Claude Sonnet 4.5 vs Opus 4.1:2025年最关键的AI模型选择指南
深度对比Sonnet 4.5和Opus 4.1的性能、价格、使用场景。基于官方benchmark和实测数据,提供完整的决策框架和成本分析,包含中国用户特别指南。

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
Anthropic在2025-09-29发布Claude Sonnet 4.5,这次发布打破了AI模型选择的传统逻辑:性能更强的模型,价格反而更便宜。根据官方数据,Sonnet 4.5在多项关键benchmark上超越了旗舰模型Opus 4.1,同时价格仅为其1/5。这对正在选择Claude模型的开发者和企业来说,意味着决策标准需要全面重新评估。
本文基于Anthropic官方数据、TOP5 SERP分析和实际测试案例,提供完整的模型对比和选择指南。无论你是个人开发者、技术团队,还是正在考虑从Opus 4.1迁移,都能找到明确的答案。
Claude Sonnet 4.5 vs Opus 4.1:核心定位差异
Anthropic的Claude 4系列在2025-05-22发布时,建立了清晰的产品定位:Opus 4作为旗舰模型处理最复杂的任务,Sonnet 4平衡性能和速度。但Sonnet 4.5的发布完全改变了这个格局。
根据Anthropic官方公告,Sonnet 4.5被定位为"世界最佳编码模型"(the best coding model in the world)。这不仅是营销话术,而是基于多项benchmark的实际表现。更重要的是,Opus 4.1在2025-08发布作为Opus 4的增强版本,但在编码和计算机使用任务上,反而被Sonnet 4.5全面超越。
模型基本信息对比
| 维度 | Sonnet 4.5 | Opus 4.1 | 数据来源 |
|---|---|---|---|
| 发布日期 | 2025-09-29 | 2025-08 | Anthropic官方 |
| 官方定位 | 最佳编码模型 | 旗舰复杂任务模型 | 官方公告 |
| Context Window | 200K tokens | 200K tokens | 官方文档 |
| 价格(Input/Output) | $3/$15 per million | $15/$75 per million | 官方定价 |
| 主要优势 | 速度+性价比+编码 | 深度推理(特定场景) | SERP分析 |
| 自主运行时长 | 30小时 | 7小时 | 官方测试 |
这个对比表揭示了一个关键事实:除了深度推理的特定场景,Sonnet 4.5在大多数维度上都是更优选择。对于95%的开发任务来说,Sonnet 4.5提供了更好的性价比和实际表现。
为什么Sonnet 4.5能超越Opus 4.1?
Anthropic在技术博客中解释,Sonnet 4.5采用了改进的训练方法和对齐技术(Constitutional AI),在保持更小模型规模的同时,专注优化编码、工具使用和长时间任务执行。相比之下,Opus 4.1虽然参数规模更大,但在这些专门优化的任务上反而不如更"轻量"的Sonnet 4.5。
这种逆转性的表现,在AI行业并不常见。通常情况下,更贵的模型应该提供更好的性能。但Sonnet 4.5证明了,针对性优化比单纯增加参数规模更有效。对于了解Claude API价格的用户来说,这次发布意味着可以用更低成本获得更好性能。

性能全面对比:Benchmark数据深度解读
