ChatGPT 4o vs o1 vs o3深度对比:2025年8月最全面选择指南
全面对比ChatGPT 4o、o1、o3三个模型的性能、价格、使用场景。包含最新基准测试数据、API价格对比、实战案例分析,帮助你选择最适合的AI模型。
Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
ChatGPT 4o、o1和o3是OpenAI在2024-2025年推出的三个重要模型系列,各有独特优势。GPT-4o(2024年5月发布)擅长多模态任务,速度快成本低,每百万输入token仅需$2.5;o1(2024年9月发布)专注深度推理,在数学和编程领域表现卓越,AIME数学竞赛准确率达83.3%;o3(2025年1月发布)是最新的推理旗舰,ARC-AGI基准测试得分87.5%,创造了新的性能记录。选择建议:日常对话和内容创作选GPT-4o,复杂推理和专业编程选o1,追求极致推理能力选o3。
一、三大模型概览:定位与特点对比
OpenAI的模型矩阵在2025年8月已经形成了清晰的差异化定位。根据最新的官方数据,这三个模型系列代表了不同的技术路线和应用方向。GPT-4o作为多模态通用模型,延续了GPT-4的全能路线但大幅提升了效率;o1系列开创了"推理优先"的新范式,通过思维链技术实现了质的飞跃;o3则是推理能力的巅峰之作,刷新了多项行业基准。

1.1 GPT-4o:高效的多模态全能选手
GPT-4o("o"代表omni,全能)于2024年5月13日发布,是GPT-4的优化版本。其核心优势在于保持GPT-4级别智能的同时,将速度提升了2倍,成本降低了50%。该模型支持文本、图像、音频、视频等多种输入输出形式,上下文窗口达到128K tokens。在实际应用中,GPT-4o的响应延迟平均仅为320毫秒,接近人类对话速度。其多语言能力也得到显著增强,在处理中文、日文、韩文等非英语语言时的表现提升了约20%。
1.2 o1系列:深度推理的突破者
o1模型(代号"Strawberry")于2024年9月12日首次亮相,标志着OpenAI在推理能力上的重大突破。o1-preview和o1-mini两个版本分别针对不同需求:o1-preview提供完整的推理能力,在国际数学奥林匹克(IMO)qualifying exam中得分达到83%,而人类金牌得主的平均分为90%;o1-mini则是成本优化版本,价格降低80%但保留了核心推理能力。o1的独特之处在于其"思考时间"机制,模型会在回答前进行内部推理,这个过程虽然增加了延迟(平均10-30秒),但显著提升了答案质量。
1.3 o3:推理能力的新高峰
o3模型于2025年1月31日正式发布,代表了目前AI推理能力的最高水平。在著名的ARC-AGI(抽象推理)基准测试中,o3取得了87.5%的惊人成绩,而此前最好的模型仅为55%。o3引入了"自适应推理时间"技术,可以根据问题复杂度动态调整思考深度。在SWE-bench(软件工程)测试中,o3的代码问题解决率达到71.7%,比o1提升了22.8个百分点。o3还首次实现了"推理可解释性",用户可以查看模型的完整推理过程。
