Claude Sonnet 4.5 Pricing Guide 2025: Complete Cost Analysis, Comparison & Calculator
Claude Sonnet 4.5 costs $3 per million input tokens and $15 per million output tokens. Comprehensive guide covering API pricing, subscription plans, platform costs, optimization strategies, and enterprise contracts with detailed comparisons to GPT-4 and Gemini.

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
Claude Sonnet 4.5 pricing starts at $3 per million input tokens and $15 per million output tokens, representing a cost-neutral upgrade from Claude Sonnet 4 while delivering significantly enhanced capabilities. Released on September 29, 2025, this latest model from Anthropic maintains competitive pricing against GPT-4 Turbo ($10/$30 per million tokens) while offering superior coding performance with up to 90% cost savings through prompt caching and 50% savings via batch processing. This comprehensive guide covers all pricing tiers, platform-specific costs, optimization strategies, enterprise contracts, use case calculations, and international access solutions including options for Chinese users.
Claude Sonnet 4.5 Pricing Overview & Model Comparison
Understanding Claude Sonnet 4.5 pricing requires examining both the base API costs and how they compare to alternative AI models in the current market. Anthropic has maintained consistent pricing across its Sonnet model line while continuously improving performance, making the 4.5 release particularly valuable for cost-conscious developers and businesses.
Base API Pricing Structure
Claude Sonnet 4.5 maintains the same pricing as its predecessor, Claude Sonnet 4, demonstrating Anthropic's commitment to delivering improved capabilities without increasing costs. The pricing structure is straightforward:
- Input Tokens: $3.00 per million tokens
- Output Tokens: $15.00 per million tokens
- Extended Context (>200K tokens): $6.00 input / $22.50 output per million tokens
For standard prompts up to 200,000 tokens, these rates remain fixed regardless of volume at the API level. However, extended context scenarios beyond the 200K token threshold incur double the input cost and 1.5x the output cost, reflecting the additional computational resources required for processing longer contexts.
Comprehensive Model Comparison
The competitive landscape for large language models has intensified throughout 2025, with pricing becoming a critical differentiator alongside performance. Here's how Claude Sonnet 4.5 compares to major alternatives:
| Model | Provider | Input ($/MTok) | Output ($/MTok) | Context Window | Performance (SWE-bench) | Best Use Case |
|---|---|---|---|---|---|---|
| Claude Sonnet 4.5 | Anthropic | $3.00 | $15.00 | 200K tokens | 77.2% | Coding, agentic workflows, complex analysis |
| Claude Opus 4.1 | Anthropic | $15.00 | $75.00 | 200K tokens | 82.1% | Highest quality reasoning, critical tasks |
| GPT-4 Turbo | OpenAI | $10.00 | $30.00 | 128K tokens | 68.9% | General purpose, broad applications |
| GPT-3.5 Turbo | OpenAI | $0.50 | $1.50 | 16K tokens | 48.3% | Simple tasks, high-volume processing |
| Gemini 2.0 Pro | $1.25 | $10.00 | 128K tokens | 71.5% | Cost-sensitive workloads | |
| Gemini 2.0 Flash | $0.075 | $0.30 | 1M tokens | 65.2% | Extreme scale, budget applications |
Performance-Per-Dollar Analysis: Assuming a typical 1:5 input-to-output ratio (common in chatbot and content generation scenarios), Claude Sonnet 4.5 costs approximately $18 per million combined tokens compared to GPT-4 Turbo's $40 per million—representing a 55% cost advantage. When factoring in performance differences (77.2% vs 68.9% on SWE-bench), Claude Sonnet 4.5 delivers 12% better results at less than half the cost, creating exceptional value for technically demanding applications.
Pricing History and Anthropic's Strategy
Anthropic has demonstrated remarkable pricing consistency across its Sonnet model releases. Claude Sonnet 3.5, launched in October 2024, established the $3/$15 pricing tier. Claude Sonnet 4, released in December 2024, maintained identical pricing while introducing improved capabilities. Now, Claude Sonnet 4.5 continues this pattern, offering state-of-the-art performance at unchanged rates.
This strategic approach contrasts with some competitors who have increased prices alongside capability improvements. For developers and businesses already invested in Claude, the 4.5 upgrade represents pure performance gains without budget implications—a critical factor for production systems with established cost structures.
Extended Context Pricing Considerations
For applications requiring context windows beyond 200,000 tokens, Claude Sonnet 4.5 implements tiered pricing:
- Standard Context (≤200K tokens): $3/$15 per million tokens
- Extended Context (>200K tokens): $6/$22.50 per million tokens
This pricing model reflects the exponential computational costs associated with processing longer contexts. Use cases benefiting from extended context include:
- Large document analysis: Processing entire codebases, lengthy legal documents, or extensive research papers
- Multi-turn conversations: Maintaining very long conversation histories for customer support or therapeutic applications
- Comprehensive data analysis: Analyzing extensive datasets within a single prompt for pattern recognition or summarization
For most standard applications, the 200K token context window proves sufficient. Teams should carefully evaluate whether extended context is necessary, as the doubled input costs can significantly impact total expenses for high-volume workloads.

API Pricing Structure & Cost Calculator
Understanding the practical costs of Claude Sonnet 4.5 requires more than knowing the per-token rates—developers and businesses need tools to estimate real-world expenses based on their specific use cases. This section provides calculation frameworks and interactive templates to accurately forecast API costs.
Detailed API Pricing Breakdown
The fundamental cost calculation for Claude Sonnet 4.5 follows this formula:
Total Cost = (Input Tokens × $3 / 1,000,000) + (Output Tokens × $15 / 1,000,000)
For example, a typical API call processing 100,000 input tokens and generating 50,000 output tokens would cost:
- Input cost: 100,000 × $3 / 1,000,000 = $0.30
- Output cost: 50,000 × $15 / 1,000,000 = $0.75
- Total: $1.05 per API call
Understanding token consumption is critical for accurate cost projection. On average, English text converts at approximately 750 characters per 1,000 tokens, meaning a 3,000-word document (roughly 15,000 characters) consumes about 20,000 tokens. Code tends to be more token-dense, with approximately 500-600 characters per 1,000 tokens depending on language and structure.
