AI 大模型怎么选:2026 年订阅、API 与路由方案实战指南
想在 GPT-5.4、Claude Sonnet 4.6、Claude Opus 4.6、Gemini 2.5 Pro 与 Gemini 3.1 Pro Preview 之间做选择?这篇指南按订阅、API、稳定版/预览版与预算拆解,帮你直接做出决定。

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
AI 大模型怎么选:2026 年订阅、API 与路由方案实战指南
如果你这周刚好要做一个决定: 是继续给 ChatGPT 续费、改投 Claude,还是把产品 API 接到 GPT-5.4、Claude Sonnet 4.6、Gemini 2.5 Pro,甚至试试 Gemini 3.1 Pro Preview,那么你真正要避免的风险已经不是“没买到最强模型”,而是把预览版当成生产主力、把排行榜当成采购答案、把单模型当成万能方案。
这也是这篇更新版指南和旧式“30+ 模型排行榜”的区别。本文按 2026 年 3 月 18 日重新核对官方资料后重写,不再试图给所有模型排一个总榜,而是先回答三个更实际的问题: 你是在买订阅还是接 API,你需不需要稳定版而不是 preview,你的工作流到底更像代码、研究、内容还是长文档分析。
TL;DR(快速结论)
- 只买一个订阅时,不要先问“谁最强”,要先问“你每天主要在写、查、还是做代码任务”。偏写作和长文协作的人通常更容易留在 Claude,偏通用职业工作流的人更容易留在 ChatGPT,已经深度在 Google 生态里的用户再考虑 Gemini。
- 只接一个稳定 API 时,大多数团队先从
Claude Sonnet 4.6或Gemini 2.5 Pro起步更稳;需要更强综合专业能力时,再评估GPT-5.4或Claude Opus 4.6。Gemini 3 Pro Preview已在 2026 年 3 月 9 日关闭并切到Gemini 3.1 Pro Preview(Google Gemini API Release Notes,2026-03-18)。这意味着 Google 最新能力值得评估,但不应该默认当成生产主干。- 当你同时追求质量、延迟和成本时,问题通常不再是“选一个冠军模型”,而是“什么时候该上双模型路由”。

为什么 2026 年的“AI 大模型对比”已经不能只看排行榜
过去那种“哪个模型第一、哪个模型第二”的写法,在 2026 年的问题越来越明显。模型版本更新太快,很多页面把稳定版、预览版、临时别名和聚合平台上的可调用模型混在一起,结果读者看到了很漂亮的榜单,却没法据此做上线决策。
Google 是最典型的例子。很多文章还在把 Gemini 3 Pro、Gemini 3.1 Pro 写成一个稳定延续的系列,但官方发布记录写得很清楚: Gemini 3 Pro Preview 已于 2026 年 3 月 9 日关闭,别名切到了 Gemini 3.1 Pro Preview(Google Gemini API Release Notes,2026-03-18)。如果你忽略这件事,就会把“最新预览能力”误读成“最稳生产方案”。
同样的道理也适用于 Anthropic 和 OpenAI。Anthropic 的官方模型选择页把 Claude Opus 4.6 定位为最强模型,把 Claude Sonnet 4.6 定位为面向 coding、agents 和 enterprise workflows 的前沿工作马(Anthropic Choosing a model,2026-03-18);OpenAI 则把 GPT-5.4 定位为“professional work”的旗舰模型,并给出明确的上下文和价格边界(OpenAI API Pricing;OpenAI Models docs,2026-03-18)。今天真正有价值的比较,不是再做一个总分榜,而是把这些定位差异翻译成行动建议。
