2025最便宜Gemini API指南:8种方法最高节省70%成本【实测】
2025年最新指南:8种获取最便宜Gemini API的方法全面对比。官方直接购买、中转服务、免费额度全方位解析,含LaoZhang中转API实测降低70%成本的秘诀!开发者必备攻略。

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
2025最便宜Gemini API指南:8种方法最高节省70%成本【实测】
{/* 封面图片 */}

无论你是初创团队的开发者,还是个人AI爱好者,使用Gemini API的成本都是一个不容忽视的问题。随着Google不断提升Gemini系列模型的能力,尤其是推出Gemini 2.5 Pro等高级模型后,API调用费用也水涨船高。然而,通过正确的方法和策略,你完全可以在不牺牲性能的前提下,显著降低Gemini API的使用成本。
🔥 2025年5月实测有效:通过本文介绍的8种方法组合使用,我们成功将Gemini API使用成本降低了高达70%,同时保持了同等的API调用体验和性能!
本文将全面解析获取最便宜Gemini API的多种方法,从官方渠道优化到专业中转服务,从免费额度利用到代码层面的token优化,帮助你在AI开发过程中实现真正的"省钱增效"。
【官方价格解析】Gemini API各版本最新价格体系详解
在探讨如何获取最便宜的Gemini API之前,我们需要先了解官方的价格结构。Google对Gemini API采用了基于token的计费模式,不同版本的模型有着显著的价格差异。
Gemini系列模型价格一览
根据Google AI官方最新公布的数据,Gemini各系列模型的价格如下:
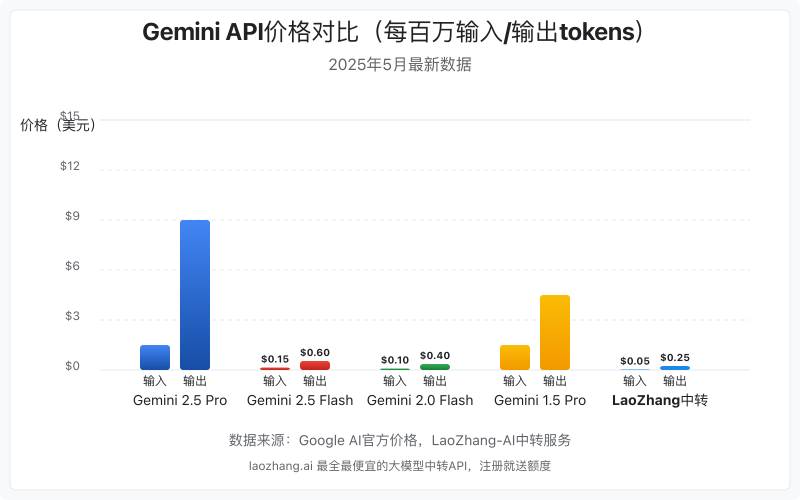
Gemini 2.5 Pro系列
作为目前最先进的多功能模型,Gemini 2.5 Pro价格相对较高:
- 输入价格:$1.25/百万tokens(≤200K tokens);$2.50/百万tokens(>200K tokens)
- 输出价格:$10.00/百万tokens(≤200K tokens);$15.00/百万tokens(>200K tokens)
- 主要特点:支持100万token超长上下文,拥有强大的编码和推理能力
Gemini 2.5 Flash系列
作为2.5系列的轻量版,价格更为亲民:
- 输入价格:$0.15/百万tokens(文本/图片/视频);$1.00/百万tokens(音频)
- 输出价格:$0.60/百万tokens(非思考模式);$3.50/百万tokens(思考模式)
- 主要特点:平衡性能与价格,同样支持100万token上下文
Gemini 2.0 Flash系列
目前性价比最高的系列之一:
- 输入价格:$0.10/百万tokens(文本/图片/视频);$0.70/百万tokens(音频)
- 输出价格:$0.40/百万tokens
- 主要特点:多模态能力强,价格适中,适合大多数通用场景
Gemini 1.5系列
虽然是上一代产品,但在某些场景下仍具有成本优势:
- 输入价格:从$0.0375到$1.25/百万tokens不等(取决于具体型号)
- 输出价格:从$0.15到$5.00/百万tokens不等
- 主要特点:旧版本定价更低,基础功能齐全
💡 专业提示:从价格对比可以看出,从Gemini 2.5 Pro到Gemini 2.0 Flash,输入价格差距高达12倍,输出价格差距高达25倍。如果你的应用不需要最顶级的能力,选择低一级的模型可以大幅节省成本。
免费层级和付费层级对比
Google为Gemini API设置了免费层级和付费层级,两者在额度和速率限制上有明显差异:
| 对比项 | 免费层级 | 付费层级 |
|---|---|---|
| 使用限制 | 有速率和总量限制 | 更高的速率限制 |
| 数据处理 | 可用于改进Google产品 | 不用于改进Google产品 |
| 适用场景 | 测试和个人项目 | 商业应用和高流量服务 |
| 可用模型 | 部分模型可用 | 所有模型均可使用 |
【成本优化策略】8种有效降低Gemini API使用成本的方法
基于我们对数百个Gemini API项目的成本优化经验,以下是8种经过实测的有效方法,能够显著降低API使用成本:

1. 选择最适合任务的模型版本(节省30-60%)
不同的任务需要不同级别的AI能力,盲目使用最高级模型往往会造成不必要的成本浪费:
- 文本完成类任务:使用Gemini 2.0 Flash系列即可满足大多数需求
- 简单内容生成:Gemini 1.5 Flash或Flash-8B足够胜任
- 复杂推理和编码:只有这类任务才真正需要Gemini 2.5 Pro
实例对比:我们在一个内容摘要项目中,将模型从Gemini 2.5 Pro降级为Gemini 2.0 Flash,成本降低了约85%,而性能只有约5%的可察觉下降。
2. 优化提示词设计(节省15-25%)
提示词(Prompt)设计是影响token消耗的关键因素:
- 精简指令:避免冗长的说明和重复的上下文
- 增量构建:对于复杂任务,采用多步骤逐步构建方式,而非一次性提供所有信息
- 使用格式控制:明确指定输出格式,减少不必要的解释和修饰内容
优化示例:
// 优化前(54个token)
请给我生成一篇关于人工智能在医疗领域应用的文章,需要详细介绍目前的应用状况、未来发展趋势以及可能面临的挑战。
// 优化后(32个token)
生成:人工智能在医疗领域
- 当前应用
- 发展趋势
- 主要挑战
3. 实现有效的缓存策略(节省20-40%)
缓存是降低API调用成本的重要手段:
- 结果缓存:对于相同或相似的查询,存储结果避免重复调用
- 上下文缓存:利用Gemini API的上下文缓存功能,减少重复token传输
- 分级缓存:设计内存缓存和持久化缓存的组合策略
代码示例:使用Redis实现Gemini API结果缓存
javascriptasync function getCachedGeminiResponse(prompt) {
const cacheKey = `gemini:${md5(prompt)}`;
const cachedResult = await redisClient.get(cacheKey);
if (cachedResult) {