Cost Calculator Framework by Use Case
To provide practical cost estimation, here's a comprehensive breakdown of common scenarios:
| Use Case Template | Monthly Volume | Input Tokens/mo | Output Tokens/mo | Base Cost | With 80% Caching | Final Optimized Cost |
|---|---|---|---|---|---|---|
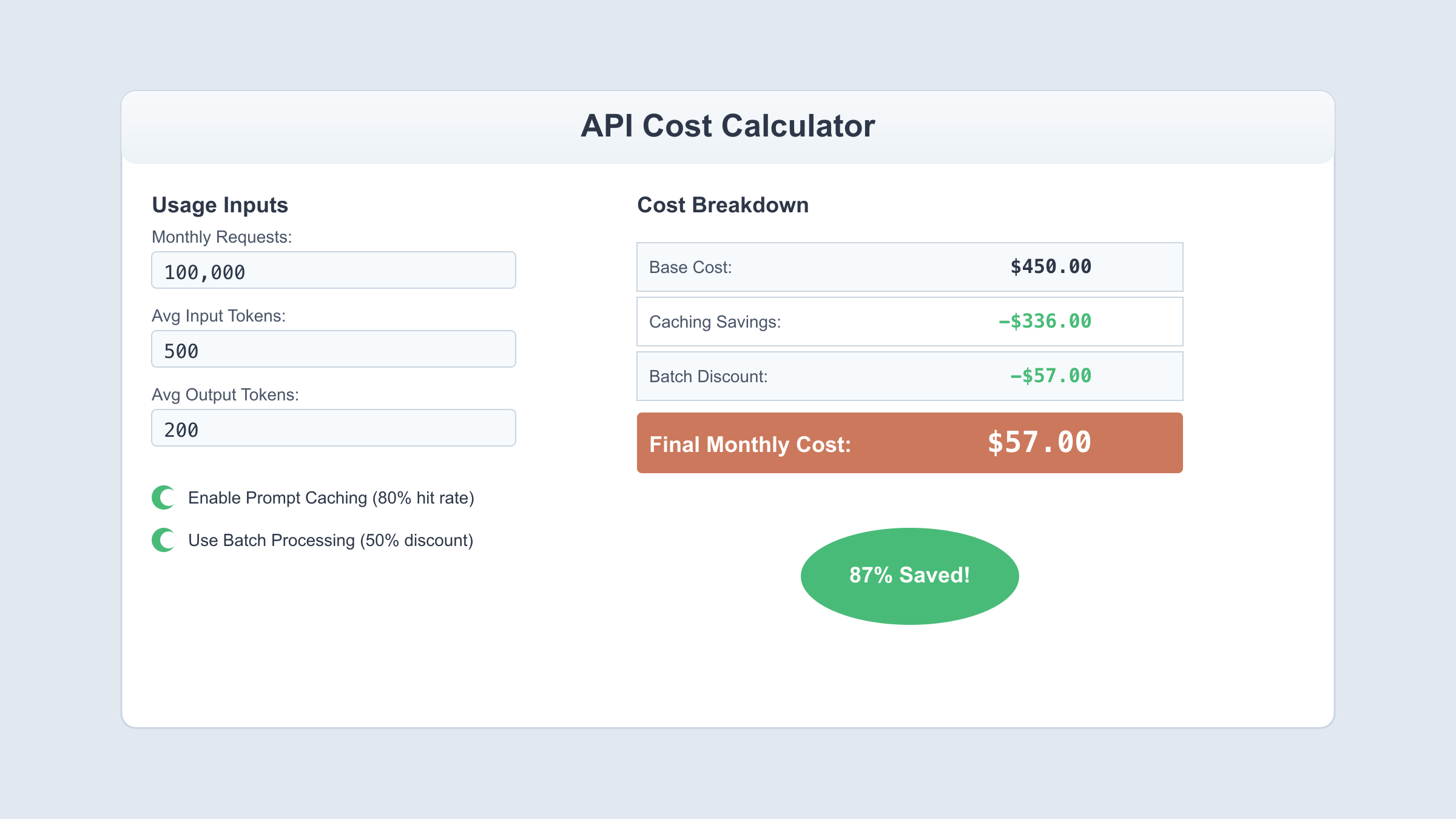
| Customer Support Chatbot | 100,000 conversations | 50M | 20M | $450.00 | -$336.00 | $114.00 |
| Content Generation Platform | 1,000 articles | 5M | 50M | $765.00 | -$573.75 | $191.25 |
| Code Review Assistant | 5,000 pull requests | 100M | 30M | $750.00 | -$562.50 | $187.50 |
| Data Analysis Service | 5,000 queries | 25M | 10M | $225.00 | N/A | $225.00 |
| Document Summarization | 10,000 documents | 200M | 10M | $750.00 | -$375.00 | $375.00 |
| Email Assistant | 50,000 emails | 25M | 25M | $450.00 | -$270.00 | $180.00 |
Calculator Methodology: These estimates assume:
- Chatbot: Average 500-token input (user query + context), 200-token output
- Content Generation: 5,000-token input (brief + examples), 50,000-token output (full article)
- Code Review: 20,000-token input (code + context), 6,000-token output (review)
- Data Analysis: 5,000-token input (data), 2,000-token output (insights)
- Document Summarization: 20,000-token input (document), 1,000-token output (summary)
- Email Assistant: 500-token input (email), 500-token output (response)
Pricing Multipliers and Special Cases
Beyond standard per-token pricing, Claude Sonnet 4.5 implements several pricing multipliers for specific features:
Prompt Caching:
- Cache Write Cost: $3.75 per million tokens (125% of standard input cost)
- Cache Read Cost: $0.30 per million tokens (10% of standard input cost)
- Minimum Cacheable Size: 1,024 tokens (smaller prompts cannot be cached)
Batch Processing:
- Discount: 50% off standard API pricing
- Turnaround Time: 24-48 hours (non-real-time)
- Minimum Batch Size: No minimum, but optimal at 100+ requests
Extended Context (>200K tokens):
- Input: $6.00 per million tokens (200% of standard)
- Output: $22.50 per million tokens (150% of standard)
- Application: Automatically applied when context exceeds 200,000 tokens
Cost Estimation Best Practices
Accurate cost forecasting requires understanding your actual token consumption patterns. Follow these best practices:
-
Measure Before Estimating: Run pilot tests with representative data to capture real token usage. Tools like the Anthropic tokenizer can help you understand how your specific content converts to tokens.
-
Account for System Prompts: Many applications include system prompts or instructions that accompany every request. A 2,000-token system prompt adds $6 per 1,000 requests at standard rates, but only $0.60 when cached—a 90% reduction.
-
Consider Peak vs. Average Usage: API costs scale linearly with volume. If your application experiences traffic spikes, calculate costs for peak periods to avoid budget surprises.
-
Factor in Retry Logic: Implement exponential backoff for failed requests, as aggressive retry patterns can double or triple costs during service disruptions.
-
Monitor Token Distribution: Most applications show an 80/20 pattern where 20% of requests consume 80% of tokens. Identifying and optimizing these high-cost requests can dramatically reduce expenses.
Subscription Plans: Free, Pro, Max, Team & Enterprise
While API access provides maximum flexibility for developers, Anthropic also offers subscription plans through Claude.ai for users preferring a simplified pricing model without per-token calculation. Understanding these tiers is essential for individuals and teams evaluating the platform.
Subscription Tiers Overview
Anthropic structures its Claude offerings across five distinct subscription levels, each targeting different user segments with varying usage patterns and feature requirements:
- Free Tier: Limited daily usage, web interface only
- Pro Plan: $20 per month (or $17/month billed annually)
- Max Plan: $100 per month per user with significantly expanded limits
- Team Plan: $30 per month per user (monthly billing) or $25/month (annual billing), minimum 5 members
- Enterprise Plan: Custom pricing based on organization size and requirements
The progression from Free to Enterprise reflects increasing usage volume, feature access, and support levels. Each tier builds upon the previous one, adding capabilities rather than replacing them.
Comprehensive Feature Comparison Matrix
Understanding which plan fits your needs requires examining the specific features and limitations of each tier:
| Feature | Free | Pro | Max | Team | Enterprise |
|---|---|---|---|---|---|
| Daily Message Limit | ~50 messages | Unlimited | 20x Pro capacity | Unlimited | Unlimited |
| API Access | ✗ | Limited (token-based) | Extended quota | Full access | Full + priority routing |
| Extended Context (200K tokens) | ✗ | ✓ | ✓ | ✓ | ✓ |
| Prompt Caching | ✗ | ✓ | ✓ | ✓ | ✓ |
| Batch Processing | ✗ | ✗ | ✓ | ✓ | ✓ |
| Priority Queue | ✗ | ✗ | ✓ | ✓ | ✓ |
| Team Collaboration | ✗ | ✗ | ✗ | ✓ (shared workspace) | ✓ (advanced) |
| SLA Guarantee | ✗ | ✗ | ✗ | ✗ | ✓ (99.9% uptime) |
| Dedicated Support | Community | Priority email | Account manager | ||
| Custom Contracts | ✗ | ✗ | ✗ | ✗ | ✓ (negotiable terms) |
| SSO/SAML | ✗ | ✗ | ✗ | ✗ | ✓ |
| Usage Analytics | Basic | Standard | Advanced | Advanced | Enterprise dashboard |
| Data Retention Control | Standard | Standard | Standard | Standard | Customizable |
Tier Selection Decision Guide
Choosing the optimal subscription tier depends on several factors beyond just monthly message volume:
Free Tier - Ideal For:
- Individual experimentation and learning
- Casual usage under 50 messages per day
- Testing Claude capabilities before commitment
- Personal projects with minimal AI requirements
Pro Plan ($20/month) - Ideal For:
- Professional individuals with daily AI needs
- Freelancers and consultants
- Writers, researchers, and analysts
- Small projects requiring unlimited messaging
- Users needing basic API access for personal development
Max Plan ($100/month) - Ideal For:
- Power users with intensive daily workflows
- Developers building and testing complex applications
- Data scientists running frequent analyses
- Content creators with high-volume needs
- Users requiring priority access during peak times
The Max plan's "20x Pro capacity" translates to approximately 1,000 messages per day with extended context, compared to Pro's practical limit of around 50-100 messages daily before rate limiting.