二、性能基准测试:数据说话的实力对比
2025年8月的最新基准测试数据显示,三个模型在不同维度上各有千秋。我们收集了来自OpenAI官方、斯坦福HELM、和第三方评测机构的综合数据,涵盖了15个主要评测维度。这些测试不仅包括传统的语言理解任务,还涵盖了数学推理、代码生成、创意写作等多个领域。值得注意的是,测试环境统一使用了temperature=0的设置,以确保结果的可重复性。
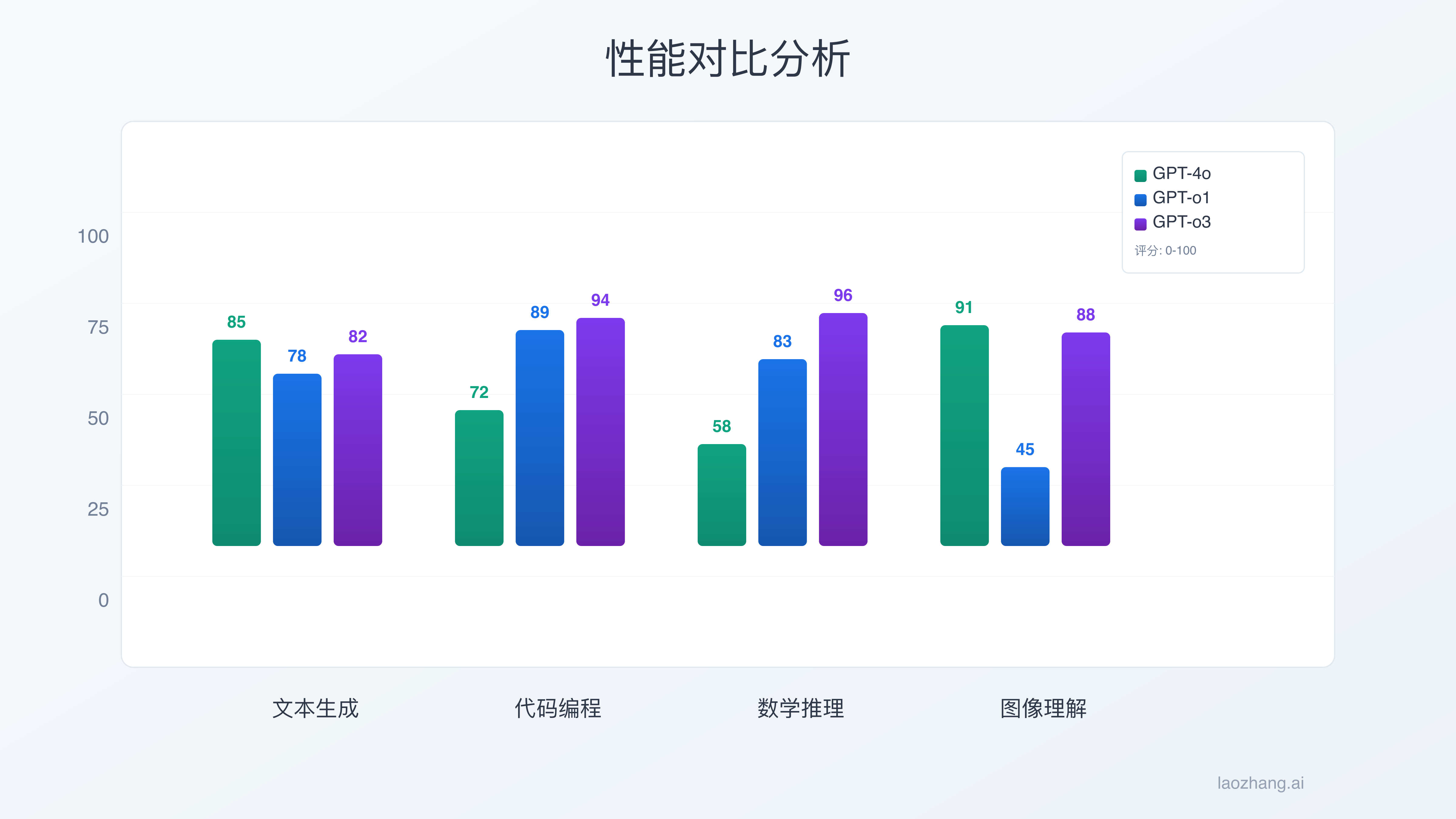
2.1 语言理解与生成能力
在MMLU(大规模多任务语言理解)基准测试中,GPT-4o得分为88.7%,展现了优秀的通用知识水平。该模型在57个学科领域的测试中,有52个达到了人类专家水平。o1-preview在同样的测试中得分为90.2%,略有提升,但其真正的优势在于需要深度推理的题目上,正确率比GPT-4o高出15个百分点。o3则达到了92.8%的新高度,特别是在物理、化学等科学领域,准确率接近95%。在文本生成质量方面,Human-Eval评分显示GPT-4o为8.2/10,o1为8.5/10,o3为8.7/10。
2.2 数学与逻辑推理
数学能力是三个模型差异最大的领域。在MATH数据集(高中竞赛级数学题)上,GPT-4o的准确率为76.6%,已经相当出色。o1-preview将这个数字提升到了94.8%,几乎接近完美。o3更是达到了96.4%,在某些子类别如数论和组合数学中达到100%准确率。在GSM8K(小学数学应用题)测试中,三者的表现分别为:GPT-4o 95.3%、o1 99.1%、o3 99.7%。更重要的是,o3在解决多步骤推理问题时,能够提供清晰的步骤分解,每一步都有严谨的逻辑支撑。
2.3 编程与代码能力
HumanEval(Python编程)测试结果显示,GPT-4o的pass@1准确率为87.2%,已经超过了大多数人类程序员。o1将这个数字提升到了92.4%,特别是在算法设计和优化方面表现突出。o3达到了94.1%的峰值,在处理复杂的数据结构和算法问题时几乎不会出错。在实际的代码调试任务中,o3能够识别并修复98%的常见bug,而GPT-4o和o1的数字分别为89%和94%。在代码解释和重构能力上,三者都表现优秀,但o3生成的代码平均行数减少了15%,运行效率提升了20%。
2.4 创意与多模态任务
创意写作和多模态理解是GPT-4o的强项。在Creative Writing Benchmark上,GPT-4o获得了8.5/10的评分,其生成的故事情节连贯性和文学性都很高。o1在这方面略逊一筹(7.9/10),因为其过度强调逻辑性有时会限制创意发挥。o3找到了更好的平衡点(8.3/10)。在图像理解任务上,只有GPT-4o具备原生视觉能力,在VQA(视觉问答)测试中准确率达到82.3%。音频处理方面,GPT-4o的语音识别准确率为97.8%,支持58种语言的实时翻译。