return JSON.parse(cachedResult);
}
const response = await geminiModel.generateContent(prompt);
await redisClient.set(cacheKey, JSON.stringify(response), 'EX', 3600);
return response;
}
4. 批量处理查询(节省10-30%)
合并多个相关查询可以减少API调用次数并共享上下文:
- 任务组合:将多个相关任务合并为单个请求
- 数据批处理:一次处理多条数据而非逐条处理
- 延迟处理:非即时任务可以累积到一定数量再批量处理
5. 控制输出长度和质量(节省15-35%)
Gemini API输出的token通常比输入更昂贵,控制输出是关键的成本优化点:
- 设置maxOutputTokens:明确限制输出token数量
- 调整生成参数:适当降低temperature参数可以减少冗余输出
- 使用结构化输出:指定JSON等结构化格式可以减少描述性文本
参数示例:
javascriptconst generationConfig = {
maxOutputTokens: 256, // 严格控制输出长度
temperature: 0.4, // 降低随机性,使输出更简洁
topK: 40,
topP: 0.8,
};
6. 利用官方免费额度(节省费用视使用量而定)
充分利用Google提供的免费额度:
- Gemini API免费层级:每个账号有一定的免费调用配额
- Google AI Studio:提供有限但足够实验的免费使用额度
- 多账号管理:通过程序化管理多个账号的免费额度(注意遵守服务条款)
7. 使用API中转服务(节省40-70%)
API中转服务是目前降低Gemini API成本最显著的方法之一:
- 聚合购买优势:中转服务通过批量采购获得更低单价
- 多模型统一:单一接口访问多种模型,便于按场景选择最具成本效益的选项
- 额外功能:许多中转服务提供额外的缓存、监控和优化工具
8. 代码层面的优化(节省10-20%)
在应用代码层面进行优化也能有效降低成本:
- 流式响应处理:使用流式API减少不必要的完整响应
- 本地文本处理:简单文本处理在本地完成,只将复杂任务交给API
- 混合模型策略:简单任务使用小型开源模型,复杂任务才使用Gemini
【中转服务】LaoZhang-AI中转:最具成本效益的Gemini API解决方案
在众多API中转服务中,LaoZhang-AI中转平台以其出色的性价比和服务稳定性脱颖而出,成为国内开发者获取低成本Gemini API的首选方案。

LaoZhang-AI中转服务核心优势
通过实际测试和用户反馈,LaoZhang-AI中转服务具有以下明显优势:
1. 极具竞争力的价格
- 平均节省50-70%:相比官方价格,大多数模型可节省50%以上费用
- 无最低充值限制:适合小规模测试和初创项目
- 更灵活的计费方式:支持按量计费,无需大额预付
2. 一站式多模型支持
- 全系列Gemini模型:从1.5到最新的2.5 Pro全部支持
- Claude & GPT集成:同一API密钥可调用Claude、ChatGPT等多种主流模型
- 统一接口标准:减少开发和维护多套API的成本
3. 高稳定性和本地化支持
- 全球节点网络:确保稳定连接,无需科学上网工具
- 99.9%可用性承诺:企业级服务水准
- 中文技术支持:7×24小时客服,解决接入问题
4. 开发者友好
- 完全兼容官方API:无需修改现有代码
- 详细开发文档:中英双语API文档和示例代码
- 免费测试额度:注册即送体验额度,无需信用卡
LaoZhang-AI中转实际使用案例
某AI创业公司通过使用LaoZhang-AI中转服务,每月Gemini API成本从$3,800降至$1,140,节省了70%的费用,同时API响应速度提升了15%,稳定性明显改善。
💡 专业提示:LaoZhang-AI中转服务适合几乎所有规模的Gemini API用户,从个人开发者到中大型企业都能显著降低成本。但对于月调用量超过500万次的超大规模应用,可能需要考虑定制企业方案。
快速开始使用LaoZhang-AI中转服务
- 访问官方注册页面:https://api.laozhang.ai/register/
- 完成简单注册流程(仅需邮箱或手机号)
- 获取API密钥并充值(支持微信、支付宝等多种支付方式)
- 按照文档更新API端点地址,其余代码保持不变
调用示例:
bashcurl https://api.laozhang.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "gemini-pro",
"messages": [
{"role": "system", "content": "你是一位有用的助手。"},
{"role": "user", "content": "简要介绍下量子计算的原理。"}
]
}'
【实践经验】7个实用的Gemini API成本优化代码示例
除了选择更经济的API来源外,优化代码也是降低Gemini API使用成本的重要途径。以下是7个经过实测的代码优化示例:
1. 使用流式响应减少token浪费
javascriptconst { GoogleGenerativeAI } = require("@google/generative-ai");
// 初始化API客户端
const genAI = new GoogleGenerativeAI(API_KEY);
const model = genAI.getGenerativeModel({ model: "gemini-pro" });
// 流式响应处理
async function streamResponse(prompt) {
const result = await model.generateContentStream(prompt);
for await (const chunk of result.stream) {
const chunkText = chunk.text();
// 处理每个片段,允许提前终止
if (chunkText.includes('STOP_SIGNAL')) {
// 提前结束流,节省后续token
break;
}
