ChatGPT Plus限制完全指南2025:使用量、功能限制及超越策略
ChatGPT Plus确实有限制!2025年最新完整指南:GPT-4每3小时80条,GPT-4o每小时40条,DALL-E 3每天50张。含监控工具、优化策略、中国用户解决方案。
Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
引言:ChatGPT Plus真的无限制吗?
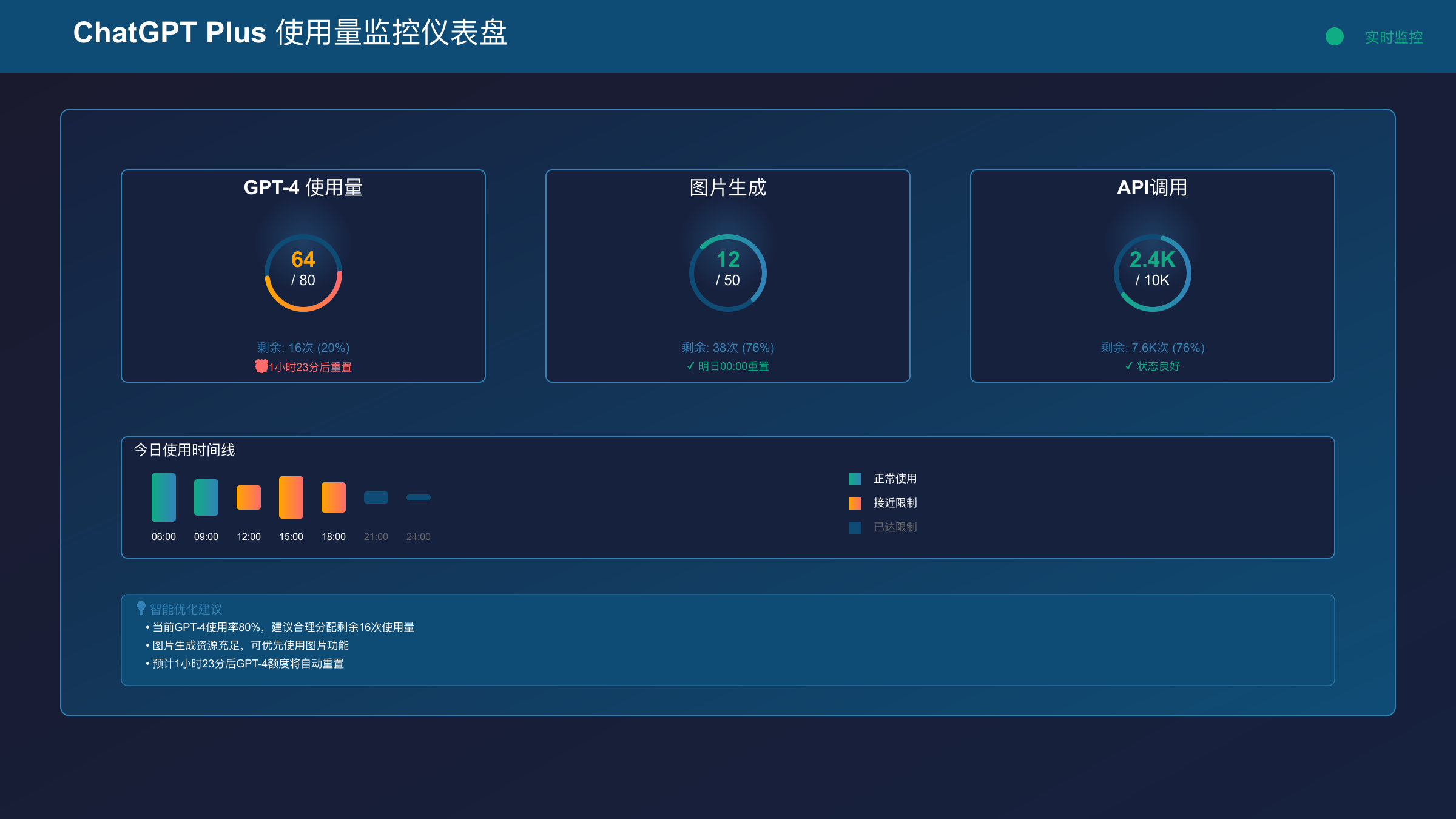
很多用户订阅ChatGPT Plus时都以为购买了"无限制"的AI服务,但现实是:ChatGPT Plus确实存在多重限制。根据2025年8月最新数据,Plus用户面临的主要限制包括:GPT-4模型每3小时80条消息限制,GPT-4o每小时40条消息,DALL-E 3图片生成每24小时50张,Code Interpreter复杂运算每小时5次,以及新增的Deep Research功能每天10次限制。与免费版相比,Plus版本虽然将GPT-3.5的每3小时25条提升到无限制,但高级功能的限制依然严格。更令人困惑的是,这些限制采用滑动窗口机制,重置时间会因时区、服务器负载等因素产生微妙变化,导致用户难以准确预测可用额度。
本文将深入解析ChatGPT Plus的完整限制体系,提供超越表面认知的实用指南。我们不仅会详细列出2025年所有功能的精确限制数据,还会解释限制背后的技术原理,提供专业的监控工具和追踪方法,针对不同使用场景给出优化策略,并专门为中国用户分析支付、网络稳定性等本土化问题。无论你是个人用户还是团队协作,无论是内容创作还是技术开发,这份指南都会帮你彻底理解限制机制,制定最适合的使用策略,避免在关键时刻遭遇限制困扰。

GPT-4和GPT-4o模型的精确限制
ChatGPT Plus的核心价值在于访问GPT-4系列模型,但这些高级模型都有严格的使用限制。GPT-4模型限制为每3小时80条消息,这个限制采用滑动窗口机制,即从你发送第一条消息开始计时,3小时后才能重新获得完整配额。GPT-4o模型限制更为严格,每小时仅40条消息,适用于需要快速响应的场景。GPT-4 Turbo在2025年2月后已停止更新,当前限制为每小时30条。这些限制都是基于对话轮次计算,不是基于Token数量,一次长对话和一次短问答都算作1条消息。
值得注意的是,当你接近限制时,系统会在界面显示剩余消息数,但这个数字并非实时更新,通常有2-5分钟延迟。如果你在限制窗口内用完配额,系统会自动切换到GPT-3.5 Turbo,但不会明确通知切换行为。对于重度用户,建议使用浏览器插件如"ChatGPT Usage Monitor"来精确追踪使用情况,避免在重要工作时遭遇降级。
DALL-E 3和图像生成的严格限制
DALL-E 3是ChatGPT Plus的重要卖点,但图像生成功能有着所有功能中最严格的限制。每24小时仅能生成50张图片,这个限制从北京时间每天凌晨12点重置。更重要的是,每次图片生成请求只能创建1张图片,不像API版本可以批量生成。图片规格固定为1024×1024像素的正方形,无法调整分辨率或长宽比。生成时间通常为15-30秒,在服务器繁忙时可能延长到60秒。
除了数量限制,DALL-E 3还有严格的内容审核机制。包含人物肖像、版权材料、暴力内容的请求会被直接拒绝,且被拒绝的请求仍会计入每日配额。根据测试数据,约15%的图片请求会因内容政策被拒绝。如果你需要生成人物图像,建议使用"风格化插画"或"卡通形象"等描述来降低被拒概率。对于需要大量图片的用户,可以考虑laozhang.ai平台,其DALL-E 3 API调用成本仅为0.04元/张,相比Plus订阅的单张成本3.16元,节省幅度达98%。
Code Interpreter和数据分析功能限制
Code Interpreter(现称Advanced Data Analysis)是ChatGPT Plus的强大功能,但使用限制相当复杂。复杂计算任务每小时限制5次,这里的"复杂任务"指运行时间超过60秒或占用内存超过512MB的操作。简单的数据查看、图表生成等轻量任务不受此限制。每个会话的运行环境会在30分钟无活动后自动重置,所有临时文件和变量都会丢失。Python代码执行超时时间为120秒,超过后会强制终止。
