2025 Complete Guide to Fixing Claude API 429 Errors: Rate Limit Solutions
Exclusive guide to solving Claude API 429 errors with 8 effective strategies for handling rate limits, enhancing API efficiency, and implementing robust error handling. Includes complete code examples and best practices!

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
Complete Guide to Fixing Claude API 429 Errors (2025 Edition)
🔥 Verified effective as of June 2025 - This guide provides the most up-to-date strategies for dealing with Claude API rate limiting challenges.
Have you encountered the frustrating "429 Too Many Requests" error when using Claude's API? You're not alone. As Claude's popularity continues to grow, developers increasingly face rate limiting challenges, particularly during high-traffic periods or intensive development cycles.
In this comprehensive guide, I'll share 8 proven strategies to effectively overcome Claude API 429 errors. Whether you're building a production application or conducting experimentation, these solutions will help you maintain smooth API interactions while respecting Anthropic's rate limits.
Understanding Claude API 429 Errors
Before diving into solutions, it's essential to understand what causes these errors. The "429 Too Many Requests" response is a standard HTTP status code indicating that you've exceeded the allowed request rate.
Types of Rate Limits
Claude API implements several types of rate limits:
- Requests per minute (RPM) - Limits the number of API calls within a 60-second window
- Tokens per minute (TPM) - Caps the total tokens (both input and output) processed within a minute
- Daily token quota - Restricts the total tokens processed within a 24-hour period
