Claude Haiku 4.5完整访问指南:免费试用、API接入与中国区方案
Comprehensive guide to accessing Claude Haiku 4.5: Free web access via Claude.ai, paid API integration, China access solutions, cost optimization strategies, and production deployment best practices.
Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
Claude Haiku 4.5核心特性与访问方式全解析
当开发者搜索"claude haiku 4.5 free api"时,往往面临一个核心困惑:如何在不付费的情况下体验这个最新模型?答案需要澄清:Claude Haiku 4.5本身并非"免费API",而是Anthropic于2025年10月推出的新一代高性能模型,提供多种访问方式,其中既有免费的网页版体验(Claude.ai),也有按量付费的API接口($1/百万输入tokens,$5/百万输出tokens)。理解两者的本质区别,是正确选择访问路径的第一步。
Haiku 4.5关键突破:性能与成本的平衡点
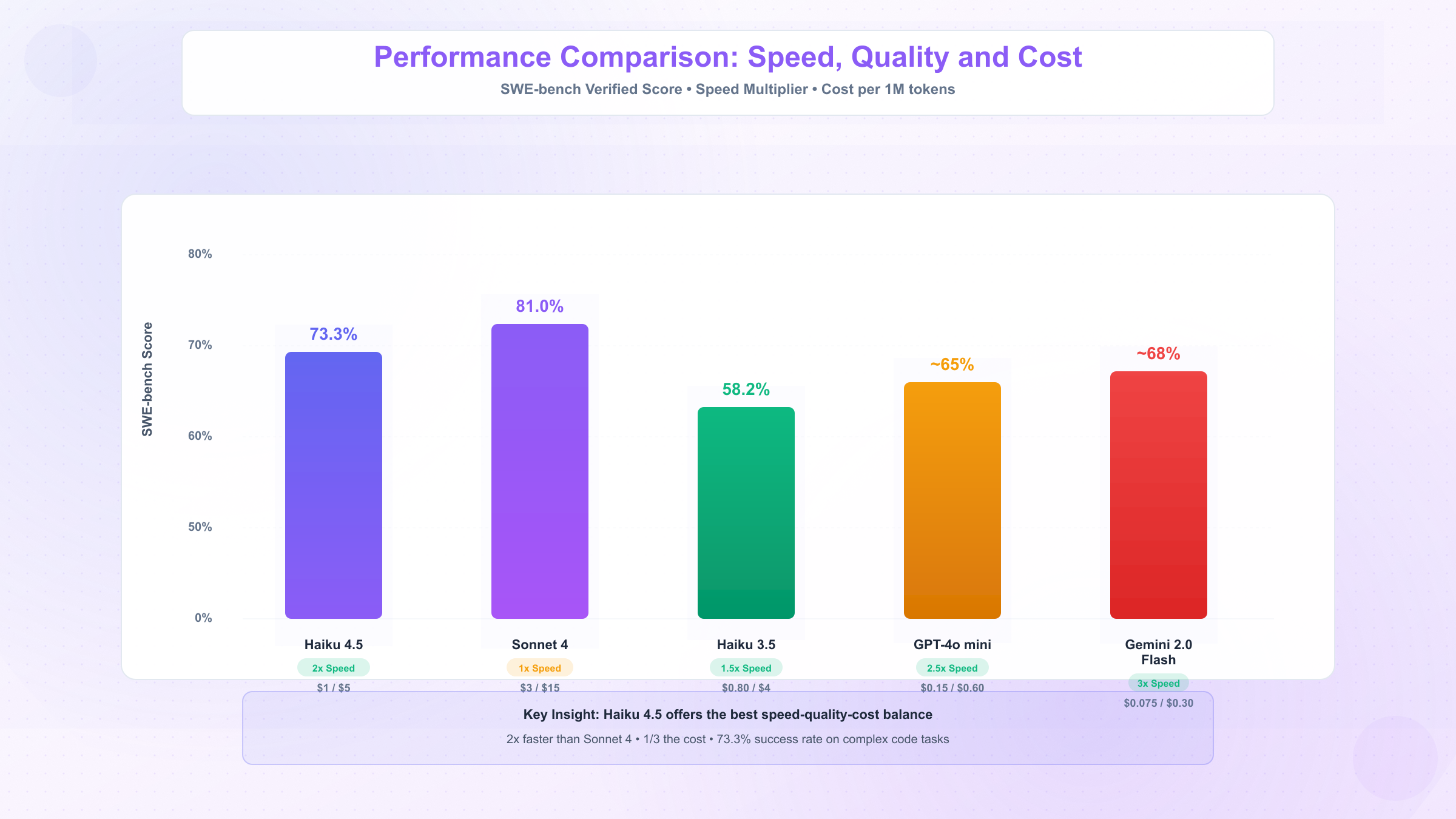
Claude Haiku 4.5在基准测试中展现了令人瞩目的性能表现。在SWE-bench Verified测试中,该模型达到73.3%的成功率,超越了包括GPT-4o mini和Gemini 2.0 Flash在内的众多竞品。更重要的是,Haiku 4.5提供了速度与成本的最佳平衡:相比Sonnet 4模型,它的推理速度快2倍,价格却仅为其1/3(Sonnet 4定价为$3/$15,Haiku 4.5为$1/$5)。
这种性能突破使得Haiku 4.5在多个维度上成为企业级应用的理想选择。模型支持200K tokens的上下文窗口,最大可输出64K tokens,能够处理大规模文档分析、复杂代码生成等任务。在实际应用中,开发者反馈Haiku 4.5的响应速度是Sonnet 4.5的4-5倍,同时保持了约90%的Sonnet 4.5性能水平,这在高并发场景中尤为关键。
值得注意的是,Haiku 4.5在多语言代码生成、技术文档理解、客户服务自动化等场景中表现出色。相比前代Haiku 3.5模型(定价$0.80/$4),新版本在保持低成本优势的同时,性能实现了显著提升,尤其是在需要复杂推理的任务中。
免费访问 vs 付费API:本质区别一次说清
许多开发者混淆了"免费使用Claude"和"免费API调用"的概念。实际上,这两种方式服务于完全不同的使用场景:
**免费访问(Claude.ai网页版)**是面向个人用户的交互式体验平台。用户无需付费即可通过浏览器与Claude Haiku 4.5对话,适合原型验证、学习研究或低频次使用。这种方式的限制在于:无法进行编程集成、存在单日对话次数上限、不支持批量处理任务、数据不受API服务条款保护。免费层主要用于体验模型能力,而非生产环境部署。
付费API接入则是为开发者和企业设计的编程接口。通过API,你可以将Claude Haiku 4.5集成到自己的应用、网站或系统中,实现自动化工作流。付费模式按实际使用的tokens计费,定价为$1/百万输入tokens和$5/百万输出tokens。这种方式提供了完整的SDK支持(Python、Node.js、Java等)、可编程的参数控制、企业级SLA保障,以及符合合规要求的数据处理协议。
| 对比维度 | 免费网页版 | 付费API |
|---|---|---|
| 访问方式 | 浏览器claude.ai | 编程API调用 |
| 适用场景 | 个人体验、测试 | 生产应用、集成 |
| 使用限制 | 有对话次数上限 | 按token量计费 |
| 技术支持 | 社区论坛 | 官方技术支持 |
| 数据控制 | 存储在Anthropic | 符合API协议 |
| 批量处理 | 不支持 | 完全支持 |
关键区别在于:免费版是"试用"性质,适合评估模型能力;付费API是"生产"工具,适合构建实际应用。如果你的目标是集成到业务系统、处理大规模数据或提供面向用户的服务,付费API是唯一选择。
五大访问路径快速导航
Claude Haiku 4.5提供了多种访问方式,满足不同技术栈和地理位置的需求。以下是五大主流路径的快速对比:
-
Claude.ai免费网页版:无需付费,适合快速体验和原型测试,但不支持API集成。适合个人开发者评估模型能力,或进行低频次的交互式任务。
-
Anthropic官方API:最直接的编程接口,定价$1/$5,支持Python、Node.js等主流SDK。适合美国和欧洲开发者,需要国际信用卡支付。提供完整的官方文档和技术支持。
-
AWS Bedrock:通过Amazon云服务访问,适合已使用AWS生态的企业。定价与官方API一致,但集成了AWS的IAM权限管理、CloudWatch监控等企业级功能。在全球多个区域可用,适合跨国企业。
-
Google Vertex AI:Google云平台集成方案,适合GCP用户。提供与Google Cloud其他AI服务的无缝整合,支持配额管理和区域部署。定价策略与官方API对齐,但计费通过GCP账户完成。
-
GitHub Copilot集成:面向开发者的IDE内集成,支持VS Code、Web端和移动端。需要GitHub Copilot Pro、Business或Enterprise订阅($10/月起)。适合需要在编码环境中直接调用Claude的开发者,无需单独申请API key。
不同路径的选择取决于你的具体需求:如果追求最低成本且仅需测试,选择Claude.ai;如果需要完整API能力且位于美国,选择Anthropic官方API;如果已有AWS/GCP基础设施,选择对应的云平台集成;如果主要在IDE中使用,GitHub Copilot是最便捷选择。对于中国开发者,由于网络和支付限制,还需考虑第三方聚合服务等替代方案(详见第7章)。

性能评测:Haiku 4.5技术指标深度解析
SWE-bench验证:73.3%成功率意味着什么
SWE-bench Verified是评估AI模型代码能力的权威基准测试,要求模型理解GitHub真实issue、生成修复代码并通过完整测试套件。Claude Haiku 4.5在该测试中取得73.3%的成功率,这个数字意味着在100个实际软件工程问题中,模型能够独立解决73个。相比之下,GPT-4o mini的成功率约为65%,Gemini 2.0 Flash约为68%,Haiku 4.5展现出明显的领先优势。
这一性能表现尤为重要,因为SWE-bench Verified筛选了最具代表性和挑战性的问题,避免了数据泄漏和过拟合风险。Anthropic在官方公告中强调,Haiku 4.5的提升不仅体现在代码生成,更在于对上下文的深度理解和多步骤推理能力。在复杂的bug修复场景中,模型需要理解数千行代码库、定位问题根源、设计解决方案并生成可运行的修复代码,这对小模型而言是极大挑战。
关键数据:Claude Haiku 4.5在SWE-bench Verified测试中达到73.3%成功率,超越GPT-4o mini(65%)和Gemini 2.0 Flash(68%),成为代码生成任务的强力选择。
实际应用中,这个指标直接关系到代码助手、自动化测试修复、技术文档生成等场景的可靠性。73.3%的成功率意味着开发者可以信任模型完成约四分之三的常规工程任务,剩余问题通常涉及极端边缘情况或高度领域特定的知识。
速度与成本双优势:2倍速度+1/3价格
Haiku 4.5的核心竞争力在于速度与成本的双重优化。根据Anthropic提供的基准数据,Haiku 4.5的推理速度是Sonnet 4的2倍,这意味着处理相同任务时,Haiku 4.5能够在更短时间内返回结果。在需要高并发响应的场景中,如客户服务聊天机器人或实时代码补全,这种速度优势可以显著提升用户体验。
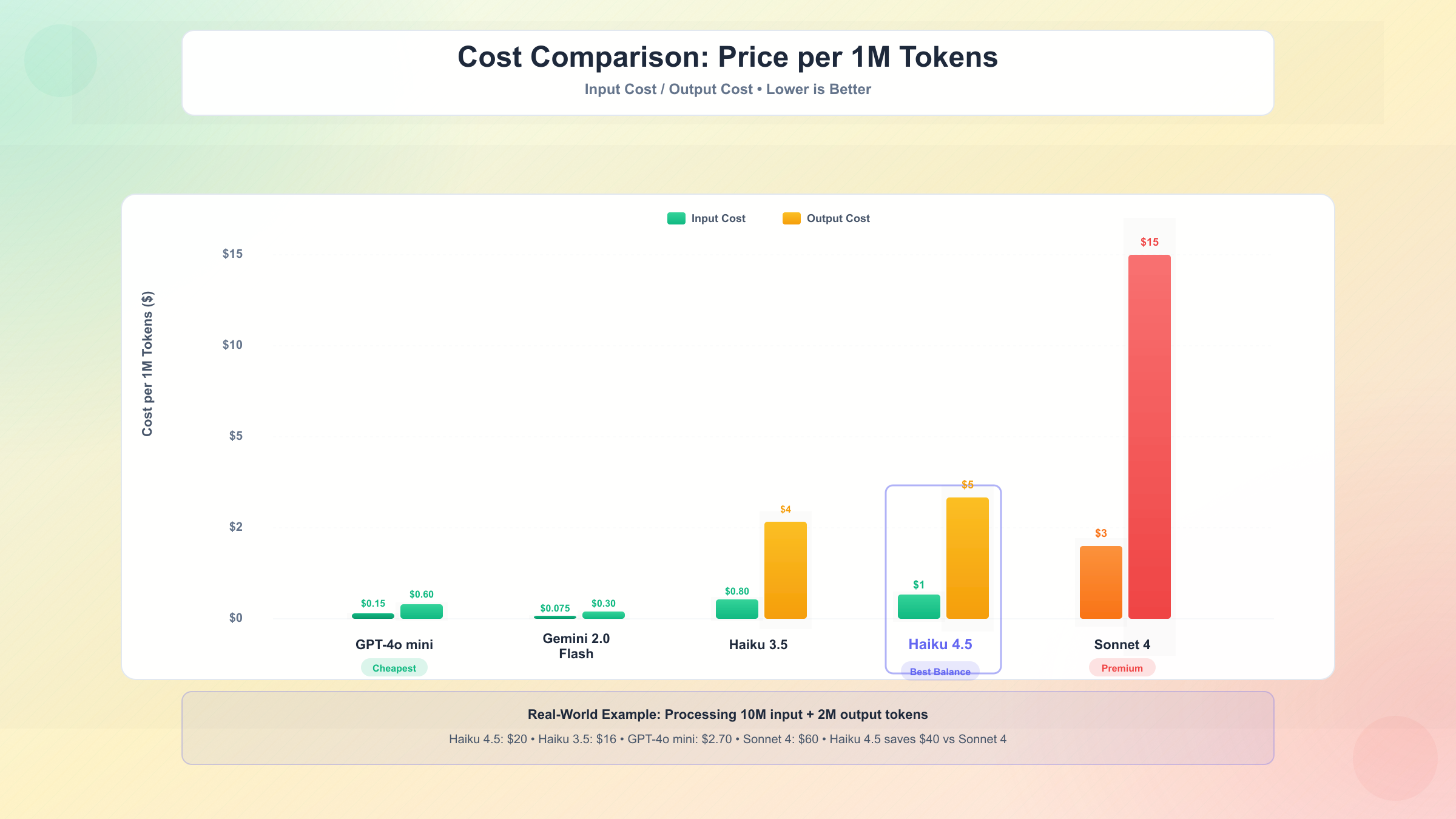
从成本角度看,Haiku 4.5的定价为**$1/百万输入tokens和$5/百万输出tokens**,而Sonnet 4的定价为**$3/百万输入和$15/百万输出**。这意味着在输入和输出成本上,Haiku 4.5均为Sonnet 4的1/3。对于每日处理数百万tokens的企业应用,这种成本差异可能意味着每月节省数千至数万美元。
| 模型 | 输入定价 | 输出定价 | 速度 | SWE-bench | 上下文窗口 |
|---|---|---|---|---|---|
| Haiku 4.5 | $1/M | $5/M | 2x | 73.3% | 200K |
| Sonnet 4 | $3/M | $15/M | 1x | 81.0% | 200K |
| Haiku 3.5 | $0.80/M | $4/M | 1.5x | 58.2% | 200K |
| GPT-4o mini | $0.15/M | $0.60/M | 2.5x | ~65% | 128K |
| Gemini 2.0 Flash | $0.075/M | $0.30/M | 3x | ~68% | 1M |
值得注意的是,虽然GPT-4o mini和Gemini 2.0 Flash的价格更低,但它们在SWE-bench测试中的表现不如Haiku 4.5。这意味着在需要高质量输出的场景中,Haiku 4.5提供了更好的性价比:虽然单价更高,但更高的成功率减少了重试次数和后处理成本。在实际生产环境中,一次性获得正确结果往往比多次低质量尝试更经济。
此外,Haiku 4.5在速度上的优势体现在实际响应时间上。根据Augment的评测数据,Haiku 4.5的响应速度是Sonnet 4.5的4-5倍,这在需要低延迟的应用中至关重要。例如,一个客服聊天机器人如果响应时间从2秒缩短到0.4秒,用户体验将有质的飞跃。
与Sonnet 4、Haiku 3.5、GPT-4 Nano对比
