2025 AI对口型怎么选:照片开口、视频换音、数字人与本地开源完整指南
基于 2026-03-18 官方信息重写的 AI 对口型决策指南:不再做失真的“10 款工具总排行”,而是围绕照片开口、已有视频换音、脚本化数字人与本地开源四条路线,帮你先选对方案,再决定要不要上传真人素材。

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
2025 AI对口型怎么选:照片开口、视频换音、数字人与本地开源完整指南
大多数人搜索“AI 对口型”时,真正卡住的不是“这个技术能不能做”,而是“我这次到底该选哪一类工具,以及我能不能把这段真人素材直接上传出去”。如果你只是想让一张照片开口,和你要给成片视频换音并保留原口型,根本不是同一个问题;继续拿“10 款工具总排行”去选,往往只会把时间浪费在错误的路线里。
旧式教程喜欢先讲原理、再列榜单、最后附一份通用操作流程,看起来很完整,实际却把 talking photo、已有视频换音、脚本化数字人和本地开源混在了一起。对口型这件事最怕的不是不会点按钮,而是一开始就把任务类型分错了。照片开口更看重上手速度,视频换音更看重时序稳定,培训数字人更看重脚本和产能,而本地开源更看重控制力与素材不出域。
所以这次重写版不再试图给你一个“全网最全工具榜”,而是先解决三个更现实的问题:你属于哪条路线,这条路线的能力边界在哪里,以及什么情况下根本不该先传素材。看完后,你不一定会记住所有产品名,但应该能在几分钟内做出一个更少返工的决定。
TL;DR
- 这篇文章最重要的不是工具名单,而是后文的 AI 对口型路线选择矩阵 和 上传真人素材前的 stop/go 决策树。
- 如果你只有一张照片,优先看照片开口路线;如果你已经有真人视频并且要换音或多语言,本质上是在做 video-to-video lip sync,而不是 talking photo。
- 如果素材涉及客户、员工、未成年人、品牌账号或公开传播,先做授权与标识判断,再考虑用不用云端工具。
- 当前主流云端工具的能力边界已经很清楚:HeyGen Creator 为
29 美元/月、提供175+ languages and dialects、1080p导出并包含带口型同步的视频翻译(HeyGen,2026-03-18);Magic Hour 免费工具每天3 free lip syncs,但免费版最长只有10 seconds(Magic Hour,2026-03-18)。

先看结论:AI 对口型不是选“最强工具”,而是先选路线
