AI绘画角色一致性怎么做:按 3 层工作流选对路线的实战指南
角色一致性不是“哪个 AI 画图工具最好”的问题,而是你该停留在单图引用、升级到 Control 工作流,还是直接训练角色模型。本文基于 2026-03-18 官方资料复核,重构 Midjourney、OpenAI、Leonardo 与 Stable Diffusion 的角色一致性路线。
Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
如果你要让同一个漫画主角、 品牌吉祥物、 虚拟主播或游戏角色连续出现在多张图里, 真正困难的通常不是“哪个模型最强”, 而是你到底在解决哪一类一致性问题。 你是只想用一张参考图快速换几个场景, 还是要做 20 张连贯海报, 或者准备长期维护一个会反复出现在商业资产里的角色设定? 这三种任务看起来都叫“角色一致性”, 但它们根本不是同一层工作流。
很多旧教程会把 Midjourney、 ChatGPT、 Leonardo、 Stable Diffusion、 ComfyUI 一股脑放进同一张排行榜里, 最后给出一个看似全面、 实际很难落地的结论。 结果就是读者拿着一张头像硬扛几十张连续场景, 要么风格一变就漂, 要么侧面和全身完全不像同一个人。 本文不再做“7 种方法大盘点”, 而是基于 2026-03-18 仍可核验的官方资料, 直接回答一个更实际的问题: **为了让角色在不同角度、 场景和风格里尽量不漂, 我现在应该选择哪一层工作流, 什么时候必须升级? **
TL;DR
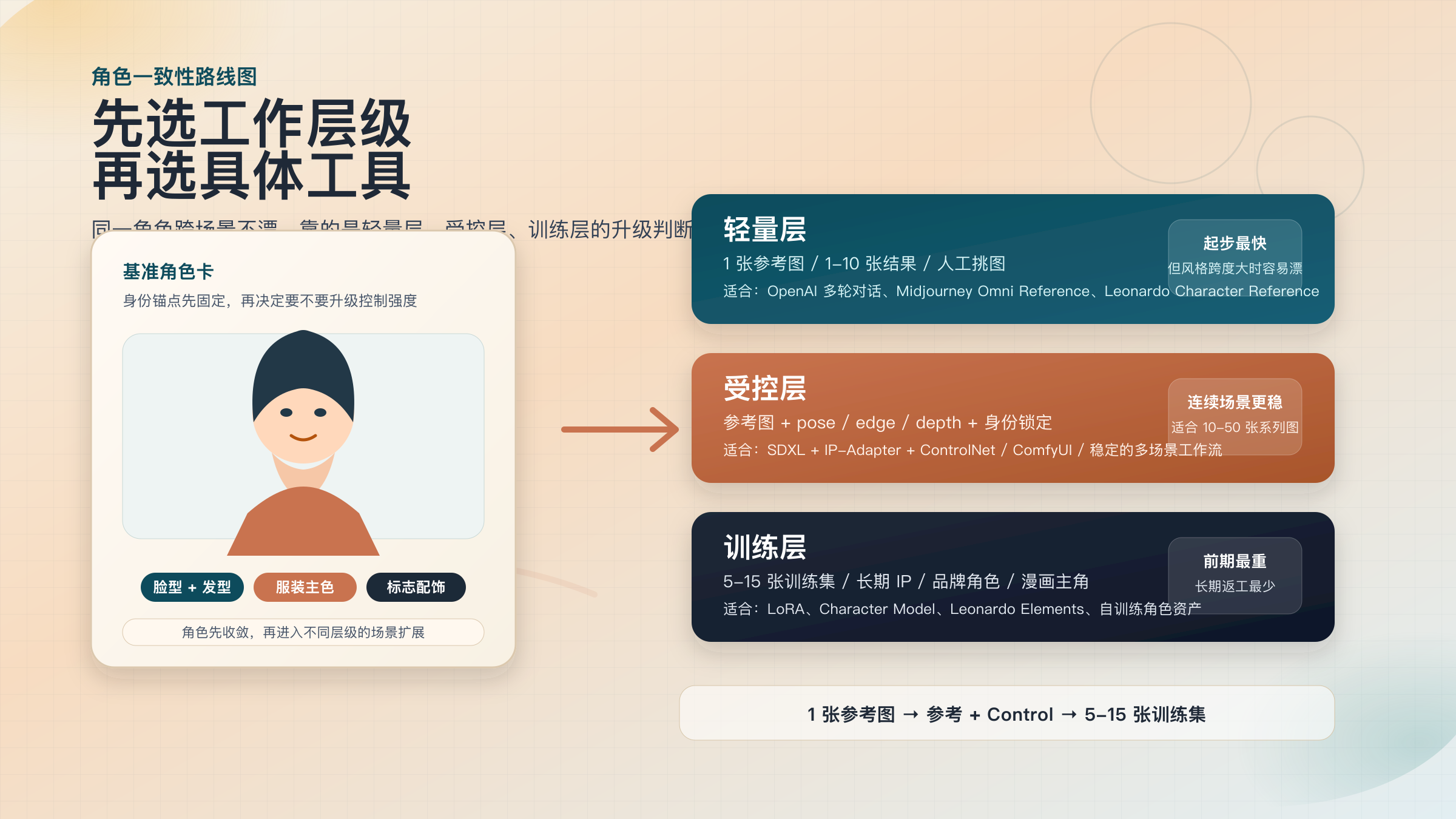
- 如果你只有 1 张参考图, 只想快速出 1-10 张结果, 先看 轻量层: OpenAI 的多轮图像对话、 Midjourney 的 Omni Reference、 Leonardo 的 Character Reference 都适合起步, 但它们本质上仍是“引用式一致性”, 不是长期角色资产系统。
- Midjourney 现在的角色一致性路径是
Omni Reference, 仅支持 1 张参考图, 约消耗2xGPU 时间, 且不兼容 Pan、 Zoom Out、 Vary Region 等旧编辑能力(Midjourney Docs, 2026-03-18 核验)。- 当你开始做连续场景、 不同机位或稳定复用的角色内容时, 应该尽快升级到 受控层: ControlNet 提供 pose / edge / depth 等条件控制, IP-Adapter 则是“不训练整模型也能锁住身份”的中间层(Hugging Face Diffusers, 2026-03-18 核验)。
- 如果角色会长期复用, 或者你已经拥有 5-15 张可整理的参考集, 直接考虑 训练层 更省返工。 Scenario 也明确把 single-image consistency 与 5-15 张图的 LoRA 训练分开, 后者才是高保真的长期路径(Scenario, 2026-03-18 核验)。