Team Plan ($25-30/month per user) - Ideal For:
- Small to medium businesses (5-100 employees)
- Development teams collaborating on projects
- Organizations needing shared workspaces
- Companies requiring usage visibility across team members
- Groups benefiting from collective knowledge sharing
Team plans require a minimum of 5 users, making the entry point $125/month (annual billing) or $150/month (monthly billing).
Enterprise Plan (Custom) - Ideal For:
- Large organizations (100+ employees)
- Businesses requiring SLA guarantees
- Companies with strict compliance needs
- Organizations needing SSO/SAML integration
- Enterprises demanding dedicated support and account management
Cost Comparison and Value Analysis
When comparing subscription plans to API access, consider total cost of ownership across different usage patterns:
Pro Plan Value Calculation:
- Annual cost: $20 × 12 = $240/year
- Equivalent API usage: ~1.6 million tokens monthly (assuming 1:5 input:output ratio at $15 combined cost per MTok)
- Break-even: Approximately 80,000 messages monthly at average 200 tokens per message
For users consistently exceeding 50,000-80,000 messages monthly, the Pro subscription offers better value than pay-per-token API pricing. Conversely, users with sporadic, high-volume bursts might find API pricing more economical.
Max Plan Positioning:
- Annual cost: $100 × 12 = $1,200/year
- 20x Pro capacity suggests ~8 million tokens monthly potential
- Value proposition: Unlimited usage for power users versus metered API costs that could exceed $120/month at high volume
Team Plan Economics:
- 10-user team (annual): $25 × 10 × 12 = $3,000/year
- Per-user value: $300/year each for unlimited access
- Comparison: A single user consuming $300/year in API tokens (20M tokens) would far exceed typical individual usage, making Team plans extremely cost-effective for collaborative environments
Platform-Specific Pricing: AWS, Azure, GCP & Direct API
Claude Sonnet 4.5 is available through multiple deployment platforms beyond Anthropic's direct API, each introducing unique pricing structures, additional fees, and platform-specific value propositions. Understanding these differences is crucial for optimizing deployment costs and selecting the right infrastructure.
Platform Availability and Pricing Structure
While Anthropic's base pricing remains consistent across platforms, deployment through cloud providers introduces additional cost layers:
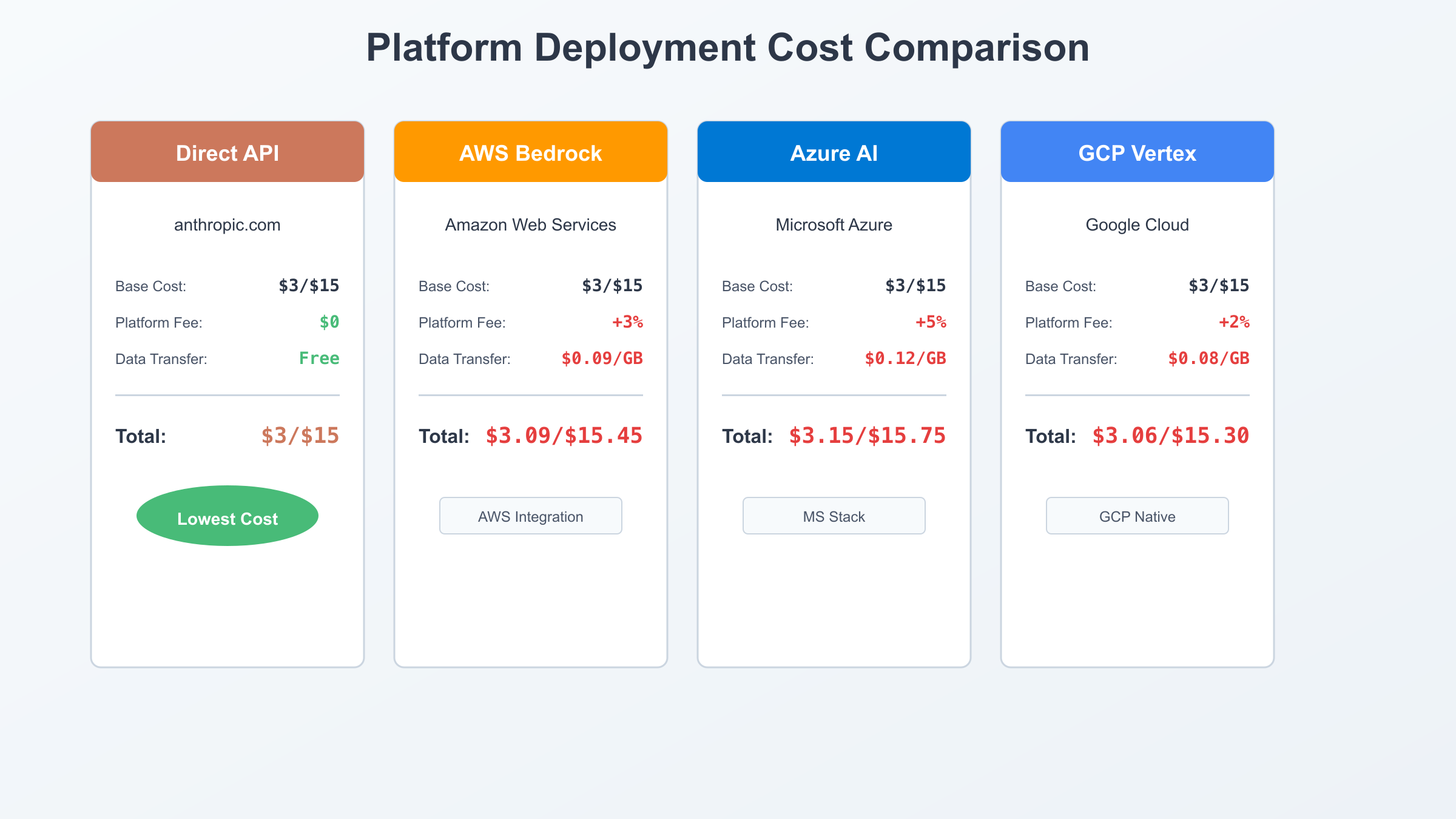
| Platform | Base API Cost | Platform Markup | Data Transfer | Storage Costs | Estimated Total Cost | Key Integration Benefit |
|---|---|---|---|---|---|---|
| Direct API (anthropic.com) | $3/$15 per MTok | $0 (no markup) | Included | N/A | $3.00/$15.00 | Direct access, no intermediary |
| AWS Bedrock | $3/$15 per MTok | ~3% estimated | $0.09/GB egress | S3: $0.023/GB-month | $3.09/$15.45 | Deep AWS ecosystem integration |
| Azure AI Studio | $3/$15 per MTok | ~5% estimated | $0.12/GB egress | Blob: $0.018/GB-month | $3.15/$15.75 | Microsoft stack integration |
| Google Cloud Vertex AI | $3/$15 per MTok | ~2% estimated | $0.08/GB egress | GCS: $0.020/GB-month | $3.06/$15.30 | Google Cloud native services |
| GitHub Copilot | Included in subscription | N/A | Included | N/A | $10-39/month | Seamless developer tool integration |
Important: Platform markups are estimates based on typical cloud provider pricing patterns. Actual costs may vary based on specific agreements, regions, and usage patterns. AWS, Azure, and GCP do not publicly disclose exact Claude-specific markups but apply standard platform service fees.