如果你今天只记住一句话,那就是:AI 对口型是一个工作流问题,不是一个冠军榜单问题。你先要分清自己处理的是单张照片、已有真人视频、脚本化数字人,还是必须留在本地环境里的开源流程。只要这一步没分清,后面无论你试多少产品,看到的都只是“某个工具一时能不能跑起来”,而不是“它适不适合你这次任务”。
这也是为什么现在能拿到流量的页面,大多都不再从“什么是 lip sync”讲起,而是直接告诉用户几步完成、是否免费、多语言到什么程度、最长能做多久。比如 Vidnoz 的 lip sync 页面对新手很友好,因为它直接写明支持 Over 100 languages,并把视频上传上限写成 500MB、音频上限写成 50MB(Vidnoz,2026-03-18)。这类信息不一定让它成为最强方案,却能让用户很快判断“我能不能先试一下”。
问题在于,产品页通常只会替自己的那条路线辩护。它们会告诉你“我们的工具能做什么”,但很少告诉你“你其实不该继续上传真人素材”或者“你已经不适合网页工具,应该切到本地开源或 API 流程”。如果你要的是更少踩坑的决定,而不是更快点进某个注册页,就需要一篇把路线和风险一起讲清楚的指南。
AI 对口型路线选择矩阵:照片、已有视频、数字人、本地开源怎么分
更省时间的做法,不是把所有工具都试一遍,而是先看你的任务属于哪个象限。判断时只需要问四个问题:你处理的是照片还是视频?结果是一次性还是高频复用?素材是否敏感?是否会公开传播?这四个问题已经足够把大多数人分到不同路线里。
如果你的目标是头像、讲解照片、社媒配音卡片或会说话海报,照片开口路线最自然。它的价值不是绝对真实性,而是最快把静态素材变成可播出的短内容。反过来,只要你已经有真人视频,还希望换一段新的旁白、做视频翻译或保留原镜头的嘴型动作,本质上就是 video-to-video lip sync,判断标准立刻会从“会不会动”变成“时序稳不稳、最长能跑多久、上传限制是什么”。
当你开始在意隐私、批量、合规或商用边界时,脚本化数字人与本地开源才是正确比较对象。Synthesia 这类路线不是为了让你随手做一条社媒梗图,而是为了让培训、演示、企业沟通这类脚本视频更稳定地产出;它的 Starter 方案是 29 美元/月,Creator 方案是 89 美元/月,Starter 每月包含 10 video minutes(Synthesia,2026-03-18)。本地开源则是另一套逻辑,它解决的是“我能不能在自己环境里掌控素材、推理和批处理”,而不是“我能不能三分钟上手”。
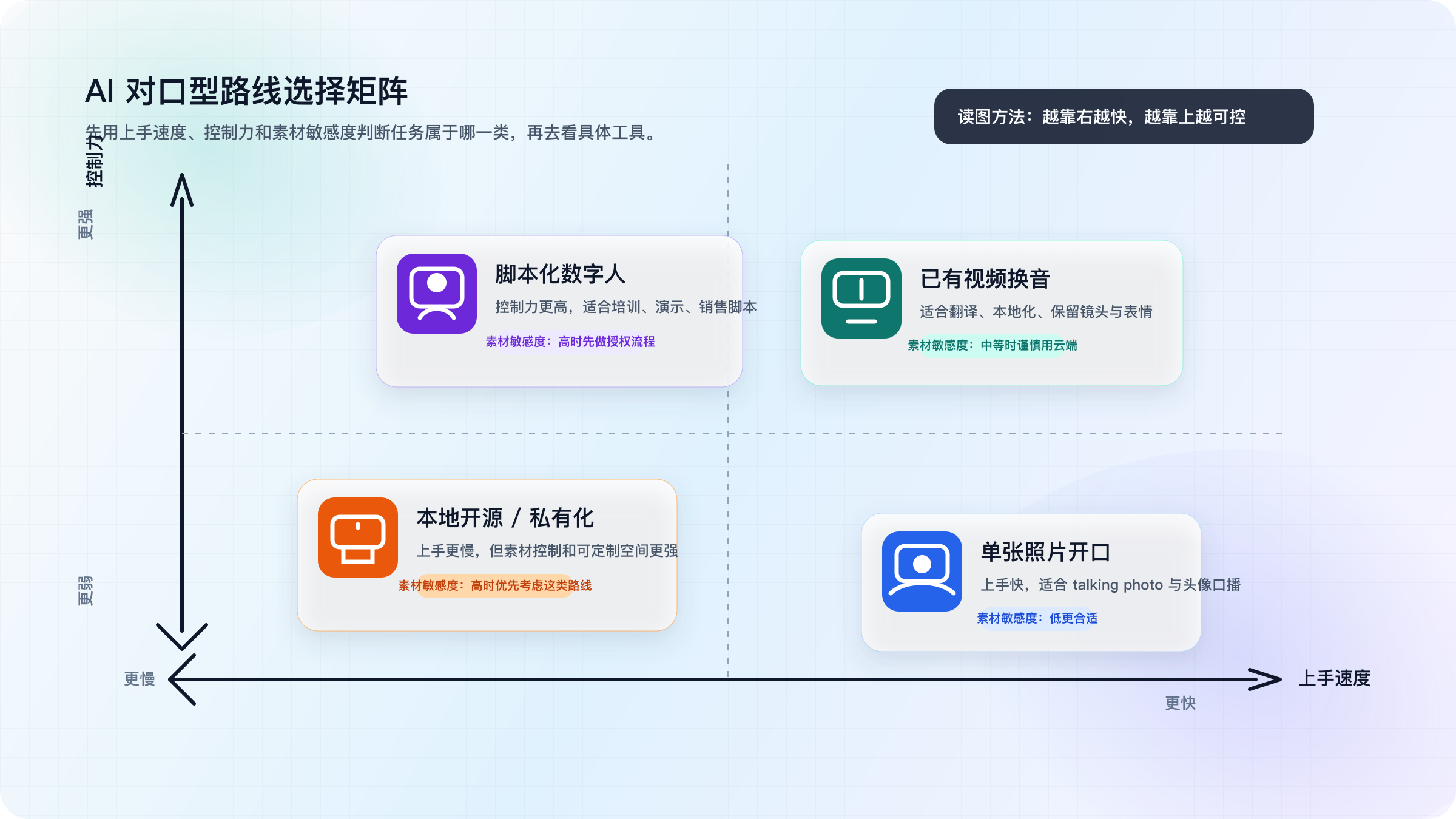
下面这张表,不是在回答“谁最强”,而是在回答“你现在应该从哪条路开始”。
| 路线 | 适合谁 | 代表方案 | 优先看什么 | 什么时候别选 |
|---|---|---|---|---|