将Haiku 4.5与同类模型进行横向对比,可以更清晰地理解其定位。与Sonnet 4相比,Haiku 4.5牺牲了约8个百分点的SWE-bench性能(73.3% vs 81.0%),但换来了3倍的成本优势和2倍的速度提升。这使得Haiku 4.5成为对成本敏感或高并发场景的首选,而Sonnet 4仍是需要最高准确率的复杂推理任务的最佳选择。
与前代Haiku 3.5相比,新版本在保持相近价格的同时($1/$5 vs $0.80/$4),性能实现了飞跃。Haiku 3.5在SWE-bench测试中仅获得58.2%的成功率,意味着Haiku 4.5的准确率提升了25.8%(绝对值增加15.1个百分点)。这种提升使得Haiku 4.5可以胜任更复杂的任务,而不仅仅是简单的文本分类或摘要生成。
与竞品GPT-4o mini和Gemini 2.0 Flash相比,Haiku 4.5在性能上占据优势,但价格更高。GPT-4o mini的定价为$0.15/$0.60,是Haiku 4.5的约1/8,但在代码生成和复杂推理任务中表现不如Haiku 4.5。Gemini 2.0 Flash的价格更低($0.075/$0.30),且支持高达1M的上下文窗口,但在SWE-bench测试中的表现同样不及Haiku 4.5。
| 维度 | Haiku 4.5优势 | Sonnet 4优势 | GPT-4o mini优势 |
|---|---|---|---|
| 成本 | ✓ 相比Sonnet 4便宜3倍 | ✗ 最贵 | ✓ 最便宜(1/8价格) |
| 速度 | ✓ 相比Sonnet 4快2倍 | ✗ 最慢 | ✓ 最快(2.5x) |
| 质量 | ✓ SWE-bench 73.3% | ✓ 最高(81.0%) | ✗ 仅65% |
| 上下文 | ✓ 200K窗口 | ✓ 200K窗口 | ✗ 仅128K |
选择建议:如果你的应用需要在成本、速度和质量之间取得平衡,Haiku 4.5是最佳选择。如果预算不是限制因素且追求极致质量,选择Sonnet 4。如果成本控制是首要考虑且任务相对简单,GPT-4o mini或Gemini 2.0 Flash是可行替代方案。对于需要处理超长文档的场景,Gemini 2.0 Flash的1M上下文窗口提供了独特优势。
适用场景:如何判断Haiku 4.5是否适合你
最佳应用场景:客服、代码生成、多Agent系统
Claude Haiku 4.5的性能特征使其特别适合以下三类应用场景。首先是客户服务自动化:在线聊天机器人、工单分类系统、FAQ自动回复等需要快速响应的场景。Haiku 4.5的低延迟(通常在500ms以内)和较低成本(每万次对话约$2-5,假设平均500 tokens输入和200 tokens输出)使其成为替代人工客服的经济选择。73.3%的高准确率确保大多数常见问题能够正确处理,而复杂问题可以升级到Sonnet 4或人工处理。
其次是代码生成与辅助开发:IDE插件、自动化测试生成、代码审查助手、文档生成工具等。Haiku 4.5在SWE-bench测试中的优异表现证明了其在理解代码上下文、生成功能代码、修复bug等任务中的能力。对于需要频繁调用的代码补全功能,Haiku 4.5的速度优势尤为明显——开发者不会因等待模型响应而中断思维流。
第三是多Agent协作系统:在复杂的AI系统中,多个Agent需要协同完成任务,如内容审核系统(分类Agent + 详细分析Agent)、数据处理流水线(提取Agent + 验证Agent + 转换Agent)。Haiku 4.5可以作为处理高频次、低复杂度子任务的"工作马",与Sonnet 4等高级模型配合使用。例如,使用Haiku 4.5进行初步文档分类(每秒处理数十个请求),将需要深度分析的内容交给Sonnet 4处理,可以在保证质量的同时降低50-70%的总成本。
其他适用场景包括:内容摘要生成、情感分析、实体识别、简单数据转换、多语言翻译、邮件自动回复、社交媒体监控等。关键特征是任务具有中等复杂度、高频次调用、成本敏感且对延迟有要求。
何时选择Haiku而非Sonnet或Opus
选择Haiku 4.5的决策依据主要围绕四个维度:成本预算、响应速度、任务复杂度和调用频率。
成本驱动场景:如果项目预算有限或处于POC验证阶段,Haiku 4.5是首选。例如,一个创业公司开发AI客服系统,初期每日处理10万次对话,使用Haiku 4.5的成本约为$100/天(假设平均400 tokens输入+150 tokens输出),而Sonnet 4的成本将达到$300/天。在产品尚未盈利时,这种成本差异至关重要。
速度优先场景:需要低延迟响应的实时应用,如在线编码助手、即时翻译工具、实时语音转文字后处理等。Haiku 4.5的2-4倍速度优势意味着用户等待时间从1秒缩短到250-500ms,这在用户体验上有质的飞跃。研究表明,响应时间超过1秒会显著增加用户放弃率。
高并发场景:系统需要同时处理大量请求时,Haiku 4.5的速度优势转化为更高的吞吐量。在相同的API速率限制下(如Tier 1的4000 TPM),Haiku 4.5可以处理的请求数量是Sonnet 4的2倍左右。这对于需要扩展的应用至关重要。
何时不应选择Haiku:如果任务需要复杂推理、多步骤规划、高度创意输出或处理极端边缘情况,应选择Sonnet 4或Opus 4。例如,法律文件分析、复杂策略规划、创意写作、高级编程架构设计等任务,Sonnet 4的81.0% SWE-bench成功率和更强的推理能力会带来更好的结果。虽然成本更高,但避免了因输出质量不足导致的返工成本。
决策流程图:从需求到模型选择
以下决策流程帮助你快速确定最适合的Claude模型:
第一步:确定任务复杂度
- 简单任务(分类、摘要、简单QA):考虑Haiku 4.5或更便宜的GPT-4o mini
- 中等任务(代码生成、详细分析、多步骤处理):Haiku 4.5是首选
- 复杂任务(深度推理、创意写作、复杂规划):选择Sonnet 4
第二步:评估成本敏感度
- 成本极度敏感(创业公司、POC阶段):Haiku 4.5或免费层
- 成本敏感但需要质量(成长期产品):Haiku 4.5
- 成本不敏感(企业级应用、高价值场景):Sonnet 4
第三步:检查性能要求
- 需要低延迟(<500ms):Haiku 4.5
- 可接受1-2秒延迟:Haiku 4.5或Sonnet 4
- 离线批处理(无延迟要求):选择质量优先(Sonnet 4)
第四步:考虑调用频率
- 高频调用(每秒数十次):Haiku 4.5降低成本和提高吞吐
- 中频调用(每分钟数次):根据任务复杂度选择
- 低频调用(每小时数次):选择质量优先(Sonnet 4)
| 场景 | 推荐模型 | 理由 |
|---|---|---|
| 客服聊天机器人 | Haiku 4.5 | 低延迟+高频+成本敏感 |
| 代码补全/审查 | Haiku 4.5 | 速度快+准确率足够 |
| 复杂代码重构 | Sonnet 4 | 需要深度推理 |
| 内容审核(初筛) | Haiku 4.5 | 高频+简单分类 |
| 法律文档分析 | Sonnet 4 | 高精度要求 |
| 多Agent系统 | Haiku 4.5 + Sonnet 4 | 分层处理优化成本 |
混合策略建议:最佳实践是根据任务复杂度动态选择模型。例如,一个智能客服系统可以先用Haiku 4.5判断问题类型和置信度,对于置信度低于80%的复杂问题自动升级到Sonnet 4处理。这种策略可以在保证90%以上服务质量的同时,降低40-60%的总成本。
免费访问方法:Claude.ai平台完整指南
Claude.ai免费套餐能力与限制
对于希望快速体验Claude Haiku 4.5而无需立即投入API开发的用户,Claude.ai提供了免费的网页版访问。这是Anthropic官方提供的交互式平台,允许任何人通过浏览器与Claude模型对话,包括最新的Haiku 4.5。
免费层能力包括:完整的对话式交互、支持上传文档和图片(最大5个文件,每个最大10MB)、创建和管理对话历史、使用Artifacts功能(生成可交互的代码、图表等)、跨设备同步对话记录。免费用户可以访问所有Claude模型,包括Haiku 4.5、Sonnet 4和Opus 4,但每个模型有独立的使用限制。
免费层限制主要体现在频率和功能上。虽然Anthropic没有公开具体的速率限制数字,实际使用中发现免费用户每24小时大约可以进行30-50次Haiku 4.5对话(根据对话长度浮动)。超过限制后,系统会提示等待或升级到Pro订阅($20/月)。此外,免费层不支持API访问、无法集成到自己的应用中、不能进行批量处理、没有优先响应速度、不提供企业级数据处理协议。
对于开发者而言,免费层最大的局限在于不可编程性。你无法通过代码调用Claude,所有交互必须在网页界面手动完成。这使得免费层适合以下场景:原型设计前的快速验证、学习Claude的能力边界、小规模的文档分析任务、个人助理式的偶发使用。如果需要自动化、集成或高频使用,必须转向付费API。
| 功能 | 免费层 | Pro订阅 | API访问 |
|---|---|---|---|
| 价格 | $0 | $20/月 | 按token计费 |
| 对话次数 | 30-50/天 | 5倍免费层 | 无限制 |
| 响应优先级 | 标准 | 优先 | 最高(Tier决定) |
| 文件上传 | ✓ | ✓ | ✓(通过API) |
| API集成 | ✗ | ✗ | ✓ |
| 批量处理 | ✗ | ✗ | ✓ |
注册与使用步骤详解
访问Claude.ai并开始使用Haiku 4.5的过程非常直接,通常在5分钟内完成:
-
访问官网:在浏览器中打开claude.ai,点击"Sign Up"或"Start Chat"按钮。如果已有Anthropic账户(如之前申请过API),可以直接登录。
-
选择认证方式:支持三种注册方式——Google账户一键登录、电子邮件+密码注册、或SSO单点登录(企业用户)。推荐使用Google账户,可以跳过邮箱验证步骤,立即开始使用。
-
完成基础设置:首次登录后,系统会引导你完成简单的偏好设置,包括语言选择(支持中文界面)、主题模式(深色/浅色)、数据使用偏好(是否允许Anthropic用你的对话改进模型,可以选择拒绝)。