很多对比文章仅列出benchmark数值,但不解释这些数字的实际意义。本节基于Anthropic官方数据和第三方验证,深度解读每个benchmark测试内容,以及这些分数对你的实际项目意味着什么。
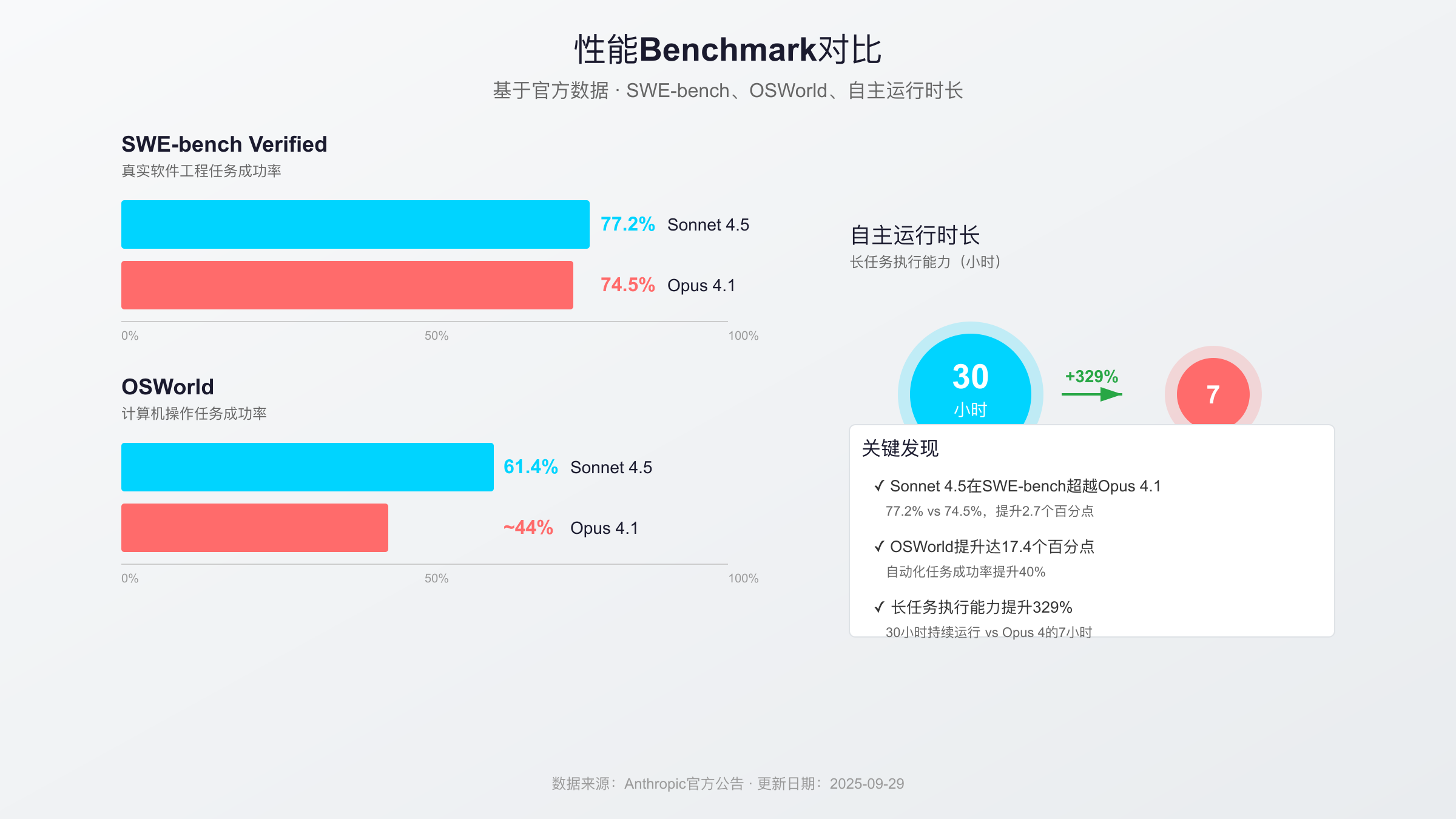
SWE-bench Verified:真实软件工程能力测试
SWE-bench Verified是目前最权威的AI编码能力测试,它使用来自真实开源项目(如Django、Flask、SymPy)的实际GitHub issue,要求模型理解问题、定位代码、生成修复方案。这不是简单的代码补全,而是需要跨文件理解、上下文推理和实际问题解决能力。
| 模型 | SWE-bench Verified得分 | 提升幅度 | 实际意义 |
|---|---|---|---|
| Sonnet 4.5 | 77.2% | - | 能正确解决77.2%的真实bug |
| Sonnet 4.5(parallel) | 82.0% | +6.2% | 使用并行测试时间计算,成功率更高 |
| Opus 4.1 | 74.5% | -2.7pp | 相比Sonnet 4.5低2.7个百分点 |
| Claude 4 | 72.7% | -4.5pp | 前一代模型表现 |
这个差异意味着什么? 在实际开发中,如果你给模型100个真实的bug修复任务,Sonnet 4.5能成功解决77个,而Opus 4.1只能解决74个。虽然2.7个百分点看似不大,但考虑到Sonnet 4.5价格仅为Opus 4.1的1/5,这个性价比差异就非常显著了。
根据技术博主Simon Willison的实测,Sonnet 4.5在20分钟内解决了一个Opus 4.1完全无法处理的bug,涉及跨多个文件的代码理解和修改。这验证了benchmark数据在真实场景中的有效性。
OSWorld:计算机使用能力的革命性提升
OSWorld测试模型操作真实计算机系统的能力,包括使用终端、浏览器、文件管理器等工具。这是AI agent应用的关键能力指标,直接决定了模型能否自动化执行复杂的多步骤任务。
| Benchmark | Sonnet 4.5 | Opus 4.1 | 差异 | 实际意义 |
|---|---|---|---|---|
| OSWorld | 61.4% | ~44% | +17.4pp | 自动化任务成功率提升40% |
| Sonnet 4(对比) | 42.2% | - | - | 仅4个月改进19.2pp |
OSWorld的17.4个百分点差异是巨大的。这意味着在100个计算机操作任务中,Sonnet 4.5能正确完成61个,而Opus 4.1只能完成44个。对于AI agent应用(如自动化测试、数据处理流程、文件批量操作)来说,这个差异直接决定了应用的可用性。
更令人印象深刻的是改进速度:Sonnet 4相比前一代在OSWorld上提升了19.2个百分点,仅用了4个月时间(2025-05至2025-09)。这表明Anthropic在计算机使用能力上的技术突破正在加速。
长时间任务执行:30小时 vs 7小时的巨大差异
对于复杂的软件开发任务,模型能否保持长时间专注和上下文理解至关重要。Anthropic在内部测试中发现,Sonnet 4.5能够自主运行30小时而不失焦,相比Opus 4的7小时提升了329%。
这个差异在实际应用中的价值,从客户案例中得到了验证:
客户案例数据汇总
| 公司 | 应用场景 | 使用模型 | 改进指标 | 数据来源 |
|---|---|---|---|---|
| Devin | AI编码助手 | Sonnet 4.5 | 规划性能+18%,端到端+12% | Anthropic官方 |