| 单张照片开口 | 想快速做 talking photo、口播头像、轻量社媒内容的人 | HeyGen 照片/头像路线、Magic Hour 轻量视频路线 | 上手速度、脚本输入方式、短时长效果 | 你已经有真人成片视频,或素材高度敏感时 |
| 已有视频换音 | 需要保留原镜头、改配音、做翻译或多语言版本的人 | Vidnoz、HeyGen Video Translation、VEED API | 时长限制、上传上限、处理速度、导出质量 | 你只是想让一张图片开口,或没有可用视频素材时 |
| 脚本化数字人 | 培训、营销、企业演示、标准化讲解视频团队 | Synthesia、HeyGen Avatar | 视频分钟数、分辨率、团队协作、个人头像授权流程 | 你只做一次性短视频,且不想为脚本平台付费时 |
| 本地开源/私有化 | 在意控制力、素材不出域、愿意承担技术门槛的人 | MuseTalk、Wav2Lip、一类自建流程 | 商用边界、显卡要求、推理速度、批处理能力 | 你只是偶尔做一段短内容,且不想折腾环境时 |
这张矩阵真正的作用,是帮你把“能做”和“该不该做”拆开。很多返工并不是因为模型不够强,而是你明明在做视频翻译,却先去试 talking photo;或者你明明已经在处理客户素材,却还在用“免费在线先试一下”的思维做决定。
5 条当前最值得看的路线,分别适合谁
第一条路线是照片开口,也就是你只有一张照片或一张头像,希望尽快让它说话。这个场景的核心不是长时长稳定性,而是启动速度和容错率。HeyGen 的 lip sync 工具页把流程压缩成 4 步,而且同时支持上传音频和直接输入脚本(HeyGen,2026-03-18)。这类路线适合讲解头像、轻量口播、测试创意,但不适合你把它误当成“任何视频都能无损改口型”的通用方案。
第二条路线是已有视频换音。只要你已经有真人拍好的镜头,希望换配音、做视频翻译或多语言版本,优先关注时长、上传限制和处理速度。Vidnoz 适合预算敏感的新手,因为它把 Over 100 languages、500MB 视频上限和 50MB 音频上限写得很直接(Vidnoz,2026-03-18)。如果你是开发者或团队化流程,VEED 的 lip sync API 反而更值得看,因为它明确给出 0.40 美元/分钟 的计费与约 2-2.5 分钟生成 1 分钟视频 的处理速度(VEED,2026-03-18)。
