Claude API 速率限制指南:2026 年仍适用的 429 排查、Tier 升级与提额策略
基于 2026-03-18 官方文档重写的 Claude API 速率限制指南,重点解释 RPM、ITPM、OTPM、429 与 acceleration limits,以及何时该用缓存、Message Batches、队列整形或直接升 tier。

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
很多关于 Claude API 速率限制的旧文章,现在最大的问题不是“写得不够多”,而是把某一周抓到的数字,当成可以长期复用的结论。 这会直接误导排障动作。
Anthropic 在 2025-07、2025-08 和 2026-02 的 API release notes 里都记录过 rate limit 调整或相关能力变化,这意味着你今天看到的一张静态限额表,很可能几个月后就只剩参考价值(Anthropic API Release Notes,2026-03-18)。 如果你还在照着 2025 年初那批文章里的固定表格做容量规划,出错并不奇怪。
这篇文章只保留到 2026-03-18 仍能被官方页面验证的内容。 更重要的是,我不会再把“八个技巧”平铺给你,而是把它们压缩成一个更实用的问题:当 Claude API 报 429 时,你现在最该改的是队列、缓存、批处理、上下文结构,还是采购策略。
TL;DR
- Anthropic 当前的核心限流维度是 RPM、ITPM、OTPM,并采用 token bucket 算法;所以“平均每分钟没超”不代表短时间突发一定不会被拦(Anthropic Rate Limits,2026-03-18)。
429不只代表你超了长期配额,也可能是 acceleration limits,也就是流量爬升过快;看到retry-after时,优先按它退避,而不是立刻无限重试(Anthropic Errors;Anthropic Rate Limits,2026-03-18)。- 对重复前缀很重的请求,prompt caching 往往比单纯升 tier 更省钱;5 分钟 cache write 是基础输入价格的
1.25x,cache hit 是0.1x,经常重复的系统提示能明显降压(Anthropic Pricing;Anthropic Prompt Caching,2026-03-18)。- 对非实时任务,Message Batches 的输入和输出价格都是标准 API 的 50%,通常比你自己并发怼同步接口更稳,也更便宜(Anthropic Pricing,2026-03-18)。
- 真正该直接升 tier 的情况,是你已经做过排队整形、缓存、输出裁剪和离线批处理后,基线流量仍然长期贴近上限;如果问题主要来自大上下文或突发尖峰,先改请求结构通常比先花钱更有效。

Claude API 速率限制在 2026 年到底怎么计算
先把最基础的一点说清楚。 Anthropic 当前把速率限制拆成三个主维度:RPM、ITPM、OTPM,也就是每分钟请求数、每分钟输入 tokens、每分钟输出 tokens(Anthropic Rate Limits,2026-03-18)。
这和很多旧文里那种“只有 RPM 和 TPM”的写法已经不一样了。 如果你还在按“总 tokens 一把抓”的思路排查,很容易误判到底是输入太长,还是输出太多,还是纯粹请求打得太快。
官方文档还明确提到,Claude API 用的是 token bucket 算法。 翻成开发动作就是:即使你一分钟总量看起来没超,短时间内的流量尖峰还是可能触发限制(Anthropic Rate Limits,2026-03-18)。
所以,Claude API 速率限制从来不是一张简单的“每分钟上限表”。 它更像一个多维约束系统。
| 维度 | 你真正要关注的信号 | 最常见误判 | 更合适的第一反应 |
|---|---|---|---|
| RPM | 请求数量暴涨,尤其是并发 worker 同时出手 | 以为要立刻升 tier | 先做队列整形、并发上限和抖动退避 |
