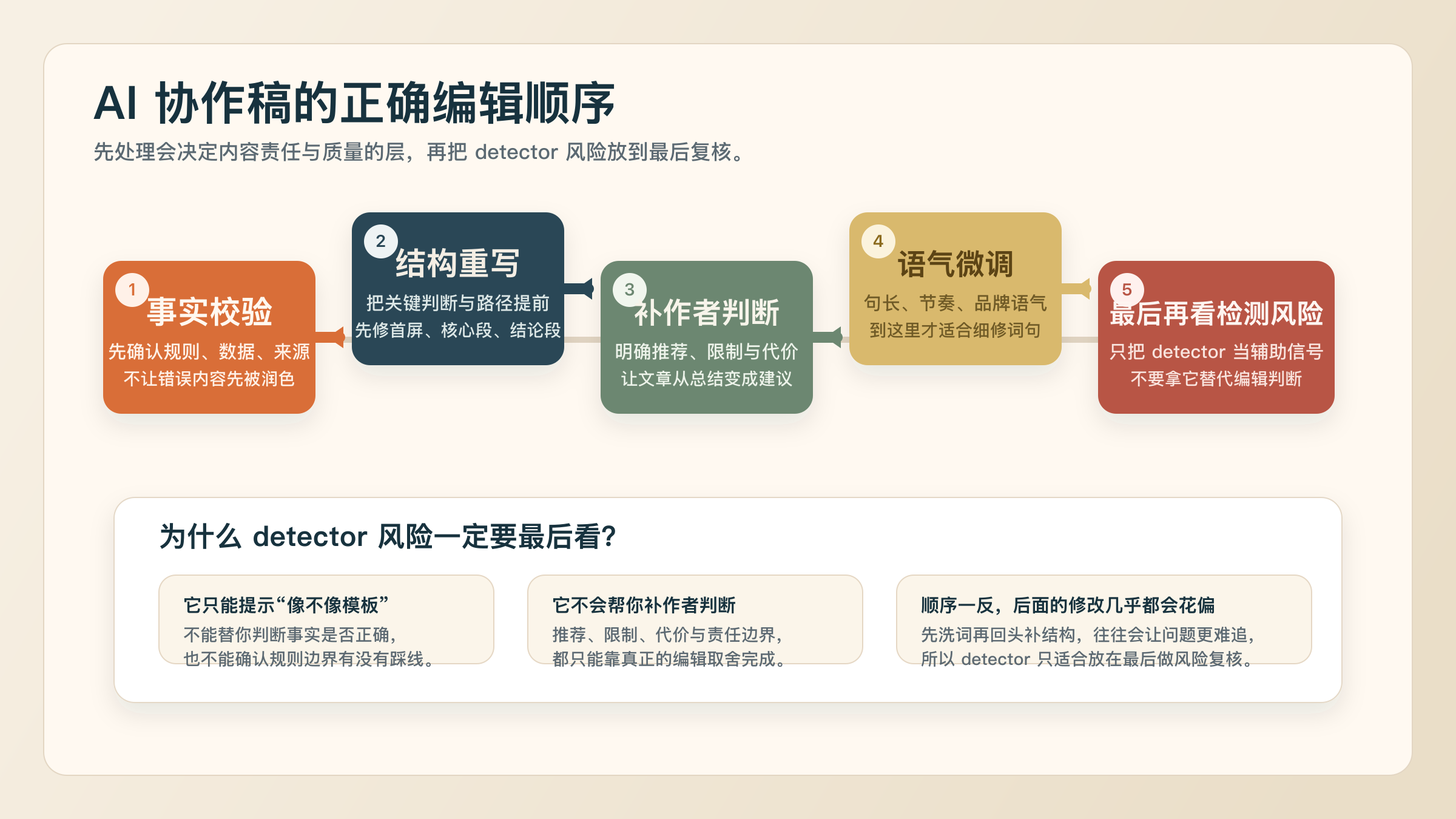
第一步,先做事实校验。 如果一篇稿子的事实本身就站不住, 后面所有“更自然”的修辞都是在帮错误内容变得更像真的。 尤其是涉及检测器、学校规则、搜索引擎、模型能力这类容易变化的话题, 先确认事实边界, 再谈文风。 例如, Google Search Central 现在明确说明, AI features 不需要单独的特殊优化, 基础 SEO 仍然适用(Google Search Central, 2026-03-18)。 如果你还在稿子里写“只要把 AI 痕迹抹干净就更利于搜索”,那就是顺序错了。 又例如, Turnitin 不是“最后的法官”, 而是一个需要人工复核的风险信号(Turnitin Guides, 2026-03-18)。 如果稿子把它写成“高分就基本确定是 AI”,那也要先改事实,不是先改语气。 第二步,再做结构重写。 真正显得“像 AI”的文章,常常不是因为某个词,而是因为整个结构太平均。 每个段落都差不多长。 每个结论都差不多保守。 每个小节都像按同一模板展开。 这时最有效的动作通常不是替换词语,而是重排段落顺序。 把最关键的判断提前。 把真正帮助读者做决定的表格或框架提前。 把泛泛的背景解释缩短。 Google Search Central 还提到, AI Mode 更适合复杂比较与探索型查询(Google Search Central, 2026-03-18)。 这意味着对这类主题,真正有价值的不是“更多背景”,而是“更快给出比较和路径”。 第三步,补作者判断。 这是很多 AI 稿最缺的层。
你会发现它看起来什么都没错,但就是没有人味。 原因往往不是它不口语,而是它不承担判断。 它只会说“要视情况而定”“需要综合考虑”“合理使用工具很重要”。 真实作者的文字,通常会在关键处做一个更清晰的取舍。 例如: 对于低风险社媒文案,我会明确说先做轻润色,不要浪费时间跑 detector。 对于品牌博客, 如果首屏还在解释“AI 是什么”, 那就不是润色问题, 而是首屏重写问题。 对于申请材料或课程作业, 我会明确把证据链放到和改文同等重要的位置, 而不是等到出问题再补。 这类判断一出现,文章就会明显从“系统总结”变成“有人负责的建议”。 第四步,最后才做语气微调。 到了这一步,你才适合去改句长、节奏、连接词、代入感和口语程度。 因为这时内容方向已经稳定,语气调整才不会把真正重要的信息带偏。 最稳妥的做法通常不是“让每一段都更口语”,而是让该有作者存在感的地方更像作者。 重点通常是:
- 开头两段
- 核心建议段
- 转折段
- 结论段
- FAQ 里的明确回答
