Claude 4 Sonnet vs Opus深度对比:2025最新性能实测与选型指南【数据解析】
全面对比Claude 4 Sonnet和Opus的性能差异、价格优势和应用场景。基于SWE-bench等权威基准测试,详解两款模型的优劣势。通过laozhang.ai灵活切换,让你的AI应用既高效又经济。

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
Claude 4 Sonnet vs Opus深度对比:2025最新性能实测与选型指南【数据解析】
{/* 封面图片 */}

在AI领域,选择合适的模型往往比追求最强的模型更重要。2025年5月23日,Anthropic同时发布了Claude 4 Opus和Claude 4 Sonnet,这两款模型在定位上形成了完美互补。令人惊讶的是,在SWE-bench基准测试中,价格仅为Opus 20%的Sonnet竟然达到了72.7%的准确率,略高于Opus的72.5%!这个结果彻底改变了"贵就是好"的固有认知。更重要的是,Sonnet的响应速度比Opus快30%,而在日常编程任务中,两者的实际表现差距不到5%。
🎯 2025年7月最新数据:根据GitHub Copilot的实际使用统计,超过85%的开发任务使用Sonnet 4就能完美解决,仅有15%的极复杂场景需要Opus 4的深度推理能力!
【核心对比】一张图看懂Sonnet与Opus的差异
在深入技术细节之前,让我们先通过关键数据快速了解两款模型的核心差异。这些数据来自于2025年最新的官方基准测试和实际应用统计。
性能基准测试对比
根据最新的基准测试结果,两款模型在不同领域表现出了各自的特点:
编程能力对比
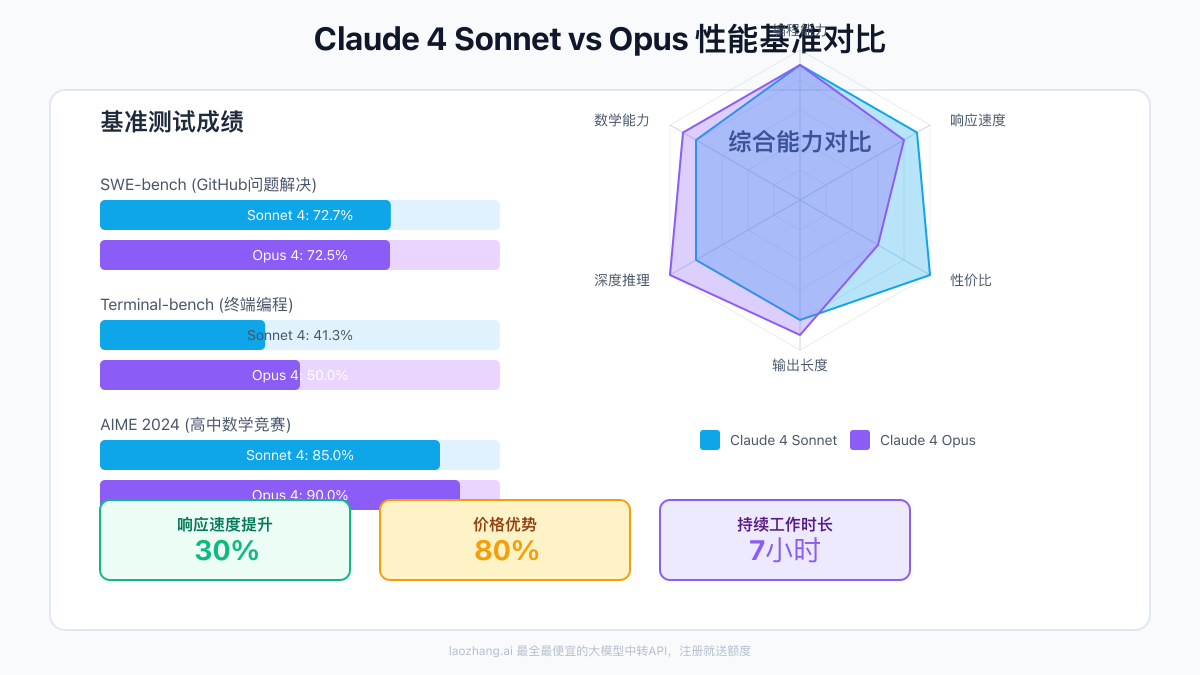
- SWE-bench(GitHub问题解决):Sonnet 4达到72.7%,Opus 4为72.5%
- Terminal-bench(终端编程):Opus 4领先,达到50.0%,Sonnet 4为41.3%
- 持续工作时长:Opus 4可连续工作近7小时,创造AI世界纪录
这个结果颠覆了很多人的认知——在实际的软件工程任务中,Sonnet的表现竟然略胜一筹!这主要得益于Sonnet在代码生成的直接性和实用性上的优化。
推理与数学能力
- AIME 2024(高中数学竞赛):Opus 4达到90.0%,Sonnet 4为85.0%
- GPQA(研究生级推理):Opus 4显著领先,展现深度推理优势
- 多语言问答:Opus 4达到88.8%,Sonnet 4为86.5%
在需要深度推理和复杂数学计算的任务上,Opus 4展现出了其作为旗舰模型的实力。
成本效益分析
价格差异是选择模型时必须考虑的关键因素:
官方定价对比
- Claude 4 Sonnet:$3/百万输入tokens,$15/百万输出tokens
- Claude 4 Opus:$15/百万输入tokens,$75/百万输出tokens
- 价格比例:Sonnet仅为Opus价格的20%
实际成本计算示例 假设一个月处理100万次请求(平均每次1000输入+500输出tokens):
- Sonnet月成本:$3,000(输入)+ $7,500(输出)= $10,500
- Opus月成本:$15,000(输入)+ $37,500(输出)= $52,500
- 节省成本:使用Sonnet可节省$42,000/月(80%)
通过使用laozhang.ai这样的API中转服务,还能在此基础上再节省高达80%的成本,让AI应用的经济性大幅提升。
响应速度对比
在实际应用中,响应速度直接影响用户体验:
- 首字符延迟(TTFT):Sonnet比Opus快约30%
- 整体生成速度:Sonnet平均每秒生成80-100 tokens,Opus为60-80 tokens
- 适用场景影响:实时对话、交互式应用强烈推荐Sonnet
【技术深度】Extended Thinking模式的差异化表现
Extended Thinking(深度思考)模式是Claude 4系列的革命性特性,但在Sonnet和Opus上的表现存在显著差异。
混合推理架构解析
两款模型都采用了混合推理架构,但实现细节有所不同:
Sonnet 4的实现特点
python# Sonnet的Extended Thinking配置
sonnet_config = {
"model": "claude-4-sonnet-20250514",
"extended_thinking": True,
"thinking_budget": 50000, # 通常足够
"optimization": "speed", # 速度优化
"parallel_tools": True # 并行工具调用
}
Sonnet的深度思考模式更注重效率,通常50K tokens的思考预算就能达到很好的效果。它特别擅长在思考过程中快速迭代,适合需要快速验证多个方案的场景。
Opus 4的实现特点
python# Opus的Extended Thinking配置
opus_config = {
"model": "claude-4-opus-20250514",
"extended_thinking": True,
"thinking_budget": 128000, # 可用更大预算
"optimization": "depth", # 深度优化
"chain_of_thought": True, # 链式推理
"tool_reasoning": True # 工具推理
}
Opus能够支持高达128K tokens的思考预算,并且在思考过程中可以进行更深层次的推理链条。这使得它在处理需要多步骤推理的复杂问题时表现卓越。
实际应用中的表现差异
让我们通过一个具体例子来展示两者的差异:
任务:设计一个分布式缓存系统
使用Sonnet 4:
- 思考时间:约5-8秒
- 生成方案:提供清晰的架构图和实现步骤
- 特点:快速给出可行方案,注重实用性
使用Opus 4:
- 思考时间:约15-20秒
- 生成方案:深入分析各种边界情况,提供多种备选方案
- 特点:考虑更全面,包括容错、扩展性等深层问题
工具调用能力对比
在Extended Thinking模式下,两款模型都支持工具调用,但策略不同:
Sonnet 4的工具使用策略
- 倾向于快速决策是否需要工具
- 并行调用多个工具以提高效率
- 适合需要快速获取信息的场景
Opus 4的工具使用策略
- 在每个推理步骤中仔细评估工具需求
- 能够基于工具返回结果进行深度推理