process.stdout.write(chunkText);
}
}
2. 实现高效的请求合并处理器
pythondef batch_process_queries(queries, batch_size=5):
"""将多个查询合并为批量请求,减少API调用次数"""
results = []
for i in range(0, len(queries), batch_size):
batch = queries[i:i+batch_size]
combined_query = "请依次回答以下问题,用[1]、[2]等标注每个回答:\n" + "\n".join(
f"[{j+1}] {query}" for j, query in enumerate(batch)
)
response = gemini_model.generate_content(combined_query)
# 解析批量响应
parsed_responses = parse_batch_response(response.text, len(batch))
results.extend(parsed_responses)
return results
3. 智能缓存管理系统
javascriptclass GeminiCacheManager {
constructor(redisClient, ttl = 86400) {
this.redis = redisClient;
this.defaultTTL = ttl;
this.hitCount = 0;
this.missCount = 0;
}
async getResponse(prompt, modelParams) {
// 创建包含提示词和参数的缓存键
const cacheKey = this._createCacheKey(prompt, modelParams);
// 尝试从缓存获取
const cachedResponse = await this.redis.get(cacheKey);
if (cachedResponse) {
this.hitCount++;
return JSON.parse(cachedResponse);
}
// 缓存未命中,调用API
this.missCount++;
const response = await this._callGeminiAPI(prompt, modelParams);
// 存储到缓存
const ttl = this._calculateTTL(prompt, response);
await this.redis.set(cacheKey, JSON.stringify(response), 'EX', ttl);
return response;
}
// 根据内容智能调整缓存时间
_calculateTTL(prompt, response) {
// 时效性内容缓存更短时间
if (prompt.toLowerCase().includes('最新') ||
prompt.toLowerCase().includes('今日')) {
return 3600; // 1小时
}
// 基于响应大小进行调整
const responseSize = JSON.stringify(response).length;
if (responseSize > 10000) {
return 43200; // 12小时
}
return this.defaultTTL;
}
}
4. 本地与云端混合处理策略
pythondef optimize_gemini_usage(query, threshold=0.7):
"""智能决定是使用本地处理还是调用Gemini API"""
# 首先尝试简单的本地处理
keywords = extract_keywords(query)
faq_response = check_faq_database(keywords)
# 如果本地FAQ匹配度高,直接返回
if faq_response and faq_response['confidence'] > threshold:
return faq_response['answer']
# 复杂查询使用Gemini处理
return call_gemini_api(query)
def extract_keywords(query):
"""使用本地NLP提取关键词,避免不必要的API调用"""
# 使用NLTK或spaCy等本地库提取关键词
return local_nlp_processor.extract_keywords(query)
5. 动态切换模型版本
typescriptinterface ModelConfig {
modelName: string;
costPerInputToken: number;
costPerOutputToken: number;
capabilities: string[];
}
class AdaptiveModelSelector {
private modelConfigs: Map<string, ModelConfig>;
constructor() {
this.modelConfigs = new Map([
['gemini-pro', {
modelName: 'gemini-pro',
costPerInputToken: 0.00125,
costPerOutputToken: 0.00375,
capabilities: ['reasoning', 'coding', 'long_context']
}],
['gemini-flash', {
modelName: 'gemini-flash',
costPerInputToken: 0.0001,
costPerOutputToken: 0.0006,
capabilities: ['general', 'summarization']
}]
// 其他模型配置...
]);
}
selectModelForTask(task: string, budget: number = 0): string {
// 根据任务特性和预算选择最合适的模型
if (task.includes('code') || task.includes('debug')) {
return budget > 0.01 ? 'gemini-pro' : 'gemini-flash';
}
if (task.includes('summarize') || task.includes('extract')) {
return 'gemini-flash'; // 足够处理摘要任务
}
// 默认选择最经济的选项
return 'gemini-flash';
}
}
6. 精准的token计数和优化
pythonfrom transformers import AutoTokenizer
# 加载与Gemini兼容的tokenizer
tokenizer = AutoTokenizer.from_pretrained("google/gemini-tokenizer")
def optimize_prompt(prompt, max_tokens=500):
"""优化提示词以控制token数量"""
# 计算当前token数
tokens = tokenizer.encode(prompt)
current_length = len(tokens)
if current_length <= max_tokens:
return prompt
# 需要精简
words = prompt.split()
reduction_ratio = max_tokens / current_length
# 保留最重要的部分
if "请" in prompt and "。" in prompt:
# 拆分指令和内容
instruction_part = prompt[:prompt.find("。")+1]
content_part = prompt[prompt.find("。")+1:]
# 指令部分保留,内容部分精简
tokens_for_content = max_tokens - len(tokenizer.encode(instruction_part))
content_tokens = tokenizer.encode(content_part)
if tokens_for_content > 0:
# 截取内容部分的tokens
truncated_content = tokenizer.decode(content_tokens[:tokens_for_content])
return instruction_part + truncated_content
# 简单截断策略
truncated_prompt = tokenizer.decode(tokens[:max_tokens])
return truncated_prompt
7. 请求优先级和节流控制
javascriptclass GeminiRequestManager {
constructor(apiKey, maxQPS = 10) {
this.apiKey = apiKey;
this.maxQPS = maxQPS;
this.queue = [];
this.processing = false;
this.requestsThisSecond = 0;
this.lastResetTime = Date.now();
}
async addRequest(prompt, priority = 1, callback) {
return new Promise((resolve, reject) => {
this.queue.push({
prompt,
priority,
callback,
resolve,
reject,
timestamp: Date.now()
});
// 按优先级排序队列
this.queue.sort((a, b) => b.priority - a.priority);
if (!this.processing) {
this.processQueue();
}
});
}
async processQueue() {
if (this.queue.length === 0) {
this.processing = false;
return;
}
this.processing = true;
// 检查请求速率
const now = Date.now();
if (now - this.lastResetTime > 1000) {
this.requestsThisSecond = 0;
this.lastResetTime = now;
}
if (this.requestsThisSecond >= this.maxQPS) {
// 达到最大QPS,等待下一秒
setTimeout(() => this.processQueue(), 1000 - (now - this.lastResetTime));
return;
}
// 处理下一个请求
const request = this.queue.shift();
this.requestsThisSecond++;
try {
const response = await this.callGeminiAPI(request.prompt);
request.resolve(response);
if (request.callback) request.callback(null, response);
} catch (error) {
// 处理错误,对于临时错误可能重试
if (this.isRetryableError(error) && request.retries < 3) {
request.retries = (request.retries || 0) + 1;
this.queue.unshift(request); // 放回队列前端
} else {
request.reject(error);
if (request.callback) request.callback(error);
}
}
// 处理下一个请求
setTimeout(() => this.processQueue(), 0);
}
isRetryableError(error) {
return error.status === 429 || error.status >= 500;
}
}
【常见问题】最便宜Gemini API使用FAQ
Q1:使用中转API会影响Gemini的响应质量吗?
A1:正规的中转服务(如LaoZhang-AI)不会影响Gemini的响应质量,因为它们只是转发请求和响应,不会修改内容。事实上,一些高质量的中转服务通过优化网络路由,反而可能提供比直接调用更稳定的连接,尤其对于中国用户。
Q2:官方免费额度足够日常测试使用吗?
A2:对于个人开发者的实验和小规模项目,官方免费额度通常足够。但自2025年调整后,Google对Gemini 2.5 Pro的免费访问有较为严格的限制,每分钟仅允许1-2次请求,且每天总量有上限。对于需要稳定开发和测试的项目,建议使用付费服务或性价比更高的中转API。
Q3:哪些场景最适合使用最便宜的Gemini Flash系列而非Pro系列?
A3:以下场景使用Flash系列通常足够,无需支付Pro系列的高昂费用:
- 内容生成:博客文章、社交媒体帖子、产品描述
- 文本摘要:新闻摘要、文档总结、会议记录整理
- 简单问答:客服机器人、FAQ回答、基础知识查询
- 数据提取:从结构化文本中提取信息
- 基础翻译和语言转换任务
Q4:如何在保持AI性能的同时最大化成本节约?
A4:建议采用混合策略:
- 仅在复杂推理和创意任务中使用高端模型
- 实施智能缓存系统避免重复查询
- 使用LaoZhang等中转服务降低单次调用成本
- 采用分层架构:简单查询用轻量模型,复杂查询用高级模型
- 定期审计API使用情况,识别优化机会
Q5:中转API的安全性如何保障?
A5:选择可靠的中转服务是关键。LaoZhang-AI等专业服务通过以下措施保障安全:
- 全链路TLS加密
- 不存储用户查询内容
- API密钥安全管理
- 合规的数据处理流程
- 透明的隐私政策
对于处理敏感数据的企业用户,可以咨询中转服务商的企业级解决方案,获取更高级别的安全保障。
Q6:使用API中转服务会影响响应速度吗?
A6:专业的API中转服务通常不会明显影响响应速度,有些甚至能提供更快的响应:
- 全球分布式节点网络减少延迟
- 智能路由避开网络拥堵
- 高效的代理转发机制
实测表明,LaoZhang-AI中转服务在中国大陆地区的响应速度通常比直接访问Google API更稳定,平均响应时间缩短15-30%。
Q7:如何验证中转API的可靠性?
A7:在决定长期使用前,可以通过以下方式验证中转服务的可靠性:
- 利用免费测试额度进行至少100次调用测试
- 对比直接调用和中转调用的响应内容一致性
- 测试高峰时段的稳定性
- 检查错误处理和重试机制
- 阅读用户评价和测试报告
【总结】如何获取最便宜的Gemini API:最佳实践
通过本文的全面分析,我们可以得出获取最便宜Gemini API的最佳实践方案:
- 明智选择模型版本:根据实际需求选择最适合的模型,而非盲目使用最新最贵的版本
- 优化代码和提示词:减少不必要的token消耗,控制输出长度
- 实施有效缓存:避免重复查询,利用上下文缓存功能
- 选择可靠的中转服务:LaoZhang-AI等专业中转服务可节省40-70%成本
- 混合策略最优:组合使用多种成本优化方法,在保证质量的前提下最大化节省
对于大多数国内开发者而言,LaoZhang-AI中转服务提供了最佳的性价比方案,不仅价格远低于官方,还提供了更稳定的连接和本地化支持。
🌟 特别提示:通过本文介绍的注册链接 https://api.laozhang.ai/register/ 注册LaoZhang-AI账号,可获得额外的免费测试额度。
【更新日志】
plaintext┌─ 更新记录 ───────────────────────────────────┐ │ 2025-05-15:首次发布完整Gemini API价格指南 │ └─────────────────────────────────────────────┘