这些地方一旦仍然像模板,读者会在前 30 秒内失去信任。 第五步,检测风险只放在最后看。 这一步不是完全不需要,而是不该先做。 Grammarly 已经写得很清楚, AI detector 不能独立证明作者身份, 也不能保证不误判(Grammarly, 2026-03-18)。 所以更合理的顺序是:先把内容变得具体、可验证、可归因, 再看它在 detector 里是否仍然显得过于机械。 如果你在 prompt 阶段就想减少后期返工,也可以顺手看如何改进提示词生成的内容。 但即便 prompt 写得更好,最后这四步编辑顺序依然不能省。
什么时候用 humanizer,什么时候必须人工重写
现在的主流工具页都在说 humanizer。 这本身没有问题。 Grammarly 把重点放在 custom voice 与 authorship。 QuillBot 也不再只强调“更自然”, 而是连 AI 使用规范和引用边界一起写进了页面(Grammarly, 2026-03-18; QuillBot,2026-03-18)。 真正的问题不是能不能用,而是该用到什么程度。 我的建议很简单。 把 humanizer 当作“后处理工具”, 不要把它当作“补救所有结构问题的总开关”。 适合优先用 humanizer 的情况,通常有三个信号。 第一,稿子的事实已经核对过了。 第二,结构已经像一篇真实文章,而不是大纲扩写。 第三,缺的主要是节奏、口语温度和品牌语气一致性。 如果这三点都成立,humanizer 很适合做最后一轮打磨。 它能帮你把过度整齐的表达拉回自然区间, 也能帮你发现一些“默认 AI 腔”的重复句式。 但下面这些情况,我更建议直接人工重写。 情况一:开头没有真实场景。 如果一篇稿子的前两段只是在说“随着人工智能的发展……”,那不叫文风问题。 那是首屏失焦。 这种地方必须人工重写。 因为你真正要补的是判断和场景,而不是句法变化。 情况二:核心建议没有取舍逻辑。 如果文章一直在说“都可以”“视情况而定”, humanizer 再强也只能让模糊结论变得更顺口。 它不能替你做决定。 真正该做的是把“为什么推荐 A,不推荐 B”写出来。 情况三:案例和证据太泛。
如果稿子里全是“企业可以”“用户可以”“平台能够”, 你需要补的是具体案例、具体限制、具体代价。 这也不是 humanizer 的工作。 情况四:高风险场景。 课程作业、学习申请、研究摘要、客户验收、公开署名报告, 这些内容不适合把核心动作设成“先让它不那么像 AI”。 正确动作是先确认规则,再记录过程,再完成重写和必要披露。 一句话总结: humanizer 更适合处理“像不像你”的末端问题。 人工重写负责解决“这篇内容到底有没有你的判断”的根问题。 如果你还在挑选起草工具,而不是后处理方式,可以再看AI写作工具指南。 但工具选得再好,也替代不了最后这一步人工判断。
三类常见场景怎么做:品牌内容、学习申请、社媒短稿
同样是“AI 创作人性化”,不同场景的优先级完全不同。 把它们混成一套建议,是很多旧教程最大的问题之一。