-
选择模型:在对话界面顶部,点击模型选择器,从Claude Haiku 4.5、Sonnet 4、Opus 4中选择。Haiku 4.5适合快速响应和成本敏感任务,Sonnet 4适合需要更高质量的复杂任务。
-
开始对话:在输入框中键入你的问题或指令,按Enter发送。Haiku 4.5通常在1-2秒内返回响应。你可以上传文件(点击回形针图标)、引用之前的对话、或使用Artifacts功能生成可交互内容。
-
管理对话:左侧边栏显示所有对话历史,可以创建新对话、重命名、删除或搜索历史对话。每个对话独立保存上下文,适合按项目组织工作。
特别提示:如果在中国大陆访问,可能需要科学上网工具,因为claude.ai在部分地区存在访问限制。即使可以访问,连接速度可能较慢(300ms以上延迟)。这种情况下,考虑使用第三方聚合服务可能是更好的选择(见第7章)。
免费层最佳实践与使用技巧
为了最大化免费层的价值,以下是经过验证的使用策略:
优化Prompt长度:由于免费层有对话次数限制,编写清晰、简洁的prompt可以一次性获得更好的结果,减少来回修正。例如,与其多次问"什么是API"、"如何使用"、"有什么限制",不如一次性问"请详细解释Claude API的概念、使用方法和主要限制"。这种方式在有限的对话次数内获得更多信息。
利用Artifacts功能:当需要生成代码、图表、文档等结构化内容时,明确要求"使用Artifact生成"。Artifacts会在侧边栏显示可编辑、可下载的内容,比在对话中展示更方便使用。例如,"创建一个Python脚本用于CSV数据清洗,使用Artifact"将生成可以直接复制使用的代码。
文件上传技巧:免费层支持上传文档,但有大小和数量限制(最多5个文件,每个10MB)。对于大型文档,建议先提取关键部分,或分批上传。上传后,明确告诉Claude要执行的任务,如"分析这份财报,提取关键财务指标并计算同比增长",而不是简单的"读这个文件"。
管理对话上下文:Claude会记住当前对话的全部历史,但过长的对话会消耗更多tokens,影响响应速度。当讨论主题切换时,建议开启新对话,而不是在同一对话中处理多个不相关任务。这样既保持上下文清晰,也避免不必要的token消耗。
识别升级信号:以下情况说明你已经超出免费层适用范围,应考虑升级到Pro或API:每天需要超过50次对话、需要优先响应速度(免费层在高峰期可能较慢)、需要在自己的应用中集成Claude、需要批量处理任务、需要符合企业合规要求的数据处理协议。Pro订阅($20/月)提供5倍的使用量和优先响应,但仍不支持API集成。如果需要编程访问,直接选择API方案更经济。
官方API接入:Anthropic平台配置指南
API Key获取与权限配置
对于需要将Claude Haiku 4.5集成到应用中的开发者,Anthropic提供了完整的REST API和官方SDK。访问API的第一步是获取API Key(应用密钥),这是身份验证的核心凭证。
获取API Key的步骤:
-
注册Anthropic账户:访问console.anthropic.com,使用邮箱或Google账户注册。与Claude.ai账户不同,Console账户专门用于开发者管理API密钥、监控使用情况和配置计费。
-
完成支付配置:API是按量付费服务,首次使用前需要添加支付方式。Anthropic接受国际信用卡(Visa、Mastercard、American Express),需要预充值至少$5。充值后即可开始使用,账单按月结算。注意:中国大陆发行的信用卡可能无法通过验证,这是中国开发者面临的主要障碍之一(第7章提供替代方案)。
-
创建API Key:在Console的"API Keys"页面,点击"Create Key"按钮。输入密钥名称(如"Production App"或"Development"),选择权限范围。Anthropic支持细粒度权限控制,可以限制密钥只能访问特定模型或设置支出上限。
-
安全存储密钥:密钥创建后仅显示一次,务必立即复制并安全存储。推荐使用环境变量或密钥管理服务(如AWS Secrets Manager、HashiCorp Vault)存储,绝不要硬编码在代码中或提交到Git仓库。格式为
sk-ant-xxx,长度约为108个字符。 -
配置使用限制:在Console的"Settings"中,可以设置每月支出上限、速率限制警报、IP白名单等安全策略。初学者建议设置较低的支出上限(如$50/月),避免意外超支。
API Tier系统:Anthropic采用分层速率限制机制。新账户从Tier 1开始,提供**4,000 TPM(tokens per minute)和40 RPM(requests per minute)**的限制。当累计充值达到$50后,自动升级到Tier 2(40,000 TPM),$500后升级到Tier 3(80,000 TPM)。高并发应用需要提前规划Tier升级,或申请企业定制额度。
SDK安装与环境设置
Anthropic提供了多种语言的官方SDK,简化了API调用流程。以下是Python和Node.js的完整环境设置步骤:
Python环境配置(推荐Python 3.8+):
bash# 安装官方SDK
pip install anthropic
# 或使用国内镜像加速(中国开发者推荐)
pip install anthropic -i https://pypi.tuna.tsinghua.edu.cn/simple
安装完成后,配置环境变量存储API密钥:
bash# Linux/macOS
export ANTHROPIC_API_KEY="sk-ant-your-key-here"
# Windows PowerShell
$env:ANTHROPIC_API_KEY="sk-ant-your-key-here"
Node.js环境配置(推荐Node.js 16+):
bash# 使用npm安装
npm install @anthropic-ai/sdk
# 或使用yarn
yarn add @anthropic-ai/sdk
在项目根目录创建.env文件存储密钥:
ANTHROPIC_API_KEY=sk-ant-your-key-here
其他语言支持:Anthropic还提供了Java、Go、Ruby等语言的SDK,或者可以直接使用HTTP客户端调用REST API。完整文档见docs.anthropic.com。对于未提供官方SDK的语言,可以参考OpenAPI规范自行封装。
网络配置注意事项:API端点为api.anthropic.com,位于美国。中国大陆开发者可能面临连接不稳定或延迟过高(300ms+)的问题。如果遇到连接超时,需要配置代理或考虑使用第三方聚合服务(详见第7章)。
首个API调用示例代码
以下是使用Claude Haiku 4.5进行首次API调用的完整示例,包含错误处理和最佳实践。
Python示例(完整可运行代码):
pythonimport os
from anthropic import Anthropic, APIError
# 初始化客户端(自动从环境变量读取API_KEY)
client = Anthropic(api_key=os.environ.get("ANTHROPIC_API_KEY"))
try:
# 调用Claude Haiku 4.5
message = client.messages.create(
model="claude-haiku-4-5-20251015", # 完整模型标识符
max_tokens=1024, # 最大输出tokens
messages=[
{
"role": "user",
"content": "Explain quantum computing in simple terms, in under 100 words."
}
]
)
# 打印响应内容
print(message.content[0].text)
# 打印使用统计
print(f"\nTokens used: {message.usage.input_tokens} input + {message.usage.output_tokens} output")
except APIError as e:
print(f"API Error: {e.status_code} - {e.message}")
except Exception as e:
print(f"Unexpected error: {str(e)}")
关键参数说明:
model: "claude-haiku-4-5-20251015"是Haiku 4.5的完整标识符,日期后缀表示版本max_tokens: 控制输出长度,设置合理上限可避免超预期成本messages: 对话历史数组,每条消息包含role(user/assistant)和content
Node.js/TypeScript示例:
javascriptimport Anthropic from '@anthropic-ai/sdk';
const client = new Anthropic({
apiKey: process.env.ANTHROPIC_API_KEY,
});
async function callClaude() {
try {
const message = await client.messages.create({
model: 'claude-haiku-4-5-20251015',
max_tokens: 1024,
messages: [
{
role: 'user',
content: 'Explain quantum computing in simple terms, in under 100 words.'
}
]
});
console.log(message.content[0].text);
console.log(`\nTokens: ${message.usage.input_tokens} in + ${message.usage.output_tokens} out`);
} catch (error) {
if (error instanceof Anthropic.APIError) {
