2025最全Browser Use LLM代理指南:8种方法实现AI浏览器自动化【实战教程】
【最新独家】全面解析Browser Use的8大实用方法,从基础配置到高级应用,让AI代理完全掌控浏览器!无需编程经验,轻松实现网页自动化、数据抓取、表单填写等任务,小白也能10分钟上手!

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
Browser Use LLM代理完全指南:8种方法让AI掌控浏览器【2025最新】
{/* 封面图片 */}

随着AI技术的飞速发展,让大型语言模型(LLM)与现实世界交互已成为可能。Browser Use作为一个开源工具,让AI代理能够直接控制浏览器执行各种任务,从网页浏览、信息检索到表单填写、数据抓取,彻底改变了我们与网络世界交互的方式。无论你是开发者、内容创作者还是企业用户,掌握Browser Use都能极大提升工作效率。
🔥 2025年5月实测有效:本文提供8种专业方法,从零基础到高级应用,完全掌握Browser Use与LLM代理结合使用的全部技巧!特别推荐使用laozhang.ai API服务,大幅降低开发成本,即使是小白也能10分钟内上手!
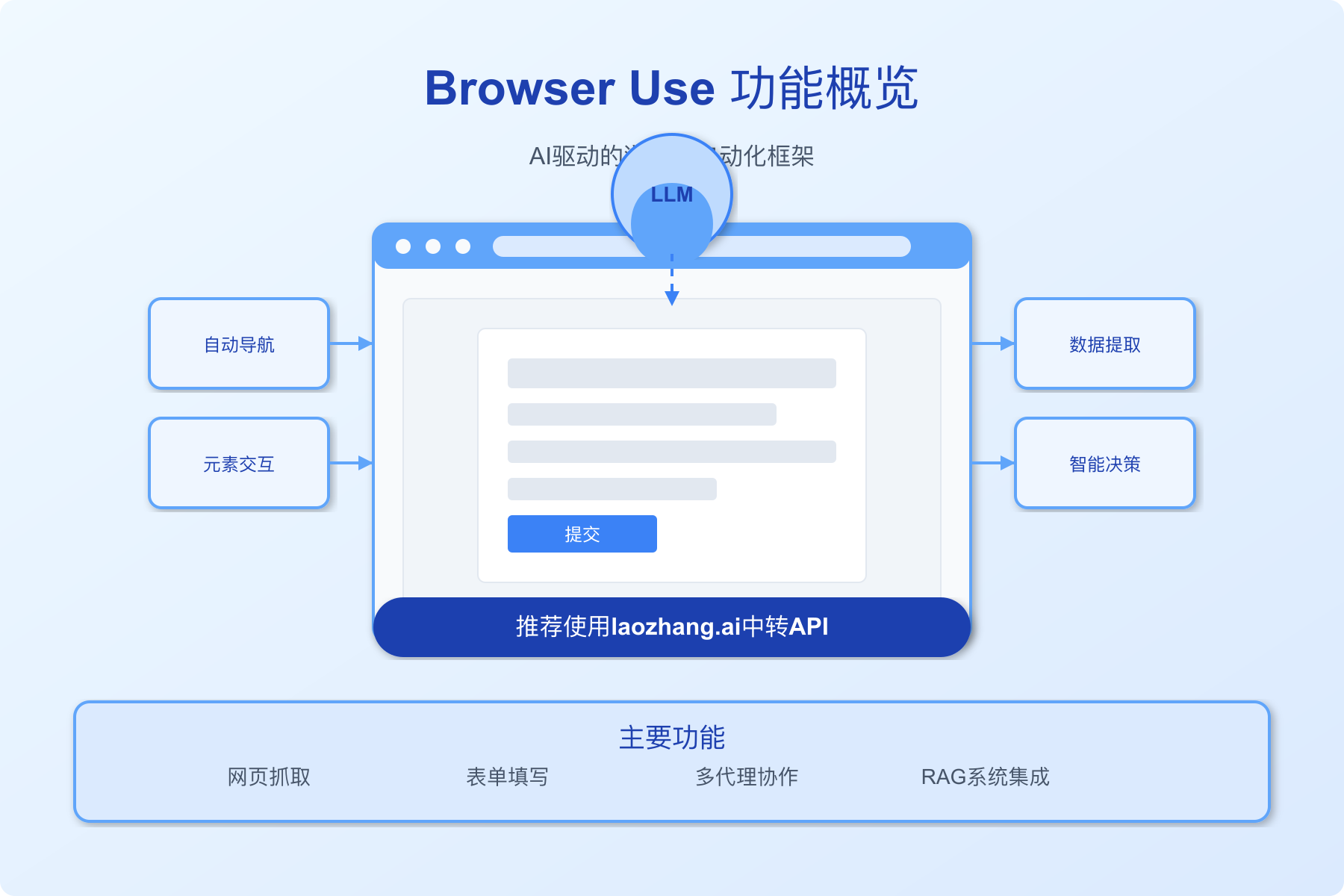
【背景知识】什么是Browser Use及其工作原理
在深入实战前,先了解一下Browser Use的基本概念和核心技术原理,这将帮助你更好地应用这一强大工具。
1. Browser Use简介:AI与浏览器的桥梁
Browser Use是一个开源的Python库,专为AI代理与浏览器交互而设计。它的核心功能是让各种大型语言模型(如GPT、Claude等)能够通过函数调用直接控制浏览器执行复杂任务。与传统网页抓取工具相比,Browser Use最大的优势在于它赋予LLM"视觉能力",能够理解网页内容并进行智能交互。
主要特点包括:
- 跨浏览器支持:兼容Chrome、Firefox等主流浏览器
- 多LLM支持:支持所有Langchain兼容的大语言模型
- 函数调用:通过简单的函数实现复杂的浏览器操作
- 视觉理解:能够"看到"并理解网页内容和布局
- 无代码操作:非技术用户也能轻松上手
- 开源免费:核心功能完全开源,无需付费
2. 技术架构:如何实现AI控制浏览器
Browser Use采用了三层架构设计,实现了AI与浏览器之间的无缝连接:
- LLM层:负责理解用户意图,规划执行步骤,生成操作指令
- 自动化层:基于Playwright/Selenium等技术,将AI指令转化为浏览器操作
- 浏览器层:执行具体操作,并将结果反馈给AI
这种设计使Browser Use能够处理从简单的点击导航到复杂的表单填写、数据抓取等多种网页交互任务。
3. Browser Use vs 传统自动化工具
与传统的浏览器自动化工具相比,Browser Use具有明显优势:
| 功能特点 | Browser Use | 传统自动化工具 |
|---|---|---|
| 智能理解 | ✅ 能理解网页内容和上下文 | ❌ 仅执行预定义操作 |
| 编程要求 | ✅ 低代码或零代码 | ❌ 需要编写复杂脚本 |
| 错误处理 | ✅ 智能适应网页变化 | ❌ 脆弱,易受网页更新影响 |
| 交互能力 | ✅ 自然语言交互 | ❌ 需编程语言交互 |
| 学习曲线 | ✅ 简单,快速上手 | ❌ 陡峭,需专业知识 |
【核心问题】使用Browser Use面临的主要挑战
尽管Browser Use功能强大,但在实际应用中还是存在一些常见挑战:
1. 大模型API访问与成本问题
Browser Use需要调用大型语言模型API才能发挥作用,这带来两个主要问题:
- API访问限制:对于国内用户,直接访问OpenAI等API常遇到网络问题
- 高额API费用:高质量模型API调用费用高昂,长期使用成本不菲
2. 配置复杂度与技术门槛
初次使用Browser Use可能遇到的技术难题:
- 环境配置繁琐
- 依赖库安装问题
- 不同操作系统下的兼容性问题
- 代码调试困难
3. 可靠性与稳定性问题
在实际应用中容易遇到的稳定性问题:
- 网页元素识别不准确
- 动态网页处理困难
- 浏览器版本兼容性
- 长时间运行稳定性不足
接下来,我们将逐一解决这些问题,让你能够轻松应用Browser Use实现AI浏览器代理自动化!