品牌内容:优先补观点和品牌语气,不要只改词
品牌博客、官网长文、知识库文章最怕的, 不是机器味本身, 而是“任何品牌都能发”的空泛感。 这种稿子常见的坏味道不是口语不足, 而是所有判断都很安全、所有建议都很中性、所有段落都过度平均。 如果你负责品牌内容,我建议先检查两件事。 第一,这篇内容有没有清楚告诉读者“我们为什么推荐这条路”。 第二,这篇内容有没有至少两三处明显属于这个品牌或作者的判断方式。 如果这两件事都没有,先别急着让工具帮你“自然化”。 先把首屏、关键建议段、对比段和结论段重写出来。 之后再做语气微调,效果会比先 humanize 一轮好得多。
学习申请或课程相关:先看规则,再看写作过程
这一类场景最容易走偏。
因为很多人一看见 detector 分数高,就想通过改写把风险压下去。
但真正重要的,不是“改到多少分”,而是这份内容能不能说明它经过了你的真实参与。
Turnitin 明确提示 AI Writing Report 不应被用作唯一处分依据,而且 1%-19% 的区间不再展示精确数值,以减少误解(Turnitin Guides,2026-03-18)。
这其实是在提醒你:单个分数没有你想象中那么稳定。
如果你处在这类场景,最该做的不是一轮又一轮地洗稿,而是准备好:
- 草稿版本记录
- 资料来源
- 你做过哪些修改
- 哪些部分用了 AI 起草
- 规则要求下的必要说明
真正能降低争议的,往往不是“更像人类的句子”,而是“更完整的过程证据”。
社媒短稿、邮件和内部沟通:快改快发,别过度工程化
最容易被过度操作的,其实是最短的内容。 几十到几百字的社媒文案、工作邮件、活动通知,本身就不适合拿检测器做强判断。 短文本上下文太少,模型很容易把“简洁模板化”误判成“像 AI”。 这种内容更实用的做法是: 先删掉过度完整的套话。 再把一个最重要的判断写明确。 最后把句子节奏拉开一点。 如果你发的是品牌账号内容,再加上一点具体场景或动作提示,通常就足够了。 在这一类场景里,追 detector 分数经常是最浪费时间的一步。
改完以后怎么自检:别把 detector 分数当终点
改写完成后,我更建议你做一轮“编辑自检”,而不是立刻去测分。 这轮自检的目标, 是确认内容已经从“看起来像生成结果”变成“看起来像有人负责的判断”。 你可以直接用下面这张表。
| 自检问题 | 如果答案是“否”,你该做什么 |
|---|---|
| 开头两段有没有具体场景,而不是大背景套话? | 重写首屏,把读者当前的决策困境写出来 |
| 关键建议有没有明确取舍,而不是“都可以”? | 补一条更明确的推荐逻辑 |
| 至少 3 个关键判断有没有来源或事实依据? | 回到资料核验,而不是继续调语气 |
| 是否出现了只有这个作者才会做出的判断或例子? | 补作者判断和场景细节 |