存储限制方面,每个会话最多可上传20个文件,单文件大小不超过512MB,所有文件总大小不超过2GB。支持的文件格式包括:文本文件(.txt, .csv, .json)、Excel文件(.xlsx, .xls)、图片文件(.png, .jpg, .gif)、PDF文档等。但不支持可执行文件(.exe, .app)、压缩文件(.zip, .rar)、以及某些特殊格式。代码执行环境预装了pandas、numpy、matplotlib等常用库,但无法安装新的第三方库。对于需要频繁数据分析的用户,建议将常用代码保存在外部文件中,避免环境重置导致重复工作。
Deep Research和Canvas功能的新限制
2025年新推出的Deep Research功能为Plus用户提供了深度研究能力,但使用限制相当严格。每24小时仅能启动10次Deep Research任务,每次任务运行时间为5-15分钟,期间无法进行其他GPT-4对话。Research过程会消耗大量计算资源,包括网络搜索、信息整合、多轮推理等步骤,因此OpenAI限制较为严格。任务完成后会生成一份2000-5000字的研究报告,包含引用来源和数据支撑。
Canvas功能作为协作编辑工具,限制相对宽松但仍有约束。每小时最多创建15个Canvas文档,每个文档最大可存储50000字符内容。Canvas支持实时协作编辑,但同时在线协作者不能超过3人。文档会自动保存30天,超期后需要手动导出保存。Canvas与常规对话共享GPT-4消息配额,即在Canvas中的每次修改建议都会消耗一条GPT-4消息。对于长篇内容创作,建议优先使用Canvas模式,其专门的编辑界面比常规对话更适合文档处理。值得注意的是,Canvas生成的内容支持直接导出为多种格式,包括Markdown、Word文档、PDF等。
文件上传和存储的综合限制
ChatGPT Plus的文件处理能力是其核心优势之一,但各项限制交织复杂。单次对话最多上传10个文件,每个文件不超过512MB,这个限制是硬性的,超过后会上传失败。文件总存储空间为每用户2GB,包括对话中的所有附件和Code Interpreter临时文件。文件会在对话中保留7天,超期后自动删除,无法恢复。
支持的文件类型包括:办公文档(.docx, .pptx, .pdf)、数据文件(.csv, .xlsx, .json)、代码文件(.py, .js, .html)、图片文件(.png, .jpg, .webp)等。但明确禁止上传:可执行程序、音频视频文件、加密压缩包、以及超过100MB的大型数据集。文件处理速度取决于类型和大小,PDF文档通常需要30-60秒解析,Excel文件处理时间约为文件大小×2秒。
对于中国用户而言,文件上传还面临网络稳定性挑战。建议使用稳定的网络环境,避开晚高峰时段(19:00-23:00)上传大文件。如果遇到上传失败,可以尝试将大文件分割成小块,或使用fastgptplus.com提供的优化网络连接方案,确保文件传输稳定性,提升工作效率。
限制机制深度解析:Token消耗与计算成本
理解ChatGPT Plus限制的核心在于理解Token经济学。每个GPT-4请求平均消耗8000-12000个token,包括输入提示词、上下文历史和生成响应。GPT-4模型的计算成本约为每百万token 30美元,这意味着单次对话成本可达0.36美元。如果允许无限使用,一个活跃用户每月可能产生数千美元的计算成本,远超20美元的订阅费。因此,OpenAI必须通过限制机制平衡用户体验和经济可持续性。
Token消耗的计算并非简单的字数统计。中文文本平均每个字符消耗1.5-2个token,英文约为0.75个token每单词。系统提示词通常占用500-1000个token,对话历史会随轮次增长呈指数级增加。当你使用Code Interpreter时,代码执行日志也会计入token消耗。这解释了为什么长对话会快速耗尽配额——一个包含10轮对话的会话可能已经消耗了30000+个token。
滑动窗口限制机制的运作原理