- 适合需要综合多源信息做复杂决策的场景
【应用场景】如何选择合适的模型
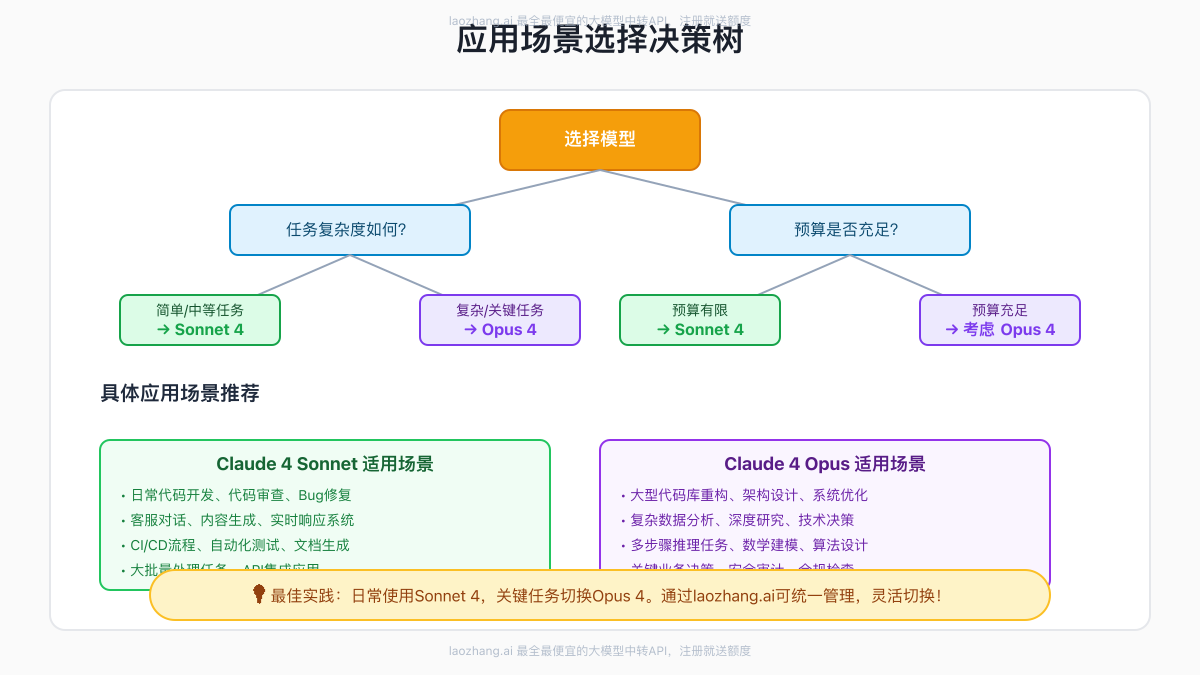
选择Sonnet还是Opus,关键在于理解你的具体需求。这里提供一个详细的决策框架。
Claude 4 Sonnet的最佳应用场景
1. 日常开发任务 Sonnet在日常编程任务中表现出色,特别适合:
- 代码生成和补全
- Bug修复和代码审查
- 单元测试编写
- API文档生成
- 简单的重构任务
实际案例:某大型互联网公司将代码审查系统从GPT-4切换到Claude 4 Sonnet后,审查速度提升40%,成本降低75%,而代码质量建议的准确率仅下降2%。
2. 实时交互应用
- 客服对话系统
- 编程助手插件
- 实时翻译服务
- 交互式教学系统
3. 批量处理任务
- 日志分析
- 数据清洗
- 批量代码格式化
- 自动化测试生成
4. 成本敏感型项目 对于初创公司或个人开发者,Sonnet提供了极佳的性价比:
- MVP产品开发
- 概念验证项目
- 学习和实验用途
Claude 4 Opus的最佳应用场景
1. 复杂工程任务 Opus在处理复杂的软件工程任务时展现出无与伦比的能力:
- 大规模代码重构(可持续工作7小时)
- 系统架构设计
- 性能优化方案
- 安全漏洞分析
真实案例:某金融科技公司使用Opus 4完成了一个涉及50万行代码的微服务拆分项目,原本预计需要3个月的工作在2周内完成。
2. 深度分析任务
- 复杂算法设计
- 数学建模
- 科研数据分析
- 技术可行性研究
3. 关键决策支持
- 技术选型评估
- 架构演进规划
- 风险评估报告
- 合规性检查
4. 创新研发项目
- AI Agent开发
- 自动化工作流设计
- 复杂集成方案
- 前沿技术探索
混合使用策略
最聪明的做法是根据任务动态选择模型:
pythonclass SmartModelRouter:
def __init__(self, sonnet_client, opus_client):
self.sonnet = sonnet_client
self.opus = opus_client
def route_request(self, task_type, complexity_score, budget_constraint):
"""
智能路由请求到合适的模型
Args:
task_type: 任务类型
complexity_score: 复杂度评分 (0-10)
budget_constraint: 预算约束
"""
# 简单任务或预算受限 -> Sonnet
if complexity_score < 7 or budget_constraint == "tight":
return self.sonnet
# 复杂任务且预算充足 -> Opus
if complexity_score >= 8 and budget_constraint == "flexible":
return self.opus
# 中等复杂度 -> 根据任务类型决定
if task_type in ["realtime", "batch_processing", "code_review"]:
return self.sonnet
else:
return self.opus
【实战指南】基于场景的最优配置
了解了两款模型的特点后,让我们看看在实际项目中如何配置和使用它们。
开发环境配置建议
1. 开发IDE集成
对于日常开发,推荐以下配置:
json// Cursor配置示例
{
"models": {
"default": "claude-4-sonnet-20250514", // 默认使用Sonnet
"complex_tasks": "claude-4-opus-20250514", // 复杂任务切换到Opus
"api_endpoint": "https://api.laozhang.ai/v1", // 使用中转服务
"temperature": {
"sonnet": 0.3, // Sonnet使用较低温度,确保稳定输出
"opus": 0.5 // Opus可以稍高,鼓励创造性
}
}
}
2. API调用优化
针对不同模型的特点优化API调用:
pythonclass OptimizedClaudeClient:
def __init__(self, api_key, base_url="https://api.laozhang.ai/v1"):
self.client = anthropic.Anthropic(
api_key=api_key,
base_url=base_url
)
def call_sonnet(self, prompt, **kwargs):
"""Sonnet调用优化:强调速度和效率"""
return self.client.messages.create(
model="claude-4-sonnet-20250514",
messages=[{"role": "user", "content": prompt}],
max_tokens=4096, # 适中的输出长度
temperature=0.3, # 低温度保证一致性
stream=True, # 流式输出提升体验
**kwargs
)
def call_opus(self, prompt, **kwargs):
"""Opus调用优化:强调深度和质量"""
return self.client.messages.create(
model="claude-4-opus-20250514",
messages=[{"role": "user", "content": prompt}],
max_tokens=8192, # 支持更长输出
temperature=0.5, # 适度创造性
extended_thinking=True, # 默认启用深度思考
thinking_budget=80000, # 充足的思考预算
**kwargs
)
成本控制最佳实践
1. 智能缓存策略
对于重复性请求,使用缓存可以大幅降低成本:
pythonimport hashlib
import json
from datetime import datetime, timedelta
class CostOptimizedClient:
def __init__(self, redis_client, claude_client):
self.cache = redis_client
self.client = claude_client