先选使用方式:订阅用户和 API 团队不是同一道题
很多人会把“我要买一个最好用的 AI”当成一个问题,但订阅用户和 API 团队关心的根本不是同一组变量。前者在意的是主观使用感受、写作流畅度、生态粘性和月费是否值得;后者在意的是价格曲线、上下文边界、稳定性、工具调用和生产风险。
如果你是订阅用户,第一步应该先看“哪一种工作最占你每天时间”。经常写长文、改措辞、做深度文稿协作的人,通常更在意输出自然度和长对话中的稳定性;经常做通用办公、整理资料、跨任务切换的人,更在意全能感和生态工具;如果你本身就在 Google Workspace 里工作,再考虑 Gemini 才最自然。订阅阶段先找主工作流,而不是去背一堆 benchmark。
如果你是 API 团队,顺序刚好反过来。你先看的是稳定版还是 preview、上下文是否足够、价格是否可控、以及模型在你的真实工作流里是不是需要被拆成两层。因为一旦进入生产,错误的不是“买贵了”,而是把一个不该承担主链路的模型放到了主链路上。
| 使用方式 | 你最该先看什么 | 第一轮推荐思路 |
|---|---|---|
| 订阅用户 | 主工作流是写作、通用办公还是研究 | 先从一个你每天都愿意打开的产品开始,不必一开始就追最强 API |
| API 团队 | 稳定版 / 预览版、价格、上下文、延迟 | 先选稳定主模型,再决定是否需要 preview 试验或双模型路由 |
这也是为什么很多团队会在一开始做错题。明明眼下只是想提升个人工作效率,却先去比一圈 API 价格;或者明明已经准备把模型接进生产,却还在用“我自己用起来最顺手”的主观体验代替系统级判断。把订阅和 API 分开,本质上是在把“个人偏好”与“生产责任”分开。
按工作流与发布要求选模型:一张表先看懂
真正能改变选择结果的,不是“某个模型在某个榜单多高 2 分”,而是你的工作流到底属于哪一类。代码代理、研究综合、内容生产和长文档处理,看起来都叫“用 AI”,但在生产里对模型的要求完全不同。
截至 2026 年 3 月 18 日,我更建议把选择拆成两个层次来做。第一层是“稳定优先”,也就是今天就能承担主链路的选择;第二层是“可试预览版”,也就是你愿意在评估环境里验证新能力,但暂时不让它背生产 SLA 的选择。
很多团队最容易犯的错,是把“我看过一个最新模型评测”直接翻译成“那我就把它接上生产”。对 2026 年的大模型采购来说,这一步通常太快了。先把工作流归类,再决定是单模型还是路由,几乎总比先选一个冠军再硬套场景更稳。

| 工作流 | 稳定优先首选 | 可试预览版 | 什么时候该加路由 |
|---|---|---|---|
| 代码与代理 | Claude Sonnet 4.6 | Claude Opus 4.6、Gemini 3.1 Pro Preview | 低风险工单很多,但少数任务要求极高质量时 |
| 研究与综合分析 | GPT-5.4 或 Gemini 2.5 Pro | Gemini 3.1 Pro Preview | 资料检索、预处理和最终综合的成本差异明显时 |
| 内容与文稿生产 | Claude Sonnet 4.6 | 一般不必为了写作优先上 preview | 批量草稿与最终定稿质量要求不同步时 |
| 长文档 / 大仓库处理 | Gemini 2.5 Pro | Gemini 3.1 Pro Preview | 预筛选和最终回答可以拆成两档成本时 |
这张表的核心不是“给每个场景封一个冠军”,而是先把错误答案排除掉。比如你要上线一个稳定的文档问答工作流,看到 Gemini 3.1 Pro Preview 更新很快,并不意味着它应该直接替代 Gemini 2.5 Pro 成为你的默认生产选项;相反,它更适合进入评估环境,验证你是否真的能从新能力里得到足够收益。