When you exceed any of these limits, the API returns a 429 error with a message specifying which limit was breached and a Retry-After header indicating the recommended wait time before retrying.
Common Error Messages
- "Number of request tokens has exceeded your per-minute rate limit"
- "Number of request tokens has exceeded your daily rate limit"
- "Number of requests has exceeded your per-minute rate limit"
- "Quota exceeded" (specifically for Claude on Google Cloud)
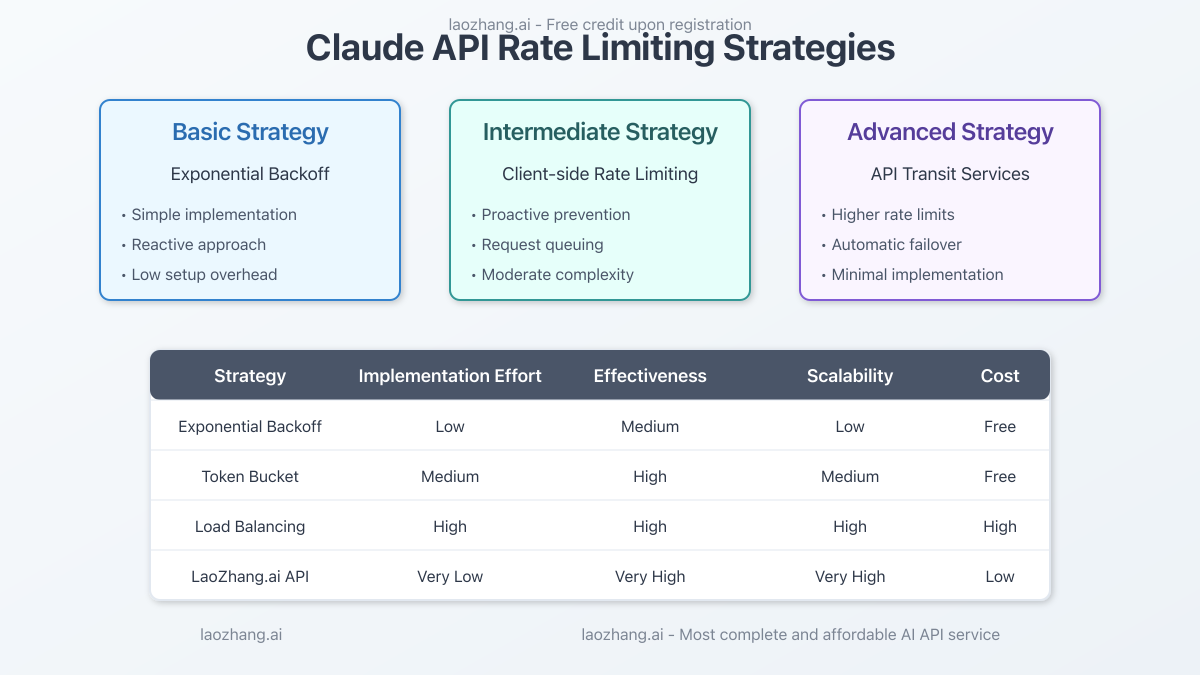
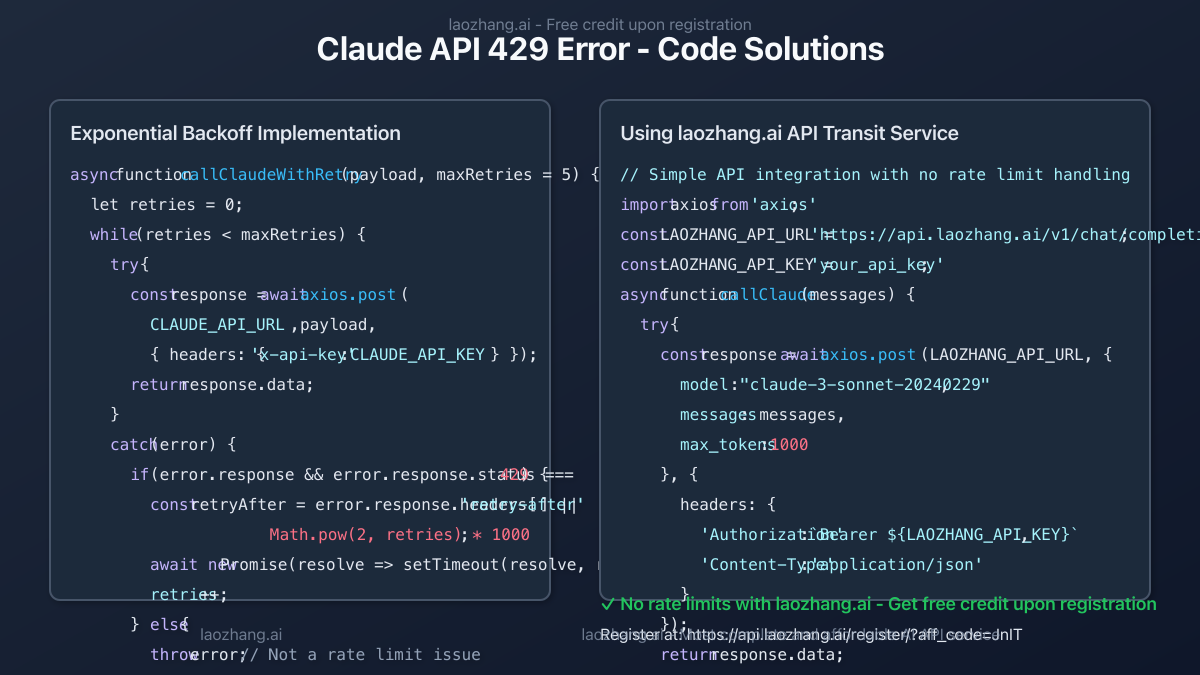
Strategy 1: Implement Exponential Backoff
The simplest approach to handling 429 errors is implementing exponential backoff - automatically retrying requests with progressively longer wait times between attempts.
javascriptasync function callClaudeWithRetry(payload, maxRetries = 5) {
let retries = 0;
while (retries < maxRetries) {
try {
const response = await axios.post(CLAUDE_API_URL, payload, {
headers: { 'x-api-key': CLAUDE_API_KEY }
});
return response.data;
} catch (error) {
if (error.response && error.response.status === 429) {
// Get retry-after header or calculate backoff time
const retryAfter = error.response.headers['retry-after'] ||
Math.pow(2, retries) * 1000;
console.log(`Rate limited. Retrying after ${retryAfter}ms. Attempt ${retries + 1}/${maxRetries}`);
await new Promise(resolve => setTimeout(resolve, retryAfter));
retries++;
} else {
throw error; // Not a rate limit issue
}
}
}
throw new Error("Maximum retries reached with rate limiting");
}
This solution is reactive but straightforward, automatically handling temporary rate limits without requiring additional infrastructure.