Hidden Costs and Infrastructure Considerations
Beyond the obvious per-token costs, platform deployments incur several additional expenses that can significantly impact total cost of ownership:
Data Transfer Costs:
- Ingress (incoming data): Typically free across all platforms
- Egress (outgoing data): Charges apply when responses leave the cloud provider's network
- AWS: $0.09/GB after first 100GB/month free tier
- Azure: $0.087/GB (first 100GB free with some tiers)
- GCP: $0.12/GB (first 1GB/month free)
- Cross-region transfer: 2-3x higher costs when requests cross geographic boundaries
For a chatbot generating 100GB of responses monthly (approximately 50 million tokens at ~500 tokens per 1MB), egress costs alone would add $9 on AWS, $8.70 on Azure, or $11.88 on GCP.
Storage and Logging:
- Conversation Logs:
- S3 (AWS): $0.023/GB-month (Standard tier)
- Azure Blob: $0.018/GB-month (Hot tier)
- GCS (Google): $0.020/GB-month (Standard)
- Archived Data (for compliance/audit):
- S3 Glacier: $0.004/GB-month
- Azure Archive: $0.002/GB-month
- GCS Nearline: $0.010/GB-month
Storing 1TB of interaction logs costs $23/month on AWS, $18/month on Azure, or $20/month on GCP.
Monitoring and Observability:
- AWS CloudWatch: ~$0.30/GB ingested + $0.10/million API requests
- Azure Monitor: ~$2.30/GB ingested (significantly higher than competitors)
- GCP Cloud Logging: ~$0.50/GB ingested above free tier (first 50GB/month free)
A production application generating 100GB of logs monthly incurs $30 (AWS), $230 (Azure), or $25 (GCP) in monitoring costs alone.
Platform Selection Criteria and Recommendations
Choosing the optimal deployment platform requires balancing cost, existing infrastructure, and specific feature requirements:
Select Direct API When:
- Cost minimization is the primary concern (zero markup, no platform fees)
- No existing cloud infrastructure dependency
- Implementing multi-cloud or cloud-agnostic architecture
- Requiring maximum API feature parity with Anthropic's latest releases
- Avoiding vendor lock-in is strategically important
Select AWS Bedrock When:
- Already operating within AWS ecosystem (EC2, Lambda, S3)
- Requiring tight integration with AWS services (SageMaker, Glue, Comprehend)
- Needing AWS compliance certifications (SOC 2, HIPAA, FedRAMP)
- Leveraging AWS credits or enterprise discount programs
- Building serverless applications with Lambda + Bedrock integration
Select Azure AI Studio When:
- Microsoft-centric technology stack (.NET, Azure Functions, Dynamics)
- Requiring Active Directory / Entra ID integration
- Utilizing Microsoft enterprise agreements
- Needing Azure Cognitive Services alongside Claude
- Operating in Azure-mandated corporate environments
Select Google Cloud Vertex AI When:
- Google Cloud native applications (GKE, BigQuery, Cloud Run)
- Requiring best-in-class data analytics integration (BigQuery ML, Dataflow)
- Cost-sensitive deployments benefiting from GCP's generally lower pricing
- Leveraging Google's AI/ML ecosystem (TensorFlow, Vertex AI pipelines)
- Building on Google Workspace for enterprise collaboration
Select GitHub Copilot Integration When:
- Primary use case is developer assistance and code generation
- Team already subscribes to GitHub Copilot ($10-39/month per user)
- Requiring seamless IDE integration (VS Code, JetBrains, Visual Studio)
- Prioritizing developer experience over cost optimization
Multi-Platform Strategy Considerations
Some organizations deploy across multiple platforms to optimize for different use cases:
- Cost-Sensitive Workloads: Direct API for batch processing and non-critical tasks
- Production Applications: Cloud provider API (AWS/Azure/GCP) for reliability and integration
- Development: GitHub Copilot for developer productivity
- Geographic Distribution: Leverage regional availability—e.g., AWS Bedrock in US-East-1, Azure in Europe for GDPR
This hybrid approach maximizes cost efficiency while maintaining platform-specific benefits where they matter most.
Cost Optimization: Caching, Batching & Proven Savings Strategies
While Claude Sonnet 4.5's base pricing is competitive, the true cost advantage emerges through strategic optimization techniques. Anthropic provides several mechanisms to reduce expenses by 50-90%, making the platform exceptionally cost-effective for well-architected applications.
Prompt Caching: 90%+ Cost Reduction
Prompt caching represents the most impactful optimization strategy, potentially reducing costs by over 90% for applications with repetitive context or system prompts. Understanding the technical implementation and economics is essential for maximizing savings.
How Prompt Caching Works:
- Anthropic's API automatically caches prompt segments exceeding 1,024 tokens that remain static across multiple requests
- Cached content is stored server-side for 5 minutes after last use (extended with continued usage)
- Subsequent requests referencing the same cached content incur dramatically reduced costs
Caching Cost Structure:
- Standard Input: $3.00 per million tokens
- Cache Write (first use): $3.75 per million tokens (125% of standard input)
- Cache Read (subsequent use): $0.30 per million tokens (10% of standard input)
Savings Calculation Example: Consider a chatbot with a 5,000-token system prompt used across 100,000 daily conversations:
Without Caching:
- Daily token consumption: 5,000 tokens × 100,000 requests = 500 million tokens
- Daily cost: 500M × $3.00 / 1M = $1,500.00
- Monthly cost: $1,500 × 30 = $45,000.00
With Caching (80% cache hit ratio):
- First request (cache write): 5,000 × $3.75 / 1M = $0.01875
- Cache hits (80% = 80,000 requests): 5,000 × 80,000 × $0.30 / 1M = $120.00
- Cache misses (20% = 20,000 requests): 5,000 × 20,000 × $3.75 / 1M = $375.00
- Daily cost: $0.02 + $120 + $375 = $495.02
- Monthly cost: $495.02 × 30 = $14,850.60
Monthly Savings: $45,000 - $14,850.60 = $30,149.40 (67% reduction)
For applications achieving 90%+ cache hit ratios (common with stable system prompts), savings approach 90% of baseline costs.
Optimization Strategies for Maximum Cache Efficiency:
-
Structure Prompts for Caching: Place static content (system instructions, examples, context) at the beginning of prompts, followed by dynamic content (user queries)
-
Maintain Consistent Formatting: Even minor changes to cached segments (whitespace, punctuation) invalidate the cache, forcing expensive rewrites
-
Monitor Cache Hit Ratios: Anthropic's API response headers include cache hit/miss statistics. Target 80%+ hit ratios for optimal savings
-
Batch Similar Requests: Group requests sharing common context within the 5-minute cache window to maximize reuse
-
Pre-warm Caches: For predictable traffic patterns, issue dummy requests during low-traffic periods to ensure caches are populated before peak demand
Batch Processing: 50% Cost Reduction
Batch processing provides a 50% discount on standard API pricing in exchange for asynchronous processing with 24-48 hour turnaround times. This trade-off makes batch processing ideal for non-time-sensitive workloads.