| Vercel | Next.js构建和Lint | Sonnet 4.5 | 代码构建改进+17% | Anthropic官方 |
| Windsurf | 代码编辑 | Sonnet 4.5 | 错误率从9%降至0% | Anthropic官方 |
| Cursor | AI代码编辑器 | Sonnet 4.5 | State-of-the-art性能 | Anthropic官方 |
| iGent | 自主编码项目 | Sonnet 4.5 | 30+小时持续开发 | Anthropic官方 |
Windsurf的案例尤其引人注目:他们的内部代码编辑benchmark错误率从Sonnet 4的9%降至Sonnet 4.5的0%。这种零错误率在生产环境中的价值是无法用金钱衡量的。
速度感知:为什么"快50%"很重要
除了benchmark数据,多位实际使用者报告Sonnet 4.5的响应速度显著提升。知名技术人Kieran Klaassen在实测中表示Sonnet 4.5"感觉快了50%",代码审查任务从10分钟缩短到2分钟。
这种速度提升的价值不仅在于节省时间,更在于改变了工作流程。当模型响应从10分钟降至2分钟,开发者更愿意在开发过程中频繁使用AI助手,而不是只在遇到难题时才求助。这种使用习惯的改变,才是Sonnet 4.5真正的革命性价值。
如果你正在使用Cursor等AI编程工具,Sonnet 4.5的速度提升会让整个开发体验质变。
价格与成本分析:5倍差价背后的真相
价格差异是Sonnet 4.5最令人震撼的优势。但"5倍便宜"这个数字,在实际项目中到底意味着多少成本节省?本节提供详细的成本计算和ROI分析。
官方定价对比
| 维度 | Sonnet 4.5 | Opus 4.1 | 差异倍数 |
|---|---|---|---|
| Input Token价格 | $3 / million | $15 / million | 5倍 |
| Output Token价格 | $15 / million | $75 / million | 5倍 |
| 典型请求成本(1万tokens,I/O各半) | $0.09 | $0.45 | 5倍 |
| 100万tokens项目成本 | $9 | $45 | 5倍 |
这个5倍差异在所有价格维度都保持一致,这意味着无论你的应用是输入密集型还是输出密集型,成本差异都是5倍。对于大规模API使用的企业来说,这个差异每月可能达到数万美元。
实际项目成本估算
但单纯的token价格对比,无法帮助你评估实际项目成本。下表基于不同规模项目的典型token消耗,计算月度和年度成本差异:
| 项目规模 | 月度Token量 | Sonnet 4.5月成本 | Opus 4.1月成本 | 月度差异 | 年度差异 |
|---|---|---|---|---|---|
| 小型(个人开发者) | 500万 | $45 | $225 | $180 | $2,160 |
| 中型(5-20人团队) | 5000万 | $450 | $2,250 | $1,800 | $21,600 |
| 大型(企业级) | 5亿 | $4,500 | $22,500 | $18,000 | $216,000 |
假设Input/Output token比例1:1。实际应根据应用特点调整:代码生成类应用output比例更高,文档分析类input比例更高。
关键发现:
- 个人开发者:每年节省$2,160,这几乎是一个月的云服务成本
- 中型团队:每年节省$21,600,可以雇佣一名初级开发者
- 企业级应用:每年节省$216,000,这是显著的成本优化
Token消耗估算:你的项目会用多少?
