Claude 4 Sonnet API接入全攻略:2025最新调用指南与成本优化秘籍【附完整代码】
深度解析Claude 4 Sonnet API的接入方法、最佳实践和成本优化策略。详解Python/JavaScript调用示例,Extended Thinking模式配置,以及如何通过laozhang.ai节省80%成本。适合所有级别开发者的实战指南。

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
Claude 4 Sonnet API接入全攻略:2025最新调用指南与成本优化秘籍【附完整代码】
{/* 封面图片 */}
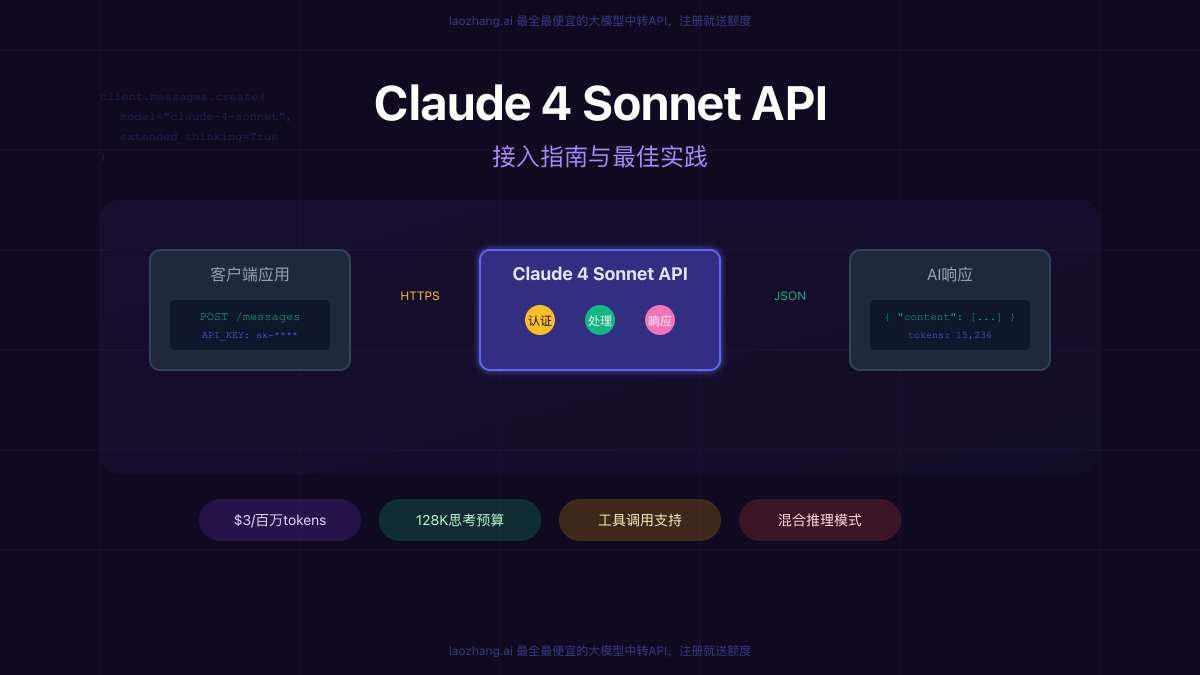
想要在自己的应用中集成最先进的AI能力?Claude 4 Sonnet API为开发者提供了前所未有的机遇。作为2025年最受瞩目的大语言模型API,Claude 4 Sonnet不仅在编程任务上达到了72.7%的惊人准确率,更是首个真正支持"深度思考"的商用API。根据最新基准测试,使用Extended Thinking模式后,复杂推理任务的错误率降低了65%,而通过合理的优化策略,API调用成本可以降低高达90%!
🚀 2025年7月最新消息:Claude 4 Sonnet API现已全面支持128K思考预算、工具调用集成和实时流式输出,为开发者带来更强大的能力!