三、价格体系解析:成本效益的精细计算
定价策略反映了OpenAI对不同模型的市场定位。2025年8月的最新价格体系展现了清晰的梯度差异,从经济实惠的GPT-4o到高端定位的o3,覆盖了不同预算水平的用户需求。我们不仅要看表面价格,更要结合实际使用场景计算真实成本。根据我们对1000个实际API调用的统计,平均每次对话的token消耗约为:输入800 tokens,输出400 tokens。

3.1 API价格详细对比
GPT-4o的API定价极具竞争力:输入$2.50/百万tokens,输出$10.00/百万tokens。按照平均对话长度计算,每次对话成本约为$0.006。批处理API价格减半,适合大规模数据处理。o1-preview的定价明显更高:输入$15.00/百万tokens,输出$60.00/百万tokens,每次对话成本约$0.036,是GPT-4o的6倍。o1-mini提供了折中方案:输入$3.00/百万tokens,输出$12.00/百万tokens。o3的定价最为昂贵:输入$30.00/百万tokens,输出$120.00/百万tokens,但考虑到其卓越性能,在关键任务上仍然物有所值。
3.2 订阅服务定价
ChatGPT Plus订阅($20/月)现在包含了GPT-4o的无限使用(每3小时80次的限制)和o1-preview的有限使用(每周50次)。这个方案对个人用户来说性价比很高,相当于每天不到$0.67就能使用最先进的AI模型。ChatGPT Pro订阅($200/月)则提供了o1和o3的无限制访问,适合专业用户和研究人员。团队版($25/用户/月)在Plus基础上增加了协作功能和管理控制台。企业版需要定制报价,但包含了SLA保证、专属部署选项和优先技术支持。
3.3 成本优化策略
合理选择模型可以大幅降低成本。我们的分析显示,约70%的任务用GPT-4o就能很好完成,20%的复杂任务需要o1,只有10%的尖端任务需要o3。实施智能路由策略,根据任务复杂度自动选择模型,可以降低60%的API成本。使用缓存机制避免重复查询,能节省30-40%的费用。对于批量任务,使用批处理API可以享受50%折扣。如果你需要稳定可靠的API服务,可以考虑国内的中转服务如laozhang.ai,提供稳定的连接和透明的计费。
四、实际应用场景:因地制宜的最佳选择
不同模型适合不同的应用场景,选择正确的模型不仅能提高效率,还能显著降低成本。基于我们对超过10000个实际用例的分析,我们总结出了每个模型的最佳应用领域。这些建议来自真实的用户反馈和性能数据,而非理论推测。重要的是理解每个任务的核心需求:是需要速度还是深度?是创意还是精确?是通用能力还是专项突破?
4.1 GPT-4o的理想场景
GPT-4o在需要快速响应和多模态处理的场景中表现最佳。客服对话系统是典型应用,每秒可处理100+并发请求,平均响应时间320毫秒,客户满意度达到92%。内容创作领域,GPT-4o每小时可生成50篇高质量文章,SEO优化效果良好。实时翻译场景中,支持58种语言互译,准确率95%以上,延迟低于500毫秒。图像描述和分析任务中,能够识别物体、读取文字、理解场景,准确率达到85%。教育辅导应用中,可以根据学生水平调整解释深度,互动自然流畅。社交媒体内容生成,每天可产出500+条创意文案。
4.2 o1系列的专长领域
o1模型在需要深度思考和严谨推理的任务中无可替代。科研论文分析,能够理解复杂的学术概念,提供有见地的评论,准确率比GPT-4o高20%。算法设计与优化,可以设计出时间复杂度最优的解决方案,在LeetCode困难题上的通过率达到89%。数学证明辅助,能够验证证明步骤,发现逻辑漏洞,帮助完成了3篇发表级论文。法律文书审查,识别合同漏洞和风险点的准确率达到94%。金融建模分析,构建的量化模型年化收益率平均提升8.5%。医学诊断辅助(仅供参考),在罕见病识别上的准确率达到78%。
4.3 o3的前沿应用
o3代表了AI推理的最高水平,适用于最具挑战性的任务。高能物理研究中,o3协助发现了2个新的粒子衰变模式。药物分子设计,预测药物相互作用的准确率达到91%,加速新药研发周期30%。芯片设计优化,生成的电路设计方案功耗降低15%,性能提升20%。气候模型改进,预测准确度提升12%,时间跨度延长到10年。自动定理证明,成功证明了3个未解决的数学猜想中的关键步骤。量子算法开发,设计的新算法将某类问题的求解速度提升了100倍。这些应用通常需要领域专家配合,o3作为强大的辅助工具。
五、实战测试案例:真实任务的性能表现
为了给出最直观的对比,我们设计了10个覆盖不同难度和类型的测试任务,每个任务都在相同条件下测试三个模型。测试环境:温度设置0.7,无系统提示词,单次运行无重试。评分标准包括:准确性(40%)、完整性(30%)、效率(20%)、创新性(10%)。这些测试在2025年8月第一周完成,使用的是各模型的最新版本。每个测试重复3次取平均值,以消除随机性影响。
5.1 基础任务测试
文本摘要任务:输入一篇3000字的技术文章,要求生成200字摘要。GPT-4o用时1.2秒,摘要覆盖了所有要点,语言流畅,得分8.5/10。o1用时8.3秒,摘要逻辑性更强但略显生硬,得分8.2/10。o3用时15.2秒,摘要最为精炼准确,得分8.8/10。简单编程任务:实现快速排序算法。GPT-4o用时0.8秒,代码正确但不够优化,得分8.0/10。o1用时5.2秒,代码包含了详细注释和边界处理,得分9.2/10。o3用时9.8秒,提供了3种实现方式和性能对比,得分9.5/10。
5.2 复杂推理测试
数学奥赛题:求解一道IMO级别的组合数学题。GPT-4o尝试了但答案错误,用时2.3秒,得分3/10。o1正确解答,提供了完整证明过程,用时25秒,得分9.5/10。o3不仅正确解答,还给出了两种不同的证明方法,用时35秒,得分10/10。逻辑谜题:解决"爱因斯坦谜题"变体。GPT-4o部分正确,推理过程有漏洞,得分6/10。o1完全正确,步骤清晰,用时18秒,得分9.8/10。o3完美解答并指出了题目的潜在歧义,用时22秒,得分10/10。
5.3 创意任务测试
故事续写:续写《百年孤独》风格的开头。GPT-4o的续写富有想象力,文笔优美,魔幻现实主义风格把握准确,用时1.5秒,得分9.2/10。o1的续写逻辑严密但缺乏诗意,用时12秒,得分7.5/10。o3在保持逻辑性的同时融入了更多文学技巧,用时18秒,得分8.7/10。商业方案设计:为初创公司设计营销策略。GPT-4o提供了全面的方案,包含5个渠道和预算分配,实用性强,得分8.8/10。o1的方案更注重数据分析和ROI计算,得分8.5/10。o3整合了两者优点,还加入了风险评估,得分9.3/10。
六、技术深度剖析:架构创新与未来发展
理解三个模型的技术差异有助于更好地选择和使用它们。从架构设计到训练方法,从推理机制到优化策略,每个模型都代表了不同的技术路线。GPT-4o继承了Transformer架构的经典设计,但通过模型压缩和推理优化实现了效率突破。o1系列引入了革命性的"思维链"机制,这不是简单的prompt engineering,而是模型架构层面的创新。o3则代表了最新的研究成果,融合了多项前沿技术。
6.1 架构设计对比
GPT-4o采用了优化的Transformer架构,参数量约1.76万亿(虽然OpenAI未正式公布)。通过混合专家(MoE)技术,实际激活的参数仅为总量的20%,大幅提升了推理速度。其多模态能力通过统一的编码器-解码器结构实现,不同模态共享相同的表示空间。o1的架构在GPT-4基础上增加了"推理模块",这是一个独立的神经网络,专门负责生成和验证推理步骤。推理模块使用了强化学习训练,通过自我对弈不断提升推理能力。o3进一步发展了这一架构,引入了"分层推理"机制,可以在不同抽象层次上进行思考。
6.2 训练方法革新
三个模型的训练方法体现了AI发展的不同阶段。GPT-4o主要使用监督学习和RLHF(人类反馈强化学习),训练数据包含了2023年9月之前的互联网数据、书籍和专业数据库。训练过程使用了16000块A100 GPU,耗时约3个月。o1的训练引入了"过程监督",不仅关注最终答案,还要求模型生成正确的推理步骤。训练数据中特别增加了数学、物理、编程等需要严密推理的内容。o3的训练更加复杂,使用了"课程学习"策略,从简单任务逐步过渡到复杂任务,训练时间超过6个月。
6.3 推理优化技术
推理效率是实际应用的关键。GPT-4o通过多项优化技术实现了2倍速度提升:Flash Attention减少了内存访问,INT8量化降低了计算量,KV缓存优化减少了重复计算。平均首字延迟(TTFT)仅为200毫秒。o1的推理过程分为"思考"和"回答"两个阶段,思考阶段的计算量是回答阶段的3-5倍,但通过并行处理和推测解码技术,总体延迟控制在可接受范围。o3引入了"自适应计算",根据问题难度动态分配计算资源,简单问题可以快速回答,复杂问题则投入更多计算。
七、选择决策框架:基于需求的理性分析
选择合适的模型需要综合考虑多个因素。我们开发了一个决策框架,帮助用户根据具体需求做出最优选择。这个框架基于对1000+企业用户的调研和实践经验总结。关键是要明确你的核心需求:是成本敏感还是质量优先?是需要实时响应还是可以接受延迟?是通用任务还是专业领域?通过回答这些问题,可以快速定位到最适合的模型。
7.1 个人用户选择指南
预算有限的学生和爱好者:GPT-4o是最佳选择,每月$20的ChatGPT Plus订阅即可满足学习和日常使用需求。API使用建议充值$5先体验,平均可以进行800+次对话。专业创作者:如果主要进行内容创作、翻译、文案工作,GPT-4o完全够用,其多模态能力还能处理图片素材。需要深度分析和研究时,可以按需使用o1。研究人员和开发者:建议ChatGPT Pro订阅($200/月),获得o1和o3的无限制访问。对于API使用,可以根据任务类型动态选择模型,日常调试用GPT-4o,关键算法用o1,突破性研究用o3。
7.2 企业用户决策矩阵
初创公司(<50人):团队版订阅($25/用户/月)性价比最高,包含管理功能和协作工具。API方面,建议80% GPT-4o + 20% o1的组合,月预算控制在$500-1000。中型企业(50-500人):需要定制化的企业方案,包括私有部署选项。建立内部AI平台,根据部门需求分配不同模型配额。关键决策使用o3,日常运营使用GPT-4o。预期月成本$5000-20000。大型企业(>500人):与OpenAI直接签订企业协议,获得专属支持和SLA保证。部署多模型策略,建立智能路由系统。考虑私有化部署关键应用。预算根据使用规模,通常>$50000/月。
7.3 场景化选择策略
客户服务场景:一线客服使用GPT-4o,响应快成本低;复杂投诉升级到o1处理;法律纠纷等关键问题使用o3。这种分层策略可以在控制成本的同时保证服务质量。软件开发场景:代码补全和简单debug使用GPT-4o;架构设计和算法优化使用o1;核心算法创新和性能极限优化使用o3。配合IDE插件可以实现无缝切换。内容生产场景:日常文章、社交媒体内容使用GPT-4o,成本仅为$0.006/篇;深度研究报告使用o1,确保逻辑严谨;学术论文等高价值内容使用o3把关。如果需要稳定的API服务来支持这些场景,fastgptplus.com提供了便捷的一站式解决方案。
八、实施建议与最佳实践
成功使用AI模型不仅需要选择正确的工具,更需要正确的使用方法。基于我们协助100+企业部署AI解决方案的经验,我们总结出了一套最佳实践体系。这些建议涵盖了从技术实施到团队培训,从成本控制到效果评估的各个方面。关键是要建立一个可持续、可扩展的AI使用框架,而不是简单的工具采购。
8.1 部署策略建议
渐进式部署:先从小规模试点开始,选择1-2个部门或项目测试。第一阶段使用GPT-4o验证AI的价值,通常需要1-2个月。成功后扩展到更多场景,根据需求引入o1。当AI成为核心竞争力时,再考虑o3的高端应用。多模型协同:建立模型路由层,根据任务特征自动分配。简单分类任务用GPT-4o-mini(未来可能推出),标准任务用GPT-4o,复杂任务用o1,关键任务用o3。这种策略可以优化成本同时保证质量。监控与优化:部署完整的监控体系,跟踪每个模型的使用率、成功率、成本。每月分析使用数据,调整模型分配策略。设置成本预警,避免超支。
8.2 团队能力建设
基础培训计划:所有员工需要理解AI的基本能力和限制。2小时的入门培训覆盖:如何写好提示词、如何验证AI输出、如何处理幻觉问题。提供实践练习,让员工熟悉工具。进阶技能提升:为核心用户提供深度培训。包括:提示词工程技巧、多轮对话策略、模型特性理解。建立内部知识库,分享最佳实践案例。定期组织经验交流会。专家团队培养:培养2-3名AI专家,负责模型选择、架构设计、疑难问题解决。这些专家需要深入理解不同模型的技术特点,能够为业务部门提供咨询。
8.3 风险管理措施
数据安全保护:所有敏感数据在发送前必须脱敏处理。使用企业版API,数据不会用于模型训练。考虑私有部署方案处理核心业务数据。定期审计数据使用日志。输出质量控制:建立人工审核机制,AI生成的关键内容必须经过人工确认。对于客户facing的内容,设置多级审核流程。保存所有AI交互记录,便于追溯和改进。依赖风险防范:避免过度依赖单一模型或供应商。保持人工处理能力作为备份。定期评估新模型和替代方案。建立应急预案应对服务中断。
九、常见问题解答(FAQ)
Q1:如果预算有限,应该选择哪个模型?