| 图片和表格是否真的在解释内容,而不是装饰? | 砍掉装饰图,换成解释图 |
如果这五个问题里有两个以上答不上来,说明你还没完成“人性化”。 因为真正的人性化不是更像聊天,而是更像一个真实编辑对这份内容负过责。 你当然也可以在最后跑一次 detector。 但要记住它的定位。 它只适合告诉你:这篇稿子是否还有明显机械感,是否需要继续做人工复核。 它不适合告诉你:这篇稿子是不是已经“安全”。 Grammarly 自己就在 FAQ 里写明, AI detector 不能独立判断作者身份, 轻度编辑的 AI 内容也可能逃过检测(Grammarly, 2026-03-18)。 所以更稳妥的流程是: 先做编辑自检。 再把 detector 当作辅助信号。 如果你发现 detector 结果仍然偏高,不要直接开始洗词。 先回头问自己三个问题: 是不是首屏还太模板化? 是不是判断还不够明确? 是不是案例仍然太泛? 这三个问题比“再换几个词”更可能让你找到真正的症结。
哪些场景必须保留证据链或披露 AI 协作
很多页面会把这部分写得很轻。 我反而认为,这才是这类主题里最容易被低估的内容。 只要你进入下面这些场景,就不要把“改得更自然”视为全部工作。
| 场景 | 为什么风险更高 | 最少要保留什么 |
|---|---|---|
| 课程作业、研究摘要、学习申请 | 可能触发诚信和误判争议 | 版本记录、资料来源、修改说明 |
| 客户验收稿、外部署名稿 | 涉及责任边界和交付标准 | 原始需求、草稿演变、审校痕迹 |
| 企业知识库、规范文档 | 错误信息可能被反复传播 | 事实来源、更新时间、责任人 |
| 招聘材料、公开个人陈述 | 直接影响个人信誉 | 自述修改记录、来源与 AI 使用边界 |
这张表背后的逻辑其实很简单。 低风险场景里,你主要是在优化“读起来像不像你”。 高风险场景里,你还必须能够回答“这份内容为什么可以代表你或你的组织”。 Turnitin 的说明之所以重要,不只是因为它谈到了误判。 更因为它把“进一步审查与人工判断”写成了必要条件(Turnitin Guides, 2026-03-18)。 这和很多人的直觉正好相反。 很多人觉得,只要把内容再改一改,让它看起来更不像 AI,就能解决风险。 其实在高风险场景里,真正有用的是两件事: 第一,你有没有实质性参与判断和重写。 第二,你能不能把这个过程解释清楚。 如果机构、学校、客户或团队规则要求披露 AI 协作, 就不要把披露理解成“认输”。 恰恰相反。 在很多情境里,清楚说明 AI 参与范围,比模糊处理要更安全。 因为它把争议焦点从“你有没有偷偷用 AI”转向“你有没有对最终内容负责”。 而真正值得信任的写作者和编辑,最终都要回到这个问题。
常见问题(FAQ)
AI humanizer 能不能保证内容不被检测出来?