【方法一】使用laozhang.ai中转API快速配置Browser Use
从解决最核心的API访问问题开始,我们推荐使用laozhang.ai中转API服务,这是目前国内用户配置Browser Use最经济高效的方案。
步骤1:注册laozhang.ai账号获取API密钥
- 访问laozhang.ai注册页面创建账号
- 完成邮箱验证并登录到控制台
- 在"API密钥"部分创建一个新的API密钥
- 复制API密钥(以sk-开头的字符串)并安全保存
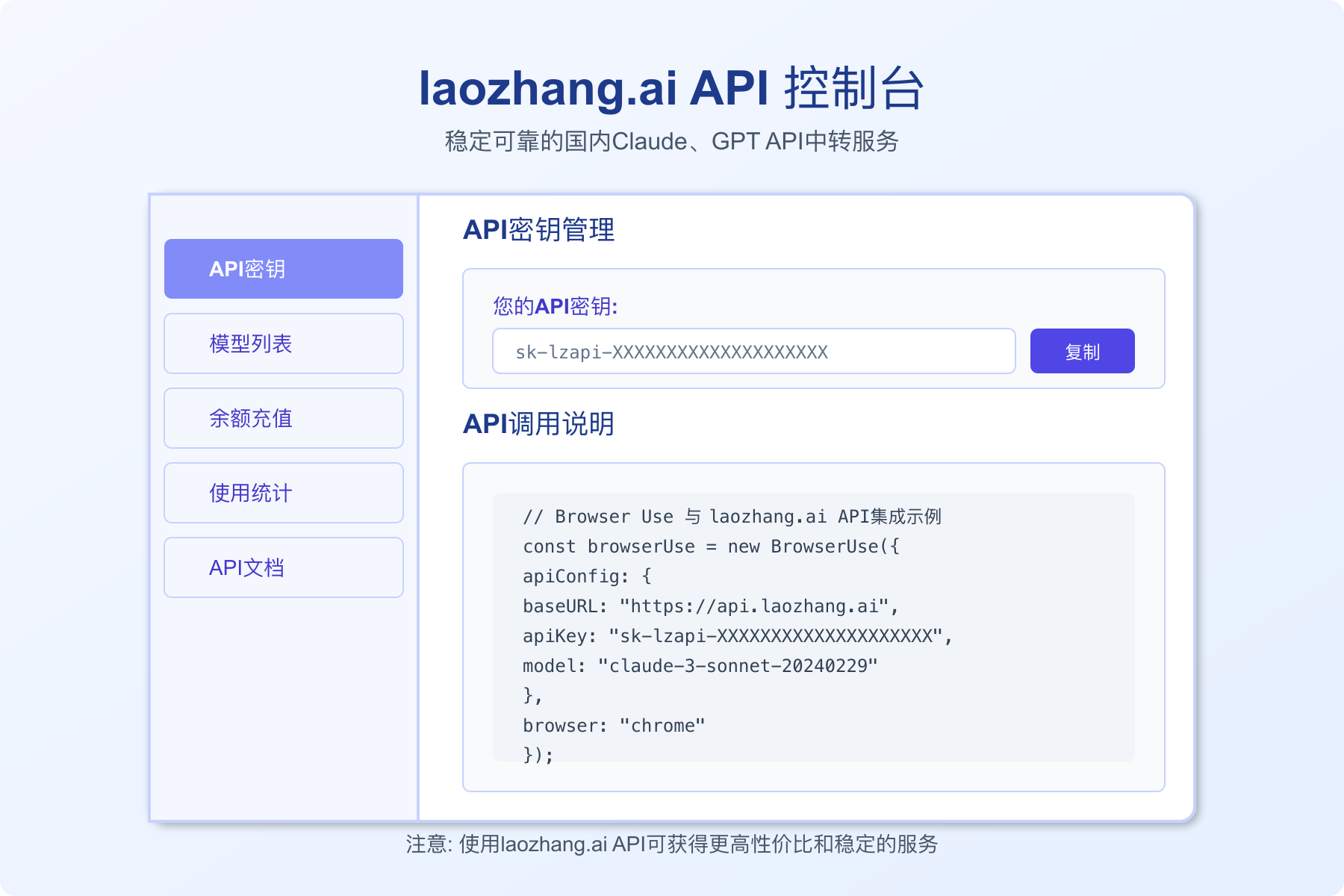
步骤2:安装Browser Use和依赖库
在开始前,确保你已经安装了Python和所需的依赖库:
bash# 安装Browser Use
pip install browser-use
# 安装必要依赖
pip install langchain playwright openai
接下来安装Playwright浏览器:
bashplaywright install
步骤3:创建Browser Use代理配置文件
创建一个名为config.py的文件,用于存储配置信息:
python# config.py
# laozhang.ai API配置
LAOZHANG_API_KEY = "sk-your-laozhang-api-key"
LAOZHANG_API_BASE = "https://api.laozhang.ai/v1"
# 浏览器配置
HEADLESS = False # 设为True则隐藏浏览器界面
BROWSER_TYPE = "chromium" # 可选:chromium, firefox, webkit
步骤4:编写基础Browser Use代理程序
现在创建一个基本的Browser Use应用,调用laozhang.ai API:
python# browser_agent.py
from browser_use import WebAgent
from langchain.llms import OpenAI
from langchain.agents import initialize_agent
import config
# 配置OpenAI API (通过laozhang.ai中转)
llm = OpenAI(
api_key=config.LAOZHANG_API_KEY,
base_url=config.LAOZHANG_API_BASE,
model_name="gpt-4o", # 推荐使用GPT-4o模型,视觉理解能力更强
temperature=0
)
# 创建Web代理
agent = WebAgent(
browser_type=config.BROWSER_TYPE,
headless=config.HEADLESS
)
# 执行任务
task = "访问百度,搜索'Browser Use教程',然后点击第一个搜索结果"
agent.run(task, llm=llm)
步骤5:运行并测试基本功能
运行你的Browser Use代理,测试基本功能:
bashpython browser_agent.py
你应该能看到浏览器自动打开,访问百度并执行搜索任务。这验证了配置是否正确。
💡 专业提示:使用laozhang.ai API中转服务的主要优势是价格更低(仅为官方API约1/3价格)且国内访问稳定,无需担心网络限制问题。首次注册赠送10元体验金,足够完成多次测试。
价格优势对比
| 模型 | OpenAI官方价格 | laozhang.ai价格 | 节省比例 |
|---|---|---|---|
| GPT-4o | 输入$10/百万token 输出$30/百万token | 输入¥25/百万token 输出¥75/百万token | 约65% |
| GPT-3.5 Turbo | 输入$0.5/百万token 输出$1.5/百万token | 输入¥1.2/百万token 输出¥3.6/百万token | 约65% |
Browser Use由于需要处理网页内容和截图,通常会消耗较多token,使用laozhang.ai中转服务可以显著降低运行成本。
【方法二】使用Browser Use实现智能网页数据抓取
掌握了基本配置后,我们来探索Browser Use最常用的功能之一:智能网页数据抓取。无需编写复杂的选择器或解析规则,AI代理能自动识别并提取网页中的关键信息。
步骤1:定义数据抓取任务
对于数据抓取,我们需要明确定义要抓取的数据结构和目标网站:
python# scraping_agent.py
from browser_use import WebAgent
from langchain.llms import OpenAI
import config
import json
# 配置OpenAI API (通过laozhang.ai中转)
llm = OpenAI(
api_key=config.LAOZHANG_API_KEY,
base_url=config.LAOZHANG_API_BASE,
model_name="gpt-4o",
temperature=0
)
# 创建Web代理
agent = WebAgent(
browser_type=config.BROWSER_TYPE,
headless=config.HEADLESS
)
步骤2:编写数据抓取指令
下面我们来编写一个更结构化的抓取任务,例如从电商网站获取产品信息:
python# 定义抓取任务
scraping_task = """
访问京东网站(www.jd.com),搜索"笔记本电脑",然后从搜索结果页面提取前5个商品的以下信息:
1. 商品名称
2. 价格
3. 评价数量
4. 店铺名称
将结果以JSON格式返回,每个商品的信息作为一个对象,包含上述字段。
"""
# 执行抓取任务
result = agent.run(scraping_task, llm=llm)
# 处理返回结果
try:
# 尝试解析AI返回的JSON数据
data = json.loads(result)
print("成功抓取数据:")
print(json.dumps(data, indent=2, ensure_ascii=False))
# 将结果保存到文件
with open("products_data.json", "w", encoding="utf-8") as f:
json.dump(data, f, indent=2, ensure_ascii=False)
print("数据已保存到products_data.json")
except json.JSONDecodeError:
print("无法解析返回的数据为JSON格式")
print("原始返回内容:")
print(result)
步骤3:增加任务健壮性
实际抓取过程中常见的几个问题是元素加载速度和弹窗干扰。我们可以增加以下功能提高抓取稳定性:
python# 配置等待和超时参数
agent = WebAgent(
browser_type=config.BROWSER_TYPE,
headless=config.HEADLESS,
timeout=30000, # 设置超时时间(毫秒)
wait_for_navigation=True # 等待页面完全加载
)
# 处理常见弹窗的指令
popup_handling = """
在执行任务过程中,如果遇到弹窗或广告,请尝试关闭它们。
常见的关闭按钮通常位于弹窗的右上角,或者有"关闭"、"稍后"、"取消"等文字。
"""
# 将弹窗处理指令添加到任务中
full_task = popup_handling + "\n\n" + scraping_task
# 执行抓取任务
result = agent.run(full_task, llm=llm)
步骤4:优化抓取效率
在抓取大量数据时,可以采用分页抓取策略提高效率:
python# 分页抓取函数
def scrape_multiple_pages(base_task, page_count=3):
all_results = []
for page in range(1, page_count + 1):
page_task = f"{base_task}\n\n当前抓取第{page}页数据。抓取完当前页后,请点击下一页按钮继续。"
# 仅在第一页时启动新浏览器会话
if page == 1:
result = agent.run(page_task, llm=llm)
else:
# 后续页面使用已打开的会话
result = agent.run(page_task, llm=llm, new_session=False)
try:
page_data = json.loads(result)
all_results.extend(page_data)
print(f"已成功抓取第{page}页数据,共{len(page_data)}条记录")
except:
print(f"抓取第{page}页时出现问题")
return all_results
# 使用分页抓取函数
products = scrape_multiple_pages(scraping_task, page_count=3)

高级功能:自适应数据结构抓取
Browser Use与传统爬虫工具最大的区别在于它能够自动适应不同网站的结构。以下是一个通用抓取模板,可以应用于任何网站:
python# 通用抓取模板
def universal_scraper(website_url, data_description):
scraping_template = f"""
访问网站 {website_url}
请提取以下数据:
{data_description}
如果网站需要登录或有验证码,请告知无法完成任务。
如果遇到弹窗,请尝试关闭。
将所有数据以JSON格式返回,确保格式正确可解析。
"""
return agent.run(scraping_template, llm=llm)
# 使用示例
job_data = universal_scraper(
"https://www.zhipin.com/web/geek/job?query=Python",
"""
从这个招聘网站提取以下信息:
1. 职位名称
2. 公司名称
3. 薪资范围
4. 工作地点
5. 工作经验要求
提取前10个职位信息。
"""
)
⚠️ 重要提示:使用网页抓取功能时,请遵守网站的使用条款和robots.txt规则,避免过于频繁的请求,以免对目标网站造成压力或被封禁IP。
【方法三】使用Browser Use实现表单自动填写和提交
在自动化流程中,表单填写是最常见的任务之一。Browser Use因其理解网页结构的能力,可以智能地识别表单字段并准确填写,大大简化了表单自动化流程。
步骤1:设置表单自动填写代理
首先,我们需要创建一个专门用于表单自动化的代理:
python# form_automation.py
from browser_use import WebAgent
from langchain.llms import OpenAI
import config
# 配置OpenAI API (通过laozhang.ai中转)
llm = OpenAI(
api_key=config.LAOZHANG_API_KEY,
base_url=config.LAOZHANG_API_BASE,
model_name="gpt-4o",
temperature=0
)
# 创建Web代理,表单填写通常需要看到操作过程,故禁用headless模式
agent = WebAgent(
browser_type=config.BROWSER_TYPE,
headless=False,
timeout=30000,
slow_mo=100 # 放慢操作速度(毫秒),便于观察
)
步骤2:编写表单填写指令
以注册表单为例,我们可以设计一个智能填写任务:
python# 定义表单数据
form_data = {
"用户名": "test_user_2025",
"邮箱": "[email protected]",
"密码": "SecurePassword123!",