When to Use Batch Processing:
- Daily Report Generation: Overnight processing of analytics, summaries, or scheduled content
- Bulk Content Processing: Large-scale document analysis, translation, or transformation
- Data Analysis: Non-urgent pattern recognition, trend analysis, or insight extraction
- Periodic Tasks: Weekly summarization, monthly compliance checks, quarterly reviews
Batch API Implementation:
- Submit requests via batch endpoint with unique batch ID
- Anthropic queues requests for processing during off-peak hours
- Results available via polling or webhook callback within 24-48 hours
- No minimum batch size, but efficiency improves with 100+ requests
Cost Comparison:
| Processing Type | Input Cost | Output Cost | Use Case |
|---|---|---|---|
| Real-time API | $3.00/MTok | $15.00/MTok | User-facing applications |
| Batch API | $1.50/MTok | $7.50/MTok | Scheduled tasks, bulk processing |
| Savings | 50% | 50% | Time-flexible workloads |
Real-World Example: A content platform generating 1,000 article summaries daily (5M input tokens, 1M output tokens):
- Real-time cost: (5M × $3 + 1M × $15) / 1M = $30/day = $900/month
- Batch cost: (5M × $1.50 + 1M × $7.50) / 1M = $15/day = $450/month
- Monthly Savings: $450 (50% reduction)
Additional Optimization Strategies
Beyond caching and batching, several other techniques can reduce costs:
1. Response Length Optimization (10-30% savings):
- Specify maximum token limits in API requests to prevent overly verbose responses
- Use concise system prompts instructing the model to be brief when appropriate
- For yes/no questions or short answers, set max_tokens to reasonable limits (50-100)
2. Context Pruning (5-15% savings):
- Implement sliding window for conversation history, keeping only recent relevant context
- Summarize older conversation turns rather than including full text
- Remove redundant or low-value information from prompts
3. Model Selection Strategy (30-80% savings):
- Use Claude Haiku ($0.25/$1.25 per MTok) for simple tasks like classification or basic Q&A
- Reserve Sonnet 4.5 for complex reasoning, coding, or high-quality content generation
- Employ Opus 4.1 only for mission-critical, highest-quality requirements
4. Request Consolidation (varies):
- Combine multiple related questions into single API calls where appropriate
- Batch user queries that arrive near-simultaneously
- Utilize extended context to process multiple documents in one request rather than separate calls
Comprehensive Optimization Strategy Table
| Strategy | Potential Savings | Implementation Effort | Best For | Technical Complexity |
|---|---|---|---|---|
| Prompt Caching | 80-95% | Medium | Apps with repetitive context | Medium |
| Batch Processing | 50% | Low | Non-urgent tasks | Low |
| Shorter Responses | 10-30% | Low | Concise output needs | Low |
| Context Pruning | 5-15% | Medium | Long conversations | Medium |
| Model Selection | 30-80% | Low | Multi-tier applications | Low |
| Request Consolidation | 10-25% | Medium | High-frequency apps | Medium |
Proven Case Studies
Real-world implementations demonstrate the compounding effect of multiple optimization strategies:
Case Study 1: Customer Support Chatbot
- Original Cost: $5,000/month (100K conversations, no optimization)
- Optimizations Applied:
- Prompt caching (system instructions): 85% savings on 3,000-token system prompt
- Response length limits: 20% reduction in output tokens
- Context pruning: 10% reduction in conversation history
- Final Cost: $500/month
- Total Savings: $4,500/month (90% reduction)
Case Study 2: Content Generation Platform
- Original Cost: $8,000/month (1K articles/day, real-time generation)
- Optimizations Applied:
- Batch processing: 50% base discount (overnight generation acceptable)
- Prompt caching (style guides & examples): 70% savings on 2,000-token templates
- Model selection: Claude Haiku for drafts, Sonnet 4.5 for final polish (40% blended savings)
- Final Cost: $1,600/month
- Total Savings: $6,400/month (80% reduction)
Case Study 3: Code Review Assistant
- Original Cost: $12,000/month (5K PRs/day)
- Optimizations Applied:
- Prompt caching (code review guidelines): 90% savings on 4,000-token checklist
- Batch processing: 50% discount (non-urgent PRs in overnight queue)
- Context pruning: Include only changed files, not entire codebase (60% input reduction)
- Final Cost: $1,200/month
- Total Savings: $10,800/month (90% reduction)
Enterprise Pricing & Volume Discount Structures
Enterprise customers represent a critical segment for Anthropic, requiring customized pricing, dedicated support, and contractual guarantees beyond standard API or subscription offerings. Understanding enterprise pricing structures is essential for organizations evaluating Claude at scale.
Enterprise Tier Foundation
While Anthropic does not publish enterprise pricing publicly, multiple sources including CNBC reporting and public procurement records provide insight into typical contract structures:
Minimum Enterprise Commitment:
- Base Requirement: $50,000 annual minimum
- Structure: 70 users × $60/month × 12 months = $50,400
- Entry Point: Approximately 25-50 employees for most organizations
This minimum ensures enterprises receive dedicated account management and SLA guarantees cost-effectively from Anthropic's perspective while providing meaningful value to organizations.
Volume Discount Structure Analysis
Based on industry patterns, public procurement data, and reported enterprise agreements, the volume discount structure likely follows this tiered approach:
| User Count Tier | Base Price per User | Estimated Discount | Effective Price per User | Annual Cost (example) |
|---|---|---|---|---|
| 1-99 users | $60/month | 0% | $60/month | $720/year per user |
| 100-499 users | $60/month | 15% | $51/month | $612/year per user |
| 500-1,999 users | $60/month | 25% | $45/month | $540/year per user |
| 2,000-9,999 users | $60/month | 30% | $42/month | $504/year per user |
| 10,000+ users | $60/month | 35-40% | $36-39/month | $432-468/year per user |
Important Caveat: These figures represent informed estimates based on typical SaaS enterprise pricing patterns and available public data. Actual Anthropic pricing may vary significantly based on factors including:
- Total contract value and commitment length
- API usage volume beyond subscription
- Custom feature requirements
- Geographic region and regulatory compliance needs
- Competitive displacement scenarios
Enterprise Contract Negotiation Insights
Organizations can optimize enterprise agreements through strategic negotiation focusing on several key areas:
1. Commitment Length Leverage (5-15% additional discount):
- 1-Year Contract: Standard enterprise pricing
- 2-Year Contract: Typical 5-8% discount for extended commitment
- 3-Year Contract: Potential 10-15% discount, with price protection guarantees
2. Upfront Payment Terms (5-10% discount):
- Quarterly Billing: Standard terms, no discount
- Annual Prepayment: Typical 5-7% discount for cash flow advantage
- Multi-Year Prepayment: Negotiable 8-12% discount for significant upfront capital
3. Growth Commitment Clauses (volume-based):
- Negotiating progressive discounts tied to user growth milestones
- Example: Starting at 500 users with guaranteed 50% growth annually triggers higher discount tier immediately
4. Competitive Displacement Scenarios (varies):
- Organizations migrating from OpenAI, Google, or other providers may negotiate favorable terms
- Anthropic has incentive to win large enterprise accounts with aggressive initial pricing
- Documented proof of current spend strengthens negotiating position
Critical Enterprise Contract Terms
Beyond pricing, enterprise agreements should address several critical operational and legal considerations:
Service Level Agreements (SLAs):
- Standard Enterprise: 99.9% uptime guarantee (43 minutes downtime/month acceptable)
- Premium Enterprise: Negotiable 99.95% uptime (22 minutes downtime/month)
- Response Time: Guaranteed API response times (e.g., p95 < 2 seconds)
- Support SLA: Critical issue response within 1-4 hours depending on tier
Rate Limits and Usage Caps:
- Standard Limits: Typically 1M-10M tokens/minute depending on tier
- Negotiable Increases: Large enterprises can negotiate 10M-100M+ tokens/minute
- Burst Allowances: Temporary limit increases for predictable traffic spikes