第三条路线是脚本化数字人。它和 video-to-video lip sync 看起来都在“让人开口说话”,但目的完全不同。脚本化数字人更像一种产能工具,你给它脚本、模板和角色,持续输出培训、演示、销售或入门视频。Synthesia 的价值就在这里,它不仅有标准化视频分钟数和团队化流程,而且在个人头像创建上要求 live consent recording,视频版头像通常需要 24 hours 准备完成(Synthesia Docs,2026-03-18)。这说明它并不是“你上传任何人脸都能马上变数字人”的轻量玩具,而是把授权与治理前置进了流程。
第四条路线是轻量创作者型云端工具,Magic Hour 是当前比较典型的例子。它对创作者友好的地方在于信息写得够直接:免费工具每天 3 free lip syncs,支持 MP4/MOV up to 4K,但免费版最长只到 10 seconds;如果进入完整工具,最长可做到 83 minutes (at 24 FPS),同时页面还标出 Retention: 1 day(Magic Hour,2026-03-18)。这类路线适合快速验证效果,但也在提醒你:当素材敏感、时长变长或需要长期留存时,网页工具未必还是默认答案。
第五条路线是本地开源。很多人只把它理解成“更难装”,这其实太浅了。本地开源真正的价值是控制力,但代价是你要接受商用边界、硬件门槛和更强的工程属性。Wav2Lip 仓库直接写明结果仅应用于 research/academic/personal purposes,并强调 any form of commercial use is strictly prohibited(Wav2Lip GitHub,2026-03-18)。MuseTalk 则更像“本地可控但仍需成本”的现实路线,它宣称在 V100 上可达 30fps+,但仓库也坦白 RTX 3050 Ti 4GB VRAM 环境下生成 8 秒视频大约要 5 分钟(MuseTalk GitHub,2026-03-18)。如果你是开发者、对素材外传敏感,或者后续还想衔接自建流程,这条路线比“再试一个网页工具”更值得认真看。
在线工具和本地开源的分界线:什么时候该切换
在线工具并不天然“不专业”。如果你只是偶发地做几条短内容、验证一个创意,或者想在团队里快速出样,在线路线几乎总是更省时间。真正的问题是,你有没有开始反复遇到同一种痛点,而且这种痛点已经不是“再换个网页试试”能解决的。
第一个切换信号是素材敏感度。只要你处理的是客户肖像、员工素材、未成年人、企业内部画面,或者这些内容将进入公开传播,你面对的就不再只是“效果好不好”,而是“我能不能控制上传、留存、删除与后续使用”。此时本地开源哪怕更麻烦,也会开始变成合理成本,而不是技术洁癖。