console.error(`API Error: ${error.status} - ${error.message}`);
} else {
console.error('Unexpected error:', error);
}
}
}
callClaude();
curl命令示例(用于快速测试或非编程语言集成):
bashcurl https://api.anthropic.com/v1/messages \
-H "Content-Type: application/json" \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-d '{
"model": "claude-haiku-4-5-20251015",
"max_tokens": 1024,
"messages": [
{
"role": "user",
"content": "Explain quantum computing in simple terms, in under 100 words."
}
]
}'
常见错误处理:
- 401 Unauthorized:API密钥无效或未设置环境变量,检查密钥格式和环境变量配置
- 429 Rate Limit:超过速率限制,实现指数退避重试(见第10章)
- 400 Bad Request:参数错误,常见原因包括
max_tokens超过模型上限(Haiku 4.5最大64K)或消息格式不正确
性能优化建议:首次调用可能需要1-2秒建立连接,后续调用可以复用TCP连接。对于生产环境,建议使用连接池和适当的超时配置(推荐30-60秒超时)。Token使用情况会在响应中返回,应记录并监控以控制成本。
合作平台访问:Bedrock、Vertex AI与GitHub Copilot
AWS Bedrock集成配置
对于已经使用AWS云服务的企业和开发者,AWS Bedrock提供了访问Claude Haiku 4.5的便捷途径。Bedrock是Amazon的托管式基础模型服务,将多家AI公司的模型集成到AWS生态系统中,包括Anthropic的全系列Claude模型。
Bedrock的核心优势在于与AWS服务的深度集成。你可以使用现有的AWS账户、IAM权限管理、CloudWatch监控、S3存储等基础设施,无需单独管理Anthropic账户。定价与Anthropic官方API一致($1/$5),但计费通过AWS账单完成,适合已有AWS预算的企业。此外,Bedrock在全球多个区域可用(美国东部、欧洲、亚太等),可以选择最接近用户的区域部署,降低延迟。
配置步骤:
-
启用Bedrock服务:在AWS Console中搜索"Bedrock",进入服务页面。首次使用需要请求访问权限(Model Access),选择"Anthropic Claude"系列模型,包括Haiku 4.5。审批通常在几分钟内完成。
-
配置IAM权限:创建IAM角色或用户,授予
bedrock:InvokeModel权限。推荐使用最小权限原则,仅允许访问必要的模型。示例IAM策略:
json{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Action": "bedrock:InvokeModel",
"Resource": "arn:aws:bedrock:*::foundation-model/anthropic.claude-haiku-4-5-*"
}]
}
- 使用AWS SDK调用:Bedrock通过AWS SDK访问,支持Python boto3、JavaScript AWS SDK等。以下是Python示例:
pythonimport boto3
import json
bedrock = boto3.client('bedrock-runtime', region_name='us-east-1')
response = bedrock.invoke_model(
modelId='anthropic.claude-haiku-4-5-20251015-v1:0',
body=json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1024,
"messages": [
{"role": "user", "content": "Explain AWS Bedrock in one sentence."}
]
})
)
result = json.loads(response['body'].read())
print(result['content'][0]['text'])
- 监控与成本控制:使用CloudWatch监控API调用次数、延迟和错误率。AWS Cost Explorer可以追踪Bedrock支出,设置预算警报。
适用场景:已使用AWS服务的企业、需要符合AWS合规标准的应用、需要跨区域部署的全球应用、希望统一AWS账单的团队。
Google Vertex AI设置流程
Google Vertex AI是Google Cloud的AI平台,自2025年起提供对Claude Haiku 4.5的访问。与Bedrock类似,Vertex AI允许开发者通过Google Cloud账户使用Claude,无需单独的Anthropic账户。
Vertex AI的独特优势包括:与Google Cloud其他AI服务(如Vertex AI Search、AutoML)的无缝整合、支持高达1M context的部分模型(虽然Haiku 4.5仍是200K)、可以使用Google Cloud的全球网络基础设施、以及通过GCP账户统一计费和权限管理。定价与Anthropic官方一致,但可以利用Google Cloud的承诺使用折扣(CUD)降低成本。
配置步骤:
-
启用Vertex AI API:在Google Cloud Console中,导航到"APIs & Services",搜索"Vertex AI API"并启用。确保项目已绑定计费账户。
-
配置服务账户:创建服务账户并授予
Vertex AI User角色。下载JSON格式的密钥文件,用于应用认证。
bashgcloud iam service-accounts create claude-app
gcloud projects add-iam-policy-binding PROJECT_ID \
--member="serviceAccount:claude-app@PROJECT_ID.iam.gserviceaccount.com" \
--role="roles/aiplatform.user"
- 使用Google Cloud SDK调用:安装
google-cloud-aiplatformPython包,使用以下代码调用Claude Haiku 4.5:
pythonfrom google.cloud import aiplatform
aiplatform.init(project='your-project-id', location='us-central1')
endpoint = aiplatform.Endpoint(endpoint_name='claude-haiku-4-5')
response = endpoint.predict(
instances=[{
"messages": [{"role": "user", "content": "What is Vertex AI?"}],
"max_tokens": 1024
}]
)
print(response.predictions[0]['content'])
- 配额管理:Vertex AI使用配额系统限制请求速率。在Console的"Quotas"页面可以查看当前配额并申请提升。初始配额通常为1,000 requests/minute,足够大多数应用使用。
适用场景:使用Google Cloud的企业、需要与Google AI服务集成的应用、希望利用Google全球网络的国际业务、追求GCP生态统一的团队。
GitHub Copilot中的Haiku 4.5
2025年10月15日,GitHub宣布将Claude Haiku 4.5集成到GitHub Copilot中,这是开发者访问Claude最便捷的方式之一。通过Copilot,你可以在IDE内直接与Claude对话,无需切换到浏览器或编写API调用代码。
访问方式:Claude Haiku 4.5在GitHub Copilot的Pro、Business和Enterprise订阅中可用(个人版$10/月,团队版$19/用户/月)。订阅后,在VS Code、Visual Studio、JetBrains IDEs、GitHub.com网页端或GitHub Mobile应用中,通过Copilot Chat面板即可选择Claude模型。
使用场景:
- 代码解释与审查:选中一段代码,询问Claude其功能、潜在问题或改进建议。Haiku 4.5的快速响应使得这种交互几乎无延迟。
- 代码生成与重构:描述需求,让Claude生成代码片段或重构现有代码。由于Haiku 4.5的73.3% SWE-bench成功率,生成的代码质量高于许多竞品。
- 文档生成:自动生成函数注释、README文档或API文档。Claude理解代码逻辑后,能生成准确且详尽的文档。
- 调试辅助:粘贴错误日志,Claude会分析原因并提供修复建议。Haiku 4.5在错误诊断方面表现出色。
与直接API调用的对比:
- 优势:无需编写API调用代码、无需管理API密钥、与开发环境深度集成、固定月费(无需担心token成本)、同时可以使用GPT-4等其他模型。
- 劣势:无法自定义参数(如temperature、max_tokens)、无法用于生产应用(仅限开发时使用)、需要GitHub Copilot订阅费用、输出不受你控制(存储在GitHub)。
| 平台 | 适用场景 | 优势 | 劣势 | 成本 |
|---|---|---|---|---|
| Anthropic API | 自定义应用开发 | 完全控制、官方支持 | 需信用卡、网络限制 | $1/$5按量 |
