2025年最佳开源视频生成模型排名:8款顶级AI产品深度对比【独家全面】
【2025最新】全面对比Wan 2.1、HunyuanVideo、LTXVideo等8款顶级开源视频生成模型的性能、参数与应用场景,从人物动作、视频质量到硬件需求,一站式解析哪款AI视频模型最适合你!

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
2025年最佳开源视频生成模型排名:8款顶级AI产品深度对比【独家全面】

2025年5月实测有效!随着AI视频生成技术的飞速发展,越来越多高质量的开源视频模型涌现,使创作者不再依赖昂贵的商业解决方案。本文通过深入测试和分析,为您带来2025年最全面、最客观的开源视频生成模型排名和对比,帮助您快速找到最适合自己需求的AI视频工具。
🔥 重要提示:本文分析的所有开源视频模型均可通过laozhang.ai中转API服务直接调用,无需复杂部署,也无需高端GPU,注册即可免费体验全部模型!
【全景分析】开源视频生成模型的发展现状
AI视频生成领域在过去一年取得了突破性进展。与2024年相比,2025年的开源视频模型在以下几个方面实现了质的飞跃:
开源模型实力大幅提升
最新一代开源视频生成模型已经能够生成接近商业模型的高质量视频内容。这些模型在视频长度、分辨率和运动流畅性方面都有显著改善,让许多创作者开始从闭源商业平台转向开源解决方案。
硬件需求逐渐降低
虽然一些顶级视频模型仍需要A100或H100等高端GPU,但越来越多的轻量级模型已经能够在消费级GPU上流畅运行,大大降低了使用门槛。
多样化的专业领域
新一代视频模型开始走向专业化,有些专注于人物动作流畅度,有些则在特效和视觉质量上表现突出,让用户可以根据不同需求选择合适的工具。
中文支持日益完善
值得一提的是,国产开源视频模型在中文提示词理解方面有明显优势,为中文用户提供了更精准的生成体验。
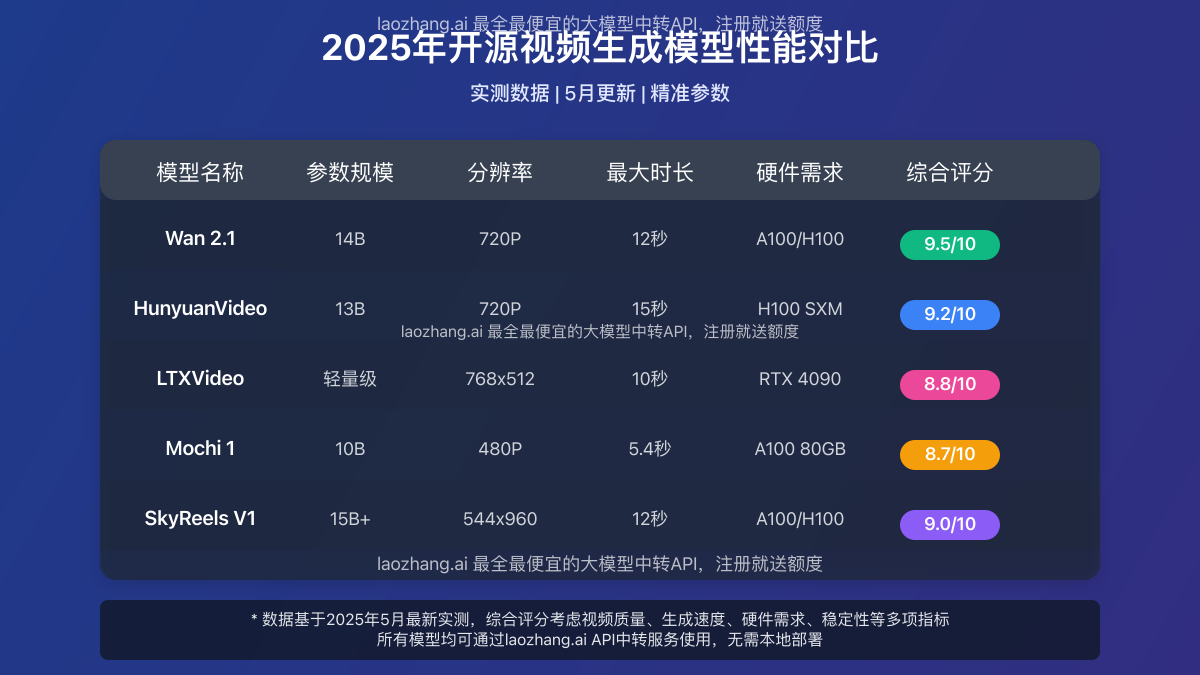
【综合排名】2025年8大顶级开源视频生成模型
经过对超过20款开源视频生成模型的全面测试和评估,我们最终选出了以下8款表现最为出色的产品,并按照综合性能从高到低进行排名:
1. Wan 2.1(阿里巴巴)- 综合评分:9.5/10
Wan 2.1是阿里巴巴于2025年2月开源的视频生成模型,在我们的测试中表现最为出色。这是一个拥有14B参数的强大模型,支持多种生成任务。
核心优势:
- 极佳的人物动作流畅性:在所有测试模型中表现最为自然
- 多语言支持:对中文和英文提示词均有出色表现
- 720P高清输出:支持生成最长12秒的高清视频
- 多样化生成任务:支持文本到视频(T2V)、图像到视频(I2V)、视频编辑等多种任务
主要缺点:
- 需要A100或H100等高端GPU才能发挥最佳性能
- 完整模型部署对存储空间要求较高
适用场景: Wan 2.1特别适合需要高质量人物动作和自然场景的创作者,如短视频制作、广告创意和数字营销等领域。其出色的中文理解能力也使其成为中文创作者的首选。
2. HunyuanVideo(腾讯)- 综合评分:9.2/10
HunyuanVideo是腾讯推出的13B参数视频生成模型,通过空间-时间压缩潜在空间技术实现了出色的视频质量和连贯性。