| ITPM | 输入前缀太长、RAG 拼太多、同一系统提示反复发送 | 以为只要减少 max_tokens 就行 | 先做 prompt caching、压缩上下文、拆请求 |
| OTPM | 输出过长、一次让模型生成太多内容 | 以为缓存能解决 | 先缩短输出目标、改分段生成 |
| Acceleration | 新流量突然拉高,即使长期平均量并不夸张 | 以为官方配额错了 | 先平滑放量,优先遵守 retry-after |
| Long context | 单次请求超过 200K tokens 或直接要上 1M context | 以为只是一般 ITPM 问题 | 先确认 tier 条件,再评估是否拆上下文 |
这里还有两个旧文最容易漏掉的细节。 第一,Anthropic 文档说明速率限制是按组织层级管理的,但可以在 workspace 再下压更低的额度(Anthropic Rate Limits,2026-03-18)。
这意味着如果你是团队环境,某个成员看到的“撞墙”并不一定来自 Anthropic 官方上限,也可能是你们自己给 workspace 设了更紧的阈值。 第二,官方也明确写了,不同模型有各自的限制,所以多模型并用可以帮你分散压力,但这不等于“随便切模型就能无限扩容”(Anthropic Rate Limits,2026-03-18)。
如果你需要一个当前仍有参考意义的最小样本,可以看 Tier 1 的官方示例。
以 2026-03-18 官方文档为准,Claude Sonnet 4 的 Tier 1 上限是 50 RPM / 30,000 ITPM / 8,000 OTPM,Claude Haiku 3.5 的 Tier 1 上限是 50 RPM / 50,000 ITPM / 10,000 OTPM(Anthropic Rate Limits,2026-03-18)。
但我不建议你把这些数字抄进 Excel 然后长期不看。 因为 Anthropic 既会更新模型,也会更新 rate limits,本篇后面所有判断逻辑都尽量不建立在“数字永远不变”这个前提上。
先判断你撞到的是哪一种 429
Claude API 的 429 不是一个足够精细的诊断结论。
它只是一个结果。
Anthropic 在错误文档里把 429 归类为 rate_limit_error,同时在 rate limits 文档里明确提醒,acceleration limits 也会返回 429,也就是你的流量爬升太陡时,系统会先拦住你(Anthropic Errors;Anthropic Rate Limits,2026-03-18)。
这件事对处理策略影响很大。 如果你根本不是长期配额不够,而是新版本上线后 30 秒内把并发拉满,那么“立刻升 tier”通常不是最优动作。
更可靠的排查顺序是:
- 先看是不是只在流量突然放大时才出错。
- 再看是输入 tokens 太多,还是输出 tokens 太多。
- 最后才判断是不是长期基线已经高到需要升 tier。
官方建议在收到限流时参考 retry-after。
如果接口同时返回了 anthropic-ratelimit-* 相关头部,你可以把 requests 和 tokens 的剩余量一起记进监控,用它来驱动更平滑的退避和排队(Anthropic Errors;Anthropic Rate Limits,2026-03-18)。
下面这段伪代码比“收到 429 就 sleep 1 秒再重试”更接近生产环境。
重点不是 SDK 细节,而是两个动作:遵守 retry-after,以及在外层加并发闸门。
pythonimport asyncio
import random
semaphore = asyncio.Semaphore(8)
async def send_with_backpressure(client, payload):
async with semaphore:
for attempt in range(5):
try:
return await client.messages.create(**payload)
except Exception as exc:
retry_after = getattr(exc, "retry_after", None)