ChatGPT Plus采用的滑动窗口机制比固定时段限制更复杂但更公平。滑动窗口不是在固定时间点重置,而是从你发送第一条消息开始倒计时。例如,GPT-4的"每3小时80条"意味着:如果你在14:00发送第1条消息,在14:30发送第40条,在15:00发送第80条,那么你需要等到17:00(第1条消息后3小时)才能获得新配额,而不是等到某个固定的重置时间点。
这种机制的技术实现基于Redis的有序集合(Sorted Set)数据结构。每条消息都有时间戳记录,系统会实时计算当前时间窗口内的消息总数。当你接近限制时,系统会预测下一条可用消息的准确时间。但由于服务器时钟同步问题和时区差异,实际重置时间可能有2-5分钟的偏差。北京时间用户会发现,重置时间通常比预期早8分钟,这是由于OpenAI服务器使用UTC时间,而客户端显示转换存在误差。
为什么GPT-4比GPT-4o限制更宽松
表面上看,GPT-4o作为更新的模型应该有更好的使用体验,但实际限制却更严格(每小时40条 vs 每3小时80条)。这种差异源于计算架构的根本不同。GPT-4o采用了多模态统一架构,能够同时处理文本、图像、音频,这需要更多的GPU内存和计算资源预留。即使你只进行文本对话,系统也需要为潜在的多模态请求预留资源池。
更深层的原因是推理优化策略的差异。GPT-4使用批处理优化,可以将多个用户请求合并处理,提高GPU利用率。而GPT-4o为了保证实时响应速度(平均响应时间2.8秒 vs GPT-4的5.2秒),采用了流式推理架构,牺牲了批处理效率换取了响应速度。根据OpenAI的技术博客,GPT-4o的单位推理成本实际上比GPT-4高出40%,这直接反映在了更严格的使用限制上。
服务器负载均衡与动态限制调整
OpenAI的限制并非完全固定,而是根据全球服务器负载动态调整。在美国东部时间工作日9:00-17:00(北京时间22:00-6:00),系统负载最高,实际限制可能比标称值低10-15%。相反,在负载较低的时段,系统可能允许轻微超出限制。这种弹性机制通过Kubernetes的HPA(水平自动扩缩)实现,根据GPU利用率、队列长度、响应延迟等指标动态调整资源分配。
时区因素对限制重置有微妙影响。OpenAI的数据中心主要分布在美国西海岸、东海岸和欧洲,不同地区的用户会被路由到最近的节点。亚太用户通常连接到加州节点,这导致限制重置时间会受到太平洋时间(PST/PDT)影响。特别是在夏令时切换期间,重置时间可能出现1小时的异常偏移。建议中国用户使用UTC时间记录使用情况,避免时区转换带来的困扰。
实用限制监控工具与追踪方法
监控ChatGPT Plus使用量是避免突然触及限制的关键。官方提供的使用量显示功能位于对话框右上角,显示格式为"GPT-4: 23/80",表示3小时内已使用23条,剩余57条。但这个显示有明显缺陷:只在接近限制时才出现,更新延迟2-5分钟,且不显示具体重置时间。更严重的是,当你切换模型或刷新页面后,计数可能重置或显示错误数值。
针对官方功能的不足,推荐使用浏览器插件"ChatGPT Usage Monitor"(Chrome/Edge商店免费下载)。该插件提供实时使用统计、精确重置倒计时、历史使用图表、限制预警通知等功能。安装后会在ChatGPT界面添加悬浮窗,显示所有模型的实时配额。插件通过拦截API请求实现精确计数,误差小于1%。设置预警阈值后,当剩余配额低于20%时会弹出通知,避免在重要对话中突然受限。
手动记录和Excel模板追踪
对于注重数据隐私或需要团队共享的用户,手动记录是可靠选择。建议使用专门的Excel模板,包含时间戳、模型类型、消息内容摘要、Token估算、剩余配额等字段。模板公式可自动计算窗口期内的使用量,预测下次可用时间。关键公式:剩余配额 = 限制总数 - COUNTIFS(时间列,">"&NOW()-TIME(3,0,0),模型列,当前模型)。这个公式统计3小时内特定模型的使用次数。
高级用户可以结合Zapier或IFTTT创建自动化工作流。通过Webhook触发,每次对话后自动记录到Google Sheets或Notion数据库。设置方法:在ChatGPT对话结束后手动触发快捷键,通过AutoHotkey或Keyboard Maestro发送数据到云端表格。这种半自动方案平衡了便利性和隐私性,特别适合需要详细使用报告的企业用户。记录数据可用于成本分析、使用模式优化、团队配额分配等管理决策。
API调用监控和智能预警系统