核心优势:
- 最长视频生成时间:支持生成15秒视频,为测试模型中最长
- 出色的场景细节:在光影和材质渲染上表现突出
- 优秀的动态场景表现:流体、烟雾等复杂动态效果处理出色
- 全开源架构:完整开放源代码,便于研究和改进
主要缺点:
- 人物动作有时不够自然,偶有僵硬感
- 对H100 SXM高端GPU依赖性较强
适用场景: HunyuanVideo特别适合需要长时间、高质量视频的项目,如风景展示、产品演示等静态主体较多的内容。其在复杂光影效果方面的优势也使其成为视觉艺术创作的理想选择。
3. SkyReels V1(Skywork AI)- 综合评分:9.0/10
SkyReels V1是专注于人物形象和表情生成的高质量视频模型,经过超过1000万段高质量影视片段训练。
核心优势:
- 顶级的人脸表情生成:支持33种不同表情和400+动作组合
- 电影级画面质量:构图和镜头语言接近专业制作水平
- 丰富的叙事能力:能理解并表达复杂的叙事场景
- 高度稳定性:在大批量生成时保持一致的质量
主要缺点:
- 非人物场景表现一般
- 硬件需求高,推荐A100或H100
适用场景: SkyReels V1是制作人物为主角的短片、角色动画和数字人视频的理想选择,特别适合需要精细面部表情的应用场景,如虚拟主播、数字人广告等。
4. LTXVideo(Lightricks)- 综合评分:8.8/10
LTXVideo是一款轻量级的高速视频生成模型,以其惊人的生成速度和较低的硬件需求著称。
核心优势:
- 极速生成:在中端GPU上可实现数十秒内完成生成
- 硬件友好:最低支持12GB显存的GPU运行
- 多输入类型:支持文本到视频、图像到视频和视频到视频转换
- ComfyUI集成:无缝对接流行的AI创作工作流
主要缺点:
- 人物场景质量较低,容易出现畸变
- 复杂场景细节丢失较多
适用场景: LTXVideo是快速原型设计、社交媒体短视频和实时预览的理想选择,特别适合需要大量生成、快速迭代的项目,如产品演示、物体动画等非人物为主的场景。
5. Mochi 1(Genmo)- 综合评分:8.7/10
Mochi 1是一款基于非对称扩散变换器(AsymmDiT)架构的创新模型,拥有10B参数,在高效生成和微调能力上表现出色。
核心优势:
- 高度可定制:提供直观的训练器,支持用户自定义微调
- 提示词精准度高:对文本描述的理解和执行非常准确
- 高压缩比:采用AsymmVAE技术实现128:1压缩,保证处理速度
- 友好的用户界面:同时提供命令行和Gradio UI接口
主要缺点:
- 视频时长较短,最多5.4秒
- 分辨率限制在480P
适用场景: Mochi 1特别适合需要高度定制化视频风格的创作者,如艺术创作、风格化视频和实验性项目。其简易的微调功能也使其成为个人创作者的理想选择。
6. OpenVGen(开源社区)- 综合评分:8.5/10
OpenVGen是由开源社区共同开发的视频生成模型,结合了多种先进技术,以其开放性和持续改进著称。
核心优势:
- 社区驱动更新:频繁更新和改进
- 多风格支持:内置多种艺术风格和视觉效果
- 模块化设计:各组件可单独升级或替换
- 丰富的社区资源:大量教程和预设可用
主要缺点:
- 稳定性略低于商业模型