if retry_after is None:
retry_after = min(2 ** attempt, 30)
# 给所有 worker 一个很小的随机抖动,避免同时醒来再撞一次
await asyncio.sleep(retry_after + random.uniform(0, 0.25))
raise RuntimeError("rate limited after retries")
如果你的症状是“夜里批量任务一开就集体撞墙”,先别急着去采购。 先把同步高并发改成受控队列,很多时候就能把 429 直接打掉大半。
如果你的症状是“少量请求也经常失败,而且每个请求都塞了很长的系统提示和文档片段”,那更像 ITPM 问题。 这时候你更该看缓存、上下文压缩和分层检索,而不是只盯着 RPM。
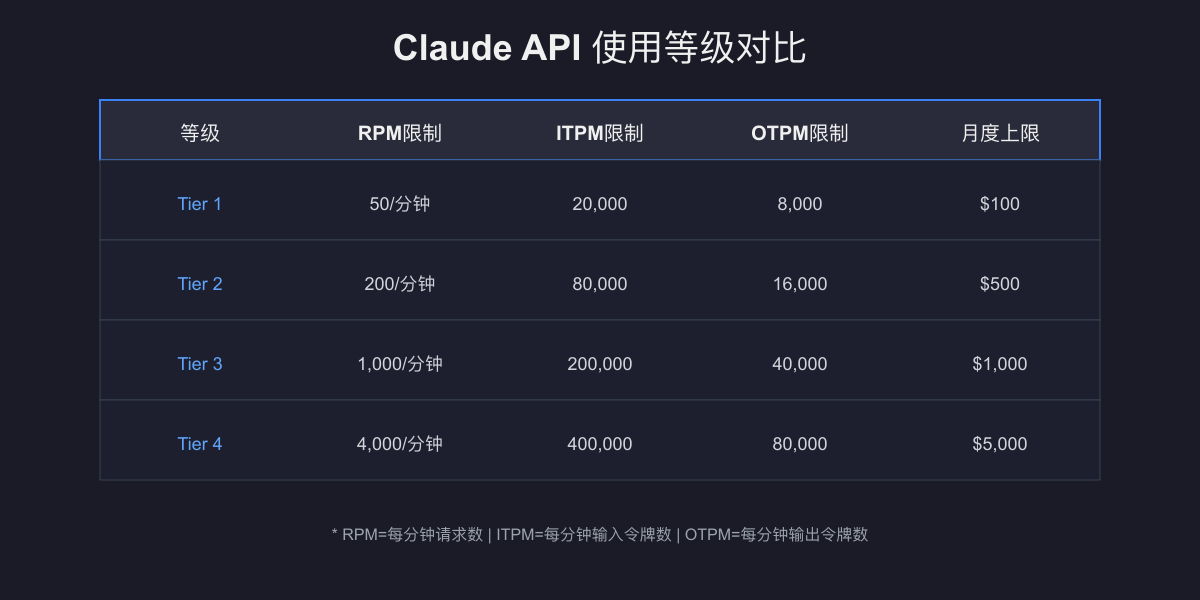
Usage Tier 和月度额度到底意味着什么
很多文章把 tier 写成“更高级别 = 更高 RPM”,这不算错,但太粗了。 真正决定你能否升级的,是充值金额和等待时间。
Anthropic 当前文档给出的 usage tier 条件如下:
| Tier | 升级条件 | 首笔付款等待时间 | 月度 max credits |
|---|---|---|---|
| Tier 1 | 累计充值至少 $5 | 无 | $100 |
| Tier 2 | 累计充值至少 $40 | 7 天 | $500 |
| Tier 3 | 累计充值至少 $200 | 7 天 | $1,000 |
| Tier 4 | 累计充值至少 $400 | 14 天 | $5,000 |
这组数据来自 Anthropic 官方 rate limits 页面(Anthropic Rate Limits,2026-03-18)。 对开发者来说,真正重要的理解是:tier 既是吞吐权限问题,也是消费门槛问题。
如果你今天才第一次给组织充值,即使业务已经起量,也不代表你能立刻跳到更高 tier。 这就是为什么很多团队在上线前一周就应该把付款和升 tier 节奏安排掉,而不是等到生产流量打上来再补动作。
另一个容易被忽略的点是,月度 max credits 和瞬时吞吐不是同一个概念。
你可能月账单还远没花满,但因为某个接口在一分钟内爆量,照样会先收到 429。
所以容量规划至少要拆成两层。 第一层问“这个月我能花多少”,第二层问“这分钟我能打多少”。
如果你的场景涉及超长上下文,这个判断还要再加第三层。 Anthropic 文档写得很直接:1M token context window 需要 Tier 4;而对超过 200K tokens 的请求,速率限制按 prompt tokens 生效(Anthropic Rate Limits,2026-03-18)。
这意味着做大文档问答、法务审阅、超长代码库分析时,所谓的“提额”可能根本不是一个单纯的 RPM 话题。 你很可能需要同时处理 tier、长上下文限制和请求结构。
还有一个旧文常见坑要顺手修正。
一些早期示例喜欢拿 claude-3-opus、claude-3-sonnet 这类模型名来举例,但 Anthropic 的 model deprecations 页面已经明确记录,Claude Sonnet 3 和 Claude 2.1 已在 2025-07-21 退役,Claude Opus 3 已在 2026-01-05 退役(Anthropic Model Deprecations,2026-03-18)。
如果你还在用那些老示例做流量分流策略,本身就已经偏离当前生产环境了。 这也是这篇文章选择重写而不是修补的原因。
决策矩阵:先改哪里,通常比先升 Tier 更重要
这一节是全文最重要的部分。 如果你只有两分钟,把这张表看完就够了。
| 你的真实症状 | 最可能的限制类型 | 第一优先动作 | 第二优先动作 | 为什么这样排 |
|---|---|---|---|---|
| 上线或定时任务开始后立刻出现 429 | Acceleration 或 RPM | 加队列、限并发、遵守 retry-after | 再评估 tier | 这类问题常常是流量曲线太陡,不是长期额度不够 |