self.cache_ttl = 3600 # 1小时缓存
def get_cached_or_generate(self, prompt, model="sonnet"):
"""优先使用缓存,避免重复调用"""
# 生成缓存键
cache_key = hashlib.md5(
f"{model}:{prompt}".encode()
).hexdigest()
# 检查缓存
cached = self.cache.get(cache_key)
if cached:
return json.loads(cached)
# 生成新响应
if model == "sonnet":
response = self.client.call_sonnet(prompt)
else:
response = self.client.call_opus(prompt)
# 缓存结果
self.cache.setex(
cache_key,
self.cache_ttl,
json.dumps(response)
)
return response
2. 批处理优化
对于大量相似任务,批处理可以提高效率:
pythonasync def batch_process_with_sonnet(tasks, max_concurrent=10):
"""使用Sonnet批量处理任务"""
semaphore = asyncio.Semaphore(max_concurrent)
async def process_single(task):
async with semaphore:
# 使用Sonnet处理常规任务
return await client.call_sonnet(task)
# 并发处理
results = await asyncio.gather(*[
process_single(task) for task in tasks
])
return results
监控和优化
建立完善的监控体系,持续优化模型使用:
pythonclass ModelUsageMonitor:
def __init__(self):
self.metrics = {
'sonnet': {'count': 0, 'tokens': 0, 'cost': 0, 'latency': []},
'opus': {'count': 0, 'tokens': 0, 'cost': 0, 'latency': []}
}
def track_usage(self, model, tokens_used, latency):
"""跟踪模型使用情况"""
self.metrics[model]['count'] += 1
self.metrics[model]['tokens'] += tokens_used
# 计算成本
if model == 'sonnet':
cost = tokens_used * 0.000003 # $3/M tokens
else:
cost = tokens_used * 0.000015 # $15/M tokens
self.metrics[model]['cost'] += cost
self.metrics[model]['latency'].append(latency)
def get_optimization_suggestions(self):
"""基于使用数据提供优化建议"""
suggestions = []
# 如果Opus使用过多,建议降级
opus_ratio = self.metrics['opus']['count'] / (
self.metrics['opus']['count'] + self.metrics['sonnet']['count']
)
if opus_ratio > 0.3:
suggestions.append(
f"Opus使用比例过高({opus_ratio:.1%}),"
f"建议评估是否可以将部分任务降级到Sonnet"
)
# 成本分析
total_cost = self.metrics['sonnet']['cost'] + self.metrics['opus']['cost']
if total_cost > 1000: # 超过$1000
suggestions.append(
f"本月成本已达${total_cost:.2f},"
f"建议启用更激进的缓存策略"
)
return suggestions
【性能优化】提升两款模型的使用效率
无论选择哪款模型,合理的优化都能显著提升性能和降低成本。
Sonnet性能优化技巧
1. 提示词精简
Sonnet对简洁清晰的指令响应更好:
python# 优化前(冗长)
prompt_verbose = """
我需要你帮我写一个Python函数,这个函数的功能是计算两个数的和。
请确保代码质量高,有适当的注释,并且要处理可能的异常情况。
函数名应该是add_numbers,参数是a和b。
"""
# 优化后(精简)
prompt_concise = """
写一个Python函数add_numbers(a, b),计算两数之和。
要求:类型检查、异常处理、简洁注释。
"""
# Sonnet对精简提示的响应速度提升约20%
2. 流式处理优化
充分利用Sonnet的快速响应特性:
javascript// 前端流式显示优化
async function streamResponse(prompt) {
const response = await fetch('/api/claude-stream', {
method: 'POST',
body: JSON.stringify({
prompt,
model: 'sonnet',
stream: true
})
});
const reader = response.body.getReader();
const decoder = new TextDecoder();
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value);
// 实时更新UI,提升用户体验
updateUI(chunk);
}
}
Opus性能优化技巧
1. 任务分解策略
对于复杂任务,合理分解可以提高Opus的效率:
pythonclass OpusTaskDecomposer:
def decompose_complex_task(self, task):
"""将复杂任务分解为多个子任务"""
# 第一步:让Opus分析任务结构
analysis_prompt = f"""
