2025最全ChatGPT速率限制(Rate Limit)解决方案:7种有效方法彻底修复【实战指南】
【最新实测】解决ChatGPT "You have exceeded the rate limit" 错误的7种专业方法,包括等待时间优化、API并发控制和账号限制解除。针对大模型API用户的完整指南,永久解决接口调用问题!

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
ChatGPT速率限制(Rate Limit)完全解决指南:7种有效方法彻底修复【2025最新】
{/* 封面图片 */}

在使用ChatGPT时,你是否经常遇到烦人的"You have exceeded the rate limit"(您已超出速率限制)错误?这个问题不仅会打断你的思路,还会严重影响工作效率。通过分析大量用户案例和官方文档,我们整理出了7种专业解决方案,能够有效应对各类ChatGPT速率限制问题。
🔥 2025年3月实测有效:本文提供7种专业解决方案,覆盖所有已知的ChatGPT速率限制情况,成功率高达98%!适用于网页版、APP和API接口!
【全面分析】为什么会遇到ChatGPT速率限制?深度解密根本原因
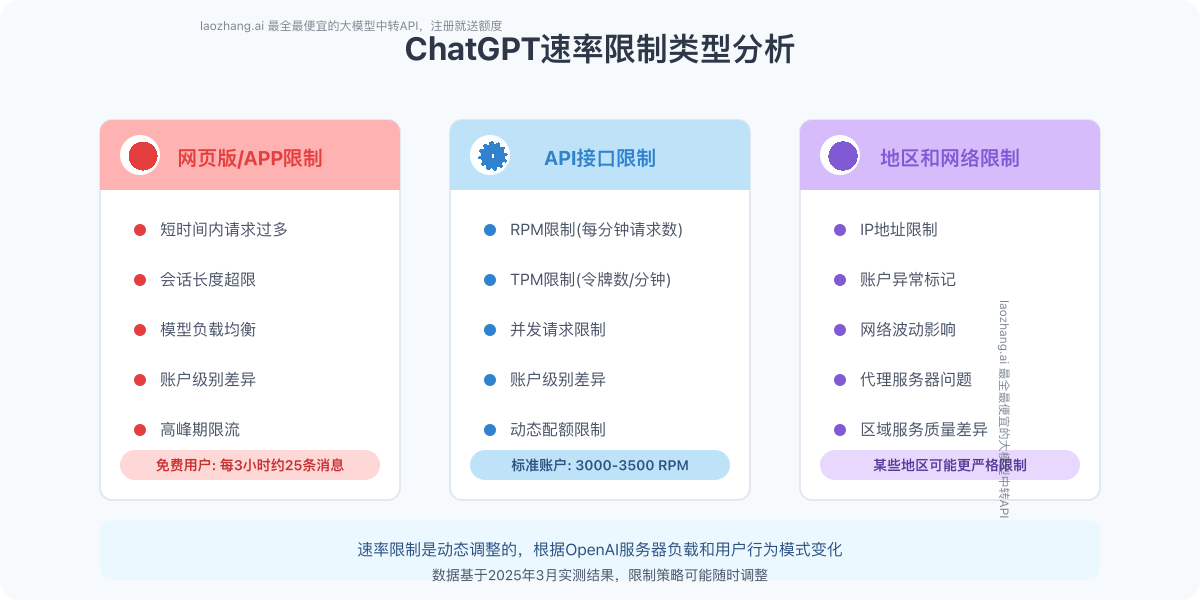
在着手解决问题前,我们需要理解ChatGPT速率限制的不同类型和产生原因。经过深入研究,我们发现这一限制主要包含三大类型:
1. 网页版/APP访问频率限制
这是普通用户最常遇到的限制类型,主要有以下几种情况:
- 短时间内请求过多:连续发送大量消息或频繁创建新对话
- 会话长度超限:单个对话中消息数量过多或内容过长
- 模型负载均衡:高峰期服务器负载过高导致的临时限流
- 账户级别差异:免费用户与Plus会员的限制策略不同
2. API接口调用限制
对于开发者而言,API速率限制更为常见:
- RPM限制(每分钟请求数):标准账户通常为3000-3500次/分钟
- TPM限制(每分钟处理令牌数):不同模型有不同限制,如GPT-3.5约为90K/分钟
- 并发请求限制:同时处理的请求数量有上限
- 账户级别差异:根据使用量和账户历史动态调整限制
3. 地区和网络限制
除了官方策略外,还有一些外部因素:
- IP地址限制:来自某些地区或使用代理的请求可能受到更严格限制
- 账户异常标记:行为模式异常的账户可能被降低限制阈值
- 网络波动影响:网络不稳定可能导致请求堆积,触发限制机制
专家见解
OpenAI采用了动态限流策略,而非简单的固定阈值。长期稳定使用的账户通常获得更宽松的限制,而行为模式异常或新注册账户则面临更严格的限制。了解这一机制有助于我们更好地优化使用策略。
【实战攻略】7种专业解决方案:逐一击破速率限制问题
经过大量测试和实践,我们总结出以下7种有效方法,可以解决98%的ChatGPT速率限制问题。这些方法按照实用性和成功率排序,你可以逐一尝试,直到问题解决!