- 这篇文章最重要的结论不是“谁第一”, 而是: **先判断项目属于哪一层, 再选工具。 ** 选错层级, 比选错产品更容易让角色崩掉。
先说结论:角色一致性不是选“最好工具”,而是选对工作层级
角色一致性最常见的误判, 是把所有问题都丢给同一种方法。 有些人只有一张头像, 却想直接做几十张不同角度的角色图; 有些人明明只是想快速做几张概念图, 却一开始就准备训练 LoRA。 前者会在连续出图时被漂移拖垮, 后者则会在前期投入上浪费太多时间。 真正有效的做法, 是先判断你处在哪一层工作流。
第一层是轻量层。 它适合手里只有一张参考图、 需要快速探索方向、 愿意人工看结果的人。 这一层的特点是启动快、 学习成本低, 但稳定性依赖参考图质量、 提示词纪律和上下文连续性。 第二层是受控层。 一旦你进入连续场景、 不同机位、 不同姿态, 或者开始在多张图里维持同一个角色的服装、 发型和面部结构, 你就需要更明确的结构控制。 第三层是训练层。 当角色已经不只是“一次性的生成对象”, 而是一个要长期复用、 跨项目维护的资产, 训练角色模型、 LoRA 或平台内的 Element/Character Model 通常反而更省总成本。
这三层并不是“从低到高”的鄙视链, 而是三种完全不同的生产逻辑。 轻量层解决的是“我能不能尽快出一版像样的角色变化图”; 受控层解决的是“我能不能在多场景里把同一个人尽量锁住”; 训练层解决的是“这个角色以后会不会成为长期资产”。 只要你在开始前把这个问题想清楚, 后面的工具选择会清楚很多。
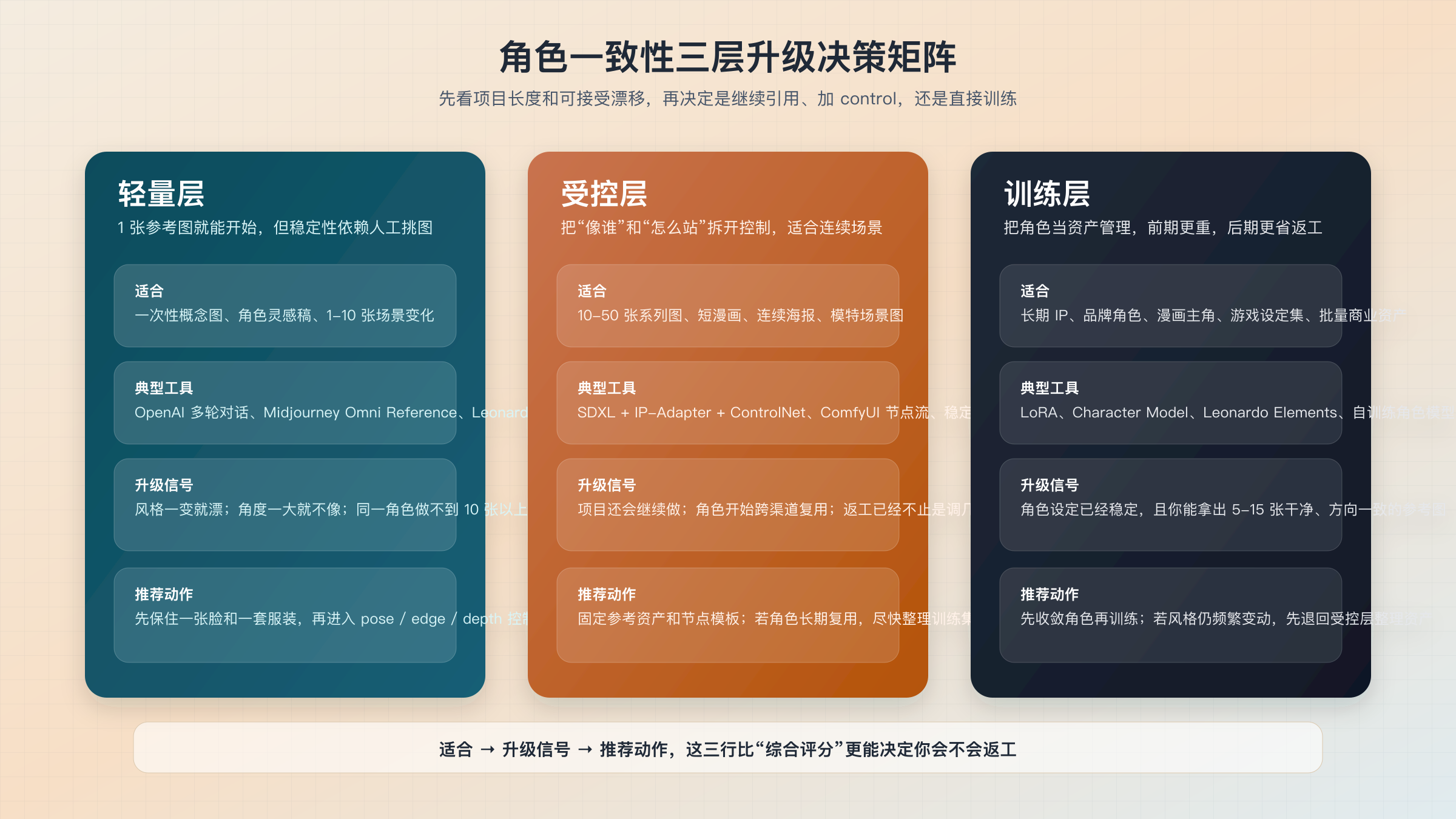
角色一致性三层升级决策矩阵
下面这张矩阵不是按“综合评分”排的, 而是按你面对的任务类型来判断。 读的时候不要问“哪个工具最厉害”, 而要问“我的返工成本会在哪一层开始失控”。
| 层级 | 最适合的项目 | 典型路线 | 明显短板 | 升级信号 | 推荐动作 |
|---|---|---|---|---|---|
| 轻量层 | 一次性概念图、1-10 张角色变化图、人工审图 | OpenAI 多轮图像对话、Midjourney Omni Reference、Leonardo Character Reference | 风格跨度大时容易漂;连续场景稳定性有限 | 一换角度就不像、一换风格就丢脸部特征 | 加入 pose / edge / depth control,进入受控层 |
| 受控层 | 10-50 张连续场景、短漫画、商品模特、海报系列 | SDXL + ControlNet + IP-Adapter、ComfyUI 节点流、Leonardo image guidance | 搭建成本更高;维护参数和参考资产更复杂 | 同一角色会长期复用,且数据集已经可整理 | 把参考流程升级为训练流程,进入训练层 |
| 训练层 | 长期 IP、品牌角色、漫画主角、游戏设定集、批量商业资产 | LoRA、Character Model、Leonardo Elements、自训练角色模型 | 前期准备最重;需要更好的素材纪律 | 角色设计频繁变化、训练集质量不稳定 | 先回到受控层收敛设计,再重做训练集 |