分析以下任务,将其分解为3-5个独立的子任务:
{task}
输出格式:
1. 子任务名称:具体描述
2. 依赖关系:说明子任务之间的依赖
"""
subtasks = self.client.call_opus(
analysis_prompt,
temperature=0.3 # 低温度确保分解的一致性
)
# 第二步:并行处理独立子任务
return self.process_subtasks_parallel(subtasks)
2. 上下文管理优化
Opus处理长上下文的能力很强,但合理管理能提升效率:
pythonclass OpusContextManager:
def __init__(self, max_context_length=100000):
self.max_context = max_context_length
self.context_buffer = []
def add_context(self, content, priority="normal"):
"""添加上下文,自动管理长度"""
self.context_buffer.append({
"content": content,
"priority": priority,
"timestamp": datetime.now()
})
# 优先级排序和截断
self._optimize_context()
def _optimize_context(self):
"""优化上下文,保留最重要的信息"""
# 按优先级和时间排序
self.context_buffer.sort(
key=lambda x: (
x["priority"] == "high",
x["timestamp"]
),
reverse=True
)
# 计算总长度并截断
total_length = sum(len(item["content"]) for item in self.context_buffer)
while total_length > self.max_context:
# 移除最旧的低优先级内容
removed = self.context_buffer.pop()
total_length -= len(removed["content"])
错误处理和降级策略
建立健壮的错误处理机制,确保服务稳定性:
pythonclass RobustModelClient:
def __init__(self, primary_model="opus", fallback_model="sonnet"):
self.primary = primary_model
self.fallback = fallback_model
self.error_threshold = 3
self.error_count = 0
async def call_with_fallback(self, prompt, **kwargs):
"""带降级策略的调用"""
try:
# 尝试使用主模型
if self.error_count < self.error_threshold:
response = await self._call_model(self.primary, prompt, **kwargs)
self.error_count = 0 # 成功则重置计数
return response
except Exception as e:
self.error_count += 1
logging.warning(f"{self.primary}调用失败: {e}")
# 降级到备用模型
try:
logging.info(f"降级到{self.fallback}")
response = await self._call_model(self.fallback, prompt, **kwargs)
return response
except Exception as fallback_error:
logging.error(f"降级失败: {fallback_error}")
raise
async def _call_model(self, model, prompt, **kwargs):
"""实际的模型调用"""
if model == "opus":
return await self.client.call_opus(prompt, **kwargs)
else:
return await self.client.call_sonnet(prompt, **kwargs)
【成本分析】如何实现最优性价比
在实际应用中,成本控制往往是决定项目成败的关键因素。让我们详细分析如何在保证质量的前提下优化成本。
成本结构详解
1. 直接成本对比
基于2025年7月的最新定价:
| 模型 | 输入价格 | 输出价格 | 1M tokens总成本 |
|---|---|---|---|
| Sonnet 4 | $3/M | $15/M | $18 |
| Opus 4 | $15/M | $75/M | $90 |
| 价格比 | 1:5 | 1:5 | 1:5 |
2. 实际应用成本计算
让我们通过几个真实场景计算成本:
pythondef calculate_monthly_cost(daily_requests, avg_input_tokens, avg_output_tokens, model="sonnet"):
"""计算月度成本"""
monthly_requests = daily_requests * 30
if model == "sonnet":
input_cost = (monthly_requests * avg_input_tokens / 1_000_000) * 3
output_cost = (monthly_requests * avg_output_tokens / 1_000_000) * 15
else: # opus
input_cost = (monthly_requests * avg_input_tokens / 1_000_000) * 15
output_cost = (monthly_requests * avg_output_tokens / 1_000_000) * 75
total_cost = input_cost + output_cost
return {
"monthly_requests": monthly_requests,
"input_cost": input_cost,