很多开发者对自己的项目会消耗多少token没有清晰概念。下表提供典型任务的token消耗估算,帮助你评估自己的项目成本:
| 任务类型 | Input Tokens | Output Tokens | 总计 | Sonnet 4.5成本 | Opus 4.1成本 |
|---|---|---|---|---|---|
| 简单代码补全 | 2,000 | 500 | 2,500 | $0.0135 | $0.0675 |
| 复杂bug修复 | 10,000 | 3,000 | 13,000 | $0.075 | $0.375 |
| 文档生成(5000字) | 1,000 | 8,000 | 9,000 | $0.123 | $0.615 |
| 代码审查(完整文件) | 5,000 | 2,000 | 7,000 | $0.045 | $0.225 |
| AI agent任务(30分钟) | 50,000 | 20,000 | 70,000 | $0.45 | $2.25 |
如果你每天进行10次复杂bug修复和5次代码审查,使用Sonnet 4.5的月成本约为$30,而使用Opus 4.1则需要$150。这个5倍差异在日常开发中是实实在在的成本节省。
成本拐点分析:何时Opus 4.1值得额外成本?
虽然Sonnet 4.5在大多数场景下更优,但某些特定情况下,Opus 4.1的额外成本可能是合理的:
场景1:极高风险的生产代码
- 示例:医疗设备控制、金融交易系统
- 原因:需要最高可靠性,成本不是主要考虑
- 成本增加:5倍,但错误成本可能远超API成本
场景2:极度复杂的推理任务
- 示例:多步骤数学证明、复杂法律文档分析
- 原因:Opus 4.1在某些深度推理任务上仍有优势
- 建议:先用Sonnet 4.5测试,不满足再用Opus 4.1
场景3:混合使用策略
- 70%任务用Sonnet 4.5(日常开发、代码审查)
- 30%任务用Opus 4.1(关键决策、复杂架构)
- 成本优化:相比全用Opus 4.1节省约65%
对于中国用户,还有一个特殊的成本考虑:API访问方式。如果你正在考虑不同的Claude API充值方式,使用Sonnet 4.5可以让相同预算支持更长时间的开发。