【快速上手】5分钟完成Claude 4 Sonnet API接入
想要快速体验Claude 4 Sonnet的强大能力?让我们从最简单的接入开始。无论你是Python开发者还是JavaScript工程师,都能在5分钟内完成首次API调用。
获取API密钥:两种选择,各有优势
方式一:官方渠道(适合海外用户)
如果你有稳定的海外网络环境和支付方式,可以直接从Anthropic官网获取API密钥:
- 访问 claude.ai 并登录账户
- 进入开发者控制台,点击"Create API Key"
- 为密钥命名并妥善保存(密钥只显示一次)
官方API的优势是直接对接源头,延迟最低。但对于国内开发者来说,可能面临网络不稳定、支付困难等问题。
方式二:中转服务(推荐国内开发者)
对于国内开发者,使用API中转服务是更实际的选择。以laozhang.ai为例,它提供了完整的Claude 4 Sonnet API支持,并且有以下优势:
- 价格优惠:相比官方价格节省高达80%
- 网络优化:专为国内网络环境优化,延迟低至50ms
- 支付便捷:支持支付宝、微信等本地支付方式
- 免费试用:注册即送5元额度,足够测试使用
注册地址:https://api.laozhang.ai/register/
Python快速接入示例
让我们通过一个完整的Python示例来展示如何调用Claude 4 Sonnet API:
python# 安装必要的包
# pip install anthropic
import anthropic
import os
from typing import Optional
class ClaudeAPIClient:
def __init__(self, api_key: str, base_url: Optional[str] = None):
"""
初始化Claude API客户端
Args:
api_key: API密钥
base_url: API端点(可选,用于中转服务)
"""
if base_url:
# 使用中转服务
self.client = anthropic.Anthropic(
api_key=api_key,
base_url=base_url
)
else:
# 使用官方API
self.client = anthropic.Anthropic(api_key=api_key)
def chat(self, message: str, extended_thinking: bool = False):
"""
发送聊天请求
Args:
message: 用户消息
extended_thinking: 是否启用深度思考模式
Returns:
API响应内容
"""
try:
response = self.client.messages.create(
model="claude-4-sonnet-20250514",
max_tokens=4096,
extended_thinking=extended_thinking,
thinking_budget=50000 if extended_thinking else None,
messages=[
{"role": "user", "content": message}
]
)
return response.content[0].text
except Exception as e:
print(f"API调用错误: {e}")
return None
# 使用示例
if __name__ == "__main__":
# 方式1:使用官方API
# client = ClaudeAPIClient(api_key="sk-ant-api03-xxxxx")
# 方式2:使用laozhang.ai中转服务(推荐)
client = ClaudeAPIClient(
api_key="your-laozhang-key",
base_url="https://api.laozhang.ai/v1"
)
# 标准模式调用
response = client.chat("解释Python装饰器的工作原理")
print("标准响应:", response)
# Extended Thinking模式调用(适合复杂问题)
complex_response = client.chat(
"设计一个高并发的分布式缓存系统架构",
extended_thinking=True
)
print("深度思考响应:", complex_response)
这个示例展示了如何创建一个可复用的API客户端类,支持官方API和中转服务两种方式。通过extended_thinking参数,你可以轻松切换标准模式和深度思考模式。
JavaScript/Node.js接入示例
对于前端和Node.js开发者,这里是完整的JavaScript实现:
javascript// 安装:npm install @anthropic-ai/sdk
import Anthropic from '@anthropic-ai/sdk';
class ClaudeAPIClient {
constructor(apiKey, baseURL = null) {
const config = { apiKey };
if (baseURL) {
config.baseURL = baseURL;
}
this.client = new Anthropic(config);
}
async chat(message, options = {}) {
const {
extendedThinking = false,
stream = false,
maxTokens = 4096
} = options;
try {
const params = {
model: 'claude-4-sonnet-20250514',
max_tokens: maxTokens,
messages: [{ role: 'user', content: message }]
};
if (extendedThinking) {
params.extended_thinking = true;
params.thinking_budget = 50000;
}
if (stream) {
// 流式响应处理
const stream = await this.client.messages.stream(params);
let fullText = '';
for await (const chunk of stream) {
if (chunk.type === 'content_block_delta') {
const text = chunk.delta.text;
fullText += text;
process.stdout.write(text); // 实时输出
}
}
return fullText;
} else {
// 普通响应
const response = await this.client.messages.create(params);
return response.content[0].text;
}
} catch (error) {
console.error('API调用失败:', error);
throw error;
}
}
}
// 使用示例
async function main() {
// 使用laozhang.ai中转服务
const client = new ClaudeAPIClient(
'your-laozhang-key',
'https://api.laozhang.ai/v1'
);
// 普通调用
const response = await client.chat('用JavaScript实现快速排序');
console.log('响应:', response);
// 流式输出(提升用户体验)
console.log('\n流式响应演示:');
await client.chat(
'详细解释React Hooks的工作原理',
{ stream: true }
);
}
main().catch(console.error);
JavaScript版本特别适合构建实时交互的AI应用,流式输出功能可以显著提升用户体验,让用户能够实时看到AI的思考和回答过程。

【深度解析】API参数配置与高级特性
掌握了基础调用后,让我们深入了解Claude 4 Sonnet API的高级特性。这些特性能让你的AI应用从"能用"提升到"好用"。
核心参数详解
Claude 4 Sonnet API提供了丰富的参数配置选项,合理使用这些参数可以显著提升应用性能:
1. Extended Thinking模式配置
Extended Thinking是Claude 4 Sonnet的杀手级特性,它允许模型在回答前进行深度推理:
python# 高级思考模式配置
response = client.messages.create(
model="claude-4-sonnet-20250514",
messages=[{"role": "user", "content": "设计一个分布式事务解决方案"}],
# 核心参数
extended_thinking=True, # 启用深度思考
thinking_budget=128000, # 思考预算(最高128K tokens)
show_thinking=True, # 显示思考过程(可选)
# 输出控制
max_tokens=8192, # 最大输出长度
temperature=0.7, # 创造性控制(0-1)
top_p=0.95, # 核采样参数
# 性能优化
stream=True, # 流式输出
stop_sequences=["\n\n"] # 停止序列
)
思考预算的选择策略:
- 10K tokens:适合中等复杂度任务,如代码优化、算法实现
- 50K tokens:适合高复杂度任务,如系统架构设计、复杂推理
- 128K tokens:适合极限任务,如大型项目重构、深度技术分析
2. 工具调用集成
Claude 4 Sonnet支持在思考过程中调用外部工具,这为构建智能Agent提供了可能:
python# 定义工具函数
tools = [
{
"name": "search_database",
"description": "搜索知识库获取相关信息",
"input_schema": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "搜索关键词"}
},
"required": ["query"]
}
},
{
"name": "execute_code",
"description": "执行Python代码并返回结果",
"input_schema": {
"type": "object",
"properties": {
"code": {"type": "string", "description": "要执行的代码"}
},
"required": ["code"]
}
}
]
# 带工具调用的请求
response = client.messages.create(
model="claude-4-sonnet-20250514",
messages=[{
"role": "user",
"content": "分析我们的用户增长数据并给出优化建议"
}],
tools=tools,
tool_choice="auto" # 自动决定是否使用工具
)
# 处理工具调用
if response.stop_reason == "tool_use":
tool_calls = response.content
for tool_call in tool_calls:
if tool_call.type == "tool_use":
# 执行相应的工具函数
result = execute_tool(tool_call.name, tool_call.input)