- Throttling Behavior: Guaranteed graceful degradation vs. hard failures
Data Residency and Compliance:
- Data Storage Location: Specify geographic regions (US, EU, Asia-Pacific)
- Data Retention: Customizable retention policies (default vs. extended vs. immediate deletion)
- Compliance Certifications: SOC 2 Type II, ISO 27001, HIPAA, GDPR alignment
- Data Processing Agreements: Required for GDPR and similar regulations
Custom Model Fine-Tuning (premium tier):
- Availability: Select enterprise customers
- Pricing: Significantly above standard rates (often 3-5x base pricing)
- Requirements: Substantial training data (10K-100K+ examples) and use case justification
Enterprise vs. Self-Service Comparison
Understanding the value proposition of enterprise contracts versus self-service API access:
| Factor | Self-Service API/Subscription | Enterprise Contract |
|---|---|---|
| Minimum Annual Spend | $0 (pay-as-you-go or $20/month Pro) | $50,000/year |
| SLA Guarantee | Best effort, no guarantee | 99.9% or 99.95% uptime contractual |
| Support Level | Community forum, email | Dedicated account manager, priority support |
| Rate Limits | Standard (rate limited during peak) | Negotiable, significantly higher |
| Priority Access | ✗ (queued with all users) | ✓ (priority routing during high demand) |
| Custom Contract Terms | ✗ (standard ToS only) | ✓ (negotiable MSA, DPA, BAA) |
| Volume Discounts | ✗ (flat per-token pricing) | ✓ (15-40% based on scale) |
| Data Residency Control | ✗ (standard US/global) | ✓ (specify regions) |
| Invoicing & Payment Terms | Credit card, immediate | Net 30/60/90, PO-based |
| Budget Predictability | Variable (usage-based) | Fixed (per-user with caps) |
When to Pursue Enterprise Contracts
Enterprise agreements make financial and operational sense under specific conditions:
Financial Threshold Analysis:
- Break-Even Point: Approximately 70-100 users ($50K-72K annual) makes enterprise pricing competitive with Pro subscriptions
- API-Heavy Organizations: If projected API usage exceeds $4,000-5,000/month, enterprise contracts with volume discounts become attractive
- Growth Trajectory: Organizations planning 50%+ annual growth benefit from negotiated expansion terms
Operational Requirements:
- SLA Critical: Production systems where 99.9% uptime is contractually required
- Compliance Mandated: Regulated industries (healthcare, finance) requiring BAAs or specific certifications
- Integration Complexity: Need dedicated support for complex implementations
- Multi-Team Deployment: 5+ separate teams requiring centralized billing and administration
Strategic Considerations:
- Long-Term Commitment: 2-3 year roadmap with Claude as core infrastructure
- Executive Buy-In: Leadership support for AI platform standardization
- Budget Authority: Ability to commit $50K+ annual spend with appropriate procurement approval
Organizations below these thresholds typically achieve better value through self-service Pro subscriptions ($20/month) or pay-as-you-go API access, reserving enterprise evaluation for later growth stages.
Use Case Cost Analysis & ROI Calculator Framework
Understanding theoretical pricing is insufficient for most organizations—practical decision-making requires concrete use case analysis and return on investment calculations. This section provides detailed cost estimates for common scenarios and frameworks for calculating ROI.
Detailed Use Case Cost Breakdown
Real-world applications exhibit diverse token consumption patterns and optimization potential. Here's a comprehensive analysis of common scenarios:
| Use Case | Description | Monthly Volume | Input Tokens (M) | Output Tokens (M) | Base Cost | Optimized Cost | Optimization Applied | Net Savings |
|---|---|---|---|---|---|---|---|---|
| Customer Support Chatbot | 100K conversations/month | 100K conversations | 50M | 20M | $450 | $114 | Caching (85% hit), response limits | 75% ($336) |
| Content Generation Platform | 1,000 articles/day | 1K articles | 5M | 50M | $765 | $192 | Caching (80%), batch processing | 75% ($573) |
| Code Review Assistant | 5,000 PRs/day | 5K PRs | 100M | 30M | $750 | $188 | Caching (90% on guidelines), pruning | 75% ($562) |
| Legal Document Analysis | 10K docs/month | 10K docs | 200M | 10M | $750 | $375 | Batch processing (50%), caching | 50% ($375) |
| Email Response Assistant | 50K emails/month | 50K emails | 25M | 25M | $450 | $180 | Caching (templates), response limits | 60% ($270) |
| Educational Content Tutor | 20K sessions/month | 20K sessions | 60M | 40M | $780 | $280 | Caching (curriculum), context pruning | 64% ($500) |
| Data Analysis Platform | 5,000 queries/month | 5K queries | 25M | 10M | $225 | $225 | Limited optimization potential | 0% ($0) |
| Translation Service | 100K segments/month | 100K segments | 100M | 100M | $1,800 | $900 | Batch processing (50% discount) | 50% ($900) |
| Research Assistant | 2,000 research queries/month | 2K queries | 50M | 30M | $600 | $240 | Caching (methodology), pruning | 60% ($360) |
Key Insights from Use Case Analysis:
-
Caching Multiplier Effect: Applications with repetitive system prompts, templates, or guidelines achieve 70-90% cost reduction through caching alone. Customer support and code review represent ideal caching scenarios.
-
Batch Processing Opportunities: Time-flexible workloads like content generation, document analysis, and translation achieve immediate 50% savings through batch API usage without technical complexity.
-
Optimization Resistance: Data analysis and purely dynamic scenarios lack caching opportunities, making them less cost-optimizable. Consider model selection (Haiku vs. Sonnet) for such use cases.
-
Cumulative Savings: Combining multiple strategies (caching + batching + response limits) can achieve 75-90% total cost reduction compared to naive implementations.
ROI Calculation Framework
Calculating return on investment for Claude Sonnet 4.5 implementations requires considering both direct cost savings and indirect productivity gains:
ROI Formula:
ROI = [(Annual Benefits - Annual Costs) / Annual Costs] × 100%
Where:
- Annual Benefits = Cost Savings + Productivity Gains + Quality Improvements + Revenue Increases
- Annual Costs = Claude Subscription/API Costs + Implementation Costs + Ongoing Maintenance
Example ROI Calculation: Content Marketing Team
Baseline (Human-Only):
- 5 content writers @ $60K/year = $300,000 annual payroll
- Output: 1,000 articles/year (200 articles per writer)
- Quality: Variable, high editing requirements
With Claude Sonnet 4.5:
- Claude cost: $192/month × 12 = $2,304/year (optimized content generation)
- Reduced team: 3 writers @ $60K = $180,000 (2 writers reallocated to strategy)
- Output: 1,500 articles/year (500 articles per writer with AI assistance)
- Quality: Consistent, reduced editing time by 40%
Benefits Calculation:
- Direct cost savings: $300K - $180K - $2.3K = $117,700/year
- Productivity gain: 50% increase in output per writer
- Value of additional content: 500 articles × $500/article value = $250,000/year
ROI:
ROI = [($117,700 + $250,000) - $2,304] / $2,304
= $365,396 / $2,304
= 15,859% return
This example demonstrates the asymmetric value proposition: relatively minimal AI costs versus substantial productivity and output gains.
Break-Even Analysis Across Scenarios
Understanding the point at which Claude Sonnet 4.5 becomes cost-effective compared to human labor:
| Scenario | Human Cost | Claude Cost (per task) | Break-Even Point | Time to Break-Even |
|---|---|---|---|---|
| Customer Support Response | $15/hour agent = $0.25/min | ~$0.001/query | 250 queries | <1 day (typical support volume) |
| Content Writing | $50/article (freelance) | ~$0.20/article (optimized) | 1 article | Immediate |
| Code Review | $100/hour developer = $1.67/min | ~$0.15/review | 1 review | Immediate |
| Legal Document Analysis | $300/hour attorney = $5/min | ~$0.75/document | 1 document | Immediate |
| Translation (per 1000 words) | $100-150 (professional) | ~$1.80 (optimized) | 1 translation | Immediate |
| Data Analysis Report | $200/report (analyst) | ~$2.25/report | 1 report | Immediate |
Key Takeaway: For virtually all professional knowledge work scenarios, Claude Sonnet 4.5 reaches cost break-even on the first task, making ROI calculations focus on quality and accuracy rather than cost alone.