不能。
更准确地说,也不应该把目标设成这个。
Grammarly 已经明确写明,没有任何 AI detector 是 100% 准确的,检测结果只能作为整体判断的一部分(Grammarly,2026-03-18)。
这意味着“压低一个工具的分数”从来都不等于“证明内容已经没有风险”。
如果你真的在高风险场景里工作,
更值得追求的是让内容更具体、更有作者判断、更有证据,
而不是单纯让句子更像人工。
如果 detector 给了很高的分数,我第一步应该改哪里?
先不要碰词汇表。 先回去检查首屏、关键判断段和案例段。 大多数高分内容的根问题, 不是某几个词太像 AI, 而是开头没有真实场景、正文没有明确取舍、例子太泛。 如果这些地方没改,再多的语言微调也只是表面工程。 真正的顺序应该是:事实校验、结构重写、补作者判断、语气微调, 最后才看 detector 风险。
品牌博客和课程作业,是不是都能用同一套“人性化”方法?
不能。 品牌博客最重要的是读者价值和品牌可信度, 所以重点通常是首屏场景、品牌语气、判断逻辑和案例深度。 课程作业或学习申请则更强调规则边界、过程证据和可能的 AI 使用披露。 前者主要解决“像不像一个真实品牌或作者写的”, 后者还要解决“能不能证明这是你真正参与完成的内容”。 把这两类场景混成一套建议,就是很多旧教程最容易误导人的地方。
只改同义词、打乱句长、加一点口语,是不是就够了?
通常不够。 这些动作只能处理语气层的问题。 如果稿子本身结构模板化、案例空泛、结论不承担判断, 你只是把一篇空泛文章改得更像口语而已。 真正有效的人性化, 至少要补到三件事:更明确的场景、更清楚的作者判断、以及更具体的证据或例子。 只做同义词替换,很容易让文本看起来不像 AI,却还是不值得读。
什么时候该主动披露 AI 协作,而不是只做改写?
只要你所在的机构、学校、客户或团队规则有要求,就应该优先遵守规则。 除此之外, 凡是内容会进入公开署名、正式审核、课程评估、合同交付等高风险场景时, 我都建议你至少准备可解释的版本记录和来源说明。 披露的意义不在于证明你“没有借助 AI”, 而在于说明你对最终内容承担了什么责任。 在高风险场景里,这比一味追求“看不出来”更稳妥。
为什么中文内容特别容易显得“像 AI”?
问题往往不只在中文本身,而在中文内容的常见写法。 很多中文品牌稿、说明文、知识库和申请材料, 本来就偏爱稳定句式、整齐段落和抽象总结。 这些特征和很多人理解的“AI 味”高度重合, 所以一旦再叠加模板化结构, 就会显得更明显。 这也是为什么中文场景里真正有效的做法, 不是机械增加口语, 而是补充更具体的案例、判断和结构变化。
现在做内容优化,还要不要在意 GEO 和 AI answer 的可抽取性?
要,但方向不是做一套神秘的“AI 优化术”。 Google Search Central 已经说明, AI features 仍然沿用基础 SEO 思路, 包括文本可抓取、内链、页面体验和高质量图片(Google Search Central, 2026-03-18)。 真正适合 GEO 的内容, 通常都有共同点:前屏回答快、关键判断可引用、表格和 FAQ 清楚、信息有来源、图片能解释问题。 换句话说,GEO 的本质不是更会藏 AI,而是更会组织答案。
总结:真正的人性化,不是更像人设,而是更像作者
如果你只从这篇文章带走一个结论,我希望是这个: AI 创作人性化的核心, 不是把所有句子都改得更口语, 也不是让所有 detector 都更难抓到你。 真正的核心,是让最终内容更像一个真实作者或编辑做过判断之后的结果。 这意味着你要先做对路线选择。 低风险稿件,优先轻润色。 结构空泛的稿件,优先深度重写。 高风险场景,优先把证据链和披露准备好。 当你先把这三个判断做对,后面的语言优化才有意义。 否则,所谓“人性化”很容易只剩下一层更柔和的模板味。