Strategy 2: Client-Side Rate Limiting
A more proactive approach is implementing client-side rate limiting to prevent hitting API limits in the first place.
javascriptconst { RateLimiter } = require('limiter');
// Create a limiter: 10 requests per minute
const limiter = new RateLimiter({ tokensPerInterval: 10, interval: 'minute' });
async function callClaudeWithRateLimit(payload) {
// Wait until a token is available
await limiter.removeTokens(1);
try {
const response = await axios.post(CLAUDE_API_URL, payload, {
headers: { 'x-api-key': CLAUDE_API_KEY }
});
return response.data;
} catch (error) {
// Handle other errors
throw error;
}
}
This strategy helps you stay within Claude's limits by self-regulating your request rate, significantly reducing 429 errors.
Strategy 3: Token Bucket Implementation
For more precise control, implement a token bucket algorithm that manages both request frequency and token usage.
javascriptclass ClaudeRateLimiter {
constructor(requestsPerMinute = 10, tokensPerMinute = 10000) {
this.requestBucket = new TokenBucket(requestsPerMinute, 60);
this.tokenBucket = new TokenBucket(tokensPerMinute, 60);
this.requestQueue = [];
this.processing = false;
}
async submitRequest(messages, maxTokens) {
// Estimate token usage (input + expected output)
const estimatedTokens = this.estimateTokens(messages, maxTokens);
return new Promise((resolve, reject) => {
this.requestQueue.push({
messages,
maxTokens,
estimatedTokens,
resolve,
reject
});
if (!this.processing) this.processQueue();
});
}
async processQueue() {
if (this.requestQueue.length === 0) {
this.processing = false;
return;
}
this.processing = true;
const request = this.requestQueue[0];
try {
// Wait for both request slot and token availability
await this.requestBucket.consume(1);
await this.tokenBucket.consume(request.estimatedTokens);
const response = await axios.post(CLAUDE_API_URL, {
model: "claude-3-sonnet-20240229",
messages: request.messages,
max_tokens: request.maxTokens
}, {
headers: { 'x-api-key': CLAUDE_API_KEY }
});
request.resolve(response.data);
} catch (error) {
request.reject(error);
} finally {
this.requestQueue.shift();
setTimeout(() => this.processQueue(), 0);
}
}
estimateTokens(messages, maxTokens) {
// Simplified token estimation logic
let inputTokens = 0;
messages.forEach(msg => inputTokens += msg.content.length / 4);
return inputTokens + maxTokens;
}
}
This approach effectively manages both request frequency and token consumption, providing the highest level of control for high-volume applications.
Strategy 4: Request Batching and Caching
Reduce API calls by batching similar requests and implementing an effective caching strategy.
javascriptconst LRU = require('lru-cache');
const hash = require('object-hash');
// Create cache with 1-hour TTL
const cache = new LRU({
max: 100, // Maximum items in cache
ttl: 1000 * 60 * 60, // 1 hour TTL
});
async function callClaudeWithCache(messages) {
// Generate a deterministic hash of the request
const requestHash = hash(messages);
// Check if response is in cache
if (cache.has(requestHash)) {
console.log('Cache hit! Returning cached response');
return cache.get(requestHash);
}
// Call API if not in cache
try {
const response = await callClaudeWithRetry({
model: "claude-3-sonnet-20240229",
messages: messages,
max_tokens: 1000
});
// Cache the result
cache.set(requestHash, response);
return response;
} catch (error) {
throw error;
}
}
Caching is especially effective for applications with repetitive or similar queries, significantly reducing the number of API calls required.
Strategy 5: Request Prioritization and Queuing
For applications with varying request importance, implement a priority queue system to ensure critical requests get processed first.
javascriptconst PriorityQueue = require('priorityqueuejs');
class ClaudePriorityRequestManager {
constructor() {
// Queue with highest priority first
this.queue = new PriorityQueue((a, b) => {
return a.priority - b.priority; // Lower number = higher priority
});
this.processing = false;
}
// Add a request to the queue with priority
async enqueueRequest(messages, priority = 5) {
return new Promise((resolve, reject) => {
this.queue.enq({
messages,
priority,
resolve,
reject,
timestamp: Date.now()
});
if (!this.processing) this.processQueue();
});
}
async processQueue() {
if (this.queue.isEmpty()) {
this.processing = false;
return;
}
this.processing = true;
const request = this.queue.deq();
try {
// Rate limiting logic here
const response = await callClaudeWithRetry({
model: "claude-3-sonnet-20240229",
messages: request.messages,
max_tokens: 1000
});
request.resolve(response);
} catch (error) {
request.reject(error);
} finally {
setTimeout(() => this.processQueue(), 250); // Process next after 250ms
}
}
}
This approach ensures that high-priority requests receive preferential treatment, making it ideal for applications with varying degrees of request urgency.