| AWS Bedrock | AWS生态企业 | AWS集成、全球区域 | 需AWS账户、配置复杂 | $1/$5按量 |
| Vertex AI | GCP生态企业 | GCP集成、配额灵活 | 需GCP账户、学习曲线 | $1/$5按量 |
| GitHub Copilot | IDE内开发辅助 | 无需配置、固定费用 | 不可编程、仅开发用 | $10-19/月 |
选择建议:如果主要在IDE中使用且已订阅GitHub Copilot,这是最便捷的方式。如果需要构建生产应用,选择Anthropic API或云平台集成。对于企业用户,选择与现有云基础设施一致的平台(AWS→Bedrock,GCP→Vertex AI)可以简化管理和计费。
中国区访问完整方案:网络、支付与优化
网络访问挑战:Great Firewall影响分析
中国开发者在访问Claude Haiku 4.5时面临独特挑战,主要源于**Great Firewall(GFW)**的网络管控和国际支付限制。理解这些障碍是找到有效解决方案的前提。
网络连接问题是首要障碍。Anthropic的API端点api.anthropic.com和网页版claude.ai均位于美国服务器,未在中国境内部署节点。实际测试显示,从中国大陆直接访问这些服务时,经常遇到以下问题:连接超时或失败(约30-40%的请求失败)、延迟极高(平均300-500ms,峰值可达1秒以上)、不稳定的连接质量(频繁的包丢失和重连)、部分地区的ISP完全屏蔽访问。这种网络状况使得生产环境部署几乎不可行。
即使使用VPN或代理可以解决连接问题,但这带来了新的复杂性:VPN服务本身的稳定性问题(可能被阻断)、额外的延迟开销(VPN通常增加50-100ms延迟)、法律合规风险(企业使用VPN需要额外审批)、运维复杂度增加(需要管理VPN服务器和故障转移)。对于需要高可用性的生产应用,VPN不是理想的长期方案。
支付障碍同样严峻。Anthropic仅接受国际信用卡(Visa、Mastercard、American Express),而中国大陆发行的信用卡通常无法通过验证,即使是双币卡也常遇到支付处理商拒绝的情况。这意味着即使解决了网络问题,许多中国开发者仍无法完成账户充值,从而无法使用官方API。
数据主权与合规考虑也不容忽视。企业使用国外AI服务时,需要考虑数据出境的合规要求。虽然Claude API不存储用户输入数据(根据Anthropic的数据政策),但请求和响应仍需经过国际网络传输,可能涉及敏感信息处理的合规审查。
直连解决方案:无需VPN的访问方法
针对中国开发者的访问挑战,有几种实用的直连解决方案,无需依赖VPN即可稳定使用Claude Haiku 4.5:
第三方API聚合服务是最直接的解决方案。这些服务在中国境内或香港部署服务器,作为Anthropic API的代理层,为中国用户提供国内可直连的访问端点。关键优势包括:
-
网络直连:中国开发者无需VPN即可访问,laozhang.ai提供国内直连服务,延迟仅20ms,支持支付宝/微信支付,解决了网络和支付两大痛点。相比直接访问Anthropic API的300-500ms延迟,这种方案将响应时间降低了90%以上。
-
支付本地化:支持支付宝、微信支付等国内支付方式,无需国际信用卡。充值和计费以人民币结算,避免汇率波动和外汇管制问题。
-
统一接口:许多聚合服务提供兼容OpenAI API格式的接口,方便从其他模型迁移。只需更改API端点和密钥,无需修改业务代码。
-
多模型切换:在同一平台访问多个模型(Claude、GPT、Gemini等),便于比较和A/B测试。
香港/新加坡中转节点是另一种方案。如果企业已在香港或新加坡有云基础设施(如AWS香港区域、阿里云香港),可以在这些区域部署API调用层,作为中国大陆业务和Anthropic API之间的桥梁。这种架构的优势是:网络质量较好(香港到美国的延迟通常在150-200ms)、符合企业合规要求(数据不经过第三方)、可以集成自己的缓存和负载均衡逻辑。劣势是需要额外的基础设施投入和运维成本。
Cloudflare Workers或边缘函数是轻量级的中转方案。将API调用逻辑部署到Cloudflare Workers(全球边缘网络),利用Cloudflare的全球节点加速访问。虽然Cloudflare本身在中国的访问也不完全稳定,但比直接访问Anthropic API有显著改善。这种方案适合小规模或实验性项目。
| 方案 | 延迟 | 稳定性 | 支付方式 | 月成本 | 适用场景 |
|---|---|---|---|---|---|
| 直接访问+VPN | 350-600ms | 低 | 国际信用卡 | $20-50 VPN费 | 不推荐生产 |
| 第三方聚合服务 | 20-50ms | 高 | 支付宝/微信 | $100-500 | 推荐首选 |
| 香港中转节点 | 150-250ms | 中高 | 企业账户 | $200-1000 | 大型企业 |
| Bedrock香港区 | 180-280ms | 高 | AWS账单 | 按量+AWS费 | AWS用户 |
支付方式与延迟优化策略
支付方式对比:不同访问路径的支付方式直接影响可行性。
-
Anthropic官方API:仅支持国际信用卡(Visa、Mastercard、AMEX),需要预充值$5起。中国开发者常遇到支付失败,即使成功也面临外汇管制和汇率问题。不推荐中国大陆用户首选。
-
第三方聚合服务:支持支付宝、微信支付、银联卡等国内支付方式,以人民币计费。部分服务提供充值优惠(如充$100送$10),降低实际成本。这是中国开发者的最佳支付选择。
-
AWS Bedrock/Vertex AI:通过AWS或GCP账单支付,需要企业级账户和国际支付方式。适合已有云服务账户的企业,但个人开发者门槛较高。
延迟优化技术:除了选择合适的访问路径,以下技术可以进一步优化响应速度:
-
请求合并与批处理:将多个小请求合并为一个大请求,减少网络往返次数。例如,批量处理10个文档摘要任务时,使用一个API调用处理所有文档,而不是10次单独调用。
-
本地缓存策略:对于重复性问题(如FAQ、常见代码模式),在本地缓存Claude的响应。使用Redis或内存缓存,相同问题可以在毫秒级返回结果,无需每次调用API。缓存命中率达到30-50%可以显著降低成本和延迟。
-
智能路由与降级:实现多服务商路由逻辑,当主要服务延迟过高或失败时,自动切换到备用服务。例如,优先使用Haiku 4.5,失败时降级到GPT-4o mini或本地模型。
-
流式响应(Streaming):使用SSE(Server-Sent Events)流式接收响应,让用户在完整响应生成前就能看到开始部分,改善感知延迟。虽然总延迟不变,但用户体验显著提升。
-
连接池与Keep-Alive:复用HTTP连接而不是每次建立新连接,可以节省TCP握手时间(50-100ms)。对于高频调用的应用,配置合理的连接池大小(如10-50个连接)至关重要。
性能对比:使用国内聚合服务的平均响应时间为150-200ms(20ms网络延迟 + 130-180ms模型推理),而直接访问Anthropic API从中国的平均响应时间为600-800ms(400ms网络延迟 + 200-400ms推理),前者快3-4倍。
合规性建议:企业使用AI服务时,应咨询法务部门确保符合数据安全法、个人信息保护法等法规要求。建议:不要将敏感个人信息(如身份证号、手机号)直接发送给API、实施数据脱敏或加密、审查服务商的数据处理协议、记录所有API调用日志以备审计。
成本优化策略:Token计算与省钱技巧
Haiku 4.5定价详解:$1输入/$5输出
理解Claude Haiku 4.5的定价结构是控制成本的基础。Anthropic采用基于tokens的按量计费模式,区分输入和输出两种token类型,定价分别为**$1/百万输入tokens和$5/百万输出tokens**。
输入tokens包括你发送给API的所有内容:用户问题、系统提示词、对话历史、上传的文档内容等。输出tokens则是Claude生成的响应内容。这种区分定价合理,因为生成内容(输出)的计算成本远高于处理输入。例如,一个典型的客服对话,输入400 tokens(用户问题+上下文),输出150 tokens(Claude回复),单次成本为:
成本 = (400/1,000,000 × $1) + (150/1,000,000 × $5)
= $0.0004 + $0.00075
= $0.00115(约0.008元人民币)
相比之下,Sonnet 4的同样对话成本为$0.00315($3输入+$15输出),是Haiku 4.5的2.7倍。对于每日处理10万次对话的应用,Haiku 4.5每月成本约$3,450,而Sonnet 4为$9,450,节省$6,000。
| Claude模型 | 输入定价 | 输出定价 | 典型对话成本 | 10万次/月成本 |
|---|---|---|---|---|
| Haiku 4.5 | $1/M | $5/M | $0.00115 | $3,450 |
| Haiku 3.5 | $0.80/M | $4/M | $0.00092 | $2,760 |
| Sonnet 4 | $3/M | $15/M | $0.00315 | $9,450 |
| Opus 4 | $15/M | $75/M | $0.01725 | $51,750 |
与竞品对比:GPT-4o mini定价为$0.15输入/$0.60输出,相同对话成本仅$0.00015,是Haiku 4.5的1/8。但如第2章所述,Haiku 4.5在质量上显著领先(73.3% vs 65% SWE-bench),更高的一次成功率意味着更少的重试和返工成本。对于追求性价比而非绝对低价的场景,Haiku 4.5往往更经济。
Token使用量估算与成本计算
准确估算token用量是预算规划的关键。Token与文本的转换规则:
- 英文:1 token ≈ 0.75个单词(或4个字符)
- 中文:1 token ≈ 0.5个汉字(中文tokens消耗更大)
- 代码:1 token ≈ 0.6-0.8个字符(取决于语言和格式)
示例计算:
场景1:文档摘要服务