| 相同系统提示或长前缀反复发送 | ITPM | Prompt caching | 再做上下文裁剪 | 重复前缀最适合先从缓存拿收益 |
| 单次回答总是过长 | OTPM | 下调 max_tokens,改分段生成 | 再拆任务 | 输出超长时,缓存帮不上大忙 |
| 夜间批量处理、不是实时接口 | RPM / ITPM / OTPM 的综合压力 | Message Batches | 再配合缓存 | 批处理便宜且更适合非实时任务 |
| 单次请求经常超过 200K tokens | Long context | 先重构上下文,再评估 Tier 4 | 再联系销售 | 长上下文本身就是不同的限制面 |
| 所有优化都做了,日常负载仍长期贴近上限 | 持续性容量不足 | 升 tier 或联系销售 | 再考虑 custom / priority | 这时继续挤代码收益会下降 |
这张表背后的核心逻辑只有一句话: 先判断你是在和哪一个瓶颈打架,再决定是改代码、改流量、改工作流,还是改采购。
第三方文章通常会把 cache、queue、batch、upgrade 分成独立小节介绍。 那样并没有错,但读者看完经常还是不知道现在该先做哪一步。
真正能改变决策的,不是再多背几个概念,而是知道哪种症状最适合哪种动作。 这也是本文和大多数旧版“技巧合集”最大的差别。
五种真正有效的降压与提额手段
1. 队列整形与并发闸门
如果你的请求大多是在线、同步、需要快速返回的,那么最先该做的通常不是 Message Batches,也不是换模型。 而是把并发入口先收住。
因为 token bucket 对突发流量本来就不友好。 当 20 个 worker 在同一秒一起醒来时,你看到的是“官方突然很严格”,系统看到的则是“一次性尖峰打满水桶”(Anthropic Rate Limits,2026-03-18)。
这时最有效的动作通常有三个:
- 给每个 worker 加全局并发上限。
- 把重试从固定 sleep 改成遵守
retry-after的指数退避。 - 给重试加随机抖动,避免所有请求同时恢复。
这类动作几乎不增加模型成本。 它解决的是流量曲线,而不是配额绝对值。
2. Prompt Caching
如果你的请求有一个长而稳定的前缀,比如固定系统提示、固定规则库、固定品牌规范、固定产品说明,那么 prompt caching 基本是第一优先级。 它往往同时改善 ITPM 和成本。
Anthropic 当前定价说明里,5 分钟 cache write 是基础 input 价格的 1.25x,1 小时 cache write 是 2x,cache hit 是基础 input 价格的 0.1x(Anthropic Pricing,2026-03-18)。
这看起来像“写入更贵”,但很多团队只看到第一步,没有把重复命中算进去。
拿 Claude Sonnet 4 的输入价格举一个容易算账的例子。
标准输入价格是 $3 / MTok(Anthropic Pricing,2026-03-18)。
假设你有一个 100K tokens 的稳定系统前缀,要在 5 分钟内复用 20 次。
如果完全不用缓存,单是这部分输入就要支付 2M tokens * $3 / MTok = $6。
如果你改成 5 分钟缓存:
- 第一次 cache write:
100K * $3.75 / MTok = $0.375 - 后面 19 次 cache hits:
1.9M * $0.30 / MTok = $0.57 - 合计约
$0.945
也就是说,只算稳定前缀这一部分,成本从 $6 降到约 $0.945。
这还没把它对 ITPM 压力的缓解算进去。
不过这里有一个很值得写进工程文档的小心点。
Anthropic rate limits 页面也明确说明,某些模型的 cache_read_input_tokens 仍然会计入 ITPM,这类模型会在文档里做标记(Anthropic Rate Limits,2026-03-18)。
所以,prompt caching 不是“缓存后 tokens 就彻底不存在了”。 更准确的说法是:它通常能显著降低重复前缀的成本和压力,但你仍然要看当前模型的计量规则。