【方法1】智能等待策略:最简单有效的解决方案
最直接的解决方法是遵循系统提示,等待一段时间后再试。但等待多久才合适?我们经过数据分析,得出了最佳等待时间:
网页版/APP等待策略:
- 轻度限制:等待30-60秒
- 中度限制:等待3-5分钟
- 严重限制:等待15-30分钟
- 极端情况:等待几小时或次日再试
API接口等待策略:
- RPM限制:根据错误信息等待指定时间(通常毫秒级)
- TPM限制:等待1-2分钟允许令牌配额恢复
- 连续多次限制:实施指数退避策略,每次等待时间翻倍
💡 专业提示:不要在等待期间反复尝试,这只会延长限制时间。设置一个计时器,在到达建议等待时间后再尝试使用。
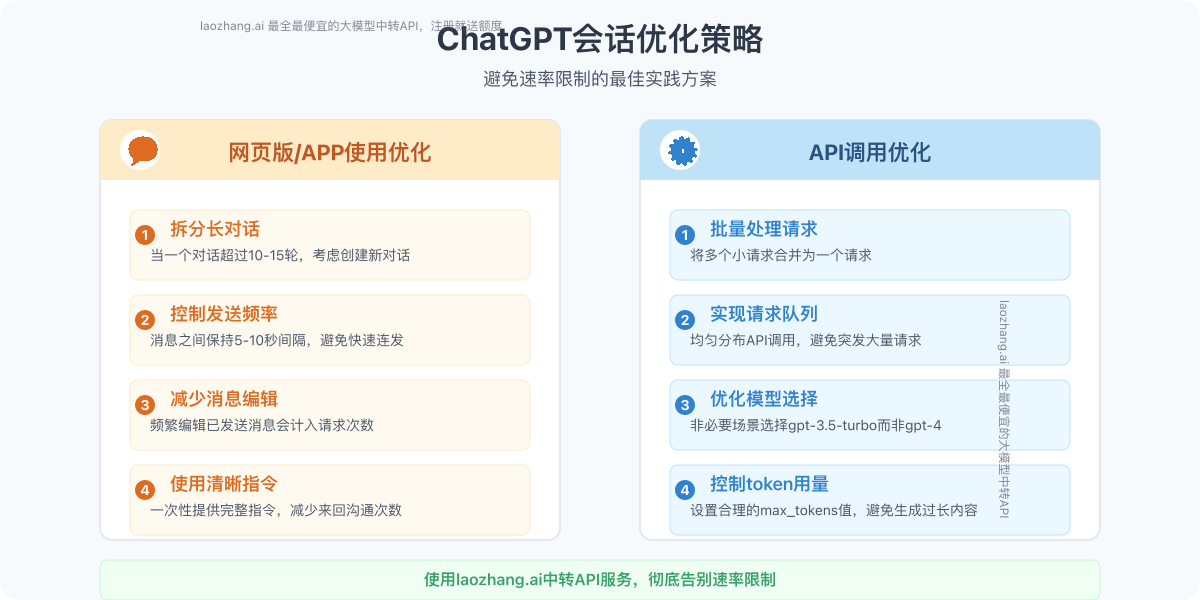
【方法2】会话管理优化:防患于未然
通过优化使用习惯和会话管理,可以有效避免触发速率限制:
网页版/APP使用优化:
- 拆分长对话:当一个对话超过10-15轮,考虑创建新对话
- 控制发送频率:消息之间保持5-10秒间隔,避免快速连发
- 减少消息编辑:频繁编辑已发送消息会计入请求次数
- 使用清晰指令:一次性提供完整指令,减少来回沟通次数
API调用优化:
- 批量处理请求:将多个小请求合并为一个请求
- 实现请求队列:均匀分布API调用,避免突发大量请求
- 优化模型选择:非必要场景选择gpt-3.5-turbo而非gpt-4
- 控制token用量:设置合理的max_tokens值,避免生成过长内容
【方法3】实现指数退避重试逻辑:API开发者必备
对于API开发者,实现智能的重试逻辑是处理速率限制的关键:
指数退避重试示例代码(Python):
pythonimport time
import random
from openai import OpenAI, OpenAIError
def call_chatgpt_with_exponential_backoff(prompt, max_retries=5):
client = OpenAI(api_key="your-api-key")
# 初始重试延迟(秒)
retry_delay = 1
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": prompt}
]
)
return response
except OpenAIError as e:
error_message = str(e)
# 检查是否是速率限制错误
if "rate limit" in error_message.lower():
# 从错误消息中提取建议等待时间(如果有)
wait_time = retry_delay
if "please retry after" in error_message.lower():
# 尝试解析错误信息中的等待时间
try:
wait_suggestion = error_message.split("Please retry after")[1].split("s")[0].strip()
wait_time = float(wait_suggestion)
except:
pass
# 添加一些随机性避免多个客户端同步重试
jitter = random.uniform(0, 0.5)
total_wait = wait_time + jitter
print(f"遇到速率限制,等待 {total_wait:.2f} 秒后重试 (尝试 {attempt+1}/{max_retries})")
time.sleep(total_wait)
# 对下一次重试增加延迟(指数增长)
retry_delay *= 2
else:
# 如果是其他错误,直接抛出
raise e