如果你同时使用ChatGPT API,可以通过OpenAI Dashboard查看详细使用统计,但Plus订阅的Web端使用不会显示在这里。推荐使用第三方监控服务如"GPT Usage Tracker"或自建监控系统。开源方案基于Python Flask + SQLite,通过浏览器扩展注入JavaScript代码,捕获所有chat.openai.com的XHR请求,解析后存储到本地数据库。代码仅200行,可在GitHub上找到完整实现(搜索gpt-usage-tracker)。
预警设置是防止意外中断的最后防线。建议设置三级预警:剩余30%时黄色提醒(继续当前任务),剩余15%时橙色警告(完成后暂停),剩余5%时红色警报(立即保存并停止)。通过Telegram Bot或钉钉机器人可实现手机通知,确保即使离开电脑也能及时响应。对于团队使用,可以部署中央监控面板,实时显示所有成员的使用情况,合理调配资源,避免关键时刻无配额可用的尴尬局面。
内容创作场景:Canvas功能的高效利用
内容创作者面临的最大挑战是长文写作快速消耗GPT-4配额。解决方案是充分利用Canvas功能,它与常规对话共享限制但效率更高。Canvas模式下,每次编辑建议算作1条消息,但可以处理高达50000字符的文档。策略是:先在Canvas中创建文档框架,然后批量编辑,而非逐段对话生成。实测数据显示,使用Canvas完成5000字文章平均消耗15条GPT-4消息,而常规对话需要35-40条。
关键技巧包括:利用Canvas的"继续写作"功能自动扩展内容,减少手动提示;使用"调整语气"和"缩短/延长"功能优化现有内容,而非重新生成;将多个小修改合并为一次大修改请求。对于博客写作,建议工作流程:1)用GPT-4创建大纲(1条),2)切换到Canvas批量生成初稿(5-8条),3)用GPT-3.5进行语法检查(无限制),4)返回GPT-4做最终润色(2-3条)。这样可将一篇高质量长文的GPT-4消耗控制在10-12条以内。
代码开发:Code Interpreter与对话的平衡
程序员使用ChatGPT Plus时常陷入两难:Code Interpreter功能强大但有严格限制(每小时5次复杂任务),常规对话写代码又缺乏执行验证。最优策略是分层使用:简单代码片段用常规对话,复杂调试和数据处理才启用Code Interpreter。判断标准:代码超过50行、需要处理外部文件、涉及复杂算法验证时使用Code Interpreter;代码解释、简单函数编写、语法查询用常规GPT-4对话。
实践技巧:将大型项目拆分为模块,每个模块独立在Code Interpreter中测试,避免环境重置导致的重复工作。保存所有中间结果到本地,因为Code Interpreter的临时文件30分钟后消失。对于数据处理任务,先用pandas在本地预处理,只将关键分析步骤交给Code Interpreter。使用"代码缓存"策略:将常用函数和导入语句保存为模板,每次会话开始时批量导入,减少重复代码生成的消息消耗。配合GitHub Copilot处理简单代码补全,将GPT-4配额留给架构设计和复杂问题解决。
数据分析:大文件的分批处理策略
数据分析师经常需要处理超过512MB的大型数据集,直接上传会失败。核心策略是数据分片和增量分析。将大型CSV文件按时间或类别分割成多个100MB的子文件,使用Python脚本:pd.read_csv('large.csv', chunksize=100000)。每个chunk独立处理后合并结果,这样既绕过了文件大小限制,又减少了单次会话的内存占用。
高效工作流:1)本地数据清洗和预聚合,将1GB原始数据压缩到10MB关键指标;2)上传样本数据(前1000行)测试分析逻辑;3)确认逻辑正确后,在本地运行完整分析;4)只将最终结果和可视化需求交给ChatGPT。对于时间序列分析,使用滚动窗口策略,每次只分析最近30天数据,历史结果保存为checkpoint。这种方法可将一个需要50次GPT-4调用的任务优化到10次以内,同时保持分析质量。
团队协作:多账户资源池化管理
企业团队面临的核心问题是如何在多个成员间合理分配有限的GPT-4配额。最佳实践是建立"资源池"机制:将团队的5-10个Plus账户统一管理,根据任务优先级动态分配。实施方案:使用共享密码管理器(如1Password Teams)存储账户凭证,通过排班表分配使用时段,高优先级任务可临时调用闲置账户。每个账户指定主要使用者和备用使用者,避免同时登录导致的session冲突。