对大多数中型团队来说,第一轮最稳的路径通常是这样的: 代码和代理型工作先拿 Claude Sonnet 4.6 做主工作马;超长上下文和大体量文档处理优先看 Gemini 2.5 Pro;你需要一个综合能力强、愿意为专业任务支付更高单价的 API,再去评估 GPT-5.4。只有当你已经清楚自己为什么需要更强的上限,Claude Opus 4.6 和 Gemini 3.1 Pro Preview 才会真正进入候选。
如果把这个矩阵翻译成更日常的话,其实就是四句判断。代码团队先问“我是不是每天都要稳定跑很多任务”;研究团队先问“我的工作到底更像检索综合还是长材料深读”;内容团队先问“我最怕的是不稳定还是不够新”;长文档团队先问“我到底是不是经常真的会吃到超长上下文”。很多所谓的“选型纠结”,都是这四句还没答清。
主流模型的真实差异:价格、上下文、稳定性到底怎么影响选择
先看 OpenAI。GPT-5.4 的 API 定价是 $2.50 / 1M input、$15 / 1M output,context window 是 400,000,max output 是 128,000(OpenAI API Pricing;OpenAI Models docs,2026-03-18)。这组数据的含义不是“它便宜”或“它昂贵”,而是它更像一个单价明确、定位高端专业工作的旗舰模型: 当你需要高质量综合输出、又不想把工作流拆得太碎时,GPT-5.4 的吸引力会很强。
再看 Anthropic。Claude Sonnet 4.6 的定价是 $3 / 1M input、$15 / 1M output(Anthropic migration guide to Sonnet 4.6,2026-03-18),而 Claude 4.6 family 的 context window 是 1M(Anthropic models overview,2026-03-18)。这也是为什么很多团队会把 Sonnet 4.6 当成工作马,而不是直接上 Opus: Sonnet 的价格仍处在可规模化区间,官方定位又明确偏向 coding、agents 和 enterprise workflows。你要的是“每天都要跑、而且不能太贵”的模型时,这个组合很有说服力。
Google 的判断标准则更容易因为命名而混乱。模型页仍把 Gemini 2.5 Pro 写成 “our most advanced model for complex tasks”,其 context 是 1,048,576 input / 65,536 output(Google Gemini models docs;Google Gemini 2.5 Pro model page,2026-03-18)。价格方面,Gemini 2.5 Pro 在 <=200k 输入区间是 $1.25 / 1M input、$10 / 1M output,超过 200k 后升到 $2.50 / 1M input 与 $15 / 1M output(Google Gemini Pricing,2026-03-18)。这意味着它对“稳定长上下文生产”非常有吸引力,但你不能把这个优势直接套到 preview 线上。
只盯着输入单价也很容易误判。真正影响总成本的,往往是你有没有让高价模型去处理本来可以分流的简单任务,有没有让超长上下文场景真的配上对应模型,以及你是否为 preview 带来的额外评测、回滚和故障隔离成本留了预算。模型单价只是账单的一部分,不是全部。