"output_cost": output_cost,
"total_cost": total_cost,
"daily_average": total_cost / 30
}
# 场景1:代码审查系统
code_review = calculate_monthly_cost(
daily_requests=1000,
avg_input_tokens=2000, # 代码片段
avg_output_tokens=500, # 审查建议
model="sonnet"
)
print(f"代码审查系统月成本: ${code_review['total_cost']:.2f}")
# 输出: 代码审查系统月成本: $405.00
# 场景2:复杂算法设计
algorithm_design = calculate_monthly_cost(
daily_requests=50,
avg_input_tokens=5000, # 详细需求
avg_output_tokens=3000, # 完整实现
model="opus"
)
print(f"算法设计服务月成本: ${algorithm_design['total_cost']:.2f}")
# 输出: 算法设计服务月成本: $675.00
成本优化策略
1. 动态模型选择
根据任务复杂度自动选择最经济的模型:
pythonclass CostOptimizer:
def __init__(self, complexity_analyzer):
self.analyzer = complexity_analyzer
self.cost_saved = 0
def select_model(self, task):
"""基于任务复杂度选择模型"""
complexity = self.analyzer.analyze(task)
# 复杂度阈值策略
if complexity.score < 6:
model = "sonnet"
reason = "任务简单,Sonnet足够"
elif complexity.score < 8 and complexity.requires_speed:
model = "sonnet"
reason = "需要快速响应"
elif complexity.score >= 8 or complexity.requires_deep_reasoning:
model = "opus"
reason = "需要深度推理"
else:
model = "sonnet"
reason = "默认选择经济型"
# 计算节省的成本
if model == "sonnet":
self.cost_saved += self._estimate_savings(task)
return {
"model": model,
"reason": reason,
"complexity_score": complexity.score,
"estimated_cost": self._estimate_cost(task, model)
}
2. 缓存和批处理组合
组合使用多种优化技术:
pythonclass CombinedOptimization:
def __init__(self):
self.cache = {}
self.batch_queue = []
self.batch_size = 10
self.batch_timeout = 5 # 秒
async def process_request(self, request):
"""综合优化处理请求"""
# 1. 检查缓存
cache_key = self._generate_cache_key(request)
if cache_key in self.cache:
return self.cache[cache_key]
# 2. 判断是否适合批处理
if self._is_batchable(request):
return await self._batch_process(request)
# 3. 直接处理
result = await self._direct_process(request)
# 4. 更新缓存
self.cache[cache_key] = result
return result
async def _batch_process(self, request):
"""批处理请求"""
self.batch_queue.append(request)
# 达到批次大小或超时则处理
if len(self.batch_queue) >= self.batch_size:
return await self._process_batch()
else:
# 等待更多请求或超时
await asyncio.sleep(self.batch_timeout)
return await self._process_batch()
3. 使用API中转服务
通过laozhang.ai等中转服务,可以获得额外的成本优势:
- 统一的API接口,方便切换模型
- 相比官方价格便宜高达80%
- 免费赠送额度供测试使用
- 专门的网络优化,降低延迟
注册地址:https://api.laozhang.ai/register/
ROI(投资回报率)分析
让我们通过一个实际案例分析使用AI模型的投资回报:
pythondef calculate_roi(scenario):
"""计算AI投资回报率"""
# 成本计算
ai_cost = scenario["monthly_ai_cost"]
# 收益计算
time_saved = scenario["hours_saved_monthly"] * scenario["hourly_rate"]
quality_improvement = scenario["revenue_increase"]
error_reduction = scenario["error_cost_saved"]
total_benefit = time_saved + quality_improvement + error_reduction
# ROI计算
roi = ((total_benefit - ai_cost) / ai_cost) * 100
return {
"monthly_cost": ai_cost,
"monthly_benefit": total_benefit,
"net_benefit": total_benefit - ai_cost,
"roi_percentage": roi,