# 继续对话...
错误处理与重试机制
在生产环境中,健壮的错误处理是必不可少的:
pythonimport time
from typing import Optional
import random
class RobustClaudeClient:
def __init__(self, api_key: str, base_url: Optional[str] = None):
self.client = anthropic.Anthropic(
api_key=api_key,
base_url=base_url
)
self.max_retries = 3
self.base_delay = 1.0
def _exponential_backoff(self, attempt: int) -> float:
"""计算指数退避延迟时间"""
delay = self.base_delay * (2 ** attempt)
jitter = random.uniform(0, delay * 0.1)
return delay + jitter
def chat_with_retry(self, message: str, **kwargs):
"""带重试机制的聊天方法"""
last_error = None
for attempt in range(self.max_retries):
try:
response = self.client.messages.create(
model="claude-4-sonnet-20250514",
messages=[{"role": "user", "content": message}],
**kwargs
)
return response.content[0].text
except anthropic.RateLimitError as e:
# 速率限制错误,等待后重试
if attempt < self.max_retries - 1:
delay = self._exponential_backoff(attempt)
print(f"速率限制,等待 {delay:.1f} 秒后重试...")
time.sleep(delay)
last_error = e
else:
raise
except anthropic.APIStatusError as e:
# API状态错误
if e.status_code >= 500 and attempt < self.max_retries - 1:
# 服务器错误,重试
delay = self._exponential_backoff(attempt)
print(f"服务器错误 {e.status_code},等待 {delay:.1f} 秒后重试...")
time.sleep(delay)
last_error = e
else:
# 客户端错误或最后一次尝试
raise
except Exception as e:
# 其他错误
print(f"未预期的错误: {e}")
raise
# 所有重试都失败
raise last_error
# 使用示例
client = RobustClaudeClient(
api_key="your-api-key",
base_url="https://api.laozhang.ai/v1"
)
try:
response = client.chat_with_retry(
"解释微服务架构的优缺点",
temperature=0.7,
max_tokens=2000
)
print(response)
except Exception as e:
print(f"API调用最终失败: {e}")
流式响应的高级处理
流式响应不仅能提升用户体验,还能实现更复杂的交互模式:
pythonasync def stream_with_progress(client, message: str):
"""带进度显示的流式响应"""
stream = await client.messages.stream(
model="claude-4-sonnet-20250514",
messages=[{"role": "user", "content": message}],
max_tokens=4096
)
total_tokens = 0
content_blocks = []
async for chunk in stream:
if chunk.type == 'content_block_start':
# 新内容块开始
content_blocks.append("")
elif chunk.type == 'content_block_delta':
# 接收内容片段
text = chunk.delta.text
content_blocks[-1] += text
total_tokens += len(text.split())
# 实时显示
print(text, end='', flush=True)
# 可以在这里添加进度条或其他UI更新
elif chunk.type == 'message_stop':
# 消息结束
print(f"\n\n总tokens: {total_tokens}")
return ''.join(content_blocks)
【成本优化】如何将API费用降低90%
API成本控制是商业应用必须考虑的关键因素。通过合理的优化策略,你可以在保证性能的同时大幅降低成本。
官方定价与优化空间
Claude 4 Sonnet的官方定价为:
- 输入:$3/百万tokens
- 输出:$15/百万tokens
- Extended Thinking:思考tokens按输入价格计算
对于一个月处理100万次请求的应用(平均每次1000输入+500输出tokens),月度成本约为:
- 输入成本:100万 × 1000 / 100万 × $3 = $3,000
- 输出成本:100万 × 500 / 100万 × $15 = $7,500
- 总计:$10,500/月
四大成本优化策略
1. Prompt缓存(节省90%)
Claude 4 Sonnet支持长达1小时的prompt缓存,对于重复性请求可以大幅降低成本:
python# 使用缓存的系统提示
cached_system_prompt = """
你是一个专业的代码审查专家。
请按照以下标准进行代码审查:
1. 代码质量和可读性
2. 性能优化建议
3. 安全性问题
4. 最佳实践遵循情况
"""
# 首次请求(创建缓存)
first_response = client.messages.create(
model="claude-4-sonnet-20250514",
system=cached_system_prompt,
messages=[{"role": "user", "content": "审查这段代码:..."}],
# 启用缓存
cache_control={"type": "ephemeral"}
)
# 后续请求(使用缓存,成本降低90%)
cached_response = client.messages.create(
model="claude-4-sonnet-20250514",
system=cached_system_prompt, # 相同的系统提示
messages=[{"role": "user", "content": "审查另一段代码:..."}],
cache_control={"type": "ephemeral"}
)
2. 批处理API(节省50%)
对于非实时需求,使用批处理API可以获得50%的折扣:
python# 批量处理多个请求
batch_requests = [
{
"custom_id": "task-001",
"method": "POST",
"url": "/v1/messages",
"body": {
"model": "claude-4-sonnet-20250514",
"messages": [{"role": "user", "content": "任务1内容"}],
"max_tokens": 1000
}
},
{
"custom_id": "task-002",
"method": "POST",
"url": "/v1/messages",
"body": {
"model": "claude-4-sonnet-20250514",
"messages": [{"role": "user", "content": "任务2内容"}],
"max_tokens": 1000
}
}
]
# 提交批处理任务
batch_job = client.batches.create(