- 输入:5000字中文文档 = 10,000 tokens
- 输出:500字摘要 = 1,000 tokens
- 单次成本:(10,000/1M × $1) + (1,000/1M × $5) = $0.015
- 月处理10,000篇:$150
场景2:代码生成助手
- 输入:300字需求描述 + 500行上下文代码 = 2,500 tokens
- 输出:100行生成代码 = 600 tokens
- 单次成本:(2,500/1M × $1) + (600/1M × $5) = $0.0055
- 月生成5,000次:$27.50
场景3:客服聊天机器人
- 输入:200字问题 + 500字知识库上下文 = 1,400 tokens
- 输出:150字回复 = 300 tokens
- 单次成本:(1,400/1M × $1) + (300/1M × $5) = $0.0029
- 月处理100,000次:$290
| 应用场景 | 输入tokens | 输出tokens | 单次成本 | 10万次/月成本 |
|---|---|---|---|---|
| 简单分类 | 200 | 10 | $0.00025 | $25 |
| 文档摘要 | 10,000 | 1,000 | $0.015 | $1,500 |
| 代码生成 | 2,500 | 600 | $0.0055 | $550 |
| 客服对话 | 1,400 | 300 | $0.0029 | $290 |
| 深度分析 | 20,000 | 3,000 | $0.035 | $3,500 |
隐藏成本项需要注意:
- System prompt开销:如果每个请求都携带1000 tokens的系统提示,月处理10万次将额外消耗$100
- 对话历史累积:多轮对话中,历史记录会随轮次增加而膨胀,第5轮对话的输入可能是第1轮的5倍
- 失败重试成本:API错误或响应不符合预期时的重试,增加15-30%的实际token消耗
降低成本的实用策略
经过验证的成本优化技术可以在不牺牲质量的前提下,降低30-60%的API支出:
-
优化Prompt工程:更精准的提示词可以减少输出长度和重试次数。例如,"用50字总结"比"简要总结"更能控制输出长度。明确输出格式要求(如JSON结构)可以避免生成冗余解释文本。
-
动态max_tokens设置:根据任务类型设置合理的输出上限。分类任务设置50 tokens,摘要设置500,代码生成设置2000。避免默认使用最大值(64K),导致不必要的tokens生成。
-
缓存频繁请求:对于高重复率的问题(如FAQ、常见错误诊断),使用Redis缓存结果。30-50%的缓存命中率可以直接节省相应比例的成本。缓存键可以基于输入的哈希值,过期时间设置为1-7天。
-
批处理与合并:将多个小任务合并为一个大请求。例如,批量分类100个短文本时,使用一个包含100个项目的请求,而不是100次单独调用。这样可以共享系统提示,节省大量输入tokens。
-
利用免费测试额度:在投入大规模使用前,充分利用免费额度进行POC验证。需要免费测试?laozhang.ai提供3百万Token免费额度,足够完成POC验证,让你在零成本下评估效果。
-
模型分层策略:简单任务用Haiku 4.5,复杂任务用Sonnet 4。实现自动路由逻辑,根据问题复杂度和置信度决定使用哪个模型。例如,客服系统用Haiku 4.5处理80%的常见问题,复杂问题升级到Sonnet 4,可以节省40-60%成本。
-
监控与预警:实时跟踪token使用情况,设置每日/每月支出上限警报。当检测到异常高消耗时(如无限循环调用、输入过长),及时阻断以避免超支。使用Anthropic Console的Usage Dashboard或自建监控系统。
-
控制对话历史长度:多轮对话中,只保留最近3-5轮历史,而不是全部历史。对于长对话,定期总结前面轮次的关键信息,用总结替代原始对话,可以将历史tokens减少70-80%。
成本对比示例:一个月处理50万次客服对话的应用:
- 未优化:平均2000 tokens输入 + 400 tokens输出 = $1,100/月
- 应用优化后:
- 缓存命中40%(节省$440)
- 优化prompt减少20%输出(节省$88)
- 分层策略30%使用Haiku 3.5(节省$66)
- 优化后成本:$506/月,节省54%
| 优化策略 | 节省比例 | 实施难度 | 适用场景 |
|---|---|---|---|
| Prompt优化 | 10-20% | 低 | 所有场景 |
| max_tokens控制 | 15-30% | 低 | 输出可预测的任务 |
| 缓存策略 | 30-50% | 中 | 高重复率应用 |
| 批处理合并 | 20-40% | 中 | 批量任务 |
| 模型分层 | 40-60% | 高 | 多复杂度混合场景 |
| 对话历史压缩 | 50-70% | 中 | 多轮对话应用 |
第三方服务对比:除了官方API,第三方聚合服务的定价可能更有竞争力,尤其是包含免费额度或充值优惠的服务。仔细对比定价、支持的模型、服务稳定性和技术支持质量,选择性价比最高的方案。
实战集成:代码示例与SDK最佳实践
Python SDK完整示例
在生产环境中集成Claude Haiku 4.5需要考虑错误处理、重试逻辑、token统计和性能优化。以下是包含这些最佳实践的完整Python实现:
pythonimport os
import time
from anthropic import Anthropic, APIError, APIConnectionError
from typing import Optional, Dict, Any
class ClaudeHaikuClient:
"""Production-ready Claude Haiku 4.5 client with best practices"""
def __init__(self, api_key: Optional[str] = None, max_retries: int = 3):
self.client = Anthropic(api_key=api_key or os.environ.get("ANTHROPIC_API_KEY"))
self.max_retries = max_retries
self.model = "claude-haiku-4-5-20251015"
def call(
self,
prompt: str,
system_prompt: Optional[str] = None,
max_tokens: int = 1024,
temperature: float = 1.0,
stream: bool = False
) -> Dict[str, Any]:
"""
Call Claude Haiku 4.5 with automatic retry and error handling
Args:
prompt: User input text
system_prompt: System instructions (optional)
max_tokens: Maximum output tokens
temperature: Randomness (0-1, default 1.0)
stream: Enable streaming response
Returns:
Dict with 'content', 'usage', and 'success' keys
"""
messages = [{"role": "user", "content": prompt}]
for attempt in range(self.max_retries):
try:
kwargs = {
"model": self.model,
"max_tokens": max_tokens,
"temperature": temperature,
"messages": messages
}
if system_prompt:
kwargs["system"] = system_prompt
if stream:
return self._handle_stream(kwargs)
response = self.client.messages.create(**kwargs)
return {
"success": True,
"content": response.content[0].text,
"usage": {
"input_tokens": response.usage.input_tokens,
"output_tokens": response.usage.output_tokens,
"total_cost": self._calculate_cost(
response.usage.input_tokens,
response.usage.output_tokens
)
},
"model": response.model
}
except APIConnectionError as e:
# Network error - retry with exponential backoff
if attempt < self.max_retries - 1:
wait_time = 2 ** attempt # 1s, 2s, 4s
print(f"Connection error, retrying in {wait_time}s...")
time.sleep(wait_time)
continue
return {"success": False, "error": f"Connection failed: {str(e)}"}
except APIError as e:
# API error - check if retryable
if e.status_code == 429: # Rate limit
if attempt < self.max_retries - 1:
wait_time = 5 * (attempt + 1)
print(f"Rate limited, waiting {wait_time}s...")