于是一个更真实的结论就出现了。GPT-5.4 不是“最强就必选”,而是当你愿意为专业工作付费、又不想在第一天就做复杂路由时,选它比较顺;Claude Sonnet 4.6 不是“中配版凑合用”,而是很多代码和 agent 工作流真正的主力;Gemini 2.5 Pro 也不只是“Google 备胎”,而是在稳定长上下文与价格曲线之间很有竞争力的生产选择。至于 Gemini 3.1 Pro Preview,它最值得你的不是“立刻替换一切”,而是进入评估通道,看看它是否真的能带来值得切换的收益。
| 模型 | 更适合什么 | 你该警惕什么 |
|---|---|---|
| GPT-5.4 | 高质量综合专业任务、单模型起步 | 400k context 足够很多场景,但不是 1M 档长上下文 |
| Claude Sonnet 4.6 | 代码、代理、企业级高频工作流 | 很多人低估了它作为主力而非过渡方案的价值 |
| Claude Opus 4.6 | 极致质量、复杂任务上限 | 成本与必要性要先被证明,再决定是否升级 |
| Gemini 2.5 Pro | 稳定长上下文、文档与大体量输入 | 不要把 stable 的优势和 preview 混成一个产品判断 |
| Gemini 3.1 Pro Preview | 最新能力评估、前沿试验 | preview 不等于生产默认项 |
采购与接入建议:官方 API、聚合路由、自托管分别适合谁
如果你已经知道自己要走 API,这里最实用的不是“哪个模型最酷”,而是“哪一种采购形态最省事”。对大多数团队来说,官方 API 仍然应该是第一选择。因为你要的不是最低理论价格,而是清晰的价格页、明确的版本状态、可解释的退场路径和更少的变量。
当你已经确定会长期同时使用两家以上模型时,聚合路由或兼容 OpenAI 格式的统一接入层才开始有价值。它的好处不是“自动更强”,而是账单统一、切换更快、低风险任务更容易分流给便宜模型。问题在于,一旦你在还没选定主模型前就先上聚合层,很容易把主决策问题推迟,最后变成“什么都能接,但谁都没接好”。
自托管则是另一条路线。它适合对数据控制权、私有部署、合规边界有硬要求的团队,而不适合“我只是想先试试最强模型”的人。开源模型能不能替代闭源,不是看排行榜,而是看你的工作流能不能接受更重的工程负担、评测成本和持续维护。
实际采购时,还要补一个经常被忽略的维度: 责任边界。官方 API 的优势,是版本、账单、文档和异常处理路径更清楚;聚合路由的优势,是多厂商切换快、便于一套接入覆盖多个模型;自托管的优势,则是控制权最强。你选择的不是“买谁更酷”,而是“哪种责任边界更适合你的团队成熟度”。
如果你还在更细的子问题里纠结,可以继续看站内几篇相关文章: ChatGPT 与 Claude 对比指南、Claude 4 Sonnet vs Opus 深度对比、Gemini 2.5 Pro 免费额度与限制。先把“主模型怎么选”想明白,再去看单厂商细节,效率会高很多。
什么时候该上双模型路由,而不是继续赌一个“全能模型”
真正需要路由的团队,往往已经出现三个信号。第一,低风险高频任务很多,继续让旗舰模型处理这些任务会明显浪费预算。第二,少数高价值复杂任务对质量非常敏感,便宜模型一旦出错,返工成本会迅速吃掉你省下来的 token 费用。第三,你已经开始区分“生产稳定”与“新能力试验”,但又不想每次都做一次全量切换。
如果你的团队还没有出现这三个信号,单模型通常就够用。很多公司之所以太早做路由,不是因为它真的需要,而是因为它在用“更复杂的架构”掩盖“其实还没弄清主工作流”的问题。把一个稳定工作马跑透,通常比一开始就做三层路由更务实。
但一旦这三个信号同时出现,路由反而会比继续赌“一个全能模型”更简单。原因很直接: 你不再需要让每一次请求都买同一档的质量,而是把低风险请求交给更省钱的路径,把高风险请求交给更强的稳定模型,把 preview 留在旁路做试验。
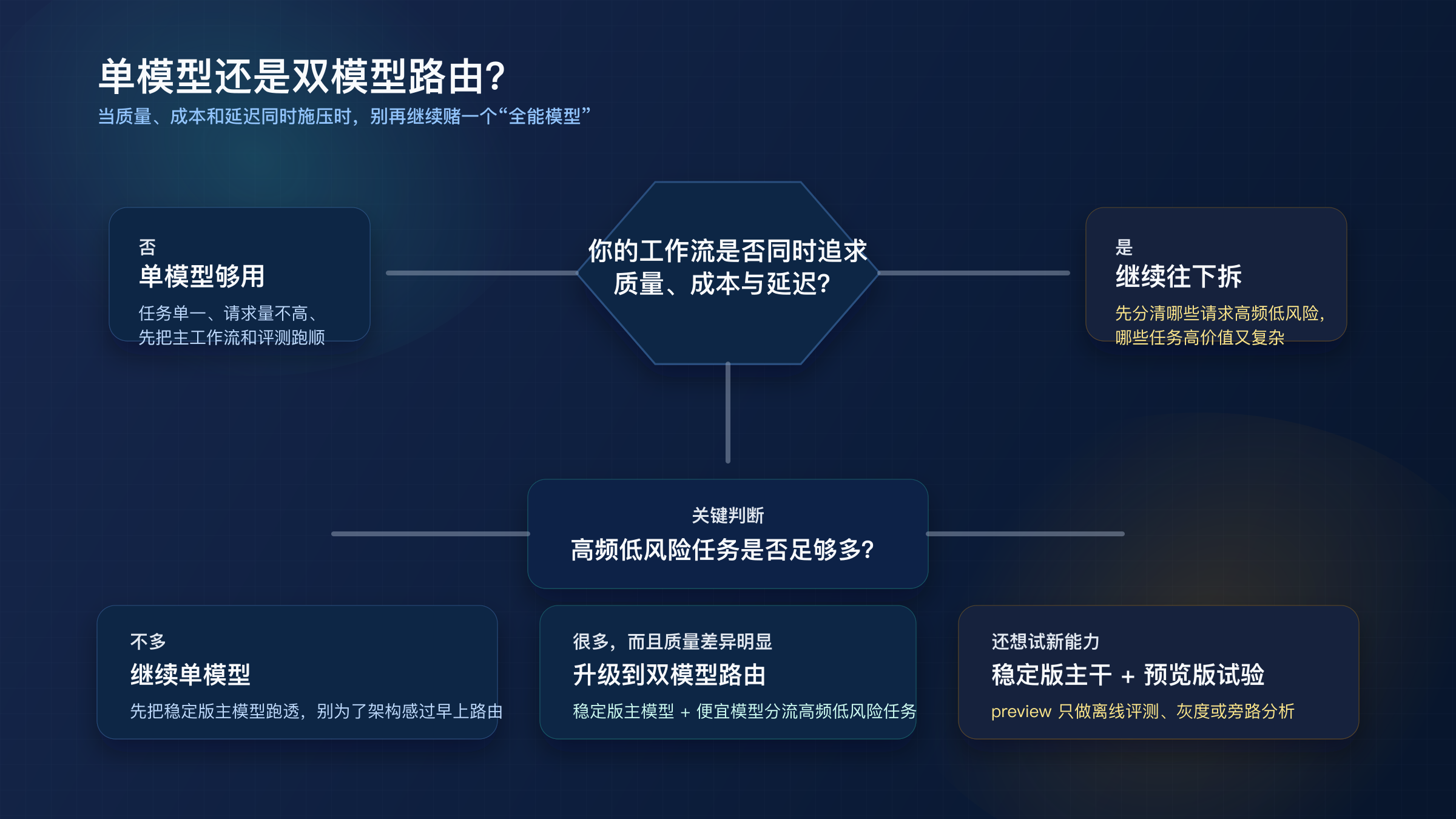