"payback_months": ai_cost / (total_benefit - ai_cost) if total_benefit > ai_cost else None
}
# 实际案例:某电商公司客服系统
customer_service_roi = calculate_roi({
"monthly_ai_cost": 2000, # 使用Sonnet的月成本
"hours_saved_monthly": 200, # 节省人工小时数
"hourly_rate": 25, # 客服时薪
"revenue_increase": 3000, # 因响应速度提升带来的额外收入
"error_cost_saved": 1000 # 减少错误处理成本
})
print(f"ROI: {customer_service_roi['roi_percentage']:.1f}%")
print(f"投资回收期: {customer_service_roi['payback_months']:.1f}个月")
# 输出: ROI: 350.0%
# 输出: 投资回收期: 0.3个月
【安全合规】企业级部署考虑
在企业环境中部署AI模型,安全性和合规性是必须考虑的重要因素。
AI安全等级(ASL)差异
Anthropic为不同模型设定了不同的安全等级:
- Claude 4 Sonnet:ASL-2(标准级)
- Claude 4 Opus:ASL-3(提升级),首个达到此级别的模型
这意味着什么?
ASL-2(Sonnet)特点:
- 适合大多数商业应用
- 标准的安全防护措施
- 较少的使用限制
- 快速部署和集成
ASL-3(Opus)特点:
- 需要更严格的访问控制
- 增强的监控和审计要求
- 适合处理敏感数据的场景
- 可能需要额外的合规审查
企业部署最佳实践
1. 访问控制和审计
pythonclass EnterpriseClaudeClient:
def __init__(self, config):
self.config = config
self.audit_logger = self._setup_audit_logging()
def _setup_audit_logging(self):
"""设置审计日志"""
logger = logging.getLogger('claude_audit')
handler = logging.FileHandler('claude_audit.log')
handler.setFormatter(logging.Formatter(
'%(asctime)s - %(user)s - %(model)s - %(action)s - %(details)s'
))
logger.addHandler(handler)
return logger
def call_with_audit(self, user_id, prompt, model="sonnet"):
"""带审计的API调用"""
# 权限检查
if not self._check_permissions(user_id, model):
self.audit_logger.warning(
"Permission denied",
extra={
"user": user_id,
"model": model,
"action": "call_denied",
"details": "Insufficient permissions"
}
)
raise PermissionError(f"User {user_id} cannot access {model}")
# 内容审查
if self._contains_sensitive_data(prompt):
# 对敏感数据使用Opus的增强安全特性
model = "opus"
# 记录调用
self.audit_logger.info(
"API call",
extra={
"user": user_id,
"model": model,
"action": "call_started",
"details": f"Prompt length: {len(prompt)}"
}
)
# 执行调用
response = self._execute_call(prompt, model)
return response
2. 数据隐私保护
pythonclass PrivacyProtectedClient:
def __init__(self):
self.pii_detector = PIIDetector()
self.encryption = DataEncryption()
def process_with_privacy(self, data, model="sonnet"):
"""隐私保护处理流程"""
# 1. 检测PII
pii_entities = self.pii_detector.detect(data)
# 2. 脱敏处理
masked_data, mapping = self._mask_pii(data, pii_entities)
# 3. API调用
response = self.client.call(masked_data, model=model)
# 4. 还原PII(如果需要)
if self._should_restore_pii(response):
response = self._restore_pii(response, mapping)
return response
def _mask_pii(self, text, entities):
"""PII脱敏"""
mapping = {}
masked_text = text
for entity in entities:
placeholder = f"[{entity.type}_{entity.id}]"
mapping[placeholder] = entity.value
masked_text = masked_text.replace(entity.value, placeholder)
return masked_text, mapping
3. 合规性检查清单
企业部署前的合规检查要点:
- 数据存储位置符合法规要求
- API调用日志保留期限设置
- 用户同意和隐私政策更新
- 敏感数据分类和处理流程
- 事件响应和通知机制
- 定期安全审计计划
【常见问题】Sonnet vs Opus选择疑难解答
Q1: 什么情况下Sonnet的表现会超过Opus?