Strategy 6: Multiple API Keys and Load Balancing
For enterprise applications with higher volume requirements, rotate between multiple API keys to distribute the load.
javascriptclass ClaudeLoadBalancer {
constructor(apiKeys) {
this.apiKeys = apiKeys.map(key => ({
key,
lastUsed: 0,
rateLimit: { reset: 0, remaining: 50 } // Default limits
}));
}
async getNextAvailableKey() {
const now = Date.now();
// Sort keys by availability
this.apiKeys.sort((a, b) => {
// If a key has reset its limits, it's immediately available
if (a.rateLimit.reset < now && b.rateLimit.reset >= now) return -1;
if (b.rateLimit.reset < now && a.rateLimit.reset >= now) return 1;
// If both keys are within the same rate limit window
if (a.rateLimit.remaining !== b.rateLimit.remaining) {
return b.rateLimit.remaining - a.rateLimit.remaining;
}
// Otherwise use least recently used
return a.lastUsed - b.lastUsed;
});
const selectedKey = this.apiKeys[0];
// If no keys available, wait until the first one resets
if (selectedKey.rateLimit.remaining <= 0 && selectedKey.rateLimit.reset > now) {
const waitTime = selectedKey.rateLimit.reset - now + 100; // Add 100ms buffer
await new Promise(resolve => setTimeout(resolve, waitTime));
// Recursive call after waiting
return this.getNextAvailableKey();
}
// Mark key as used
selectedKey.lastUsed = now;
selectedKey.rateLimit.remaining--;
return selectedKey.key;
}
async callClaude(messages) {
const apiKey = await this.getNextAvailableKey();
try {
const response = await axios.post(CLAUDE_API_URL, {
model: "claude-3-sonnet-20240229",
messages,
max_tokens: 1000
}, {
headers: { 'x-api-key': apiKey }
});
// Update rate limit info from headers
const keyData = this.apiKeys.find(k => k.key === apiKey);
if (keyData && response.headers) {
keyData.rateLimit = {
reset: parseInt(response.headers['ratelimit-reset'] || '0') * 1000 + Date.now(),
remaining: parseInt(response.headers['ratelimit-remaining'] || '0')
};
}
return response.data;
} catch (error) {
if (error.response && error.response.status === 429) {
// Update rate limit for this key
const keyData = this.apiKeys.find(k => k.key === apiKey);
if (keyData) {
keyData.rateLimit = {
reset: Date.now() + 60000, // Assume 1 minute penalty
remaining: 0
};
}
// Retry with a different key
return this.callClaude(messages);
}
throw error;
}
}
}
This advanced strategy works well for enterprise applications that need to process a high volume of requests while minimizing rate limit errors.
Strategy 7: Use an API Transit Service (Recommended)
For the simplest solution with the highest rate limits, consider using an API transit service like laozhang.ai. These services aggregate requests across multiple API keys and offer simplified access to Claude's API with higher rate limits.
javascriptimport axios from 'axios';
const LAOZHANG_API_URL = 'https://api.laozhang.ai/v1/chat/completions';
const LAOZHANG_API_KEY = 'your_api_key'; // Get from https://api.laozhang.ai/register/
async function callClaude(messages) {
try {
const response = await axios.post(LAOZHANG_API_URL, {
model: "claude-3-sonnet-20240229",
messages: messages,
max_tokens: 1000
}, {
headers: {
'Authorization': `Bearer ${LAOZHANG_API_KEY}`,
'Content-Type': 'application/json'
}
});
return response.data;
} catch (error) {
console.error("API request failed:", error);
throw error;
}
}
🔧 Pro Tip: Register at laozhang.ai to get free API credits. Their service offers the most affordable and comprehensive Claude API proxy, eliminating rate limit concerns while maintaining full API compatibility.