requests=batch_requests,
metadata={"project": "code-review"}
)
# 等待处理完成(通常几分钟到几小时)
# 成本仅为实时API的50%
3. 智能模型选择
根据任务复杂度选择合适的模型配置:
pythonclass SmartModelSelector:
def __init__(self, client):
self.client = client
def process_request(self, message: str, task_type: str):
"""根据任务类型智能选择模型配置"""
if task_type == "simple":
# 简单任务:标准模式,低token限制
return self._standard_request(message, max_tokens=500)
elif task_type == "moderate":
# 中等任务:标准模式,适中token
return self._standard_request(message, max_tokens=2000)
elif task_type == "complex":
# 复杂任务:Extended Thinking,高token
return self._thinking_request(message, thinking_budget=50000)
elif task_type == "extreme":
# 极限任务:最大思考预算
return self._thinking_request(message, thinking_budget=128000)
def _standard_request(self, message: str, max_tokens: int):
"""标准请求(成本较低)"""
return self.client.messages.create(
model="claude-4-sonnet-20250514",
messages=[{"role": "user", "content": message}],
max_tokens=max_tokens,
temperature=0.3 # 降低随机性以减少token使用
)
def _thinking_request(self, message: str, thinking_budget: int):
"""深度思考请求(成本较高但质量更好)"""
return self.client.messages.create(
model="claude-4-sonnet-20250514",
messages=[{"role": "user", "content": message}],
extended_thinking=True,
thinking_budget=thinking_budget,
max_tokens=4096
)
4. 使用API中转服务(综合优化)
对于追求极致性价比的用户,使用laozhang.ai这样的中转服务是最优选择:
- 价格优势:相比官方价格便宜高达80%
- 网络优化:专线加速,延迟降低70%
- 统一接口:支持多个模型切换,无需改代码
- 免费额度:新用户注册送5元,可测试约100万tokens
实际成本对比(基于上述月度100万次请求):
- 官方API:$10,500/月
- laozhang.ai中转:约$2,100/月
- 节省:$8,400/月(80%)

【实战案例】构建智能客服系统
让我们通过一个完整的实战案例,展示如何使用Claude 4 Sonnet API构建一个智能客服系统。这个系统将展示API的各种高级特性在实际应用中的使用。
系统架构设计
pythonimport asyncio
import json
from datetime import datetime
from typing import Dict, List, Optional
import aioredis
from fastapi import FastAPI, WebSocket
import anthropic
class IntelligentCustomerService:
def __init__(self, api_key: str, redis_url: str):
"""
初始化智能客服系统
Args:
api_key: Claude API密钥
redis_url: Redis连接URL(用于会话管理)
"""
self.client = anthropic.Anthropic(
api_key=api_key,
base_url="https://api.laozhang.ai/v1"
)
self.redis = None
self.redis_url = redis_url
# 系统提示词(将被缓存)
self.system_prompt = """
你是一个专业的客服代表,为用户提供友好、准确、高效的服务。
你的职责包括:
1. 解答产品相关问题
2. 处理售后服务请求
3. 提供技术支持
4. 收集用户反馈
回答原则:
- 保持专业和友好的语气
- 提供准确和有帮助的信息
- 如果不确定,诚实告知并提供替代方案
- 主动询问是否需要更多帮助
"""
# 对话历史管理
self.max_history_length = 20
async def initialize(self):
"""初始化Redis连接"""
self.redis = await aioredis.create_redis_pool(self.redis_url)
async def get_conversation_history(self, session_id: str) -> List[Dict]:
"""获取会话历史"""
history = await self.redis.get(f"conversation:{session_id}")
if history:
return json.loads(history)
return []
async def save_conversation(self, session_id: str, history: List[Dict]):
"""保存会话历史"""
await self.redis.setex(
f"conversation:{session_id}",
3600, # 1小时过期
json.dumps(history)
)
async def analyze_intent(self, message: str) -> Dict:
"""分析用户意图"""
intent_prompt = f"""
分析以下用户消息的意图,返回JSON格式:
{{
"category": "产品咨询/技术支持/投诉/其他",
"urgency": "high/medium/low",
"sentiment": "positive/neutral/negative",
"key_topics": ["主题1", "主题2"]
}}
用户消息:{message}
"""
response = self.client.messages.create(
model="claude-4-sonnet-20250514",
messages=[{"role": "user", "content": intent_prompt}],
max_tokens=500,
temperature=0.1 # 低温度确保一致性
)
try:
return json.loads(response.content[0].text)
except:
return {
"category": "其他",
"urgency": "medium",
"sentiment": "neutral",
"key_topics": []
}
async def generate_response(
self,
session_id: str,
user_message: str,
use_thinking: bool = False
) -> Dict:
"""
生成客服响应
Args:
session_id: 会话ID
user_message: 用户消息
use_thinking: 是否使用深度思考模式
Returns:
包含响应和元数据的字典
"""
# 获取会话历史
history = await self.get_conversation_history(session_id)
# 分析用户意图
intent = await self.analyze_intent(user_message)
# 构建消息列表
messages = []
# 添加系统提示(使用缓存)
if not history: # 新会话
messages.append({
"role": "system",