3. Message Batches
如果你的任务不是实时的,比如夜间分析、批量分类、内容生成、数据清洗,那么 Message Batches 常常比你自己堆同步并发更像正确答案。 原因很简单:便宜,而且天然适合离线工作流。
Anthropic 当前定价页明确写明,Message Batches 的输入和输出价格都是标准 API 的 50%(Anthropic Pricing,2026-03-18)。 这不是一个边角折扣,而是足够改变架构选择的信号。
举个很实际的数字。
如果你要跑一批总量约 1M input tokens + 200K output tokens 的 Claude Sonnet 4 任务,标准同步 API 大约是 1M * $3 + 200K * $15 = $6。
如果改成 Batch,同样工作量大约就是 $3。
这对“几分钟内必须回结果”的在线接口没有意义。 但对“凌晨前跑完就行”的工作流非常有意义。
所以,只要你的业务允许异步,别把同步接口当万能锤。 很多限流问题,本质上是把不需要实时的事情硬塞进了实时链路。
4. 输出裁剪与任务拆分
OTPM 是很多团队后期才意识到的问题。 因为前期大家总盯着输入上下文,却忘了输出也有自己的上限。
如果你的请求经常要求模型一次性返回完整长文、全量 JSON 或超长报告,那么你会发现:即使输入不算夸张,也可能因为输出过长撞到天花板。 这时最稳的做法通常不是换缓存,而是缩短每轮产出,让模型分段生成。
比如,把“生成 4,000 行结构化结果”改成“先返回目录与任务计划,再按章节增量产出”,通常就比单次把输出开得很大更稳。 这类动作看起来像产品层改动,但实际上往往比单纯提额便宜很多。
5. Tier 升级或联系销售
升 tier 当然是有效手段。 问题只是,它不该总是第一手段。
当你已经确认:
- 429 不是由 acceleration 引起的;
- 重复前缀已经做了缓存;
- 非实时任务已经改走 batch;
- 输出也已经裁剪;
- 流量基线仍然长期贴近上限;
那这时升 tier 就很合理。 因为你已经把工程层面最划算的优化都做完了。
如果你的场景还涉及大上下文、企业合规或更高预算池,联系销售通常比死扛 Tier 4 的公开层级更实际。 Anthropic 的 pricing 页面也明确把企业定价与 sales 联系放在正式路径里(Anthropic Pricing,2026-03-18)。
把五种手段放到同一张取舍表里
如果你要在团队里推动方案落地,光说“都可以试试”通常没有用。 真正能推动决策的,是把成本、延迟和工程复杂度摆到一张表里。
| 手段 | 对哪类问题最有效 | 成本影响 | 延迟影响 | 工程复杂度 | 最常见误用 |
|---|---|---|---|---|---|
| 队列整形 | Acceleration、RPM 尖峰 | 几乎不增加模型成本 | 轻微增加排队延迟 | 低到中 | 明明是突发问题,却先去升级 tier |
| Prompt caching | 重复长前缀、ITPM 压力 | 高复用时显著降成本 | 基本不影响体验 | 中 | 复用很低也强行上缓存 |
| Message Batches | 非实时的大批量任务 | 价格直接降到标准 API 的 50%(Anthropic Pricing,2026-03-18) | 明显增加等待时间 | 中 | 把实时接口误改成 batch |
| 输出裁剪与拆分 | OTPM、超长回答 | 通常会降低成本 | 可能需要多轮交互 | 中 | 只看输入,不看输出 |
| 升 tier / 联系销售 | 长期持续高位负载 | 直接提高预算投入 | 几乎不改接口时延 | 低 | 还没做基础优化就先买容量 |
这张表有一个很现实的含义。 最便宜的手段,不一定是最省时间的;最省时间的手段,也不一定最适合当前问题。
例如,队列整形通常是最快能上线的动作。 它对 acceleration 和 RPM 尖峰特别有效,但几乎不改变 ITPM。
Prompt caching 则正好相反。 它对重复长前缀很有用,但如果你的每次请求内容都完全不同,缓存收益就不会高。
Batch 更极端。 它对预算和吞吐都很友好,但前提是你业务能接受异步。