Strategy 8: Hybrid Approach for Enterprise Applications
For large-scale enterprise applications, combine multiple strategies for the most robust solution:
- Use an API transit service for baseline capacity
- Implement client-side rate limiting as a safety measure
- Add exponential backoff for resilience
- Incorporate caching for frequently repeated requests
- Set up request prioritization for mission-critical operations
This multi-layered approach provides the highest level of protection against rate limiting while ensuring optimal performance.
javascript// Simplified implementation of hybrid approach
class EnterpriseClaudeClient {
constructor(config) {
this.apiTransit = new LaoZhangApiClient(config.laozhangApiKey);
this.directApi = new ClaudeLoadBalancer(config.claudeApiKeys);
this.rateLimiter = new TokenBucketLimiter(config.requestsPerMinute);
this.cache = new LRU({ max: 500, ttl: config.cacheTtl });
this.priorityQueue = new PriorityRequestQueue();
}
async query(messages, options = {}) {
const { priority = 5, bypassCache = false, forceDirectApi = false } = options;
// Check cache unless bypassed
const cacheKey = this.getCacheKey(messages);
if (!bypassCache && this.cache.has(cacheKey)) {
return this.cache.get(cacheKey);
}
return new Promise((resolve, reject) => {
this.priorityQueue.enqueue({
execute: async () => {
await this.rateLimiter.consume(1);
try {
// Try API transit service first unless directed to use direct API
const api = forceDirectApi ? this.directApi : this.apiTransit;
const result = await api.callClaude(messages);
// Cache successful results
this.cache.set(cacheKey, result);
return result;
} catch (error) {
if (error.isTransitError && !forceDirectApi) {
// Fallback to direct API if transit fails
return this.query(messages, { ...options, forceDirectApi: true });
}
throw error;
}
},
priority,
resolve,
reject
});
});
}
getCacheKey(messages) {
// Generate deterministic hash from messages
return hash(messages);
}
}
This enterprise-grade solution ensures maximum uptime and resilience against rate limiting, making it ideal for production applications with high reliability requirements.
Requesting Higher Rate Limits
If you consistently encounter rate limit errors despite implementing these strategies, you may need higher limits for your application. Anthropic offers the following options:
- Upgrade your plan: Review Anthropic's pricing tiers for higher rate limits
- Request quota increase: Enterprise customers can request increased limits through Anthropic's support
- For Google Cloud users: Request quota increases through the Google Cloud Console
- Contact Anthropic sales: For enterprise-level requirements with custom solutions
Remember that rate limits exist to ensure fair usage across all customers, so be prepared to justify your higher limit requirements.
Conclusion
Claude API 429 errors can be frustrating, but they're a manageable challenge with the right strategies. From simple exponential backoff to sophisticated enterprise solutions, this guide provides multiple approaches to overcome rate limiting.
For developers seeking the quickest solution, I recommend the API transit service approach (Strategy 7) using laozhang.ai. It offers immediate relief from rate limiting concerns while providing all the benefits of Claude's powerful API.
Remember that respecting API limits while implementing these strategies ensures that you maintain a good relationship with Anthropic while delivering a reliable experience to your users.
Frequently Asked Questions
What exactly causes Claude API 429 errors?
Claude API 429 errors occur when you exceed one of three rate limits: requests per minute, tokens per minute, or daily token quota. The API returns a 429 response code with a specific message indicating which limit was exceeded.
How do I know which rate limit I've exceeded?
The error message in the 429 response will specify which limit you've exceeded. For example, "Number of request tokens has exceeded your per-minute rate limit" indicates you've hit the tokens-per-minute limit.
Will implementing exponential backoff solve all my rate limit problems?
Exponential backoff is a reactive solution that helps recover from rate limiting, but it doesn't prevent hitting the limits. For high-volume applications, combine it with proactive strategies like client-side rate limiting or API transit services.
Are there any downsides to using API transit services?
While API transit services offer higher limits and simplified implementation, they may add a small latency overhead (typically milliseconds) and involve a service fee. However, for most applications, the benefits of avoiding rate limits far outweigh these considerations.
How can I estimate token usage to stay within limits?
A rough estimation is approximately 4 characters per token for English text. For more precise counting, use Claude's tokenizer tools or implement a client-side tokenizer that matches Claude's tokenization algorithm.
Do webhook-based implementations help with rate limiting?
Yes, webhook implementations can be more efficient as they're asynchronous and don't require keeping connections open while waiting for responses, which can help manage rate limits more effectively.
What's the best approach for a small application with occasional Claude API usage?
For small applications with low volume, implementing exponential backoff with caching is usually sufficient. These strategies are simple to implement and require minimal infrastructure changes.
How often do rate limits reset?
Per-minute rate limits reset every 60 seconds. Daily token quotas reset at midnight UTC. The specific reset time for your request will be provided in the "Retry-After" header in the 429 response.