这是一个很有趣的现象。根据实际测试,以下情况Sonnet可能表现更好:
- 直接性任务:当任务需要快速、直接的答案时
- 代码生成:特别是常见的编程模式和标准实现
- 实时交互:需要快速响应的对话场景
- 标准化流程:如代码格式化、文档生成等
原因分析:Sonnet经过优化,更擅长识别常见模式并快速给出实用答案。而Opus可能会"想太多",在简单任务上反而过度复杂化。
实例对比:
python# 任务:生成一个简单的REST API endpoint
# Sonnet响应(5秒):
# 直接给出清晰、可用的代码
# Opus响应(15秒):
# 先分析各种设计模式,讨论不同框架的优劣
# 最后给出的代码虽然更完善,但对于简单需求来说过度设计
Q2: 如何判断任务是否需要Extended Thinking?
Extended Thinking模式会显著增加延迟和成本,因此需要谨慎使用。以下是判断标准:
需要Extended Thinking的特征:
- 多步骤推理(超过3步)
- 需要考虑多个相互影响的因素
- 涉及复杂的逻辑判断
- 需要生成详细的实施方案
不需要Extended Thinking的特征:
- 事实性查询
- 简单的代码补全
- 格式转换
- 单步推理任务
判断工具:
pythondef should_use_extended_thinking(task_description):
"""判断是否需要深度思考"""
indicators = {
"complex_reasoning": ["分析", "推理", "评估", "权衡"],
"multi_step": ["步骤", "流程", "方案", "架构"],
"deep_understanding": ["为什么", "原理", "本质", "深入"]
}
score = 0
for category, keywords in indicators.items():
if any(kw in task_description for kw in keywords):
score += 1
return score >= 2 # 至少满足2个类别
Q3: 在预算有限的情况下,如何最大化AI的价值?
预算优化策略的核心是"把钱花在刀刃上":
1. 分级使用策略
pythonclass BudgetOptimizedRouter:
def __init__(self, monthly_budget):
self.budget = monthly_budget
self.spent = 0
self.usage_tiers = {
"tier1": {"model": "sonnet", "limit": 0.7}, # 70%预算
"tier2": {"model": "opus", "limit": 0.25}, # 25%预算
"buffer": {"model": "sonnet", "limit": 0.05} # 5%缓冲
}
def route_request(self, request):
"""基于预算的请求路由"""
budget_utilization = self.spent / self.budget
if budget_utilization < self.usage_tiers["tier1"]["limit"]:
# 预算充足,根据任务选择
return self._select_by_task(request)
elif budget_utilization < 0.95:
# 预算吃紧,优先Sonnet
return "sonnet"
else:
# 预算即将耗尽,仅关键任务使用
return "sonnet" if request.priority == "critical" else None
2. 成本效益最大化
- 使用laozhang.ai等中转服务节省80%成本
- 实施智能缓存减少重复调用
- 批量处理相似请求
- 优化提示词减少token使用
Q4: 两个模型可以如何配合使用?
最佳实践是建立一个智能的模型协作系统:
pythonclass ModelOrchestrator:
"""模型协调器:让Sonnet和Opus协同工作"""
def __init__(self):
self.sonnet = SonnetClient()
self.opus = OpusClient()
def collaborative_solve(self, complex_task):
"""协作解决复杂任务"""
# Step 1: 用Opus分析和规划
plan = self.opus.analyze_and_plan(
f"请分析这个任务并制定详细执行计划:{complex_task}",
extended_thinking=True
)
# Step 2: 用Sonnet执行具体步骤
results = []
for step in plan.steps:
if step.complexity < 7:
# 简单步骤用Sonnet
result = self.sonnet.execute(step.description)
else:
# 复杂步骤用Opus
result = self.opus.execute(step.description)
results.append(result)
# Step 3: 用Opus总结和优化
final_result = self.opus.synthesize(
results,
original_task=complex_task
)
return final_result
Q5: 切换模型时需要注意什么?
模型切换不仅仅是改个参数,还需要考虑以下因素:
1. 提示词适配
pythonclass PromptAdapter:
"""根据模型特点调整提示词"""
def adapt_prompt(self, original_prompt, target_model):
if target_model == "sonnet":
# Sonnet偏好简洁直接
return self._simplify_prompt(original_prompt)
else: # opus
# Opus可以处理更复杂的指令
return self._enrich_prompt(original_prompt)
def _simplify_prompt(self, prompt):
"""简化提示词for Sonnet"""
# 移除冗余说明
# 使用更直接的指令
# 减少上下文长度
return simplified_prompt
def _enrich_prompt(self, prompt):
"""丰富提示词for Opus"""
# 添加更多背景信息
# 明确期望的推理深度
# 指定输出格式要求
return enriched_prompt
2. 输出格式差异处理 两个模型的输出风格可能不同,需要统一处理:
pythonclass OutputNormalizer:
"""统一不同模型的输出格式"""
def normalize(self, output, source_model):
if source_model == "sonnet":
# Sonnet输出通常更简洁
return self._expand_if_needed(output)
else: # opus
# Opus输出可能过于详细
return self._summarize_if_needed(output)
Q6: 如何评估模型选择的效果?