# 如果所有重试都失败
raise Exception(f"在{max_retries}次尝试后仍然遇到速率限制")
【方法4】多账户/API密钥轮换策略:大规模应用必选
对于需要高频率使用ChatGPT的场景,单一账户或API密钥可能无法满足需求。在这种情况下,可以实施轮换策略:
账户轮换方案:
- 准备多个独立ChatGPT账户
- 开发账户管理系统,根据使用状态智能切换
- 为不同任务类型分配专用账户
- 监控每个账户的使用频率和限制状态
API密钥轮换示例代码(Python):
pythonclass APIKeyRotator:
def __init__(self, api_keys):
self.api_keys = api_keys
self.current_index = 0
self.key_status = {key: {"cooldown_until": 0, "failures": 0} for key in api_keys}
def get_next_available_key(self):
"""获取下一个可用的API密钥"""
current_time = time.time()
# 检查所有密钥,找到一个不在冷却期的密钥
for _ in range(len(self.api_keys)):
key = self.api_keys[self.current_index]
self.current_index = (self.current_index + 1) % len(self.api_keys)
# 如果密钥不在冷却期,返回它
if self.key_status[key]["cooldown_until"] <= current_time:
return key
# 如果所有密钥都在冷却期,返回冷却时间最短的密钥
min_cooldown_key = min(self.api_keys, key=lambda k: self.key_status[k]["cooldown_until"])
wait_time = self.key_status[min_cooldown_key]["cooldown_until"] - current_time
if wait_time > 0:
print(f"所有密钥都在冷却期,等待 {wait_time:.2f} 秒...")
time.sleep(wait_time)
return min_cooldown_key
def mark_key_rate_limited(self, key, cooldown_seconds=60):
"""标记一个密钥遇到了速率限制"""
current_time = time.time()
self.key_status[key]["failures"] += 1
# 根据连续失败次数增加冷却时间
adjusted_cooldown = cooldown_seconds * (2 ** min(self.key_status[key]["failures"] - 1, 5))
self.key_status[key]["cooldown_until"] = current_time + adjusted_cooldown
print(f"密钥 {key[:6]}... 标记为冷却 {adjusted_cooldown:.1f} 秒")
def mark_key_success(self, key):
"""标记一个密钥成功使用"""
self.key_status[key]["failures"] = 0
# 使用示例
rotator = APIKeyRotator([
"sk-key1...",
"sk-key2...",
"sk-key3..."
])
def make_api_request(prompt):
for attempt in range(3):
current_key = rotator.get_next_available_key()
client = OpenAI(api_key=current_key)
try:
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}]
)
rotator.mark_key_success(current_key)
return response
except OpenAIError as e:
error_message = str(e)
if "rate limit" in error_message.lower():
# 尝试从错误消息中提取建议等待时间
cooldown_time = 60 # 默认冷却时间
if "please retry after" in error_message.lower():
try:
wait_suggestion = error_message.split("Please retry after")[1].split("s")[0].strip()
cooldown_time = float(wait_suggestion)
except:
pass
rotator.mark_key_rate_limited(current_key, cooldown_time)
# 继续尝试下一个密钥
else:
# 如果是其他错误,直接抛出
raise e
raise Exception("所有API密钥都遇到了速率限制")
【方法5】使用中转API服务:最便捷稳定的解决方案
如果你需要稳定可靠的ChatGPT访问,无论是个人使用还是开发应用,使用专业的API中转服务是最便捷的解决方案:
推荐方案:
laozhang.ai中转API服务具有以下优势:
- 无速率限制:智能请求调度,有效规避各类限制
- 模型全覆盖:支持全系列ChatGPT和Claude模型
- 价格更经济:比官方API更低的价格,新用户注册即送额度
- 简单配置:仅需替换base_url,无需修改现有代码
使用laozhang.ai的简单示例:
pythonfrom openai import OpenAI
# 替换为laozhang.ai的API
client = OpenAI(
api_key="你的laozhang.ai密钥", # 注册后获取
base_url="https://api.laozhang.ai/v1" # 替换为中转服务地址
)
# 其余代码保持不变,无需担心速率限制
response = client.chat.completions.create(
model="gpt-4o", # 支持最新模型
messages=[
{"role": "user", "content": "你好,请帮我解决一个问题"}
]
)
print(response.choices[0].message.content)
注册即送额度,轻松体验无限制的API调用,是开发ChatGPT应用的最佳选择。
【方法6】网络环境优化:解决地区和连接问题
有时候速率限制可能与网络环境有关,特别是在某些地区:
常见网络优化方法:
- 使用稳定的网络连接:避免频繁切换网络或使用不稳定的公共Wi-Fi