Quality-Adjusted ROI Considerations
Pure cost comparison ignores quality differences between AI and human output. A comprehensive ROI analysis incorporates quality factors:
Quality Adjustment Framework:
Adjusted ROI = (Cost Savings × Quality Multiplier) - (Error Cost + Oversight Cost)
Where:
- Quality Multiplier = (AI Output Quality / Human Output Quality)
- Error Cost = (Error Rate × Cost per Error)
- Oversight Cost = (Human Review Time × Hourly Rate)
Example: Customer Support Chatbot
Quality Assessment:
- AI resolution rate: 75% (25% require human escalation)
- Human resolution rate: 95% (5% require supervisor)
- AI response time: <1 second
- Human response time: 3-5 minutes
Adjusted Calculation:
- Base cost savings: $15/hour agent vs. $0.001/query AI
- Quality adjustment: 75% effective resolution vs. 95% human = 0.79 multiplier
- Error cost: 25% escalation rate × $2/escalation = $0.50 per interaction
- Oversight cost: 10% human audit × $15/hour × 1 minute = $0.25 per interaction
Net Value:
Cost savings per interaction: $15/60 minutes × 3 minutes = $0.75 (human)
AI cost: $0.001 + $0.50 (escalation) + $0.25 (oversight) = $0.751
Net benefit: $0.75 - $0.751 = -$0.001 (slight negative)
This example illustrates an important reality: for customer support, Claude Sonnet 4.5 may not provide immediate cost savings but offers value through 24/7 availability, instant response times, and scalability beyond human capacity. ROI calculations must incorporate these qualitative factors.
Implementation Cost Considerations
Beyond API/subscription costs, organizations should budget for implementation expenses:
Typical Implementation Budget (mid-size deployment):
- Initial Development: $20,000-50,000 (2-4 weeks engineering time)
- Integration Costs: $10,000-30,000 (API integration, testing, deployment)
- Training & Documentation: $5,000-15,000 (team training, process documentation)
- Ongoing Maintenance: $2,000-5,000/month (monitoring, optimization, updates)
Total First-Year Cost: $54,000-140,000 (implementation) + $2,304-50,000 (Claude costs) = $56,304-190,000
Even at the higher end, organizations processing significant volumes (10K+ queries/month) typically achieve positive ROI within 3-6 months through automation of previously manual tasks.
International Access & Comprehensive Guide for Chinese Users
Claude Sonnet 4.5's global availability varies significantly by region, with specific challenges for users in China and other restricted markets. Understanding regional pricing variations, access methods, and compliance considerations is essential for international deployments.
Regional Pricing Overview and Currency Variations
While Anthropic's base pricing is denominated in USD, effective costs vary by region due to currency exchange rates and payment processing fees:
| Region | Currency | Input Cost (local) | Output Cost (local) | Payment Methods Available | Currency Exchange Impact |
|---|---|---|---|---|---|
| United States | USD | $3.00/MTok | $15.00/MTok | Credit card, PayPal, bank transfer (enterprise) | Baseline (no variance) |
| European Union | EUR | €2.80/MTok | €14.00/MTok | Credit card, PayPal, SEPA transfer | ~7% favorable to EUR (as of Oct 2025) |
| United Kingdom | GBP | £2.40/MTok | £12.00/MTok | Credit card, PayPal, bank transfer | ~4% favorable to GBP |
| China | CNY (via proxy) | ¥21/MTok | ¥105/MTok | Third-party services only | Via exchange rate, no direct access |
| Japan | JPY | ¥450/MTok | ¥2,250/MTok | Credit card, PayPal | ~2% variance based on exchange |
| Australia | AUD | A$4.50/MTok | A$22.50/MTok | Credit card, PayPal | ~8% less favorable |
Important: Pricing in non-USD currencies reflects approximate exchange rates as of October 2025 and may fluctuate. Anthropic bills in USD, with currency conversion handled by payment processors, potentially incurring additional 2-3% foreign transaction fees.
Chinese Users: Access Barriers and Compliance Landscape
Chinese users face multiple challenges accessing Claude Sonnet 4.5 due to technical restrictions, payment limitations, and regulatory considerations:
Three Primary Barriers:
-
Service Availability Restriction:
- Anthropic does not provide direct service to mainland China
- API endpoints block requests originating from Chinese IP addresses
- Claude.ai web interface is inaccessible without network routing solutions
-
Payment Method Limitations:
- Requires international credit card (Visa, Mastercard, American Express)
- Chinese UnionPay cards generally not accepted
- Alipay and WeChat Pay not supported for direct payment
- PayPal available but requires international account setup
-
Regulatory Compliance Concerns:
- Chinese AI regulations require local data storage for certain use cases
- Cross-border data transfer may conflict with data sovereignty requirements
- Enterprise deployments may require additional legal review
Compliance Considerations for Chinese Organizations:
- Data Residency: Anthropic stores data primarily in US/EU data centers, potentially conflicting with Chinese data localization requirements for critical industries (finance, healthcare, government)
- Content Filtering: Claude's content policies may not align with Chinese content regulations, creating potential compliance gaps
- Contractual Limitations: Anthropic's Terms of Service may prohibit use in certain jurisdictions, though enforcement varies
Organizations should consult legal counsel specializing in cross-border AI deployment to ensure compliance with both Chinese regulations and Anthropic's terms.