第二个切换信号是频率。一次性的创意视频适合在线工具,但当你开始进入固定更新、多人协作、批量复用或自动化生成,网页工具的优势会迅速下降。VEED 这类 API 路线之所以值得看,并不是因为“更高级”,而是因为它能把计费、速度和输入结构提前说清楚,让你知道这条流程能否进入生产(VEED,2026-03-18)。如果你接下来还要继续搭配翻译或配音链路,可以顺手看 AI 翻译 API 指南。
第三个切换信号是责任。如果你已经开始在意权限、日志、标识、审核失败怎么处理、结果需要保留多久,那么你面对的已经不是“做不做 lip sync”,而是“内容生产系统要怎么管”。从这个角度看,Synthesia 的 live consent 机制和头像准备流程其实不是麻烦,而是一种提醒:当内容会被团队长期使用时,治理本身就是产品能力的一部分(Synthesia Docs,2026-03-18)。
为什么同一张素材会翻车:决定效果的 5 个变量
很多人把效果好坏全归因于“工具强不强”,这只说对了一半。真正决定结果的,往往是素材条件和任务类型。你用同一个工具做头像可能很自然,换成长视频、多镜头、强表情、逆光场景时却突然崩掉,这不是模型突然失灵,而是你把它拖进了另一种难度层级。
第一个变量是角度与遮挡。正脸、光线均匀、无遮挡的人像,几乎总比低头、侧脸、手挡嘴或麦克风遮挡更容易做好。第二个变量是时长与镜头复杂度。照片开口和 10 秒视频本来就不是一个难度级别,Magic Hour 把免费版限制在 10 seconds,本身就说明“能做”和“长时间稳定做”是两回事(Magic Hour,2026-03-18)。
第三个变量是压缩与分辨率。你以为手里的视频是“高清素材”,但如果它已经经过社交平台二次压缩,脸部细节和嘴部边缘可能早就丢了。第四个变量是音频质量。音轨里如果噪声大、节奏乱、情绪跨度极高,对口型模型需要解决的并不只是“嘴巴张合”,还包括节奏与表情协同。
第五个变量是结果用途。发到朋友圈和发到品牌账号,对“看起来够不够真”的标准完全不同。前者只要自然到不出戏,后者则要考虑停顿、放大、反复观看、评论区质疑和后续留档。你如果知道自己做的是后者,就别再用“我试了一个免费工具看着还行”来给自己做判断。
如果你遇到的核心问题其实不是口型,而是脸部替换、角色一致性或更强的人像合成控制,那这类任务更接近 AI 换脸完整指南 的决策逻辑,而不是继续在 lip sync 产品页里兜圈子。
中国用户要特别注意什么:授权、标识与公开传播
对中国用户来说,AI 对口型最容易被忽略的不是技术,而是“发布之后要承担什么”。如果内容只是在本地测试,你可以先把重点放在效果和路线;但只要它会进入公众号、视频号、品牌账号、客户交付或公开平台,问题就不再只是哪个工具更顺手,而是你是否能解释清楚素材来源、授权关系和标识义务。