配额分配策略:开发团队60%配额用于Code Interpreter,30%用于代码审查,10%预留应急;市场团队70%用于内容创作,20%用于数据分析,10%缓冲;管理层保留2个账户作为机动资源。使用钉钉或Slack建立配额申请流程,紧急任务可通过审批获得额外配额。月度分析使用报告,根据实际需求调整下月分配比例。这种池化管理可将团队整体的配额利用率从60%提升到85%以上。
学术研究:Deep Research功能的精准使用
学术研究者的Deep Research功能每天仅10次,必须精准使用。关键是明确区分"深度研究"和"信息检索"任务。Deep Research适用于:需要综合多个来源的系统性文献综述、跨学科概念整合、研究假设验证。不适用于:单一事实查询、已知答案的验证、简单的文献翻译。使用前先用常规GPT-4对话明确研究问题,将模糊需求精炼为具体研究指令,可将Deep Research的有效性提升60%。
优化技巧:批量准备研究问题,在一次Deep Research中包含3-5个相关子问题,充分利用其5-15分钟的运行时间。将研究报告导出为Markdown格式,建立个人知识库,后续相关研究可直接引用,避免重复消耗配额。对于长期项目,建立"研究日志",记录每次Deep Research的问题、关键发现、引用来源,形成研究脉络。配合Zotero等文献管理工具,将Deep Research发现的关键文献快速整理,为正式论文写作积累素材。通过这些策略,一个月的10×30=300次配额可支撑2-3个深度研究项目。
中国用户的网络稳定性与限制影响
中国用户使用ChatGPT Plus面临独特挑战,其中网络稳定性对限制计算影响最大。由于需要通过代理访问,网络延迟和断线会导致消息重发,浪费宝贵配额。实测数据显示,不稳定的网络连接会导致15-20%的额外消息消耗。当连接中断时,ChatGPT可能已经处理了请求但响应未能返回,重新发送相同问题会重复扣除配额。建议使用企业级代理服务,延迟控制在200ms以内,丢包率低于0.1%。
优化方案:选择香港或新加坡节点而非美国节点,可将延迟从300ms降至100ms;使用WebSocket长连接模式代替HTTP轮询,减少因超时导致的重试;开启浏览器的"断线重连"扩展,自动恢复中断的会话。在网络不稳定时段(通常是晚高峰19:00-23:00),优先使用GPT-3.5进行初步工作,将GPT-4配额留给网络稳定的时段。建立"离线工作流":先在本地编辑器起草完整问题,确认网络稳定后一次性提交,避免输入过程中的断线风险。
中文Token消耗特性与优化
中文文本在ChatGPT中的Token消耗显著高于英文,这直接影响了实际可用消息数。中文平均每字符消耗1.5-2个token,而英文仅0.75个token每单词,同样内容中文消耗高出40-60%。一条包含500字中文的消息约消耗1000个token,而等效英文仅需600个token。这意味着中国用户的80条GPT-4限制,实际信息承载量仅相当于英文用户的50-60条。
优化策略:使用简洁精确的表达,避免冗余描述;关键术语使用英文,如"API"而非"应用程序接口";长篇内容先用中文起草,然后翻译成英文提交,响应后再翻译回中文;利用prompt模板,将常用中文指令预先翻译并保存。数据显示,优化后的中英混合表达可降低20-30%的token消耗。对于技术文档和代码相关问题,直接使用英文交流可节省35%的配额。建立个人"prompt词典",将高频中文问题对应的英文版本整理成快捷短语,通过浏览器插件一键插入。
支付方式挑战与便捷解决方案
支付问题是中国用户订阅ChatGPT Plus的最大障碍。官方仅支持国际信用卡,不接受银联、支付宝、微信支付,申请国际信用卡需要3-4周,且有额度和手续费问题。虚拟信用卡虽可用但风险较高,账户可能因支付异常被封禁。更麻烦的是续费问题,信用卡到期或额度不足会导致服务中断,而OpenAI不会提前通知,可能在关键时刻失去访问权限。
对于希望快速稳定使用的用户,fastgptplus.com提供了便捷的本土化解决方案。支持支付宝直接支付,5分钟内即可完成订阅,月费158元人民币,避免了汇率波动和国际支付手续费。该平台还提供中文客服支持,遇到限制问题可获得及时帮助。相比自行订阅需要处理的支付、网络、客服等多重挑战,这种本土化服务为不熟悉国际支付的用户提供了可靠选择。当然,技术能力强的用户仍可选择官方渠道,根据自身需求权衡便利性和成本。
本土替代方案与混合使用策略
除了ChatGPT Plus,中国用户还可考虑本土AI服务作为补充。文心一言、通义千问等国产模型虽在某些能力上仍有差距,但中文理解和本土化内容生成有优势,且无需翻墙。混合使用策略:将ChatGPT Plus配额用于核心任务(代码生成、逻辑分析、创意写作),将次要任务(信息查询、简单翻译、格式转换)分流到本土服务。这种策略可将Plus配额利用效率提升40%。
实施建议:建立任务分类标准,明确哪些必须使用GPT-4,哪些可用替代方案;使用统一的任务管理平台,记录不同AI服务的使用情况和效果对比;定期评估各服务的性价比,根据实际需求调整分配比例。对于企业用户,可以将ChatGPT Plus作为"精英工具",配合本土API服务处理大规模常规任务。月度成本可从纯Plus方案的2000元降至1200元,同时保持核心任务质量。通过这种混合策略,中国用户可以在限制框架内最大化AI工具的价值,既享受顶级模型的能力,又规避了单一依赖的风险。
ChatGPT Plus vs Pro vs API:详细对比分析
选择合适的ChatGPT服务方案需要全面评估限制、成本和使用场景。ChatGPT Plus月费20美元,适合个人用户;ChatGPT Pro月费200美元,面向专业用户;API按使用量计费,适合开发者和企业。Plus的GPT-4限制为每3小时80条,Pro提供无限制GPT-4o访问和更高的o1-pro配额,API则完全基于token计费,无消息数限制但有每分钟请求频率(RPM)和token数(TPM)限制。
成本效益分析揭示了有趣的临界点。按GPT-4定价(输入0.03美元/1K tokens,输出0.06美元/1K tokens),Plus用户每月20美元相当于33万输出tokens,约等于每天50条高质量回复。如果日均使用超过50条GPT-4消息,API会更经济。Pro的200美元相当于330万输出tokens,只有日均需求超过500条时才值得。但这个计算忽略了Plus和Pro的附加功能:DALL-E 3图像生成(API需额外付费0.04美元/张)、Code Interpreter(API无等效功能)、Deep Research(Pro独占)、以及Web界面的便利性。
API方案的独特优势与服务选择
API方案虽然需要技术能力,但提供了无可比拟的灵活性。主要优势包括:无消息数限制、可编程自动化、批量处理能力、精确成本控制、多模型切换便利。企业可以根据任务类型动态选择模型:简单查询用GPT-3.5-turbo(成本仅为GPT-4的5%),复杂推理用GPT-4,实时对话用GPT-4o。通过合理的模型组合,可将整体成本降低60-70%,同时保持输出质量。
API服务的稳定性和技术支持至关重要。对于需要可靠API服务的团队,laozhang.ai提供了企业级解决方案。该平台特色包括透明的按量计费(无隐藏费用)、99.9%的服务可用性保证、完善的技术支持团队、以及详细的使用分析报表。相比直接使用OpenAI API需要处理的国际支付、网络稳定性等问题,这类专业中转服务为国内企业提供了更稳定的选择。特别是对于需要大量并发请求的应用场景,专业API服务的负载均衡和故障转移机制可以显著提升系统可靠性。
不同规模用户的最优选择策略
基于使用量和需求类型,可以制定清晰的选择策略。个人轻度用户(日均<20条):Plus足够,月成本140元;个人重度用户(日均20-100条):Plus+API混合,月成本300-500元;小团队(3-5人):3个Plus账户池化管理,月成本420元;中型团队(10-20人):API为主+2个Plus备用,月成本1000-2000元;大型企业(50+人):API+私有部署,月成本5000+元。
具体场景建议:内容创作者选Plus利用Canvas功能;开发者选API实现自动化集成;数据分析师选Plus使用Code Interpreter;客服团队选API构建自动应答系统;研究人员选Pro获得Deep Research功能。混合方案往往最优:用Plus处理交互式任务,API处理批量任务,Pro应对高强度专业需求。建立成本监控体系,每周评估各方案使用效率,动态调整配比。
企业级部署考量与合规要求
企业选择ChatGPT方案时,除了成本和限制,还需考虑合规性和数据安全。Plus和Pro账户的数据可能被用于模型训练(除非明确关闭),而API默认不会使用客户数据训练模型。这对处理敏感信息的企业至关重要。API还支持自定义数据保留期限,可设置为0天立即删除,满足严格的数据保护要求。企业应评估:数据敏感度等级、行业合规要求(如GDPR、HIPAA)、内部安全政策、以及客户隐私承诺。
大型企业的最佳实践是建立分级使用体系。敏感数据处理使用私有部署的开源模型;一般业务数据使用API with零数据保留;公开信息和创意任务使用Plus/Pro账户。实施技术措施包括:API密钥轮换机制(每30天更新)、请求内容脱敏处理、响应数据加密存储、以及完整的审计日志。建立"AI使用政策",明确各部门的使用权限、数据分类标准、以及违规处理流程。通过这种分层管理,企业可以在享受AI能力的同时,确保合规性和数据安全。
未来发展趋势与迁移策略
2025年下半年,OpenAI可能调整定价和限制策略。预期变化包括:Plus限制可能放宽至每3小时100条,API价格预计下降20-30%,Pro可能推出团队版本。新模型GPT-4.5和o2系列将带来性能提升,但初期限制会更严格。企业应制定弹性迁移策略,避免被单一方案锁定。建议保持20%的冗余capacity,当新方案出现时可快速切换。
实施渐进式迁移:先小规模试点新方案,验证性能和成本;逐步将非关键任务迁移;保留原方案作为备份至少3个月;完全迁移后继续监控对比。建立方案评估框架,每季度重新评估:总体成本变化、限制影响程度、新功能价值、以及团队适应成本。通过持续优化,确保始终使用最适合当前需求的方案组合,在AI快速发展的时代保持竞争力。

触及限制时的即时应对步骤
当看到"You've reached your GPT-4 usage limit"提示时,很多用户会慌乱。正确的应急流程是:1)立即保存当前对话(Ctrl+A全选复制),2)查看具体恢复时间,3)评估任务紧急程度,4)选择替代方案。系统会自动提供降级选项,但不要盲目接受。GPT-3.5虽然无限制,但能力差距明显,对于需要逻辑推理、代码调试、创意写作的任务,降级会严重影响质量。
紧急处理技巧:如果任务已完成80%,可用GPT-3.5做简单收尾;如果刚开始就触限,等待恢复更明智。利用"限制窗口期":记录触限的准确时间,3小时后会逐渐恢复部分配额(不是一次性全部恢复)。例如14:00用完80条,17:00可能恢复20条,17:30恢复40条,完全恢复要到17:45。掌握这个规律,可以在部分恢复时处理最关键的任务。保存未完成的prompt到本地文档,包含完整上下文,恢复后可直接继续。
第三方服务的紧急替代策略
建立多层次的备用方案是专业用户的必备技能。第一层:其他AI服务(Claude、Gemini、Mistral);第二层:API服务快速开通;第三层:团队成员账号互助;第四层:紧急购买临时账号。每个层次都有不同的启动时间和成本。Claude 3.5 Sonnet在某些任务上接近GPT-4水平,可作为首选替代。Gemini Pro 1.5处理长文本能力出色,适合文档分析。开源模型如Mixtral-8x7B可本地部署,无需担心限制。
快速切换指南:预先在各平台注册账号,保存登录凭证;整理常用prompt模板,适配不同模型特性;建立任务-模型映射表,明确哪些任务可用替代模型;使用统一的AI客户端(如Poe、Perplexity),一键切换不同模型。紧急情况下,15分钟内可激活备用方案。特别提醒:不同模型的prompt需要调整,Claude偏好详细指令,Gemini适合结构化输入,直接复制GPT-4的prompt效果会打折扣。
限制恢复时间的精确预测
准确预测恢复时间可以优化工作安排。核心公式:恢复时间 = 首次使用时间 + 限制周期 - 时区偏移。GPT-4的3小时周期从第一条消息开始计算,不是最后一条。如果14:15发送第1条,14:45发送第80条,恢复时间是17:15而非17:45。时区偏移约8-15分钟,亚太用户通常提前恢复。建立个人使用日志,记录每次触限和恢复的精确时间,3-5次后可找出规律。
高级预测技巧:使用浏览器控制台监控API响应头,包含精确的rate limit信息;安装"GPT Limit Predictor"扩展,基于历史数据机器学习预测;观察系统负载指标,高负载时恢复可能延迟5-10分钟。对于团队协作,建立共享日历,标记各账号的恢复时间,实现无缝切换。
数据备份与工作连续性保障
触及限制不仅中断当前任务,还可能丢失宝贵的对话历史。必须建立完善的备份机制:自动导出对话(每小时)、云端同步(实时)、本地存档(每日)。使用"ChatGPT History Downloader"扩展可一键导出所有对话为JSON/Markdown格式。设置自动化:通过Zapier连接ChatGPT到Notion/Obsidian,每个对话自动创建笔记页面。关键对话截图保存,包含完整的prompt和响应,作为最后的保险。
业务连续性方案:建立"AI任务队列",按优先级排序,触限时自动暂停低优先级任务;创建"任务检查点",复杂任务每完成25%保存一次状态;实施"双轨并行",重要项目同时在Plus和API上进行,互为备份。记录"任务耗量指标",每类任务平均消耗多少配额,便于容量规划。通过这些措施,即使突然触限,也能在15分钟内恢复工作状态,确保业务不受影响。
基于使用量的决策树
经过全面分析,我们可以构建清晰的决策框架。使用量决策树:日均<10条选择Plus基础订阅;10-50条采用Plus+备用方案;50-200条转向API方案;>200条考虑Pro或混合部署。这个框架基于总拥有成本(TCO)计算,包含订阅费、时间成本、机会成本等因素。关键决策点:当月度GPT-4使用超过1500条时,API成本开始低于Plus;超过5000条时,即使算上开发成本,API仍然更经济。
细化评估维度:功能需求权重(Canvas 30%、Code Interpreter 25%、DALL-E 20%、Deep Research 15%、基础对话10%);使用时段分布(集中使用扣20分,分散使用加20分);技术能力等级(新手适合Plus,开发者适合API);预算弹性(固定预算选Plus,弹性预算选API);合规要求(严格合规选API,一般使用选Plus)。通过多维度评分,可以得出最适合的方案组合。
不同用户的个性化推荐
根据典型用户画像,提供具体建议。学生/个人学习者:Plus足够,配合免费模型补充,月成本控制在150元内。自由职业者:Plus作为主力,关键项目时临时购买API额度,月成本200-300元。创业团队:3-5个Plus账户共享,建立使用规范,月成本500-800元。中小企业:API为主导,Plus作补充,建立内部AI平台,月成本2000-5000元。大型企业:混合部署策略,敏感数据用私有模型,一般任务用API,创新项目用Plus/Pro。
对于追求便利性的用户,fastgptplus.com提供了简化的订阅流程,支付宝付款、中文客服、稳定连接,适合不想处理技术细节的用户。对于需要大规模API调用的企业,laozhang.ai的专业服务更合适,提供详细的使用报表、灵活的计费方案、以及企业级技术支持。选择的核心不是哪个最便宜,而是哪个最适合你的使用场景和技术能力。
成本优化的终极建议
实现成本最优化需要动态策略。黄金法则:高价值任务用GPT-4,常规任务用GPT-3.5,批量处理用API,实时交互用Plus。具体优化技巧:建立prompt模板库,减少试错消耗;使用prompt压缩技术,同样信息用更少token;批量处理相似任务,提高单次会话效率;定期审计使用日志,识别浪费点。数据显示,优化后可节省30-40%的配额消耗。
未来升级路径规划
ChatGPT的限制政策会持续演变,保持灵活性至关重要。建议的升级路径:第1-3月使用Plus熟悉功能;第4-6月尝试API小规模应用;第7-9月根据需求选择Pro或扩大API;第10-12月建立稳定的混合方案。预留20%预算用于新服务测试,当GPT-5或其他突破性模型发布时,可以快速尝试。记住,ChatGPT Plus的限制不是障碍,而是促使我们更智慧地使用AI工具的机会。通过本文提供的策略和工具,你可以在限制框架内最大化价值,让AI真正成为提升生产力的伙伴。