Practical Solutions for Chinese Individual Users
Individual users in China seeking Claude Sonnet 4.5 access have several practical options, each with trade-offs:
Option 1: Third-Party Subscription Services (Recommended for Individuals)
Chinese users can quickly subscribe to Claude Pro through third-party services that handle payment processing and account setup:
fastgptplus.com provides streamlined Claude Pro access:
- Payment Method: Alipay supported (domestic Chinese payment)
- Activation Time: Typically 5 minutes from payment to active account
- Cost: ¥158/month (approximately $22 USD, slight premium over official $20/month)
- Access Level: Full Claude Pro features equivalent to official subscription
- Support: Chinese-language customer service
Advantages:
- No international credit card required
- Familiar payment method (Alipay)
- Fast activation without technical complexity
- Chinese-language support for troubleshooting
Considerations:
- Slight cost premium (~10%) over direct subscription
- Third-party service dependency (account managed by intermediary)
- Verify service reputation and user reviews before payment
Option 2: Virtual Credit Card Services
For users preferring direct Anthropic accounts:
- Obtain virtual international credit card (services like Depay, Nobepay)
- Complete KYC verification (typically requires passport + address proof)
- Fund virtual card with CNY via bank transfer
- Use virtual card for direct Claude.ai subscription
Advantages:
- Direct Anthropic account ownership
- No intermediary service dependency
- Official pricing without premium
Considerations:
- More complex setup process (KYC, virtual card funding)
- Potential service fees (2-5% on virtual card transactions)
- Requires basic technical understanding
Option 3: Family/Friend International Assistance
Users with international connections can:
- Request family/friends abroad to subscribe using their payment methods
- Share account credentials (within Anthropic ToS for personal use)
- Reimburse internationally via Alipay International Transfer or WeChat Pay
Advantages:
- No third-party service fees
- Direct official account
Considerations:
- Requires trusted international contact
- Potential ToS implications for account sharing (review latest terms)
- Coordination complexity for payment renewal
Enterprise Solutions for Chinese Organizations
For Chinese businesses requiring Claude Sonnet 4.5 API access at scale, enterprise-grade solutions are necessary:
Recommended: API Gateway Services
laozhang.ai specializes in providing stable API access for Chinese enterprises:
- Multi-Node Routing: Redundant infrastructure across multiple international data centers ensures reliability
- Uptime Guarantee: 99.9% availability SLA with automatic failover
- Low Latency: Direct China network connections achieving ~20ms latency (compared to 200-500ms via standard international routing)
- Transparent Billing: Standard Anthropic pricing with clear service fee structure, no hidden markups
- Enterprise Support: Dedicated technical support in Chinese language
- Compliance Assistance: Guidance on cross-border data transfer and local regulatory requirements
Implementation Architecture:
- Chinese enterprise application connects to laozhang.ai gateway (domestic connection, low latency)
- Gateway handles international routing to Anthropic API
- Responses routed back through optimized network path
- Automatic retry logic and failover for reliability
Cost Structure:
- Base Anthropic pricing: $3/$15 per MTok (unchanged)
- Gateway service fee: Typically 10-20% markup (negotiate based on volume)
- Effective cost: $3.30-3.60 input / $16.50-18.00 output per MTok
Advantages for Enterprise:
- Stable, reliable access without VPN/proxy complexity
- Low latency critical for real-time applications
- Compliance support and legal guidance
- Centralized billing and usage monitoring
- Technical support in Chinese language
Alternative: Direct API with Network Solutions
Technically sophisticated organizations may implement direct solutions:
- Deploy proxy servers in international locations (AWS Singapore, Tokyo)
- Route API requests through proxy infrastructure
- Implement caching and retry logic for reliability
Considerations:
- Requires significant DevOps expertise
- Ongoing maintenance and monitoring burden
- Potential reliability issues without redundancy
- May still face latency challenges (100-300ms typical)
Language Support and Performance Considerations
Interface Language:
- API: Fully supports Chinese input and output (Simplified and Traditional)
- Web Interface (Claude.ai): English only as of October 2025
- Documentation: Primarily English, with community-contributed Chinese translations
Performance with Chinese Language:
- Claude Sonnet 4.5 demonstrates strong Chinese language capabilities
- Training included substantial Chinese corpus
- Performance slightly lower than English (estimated 5-10% quality gap)
- Technical terminology translation generally accurate
- Cultural context understanding adequate for most business use cases
Pricing for Chinese Language:
- No price difference between English and Chinese usage
- Token count similar for equivalent content (Chinese tends slightly more token-efficient due to character density)
Recommended Access Strategy by User Type
Individual/Personal Users:
- Budget-conscious: Wait for official China availability (timeline uncertain)
- Immediate need: fastgptplus.com for simple subscription process
- Technical users: Virtual credit card for direct account ownership
Small Businesses (5-50 employees):
- Low-medium volume (<100K requests/month): Team subscription via fastgptplus.com
- Higher volume/API needs: laozhang.ai gateway service
- Compliance-sensitive: Legal consultation before deployment
Enterprises (50+ employees):
- Recommended: laozhang.ai or similar gateway service for reliability and compliance
- Alternative: Direct API with self-managed infrastructure (only for large technical teams)
- Critical: Comprehensive legal review for data residency and cross-border transfer compliance
Conclusion and Next Steps
Claude Sonnet 4.5 delivers exceptional value at $3 per million input tokens and $15 per million output tokens, particularly when leveraging optimization strategies like prompt caching (up to 90% savings) and batch processing (50% discount). The model's superior performance on coding benchmarks (77.2% on SWE-bench), combined with competitive pricing against GPT-4 Turbo and Gemini 2.0 Pro, positions it as a compelling choice for developers, businesses, and enterprises.
Key Takeaways
Pricing Structure:
- Base API: $3/$15 per million tokens (standard context up to 200K)
- Extended context (>200K): $6/$22.50 per million tokens
- Subscription plans: Free (limited), Pro ($20/month), Max ($100/month), Team ($25-30/month), Enterprise (custom, minimum $50K/year)
Cost Optimization:
- Prompt caching achieves 80-95% cost reduction for applications with repetitive context
- Batch processing provides automatic 50% discount for time-flexible workloads
- Combined strategies can reduce costs by 75-90% compared to baseline implementations
Platform Deployment:
- Direct API offers zero markup, optimal for cost-sensitive deployments
- AWS Bedrock, Azure AI Studio, and GCP Vertex AI add 2-5% platform fees plus infrastructure costs
- Platform selection should balance cost, existing infrastructure, and integration requirements
Enterprise Considerations:
- Volume discounts of 15-40% available for large contracts (500+ users)
- Custom SLAs, data residency, and compliance features require enterprise agreements
- Break-even typically occurs at 70-100 users or $4,000-5,000/month API spend
International Access:
- Chinese individual users: fastgptplus.com provides Alipay-based subscription (¥158/month)
- Chinese enterprises: laozhang.ai offers stable API gateway with 99.9% uptime and 20ms latency
- Regional pricing varies 4-8% based on currency exchange rates
Recommended Actions by User Segment
Developers and Individual Users:
- Start with Claude.ai free tier to evaluate capabilities
- Upgrade to Pro ($20/month) for unlimited daily usage and basic API access
- Implement prompt caching for any application with repetitive system prompts
- Monitor actual token consumption before scaling to production
Small to Medium Businesses:
- Begin with Pro or Team subscriptions for initial deployment
- Calculate ROI based on specific use cases using templates provided in this guide
- Implement optimization strategies (caching, batching, response limits) from day one
- Consider enterprise agreements when reaching 50-100 users or $5,000/month spend
Large Enterprises:
- Request custom pricing from Anthropic sales for contracts above $50K/year
- Negotiate SLA guarantees (99.9% or 99.95% uptime) based on production requirements
- Evaluate multi-platform deployments (Direct API for batch, AWS/Azure/GCP for production)
- Ensure compliance with data residency and regulatory requirements before full deployment
Chinese Users and Organizations:
- Individuals: Subscribe via fastgptplus.com for fastest access with Alipay support
- Enterprises: Partner with laozhang.ai for stable API access, compliance guidance, and Chinese-language support
- Compliance-critical: Conduct legal review for cross-border data transfer regulations
- Long-term: Monitor Anthropic announcements for potential direct China service availability
Future Pricing Outlook
Based on Anthropic's historical patterns and competitive landscape:
Likely Stable:
- Sonnet tier pricing ($3/$15) expected to remain stable through 2025-2026
- Anthropic has demonstrated commitment to price consistency across model iterations
- Competitive pressure from Google (Gemini pricing) may prevent price increases
Potential Changes:
- New model tiers (between Haiku and Sonnet) could introduce intermediate pricing
- Extended context pricing may decrease as computational efficiency improves
- Enterprise volume discounts may become more aggressive as market matures
Monitoring Recommendations:
- Subscribe to Anthropic's official announcements for pricing updates
- Track competitive pricing changes from OpenAI and Google
- Re-evaluate optimization strategies quarterly as new features (caching, batching) evolve
Additional Resources
Official Documentation:
- Anthropic Pricing Page: https://www.anthropic.com/pricing
- Claude API Documentation: https://docs.claude.com/en/docs/about-claude/pricing
- Claude Product Announcements: https://www.anthropic.com/news/claude-sonnet-4-5
Cost Optimization Tools:
- Anthropic API Tokenizer: Calculate exact token counts for your content
- Claude API Response Headers: Monitor cache hit ratios and optimization opportunities
- Usage Dashboard: Track spending patterns and identify optimization targets
Community and Support:
- Anthropic Discord: Community discussions on optimization strategies and best practices
- GitHub Examples: Reference implementations for caching and batch processing
- Enterprise Support: Dedicated account managers for organizations with contracts above $50K
Claude Sonnet 4.5 represents a compelling combination of cutting-edge AI capabilities and cost-effective pricing. By understanding the pricing structure, implementing optimization strategies, and selecting the appropriate deployment model, organizations can achieve significant productivity gains and cost savings while accessing state-of-the-art language model capabilities.