我更建议用下面这套顺序判断,而不是直接问“要不要上路由”。
如果你每月 API 消耗不高、任务类型也单一,先继续单模型。这通常适用于个人产品、早期 SaaS、内容团队内部工具。你先把 prompt、评测和失败处理跑顺,比过早路由更重要。
如果你已经有大量“高频但低风险”的请求,再加少量“高价值复杂任务”,就升级到“双模型路由”。最典型的做法是: 稳定版工作马负责大多数请求,更强的稳定模型只处理复杂代码、最终报告、关键客户回复这类高价值任务。
如果你已经确认 preview 有价值,也不要让它直接承担生产主链路。更稳的做法是 稳定版生产 + 预览版试验。先用 preview 做离线评测、灰度或旁路分析,等它在你的任务集里持续证明收益,再决定是否升级。
把预算放进同一张图里看,这个判断会更清楚。订阅用户往往是在一个固定月费里追求“打开率”和主观体验;API 团队则是在波动请求量里追求“总成本”和稳定性。也正因为如此,最优解很少是“所有请求都走最强模型”,而更常是“让主模型稳定,让高价模型稀缺,让 preview 留在试验通道”。
如果你需要一个更直观的预算读法,可以这样理解。月预算很小、任务也单一时,单模型最省心;预算开始上升,但大量请求其实并不复杂时,双模型路由往往比直接全量升级旗舰更划算;当预算已经足够、你又确定 preview 真的能提高关键指标时,才值得把“稳定版主干 + preview 试验”变成长期结构。预算不是一个孤立数字,它决定的是你有没有空间把风险和质量拆开管理。
常见问题:preview 能不能直接上生产?要不要为 1M 上下文多付钱?
Q1: preview 模型能不能直接拿来做生产主链路?
原则上可以调用,不代表适合默认承担主链路。最现实的标准不是“它能不能跑”,而是“它的版本状态、退场路径、回滚成本是不是你能接受”。Gemini 3 Pro Preview 在 2026 年 3 月 9 日关闭并切到 Gemini 3.1 Pro Preview(Google Gemini API Release Notes,2026-03-18)这件事,本身就说明 preview 的价值主要在于评估新能力,而不是取代你的稳定主模型。
Q2: 我真的需要为 1M 上下文付费吗?
很多人高估了这个需求。只有在你要处理超长文档、完整代码仓库、超长研究材料或需要把大量历史上下文一次性放进模型时,1M 才会明显改变答案。否则,GPT-5.4 的 400,000 context 对很多专业任务已经足够(OpenAI Models docs,2026-03-18)。是否值得多花钱,关键不在“理论上限”,而在“你的真实输入是否真的常常接近这个量级”。
Q3: 订阅和 API 应该先选哪一个?
如果你还是个人用户、自由职业者或刚开始试工作流,先选订阅通常更合理,因为你要先验证“我愿不愿意每天打开它”。只有当你已经知道自己的重复任务是什么、准备把它嵌进产品或团队流程里,API 才会成为更关键的选择题。很多人一上来就比较 API,其实连自己每天主要在做什么都还没分清。
Q4: 开源模型什么时候值得替代闭源模型?
当你对数据控制权、私有部署、合规、定制能力的需求,已经高到足以覆盖掉额外工程成本时,它就值得了。反过来说,如果你现在最痛的是“到底哪个闭源模型更省心”,那说明你的问题还不在开源替代,而在主工作流选择。先把闭源方案中的稳定版、preview 和路由关系搞清楚,通常会比直接跳到自托管更高效。
Q5: 我应该先优化 prompt,还是先换模型?
如果你连任务分类、评测样本和失败模式都还没整理清楚,先换模型通常不会从根本上解决问题。更高的模型上限,只有在你已经知道当前失败主要来自“能力不够”而不是“提示不清、流程没拆、工具没配好”时,才会明显值回成本。实务上更稳的顺序是: 先把主工作流拆清楚,再做 prompt 和流程优化,最后才判断是否要升级模型或改成路由。