"确认密码": "SecurePassword123!",
"手机号": "13800138000",
"城市": "北京",
"职业": "软件开发"
}
# 将表单数据转换为任务描述
form_task = f"""
访问网站 https://your-target-website.com/register
填写注册表单,使用以下信息:
- 用户名: {form_data["用户名"]}
- 邮箱: {form_data["邮箱"]}
- 密码: {form_data["密码"]}
- 确认密码: {form_data["确认密码"]}
- 手机号: {form_data["手机号"]}
- 城市: {form_data["城市"]}
- 职业: {form_data["职业"]}
填写完成后提交表单,但不要实际点击最终提交按钮(仅用于测试)。
如果有验证码或人机验证,请告知但不要尝试解决。
"""
# 执行表单填写任务
result = agent.run(form_task, llm=llm)
print(result)
步骤3:处理高级表单元素
复杂表单常包含下拉菜单、日期选择器、文件上传等元素,以下是处理这些元素的增强版代理:
python# 增强表单任务指令,处理特殊元素
advanced_form_task = f"""
访问网站 https://your-target-website.com/complex-form
填写表单,按以下说明处理各类型输入:
1. 文本输入:
- 姓名: 张三
- 描述: 这是一段测试描述文字
2. 下拉菜单:
- 在"性别"下拉菜单中选择"男"
- 在"职业"下拉菜单中选择"IT/互联网"
3. 单选按钮:
- 在"年龄段"选项中选择"25-35岁"
4. 复选框:
- 勾选"同意服务条款"
- 勾选"接收活动通知"
5. 日期选择:
- 选择生日为"1990-01-01"
对于每个元素,请先尝试找到对应标签,再进行操作。
如果某个元素无法找到或操作,请跳过并在结果中说明。
"""
# 执行复杂表单填写任务
result = agent.run(advanced_form_task, llm=llm)
步骤4:创建通用表单填写器
我们可以进一步将表单填写功能封装为一个通用工具,适用于各种网站:
pythondef form_filler(url, form_fields, form_description="", submit=False):
"""
通用表单填写函数
参数:
- url: 表单页面URL
- form_fields: 字典,键为字段标签/描述,值为要填入的内容
- form_description: 可选,表单的额外描述信息
- submit: 是否提交表单
返回:
- 执行结果
"""
# 构建字段说明
fields_text = "\n".join([f"- {key}: {value}" for key, value in form_fields.items()])
# 构建表单任务
form_task = f"""
访问网站 {url}
{form_description}
请填写以下信息:
{fields_text}
{"填写完成后,点击提交按钮。" if submit else "填写完成后,不要提交表单,仅显示填写结果。"}
如果遇到验证码或其他人机验证,请告知但不要尝试解决。
"""
return agent.run(form_task, llm=llm)
使用示例:自动填写调查问卷
python# 示例:填写调查问卷
survey_result = form_filler(
url="https://docs.google.com/forms/d/e/your-form-id/viewform",
form_description="这是一份关于用户体验的调查问卷",
form_fields={
"您的年龄": "30",
"您的职业": "软件工程师",
"您每天使用手机的时间": "3-5小时",
"您最常用的社交媒体": "微信",
"您对我们产品的满意度(1-5分)": "5",
"您的建议或反馈": "产品功能丰富,但界面可以更简洁一些。"
},
submit=True
)

高级应用:多步骤表单处理
在很多实际场景中,表单提交是一个多步骤的流程。以下是处理多步表单的方法:
pythondef multi_step_form_processor(url, steps):
"""
处理多步骤表单
参数:
- url: 起始页URL
- steps: 列表,每个元素是字典,包含每一步的描述和表单字段
返回:
- 最终执行结果
"""
# 访问起始页
agent.new_session()
agent.goto(url)
results = []
# 处理每一步
for i, step in enumerate(steps):
step_task = f"""
当前正在处理表单的第{i+1}步,共{len(steps)}步。
步骤描述: {step.get('description', '')}
请填写以下字段:
"""
fields = step.get('fields', {})
step_task += "\n".join([f"- {key}: {value}" for key, value in fields.items()])
if i < len(steps) - 1:
step_task += "\n\n填写完成后,点击下一步按钮继续。"
else:
step_task += "\n\n这是最后一步,填写完成后点击提交按钮。"
# 执行当前步骤
result = agent.run(step_task, llm=llm, new_session=False)
results.append(result)
return results
💡 专业提示:对于需要登录的网站,可以先自动完成登录流程,然后再执行后续的表单操作。Browser Use能够维持浏览器会话,使多步骤操作更加顺畅。
【方法四】Browser Use实现网站登录和会话管理
很多自动化任务需要先完成登录,而会话管理是确保长时间任务稳定执行的关键。Browser Use提供了强大的会话管理功能,让登录状态保持并用于后续操作。
步骤1:配置会话持久化
首先,我们需要设置会话持久化,确保登录状态能够保持:
python# login_session.py
from browser_use import WebAgent
from langchain.llms import OpenAI
import config
import os
import json
# 配置OpenAI API (通过laozhang.ai中转)
llm = OpenAI(
api_key=config.LAOZHANG_API_KEY,
base_url=config.LAOZHANG_API_BASE,
model_name="gpt-4o",
temperature=0
)
# 定义会话存储路径
USER_DATA_DIR = "./browser_sessions"
os.makedirs(USER_DATA_DIR, exist_ok=True)
# 创建支持会话持久化的Web代理
agent = WebAgent(
browser_type=config.BROWSER_TYPE,
headless=False,
user_data_dir=USER_DATA_DIR # 启用会话持久化
)
步骤2:编写登录流程
下面我们实现一个通用的登录流程,可以应用于大多数网站:
pythondef login_to_website(url, username, password, username_selector="", password_selector=""):
"""
登录到指定网站
参数:
- url: 登录页面URL
- username: 用户名/邮箱
- password: 密码
- username_selector: 可选,用户名输入框的选择器
- password_selector: 可选,密码输入框的选择器
返回:
- 登录结果
"""
# 构建登录任务
login_task = f"""
访问网站 {url}
执行登录操作,使用以下凭据:
- 用户名/邮箱: {username}
- 密码: {password}
{"如果能找到用户名输入框,其选择器为: " + username_selector if username_selector else ""}
{"如果能找到密码输入框,其选择器为: " + password_selector if password_selector else ""}
请执行以下步骤:
1. 找到登录页面上的用户名/邮箱输入框并输入
2. 找到密码输入框并输入
3. 点击登录按钮
4. 等待页面加载完成,确认是否登录成功
如果登录成功,请返回SUCCESS和成功后的页面URL。
如果登录失败,请返回ERROR和错误信息。
如果遇到验证码,请返回CAPTCHA。
"""
return agent.run(login_task, llm=llm)
步骤3:验证登录状态与会话保存
登录后,我们需要验证登录状态并保存会话信息:
pythondef verify_and_save_session(website_name, login_result):
"""
验证登录状态并保存会话信息
参数:
- website_name: 网站名称,用于标识会话
- login_result: 登录操作的返回结果
返回:
- 验证结果
"""
# 检查登录是否成功
if "SUCCESS" in login_result:
# 保存会话信息
session_info = {
"website": website_name,
"status": "logged_in",
"timestamp": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
"user_data_dir": USER_DATA_DIR
}
# 保存到会话文件
with open(f"{USER_DATA_DIR}/{website_name}_session.json", "w") as f:
json.dump(session_info, f)
print(f"成功登录到{website_name}并保存会话信息")
return True
else:
print(f"登录{website_name}失败: {login_result}")
return False
步骤4:使用已保存会话执行任务
登录成功后,我们可以使用保存的会话执行后续任务:
pythondef use_saved_session(website_name, task_description):
"""
使用已保存的会话执行任务
参数:
- website_name: 网站名称,用于加载对应会话
- task_description: 要执行的任务描述
返回:
- 任务执行结果
"""
# 检查会话是否存在
session_file = f"{USER_DATA_DIR}/{website_name}_session.json"
if not os.path.exists(session_file):
print(f"未找到{website_name}的已保存会话")
return None
# 加载会话信息
with open(session_file, "r") as f:
session_info = json.load(f)
# 确认会话状态
if session_info.get("status") != "logged_in":
print(f"{website_name}会话状态异常")
return None
# 使用已保存会话创建代理
agent = WebAgent(
browser_type=config.BROWSER_TYPE,
headless=False,
user_data_dir=session_info.get("user_data_dir")
)
# 执行任务
print(f"使用已保存的{website_name}会话执行任务...")