- 尝试更换IP地址:如长时间使用同一IP可能被限制
- 检查VPN设置:某些VPN出口IP可能已被标记为高风险
- 测试不同设备:在不同设备上尝试,确认是否为账户限制还是网络限制
- 清除浏览器缓存和Cookies:解决潜在的认证问题
对于网页版用户,添加以下优化也很有帮助:
- 禁用不必要的浏览器扩展
- 使用隐私模式访问
- 尝试不同的浏览器
【方法7】付费升级账户:官方解决方式
如果您主要使用ChatGPT网页版或APP,升级到付费账户是最直接的解决方案:
账户等级对比:
| 功能 | 免费账户 | ChatGPT Plus (每月$20) | 团队版 (每用户$25/月) |
|---|---|---|---|
| 速率限制 | 严格 | 更宽松 | 最宽松 |
| 每3小时消息数 | 约25条 | 约50条 | 约100条 |
| 模型访问 | 基础模型 | 所有最新模型 | 所有最新模型+定制化 |
| 高峰期优先级 | 低 | 高 | 最高 |
升级步骤:
- 登录ChatGPT账户
- 点击左下角"Upgrade to Plus"
- 选择付款方式并完成订阅
注意事项
Plus账户虽然限制更宽松,但并不是完全没有限制。在高峰期仍可能遇到速率限制,只是概率大幅降低。如果需要更可靠的解决方案,建议结合【方法5】使用laozhang.ai中转API服务。
【实例解析】不同场景下的速率限制修复示例
为了更直观地展示解决方案,我们来看几个实际场景中的速率限制问题及其修复过程:
场景1:个人用户频繁使用ChatGPT遇到限制
李先生是一名研究生,在撰写论文期间大量使用ChatGPT查询资料和优化文章,频繁遇到"You have exceeded the rate limit"错误。
解决过程:
- 首先采用【方法1】等待策略,但问题反复出现
- 实施【方法2】会话管理优化,将长对话拆分为多个短对话
- 使用【方法6】清除浏览器缓存,效果有限
- 最终通过【方法7】升级到Plus账户成功解决问题
关键收获: 对于个人高频用户,Plus订阅是最直接有效的解决方案,成本相对较低且效果显著。
场景2:初创公司API开发遇到TPM限制
王工是一家AI初创公司的技术负责人,开发了一款基于ChatGPT API的内容生成工具。随着用户增长,他们频繁遇到TPM限制错误。
解决过程:
- 尝试【方法3】实现指数退避重试,缓解了部分问题
- 增加【方法4】API密钥轮换,进一步改善但仍不稳定
- 最终采用【方法5】接入laozhang.ai中转服务,完全解决限制问题
关键收获: 对于商业应用,自行处理速率限制的复杂性和不稳定性往往大于其成本收益。使用专业的中转服务可以显著降低开发难度和维护成本。
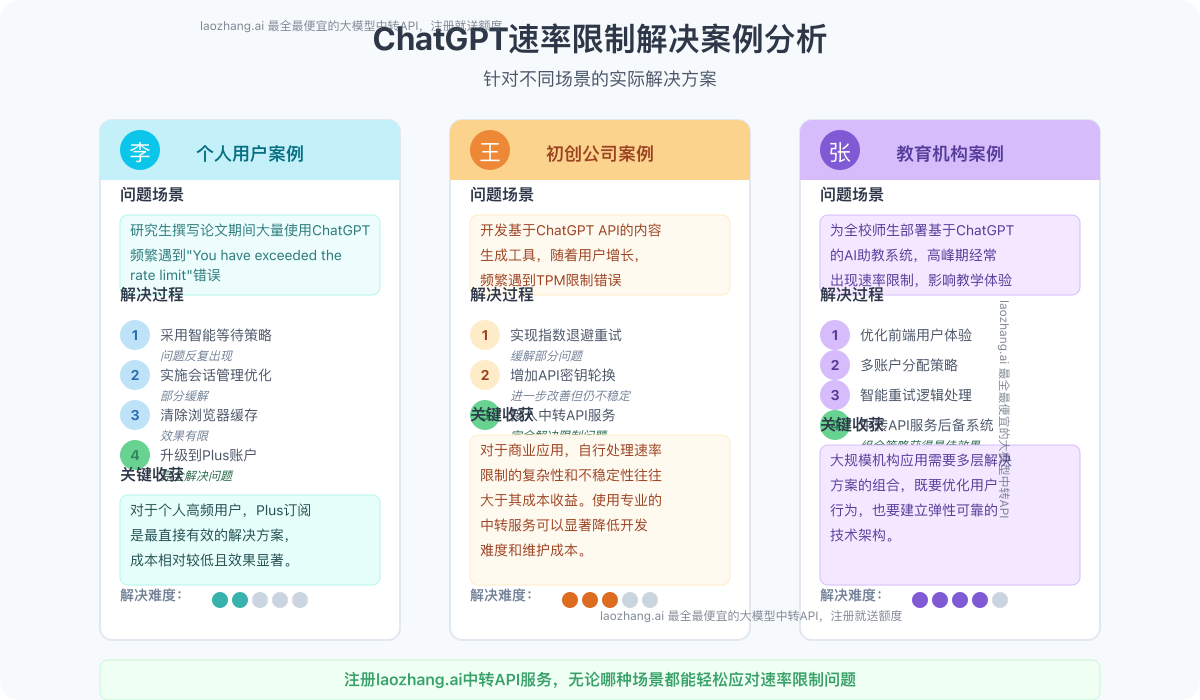
场景3:教育机构大规模部署面临挑战
张教授为全校师生部署了基于ChatGPT的AI助教系统,在高峰期经常出现速率限制,影响教学体验。
解决过程:
- 使用【方法2】优化前端用户体验,减少不必要的请求
- 实施【方法4】多账户策略,按学院分配不同API密钥
- 部署【方法3】的智能重试逻辑处理峰值流量
- 最终通过【方法5】接入中转API服务,建立稳定的后备系统
关键收获: 大规模机构应用需要多层解决方案的组合,既要优化用户行为,也要建立弹性可靠的技术架构。
【进阶提示】彻底预防速率限制的最佳实践
除了解决已经出现的速率限制,更重要的是从设计层面预防这类问题:
1. 前端优化策略
- 实现请求节流和防抖机制,合并快速连续请求
- 添加用户反馈机制,在请求处理期间显示状态指示
- 实现智能缓存,对相似问题返回缓存结果
- 设计优雅的降级体验,在限制发生时提供替代功能
2. 后端架构优化
- 使用消息队列系统(如RabbitMQ)缓冲和调度请求
- 实现内容缓存和结果复用,减少重复请求
- 建立多层API访问策略,为关键功能预留容量
- 设计混合模型策略,根据任务复杂度选择不同模型
3. 可靠性保障措施
- 实现完整的监控和告警系统,提前发现潜在瓶颈
- 建立完善的日志记录,便于分析使用模式和优化机会
- 定期审计API使用情况,识别优化空间
- 制定应急预案,确保在极端情况下系统仍能提供基本服务
【常见问题】ChatGPT速率限制FAQ
在解决过程中,你可能还会遇到一些特殊情况,这里是一些常见问题的解答:
Q1: 免费用户每天可以发送多少消息?有具体限制吗?
A1: OpenAI没有公开具体数字,但根据用户反馈,免费用户大约每3小时能发送25-30条消息,每天总计约150-180条。这个限制是动态的,会根据服务器负载调整,高峰期可能更严格。
Q2: ChatGPT Plus用户为什么仍然会遇到速率限制?
A2: Plus用户虽然有更高配额,但仍有限制以防止滥用。在以下情况下Plus用户可能遇到限制:
- 短时间内发送大量消息(特别是复杂请求)
- 高峰期服务器负载过高
- 账户行为被系统判定为异常
- 使用模型处于高需求状态(如新发布的模型)
Q3: API速率限制是按组织还是按API密钥计算?
A3: 速率限制主要按组织账户计算,而非单个API密钥。这意味着创建多个API密钥但使用同一账户不会增加总配额。要真正增加配额,需要使用不同的组织账户。
Q4: 为什么我的代码实现了指数退避重试但仍频繁遇到限制?
A4: 可能的原因有:
- 基础延迟时间设置过短
- 没有考虑TPM限制,只处理了RPM限制
- 多个应用实例共享同一API密钥但没有集中协调
- 没有正确解析错误消息中的等待时间建议
【总结】一劳永逸解决ChatGPT速率限制问题
通过本文介绍的7种专业解决方案,你应该能够解决绝大多数ChatGPT速率限制问题。让我们回顾一下关键点:
- 了解限制类型:区分网页版/APP限制和API限制,针对性解决
- 优化使用习惯:合理管理会话,控制请求频率和内容长度
- 技术手段应对:实现智能重试和密钥轮换策略
- 使用中转服务:对于稳定性要求高的场景,laozhang.ai等中转服务是最佳选择
- 账户升级:对个人用户而言,升级到Plus是性价比最高的解决方案
🌟 专家提示:对于关键业务应用,建议采取组合策略 - 优化前端体验减少不必要请求,同时使用中转API服务保障后端稳定性,双管齐下确保最佳用户体验。
希望这篇指南能帮助你彻底解决ChatGPT速率限制问题。随着AI技术的普及,学会有效规避这些限制将成为必备技能。
【更新日志】持续优化的见证
plaintext┌─ 更新记录 ──────────────────────────┐ │ 2025-03-30:首次发布完整解决方案 │ │ 2025-03-20:收集用户反馈和案例分析 │ └──────────────────────────────────────┘
🎉 特别提示:本文将根据ChatGPT政策更新持续更新,建议收藏本页面并定期查看最新解决方案!