所以这张取舍表真正想表达的不是“哪一个方法最强”。 而是“你要先承认自己到底在优化什么”。
如果你要的是更低延迟,队列和输出裁剪经常优先。 如果你要的是更低账单,缓存和 batch 更值得先看。
如果你要的是最少工程改动,而且流量也确实已经长期顶格,那升 tier 当然是合理动作。 只是别把它当成所有问题的默认答案。
什么时候该重构请求,什么时候该直接升 Tier
这一节再把判断讲得更直白一点。 不是所有限流问题都值得“先优化代码”,也不是所有问题都应该“直接买更高 tier”。
下面这棵简化判断树,适合你在排障会议里直接拿出来用。
- 如果错误主要发生在新流量启动后的前几分钟,先按 acceleration 处理。 先做队列、抖动、warm-up,不要第一反应就加预算。
- 如果错误主要发生在长提示词、重复系统提示或大段静态前缀上,先做 prompt caching。 这是最可能同时降低成本和限流压力的一步。
- 如果任务不是实时接口,优先改成 Message Batches。 这一步通常同时解决价格和吞吐问题。
- 如果单次请求超过 200K tokens,先讨论上下文切分、检索策略和 long context 需求。 大上下文不是普通的“多打一会儿”。
- 如果所有动作都做了,工作日常态仍然在高位运行,再把升级 tier 放到采购动作里。 这是最稳的顺序。
很多团队会犯的错误是把第 5 步提到第 1 步。 结果就是账单上去了,429 还是没完全消失。
原因并不复杂。 如果你的真实问题是突发尖峰或请求结构不合理,扩大配额只会延后撞墙时间,不会改变撞墙方式。
相反,如果你已经做过结构优化,业务也明确是持续高位负载,那就不要过度迷信“继续省代码成本”。 这时升级 tier 反而是工程上更便宜的选择。
一个更稳的执行方案:监控什么,怎么落地
如果你不想每次都靠日志里一句 429 来猜问题,最好从一开始就把监控拆成下面几类。
第一类是请求速率。
你至少要知道每分钟请求数、失败数、重试数和平均 retry-after。
第二类是 token 结构。 输入和输出要分开记。 否则 OTPM 撞墙时,你很容易误以为是提示词太长。
第三类是工作流指标。 例如队列长度、批处理积压量、缓存命中率、平均上下文长度和超长请求占比。
第四类才是成本指标。 月度 spend、组织 tier、workspace 限额和模型分布,都应该放在同一张看板里看。
这样做的直接好处是,你不会再把所有问题都归因给“官方给的额度太小”。 有些问题本来就不是额度问题,而是流量塑形、上下文结构和工作流设计的问题。
如果你想把这件事做得再稳一点,可以把下面这份执行清单直接落到工程里:
- 所有调用统一走一个带并发闸门的客户端层。
- 遇到
429时优先读取retry-after,没有再退回指数退避。 - 固定前缀超过某个 token 阈值就强制评估 prompt caching。
- 非实时任务默认评估是否可改 Batch。
- 大于
200K tokens的请求自动进“长上下文评审”分支。 - 监控面板同时显示 RPM、ITPM、OTPM 和 spend。
这里再补一个经常被忽略但很有价值的小点。 Anthropic 的 token counting 端点是免费的,但仍受你当前 usage tier 的 RPM 限制(Anthropic Token Counting,2026-03-18)。
这意味着它很适合做上线前估算和离线分析。
但如果你想在高并发生产链路里对每个请求先调一次 count_tokens 再决定是否发送,本身也可能把请求数推高。
三个高频场景,应该分别怎么选
到这里,你大概已经知道有哪些工具可用。 但多数团队真正卡住的地方,是不知道它们在自己场景里应该怎么排序。
下面我把最常见的三类业务拆开讲。 你不需要记住所有技巧,只需要找到和自己最像的那一类。
场景一:实时客服或 Copilot 式助手
这类场景的典型特征是: 用户在等返回。 接口一慢,体验立刻变差。
因此,Message Batches 基本不在第一选择里。 你更应该优先做的是并发闸门、重试抖动、输出裁剪,以及对稳定系统提示做缓存。