中国网信办在 2025 年发布的《人工智能生成合成内容标识办法》已把生成合成内容的标识拆成显式标识与隐式标识,覆盖文本、图片、音频和视频;同时,相关解读明确提到视频内容应在起始画面和播放周边的适当位置进行显式标识,并通过元数据加入隐式标识字段(中央网信办,2026-03-18)。这意味着“我在简介里提一句是 AI 做的”已经不是最稳妥的完成方式,至少在公开传播场景里,你需要把标识当成流程的一部分。
国际传播也是同样方向。欧盟 AI Act 第 50 条要求 deepfake 或 AI 生成/操控的图像、音频、视频内容被披露为人工生成或操控,并强调可检测、机器可读的标记要求(EU AI Act,2026-03-18)。你未必直接服务欧洲用户,但这足以说明一个趋势:透明度不再是加分项,而越来越像默认义务。
对普通中文团队更实用的做法是,把发布前检查压缩成三件事:有没有明确授权,是否需要显式标识,素材和成片是否有留存与删除策略。只要这三件事里有一项答不上来,就不要急着比较“HeyGen 和 Vidnoz 哪个更方便”,因为你此刻真正缺的不是工具,而是决策前置。
什么时候别上传真人素材:一张决策树看清风险
很多人把“哪款工具最好”当成第一问,其实第一问应该是“这张脸我到底能不能上传”。只要素材不是你自己的,或者你无法确认授权、传播范围、后续使用边界,那么默认就不该先进入任意云端产品。授权不清楚时继续上传,本质上不是效率高,而是把风险外包给未来的自己。
第二个需要立刻停一步的场景,是你准备公开传播或做品牌使用,但又没有同步准备标识方案。对口型内容一旦进入视频号、投放渠道、客户方案或教育场景,就不再只是创意实验,而是具有明确传播后果的视听内容。此时你需要先确认授权、标识、删除策略,再决定走网页工具、企业平台还是本地流程。
第三个高风险节点是未成年人、客户肖像、员工形象、校园或企业内部素材。这些场景的风险不只是“别人会不会不高兴”,而是信息治理、隐私、误导传播和责任追溯全部被拉高。只要你对任何一个条件需要犹豫 3 秒,这件事就不适合用“先传上去试试看”来推进。
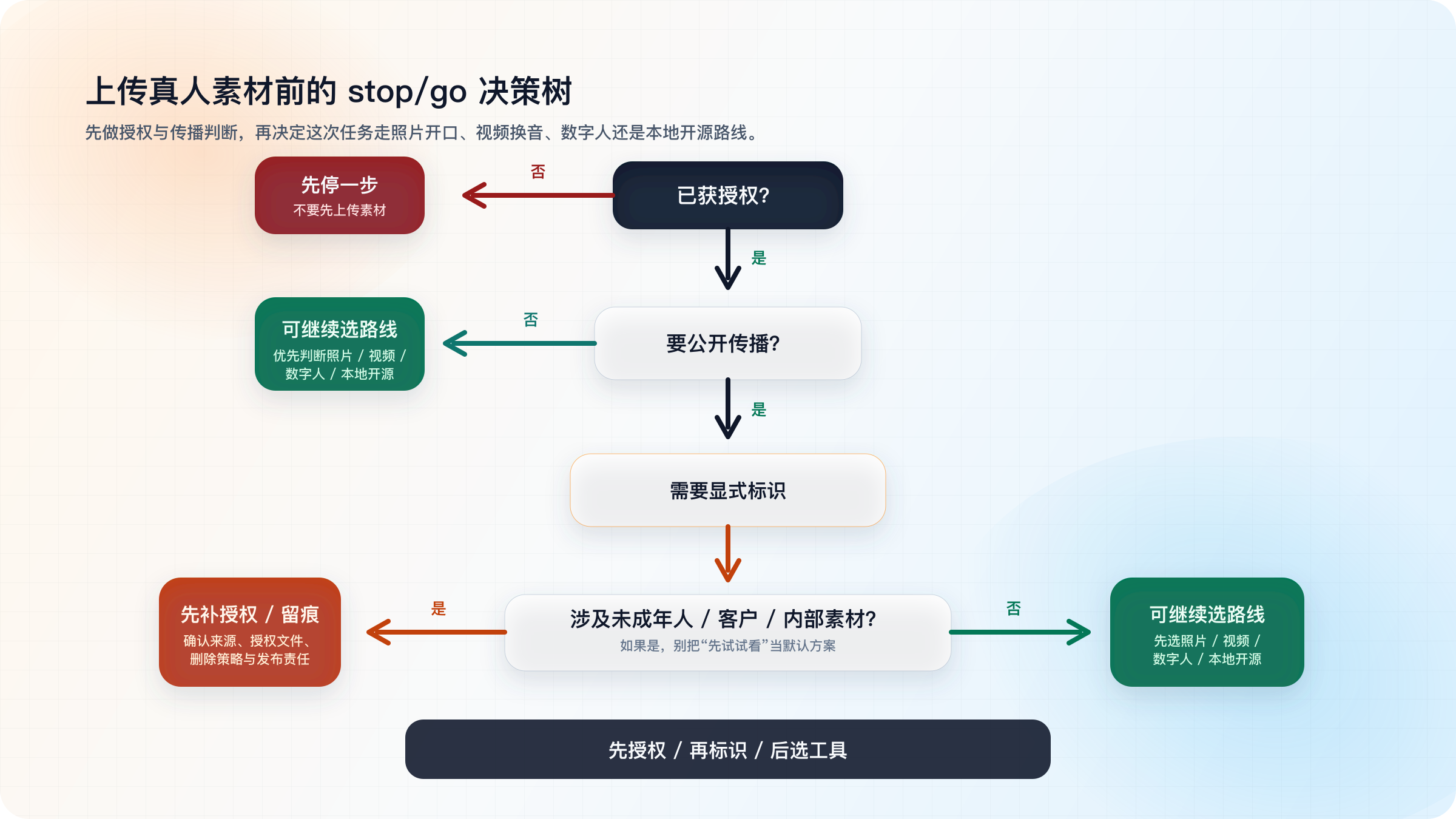
更稳妥的执行顺序应该是:先问是否已获授权,再问是否会公开传播,再问是否涉及未成年人、客户或内部素材,最后才问“我该选照片开口、视频换音、数字人还是本地开源”。只要前三问里有一个答案不清楚,就先停下来补材料、补说明、补标识方案,而不是继续点上传按钮。
这也是为什么本文一直把 stop/go 决策树和路线矩阵并列放在核心位置。路线矩阵告诉你“接下来用什么”,决策树告诉你“现在能不能继续做”。没有前者,你会选错工具;没有后者,你可能一开始就不该上传。
常见问题(FAQ)
初学者到底应该先从哪一类开始?