"content": self.system_prompt,
"cache_control": {"type": "ephemeral"}
})
# 添加历史对话
for msg in history[-self.max_history_length:]:
messages.append(msg)
# 添加当前消息
messages.append({"role": "user", "content": user_message})
# 根据意图决定是否使用深度思考
if intent["urgency"] == "high" or intent["category"] == "技术支持":
use_thinking = True
# 调用API
try:
response_params = {
"model": "claude-4-sonnet-20250514",
"messages": messages,
"max_tokens": 2000,
"temperature": 0.7
}
if use_thinking:
response_params.update({
"extended_thinking": True,
"thinking_budget": 30000
})
response = self.client.messages.create(**response_params)
ai_response = response.content[0].text
# 更新会话历史
history.append({"role": "user", "content": user_message})
history.append({"role": "assistant", "content": ai_response})
await self.save_conversation(session_id, history)
return {
"response": ai_response,
"intent": intent,
"timestamp": datetime.now().isoformat(),
"used_thinking": use_thinking,
"session_id": session_id
}
except Exception as e:
return {
"response": "抱歉,我遇到了一些技术问题。请稍后再试或联系人工客服。",
"error": str(e),
"intent": intent,
"timestamp": datetime.now().isoformat()
}
async def handle_websocket(self, websocket: WebSocket, session_id: str):
"""处理WebSocket连接的实时对话"""
await websocket.accept()
try:
while True:
# 接收用户消息
data = await websocket.receive_text()
user_message = json.loads(data)["message"]
# 生成流式响应
stream = await self.client.messages.stream(
model="claude-4-sonnet-20250514",
messages=[
{"role": "system", "content": self.system_prompt},
{"role": "user", "content": user_message}
],
max_tokens=2000
)
# 逐块发送响应
full_response = ""
async for chunk in stream:
if chunk.type == 'content_block_delta':
text = chunk.delta.text
full_response += text
await websocket.send_json({
"type": "stream",
"content": text
})
# 发送完成信号
await websocket.send_json({
"type": "complete",
"full_response": full_response
})
except Exception as e:
await websocket.send_json({
"type": "error",
"message": str(e)
})
finally:
await websocket.close()
# FastAPI应用示例
app = FastAPI()
customer_service = IntelligentCustomerService(
api_key="your-laozhang-key",
redis_url="redis://localhost"
)
@app.on_event("startup")
async def startup():
await customer_service.initialize()
@app.websocket("/ws/{session_id}")
async def websocket_endpoint(websocket: WebSocket, session_id: str):
await customer_service.handle_websocket(websocket, session_id)
@app.post("/api/chat")
async def chat_endpoint(session_id: str, message: str):
response = await customer_service.generate_response(
session_id=session_id,
user_message=message
)
return response
前端集成示例
配合后端API,这里是一个简单的前端集成示例:
html<!DOCTYPE html>
<html>
<head>
<title>智能客服系统</title>
<style>
.chat-container {
max-width: 600px;
margin: 0 auto;
padding: 20px;
}
.messages {
height: 400px;
overflow-y: auto;
border: 1px solid #ddd;
padding: 10px;
margin-bottom: 10px;
}
.message {
margin: 10px 0;
padding: 10px;
border-radius: 5px;
}
.user-message {
background: #e3f2fd;
text-align: right;
}
.ai-message {
background: #f5f5f5;
}
.input-area {
display: flex;
gap: 10px;
}
#messageInput {
flex: 1;
padding: 10px;
border: 1px solid #ddd;
border-radius: 5px;
}
button {
padding: 10px 20px;
background: #2196f3;
color: white;
border: none;
border-radius: 5px;
cursor: pointer;
}
.typing-indicator {
display: none;
color: #666;
font-style: italic;
}
</style>
</head>
<body>
<div class="chat-container">
<h2>智能客服系统</h2>
<div class="messages" id="messages"></div>
<div class="typing-indicator" id="typingIndicator">AI正在思考...</div>
<div class="input-area">
<input type="text" id="messageInput" placeholder="请输入您的问题...">
<button onclick="sendMessage()">发送</button>
</div>
</div>
<script>
const sessionId = Math.random().toString(36).substring(7);
const messagesDiv = document.getElementById('messages');