如果你的系统提示很长,而且每个会话都会重复发送相同前缀,prompt caching 往往是这里最划算的一步。 它不会像 batch 一样引入额外等待,却有机会同时降低 ITPM 和输入成本(Anthropic Pricing;Anthropic Prompt Caching,2026-03-18)。
这类业务里,很多团队会误把 OTPM 当成 ITPM。 因为他们习惯盯着检索拼接长度,却忽略自己要求模型一次回太多内容。
如果你的助手总在一轮里生成冗长解释、完整步骤、完整代码和完整 JSON,先把输出目标改短,通常比先换更贵模型来得有效。 这也是为什么实时产品里,“分两轮返回”常常比“一次返回所有内容”更稳。
对这类场景,我通常建议按这个顺序落地:
- 统一并发闸门。
- 遵守
retry-after的重试。 - 固定前缀评估缓存。
- 输出裁剪与分段生成。
- 最后才看 tier。
场景二:夜间批量生成、分类或分析
这类场景和实时产品正好相反。 用户不在前面等。 真正重要的是总吞吐和总成本。
因此,这类工作流最容易被同步 API 误伤。 很多团队图省事,直接开大量并发 worker 去打在线接口,结果同时吃到 429 和高账单。
如果任务本身允许异步完成,Message Batches 通常应该提前到第一优先级。 因为官方定价已经非常明确,Batch 的输入和输出价格都是标准 API 的 50%(Anthropic Pricing,2026-03-18)。
换句话说,你不只是更稳了。 你还在一开始就把单位成本砍掉了一半。
这类场景再叠加 prompt caching,效果往往更明显。 特别是当你对每条记录都复用同一个分类规则、抽取模板或结构化指令时,缓存和 batch 的组合会比单纯加同步并发更合理。
真正不适合这么做的,只有一种情况。 那就是你的任务虽然看起来是批量,但其实每一步都需要用户即时看到结果。
如果不是这种情况,就不要执着于“所有任务都走同一条实时链路”。 这类统一,通常只是架构偷懒,不是最优设计。
场景三:长文档审阅、RAG 或大代码库分析
这是最容易被“我已经升级 tier 了,为什么还不稳”困住的一类。 原因是这里的瓶颈经常不是单纯的 RPM,而是上下文本身。
Anthropic 文档已经明确区分了超长上下文请求。 超过 200K tokens 的请求会按 prompt tokens 走独立限制,而 1M token context window 需要 Tier 4(Anthropic Rate Limits,2026-03-18)。
所以,如果你的工作流经常把整份 PDF、整套知识库或大段代码库直接塞进去,问题就不再只是“能不能多给一点并发”。 你更应该先问:这些内容是不是都必须在同一轮请求里出现。
对这类场景,最有效的动作通常不是单点提额,而是三步:
- 先做检索分层,只让高相关片段进入主请求。
- 对稳定背景资料做缓存,而不是每轮全量重发。
- 只有在这些都做完后,才评估 long context 和更高 tier。
这样做的好处是,你不会把所有问题都压到模型上下文上。 上下文应该是推理空间,不应该是原始仓库或原始文档的堆放区。
一句话总结这三类场景
实时产品优先控制延迟。 离线批量任务优先控制总成本。 长上下文任务优先控制请求结构。
如果你把这三类问题混成一个“想办法提高 Claude API 限额”,后面的很多动作都会开始失焦。 但如果先把场景分开,应该先做缓存、batch、拆分还是升 tier,通常会清楚很多。
常见问题 FAQ
为什么我明明感觉“每分钟没超很多”,Claude API 还是报 429?
最常见的原因不是你对平均量判断错了,而是你忽略了突发流量。
Anthropic 当前文档明确说明它采用 token bucket 算法,而且 acceleration limits 也会返回 429(Anthropic Rate Limits;Anthropic Errors,2026-03-18)。
翻成工程语言就是:一分钟内总量看起来还行,不代表某几秒的尖峰也安全。 尤其是批量 worker 同时启动、重试同时恢复、定时任务整点触发时,这种问题最常见。
所以遇到这种现象,先排查并发和放量曲线。 如果你第一时间只盯着 tier,很可能会花错钱。
不同模型的限制是独立的吗,换模型能不能直接绕过去?