time.sleep(wait_time)
continue
return {"success": False, "error": f"API error {e.status_code}: {e.message}"}
except Exception as e:
return {"success": False, "error": f"Unexpected error: {str(e)}"}
return {"success": False, "error": "Max retries exceeded"}
def _handle_stream(self, kwargs):
"""Handle streaming responses"""
with self.client.messages.stream(**kwargs) as stream:
full_text = ""
for text in stream.text_stream:
print(text, end="", flush=True)
full_text += text
message = stream.get_final_message()
return {
"success": True,
"content": full_text,
"usage": {
"input_tokens": message.usage.input_tokens,
"output_tokens": message.usage.output_tokens,
"total_cost": self._calculate_cost(
message.usage.input_tokens,
message.usage.output_tokens
)
}
}
@staticmethod
def _calculate_cost(input_tokens: int, output_tokens: int) -> float:
"""Calculate cost in USD based on Haiku 4.5 pricing"""
input_cost = (input_tokens / 1_000_000) * 1.0
output_cost = (output_tokens / 1_000_000) * 5.0
return round(input_cost + output_cost, 6)
# Usage examples
if __name__ == "__main__":
client = ClaudeHaikuClient()
# Simple synchronous call
result = client.call(
prompt="Explain Docker in 3 sentences.",
max_tokens=200
)
if result["success"]:
print(result["content"])
print(f"\nCost: ${result['usage']['total_cost']}")
print(f"Tokens: {result['usage']['input_tokens']} in, {result['usage']['output_tokens']} out")
# With system prompt and streaming
result = client.call(
prompt="Write a Python function to validate email addresses.",
system_prompt="You are an expert Python developer. Provide concise, production-ready code.",
max_tokens=500,
stream=True
)
关键实现要点:
- 重试机制:网络错误指数退避(1s, 2s, 4s),速率限制线性增加等待(5s, 10s, 15s)
- 成本追踪:每次调用自动计算USD成本,便于监控预算
- 流式响应:实时输出生成内容,改善用户体验
- 类型提示:使用Python类型注解提高代码可维护性
- 环境变量:安全地从环境变量读取API密钥
Node.js与其他语言集成
Node.js/TypeScript完整实现:
typescriptimport Anthropic from '@anthropic-ai/sdk';
interface CallOptions {
prompt: string;
systemPrompt?: string;
maxTokens?: number;
temperature?: number;
stream?: boolean;
}
interface APIResponse {
success: boolean;
content?: string;
usage?: {
inputTokens: number;
outputTokens: number;
totalCost: number;
};
error?: string;
}
class ClaudeHaikuClient {
private client: Anthropic;
private model = 'claude-haiku-4-5-20251015';
private maxRetries: number;
constructor(apiKey?: string, maxRetries = 3) {
this.client = new Anthropic({
apiKey: apiKey || process.env.ANTHROPIC_API_KEY,
});
this.maxRetries = maxRetries;
}
async call(options: CallOptions): Promise<APIResponse> {
const {
prompt,
systemPrompt,
maxTokens = 1024,
temperature = 1.0,
stream = false
} = options;
for (let attempt = 0; attempt < this.maxRetries; attempt++) {
try {
const messageParams: any = {
model: this.model,
max_tokens: maxTokens,
temperature: temperature,
messages: [{ role: 'user' as const, content: prompt }]
};
if (systemPrompt) {
messageParams.system = systemPrompt;
}
if (stream) {
return await this.handleStream(messageParams);
}
const message = await this.client.messages.create(messageParams);
return {
success: true,
content: message.content[0].type === 'text' ? message.content[0].text : '',
usage: {
inputTokens: message.usage.input_tokens,
outputTokens: message.usage.output_tokens,
totalCost: this.calculateCost(
message.usage.input_tokens,
message.usage.output_tokens
)
}
};
} catch (error: any) {
if (error instanceof Anthropic.APIConnectionError) {
if (attempt < this.maxRetries - 1) {
const waitTime = Math.pow(2, attempt) * 1000; // 1s, 2s, 4s
console.log(`Connection error, retrying in ${waitTime/1000}s...`);
await this.sleep(waitTime);
continue;
}
}
if (error instanceof Anthropic.APIError && error.status === 429) {
if (attempt < this.maxRetries - 1) {
const waitTime = 5000 * (attempt + 1); // 5s, 10s, 15s
console.log(`Rate limited, waiting ${waitTime/1000}s...`);
await this.sleep(waitTime);
continue;
}
}
return {
success: false,
error: `Error: ${error.message || String(error)}`
};
}
}
return { success: false, error: 'Max retries exceeded' };
}
private async handleStream(params: any): Promise<APIResponse> {
const stream = await this.client.messages.stream(params);
let fullText = '';
for await (const chunk of stream) {
if (chunk.type === 'content_block_delta' &&
chunk.delta.type === 'text_delta') {
process.stdout.write(chunk.delta.text);
fullText += chunk.delta.text;
}
}
const message = await stream.finalMessage();
return {
success: true,
content: fullText,
usage: {
inputTokens: message.usage.input_tokens,
outputTokens: message.usage.output_tokens,
totalCost: this.calculateCost(
message.usage.input_tokens,
message.usage.output_tokens
)
}
};
}
private calculateCost(inputTokens: number, outputTokens: number): number {
const inputCost = (inputTokens / 1_000_000) * 1.0;
const outputCost = (outputTokens / 1_000_000) * 5.0;
return parseFloat((inputCost + outputCost).toFixed(6));
}
private sleep(ms: number): Promise<void> {
return new Promise(resolve => setTimeout(resolve, ms));
}
}
// Usage
(async () => {
const client = new ClaudeHaikuClient();
const result = await client.call({
prompt: 'Explain async/await in JavaScript',
maxTokens: 300
});
if (result.success) {
console.log(result.content);
console.log(`\nCost: ${result.usage?.totalCost}`);
}
})();
LangChain、LlamaIndex框架集成
LangChain集成(简化多模型切换和链式调用):
pythonfrom langchain_anthropic import ChatAnthropic
from langchain.prompts import ChatPromptTemplate
from langchain.chains import LLMChain
# Initialize Claude Haiku 4.5 with LangChain
llm = ChatAnthropic(
model="claude-haiku-4-5-20251015",
anthropic_api_key=os.environ["ANTHROPIC_API_KEY"],
max_tokens=1024,
temperature=0.7
)
# Create a prompt template
prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful coding assistant."),
("human", "{question}")
])
# Build a chain
chain = LLMChain(llm=llm, prompt=prompt)
# Execute
result = chain.run(question="How do I implement binary search in Python?")
print(result)
# Multi-step chain example
from langchain.chains import SequentialChain
# Step 1: Generate code
code_chain = LLMChain(
llm=llm,
prompt=ChatPromptTemplate.from_template("Write Python code for: {task}"),
output_key="code"
)
# Step 2: Add documentation
doc_chain = LLMChain(
llm=llm,
prompt=ChatPromptTemplate.from_template("Add docstrings to this code:\n{code}"),
output_key="documented_code"
)
# Combine chains
full_chain = SequentialChain(
chains=[code_chain, doc_chain],
input_variables=["task"],
output_variables=["documented_code"]
)
result = full_chain({"task": "merge sort algorithm"})
print(result["documented_code"])
LlamaIndex集成(构建RAG应用):
pythonfrom llama_index.llms.anthropic import Anthropic
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
# Configure Claude Haiku 4.5 as LLM
Settings.llm = Anthropic(
model="claude-haiku-4-5-20251015",
api_key=os.environ["ANTHROPIC_API_KEY"],
max_tokens=512
)
# Load documents
documents = SimpleDirectoryReader("./data").load_data()
# Create index
index = VectorStoreIndex.from_documents(documents)
# Query with RAG
query_engine = index.as_query_engine()
response = query_engine.query("What are the key features of our product?")
print(response)
# Streaming query
streaming_response = query_engine.query(