建立完善的评估体系至关重要:
pythonclass ModelEvaluator:
"""模型效果评估器"""
def __init__(self):
self.metrics = {
"accuracy": [],
"latency": [],
"cost": [],
"user_satisfaction": []
}
def evaluate_decision(self, task, chosen_model, result):
"""评估模型选择决策"""
evaluation = {
"task_id": task.id,
"model": chosen_model,
"accuracy_score": self._measure_accuracy(result, task.expected),
"response_time": result.latency,
"cost": result.token_count * self._get_price(chosen_model),
"complexity_match": self._assess_complexity_match(task, chosen_model)
}
# 判断是否应该使用另一个模型
if evaluation["complexity_match"] < 0.7:
evaluation["recommendation"] = self._suggest_alternative(task, chosen_model)
return evaluation
def generate_report(self):
"""生成评估报告"""
return {
"model_usage": self._calculate_usage_stats(),
"cost_analysis": self._analyze_costs(),
"performance_metrics": self._summarize_performance(),
"optimization_suggestions": self._generate_suggestions()
}
Q7: 两个模型的上下文窗口如何最优利用?
虽然两个模型都支持大上下文,但优化使用方式不同:
Sonnet上下文优化:
pythonclass SonnetContextOptimizer:
"""Sonnet上下文优化器"""
def optimize_context(self, messages, max_tokens=50000):
"""优化上下文for Sonnet"""
# Sonnet策略:保持最相关的信息
optimized = []
token_count = 0
# 优先级:最新消息 > 关键指令 > 历史上下文
for msg in reversed(messages):
msg_tokens = self._count_tokens(msg)
if token_count + msg_tokens <= max_tokens:
optimized.insert(0, msg)
token_count += msg_tokens
else:
# 压缩或省略
compressed = self._compress_message(msg)
if compressed:
optimized.insert(0, compressed)
break
return optimized
Opus上下文优化:
pythonclass OpusContextOptimizer:
"""Opus上下文优化器"""
def optimize_context(self, messages, task_complexity):
"""优化上下文for Opus"""
# Opus策略:提供完整的背景信息
if task_complexity > 8:
# 复杂任务:保留所有相关上下文
return self._include_full_context(messages)
else:
# 中等任务:智能筛选
return self._smart_filter(messages)
def _include_full_context(self, messages):
"""包含完整上下文用于深度推理"""
# 添加额外的背景信息
# 保留所有决策历史
# 包含相关文档
return enriched_messages
Q8: 如何处理模型输出的一致性问题?
不同模型的输出风格差异可能影响用户体验:
pythonclass ConsistencyManager:
"""输出一致性管理器"""
def __init__(self):
self.style_guide = self._load_style_guide()
self.output_templates = self._load_templates()
def ensure_consistency(self, raw_output, source_model):
"""确保输出一致性"""
# 1. 格式标准化
formatted = self._standardize_format(raw_output)
# 2. 语气统一
tone_adjusted = self._adjust_tone(formatted, self.style_guide)
# 3. 结构对齐
structured = self._apply_template(tone_adjusted, self.output_templates)
return structured
def _standardize_format(self, output):
"""标准化输出格式"""
# 统一代码块格式
# 规范列表样式
# 调整段落结构
return standardized
【总结】构建高效的AI应用策略
经过深入对比和分析,我们可以得出以下关键结论:
核心选择原则
选择Claude 4 Sonnet当:
- ✅ 日常开发任务(80%以上的场景)
- ✅ 需要快速响应(延迟敏感)
- ✅ 预算有限(成本仅为Opus的20%)
- ✅ 批量处理任务
- ✅ 标准化的工作流程
选择Claude 4 Opus当:
- ✅ 复杂的系统设计和架构
- ✅ 需要深度推理和分析
- ✅ 关键业务决策
- ✅ 长时间持续工作(可达7小时)
- ✅ 创新性和探索性任务
最佳实践总结
- 建立智能路由系统:根据任务特征自动选择模型
- 实施分级使用策略:日常用Sonnet,关键时刻用Opus
- 优化成本结构:通过缓存、批处理和中转服务降低成本
- 监控和迭代:持续评估模型选择的效果并优化
行动建议
立即开始:
- 注册laozhang.ai获取API访问:https://api.laozhang.ai/register/
- 使用本文提供的代码示例搭建智能路由系统
- 从小规模试点开始,逐步扩大应用范围
- 建立监控体系,持续优化使用策略
记住,选择模型不是"非此即彼",而是"因材施教"。通过合理的模型组合和优化策略,你可以在控制成本的同时,充分发挥AI的潜力,为业务创造真正的价值。
无论是追求极致性价比的Sonnet,还是追求极限能力的Opus,它们都是你AI工具箱中的得力助手。关键在于理解它们的特点,在正确的场景使用正确的工具。
💡 专业建议:先从Sonnet开始,当遇到Sonnet无法完美解决的问题时,再考虑使用Opus。这样可以在保证效果的同时,将成本控制在最优水平。