Anthropic 文档写明,不同模型有各自的限制,因此并行使用不同模型确实可以分散部分压力(Anthropic Rate Limits,2026-03-18)。 但这不等于“换模型就能无限扩容”。
原因有两个。 第一,你的组织 tier 仍然会限制整体能力边界。 第二,很多真实瓶颈来自请求结构本身,比如长前缀重复发送、输出过长或突发尖峰,这些问题换模型并不会自动消失。
更现实的做法是:先把模型切换当成负载分流的一部分,而不是唯一答案。 如果根因是队列和上下文设计,真正有效的动作依旧是排队整形和请求重构。
Prompt caching 会不会反而更贵?
单看第一次写入,确实会更贵一些。
官方定价里,5 分钟 cache write 是基础输入价格的 1.25x,1 小时 cache write 是 2x(Anthropic Pricing,2026-03-18)。
但 prompt caching 的价值本来就不在第一次。
它真正改变决策的地方,是稳定前缀被多次复用时,cache hit 只按基础输入价格的 0.1x 计费(Anthropic Pricing,2026-03-18)。
所以判断缓存值不值得,不能问“第一次是不是更贵”,而要问“这个前缀接下来会重复几次”。 如果复用很高,缓存通常同时改善成本和 ITPM 压力;如果复用很低,直接发送反而更简单。
Message Batches 适合拿来替代实时接口吗?
通常不适合。 Batch 的核心价值是把非实时工作从同步链路里拆出去,并且用更低的价格处理大量任务。
Anthropic 当前定价页明确写明,Message Batches 输入和输出价格都是标准 API 的 50%(Anthropic Pricing,2026-03-18)。 这让它非常适合夜间生成、批量分类、离线分析和大规模内容处理。
但如果你的产品要求“用户点击后立即返回”,Batch 的延迟模型本身就和需求冲突。 这种场景下更有效的顺序仍然是:先做并发闸门、输出裁剪、缓存,再看是否需要更高 tier。
长上下文和普通限流是什么关系?是不是只要有 1M context 就够了?
不是。 Anthropic 文档明确说明,1M token context window 需要 Tier 4;而对超过 200K tokens 的请求,速率限制按 prompt tokens 生效(Anthropic Rate Limits,2026-03-18)。
这说明“能不能塞进去”和“塞进去之后能不能稳定跑”是两件不同的事。 很多团队以为拿到更长上下文就等于问题解决了,实际上如果你的检索和切分策略没有改善,只会把 ITPM 压力换一种方式放大。
所以,大上下文是一个架构问题,不只是采购问题。 在真正决定冲 1M context 之前,最好先评估是不是能用更好的检索分层、摘要链路或段落级缓存把问题拆小。
什么情况下我应该直接联系销售,而不是继续在代码里抠吞吐?
当你已经把最便宜的优化都做完了,却仍然长期贴近上限时,就该认真考虑采购路径了。
这里说的“最便宜优化”至少包括:并发闸门、retry-after 退避、重复前缀缓存、非实时任务批处理、长输出裁剪。
如果这些都做了,业务又明确要持续高位运行,继续在代码里抠 5% 到 10% 的吞吐空间,往往不如直接升级 tier 或走企业销售路径更划算。 Anthropic 的 pricing 页面本身也把 enterprise custom pricing 作为正式选项提供出来(Anthropic Pricing,2026-03-18)。
真正成熟的做法不是“能不能永远不花钱提额”。 而是先用工程手段把明显浪费清掉,再把剩下的真实容量需求交给采购和平台决策。
结论:先分清你缺的是额度,还是方法
Claude API 速率限制真正难的地方,从来不是背住几个缩写。 难的是你要在很短时间内判断,眼前的问题到底来自请求数、输入 tokens、输出 tokens、流量爬升速度,还是长上下文。
如果你只记一个结论,就记这个: 突发流量先改队列,重复长前缀先上缓存,非实时任务先上 Batch,超长上下文先改结构,只有在这些动作做完后仍长期顶格运行,才应该把升 tier 放到第一优先级。
这样处理,通常比“先买更高额度,再看看还会不会报错”更稳,也更省钱。 这也是本文相对旧版文章最重要的升级。
如果你还要继续补齐 Claude 生态里的其它基础信息,可以顺着这三篇继续看: