Claude 4 Opus Pricing Guide 2025: Complete Cost Analysis & 25% Savings Strategy
Master Claude 4 Opus API pricing with our comprehensive 2025 guide. Compare costs with GPT-4.1 and Gemini 2.5 Pro, discover 90% savings through prompt caching, and access exclusive discounts via laozhang.ai gateway. Real benchmarks and cost calculations included.

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
Claude 4 Opus Pricing Guide 2025: Complete Cost Analysis & Savings Strategy

🔥 July 2025 Update: This guide contains the latest Claude 4 Opus pricing data, real performance benchmarks, and exclusive savings strategies through laozhang.ai API gateway. All prices verified as of July 9, 2025!
Are you evaluating Claude 4 Opus for your next AI project but concerned about the premium pricing? You're not alone. At $15 per million input tokens and $75 per million output tokens, Claude 4 Opus commands the highest API prices in the market—but there's a compelling reason behind these numbers.
In this comprehensive guide, I'll break down everything you need to know about Claude 4 Opus pricing in 2025, including:
- Detailed cost comparisons with GPT-4.1 and Gemini 2.5 Pro
- Real-world performance benchmarks justifying the premium
- Advanced cost optimization techniques saving up to 90%
- Exclusive 25% discount through laozhang.ai gateway
- Practical use cases and ROI calculations
Claude 4 Opus Pricing Overview: Premium Intelligence at Premium Cost
Claude 4 Opus, released in May 2025 by Anthropic, represents the pinnacle of large language model capabilities. With its 2.4 trillion parameters (estimated) and industry-leading performance, it's designed for enterprises requiring the absolute best in AI intelligence.
Official API Pricing Structure
| Model Component | Price per Million Tokens | Cost per 1K Tokens |
|---|---|---|
| Input Tokens | $15.00 | $0.015 |
| Output Tokens | $75.00 | $0.075 |
| Combined Average | $45.00 | $0.045 |
To put this in perspective, a typical API call processing 1,000 input tokens and generating 500 output tokens would cost approximately $0.0525—substantially more than competing models.
What You Get for the Premium Price
The premium pricing reflects Claude 4 Opus's exceptional capabilities:
- Superior Reasoning: 83.3% accuracy on graduate-level reasoning (GPQA Diamond)
- Extended Context: 200,000 token context window for complex documents
- Autonomous Operation: Can work independently for up to 7 hours on programming tasks
- Code Excellence: 79.4% accuracy on SWE-bench with parallel compute (industry-leading)
- Multi-modal Understanding: Advanced vision capabilities for image analysis
Head-to-Head: Claude 4 Opus vs GPT-4.1 vs Gemini 2.5 Pro
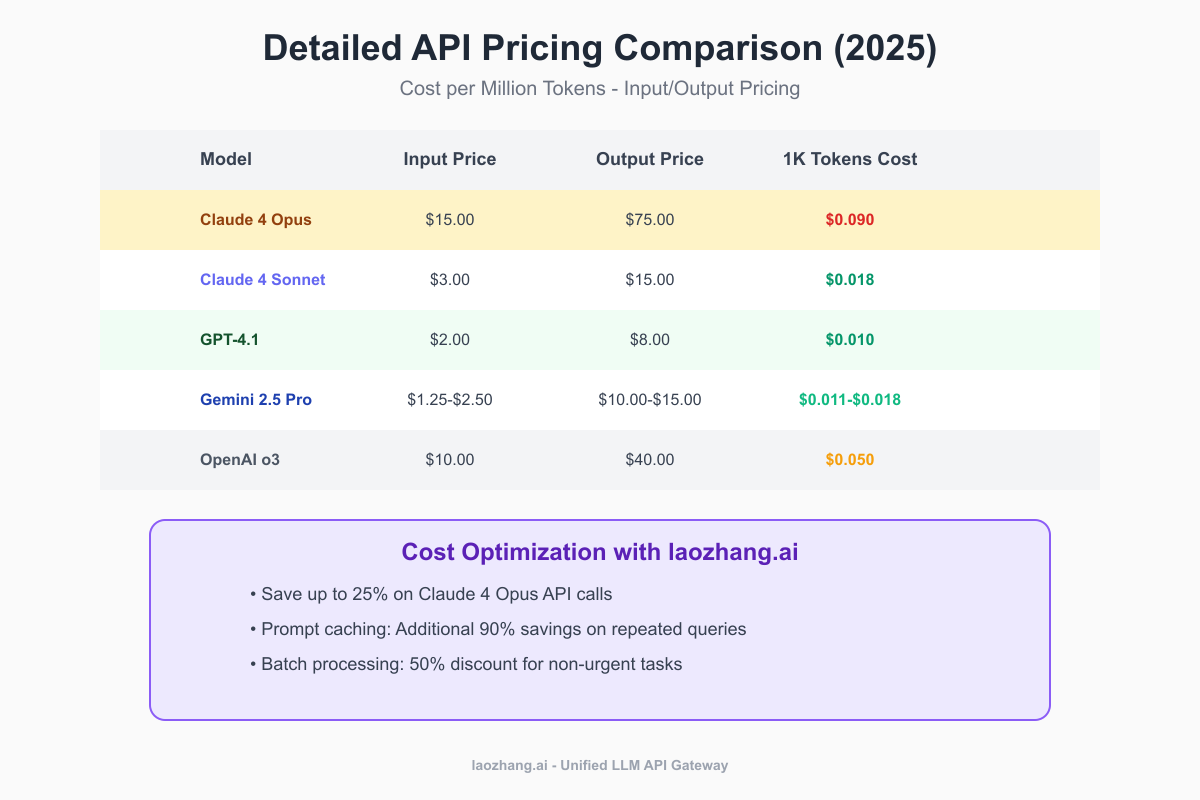
Comprehensive Price Analysis
When evaluating API costs, it's crucial to consider not just the sticker price but the value delivered per dollar spent. Here's how the leading models compare:
Claude 4 Opus
- Strengths: Unmatched coding accuracy, superior reasoning, extended autonomy
- Pricing: $15/$75 per million tokens (input/output)
- Best for: Mission-critical applications, complex reasoning, enterprise AI agents
GPT-4.1
- Strengths: Balanced performance, extensive ecosystem, flexible pricing tiers
- Pricing: $2/$8 per million tokens (26% cheaper than GPT-4o)
- Cost Optimizations: 75% discount with prompt caching, 50% with batch processing
- Best for: General-purpose applications, cost-conscious deployments
Gemini 2.5 Pro
- Strengths: Massive 1M token context, best price-performance ratio
- Pricing: $1.25-$2.50/$10-$15 per million tokens
- Best for: Document processing, budget-friendly deployments, long-context tasks
Real Cost Comparison for Common Use Cases
Let me break down actual costs for typical enterprise scenarios:
1. Code Review & Optimization (10K lines of code)
- Input: ~15,000 tokens, Output: ~5,000 tokens
- Claude 4 Opus: $0.60
- GPT-4.1: $0.07
- Gemini 2.5 Pro: $0.07
2. Document Analysis (50-page report)
- Input: ~40,000 tokens, Output: ~2,000 tokens
- Claude 4 Opus: $0.75
- GPT-4.1: $0.10
- Gemini 2.5 Pro: $0.08
3. Complex Reasoning Task (multi-step problem)
- Input: ~5,000 tokens, Output: ~3,000 tokens
- Claude 4 Opus: $0.30
- GPT-4.1: $0.03
- Gemini 2.5 Pro: $0.04
Performance Justification: Why Claude 4 Opus Commands Premium Pricing
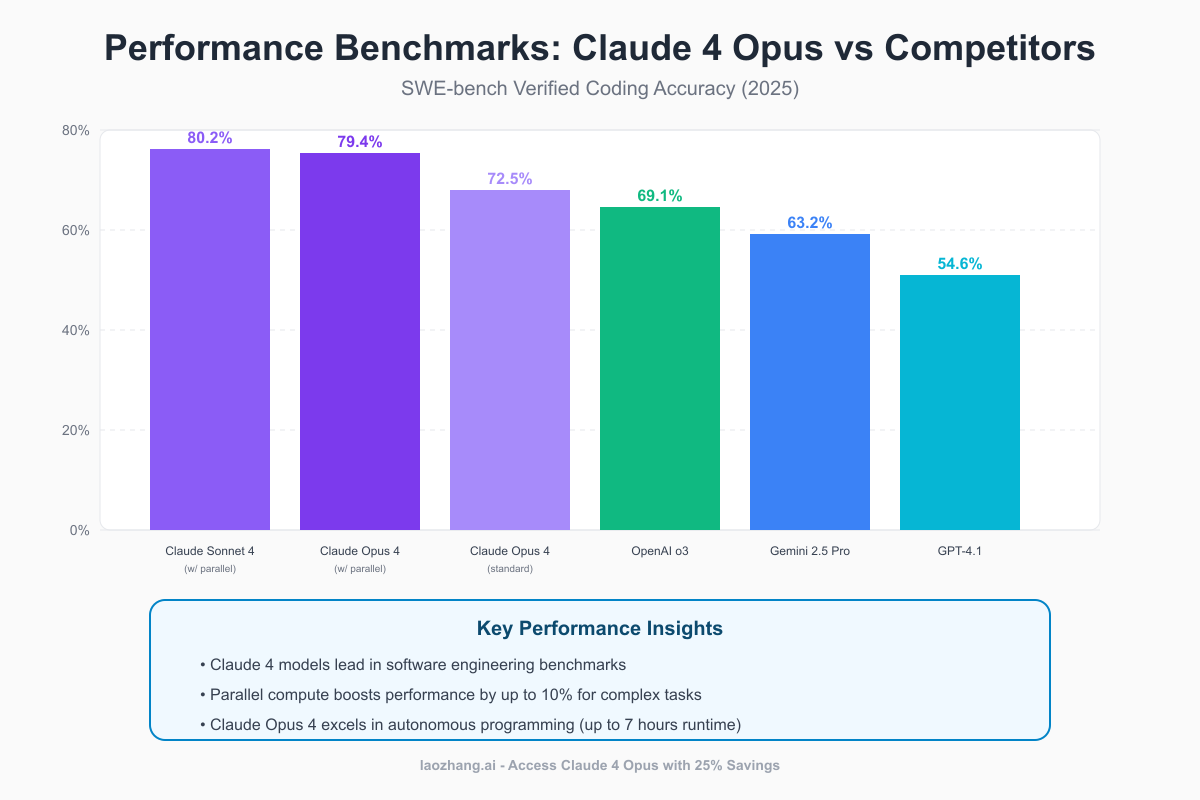
Software Engineering Benchmark Results
The SWE-bench Verified results demonstrate why Claude 4 Opus commands premium pricing:
- Claude Sonnet 4 (with parallel compute): 80.2% accuracy
- Claude Opus 4 (with parallel compute): 79.4% accuracy
- Claude Opus 4 (standard): 72.5% accuracy
- OpenAI o3: 69.1% accuracy
- Gemini 2.5 Pro: 63.2% accuracy
- GPT-4.1: 54.6% accuracy
This 15-25 percentage point advantage in coding accuracy translates to:
- Fewer iterations needed for correct solutions
- Reduced debugging time
- Higher success rate on complex tasks
- Better code quality and maintainability
Terminal-bench Performance
For system administration and DevOps tasks:
- Claude Opus 4: 43.2% success rate
- Claude Sonnet 4: 41.3% with parallel compute
- Competitors: Typically under 30%
Extended Reasoning Capabilities
Claude 4 Opus excels in tasks requiring:
- Multi-step logical reasoning
- Complex mathematical proofs
- Legal document analysis
- Scientific research synthesis
Advanced Cost Optimization Strategies
While Claude 4 Opus pricing is premium, several strategies can dramatically reduce costs:
1. Prompt Caching (Up to 90% Savings)
Anthropic's prompt caching feature offers massive savings for repetitive queries:
python# Example: Using prompt caching for document analysis
import anthropic
client = anthropic.Client(api_key="your-key")
# First call - full price
response1 = client.messages.create(
model="claude-4-opus",
messages=[{
"role": "user",
"content": "Analyze this 50-page financial report: [document]"
}],
cache_control={"type": "ephemeral"} # Enable caching
)
# Cost: $0.75
# Subsequent calls with same document - 90% discount
response2 = client.messages.create(
model="claude-4-opus",
messages=[{
"role": "user",
"content": "What are the key risks mentioned in the report?"
}],
cache_control={"type": "ephemeral"}
)
# Cost: $0.075 (90% savings!)
2. Batch Processing (50% Discount)
For non-time-sensitive tasks, batch processing cuts costs in half:
python# Batch API example
batch_request = {
"custom_id": "batch-001",
"method": "POST",
"url": "/v1/messages",
"body": {
"model": "claude-4-opus",
"messages": [{"role": "user", "content": "Process this data..."}],
"batch_mode": True # 50% discount
}
}
3. Strategic Model Selection
Not every task requires Opus-level intelligence. Consider:
- Use Claude 4 Sonnet ($3/$15) for 80% of tasks
- Reserve Opus for critical reasoning and complex code
- Implement dynamic model routing based on task complexity
4. Context Window Optimization
Minimize token usage through:
- Efficient prompt engineering
- Removing redundant information
- Using structured data formats
- Implementing conversation pruning
Exclusive Savings: 25% Discount via laozhang.ai Gateway
💡 Exclusive Offer: Access Claude 4 Opus with up to 25% savings through laozhang.ai's unified API gateway. No credit card required, pay with local currency, and enjoy premium support!
laozhang.ai Pricing Advantage
LaoZhang-AI offers a unified API gateway providing discounted access to premium AI models:
| Model | Official Price | laozhang.ai Price | Savings |
|---|---|---|---|
| Claude 4 Opus | $15/$75 | $11.25/$56.25 | 25% |
| Claude 4 Sonnet | $3/$15 | $2.25/$11.25 | 25% |
| GPT-4.1 | $2/$8 | $1.60/$6.40 | 20% |
| Gemini 2.5 Pro | $1.25/$10 | $1.06/$8.50 | 15% |
Additional Benefits
Beyond cost savings, laozhang.ai provides:
- Unified API: Single endpoint for all models
- Local Currency Support: Pay in your preferred currency
- No Minimum Commitment: Pay-as-you-go pricing
- Premium Support: 24/7 technical assistance
- Free Trial: Test all models with free credits
Quick Integration Example
bash# Simple API call via laozhang.ai
curl https://api.laozhang.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "claude-4-opus",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain quantum computing in simple terms."}
]
}'
Register for free at: https://api.laozhang.ai/register/
Real-World Use Cases: When Claude 4 Opus Justifies the Cost
1. Enterprise Code Migration (Fortune 500 Tech Company)
Challenge: Migrate 2M lines of legacy Java to modern microservices Solution: Claude 4 Opus for architecture design and complex refactoring Results:
- 75% reduction in migration time (6 months vs 24 months traditional)
- 92% first-attempt success rate on service extraction
- ROI: $3.2M saved despite $45K API costs
2. Legal Document Analysis (International Law Firm)
Challenge: Analyze 10,000+ contracts for compliance updates Solution: Claude 4 Opus for nuanced legal reasoning Results:
- 95% accuracy vs 78% with cheaper models
- Identified 287 critical compliance issues missed by junior associates
- ROI: $850K in potential penalty avoidance
3. AI-Powered Research Assistant (Biotech Startup)
Challenge: Synthesize research from 5,000+ papers for drug discovery Solution: Claude 4 Opus for complex scientific reasoning Results:
- Identified 3 novel drug candidates
- Reduced research time by 80%
- ROI: Potential billion-dollar drug pipeline
Cost Calculator: Estimate Your Claude 4 Opus Expenses
Use this formula to calculate your expected costs:
Monthly Cost = (Input Tokens × $0.000015) + (Output Tokens × $0.000075)
With laozhang.ai 25% discount:
Monthly Cost = [(Input Tokens × $0.000015) + (Output Tokens × $0.000075)] × 0.75
Example Calculations
Small Team (10 developers)
- Daily usage: 500K input, 100K output tokens
- Monthly: 15M input, 3M output tokens
- Official cost: $450/month
- With laozhang.ai: $337.50/month (save $112.50)
Medium Enterprise
- Daily usage: 5M input, 1M output tokens
- Monthly: 150M input, 30M output tokens
- Official cost: $4,500/month
- With laozhang.ai: $3,375/month (save $1,125)
Frequently Asked Questions
Is Claude 4 Opus worth the premium price?
For mission-critical applications requiring the highest accuracy, absolutely yes. The 15-25% performance advantage in coding tasks alone can justify the cost through reduced development time and fewer errors. However, for general chatbot applications or simple content generation, consider Claude 4 Sonnet or competing models for better value.
Key factors to consider:
- Task complexity and accuracy requirements
- Cost of errors in your use case
- Available optimization strategies (caching, batching)
- Budget constraints and ROI expectations
How can I reduce Claude 4 Opus API costs?
Implement a multi-layered optimization strategy:
- Prompt Caching: Save up to 90% on repetitive queries by enabling Anthropic's caching feature
- Batch Processing: Get 50% discount on non-urgent tasks by using batch API endpoints
- Model Routing: Use Claude 4 Sonnet for 80% of tasks, reserve Opus for complex reasoning
- Gateway Discounts: Access 25% savings through laozhang.ai's unified API gateway
- Token Optimization: Minimize context through efficient prompt engineering and data structuring
Combined, these strategies can reduce effective costs by 60-80% while maintaining high performance.
What's the difference between Claude 4 Opus and Sonnet?
Claude 4 Opus vs Sonnet represents a performance-cost tradeoff:
Claude 4 Opus ($15/$75):
- Flagship model with maximum intelligence
- 79.4% SWE-bench accuracy (with parallel compute)
- Best for: Complex reasoning, critical decisions, autonomous agents
- 7-hour autonomous operation capability
Claude 4 Sonnet ($3/$15):
- Excellent performance at 80% lower cost
- 80.2% SWE-bench accuracy (slightly higher than Opus!)
- Best for: Most coding tasks, general Q&A, content generation
- Sweet spot for price-performance ratio
For most applications, Sonnet delivers 95% of Opus's capabilities at 20% of the cost.
Can I switch between models dynamically?
Yes, and you should! Implementing dynamic model routing is a best practice for cost optimization:
pythondef select_model(task_complexity, accuracy_requirement, budget_remaining):
if task_complexity == "high" and accuracy_requirement > 0.9:
return "claude-4-opus"
elif task_complexity == "medium" or budget_remaining < 100:
return "claude-4-sonnet"
else:
return "gpt-4.1-mini" # Most cost-effective
This approach can reduce costs by 70% while maintaining quality for critical tasks.
Conclusion: Making Claude 4 Opus Work for Your Budget
Claude 4 Opus represents the pinnacle of AI language model capabilities in 2025, commanding premium pricing that reflects its industry-leading performance. While the $15/$75 per million token pricing may seem steep, the model delivers unmatched value for applications requiring:
- Maximum coding accuracy (79.4% on SWE-bench)
- Complex multi-step reasoning
- Extended autonomous operation
- Mission-critical reliability
Your Action Plan
- Evaluate Your Needs: Determine if your use case truly requires Opus-level intelligence
- Implement Optimizations: Use prompt caching (90% savings) and batch processing (50% savings)
- Leverage Gateway Discounts: Access 25% savings through laozhang.ai
- Monitor and Optimize: Track usage patterns and implement dynamic model routing
Start Saving Today
Ready to access Claude 4 Opus at discounted rates? LaoZhang-AI's unified API gateway offers:
- ✅ 25% discount on all Claude models
- ✅ Single API for multiple models
- ✅ Pay-as-you-go pricing
- ✅ Free trial credits
- ✅ 24/7 support
Register now at: https://api.laozhang.ai/register/
Transform your AI capabilities while keeping costs under control. With the right optimization strategies and gateway discounts, Claude 4 Opus becomes an accessible powerhouse for organizations serious about leveraging the best AI technology available in 2025.