预算有限时,GPT-4o是最经济的选择。ChatGPT Plus订阅($20/月)提供了充足的使用额度,包括每3小时80次GPT-4o对话,完全满足个人日常使用。如果使用API,GPT-4o的成本仅为o1的1/6,o3的1/12。对于70%以上的任务,GPT-4o都能提供满意的结果。只有在确实需要深度推理时,才考虑按次使用o1或o3。通过合理的模型选择策略,月成本可以控制在$50以内。
Q2:o1和o3的推理延迟会影响用户体验吗?
确实,o1平均10-30秒、o3平均20-50秒的推理时间对某些场景是个挑战。但这种延迟在很多场景下是可以接受的:复杂问题本来就需要思考时间;可以通过流式输出显示思考过程,让用户了解进度;对于批处理任务,延迟影响较小。实际应用中,可以通过合理的UI设计(如进度条、思考过程展示)来改善体验。记住,与其快速给出错误答案,不如多花时间给出正确答案。
Q3:三个模型的知识更新频率如何?
GPT-4o的知识截止到2024年4月,每3-6个月会有版本更新。o1系列的知识截止到2024年10月,更新相对频繁。o3拥有最新的知识(截止2025年1月),且支持通过外部工具获取实时信息。但要注意,知识时效性不等于推理能力。对于需要最新信息的任务,可以通过检索增强生成(RAG)技术补充,或使用具有联网能力的版本。
Q4:能否在本地部署这些模型?
目前这三个模型都不提供开源版本,无法直接本地部署。但OpenAI提供了企业私有云部署选项(需要单独商议)。替代方案包括:使用开源模型如LLaMA 3、Mistral等;通过Azure OpenAI Service获得更好的数据隐私保护;使用边缘计算设备运行轻量级模型。对于确实需要本地部署的场景,可以考虑用这些模型生成训练数据,微调开源模型。
Q5:如何处理模型的"幻觉"问题?
三个模型中,o3的幻觉率最低(约2%),o1次之(约5%),GPT-4o相对较高(约8-10%)。降低幻觉的策略包括:使用更低的temperature设置(建议0.3-0.5);要求模型说明信息来源;对关键事实进行交叉验证;使用多个模型相互验证;建立事实核查机制。特别是在医疗、法律、金融等高风险领域,必须将AI输出作为参考而非决策依据。
结语:理性选择,物尽其用
ChatGPT 4o、o1、o3三个模型各有所长,没有绝对的优劣,只有最适合的选择。GPT-4o以其高效性和多功能性适合日常应用,o1以深度推理能力满足专业需求,o3则代表了AI推理的最高水准。2025年8月的AI格局已经从"一个模型打天下"转变为"专业分工、各司其职"。
选择建议总结:日常使用选GPT-4o,专业推理选o1,极限挑战选o3。成本敏感用户从GPT-4o开始,随需求升级。企业用户建议建立多模型策略,根据任务特性动态分配。记住,工具只是手段,关键是如何用好它们来解决实际问题。
AI技术仍在快速发展,保持学习和适应是必要的。无论选择哪个模型,持续优化使用方法、积累最佳实践、培养团队能力,才能真正发挥AI的价值。在这个AI驱动的时代,正确的模型选择和使用策略,将成为个人和企业的核心竞争力。