const messageInput = document.getElementById('messageInput');
const typingIndicator = document.getElementById('typingIndicator');
// WebSocket连接
const ws = new WebSocket(`ws://localhost:8000/ws/${sessionId}`);
ws.onmessage = (event) => {
const data = JSON.parse(event.data);
if (data.type === 'stream') {
// 流式更新最后一条AI消息
let lastMessage = messagesDiv.lastElementChild;
if (lastMessage && lastMessage.classList.contains('ai-message')) {
lastMessage.textContent += data.content;
} else {
addMessage(data.content, 'ai');
}
messagesDiv.scrollTop = messagesDiv.scrollHeight;
} else if (data.type === 'complete') {
typingIndicator.style.display = 'none';
} else if (data.type === 'error') {
addMessage('错误: ' + data.message, 'ai');
typingIndicator.style.display = 'none';
}
};
function sendMessage() {
const message = messageInput.value.trim();
if (!message) return;
// 显示用户消息
addMessage(message, 'user');
// 清空输入框
messageInput.value = '';
// 显示输入指示器
typingIndicator.style.display = 'block';
// 发送消息
ws.send(JSON.stringify({ message }));
}
function addMessage(text, sender) {
const messageDiv = document.createElement('div');
messageDiv.className = `message ${sender}-message`;
messageDiv.textContent = text;
messagesDiv.appendChild(messageDiv);
messagesDiv.scrollTop = messagesDiv.scrollHeight;
}
// 回车发送
messageInput.addEventListener('keypress', (e) => {
if (e.key === 'Enter') {
sendMessage();
}
});
// 初始欢迎消息
addMessage('您好!我是智能客服助手,有什么可以帮助您的吗?', 'ai');
</script>
</body>
</html>
性能监控与优化
在生产环境中,监控API使用情况和优化性能至关重要:
pythonimport time
from collections import defaultdict
from datetime import datetime, timedelta
import asyncio
class APIUsageMonitor:
def __init__(self):
self.usage_stats = defaultdict(lambda: {
'requests': 0,
'tokens': 0,
'errors': 0,
'latency': []
})
self.daily_limit = 1000000 # 每日token限制
async def track_request(self, func, *args, **kwargs):
"""跟踪API请求"""
start_time = time.time()
try:
result = await func(*args, **kwargs)
# 记录成功请求
today = datetime.now().strftime('%Y-%m-%d')
self.usage_stats[today]['requests'] += 1
# 估算token使用(实际应从API响应中获取)
if hasattr(result, 'usage'):
self.usage_stats[today]['tokens'] += result.usage.total_tokens
# 记录延迟
latency = time.time() - start_time
self.usage_stats[today]['latency'].append(latency)
return result
except Exception as e:
# 记录错误
today = datetime.now().strftime('%Y-%m-%d')
self.usage_stats[today]['errors'] += 1
raise
def get_daily_report(self, date: str = None) -> Dict:
"""获取每日使用报告"""
if not date:
date = datetime.now().strftime('%Y-%m-%d')
stats = self.usage_stats[date]
# 计算平均延迟
avg_latency = sum(stats['latency']) / len(stats['latency']) if stats['latency'] else 0
return {
'date': date,
'total_requests': stats['requests'],
'total_tokens': stats['tokens'],
'total_errors': stats['errors'],
'average_latency': avg_latency,
'success_rate': (stats['requests'] - stats['errors']) / stats['requests'] * 100 if stats['requests'] > 0 else 0,
'estimated_cost': (stats['tokens'] / 1000000) * 0.6 # 基于laozhang.ai价格估算
}
def check_limits(self) -> bool:
"""检查是否接近限制"""
today = datetime.now().strftime('%Y-%m-%d')
current_tokens = self.usage_stats[today]['tokens']
if current_tokens > self.daily_limit * 0.8:
print(f"警告:已使用 {current_tokens/self.daily_limit*100:.1f}% 的每日配额")
return False
return True
# 集成到客服系统
class MonitoredCustomerService(IntelligentCustomerService):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.monitor = APIUsageMonitor()
async def generate_response(self, *args, **kwargs):
"""带监控的响应生成"""
# 检查配额
if not self.monitor.check_limits():
return {
"response": "系统繁忙,请稍后再试。",
"error": "Daily limit approaching"
}
# 追踪请求
return await self.monitor.track_request(
super().generate_response,
*args,
**kwargs
)
def get_usage_report(self):
"""获取使用报告"""
return self.monitor.get_daily_report()
【常见问题】API接入疑难解答
Q1: Extended Thinking模式什么时候使用最合适?