这张表真正想告诉你的, 不是某家产品强弱, 而是一致性问题本身会随着项目长度发生质变。 在轻量层里, 你主要在和“引用是否足够强”作斗争; 到了受控层, 问题会变成“我能不能把姿态、 结构和身份拆开控制”; 到了训练层, 问题又变成“这个角色是不是已经值得被当成长期资产管理”。 如果你拿轻量层的办法去硬扛训练层的问题, 最后几乎一定是返工暴涨。
轻量层:只有一张参考图时,先用对话式或引用式流程
轻量层并不意味着“效果差”, 而是指它更适合在信息不完整、 目标还在变化、 你需要快速试方向的时候使用。 比如你刚刚确定了一个漫画主角的气质, 只想先看他站在街头、 咖啡馆和地铁站里会是什么样; 或者你要给品牌吉祥物做几个初版海报, 先看色调和服装方向能不能过审。 这时候最快的路线, 往往不是训练模型, 而是用单图引用和多轮对话把方向先跑出来。
OpenAI 这一层的优势在于多轮 refinement。 官方在 4o 图像生成介绍里明确强调, 它支持在对话上下文里继续修改图像, 并在连续对话中保持相对一致的视觉身份(OpenAI, 2026-03-18 核验)。 这意味着它很适合“先做出一个基准角色, 再用追加指令逐步改背景、 动作、 服装细节”的工作方式。 它的强项不是批量流水线, 而是你可以边看结果边收敛角色定义。
Midjourney 这条线仍然值得用,
但要按现在的规则理解。
当前角色一致性能力不是旧文里常见的 --character,
而是 V7 的 Omni Reference。
官方文档说明,
--oref 只支持 1 张参考图,
约消耗 2x GPU 时间,
并且和 Pan、
Zoom Out、
Vary Region 这些仍跑在旧版本上的能力不兼容(Midjourney Docs,
2026-03-18 核验)。
这说明 Midjourney 更适合把一个已经看顺眼的角色继续拉向多个场景和艺术方向,
而不是做高度可预测的连续生产。
Leonardo 也应该按当前文档来理解。
它的 Character Reference 不是“完美复制器”,
而是一个权重可调的身份参考层。
Leonardo 官方文档给出的 weight 范围是 0-2,
并明确提醒它并不保证 perfect replica(Leonardo Docs,
2026-03-18 核验)。
这句话很重要,
因为它等于告诉你:
Leonardo 的轻量引用适合快速尝试和稳定角色气质,
但如果你已经开始追求“每次都像同一个商业 IP”,
那就不该继续把希望全压在 Character Reference 本身上。
轻量层的正确用法, 是先把角色的“不可丢特征”定义清楚。 通常至少要包括脸型、 发型、 服装主色、 最有辨识度的配饰, 以及一个最稳定的基准姿态。 这个阶段最忌讳的是一边换场景、 一边换风格、 一边换视角, 还指望角色继续绝对稳定。 轻量层的优势在于低启动成本, 不在于无限容错。
