2025最全AnythingLLM+DeepSeek本地知识库搭建指南:8步实现AI智能问答【保姆级教程】
【最新独家】一文掌握AnythingLLM与DeepSeek模型完美结合方案!从零开始搭建私有AI知识库,轻松导入文档实现智能问答,成本低至1/10,小白也能30分钟搞定!

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
AnythingLLM+DeepSeek本地知识库搭建完全指南:打造专属AI智能助手【2025最新】
{/* 封面图片 */}
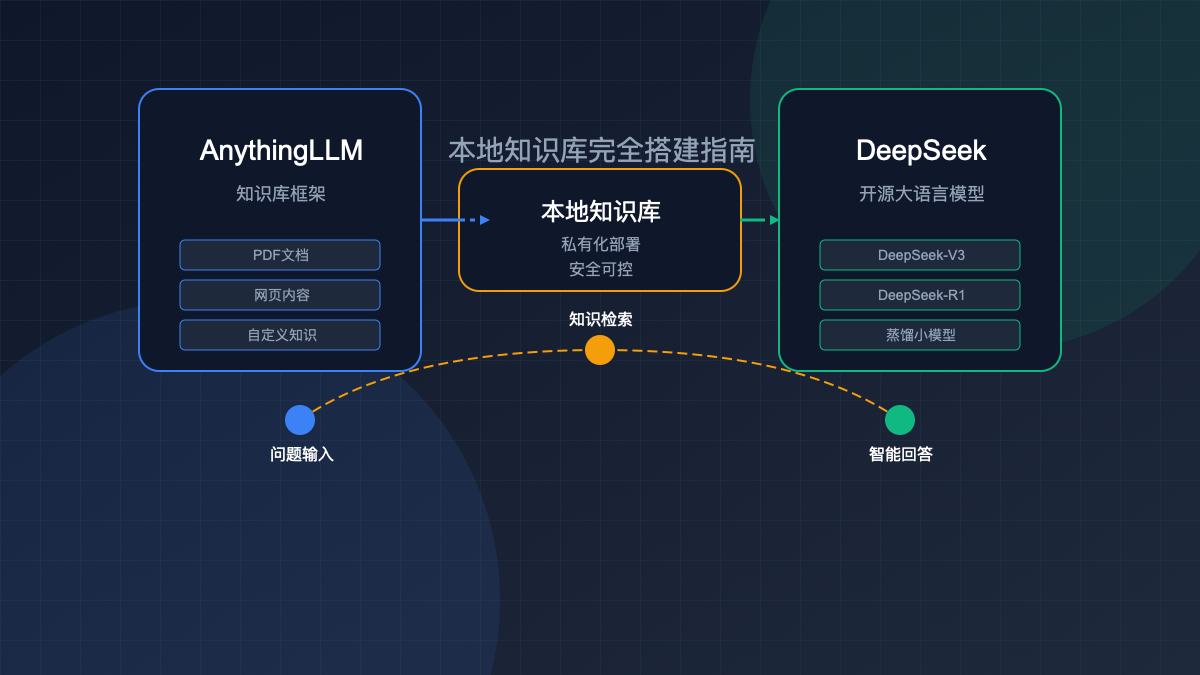
🔥 2025年3月实测有效:本指南提供8步完整流程,帮助你结合AnythingLLM与DeepSeek模型,搭建功能强大的本地知识库。无需云服务,私有化部署,性价比极高!
随着人工智能的迅猛发展,大语言模型(LLM)已成为各行各业提升效率的利器。然而,许多企业和个人面临两大痛点:一是商业模型成本高昂,二是担心敏感数据泄露风险。本教程将详细讲解如何通过开源工具AnythingLLM结合DeepSeek系列模型,搭建一个完全本地化、低成本、高性能的AI知识库系统。
💡 阅读前须知
- 本教程面向对AI知识库搭建有需求的开发者、研究人员和技术爱好者
- 基础环境要求:Windows/Mac/Linux操作系统,8GB以上内存
- 适合配置:对于流畅体验,推荐16GB RAM + NVIDIA GPU(6GB显存以上)
- 无GPU环境也可完成,但响应速度会相对较慢
一、基础概念详解:AnythingLLM与DeepSeek模型是什么?
在开始动手前,让我们先了解这两个核心工具的基本概念和优势。
1. AnythingLLM:开源知识库框架的新星
AnythingLLM是一个功能强大的开源知识库框架,设计用于将各种数据源(文档、网页、音频等)连接到大语言模型。它的核心价值在于:
- 多源数据处理:支持PDF、Word、TXT、CSV、网页URL等多种数据源导入
- 向量化存储:自动将文档切分并向量化,实现语义化检索
- 多模型兼容:支持接入OpenAI、Anthropic、Ollama等多种模型服务
- 用户友好界面:直观的Web界面,无需编程即可操作
- 工作区隔离:支持创建多个独立知识库,满足不同项目需求
2. DeepSeek系列模型:性价比之王
DeepSeek是国内领先的开源大模型系列,提供了多个不同参数规模和专长的模型版本:
- DeepSeek-V3:拥有6710亿参数的超大模型,性能可与GPT-4、Claude 3.5媲美
- DeepSeek-R1:专注于推理能力的模型,通过强化学习训练,逻辑思维能力出色
- DeepSeek蒸馏小模型:参数从1.5B到70B不等,适合本地部署,性能仍然出色
DeepSeek模型的主要优势包括:
- 性价比极高:API调用成本低至同类产品的1/10
- 多语言支持:对中文的支持尤为出色,无中英文切换障碍
- 推理能力强:尤其是R1系列,在复杂问题分析上表现优异
- 开源可控:可完全本地部署,数据不出本地网络

3. 两者结合的优势
AnythingLLM + DeepSeek的组合具有以下显著优势:
- 完全开源:从前端到后端,从模型到框架,全部开源可控
- 成本极低:相比商业解决方案,成本可降低90%以上
- 部署灵活:可根据硬件条件选择不同规模的模型
- 数据安全:所有数据和计算都在本地完成,无需担心敏感信息泄露
- 持续优化:两个项目都有活跃的社区支持和持续更新
二、环境准备:搭建知识库的基础工作
在正式开始搭建之前,我们需要准备好必要的环境和工具。
1. 硬件要求
根据不同的DeepSeek模型规模,硬件要求各不相同:
- 最低配置:8GB内存,无需GPU(使用DeepSeek-R1 1.5B模型)
- 推荐配置:16GB内存,6GB显存以上的NVIDIA GPU(使用DeepSeek-R1 7B模型)
- 高性能配置:32GB内存,16GB显存以上的NVIDIA GPU(使用DeepSeek-R1 14B模型)
2. 软件环境准备
我们需要安装以下核心软件:
- Ollama:用于本地部署和运行DeepSeek模型
- AnythingLLM:知识库框架本身
- Docker(可选):如果使用Docker部署AnythingLLM
三、八步打造专属知识库:完整搭建流程
接下来,我们将通过8个详细步骤,完成整个知识库的搭建过程。
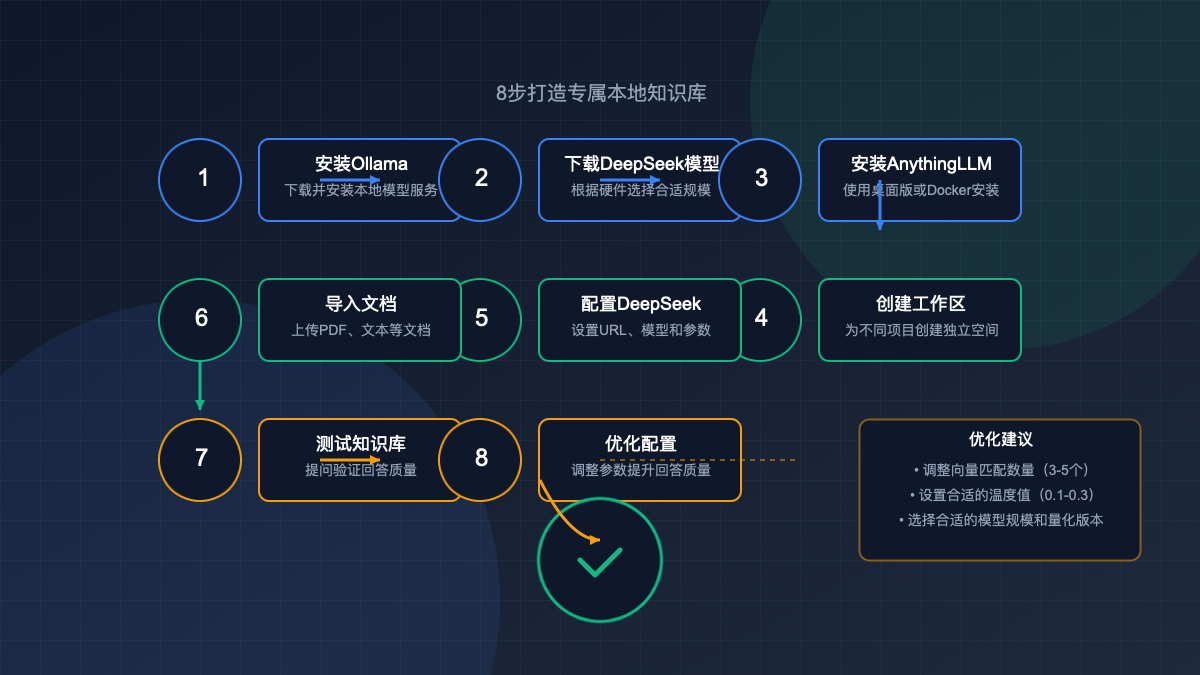
步骤1:安装Ollama
Ollama是一个简化大型语言模型本地部署的工具,我们需要先安装它:
- 访问Ollama官网下载对应操作系统的安装包
- Windows用户:直接运行安装程序
- Mac用户:将应用拖入Applications文件夹
- Linux用户:使用以下命令安装:
bashcurl -fsSL https://ollama.com/install.sh | sh
安装完成后,Ollama会在后台运行,默认监听11434端口。
步骤2:下载DeepSeek模型
根据你的硬件配置,选择合适的DeepSeek模型:
bash# 低配置电脑选择1.5B模型
ollama run deepseek-r1:1.5b
# 中配置电脑选择7B模型
ollama run deepseek-r1:7b
# 高配置电脑选择14B模型
ollama run deepseek-r1:14b
第一次运行时,Ollama会自动从网络下载模型。下载完成后,你会看到一个聊天界面,可以输入exit退出。
步骤3:安装AnythingLLM
AnythingLLM提供多种安装方式,最简单的是使用桌面应用:
- 访问AnythingLLM官网下载桌面版
- 根据操作系统选择对应的安装包:
- Windows:
.exe文件 - MacOS:
.dmg文件 - Linux:
.AppImage文件
- Windows:
- 运行安装程序,按照提示完成安装
安装完成后,启动AnythingLLM应用。首次启动时,会要求设置管理员密码。
步骤4:创建工作区
在AnythingLLM中,工作区是存放相关文档和配置的独立空间:
- 点击"创建新工作区"按钮
- 输入工作区名称(如"技术文档库"或"研究资料")
- 选择工作区图标和颜色(可选)
- 点击"创建"完成工作区创建
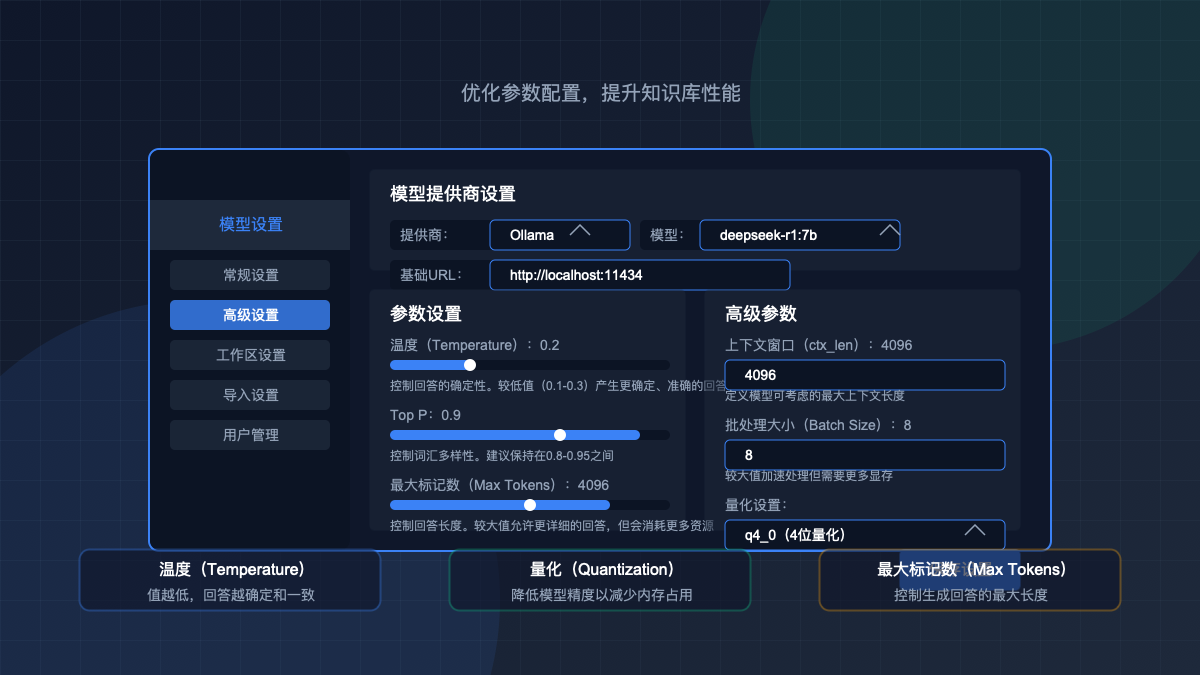
步骤5:配置DeepSeek模型
现在,我们需要将AnythingLLM连接到本地运行的DeepSeek模型:
- 点击左下角"设置"图标(⚙️)
- 在设置页面中,选择"LLM设置"选项卡
- 在"提供商"下拉菜单中选择"Ollama"
- 设置以下参数:
- 基础URL:
http://localhost:11434(如果Ollama运行在其他设备上,替换为对应IP地址) - 模型:选择你在步骤2中下载的模型(如
deepseek-r1:7b) - 温度:推荐设置为0.2-0.3(越低回答越确定)
- 基础URL:
- 点击"保存更改"按钮
步骤6:导入知识库文档
现在,我们可以向工作区添加文档:
- 进入你创建的工作区
- 点击右上角的"上传"按钮
- 选择要上传的文件(支持PDF、DOCX、TXT、CSV等)或输入网页URL
- 上传的文件将显示在临时区域
- 选择你需要导入的文件,然后点击"移至工作区"
- 最后点击"保存并嵌入"按钮
系统会自动处理文档,包括文本提取、分段和向量化。处理时间取决于文档大小和数量。
步骤7:测试知识库问答
文档处理完成后,我们可以开始测试知识库:
- 在工作区的聊天界面中,输入与你上传文档相关的问题
- 系统会从知识库中检索相关内容,然后让DeepSeek模型生成回答
- 回答中会包含引用源,显示信息来自哪些文档
测试几个不同的问题,检验知识库的效果和准确性。
步骤8:优化配置与使用技巧
为了获得最佳体验,你可以进一步优化系统:
-
调整检索参数:
- 在工作区设置中,可以修改"向量匹配数量"(推荐3-5)
- 调整"相关性阈值"(0.2-0.3之间较为合适)
-
改变聊天模式:
- "聊天模式":保持上下文,适合连续对话
- "查询模式":每次问答独立,适合单次查询
-
使用提示词技巧:
- 问题越具体,回答质量越高
- 可以指定期望的回答格式(如"列出5点"或"用表格形式回答")
⚠️ 高级使用提示
- 对于大型文档,建议预先切分为较小的文件,以提高处理效率
- 如果回答中出现幻觉(生成不在文档中的内容),可降低模型温度参数
- 使用"/reset"命令可以重置对话历史,开始新的对话
- 在导入新文档后,最好重置对话以确保模型能访问到最新知识
四、不同场景下的应用示例
接下来,我们分享几个AnythingLLM+DeepSeek组合在不同场景下的应用案例。
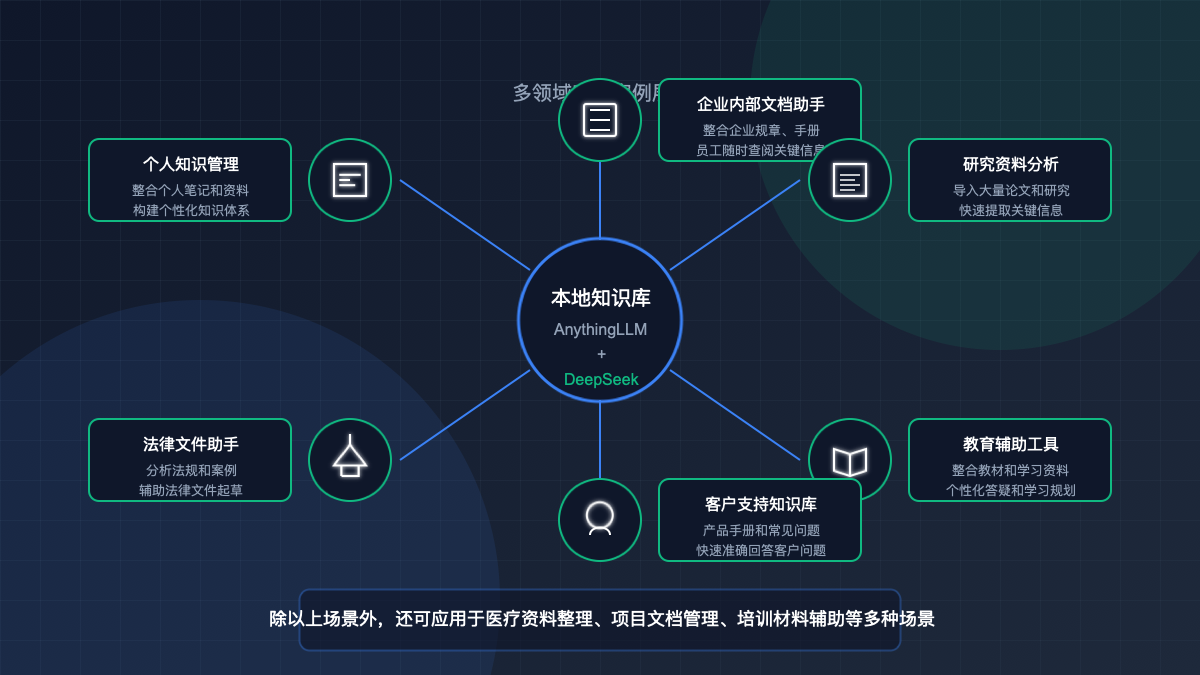
1. 企业内部文档智能助手
场景:企业拥有大量内部文档、产品手册和技术规范,员工需要快速查找相关信息。
实现方法:
- 创建专门的工作区,导入所有企业内部文档
- 配置权限系统,确保敏感信息只对特定人员可见
- 员工可通过自然语言提问,快速获取准确信息
效果:员工提问"我们的退款政策是什么?",系统立即从相关文档中提取并总结退款政策要点。
2. 研究资料分析与问答
场景:研究人员需要从大量论文和研究报告中快速提取信息。
实现方法:
- 创建研究主题工作区,导入相关论文PDF和研究报告
- 使用较低的温度参数(0.1-0.2),确保回答的准确性
- 开启引用功能,跟踪信息来源
效果:研究人员提问"CRISPR技术的最新突破是什么?",系统能够从多篇论文中提取相关信息并生成综述。
3. 个人学习助手
场景:学生或自学者需要整理和理解大量学习资料。
实现方法:
- 创建学科工作区,导入教材、笔记和相关资料
- 使用聊天模式,进行连续的问答互动
- 要求系统用简单语言解释复杂概念
效果:学生提问"量子计算的基本原理是什么?请用简单语言解释",系统能够生成通俗易懂的解释。
4. 客户支持知识库
场景:客服人员需要快速回答客户问题,确保信息准确一致。
实现方法:
- 导入产品手册、常见问题和解决方案文档
- 创建标准回答模板,确保风格一致
- 使用查询模式,每次回答独立处理
效果:当客服提问"如何解决产品X的蓝屏问题?",系统能够提供精确的故障排除步骤。
五、DeepSeek模型选择与优化
DeepSeek提供多种模型,如何选择合适的版本并优化性能是关键。
1. DeepSeek-V3与DeepSeek-R1比较
两种模型各有优势:
| 特性 | DeepSeek-V3 | DeepSeek-R1 |
|---|---|---|
| 参数规模 | 6710亿参数 | 更小,有多种规格 |
| 训练方式 | 传统预训练 | 强化学习 |
| 推理能力 | 知识面广 | 逻辑思维强 |
| 本地部署难度 | 极高 | 中等 |
| 适用场景 | 需要广泛知识的场合 | 需要强推理能力的场合 |
对于本地知识库部署,DeepSeek-R1系列的蒸馏小模型是最佳选择,它们平衡了性能和资源需求。
2. 不同参数规模的选择
根据硬件条件选择合适的模型:
- 1.5B模型:适合CPU或入门级GPU,速度快但能力有限
- 7B模型:平衡选择,中等配置电脑可流畅运行
- 14B模型:能力强但需要较好GPU,适合专业用途
- 70B模型:接近全尺寸能力,但需要高端GPU
3. 性能优化技巧
提升DeepSeek模型在AnythingLLM中的性能:
-
量化优化:
- 使用Ollama的量化功能减少内存占用
- 例如:
ollama run deepseek-r1:7b-q4_0(使用4位量化)
-
上下文窗口调整:
- 减小上下文窗口可以提高响应速度
- 在Ollama配置中设置
ctx_len参数
-
批处理大小:
- 根据GPU显存设置合适的批处理大小
- 在AnythingLLM设置中调整"批处理大小"参数
六、常见问题与解决方案
在使用过程中,你可能会遇到一些问题,以下是常见问题及解决方案。
1. 知识库问答不准确
症状:模型回答与上传文档内容不符,出现"幻觉"。
解决方案:
- 检查向量匹配数量是否设置合理(3-5个较为适宜)
- 降低模型温度(0.1-0.2),减少创造性回答
- 确保文档已正确处理,可尝试重新上传
- 使用更大参数的DeepSeek模型(如从7B升级到14B)
2. 系统运行缓慢
症状:导入文档或回答问题时系统响应极慢。
解决方案:
- 使用参数更小的模型(如从14B降至7B)
- 对模型进行量化(使用q4_0等量化版本)
- 减少单次处理的文档数量
- 增加系统内存或使用SSD提高IO速度
- 关闭其他占用资源的应用程序
3. 模型下载失败
症状:无法下载DeepSeek模型或下载中断。
解决方案:
- 检查网络连接稳定性
- 使用VPN或代理服务器
- 尝试在非高峰时段下载
- 使用
ollama pull命令代替ollama run单独下载 - 检查磁盘空间是否充足
4. 文档处理失败
症状:上传文档后处理失败或无法向量化。
解决方案:
- 检查文档格式是否受支持
- 尝试将复杂格式(如PDF)转换为纯文本
- 减小文档大小,分割大文件
- 检查文档是否加密或有权限限制
- 更新AnythingLLM到最新版本
⚠️ 常见误区警告
- 误区1:认为本地知识库能理解所有内容 — 模型只能基于导入的文档回答问题
- 误区2:上传过多文档 — 文档越多不代表效果越好,精准相关的文档更重要
- 误区3:忽视硬件限制 — 选择与硬件匹配的模型规模很重要
- 误区4:期望100%准确 — 即使最好的设置也可能偶尔出现不准确回答
七、与商业解决方案的对比
AnythingLLM+DeepSeek组合与商业知识库解决方案相比有何优劣?
1. 成本对比
| 解决方案 | 每月成本 | 部署方式 | 数据所有权 |
|---|---|---|---|
| AnythingLLM+DeepSeek | 几乎免费 | 本地私有化 | 完全自有 |
| OpenAI+Azure KB | 约$500起 | 云服务 | 部分上云 |
| Claude+企业知识库 | 约$600起 | 云服务 | 部分上云 |
| 商业知识库产品 | $1000-5000 | 混合部署 | 混合 |
2. 功能对比
| 功能 | AnythingLLM+DeepSeek | 商业解决方案 |
|---|---|---|
| 多文档格式支持 | ✅ | ✅ |
| 实时更新 | ⚠️ 需手动更新 | ✅ 自动更新 |
| 多语言支持 | ✅ | ✅ |
| 精细权限控制 | ⚠️ 有限支持 | ✅ 完全支持 |
| 企业集成 | ⚠️ 需二次开发 | ✅ 直接支持 |
| 隐私保护 | ✅ 完全本地化 | ⚠️ 可能上云 |
| 定制开发 | ✅ 完全开源 | ⚠️ 通常封闭 |
3. 使用场景建议
推荐使用AnythingLLM+DeepSeek的场景:
- 对成本敏感的中小企业和团队
- 对数据隐私有严格要求的场景
- 需要完全掌控和定制系统的技术团队
- 个人学习和研究用途
商业解决方案更适合的场景:
- 大型企业需要企业级支持和SLA保障
- 无技术团队维护本地部署的组织
- 需要与现有企业系统深度集成的场景
- 对易用性要求高于成本和隐私的用户
八、未来展望与发展方向
随着技术的不断进步,AnythingLLM+DeepSeek的组合还有很大的发展空间。
1. 技术趋势
- 多模态支持:未来版本可能支持图像和音频的理解和检索
- 工具使用能力:集成更多外部工具和API
- 自动更新机制:实现知识库的自动更新和管理
- 更智能的检索:基于语义而非关键词的更高级检索算法
- 模型持续优化:DeepSeek模型性能将不断提升
2. 可能的应用拓展
- 垂直行业解决方案:针对医疗、法律、教育等特定行业的专用知识库
- 多语言知识库:支持更多语言和跨语言检索
- 协同工作模式:支持多用户同时贡献和使用知识库
- 移动端支持:轻量级客户端实现移动设备访问
结语:打造属于你的AI知识助手
通过本教程,你已经掌握了如何使用AnythingLLM和DeepSeek模型搭建一个功能强大的本地知识库。这个系统不仅成本低廉,而且保护了数据隐私,非常适合各类组织和个人使用。
无论是企业内部文档管理、研究资料整理,还是个人学习助手,这套组合都能提供智能、高效的知识处理和问答能力。随着你不断添加和更新知识库内容,系统的价值将持续增长。
开始动手尝试吧!当你遇到任何问题,都可以参考本文的故障排除部分,或者访问AnythingLLM和DeepSeek的官方社区寻求帮助。
🌟 最后提示:技术在不断发展,请定期更新AnythingLLM和DeepSeek模型,以获得最佳体验和性能!
【更新日志】持续优化的见证
plaintext┌─ 更新记录 ──────────────────────────┐ │ 2025-03-21:首次发布完整指南 │ │ 2025-03-18:测试DeepSeek-R1最新版本 │ │ 2025-03-15:测试AnythingLLM最新版本 │ └─────────────────────────────────────┘
🎉 特别提示:本文将持续更新,建议收藏本页面,定期查看最新内容!