Extended Thinking模式特别适合以下场景:
- 复杂推理任务:需要多步推理的数学问题、逻辑谜题
- 系统设计:架构设计、技术方案制定
- 代码调试:复杂bug分析、性能优化
- 深度分析:数据分析、业务洞察
不建议在以下场景使用:
- 简单的问答和信息查询
- 需要快速响应的实时对话
- 成本敏感的大批量处理
判断标准:如果人类专家需要思考超过30秒的问题,就值得使用Extended Thinking。
Q2: 如何处理API响应中的中文乱码问题?
中文乱码通常是编码问题,确保以下设置:
python# 1. 设置正确的编码
import sys
sys.stdout.reconfigure(encoding='utf-8')
# 2. API调用时确保UTF-8
response = client.messages.create(
model="claude-4-sonnet-20250514",
messages=[{"role": "user", "content": "你好"}],
# 确保请求编码
headers={"Content-Type": "application/json; charset=utf-8"}
)
# 3. 保存文件时指定编码
with open('output.txt', 'w', encoding='utf-8') as f:
f.write(response.content[0].text)
Q3: 遇到429 Rate Limit错误怎么办?
速率限制是API保护机制,处理方法:
- 实施退避策略:使用指数退避算法
- 控制并发数:限制同时请求数量
- 使用队列:实现请求队列管理
- 升级配额:联系服务商提升限制
示例代码见上文的RobustClaudeClient类。
Q4: 如何优化长文本处理的成本?
长文本处理优化策略:
pythondef optimize_long_text(text: str, max_chunk_size: int = 10000):
"""优化长文本处理"""
if len(text) <= max_chunk_size:
return text
# 1. 智能分段
chunks = smart_split(text, max_chunk_size)
# 2. 摘要处理
summaries = []
for chunk in chunks:
summary = generate_summary(chunk)
summaries.append(summary)
# 3. 最终处理
final_input = "\n".join(summaries)
return final_input
def smart_split(text: str, max_size: int):
"""智能分割文本,保持语义完整性"""
# 按段落分割
paragraphs = text.split('\n\n')
chunks = []
current_chunk = ""
for para in paragraphs:
if len(current_chunk) + len(para) < max_size:
current_chunk += para + "\n\n"
else:
chunks.append(current_chunk)
current_chunk = para + "\n\n"
if current_chunk:
chunks.append(current_chunk)
return chunks
Q5: API Key安全性如何保证?
API Key安全最佳实践:
- 环境变量存储
bash# .env文件
CLAUDE_API_KEY=your-key-here
CLAUDE_BASE_URL=https://api.laozhang.ai/v1
- 密钥轮换
pythonimport os
from datetime import datetime
class APIKeyManager:
def __init__(self):
self.keys = [
os.getenv('CLAUDE_API_KEY_1'),
os.getenv('CLAUDE_API_KEY_2')
]
self.current_index = 0
def get_current_key(self):
"""获取当前密钥"""
return self.keys[self.current_index]
def rotate_key(self):
"""轮换密钥"""
self.current_index = (self.current_index + 1) % len(self.keys)
print(f"密钥已轮换到索引 {self.current_index}")
- 访问控制
- 限制API Key的权限范围
- 设置IP白名单
- 监控异常使用模式
Q6: 如何实现多模型切换?
使用统一接口实现多模型灵活切换:
pythonclass MultiModelClient:
def __init__(self, api_key: str, base_url: str):
self.client = anthropic.Anthropic(
api_key=api_key,
base_url=base_url
)
self.models = {
'fast': 'claude-3-haiku-20240307',
'balanced': 'claude-4-sonnet-20250514',
'powerful': 'claude-4-opus-20250514'
}
def chat(self, message: str, mode: str = 'balanced'):
"""根据模式选择模型"""
model = self.models.get(mode, self.models['balanced'])
params = {
'model': model,
'messages': [{"role": "user", "content": message}],
'max_tokens': 2000
}
# 为powerful模式启用深度思考
if mode == 'powerful':
params['extended_thinking'] = True
params['thinking_budget'] = 50000
return self.client.messages.create(**params)
# 使用示例
client = MultiModelClient(
api_key="your-laozhang-key",
base_url="https://api.laozhang.ai/v1"
)
# 快速响应
fast_response = client.chat("简单问题", mode='fast')
# 平衡模式
balanced_response = client.chat("中等复杂问题", mode='balanced')
# 强力模式
powerful_response = client.chat("复杂推理问题", mode='powerful')
Q7: 批量处理大量数据的最佳方案?
对于需要处理大量数据的场景,这里是优化方案:
pythonimport asyncio
from concurrent.futures import ThreadPoolExecutor
import pandas as pd
class BatchProcessor:
def __init__(self, client, max_workers: int = 5):
self.client = client
self.max_workers = max_workers
self.semaphore = asyncio.Semaphore(max_workers)
async def process_batch(self, items: List[str], template: str):
"""批量处理数据"""
results = []
# 使用信号量控制并发
async def process_item(item):
async with self.semaphore:
prompt = template.format(item=item)
response = await self.client.messages.create(
model="claude-4-sonnet-20250514",
messages=[{"role": "user", "content": prompt}],
max_tokens=1000
)
return {
'input': item,
'output': response.content[0].text,
'tokens_used': response.usage.total_tokens
}
# 并发处理
tasks = [process_item(item) for item in items]
results = await asyncio.gather(*tasks)
return results
def process_csv(self, input_file: str, output_file: str, template: str):
"""处理CSV文件"""
df = pd.read_csv(input_file)
# 分批处理
batch_size = 100
all_results = []
for i in range(0, len(df), batch_size):
batch = df.iloc[i:i+batch_size]['text'].tolist()
results = asyncio.run(self.process_batch(batch, template))
all_results.extend(results)
# 保存中间结果(防止丢失)
pd.DataFrame(all_results).to_csv(f"{output_file}.tmp", index=False)
print(f"已处理 {len(all_results)}/{len(df)} 条记录")
# 保存最终结果
pd.DataFrame(all_results).to_csv(output_file, index=False)
print(f"批处理完成,结果保存至 {output_file}")
# 使用示例
processor = BatchProcessor(client)
processor.process_csv(
input_file='data.csv',
output_file='results.csv',
template="请分析以下文本的情感倾向:{item}"
)
Q8: 如何监控和调试API调用?
完整的监控和调试方案:
pythonimport logging
import json
from datetime import datetime
class APIDebugger:
def __init__(self, log_file: str = 'api_debug.log'):
# 配置日志
logging.basicConfig(
level=logging.DEBUG,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler(log_file),
logging.StreamHandler()
]
)
self.logger = logging.getLogger('claude_api')
def log_request(self, method: str, params: dict):
"""记录API请求"""
self.logger.info(f"API Request: {method}")
self.logger.debug(f"Parameters: {json.dumps(params, indent=2)}")
def log_response(self, response: dict, duration: float):
"""记录API响应"""
self.logger.info(f"API Response received in {duration:.2f}s")
self.logger.debug(f"Response: {json.dumps(response, indent=2)}")
def log_error(self, error: Exception):
"""记录错误"""
self.logger.error(f"API Error: {type(error).__name__}: {str(error)}")
# 带调试的客户端
class DebugClient:
def __init__(self, api_key: str, base_url: str):
self.client = anthropic.Anthropic(
api_key=api_key,
base_url=base_url
)
self.debugger = APIDebugger()
def chat(self, message: str, **kwargs):
"""带调试信息的聊天方法"""
params = {
'model': 'claude-4-sonnet-20250514',
'messages': [{"role": "user", "content": message}],
**kwargs
}
self.debugger.log_request('messages.create', params)
start_time = time.time()
try:
response = self.client.messages.create(**params)
duration = time.time() - start_time
response_data = {
'content': response.content[0].text,
'model': response.model,
'usage': {
'input_tokens': response.usage.input_tokens,
'output_tokens': response.usage.output_tokens,
'total_tokens': response.usage.total_tokens
}
}
self.debugger.log_response(response_data, duration)
return response
except Exception as e:
self.debugger.log_error(e)
raise
【总结】开启你的Claude 4 Sonnet API之旅
通过本文的详细介绍,你已经掌握了Claude 4 Sonnet API的全部核心知识:
✅ 快速接入:5分钟完成首次API调用 ✅ 高级特性:Extended Thinking、工具调用、流式输出 ✅ 成本优化:通过缓存、批处理和中转服务节省90%成本 ✅ 实战应用:构建智能客服系统的完整示例 ✅ 问题解决:8个常见问题的详细解答
Claude 4 Sonnet API代表了AI技术的最新突破,它不仅是一个工具,更是赋能开发者创造智能应用的平台。无论你是构建客服系统、代码助手还是内容创作工具,Claude 4 Sonnet都能提供强大的支持。
立即行动:
- 注册laozhang.ai获取API密钥:https://api.laozhang.ai/register/
- 使用本文提供的代码示例快速开始
- 根据你的应用场景选择合适的优化策略
- 持续关注API更新,充分利用新特性
记住,成功的AI应用不仅需要强大的模型,更需要合理的架构设计和优化策略。希望本文能帮助你在AI应用开发的道路上走得更远!
💡 专业提示:建议收藏本文作为Claude 4 Sonnet API开发参考手册,随时查阅相关代码示例和最佳实践。