如果你只有一张参考图, 我更建议先手动补一张“文字版角色卡”。 哪怕只是 5 行内容, 也要把不能变的元素单独写出来, 例如“刘海长度”“耳饰是否必须出现”“上衣主色”“眼型”和“最常见的镜头距离”。 这样做的价值, 不是为了让 prompt 看起来更专业, 而是为了防止你在连续几轮对话后自己也忘了到底什么才算“同一个角色”。
轻量层还有一个常见误区, 就是过早要求模型同时处理“身份一致”“风格大改”“复杂动作”“环境切换”四件事。 正确顺序应该是先锁身份, 再放大变化。 你可以先做一张正面半身、 一张全身站姿、 一张最常见场景图, 把这三张当成你的最小角色包。 等这三张都稳定了, 再继续往更复杂的镜头推进。
如果你现在只是要做几张灵感图, 轻量层完全够用。 但只要你的需求开始碰到“连续镜头”“系列海报”“同一角色的多角度展示”, 你就应该提前准备进入下一层。 否则你会把大量时间浪费在重复强调提示词、 重复挑图、 重复修脸上, 看起来省事, 实际上最耗人。
受控层:当你要做连续场景时,必须把参考图变成可控工作流
受控层的本质, 是承认单图引用本身不够稳定, 于是把“角色是谁”和“画面怎么摆”拆开控制。 到了这一层, 你不再只依赖一句“请保持同一角色”, 而是会让模型分别收到身份参考、 结构约束、 姿态约束, 必要时还会加入风格控制或局部修正。 只要项目进入 10-50 张的连续产出, 这种拆分几乎就是必要条件。
ControlNet 是这层的核心原因之一。 Hugging Face Diffusers 的文档明确说明, ControlNet 可以通过 canny、 pose、 depth 等额外条件输入来约束扩散模型(Hugging Face Diffusers, 2026-03-18 核验)。 这意味着你可以用 reference 负责“像谁”, 用 pose 或 edge 负责“怎么站、 怎么转、 轮廓怎么走”。 一旦把这两个问题拆开, 角色在多角度和多场景里的稳定性通常会立刻提升。
IP-Adapter 则是另一个关键中间层。 Diffusers 也明确把它定义为一种 image prompting adapter, 可用于 SD / SDXL / ControlNet 组合, 而不需要像训练 LoRA 那样先做完整微调(Hugging Face Diffusers, 2026-03-18 核验)。 这就是为什么很多成熟的角色一致性工作流并不是“只上 ControlNet”或者“只上 reference”, 而是会把 IP-Adapter 当作身份锚点, 再配合结构控制去做连续场景。
这也是我更推荐在 ComfyUI 或稳定的 SDXL 工作流里做中批量角色项目的原因。 你可以把基准角色图、 ControlNet 节点、 IP-Adapter 节点、 采样参数和后处理串成可复用流程。 第一次搭建确实比轻量层麻烦得多, 但只要项目要反复做, 这种麻烦是值得的。 相比之下, 纯聊天式流程最容易在第 8 张、 第 12 张、 第 20 张开始失控, 因为你每一张都在重新和模型谈判。
如果你已经决定走这条路线, 可以继续参考两篇更偏实践的文章: Stable Diffusion 指南 和 ComfyUI 工作流指南。 它们更适合深入参数和节点细节, 而这篇文章的重点仍然是帮你判断什么时候该升级到这一层。
受控层最重要的纪律, 是把参考资产整理好。 至少准备一张正面、 光线干净、 表情中性的脸部参考, 最好再配一张全身或半身基准图。 不要一开始就拿滤镜很重、 角度极端、 发丝遮脸严重的图去当唯一参考, 那样你其实是在把不稳定种子种进整个工作流里。
如果你想把受控层落到真正可执行的最小流程, 我建议按下面的顺序搭起来:
- 先固定一张身份最稳定的基准图, 不要先追求戏剧性光影。
- 再决定这批图最常见的姿态变化, 用 pose 或 edge 约束去承接。
- 把服装和发型中最容易漂的部分单独观察, 必要时用局部放大或后处理补强。
- 只在流程稳定之后再追求风格强化, 否则你会很难判断到底是哪一层导致了漂移。
这个顺序看起来保守, 但它能显著减少“我以为是模型不行, 其实是工作流变量太多”的误判。 很多人搭受控层失败, 不是因为 ControlNet 或 IP-Adapter 没效果, 而是他们一次改了太多变量, 最后连自己都不知道是哪一步把角色带偏了。
训练层:当角色要长期复用时,直接训练角色模型更省返工
一旦角色开始具备“资产属性”, 也就是它会在接下来的很多张图、 很多个项目、 很多种风格里持续出现, 训练层通常比无限叠加提示词更划算。 这里的关键不是“训练听起来更高级”, 而是你已经进入了一个阶段: 角色本身值得被当成对象管理, 而不是每次重新描述。
Scenario 对这个边界说得很清楚。
它的帮助文档把 single-image consistency 和传统的角色 LoRA 训练明确分开,
并指出后者通常需要 5-15 张参考图,
才能获得更高保真的长期一致性(Scenario,
2026-03-18 核验)。
这句话之所以重要,
是因为它把很多创作者最常见的困惑说透了:
**单图引用适合快,
但不代表它适合长期。
**
Leonardo 的当前体系也在往这个方向走。 官方文档把 custom Elements / LoRAs 视为更灵活、 更适合长期一致图像创建的路径(Leonardo Docs, 2026-03-18 核验)。 换句话说, Character Reference 更像训练前的收敛工具, 而不是训练本身的替代品。 你可以先用轻量层和受控层把角色样貌收敛, 再把相对稳定的设定整理成训练集, 最后让训练层承担长期复用任务。
训练层真正节省的, 不是第一天的时间, 而是第十天、 第二十天、 第三十天的返工。 如果你准备做漫画连载、 品牌长期 campaign、 游戏角色设定集, 或者持续更新的短视频角色封面, 一开始就把角色训练成可调用资产, 往往会比每次重新 prompt 更稳。 很多人以为训练最贵, 但如果你的项目已经明显超出 20 张、 30 张、 50 张图, 继续停留在轻量层或受控层, 真正贵的是人力反复修正。
当然, 训练层也有前提。 最常见的问题不是“训练不会”, 而是训练集本身不稳定。 你如果今天想要写实、 明天想要二次元、 后天又想改发型和服装, 那说明角色定义还没收敛, 根本不该急着训练。 训练层最适合的是设定已经比较稳定、 参考素材够干净、 角色未来会反复出现的项目。 如果这些条件还没满足, 先回到受控层把角色收敛好, 通常更稳。
训练前我通常会额外问四个问题。 第一, 这个角色未来会不会在 1 个月后还继续出现。 第二, 训练集里的图是不是已经能稳定代表同一个设定。 第三, 你是否能接受一次训练后还要继续做少量微调。 第四, 团队有没有能力维护这个角色资产, 而不是只会临时调用一次。 如果这四个问题里有两个回答是否定的, 训练层大概率还不是最合适的时机。
另一个很容易被忽略的点, 是训练层并不天然等于“完全不漂”。 训练后的角色模型更像一个稳定得多的起点, 而不是永远不出错的终点。 你仍然需要限制超大风格跨度、 极端构图和过分复杂的场景提示。 换句话说, 训练层解决的是“减少重复解释角色”的成本, 不是让你彻底摆脱工作流纪律。
不同工具怎么选:按场景数量、风格跨度和时间成本做决定
如果你不想再看抽象概念, 可以直接按下面这个逻辑判断。 你只有一张头像, 想先看角色在三个场景里的感觉, 优先用 OpenAI 的多轮图像对话或 Midjourney 的 Omni Reference; 它们的优势是启动快、 反馈短, 适合先把角色大方向跑出来。 你已经要做一组连续海报、 漫画分镜或稳定的模特图, 直接转入 SDXL + IP-Adapter + ControlNet 这一类受控路线。 你已经在维护一个会反复出现的固定角色, 那就尽量别再把时间花在重复解释角色特征上, 训练层通常更值。
风格跨度也是很关键的判断点。 如果你只是换场景、 不大改审美, 轻量层成功率通常还不错; 但只要你从摄影感角色一下跳到漫画、 插画、 蒸汽波、 3D 渲染等风格跨度很大的输出, 角色漂移就会显著增加。 这时不管你用的是 Midjourney、 OpenAI 还是 Leonardo, 都不要再假设单图引用会无限稳定。 对大幅风格转换项目, 最稳的路线通常是先用轻量层确定角色核心脸谱, 再用受控层或者训练层承接风格变化。
时间成本也不能忽略。 轻量层的优势是今天就能开始, 受控层的优势是明天还能继续稳定复用, 训练层的优势是下个月仍然不会每次从零开始。 如果这是一次性的提案、 概念稿、 角色情绪板, 轻量层就很好; 如果你已经预感到这件事会反复出现, 提早升级通常比晚点补救更划算。
如果你还在 OpenAI 和 Midjourney 之间犹豫, 可以参考这篇更偏图像产品取舍的文章: Midjourney vs GPT-4o 图像对比。 它更适合帮助你判断“我要的是审美方向还是更顺手的多轮调整”。 但无论你最后选哪家, 都不要忘了一个更底层的判断: **你是在做一次性探索, 还是在做可以复用的角色资产。 **
下面这张场景表可以直接拿来做快速选择:
| 场景 | 优先路线 | 为什么 |
|---|---|---|
| 只做 3-5 张角色情绪图 | 轻量层 | 启动快,人工挑图成本低 |
| 做 10-30 张连续分镜或海报 | 受控层 | 姿态、结构、身份必须拆开控制 |
| 长期运营品牌吉祥物或漫画主角 | 训练层 | 角色已经具备资产属性,返工成本高于训练成本 |
| 还没想清楚角色长什么样 | 轻量层起步,再进受控层 | 先收敛身份,再投资更重的流程 |
| 角色设定稳定但输出风格跨度很大 | 受控层或训练层 | 单图引用往往顶不住大风格跳转 |
角色开始漂怎么办:一张排查树帮你决定加 control 还是直接训练
多数角色一致性失败, 不是因为你不会写提示词, 而是因为你没有及时识别出“现在这个症状属于哪一层问题”。 有些漂移是因为参考图太弱, 有些是因为姿态跨度太大, 有些则是因为项目本身已经超出了引用式工作流的能力边界。 只要你把症状和动作对应起来, 排查会快很多。
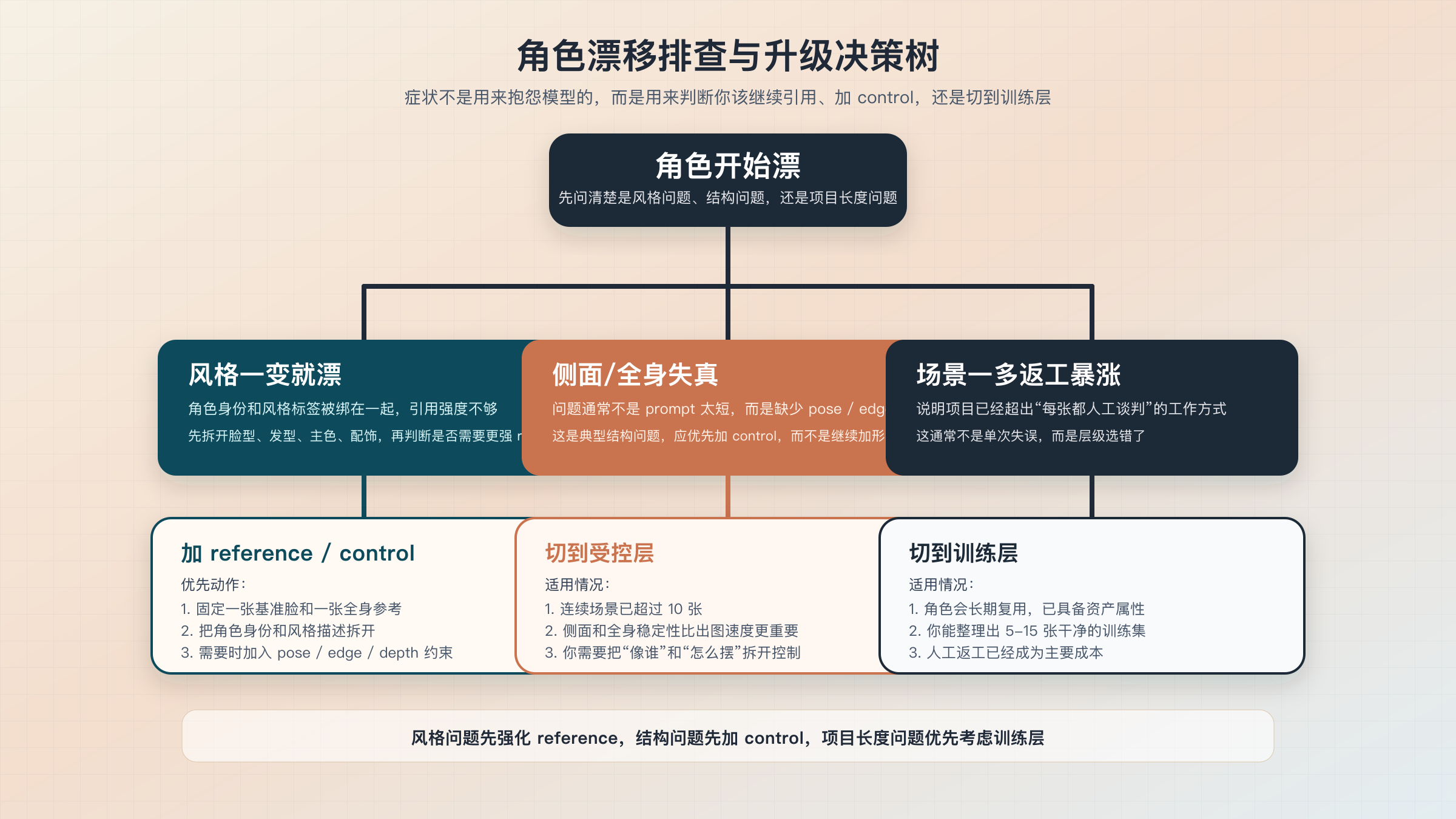
如果你遇到的是风格一变就漂, 最常见原因是角色身份和风格标签纠缠得太紧。 你应该先把角色的脸型、 发型、 服装主色、 标志性配饰从风格描述里分离出来, 再决定是否进入受控层。 如果你遇到的是侧面和全身失真, 问题通常不在于“角色描述不够长”, 而在于缺少姿态或结构约束, 这时就应该考虑 pose、 edge、 depth 这类 control, 而不是继续加形容词。 如果你遇到的是场景一多返工暴涨, 那往往说明项目已经不适合继续停留在轻量层, 应该开始整理训练集或至少把工作流资产化。
下面这张表可以直接当作排查清单:
| 症状 | 更可能的原因 | 优先动作 |
|---|---|---|
| 风格一变就丢脸部特征 | 角色身份和风格 prompt 混在一起;引用强度不够 | 先拆开身份特征,再提高 reference 强度;必要时进入受控层 |
| 侧面、背面、全身不像同一个人 | 缺少 pose / edge / depth 约束 | 进入受控层,加入 ControlNet 或同类结构控制 |
| 同一角色在 10 张之后越来越不稳 | 工作流仍靠人工追加提示词,缺少固定资产 | 先固化参考资产;项目还会继续做时,考虑训练层 |
| 每次都要人工修脸、修服装、修配饰 | 身份锁定不够,且返工已成常态 | 不再盲目加 prompt,改用 IP-Adapter 或直接训练角色模型 |
真正要避免的, 不是某一次失败, 而是你明明已经看到失败模式, 却还继续用同一种方式硬试。 角色一致性最耗时间的地方, 从来不是生成本身, 而是错误层级上的重复试错。
还有三件事特别不值得做。 第一, 不要在角色还没收敛时就急着训练; 你会把不稳定本身固化进去。 第二, 不要在同一轮测试里同时更换参考图、 风格和姿态; 这样失败后你很难知道该怪谁。 第三, 不要只盯着单张效果图做判断; 角色一致性真正的考题从来都是第 5 张、 第 10 张、 第 20 张。
FAQ:风格变化、侧面失败、批量项目、预算有限时怎么选
只有一张头像,也能做出多角度一致角色吗?
可以, 但你要接受这通常只能稳定覆盖轻量层任务。 用一张头像做 3-5 张场景变化图, 或者做一组氛围探索, 成功率往往还不错; 但如果你想直接用一张头像去稳定生成正面、 侧面、 背面、 全身、 动态动作, 并长期保持一致, 风险会很高。 单图引用的正确目标不是“无限稳定”, 而是“快速得到一个可用起点”。
为什么很多角色在换风格时最容易漂?
因为风格变化会迫使模型重新解释脸部、 服装材质和轮廓。 如果你的角色身份没有被单独锁住, 模型就会把“角色是谁”和“画面应该长什么样”一起重算。 Midjourney、 OpenAI、 Leonardo 在轻量层里都可能遇到这个问题, 所以我才更建议把角色定义先抽成固定特征, 再决定风格变化要不要进入受控层。 风格跨度越大, 越不要迷信“单图引用还能一直稳”。
Midjourney、OpenAI、Leonardo 里,哪个最适合新手?
如果你的目标是最快看结果, OpenAI 的多轮图像对话通常最顺手, 因为它更像“边聊边改”; 如果你更在意审美方向和画面张力, Midjourney 仍然很有吸引力, 但要理解它的 Omni Reference 是引用式一致性, 不是工程化生产线; 如果你希望在界面里做更清晰的图像参考控制, 并且未来有可能继续走平台内训练, Leonardo 会更自然。 对新手来说, 最重要的不是先选品牌, 而是先确定你是要快速探索, 还是要稳定复用。
我什么时候该从 reference 升级到 ControlNet 或同类受控工作流?
当你发现“继续加 prompt 的收益已经变低”时, 就该升级了。 最典型的信号有三个: 第一, 侧面和全身越来越不像同一个人; 第二, 同一角色一到复杂背景或大动作就开始丢关键特征; 第三, 你已经在做系列图, 而每一张都要重新和模型谈判。 如果你已经碰到其中两个, 通常说明 reference-only 不够了, 应该进入受控层。
什么时候值得做 LoRA、Character Model 或平台内训练?
当角色未来还会被反复使用,
而且你已经能整理出相对稳定的训练集时,
就值得。
Scenario 明确把 5-15 张参考图的 LoRA 路线视作高保真长期方案(Scenario,
2026-03-18 核验),
这很适合作为判断线:
如果你连 5 张风格和设定都相对稳定的参考图都拿不出来,
先别急着训练;
如果你已经有这些素材,
而且角色还会继续出现很多次,
训练通常比长期返工更省。
预算有限时,应该优先省在哪一层?
最不该省的是层级判断。 你完全可以先用轻量层确定角色方向, 再决定要不要升级, 这本身就是省钱方法。 真正昂贵的不是某个工具月费, 而是你把一个长期角色项目长期留在轻量层里, 最后每一张都靠人工修。 预算有限时, 更应该早一点承认项目的真实复杂度, 而不是强行在错误路线里死扛。
角色一致性这件事, 最容易让人误以为是“提示词技巧”问题, 但做久了你会发现, 它更像是工作流选择问题。 只要你先分清这是一次性角色探索、 连续场景生产, 还是长期角色资产维护, 后面的工具和参数几乎都会顺着这个判断自然清晰起来。
如果你只记住一句话, 就记住这句: **角色开始漂的时候, 先问是不是该换层级, 而不是先问是不是该多写几句 prompt。 ** 这比任何“万能参数模板”都更能减少返工。