return agent.run(task_description, llm=llm)
使用示例:登录后执行特定任务
python# 示例:登录到GitHub并获取通知
# 第一步:登录
login_result = login_to_website(
url="https://github.com/login",
username="your_github_username",
password="your_github_password"
)
# 第二步:验证并保存会话
if verify_and_save_session("github", login_result):
# 第三步:使用保存的会话执行任务
notifications_task = """
导航到GitHub通知页面(https://github.com/notifications)
获取所有未读通知的列表,包括:
1. 通知标题
2. 相关仓库
3. 通知类型(issue, PR等)
将结果以JSON格式返回。
"""
notifications = use_saved_session("github", notifications_task)
print(notifications)
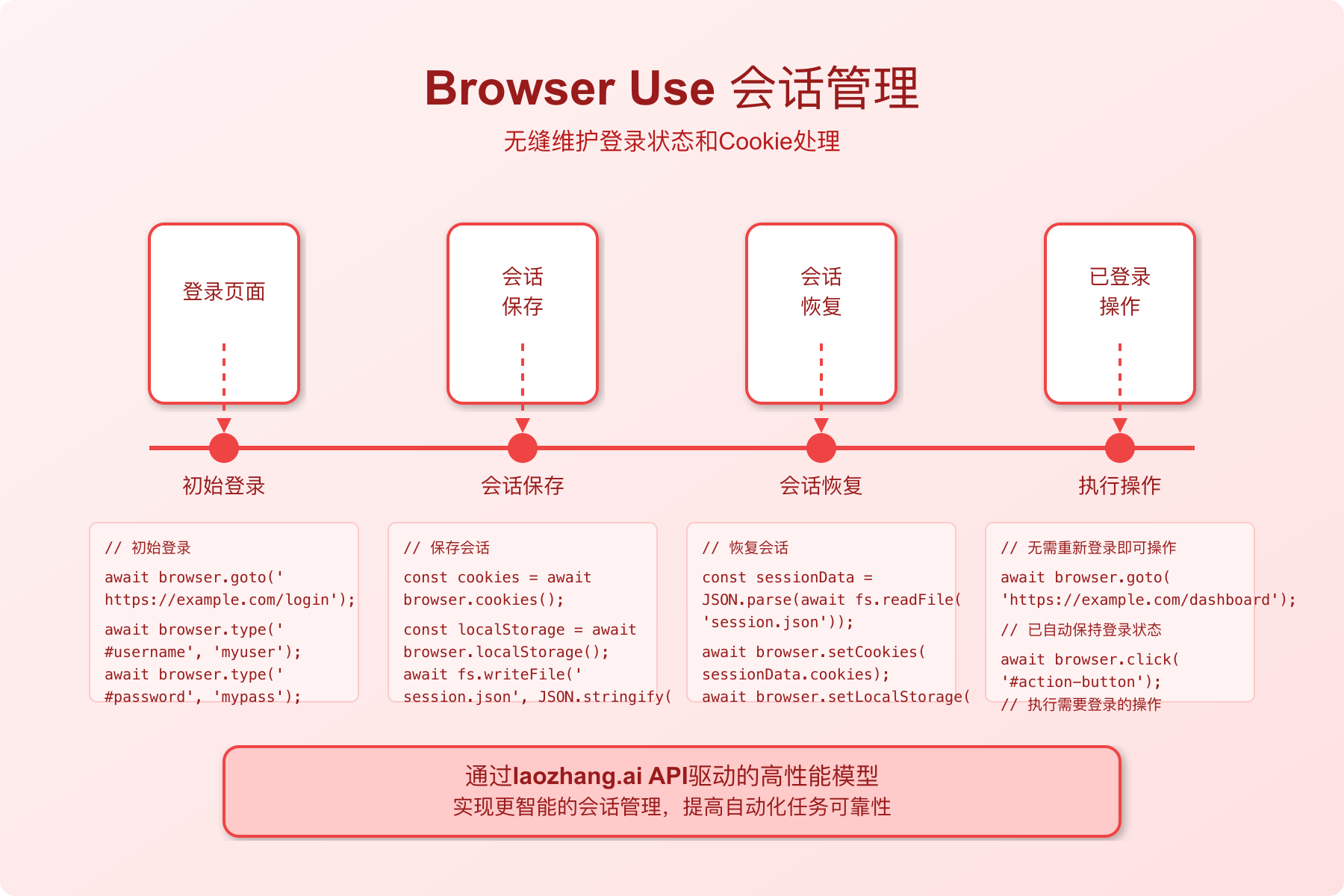
高级功能:会话有效性检查和自动重新登录
在长时间运行的自动化任务中,会话可能会过期。以下是自动检查会话有效性并在需要时重新登录的功能:
pythondef ensure_valid_session(website_config):
"""
确保会话有效,如果无效则重新登录
参数:
- website_config: 包含网站登录信息的字典
{
"name": "网站名称",
"login_url": "登录页面URL",
"username": "用户名",
"password": "密码",
"check_url": "验证会话有效性的URL",
"check_element": "登录状态的元素选择器"
}
返回:
- 有效的会话代理
"""
# 尝试使用现有会话
session_file = f"{USER_DATA_DIR}/{website_config['name']}_session.json"
if os.path.exists(session_file):
# 加载会话
with open(session_file, "r") as f:
session_info = json.load(f)
# 创建代理
agent = WebAgent(
browser_type=config.BROWSER_TYPE,
headless=False,
user_data_dir=session_info.get("user_data_dir")
)
# 检查会话是否有效
check_task = f"""
访问 {website_config['check_url']}
检查是否能找到元素 "{website_config['check_element']}"
如果能找到,返回"SESSION_VALID"
如果找不到,返回"SESSION_INVALID"
"""
check_result = agent.run(check_task, llm=llm)
if "SESSION_VALID" in check_result:
print(f"{website_config['name']}会话有效")
return agent
# 如果没有有效会话,执行登录
print(f"需要登录到{website_config['name']}")
login_result = login_to_website(
url=website_config['login_url'],
username=website_config['username'],
password=website_config['password']
)
if verify_and_save_session(website_config['name'], login_result):
# 创建新的代理
agent = WebAgent(
browser_type=config.BROWSER_TYPE,
headless=False,
user_data_dir=USER_DATA_DIR
)
return agent
else:
raise Exception(f"无法登录到{website_config['name']}")
⚠️ 安全提示:在实际应用中,请勿在代码中硬编码敏感信息如用户名和密码。建议使用环境变量或安全的密钥管理服务来存储这些信息。
【方法五】使用Browser Use Web UI实现零代码浏览器自动化
对于非技术用户来说,编写Python代码可能有一定难度。幸运的是,Browser Use提供了Web UI界面,让你无需编写代码也能使用AI浏览器代理。
步骤1:安装Browser Use Web UI
Browser Use Web UI是一个基于浏览器的图形界面,安装相当简单:
bash# 安装Browser Use Web UI
pip install browser-use-web-ui
# 安装依赖
pip install browser-use langchain playwright
安装Playwright浏览器:
bashplaywright install
步骤2:配置环境变量
在启动Web UI前,你需要设置环境变量,特别是API密钥:
bash# Linux/Mac
export OPENAI_API_KEY=sk-your-laozhang-api-key
export OPENAI_API_BASE=https://api.laozhang.ai/v1
# Windows (CMD)
set OPENAI_API_KEY=sk-your-laozhang-api-key
set OPENAI_API_BASE=https://api.laozhang.ai/v1
# Windows (PowerShell)
$env:OPENAI_API_KEY="sk-your-laozhang-api-key"
$env:OPENAI_API_BASE="https://api.laozhang.ai/v1"
步骤3:启动Web UI
配置完成后,启动Web UI服务器:
bashbrowser-use-web-ui
启动后,Web UI将在本地运行,通常在http://localhost:3000上可访问。

步骤4:通过Web UI使用Browser Use
通过Web UI使用Browser Use非常直观:
- 打开浏览器访问
http://localhost:3000 - 在"任务描述"文本框中输入你想要执行的任务
- 选择要使用的LLM模型(如GPT-4o)
- 点击"运行"按钮开始任务
- 观察浏览器自动执行任务并返回结果
Web UI的高级设置
Web UI提供了多种高级设置选项:
- 模型选择:可选择不同的LLM模型,如GPT-4o、Claude等
- 浏览器类型:选择Chrome、Firefox或Safari
- 可见性控制:决定是否显示浏览器窗口
- 操作速度:调整浏览器操作的速度
- 会话管理:允许保存和恢复会话
- 保存历史:记录所有执行过的任务及其结果
在Web UI中保存和重用任务模板
Web UI一个实用功能是可以保存常用任务模板:
- 执行一个任务后,点击"保存为模板"按钮
- 输入模板名称和描述
- 之后可以从"模板库"中加载这些保存的任务
这对于经常需要执行的标准任务非常有用,如数据抓取或表单填写。
Web UI的限制与注意事项
尽管Web UI极大简化了使用流程,但也有一些限制:
- 功能相比Python API稍受限制
- 无法执行复杂的条件逻辑和自定义处理
- 受限于浏览器的安全策略
- 无法直接访问本地文件系统(除上传文件外)
💡 专业提示:如果你需要在团队内部共享Browser Use功能,可以将Web UI部署到服务器上,并设置访问控制,让多个用户通过浏览器使用AI代理功能。
Docker部署Web UI
对于团队使用,可以通过Docker部署Web UI:
bash# 拉取Docker镜像
docker pull browseruse/web-ui:latest
# 运行容器
docker run -p 3000:3000 \
-e OPENAI_API_KEY=sk-your-laozhang-api-key \
-e OPENAI_API_BASE=https://api.laozhang.ai/v1 \
browseruse/web-ui:latest
Web UI与Python API结合使用
对于某些复杂场景,可以将Web UI与Python API结合使用:
- 使用Web UI快速验证和调试任务
- 将成功的任务导出为Python代码
- 在Python脚本中进一步定制和自动化
Web UI提供了"导出为Python"功能,可以将任务转换为完整的Python脚本,便于进一步开发。
【方法六】自定义工具扩展Browser Use能力
Browser Use的强大之处在于它的可扩展性。通过自定义工具,我们可以为Browser Use添加新功能,使其能够处理更复杂的任务。
步骤1:了解Browser Use的工具系统
Browser Use使用工具(Tools)机制来扩展功能。每个工具是一个Python函数,可以被LLM代理调用来执行特定操作:
python# custom_tools.py
from browser_use import WebAgent, Tool
from langchain.llms import OpenAI
import config
import requests
import json
import os
from datetime import datetime
# 配置OpenAI API (通过laozhang.ai中转)
llm = OpenAI(
api_key=config.LAOZHANG_API_KEY,
base_url=config.LAOZHANG_API_BASE,
model_name="gpt-4o",
temperature=0
)
步骤2:创建自定义工具
现在,我们来创建一些有用的自定义工具:
python# 1. 截图保存工具
def save_screenshot(agent, element_selector=None, filename=None):
"""
截取当前页面或特定元素的截图并保存
参数:
- agent: WebAgent实例