如果你的目标只是头像、讲解卡片或轻量社媒内容,先从照片开口路线开始最合理。HeyGen 这类工具把脚本输入和头像生成合在一起,新手很容易理解工作流;Magic Hour 和 Vidnoz 则更适合你先看短视频换音是否够用。关键不是先记住品牌名,而是先确认自己只有照片,还是已经有成片视频。
做视频时,为什么不能直接套用照片工具的经验?
因为视频问题的核心是时序一致性,而不是单帧是否自然。Vidnoz 会直接把语言数、上传上限和 video-to-video lip sync 写在页面上,就是因为视频用户首先关心的是“整段素材能不能稳定跑完”(Vidnoz,2026-03-18)。你如果拿照片开口的体验去赌长视频效果,大概率会在镜头切换、表情跨度和音轨节奏上翻车。
Wav2Lip 和 MuseTalk 这类开源方案,普通用户应该怎么理解?
最简单的理解是:它们更像控制力路线,而不是零门槛路线。Wav2Lip 的关键提醒不是“效果多强”,而是仓库明确写了 commercial use is strictly prohibited(Wav2Lip GitHub,2026-03-18);MuseTalk 的关键提醒则是硬件与推理时间依然真实存在,即便它已经比传统方案更接近实用(MuseTalk GitHub,2026-03-18)。如果你只是偶尔做一条短内容,开源不一定更划算;但如果你在意素材不出域或未来要接自己的流程,开源才值得认真投入。
什么时候我应该认真看企业/API 路线?
当你开始关心批量、日志、权限、自动化和成本边界时,就应该认真看 API 或企业平台。VEED 的 lip sync API 已经把 0.40 美元/分钟 和大致处理速度写得很清楚,这类信息对个人创意用户没那么重要,但对团队预算和产线设计非常重要(VEED,2026-03-18)。如果你已经进入这一步,继续比较“哪个网页更好上手”通常没有太大意义。
公开发布 AI 对口型内容时,最容易漏掉什么?
最容易漏掉的不是“有没有水印”,而是完整的责任链。中国网信办已经把显式标识和隐式标识分开要求,欧盟也在透明度规则里强调 AI 生成或操控内容的披露(中央网信办,2026-03-18;EU AI Act,2026-03-18)。对普通团队来说,更实用的翻译是:你至少要能回答“有没有授权”“有没有标识”“出了问题能不能回溯素材和处理流程”。答不上来,就不要急着发。
别再把“AI 对口型”理解成一个可以靠排行榜解决的单点问题。真正决定你会不会少走弯路的,是路线是否匹配任务,以及你是否在上传前就把授权、标识和传播边界想清楚了。
如果你只是让一张照片开口,追求的是速度;如果你要给真人视频换音,追求的是时序稳定;如果你做的是培训或企业内容,追求的是脚本化产能;如果你手里是敏感素材,追求的首先不是好不好玩,而是能不能不把控制权轻易交出去。把这四件事先分开,AI 对口型才会从“看起来什么都能做”变成“我知道下一步该做什么”。