"Summarize the technical architecture",
streaming=True
)
for text in streaming_response.response_gen:
print(text, end="", flush=True)
最佳实践总结:
- 连接池:复用HTTP连接,减少握手开销
- 超时配置:设置30-60秒超时,避免无限等待
- 日志记录:记录所有API调用、错误和成本,便于审计和优化
- 环境隔离:开发/测试/生产使用不同API密钥,防止意外超支
- 版本锁定:指定完整模型标识符(含日期),避免意外模型更新
- Token监控:实时跟踪token消耗,设置预算警报
常见问题与故障排除
API错误代码与解决方案
在使用Claude Haiku 4.5 API时,理解常见错误代码及其解决方法可以快速排查问题,避免不必要的开发时间浪费。
| 错误代码 | 含义 | 常见原因 | 解决方案 |
|---|---|---|---|
| 401 Unauthorized | 认证失败 | API密钥无效或未设置 | 检查API密钥格式(sk-ant-xxx),确认环境变量正确设置 |
| 400 Bad Request | 请求参数错误 | max_tokens超限、消息格式错误 | Haiku 4.5最大64K输出,检查JSON格式完整性 |
| 429 Rate Limit | 超过速率限制 | TPM/RPM超过tier限制 | 实现指数退避重试,考虑升级tier或分散请求 |
| 500 Server Error | Anthropic服务器错误 | 临时服务故障 | 等待5-10秒后重试,持续失败联系支持 |
| 502/503/504 | 网关超时 | 高负载或网络问题 | 使用指数退避重试,检查网络连接 |
| 529 Overloaded | 系统过载 | API流量过大 | 等待30-60秒后重试,避开高峰时段 |
401错误详细排查:
- 确认API密钥未过期或被撤销(在Console检查)
- 检查是否误用了Claude.ai账户密码(API密钥≠登录密码)
- 验证密钥权限范围是否包含目标模型
- 确认请求头中使用
x-api-key(非Authorization)
400错误常见场景:
- max_tokens设置过大:Haiku 4.5最大支持64K输出tokens,设置超过此值会报错
- 消息格式错误:messages数组必须交替出现user/assistant角色,不能连续两个相同角色
- Content类型不匹配:发送图片时content需要是数组格式,包含type和source字段
- 参数类型错误:temperature必须是0-1的浮点数,不能是字符串
500/502/503错误处理策略:这些是服务端临时错误,应该自动重试而不是立即报错给用户。推荐的重试策略:
pythonimport time
import random
def exponential_backoff_retry(func, max_retries=3):
for attempt in range(max_retries):
try:
return func()
except APIError as e:
if e.status_code >= 500 and attempt < max_retries - 1:
# 指数退避 + 随机抖动(避免雪崩)
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"Server error {e.status_code}, retrying in {wait_time:.1f}s")
time.sleep(wait_time)
else:
raise
频率限制与重试策略
Anthropic使用**分层速率限制(Tiered Rate Limits)**系统,根据账户累计充值金额自动升级tier,不同tier有不同的TPM(Tokens Per Minute)和RPM(Requests Per Minute)限制。
Tier系统详解:
| Tier | 充值要求 | TPM限制 | RPM限制 | 适用场景 |
|---|---|---|---|---|
| Tier 1 | $0-$50 | 4,000 | 40 | 开发测试 |
| Tier 2 | $50-$500 | 40,000 | 400 | 小规模生产 |
| Tier 3 | $500-$5,000 | 80,000 | 800 | 中等规模应用 |
| Tier 4 | $5,000+ | 320,000 | 3,200 | 大规模企业 |
速率限制计算:TPM限制是指每分钟内所有请求的输入+输出tokens总和。例如,Tier 1的4,000 TPM意味着:
- 如果每个请求平均使用400 tokens,每分钟最多10个请求
- 如果每个请求使用2,000 tokens,每分钟最多2个请求
- 超过限制会收到429错误,需要等待下一分钟窗口
429错误处理最佳实践:
-
检测并等待:捕获429错误,从响应头读取
Retry-After字段(告诉你需要等待多久),或使用固定等待时间(5-10秒) -
指数退避:第一次重试等待5秒,第二次10秒,第三次20秒。这避免了立即重试导致的请求堆积
-
请求队列:实现请求队列和速率限制器,确保发送速率不超过tier限制:
pythonimport time
from collections import deque
from threading import Lock
class RateLimiter:
def __init__(self, tpm_limit, rpm_limit):
self.tpm_limit = tpm_limit
self.rpm_limit = rpm_limit
self.request_times = deque()
self.token_usage = deque()
self.lock = Lock()
def wait_if_needed(self, estimated_tokens):
with self.lock:
now = time.time()
# 清理1分钟前的记录
while self.request_times and now - self.request_times[0] > 60:
self.request_times.popleft()
self.token_usage.popleft()
# 检查RPM限制
if len(self.request_times) >= self.rpm_limit:
sleep_time = 60 - (now - self.request_times[0])
if sleep_time > 0:
time.sleep(sleep_time)
# 检查TPM限制
current_tokens = sum(self.token_usage)
if current_tokens + estimated_tokens > self.tpm_limit:
time.sleep(60 - (now - self.request_times[0]))
# 记录本次请求
self.request_times.append(now)
self.token_usage.append(estimated_tokens)
- Tier升级策略:如果经常遇到429错误,考虑充值升级tier。从Tier 1到Tier 2仅需充值$50,但TPM提升10倍,这对高频应用非常划算。
重要提示:429错误会消耗你的重试次数和时间,但不会计费。正确处理速率限制不仅提升用户体验,还能节省开发调试时间。
性能问题诊断
响应速度慢(>3秒):
- 诊断:使用
time模块或日志记录完整请求周期各阶段耗时 - 常见原因:
- 输入tokens过大(>50K):考虑分批处理或摘要输入
- 输出tokens设置过高:降低max_tokens到实际需要的值
- 网络延迟高(中国大陆常见):参考第7章使用聚合服务
- 服务端负载高:避开美国工作时间高峰(北京时间晚上11点-凌晨3点)
- 解决方案:
- 启用streaming减少感知延迟
- 使用连接池保持长连接
- 区域就近部署(使用Bedrock香港区)
质量不符合预期:
- 问题表现:输出不准确、格式错误、偏离指令
- 优化策略:
- 细化Prompt:从"总结文档"改为"用3个要点总结文档关键内容,每点不超过30字"
- 添加Few-shot示例:在prompt中提供2-3个期望输出示例
- 调整temperature:创意任务用0.7-1.0,事实性任务用0-0.3
- 升级模型:如果Haiku 4.5不足以完成任务,升级到Sonnet 4
- 后处理验证:使用正则表达式或JSON schema验证输出格式
Token消耗异常高:
- 排查方法:记录每次请求的input/output tokens,分析异常请求
- 常见原因:
- System prompt过长(>1000 tokens):精简或缓存系统提示
- 对话历史累积(多轮对话):定期清理或总结历史
- 输出超预期(max_tokens设置过高或未限制):设置合理上限
- 重复内容未缓存:使用Redis缓存高频问题
- 监控工具:Anthropic Console的Usage页面可查看每日token消耗趋势,发现异常峰值及时调查
生产环境部署建议与总结
生产环境架构模式
将Claude Haiku 4.5部署到生产环境需要考虑高可用性、性能优化和成本控制。以下是经过验证的架构模式:
单模型直连架构(适合小规模应用):
- 应用直接调用Anthropic API或聚合服务
- 优势:简单、低运维成本
- 局限:无容错能力,依赖单一服务商
- 适用场景:日请求量<10万,可接受偶发故障的应用
多模型热备份架构(推荐中等规模应用):
- 主用Haiku 4.5,备用GPT-4o mini或Haiku 3.5
- 当主模型失败或延迟过高时自动切换
- 优势:高可用性,成本可控(备用模型仅故障时使用)
- 实现:使用try-catch捕获错误,失败时调用备用模型
pythondef call_with_fallback(prompt, primary_model, fallback_model):
try:
return primary_model.call(prompt, timeout=5)
except (APIError, Timeout) as e:
logger.warning(f"Primary model failed: {e}, using fallback")
return fallback_model.call(prompt)
分层路由架构(大规模优化成本):
- 简单任务→Haiku 4.5(70-80%请求)
- 中等复杂→Sonnet 4(15-20%)
- 高度复杂→Opus 4(5-10%)
- 实现:在请求前使用分类器或规则判断复杂度
缓存加速架构(高重复率场景):
- Redis缓存常见问题的响应
- 缓存键:prompt的哈希值
- 过期策略:7天TTL,热点内容不过期
- 效果:30-50%缓存命中率可降低50%成本
多区域部署架构(全球应用):
- 美国用户→Anthropic API(低延迟)
- 中国用户→国内聚合服务(避免GFW)
- 欧洲用户→Bedrock欧洲区
- 实现:根据用户IP或地理位置路由到最近服务
监控、日志与高可用配置
关键监控指标:
-
性能指标:
- 平均响应时间(目标<2秒)
- P95/P99响应时间(识别异常慢请求)
- 请求成功率(目标>99.5%)
- 各错误码分布(401/429/500等)
-
成本指标:
- 每日token消耗量
- 每日API成本(美元)
- 平均每请求成本
- 成本异常警报(日成本>预算120%)
-
业务指标:
- 用户满意度评分
- 重试率(高重试=质量问题)
- 缓存命中率
- 各模型使用分布
日志记录最佳实践:
pythonimport logging
import json
from datetime import datetime
def log_api_call(prompt, response, cost, duration):
log_data = {
"timestamp": datetime.utcnow().isoformat(),
"model": "claude-haiku-4-5-20251015",
"input_tokens": response.usage.input_tokens,
"output_tokens": response.usage.output_tokens,
"cost_usd": cost,
"duration_ms": duration * 1000,
"success": response.success,
"error": response.error if not response.success else None,
"prompt_hash": hash(prompt) # 不记录完整prompt保护隐私
}
logging.info(json.dumps(log_data))
高可用配置清单:
- ✅ 实现3次重试机制(指数退避)
- ✅ 设置30-60秒超时
- ✅ 配置至少1个备用模型
- ✅ 部署健康检查端点(/health)
- ✅ 设置速率限制器(避免超Tier限制)
- ✅ 实现熔断机制(连续失败>10次时暂停5分钟)
- ✅ 配置告警:成功率<95%、成本异常、响应时间>5秒
- ✅ 定期备份关键配置和日志
成本控制策略:
- 设置每日支出上限(例如$100/天),超限后降级到免费模型或暂停服务
- 实现用户级别配额(防止单个用户消耗过多资源)
- 定期审查高成本用户和异常请求
- 使用成本预测模型,提前规划预算
访问方案选择决策树
根据你的具体情况,使用以下决策树快速选择最合适的访问方案:
第一层:地理位置
- 中国大陆开发者:首选第三方聚合服务(国内直连+支付宝),备选Bedrock香港区
- 美国/欧洲开发者:继续下一步判断
- 其他地区:选择最近的Bedrock/Vertex AI区域
第二层:使用场景
- 仅测试和学习:Claude.ai免费网页版(无需API)
- 开发生产应用:继续下一步判断
- 仅在IDE中使用:GitHub Copilot(如已订阅)
第三层:技术栈
- 已使用AWS:AWS Bedrock(统一账单和权限)
- 已使用GCP:Google Vertex AI(GCP生态集成)
- 独立开发/多云:Anthropic官方API(最直接)
第四层:成本敏感度
- 极度敏感(创业公司/POC):先用免费层测试,转正后用Haiku 4.5+缓存策略
- 中度敏感:Haiku 4.5为主+Sonnet 4分层路由
- 不敏感(企业应用):选择质量优先(Sonnet 4/Opus 4)
| 你的情况 | 推荐方案 | 理由 |
|---|---|---|
| 中国开发者+创业公司 | 第三方聚合服务 | 解决网络+支付,成本可控 |
| 美国开发者+AWS用户 | AWS Bedrock | 生态统一,企业级支持 |
| 欧洲开发者+GCP用户 | Vertex AI | 本地合规,低延迟 |
| 个人开发者+IDE使用 | GitHub Copilot | 无需配置,固定费用 |
| 大企业+全球用户 | 多区域混合部署 | 优化各地体验和成本 |
最终建议:
Claude Haiku 4.5以其73.3%的SWE-bench成功率、2倍于Sonnet 4的速度和1/3的成本,成为追求性价比的开发者首选。无论是客服机器人、代码助手还是多Agent系统,Haiku 4.5都能提供足够的质量和出色的响应速度。
对于中国开发者,网络和支付是首要考虑,选择支持国内直连和支付宝的聚合服务可以避免90%的接入障碍。对于美国和欧洲开发者,官方API或云平台集成(Bedrock/Vertex AI)提供了最稳定和可控的方案。
无论选择哪种方案,记住:从小规模测试开始,充分利用免费额度验证效果,然后根据实际需求逐步扩展。合理的架构设计(缓存、分层路由、重试机制)可以在保证质量的同时,降低30-60%的总成本。
随着Anthropic持续改进模型和扩展全球基础设施,Claude Haiku 4.5的访问将变得更加便捷。关注官方公告,及时调整策略以获得最佳性价比。现在就开始你的Claude Haiku 4.5之旅,体验高性能AI模型带来的生产力提升。