- element_selector: 可选,要截图的元素选择器
- filename: 可选,文件保存路径,默认为timestamped_screenshot.png
返回:
- 保存的文件路径
"""
if filename is None:
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = f"screenshot_{timestamp}.png"
# 确保截图目录存在
os.makedirs("screenshots", exist_ok=True)
filepath = os.path.join("screenshots", filename)
if element_selector:
# 截取特定元素
element = agent.page.query_selector(element_selector)
if element:
element.screenshot(path=filepath)
else:
agent.page.screenshot(path=filepath)
return f"未找到元素{element_selector},已截取整个页面。保存到: {filepath}"
else:
# 截取整个页面
agent.page.screenshot(path=filepath)
return f"截图已保存到: {filepath}"
# 2. API调用工具
def call_external_api(agent, api_url, method="GET", data=None, headers=None):
"""
调用外部API并返回结果
参数:
- agent: WebAgent实例
- api_url: API端点URL
- method: 请求方法,默认GET
- data: 可选,请求数据
- headers: 可选,请求头
返回:
- API响应结果
"""
if headers is None:
headers = {"Content-Type": "application/json"}
try:
if method.upper() == "GET":
response = requests.get(api_url, headers=headers)
elif method.upper() == "POST":
response = requests.post(api_url, json=data, headers=headers)
elif method.upper() == "PUT":
response = requests.put(api_url, json=data, headers=headers)
elif method.upper() == "DELETE":
response = requests.delete(api_url, headers=headers)
else:
return f"不支持的HTTP方法: {method}"
# 尝试解析JSON响应
try:
return response.json()
except:
return response.text
except Exception as e:
return f"API调用失败: {str(e)}"
# 3. 数据处理工具
def process_extracted_data(agent, data, operation):
"""
处理从网页提取的数据
参数:
- agent: WebAgent实例
- data: 要处理的数据(字典或列表)
- operation: 处理操作,如"filter", "sort", "group", "calculate"
返回:
- 处理后的数据
"""
if operation == "filter":
# 示例:过滤价格>100的商品
return [item for item in data if float(item.get("price", 0)) > 100]
elif operation == "sort":
# 示例:按价格排序
return sorted(data, key=lambda item: float(item.get("price", 0)))
elif operation == "calculate":
# 示例:计算平均价格
prices = [float(item.get("price", 0)) for item in data]
return sum(prices) / len(prices) if prices else 0
elif operation == "group":
# 示例:按分类分组
groups = {}
for item in data:
category = item.get("category", "未分类")
if category not in groups:
groups[category] = []
groups[category].append(item)
return groups
else:
return f"不支持的操作: {operation}"
步骤3:注册自定义工具
将自定义工具注册到WebAgent实例:
python# 创建Web代理
agent = WebAgent(
browser_type=config.BROWSER_TYPE,
headless=False
)
# 注册自定义工具
agent.register_tool(
Tool(
name="save_screenshot",
description="保存当前网页或特定元素的截图",
function=save_screenshot
)
)
agent.register_tool(
Tool(
name="call_api",
description="调用外部API获取数据",
function=call_external_api
)
)
agent.register_tool(
Tool(
name="process_data",
description="处理和分析抓取的数据",
function=process_extracted_data
)
)
步骤4:使用自定义工具
现在可以在任务中使用这些自定义工具:
python# 使用自定义工具的任务示例
task_with_tools = """
访问京东网站(www.jd.com),搜索"笔记本电脑"。
1. 提取前10个商品的信息,包括名称、价格、评论数和店铺名
2. 使用process_data工具按价格排序
3. 对最贵的商品详情页进行截图,保存为"expensive_laptop.png"
4. 调用API将数据发送到我们的服务器(https://api.example.com/products)
请在执行每一步操作后提供详细反馈。
"""
# 执行任务
result = agent.run(task_with_tools, llm=llm)
print(result)
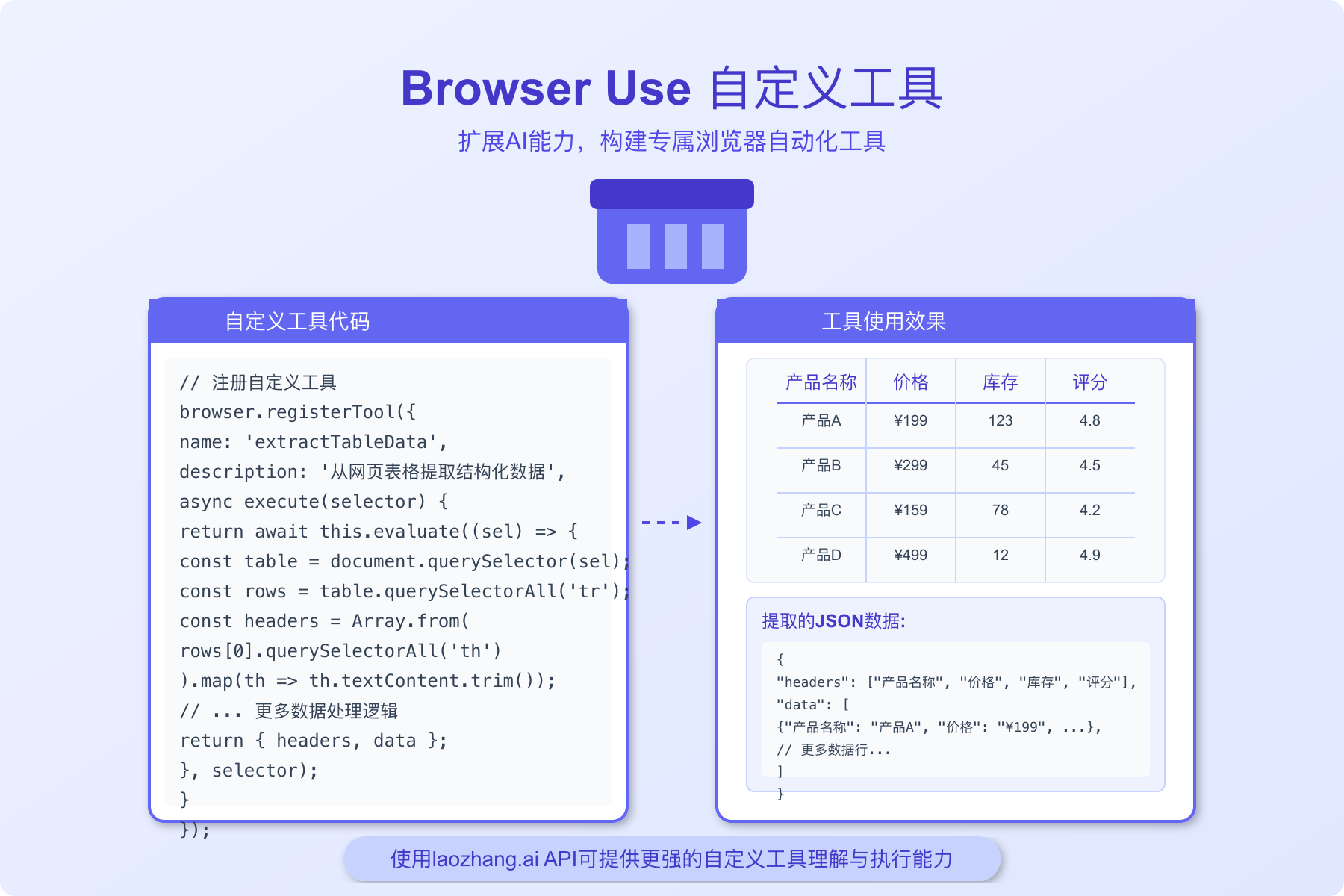
高级自定义工具示例
以下是一些更高级的自定义工具示例,可以大幅扩展Browser Use的能力:
1. PDF处理工具
pythondef extract_pdf_content(agent, pdf_url=None):
"""从PDF中提取文本内容"""
import PyPDF2
import io
import requests
if pdf_url:
# 下载PDF
response = requests.get(pdf_url)
pdf_content = io.BytesIO(response.content)
else:
# 尝试从当前页面下载PDF
current_url = agent.page.url
if current_url.endswith('.pdf'):
response = requests.get(current_url)
pdf_content = io.BytesIO(response.content)
else:
return "当前页面不是PDF,请提供PDF URL"
# 提取文本
reader = PyPDF2.PdfReader(pdf_content)
text = ""
for page in reader.pages:
text += page.extract_text() + "\n"
return text
2. 数据导出工具
pythondef export_data_to_excel(agent, data, filename="exported_data.xlsx"):
"""将数据导出为Excel文件"""
import pandas as pd
# 确保导出目录存在
os.makedirs("exports", exist_ok=True)
filepath = os.path.join("exports", filename)
# 转换为DataFrame并导出
df = pd.DataFrame(data)
df.to_excel(filepath, index=False)
return f"数据已导出到: {filepath}"
3. 网页内容翻译工具
pythondef translate_page_content(agent, source_lang="auto", target_lang="zh-CN"):
"""翻译当前页面内容"""
from deep_translator import GoogleTranslator
# 获取页面文本内容
page_text = agent.page.evaluate("() => document.body.innerText")
# 翻译内容
translator = GoogleTranslator(source=source_lang, target=target_lang)
# 分块翻译(避免超出翻译API限制)
chunks = [page_text[i:i+4900] for i in range(0, len(page_text), 4900)]
translated_chunks = [translator.translate(chunk) for chunk in chunks]
return "".join(translated_chunks)
💡 专业提示:自定义工具是扩展Browser Use能力的最佳方式。通过结合外部API、数据处理库和其他Python功能,你可以创建几乎无限的自动化可能性。使用laozhang.ai中转API服务可以显著降低开发和测试这些自定义工具的成本。
【方法七】多浏览器代理协作完成复杂任务
处理更复杂的自动化任务时,可能需要同时操作多个浏览器或跨多个页面工作。Browser Use支持多代理协作模式,大幅提升处理复杂场景的能力。
步骤1:设置多代理环境
首先,我们创建一个基础设置,支持多个Browser Use代理实例:
python# multi_agent.py
from browser_use import WebAgent
from langchain.llms import OpenAI
import config
import json
import os
from datetime import datetime
import threading
import queue
# 配置OpenAI API (通过laozhang.ai中转)
llm = OpenAI(
api_key=config.LAOZHANG_API_KEY,
base_url=config.LAOZHANG_API_BASE,
model_name="gpt-4o",
temperature=0
)
# 创建代理管理器
class MultiAgentManager:
def __init__(self, max_agents=3):
self.agents = {}
self.max_agents = max_agents
self.results_queue = queue.Queue()
def create_agent(self, agent_id, browser_type="chromium", headless=False):
"""创建新的代理实例"""
if len(self.agents) >= self.max_agents:
raise Exception(f"已达到最大代理数量限制: {self.max_agents}")
if agent_id in self.agents:
raise Exception(f"代理ID '{agent_id}' 已存在")
agent = WebAgent(
browser_type=browser_type,
headless=headless
)
self.agents[agent_id] = agent
return agent
def get_agent(self, agent_id):
"""获取现有代理实例"""
return self.agents.get(agent_id)
def run_task(self, agent_id, task, async_mode=False):
"""运行任务,可选异步模式"""
agent = self.get_agent(agent_id)
if not agent:
raise Exception(f"代理ID '{agent_id}' 不存在")
if async_mode:
# 异步执行任务
thread = threading.Thread(
target=self._run_async_task,
args=(agent_id, agent, task)
)
thread.start()
return f"任务已在代理 '{agent_id}' 上异步启动"
else:
# 同步执行任务
return agent.run(task, llm=llm)
def _run_async_task(self, agent_id, agent, task):
"""内部方法:在线程中执行任务并将结果加入队列"""
try:
result = agent.run(task, llm=llm)
self.results_queue.put({
"agent_id": agent_id,
"status": "success",
"result": result
})
except Exception as e:
self.results_queue.put({
"agent_id": agent_id,
"status": "error",
"error": str(e)
})
def get_results(self, block=False, timeout=None):
"""获取异步任务结果"""
try:
return self.results_queue.get(block=block, timeout=timeout)
except queue.Empty:
return None
def close_agent(self, agent_id):
"""关闭并移除代理"""
agent = self.get_agent(agent_id)
if agent:
agent.close()
del self.agents[agent_id]
return f"代理 '{agent_id}' 已关闭"
return f"代理 '{agent_id}' 不存在"
def close_all(self):
"""关闭所有代理"""
for agent_id in list(self.agents.keys()):
self.close_agent(agent_id)
return "所有代理已关闭"
步骤2:创建多代理协作任务
现在,我们使用多代理管理器创建和管理多个Browser Use实例:
python# 创建多代理管理器
manager = MultiAgentManager(max_agents=3)
# 创建并配置多个代理
agent1 = manager.create_agent("search_agent", browser_type="chromium")
agent2 = manager.create_agent("data_agent", browser_type="firefox")
agent3 = manager.create_agent("verification_agent", browser_type="webkit")
步骤3:分配协作任务
我们可以为不同代理分配不同任务,实现并行处理:
python# 定义各代理的任务
search_task = """
访问百度(www.baidu.com),搜索"最新笔记本电脑2025"。
获取搜索结果第一页的所有笔记本电脑产品名称和链接。
返回JSON格式的结果列表。
"""
data_collection_task = """
访问京东(www.jd.com),搜索"笔记本电脑"。
获取前5个产品的详细信息,包括价格、配置和评价数量。
返回JSON格式的结果。
"""
verification_task = """
访问中关村在线(www.zol.com.cn),搜索"笔记本电脑排行"。
获取最新的笔记本电脑排名前10名的列表。
返回JSON格式的结果。
"""
# 异步执行所有任务
manager.run_task("search_agent", search_task, async_mode=True)
manager.run_task("data_agent", data_collection_task, async_mode=True)
manager.run_task("verification_agent", verification_task, async_mode=True)
步骤4:收集和整合结果
当所有代理完成任务后,我们收集并整合结果:
python# 收集所有代理的结果
all_results = {}
for _ in range(3): # 我们知道有3个任务
result = manager.get_results(block=True) # 阻塞等待结果
all_results[result["agent_id"]] = result
print(f"收到来自 {result['agent_id']} 的结果: {result['status']}")
# 整合所有结果
if all([r["status"] == "success" for r in all_results.values()]):
try:
# 解析各代理返回的JSON数据
search_data = json.loads(all_results["search_agent"]["result"])
jd_data = json.loads(all_results["data_agent"]["result"])
zol_data = json.loads(all_results["verification_agent"]["result"])
# 综合分析(这里可以添加更复杂的数据分析逻辑)
combined_data = {
"search_results": search_data,
"pricing_data": jd_data,
"rankings": zol_data
}
# 保存综合结果
with open("laptop_market_research.json", "w", encoding="utf-8") as f:
json.dump(combined_data, f, ensure_ascii=False, indent=2)
print("所有数据已整合并保存至laptop_market_research.json")
except json.JSONDecodeError:
print("无法解析部分结果为JSON格式")
else:
failed = [k for k, v in all_results.items() if v["status"] != "success"]
print(f"以下代理任务失败: {failed}")
# 关闭所有代理
manager.close_all()
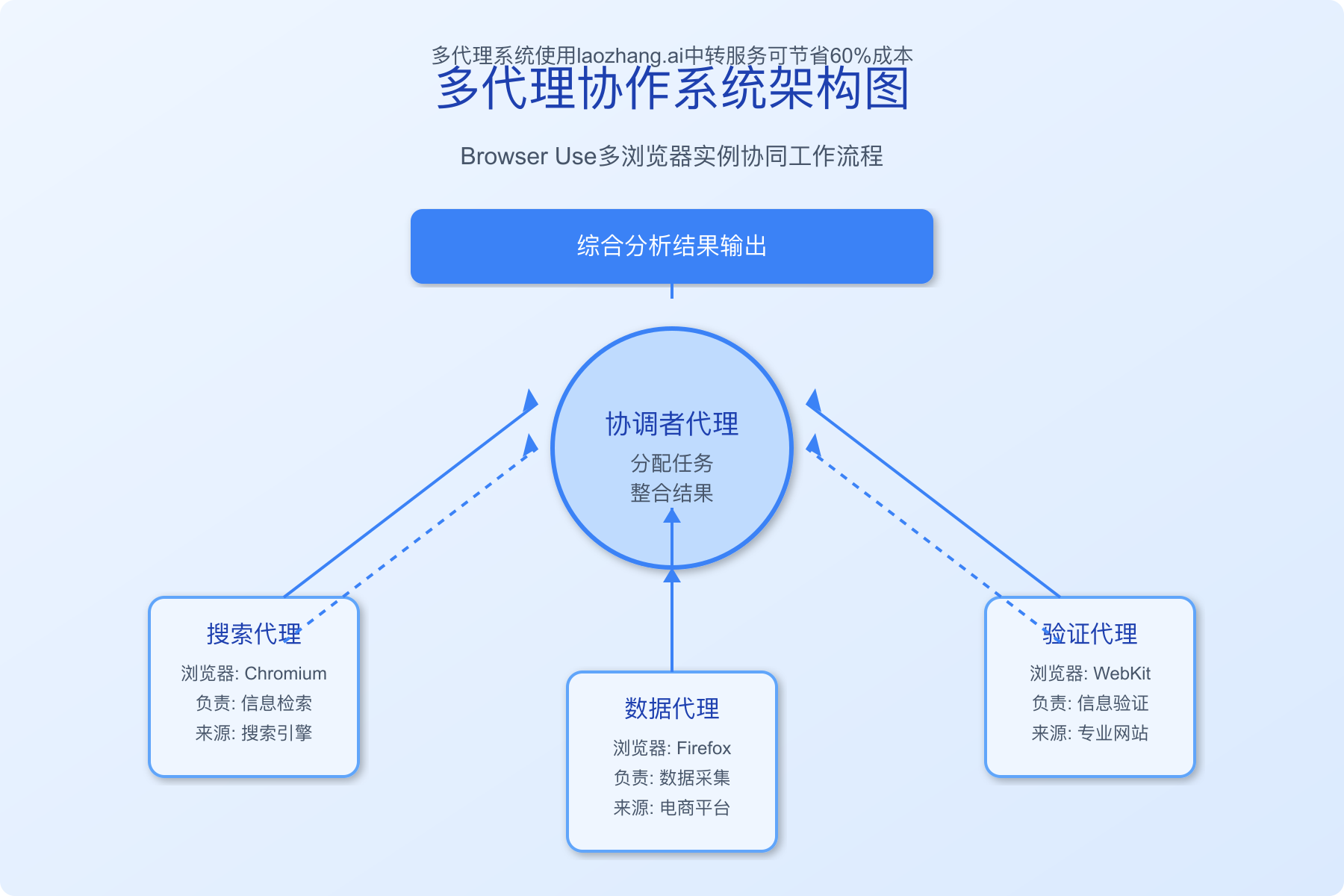
高级应用:具有通信能力的协作代理
让代理彼此传递信息,实现更复杂的协作:
python# 添加代理间通信功能
class CommunicativeMultiAgentManager(MultiAgentManager):
def __init__(self, max_agents=3):
super().__init__(max_agents)
self.message_queues = {}
def create_agent(self, agent_id, browser_type="chromium", headless=False):
"""创建带有消息队列的代理"""
agent = super().create_agent(agent_id, browser_type, headless)
self.message_queues[agent_id] = queue.Queue()
return agent
def send_message(self, from_agent, to_agent, message):
"""从一个代理向另一个代理发送消息"""
if to_agent not in self.agents:
raise Exception(f"目标代理 '{to_agent}' 不存在")
self.message_queues[to_agent].put({
"from": from_agent,
"message": message,
"timestamp": datetime.now().isoformat()
})
return f"消息已发送到代理 '{to_agent}'"
def get_messages(self, agent_id, block=False, timeout=None):
"""获取发送给指定代理的消息"""
if agent_id not in self.message_queues:
raise Exception(f"代理 '{agent_id}' 不存在")
messages = []
try:
while True:
# 非阻塞获取所有可用消息
message = self.message_queues[agent_id].get(block=block, timeout=timeout)
messages.append(message)
if block:
# 如果是阻塞模式,只获取一条消息
break
except queue.Empty:
pass
return messages
协作代理示例:自动化比价系统
使用协作代理创建一个自动比价系统:
python# 创建通信型多代理管理器
comms_manager = CommunicativeMultiAgentManager(max_agents=4)
# 创建专门的代理
coordinator = comms_manager.create_agent("coordinator")
jd_agent = comms_manager.create_agent("jd_agent")
tmall_agent = comms_manager.create_agent("tmall_agent")
suning_agent = comms_manager.create_agent("suning_agent")
# 协调者任务:分配任务并汇总结果
coordinator_task = """
协调多个电商渠道的价格比较。
1. 向其他三个代理发送消息,指示它们搜索以下产品:
- 产品名称: "Apple MacBook Pro 14 M3 Pro"
- 配置要求: "18GB统一内存 + 512GB SSD"
2. 等待所有代理返回结果
3. 综合分析各平台价格,找出最低价格的平台
请将指令发送给jd_agent、tmall_agent和suning_agent。
"""
# 运行协调者任务
comms_manager.run_task("coordinator", coordinator_task, async_mode=True)
# 配置各电商代理接收协调者消息并执行任务
for agent_id in ["jd_agent", "tmall_agent", "suning_agent"]:
# 定义根据消息执行搜索的任务
search_task = f"""
1. 检查是否有来自coordinator的消息
2. 如果有消息,访问对应的电商网站搜索指定产品
- jd_agent: 访问京东网站
- tmall_agent: 访问天猫网站
- suning_agent: 访问苏宁易购网站
3. 获取指定产品的价格、配送信息和促销活动
4. 将结果发送回coordinator
当前代理ID: {agent_id}
"""
comms_manager.run_task(agent_id, search_task, async_mode=True)
# 等待所有任务完成
# ... (此处可添加结果处理代码)
💡 专业提示:多代理协作特别适合数据采集、市场调研、价格监控等需要从多个来源获取信息的场景。使用laozhang.ai中转API可以显著降低多代理系统的运行成本,同时保证全天候稳定访问。
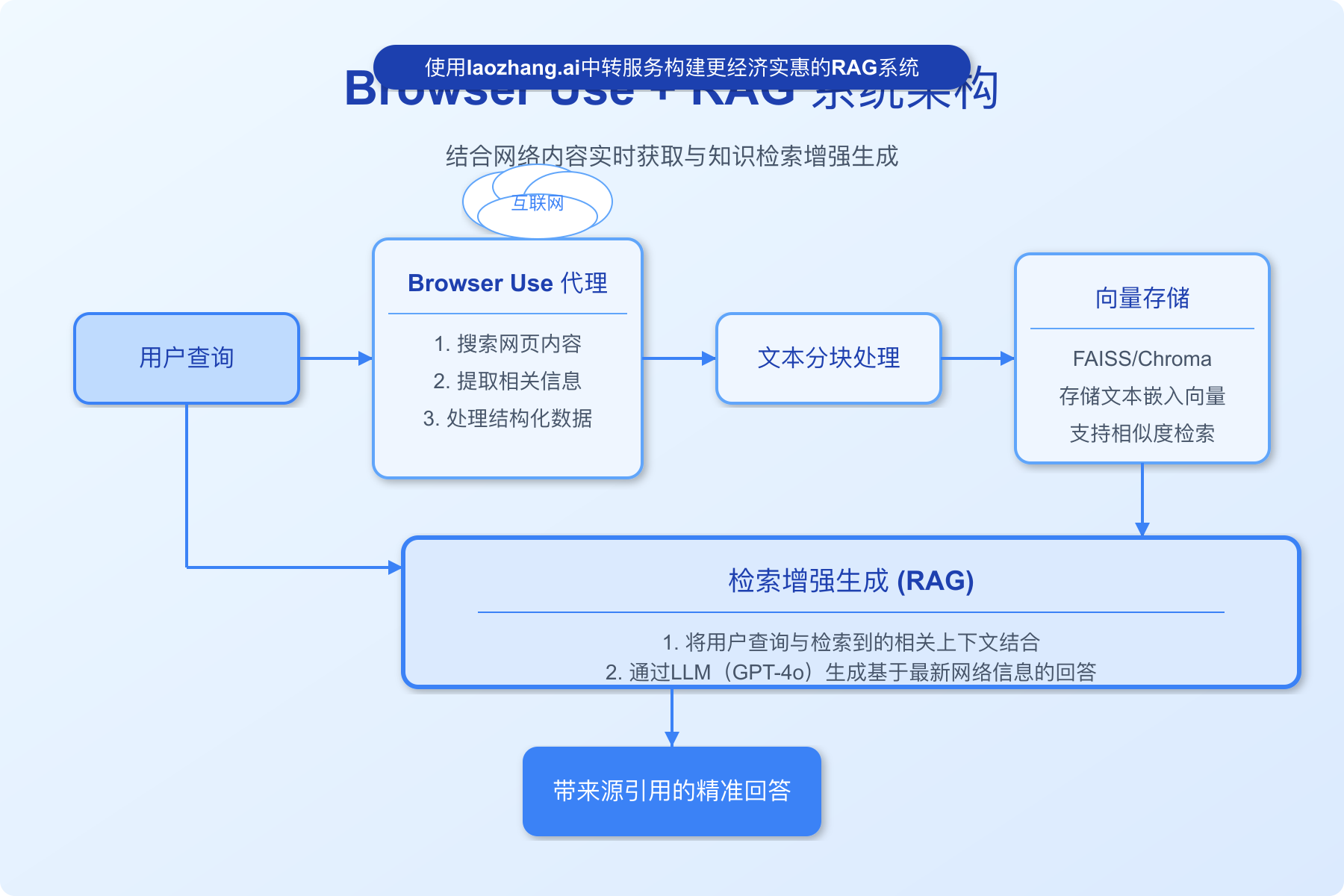
【方法八】Browser Use与RAG系统集成实现智能知识获取
在处理需要最新网络信息的复杂任务时,将Browser Use与检索增强生成(RAG)系统集成可以创建更智能的解决方案,使AI能够基于最新的网络数据生成更精准的回答。
步骤1:设置基础RAG架构
首先,我们需要创建一个基础的RAG系统架构:
python# rag_browser_use.py
from browser_use import WebAgent
from langchain.llms import OpenAI
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
import config
import json
import time
# 配置OpenAI API (通过laozhang.ai中转)
llm = OpenAI(
api_key=config.LAOZHANG_API_KEY,
base_url=config.LAOZHANG_API_BASE,
model_name="gpt-4o",
temperature=0
)
# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50
)
# 初始化向量嵌入模型
embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-small-zh-v1.5",
model_kwargs={'device': 'cpu'}
)
# 创建Browser Use代理
agent = WebAgent(browser_type="chromium", headless=True)
步骤2:实现网页内容获取与处理
创建函数从网页获取内容并处理为知识库:
pythondef fetch_and_process_web_content(search_query, num_results=5):
"""
使用Browser Use获取网页内容并处理为向量存储
"""
# 定义搜索任务
search_task = f"""
1. 访问百度(https://www.baidu.com)
2. 搜索以下关键词: "{search_query}"
3. 获取搜索结果中前{num_results}个非广告链接
4. 对每个链接,访问网页并提取主要内容文本
5. 返回一个JSON对象,包含每个页面的:
- 标题
- URL
- 提取的内容文本(去除广告、导航等无关内容)
"""
# 执行搜索任务
print(f"正在搜索关于 '{search_query}' 的信息...")
result = agent.run(search_task, llm=llm)
try:
# 解析搜索结果
search_results = json.loads(result)
# 提取所有文本内容
all_texts = []
for page in search_results:
content = page.get("content", "")
if content:
# 添加页面元信息到内容开头
content_with_metadata = f"标题: {page.get('title', '无标题')}\nURL: {page.get('url', '无URL')}\n\n{content}"
all_texts.append(content_with_metadata)
# 分割文本
print("正在处理文本...")
all_chunks = []
for text in all_texts:
chunks = text_splitter.split_text(text)
all_chunks.extend(chunks)
# 创建向量存储
print(f"创建向量数据库,共 {len(all_chunks)} 个文本块...")
vector_store = FAISS.from_texts(all_chunks, embeddings)
return vector_store
except Exception as e:
print(f"处理搜索结果时出错: {e}")
return None
步骤3:创建RAG问答接口
创建一个基于RAG的问答系统:
pythondef create_rag_qa_system(vector_store):
"""
创建基于RAG的问答系统
"""
# 创建检索器
retriever = vector_store.as_retriever(
search_type="similarity",
search_kwargs={"k": 5}
)
# 创建问答链
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True
)
return qa_chain
def answer_question(qa_chain, question):
"""
使用RAG系统回答问题
"""
result = qa_chain({"query": question})
# 提取回答和来源
answer = result.get("result", "无法获取回答")
source_docs = result.get("source_documents", [])
# 格式化输出
sources = []
for doc in source_docs:
# 尝试从文本中提取URL
content = doc.page_content
url_match = None
for line in content.split("\n"):
if line.startswith("URL:"):
url_match = line.replace("URL:", "").strip()
break
if url_match:
sources.append(url_match)
return {
"answer": answer,
"sources": list(set(sources)) # 去重
}
步骤4:集成使用示例
下面是一个完整的使用流程示例:
python# 用户查询
topic = "2025年人工智能最新技术趋势"
questions = [
"2025年AI领域的主要发展方向是什么?",
"国内外在生成式AI方面有哪些差异?",
"有哪些值得关注的AI初创公司?"