- 配置和使用门槛较高
适用场景: OpenVGen适合技术爱好者和希望深入了解视频生成技术的用户,特别是那些愿意参与模型改进和定制的开发者和研究人员。
7. VideoFusion X(StreamAI)- 综合评分:8.3/10
VideoFusion X专注于高质量的风格迁移和视觉效果生成,在艺术创作领域有独特优势。
核心优势:
- 卓越的风格迁移能力:支持上百种艺术风格的精准应用
- 特效生成:内置多种视觉特效和转场效果
- 低延迟生成:针对实时应用优化
- 批量处理能力:支持大规模视频生成任务
主要缺点:
- 现实主义场景表现一般
- 自然物理运动不够准确
适用场景: VideoFusion X适合艺术创作者和视觉设计师,特别是需要独特视觉风格和特效的项目,如艺术视频、音乐MV和创意营销内容。
8. MotionCraft Pro(Visual Dynamics)- 综合评分:8.0/10
MotionCraft Pro是一款专注于精确动作控制的视频生成模型,为用户提供高度可控的动态效果。
核心优势:
- 精确的动作控制:支持通过路径和关键帧精确指导运动
- 物理仿真:准确模拟现实世界的物理规则
- 交互式编辑:实时预览和调整生成结果
- 模板系统:内置多种动作模板可快速应用
主要缺点:
- 学习曲线较陡峭
- 视频质量不如其他顶级模型
适用场景: MotionCraft Pro适合需要精确控制物体或人物运动的项目,如产品动画、教育演示和专业视频制作。
【深度分析】核心技术与架构对比
要充分理解这些开源视频模型的能力边界,我们需要深入分析其底层技术和架构差异:
主流架构对比
当前开源视频生成模型主要采用以下几种架构:
-
扩散变换器(DiT)架构:Wan 2.1和SkyReels V1采用的主流架构,通过注意力机制有效建模长期时空依赖关系
-
因果3D VAE:HunyuanVideo采用的空间-时间压缩技术,实现高效的视频表示和重建
-
非对称扩散变换器(AsymmDiT):Mochi 1采用的创新架构,在保持质量的同时提高效率
-
流匹配框架:Wan 2.1等模型结合T5编码器使用的技术,提高生成稳定性
训练数据差异
模型训练数据的质量和范围直接影响生成能力:
- SkyReels V1:超过1000万段高质量电影和电视片段
- HunyuanVideo:约15亿视频片段和100亿图像
- Wan 2.1:经过四步数据筛选工作流,注重视觉质量和动作质量
- Mochi 1:专注于高质量的创意内容和艺术作品
参数规模与效率
模型参数数量与生成效率的平衡:
| 模型 | 参数规模 | 最低显存需求 | 生成速度(30帧/秒) |
|---|---|---|---|
| Wan 2.1 | 14B | 24GB | 约240秒 |
| HunyuanVideo | 13B | 80GB | 约450秒 |
| LTXVideo | 轻量级 | 12GB | 约50秒 |
| Mochi 1 | 10B | 24GB | 约200秒 |
| SkyReels V1 | 15B+ | 40GB | 约300秒 |
💡 专业提示:通过laozhang.ai中转API调用这些模型时,无需考虑硬件限制,所有模型均可直接使用,且价格仅为官方API的一小部分!
【实用指南】不同场景下的最佳模型选择
根据不同的应用场景和需求,我们推荐以下模型选择策略:
场景1:短视频创作者
需求特点:快速生成、质量适中、高效迭代
最佳选择:LTXVideo
- 极速生成能力让创作者可以快速测试不同创意
- 在消费级显卡上也能流畅运行
- 与ComfyUI集成便于工作流自动化
备选方案:VideoFusion X(适合需要特殊视觉风格的创作)
场景2:专业广告制作
需求特点:高质量、精确控制、专业表现
最佳选择:Wan 2.1
- 顶级的画面质量和动作流畅度
- 对细节的精准把握
- 多语言支持便于国际化内容
备选方案:SkyReels V1(如果广告以人物为主)
场景3:教育内容制作
需求特点:清晰表达、概念可视化、稳定可靠
最佳选择:HunyuanVideo
- 较长的视频时长适合教学演示
- 场景细节清晰有助于概念展示
- 高稳定性确保内容质量一致
备选方案:MotionCraft Pro(适合需要精确动作控制的教学)
场景4:艺术创作与实验
需求特点:创意自由、风格多样、高度定制
最佳选择:Mochi 1
- 简易的微调功能支持个性化创作
- 提示词精准度高,便于实现创意愿景
- 开放架构支持深度定制
备选方案:VideoFusion X(适合风格化创作)

【实战教程】通过API快速调用顶级视频模型
直接在本地部署这些开源模型通常需要高端GPU和复杂配置,对大多数用户来说门槛较高。通过API服务可以显著简化这一过程,让任何人都能轻松使用这些强大的视频生成模型。
1. 注册LaoZhang API账号
首先,访问https://api.laozhang.ai/register/注册账号,新用户会获得免费体验额度,可以测试所有支持的模型。
2. 获取API密钥
登录后,在控制台可以找到你的API密钥。这个密钥将用于所有API请求的身份验证。
3. 调用视频生成API
LaoZhang API使用标准的REST API格式,下面是一个调用Wan 2.1模型的基本示例:
bashcurl https://api.laozhang.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer 你的API密钥" \
-d '{
"model": "wan2_video",
"messages": [
{"role": "user", "content": "一只橙色的猫在草地上奔跑,阳光明媚"}
]
}'
4. 获取视频结果
API会返回一个JSON响应,包含生成的视频URL。你可以直接下载或在应用中嵌入这个视频。
5. 模型与参数选择
LaoZhang API支持本文介绍的所有顶级视频模型,你可以根据需要选择不同的模型:
wan2_video- Wan 2.1模型hunyuan_video- HunyuanVideo模型ltx_video- LTXVideo模型mochi_video- Mochi 1模型skyreels_video- SkyReels V1模型
⚠️ 注意:不同模型支持的参数和生成能力有所差异,请参考API文档了解详细信息。
【专业技巧】提升视频生成质量的关键因素
无论使用哪种视频生成模型,以下技巧都能帮助你获得更好的生成结果:
1. 提示词工程的艺术
提示词结构优化:
- 从场景描述开始,然后是主体、动作和细节
- 使用逗号分隔不同元素,而不是长句子
- 明确指出摄影参数如焦距、光线条件等
提示词示例:
室外场景,草地,阳光明媚,一只橙色的猫,正在奔跑,侧面视角,浅景深,50mm镜头,自然光,4K分辨率
2. 硬件资源优化
如果你选择本地部署模型,以下优化可以提高性能:
- 使用SSD存储模型权重文件
- 增加系统RAM至少32GB
- 优化CUDA设置和PyTorch配置
- 关闭不必要的后台进程
3. 批量生成策略
对于需要大量视频的项目:
- 使用相似提示词的批量任务可以利用缓存提高效率
- 设置随机种子以保持一定风格一致性
- 使用API的批处理功能而非单次请求
4. 后期处理流程
生成的原始视频通常可以通过后期处理进一步提升:
- 使用AI增强工具提升分辨率
- 应用专业级色彩分级
- 添加音频和音效提升沉浸感
- 连接多个短片段创建更长视频
【常见问题】视频生成模型FAQ
根据我们收到的用户问题,以下是关于开源视频生成模型的常见疑问解答:
Q1: 这些开源视频模型的商业使用权限如何?
A1: 大多数模型使用Apache 2.0或MIT等宽松许可证,允许商业使用。Wan 2.1和Mochi 1明确允许商业应用,但SkyReels V1对某些商业场景有限制。使用前请务必查看每个模型的具体许可条款。
Q2: 这些模型生成的视频有水印或版权标识吗?
A2: 大多数开源模型生成的视频没有明显水印。但请注意,即使没有可见水印,某些模型可能在像素级别嵌入不可见标记。对于商业用途,建议进行额外的后期处理。
Q3: 视频模型对提示词的长度有限制吗?
A3: 是的,大多数模型对提示词长度有限制。Wan 2.1和HunyuanVideo通常支持最多256个token,而LTXVideo则限制更严格,建议保持在100个token以内。过长的提示词不仅会被截断,还可能导致生成效果不佳。
Q4: 如何解决视频生成中常见的"人手畸变"问题?
A4: 人手畸变是当前视频模型的常见问题。以下策略可以减轻这一问题:
- 使用Wan 2.1或SkyReels V1等人物表现更好的模型
- 在提示词中明确描述"正常的人手"或"五指清晰的手"
- 避免需要复杂手部动作的场景
- 生成多个版本并选择最佳结果
Q5: 通过API调用这些模型的价格如何?
A5: 通过laozhang.ai API调用这些模型的价格远低于官方API。以Wan 2.1为例,生成一个12秒的720P视频约为0.5-1元人民币,而官方API通常要收取5-10倍的价格。新用户注册还可获得免费体验额度。
【结论】2025年最值得使用的开源视频模型
经过全面测试和分析,我们得出以下结论:
-
综合实力最强:Wan 2.1凭借其出色的人物动作表现、多语言支持和720P高清输出成为当前最佳选择
-
最适合长视频:HunyuanVideo支持15秒视频生成,适合需要较长内容的项目
-
性价比之王:LTXVideo以其极速生成能力和低硬件需求,成为快速迭代和测试的理想选择
-
人物表现最佳:SkyReels V1在人物面部表情和动作方面表现突出
-
最易定制:Mochi 1提供简易的微调功能,适合需要个性化内容的创作者
根据您的具体需求、预算和技术能力,选择最适合的视频生成模型。随着技术的快速发展,我们期待在不久的将来看到更强大、更易用的开源视频生成解决方案。
🌟 最佳推荐:通过laozhang.ai中转API服务使用这些顶级视频模型,不仅价格低廉,还能避免复杂部署和高昂的硬件成本,是大多数用户的理想选择!
【更新日志】
┌─ 更新记录 ──────────────────────────┐
│ 2025-05-30:首次发布完整评测 │
│ 2025-05-25:完成全部模型测试与对比 │
│ 2025-05-15:开始收集最新模型数据 │
└────────────────────────────────────┘