]
# 获取最新网络内容
vector_store = fetch_and_process_web_content(topic)
if vector_store:
# 创建问答系统
qa_system = create_rag_qa_system(vector_store)
# 回答问题
print("\n=== AI技术趋势问答系统 ===\n")
for i, question in enumerate(questions, 1):
print(f"问题 {i}: {question}")
response = answer_question(qa_system, question)
print(f"回答: {response['answer']}")
if response['sources']:
print("信息来源:")
for url in response['sources']:
print(f"- {url}")
print()
# 关闭浏览器
agent.close()
else:
print("无法创建知识库,请检查搜索结果")
高级应用:实时更新的专业领域知识库
创建一个可定期更新的专业领域知识库:
pythonclass AutoUpdatingKnowledgeBase:
def __init__(self, topics, update_interval_hours=24):
self.topics = topics
self.update_interval_hours = update_interval_hours
self.last_update = 0
self.vector_stores = {}
self.agent = WebAgent(browser_type="chromium", headless=True)
# 配置API
self.llm = OpenAI(
api_key=config.LAOZHANG_API_KEY,
base_url=config.LAOZHANG_API_BASE,
model_name="gpt-4o",
temperature=0
)
def update_knowledge_base(self, force=False):
"""更新知识库"""
current_time = time.time()
elapsed_hours = (current_time - self.last_update) / 3600
if force or self.last_update == 0 or elapsed_hours >= self.update_interval_hours:
print(f"更新知识库中...")
for topic in self.topics:
print(f"更新主题: {topic}")
vector_store = self._fetch_and_process_web_content(topic)
if vector_store:
self.vector_stores[topic] = vector_store
self.last_update = current_time
print(f"知识库更新完成,共处理 {len(self.topics)} 个主题")
return True
else:
print(f"知识库更新间隔未到,距离上次更新已过 {elapsed_hours:.1f} 小时,需要 {self.update_interval_hours} 小时")
return False
def _fetch_and_process_web_content(self, search_query, num_results=7):
"""从网页获取内容并处理"""
# 实现方式与前述函数类似...
# (为简洁起见,此处省略详细实现)
pass
def get_qa_system(self, topic):
"""获取特定主题的问答系统"""
if topic in self.vector_stores:
retriever = self.vector_stores[topic].as_retriever(
search_type="similarity",
search_kwargs={"k": 5}
)
qa_chain = RetrievalQA.from_chain_type(
llm=self.llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True
)
return qa_chain
else:
return None
def answer_question(self, topic, question):
"""回答特定主题的问题"""
qa_system = self.get_qa_system(topic)
if qa_system:
return self._process_qa_result(qa_system({"query": question}))
else:
return {"answer": f"未找到关于'{topic}'的知识库", "sources": []}
def _process_qa_result(self, result):
"""处理问答结果"""
# 实现方式与前述函数类似...
# (为简洁起见,此处省略详细实现)
pass
def close(self):
"""关闭资源"""
if hasattr(self, 'agent') and self.agent:
self.agent.close()
# 使用示例
kb = AutoUpdatingKnowledgeBase([
"2025人工智能技术趋势",
"大语言模型应用案例",
"国内AI政策法规"
])
# 首次更新知识库
kb.update_knowledge_base(force=True)
# 使用知识库回答问题
response = kb.answer_question(
"2025人工智能技术趋势",
"2025年大语言模型有哪些突破性进展?"
)
print(f"回答: {response['answer']}")
# 12小时后自动更新
# time.sleep(12 * 3600)
# kb.update_knowledge_base()
# 完成后关闭
kb.close()
💡 专业提示:将Browser Use与RAG系统集成是构建信息实时性强、回答精准的AI应用的理想方案。对于需要获取最新信息的垂直领域(如金融市场分析、技术趋势研究等),这种方法特别有效。使用laozhang.ai中转API可以显著降低大规模RAG系统的API成本,同时保持响应速度和稳定性。
结论:Browser Use打造智能化未来
我们通过八种方法详细展示了如何使用Browser Use这一强大的浏览器自动化工具。从基础的网页数据采集、表单填写,到高级的多代理协作和RAG系统集成,Browser Use提供了丰富的可能性。
主要优势总结
-
全面的浏览器控制:Browser Use通过LLM代理的方式实现了对浏览器的自然语言控制,无需为每个网站编写特定脚本。
-
灵活的部署选项:可以通过Python API、命令行、Web UI等多种方式使用,适应不同用户的技术水平。
-
强大的扩展能力:通过自定义工具和多代理协作,可以实现复杂的自动化流程,满足各类业务需求。
-
成本效益高:特别是结合laozhang.ai API中转服务,可以显著降低API调用成本,提高性价比。
应用场景
Browser Use在以下场景中表现出色:
- 数据采集与分析:自动化收集网络数据,支持市场研究、竞品分析等工作
- 流程自动化:处理重复性工作如表单填写、帐户管理、订单处理等
- 智能交互:通过多代理协作处理需要多步骤判断的复杂流程
- 知识获取与问答:结合RAG系统创建实时更新的智能问答系统
开发与使用建议
- 从简单案例开始:先掌握基础功能,再逐步尝试复杂场景
- 明确任务描述:给LLM的指令应详细且明确,提高自动化准确性
- 设置适当超时和重试机制:网页加载和处理可能存在延迟
- 定期更新代理配置:跟踪最新的模型和功能更新
- 优先选择稳定API服务:如laozhang.ai提供的中转API服务,保证全天候可用性
Browser Use代表了浏览器自动化的未来发展方向,它将LLM的智能理解能力与浏览器的交互能力相结合,为企业和个人用户提供了前所未有的自动化可能。无论您是开发人员、数据分析师还是业务人员,Browser Use都能为您的工作流程带来显著改进。
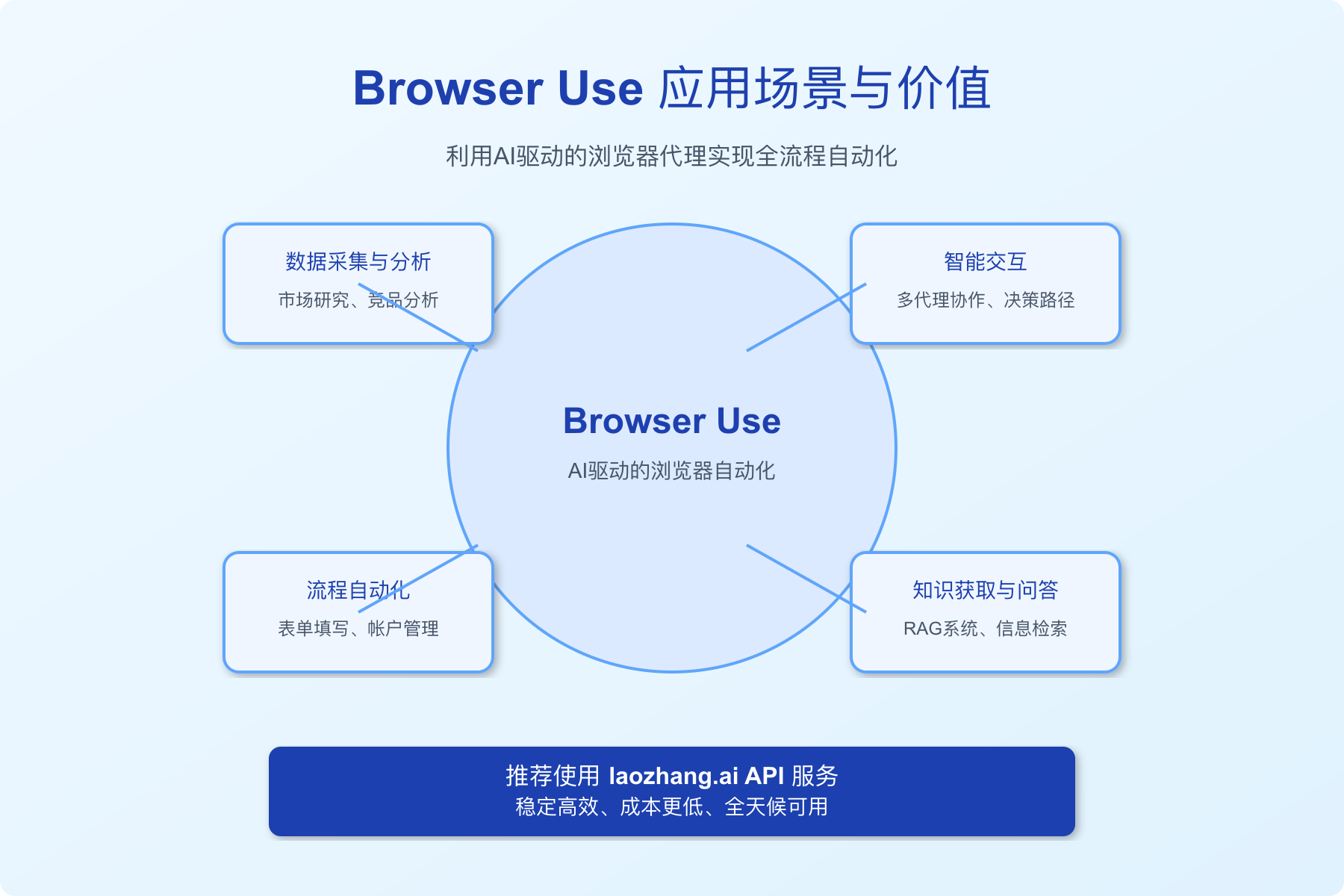
💡 最终提示:Browser Use的强大功能需要高质量的API支持才能充分发挥。推荐使用laozhang.ai API服务,不仅提供稳定高效的API访问,还有更低的调用成本和全天候的技术支持,让您的浏览器自动化之旅更加顺畅。