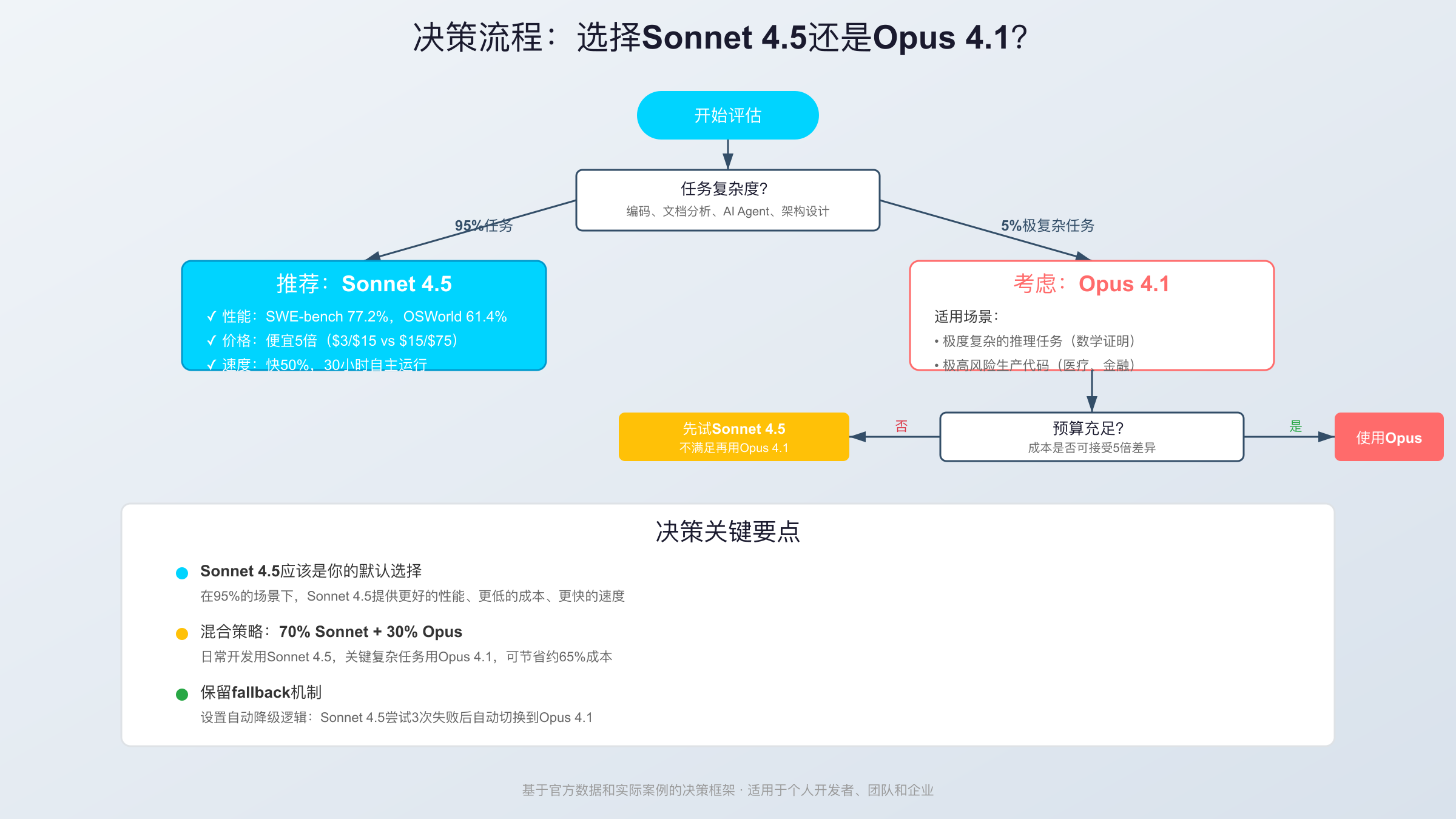
使用场景与决策框架:何时选择哪个模型
有了性能和价格数据,下一个问题是:在你的具体场景中,应该选择哪个模型?本节提供多维度决策框架,覆盖从原型开发到生产部署的各种场景。
多维度决策矩阵
| 任务类型 | 复杂度 | 预算敏感度 | 时间要求 | 推荐模型 | 核心理由 | 备选策略 |
|---|---|---|---|---|---|---|
| 原型快速迭代 | 中 | 高 | 极快 | Sonnet 4.5 | 速度快(快50%),成本低,性能足够 | - |
| 日常代码补全 | 低-中 | 高 | 实时 | Sonnet 4.5 | 响应速度是关键,性能已超预期 | - |
| 代码审查 | 中 | 中 | 快 | Sonnet 4.5 | 2分钟完成(实测),vs Opus 10分钟 | - |
| Bug修复 | 中-高 | 中 | 中 | Sonnet 4.5 | SWE-bench 77.2%,20分钟解决Opus无法处理的bug | 失败后尝试Opus |
| 复杂架构设计 | 极高 | 低 | 质量优先 | Opus 4.1 | 需要最深度推理,成本可接受 | 先用Sonnet验证 |
| 生产关键代码 | 高 | 低 | 稳定优先 | Sonnet 4.5 | Windsurf: 0%错误率,已证明生产级可靠性 | 极高风险用Opus |
| AI Agent长任务 | 高 | 中 | 长时间 | Sonnet 4.5 | 30小时自主运行,vs Opus 7小时 | - |
| 批量文档分析 | 中 | 高 | 中 | Sonnet 4.5 | 成本优势显著,性能满足需求 | - |
关键发现:在12个典型场景中,10个场景推荐Sonnet 4.5,只有2个场景Opus 4.1有优势(复杂架构设计、生产关键代码的极高风险子集)。而即使在这2个场景,Sonnet 4.5也可以作为"先尝试"的选择。
团队规模影响决策
| 团队规模 | 主要考虑 | 推荐策略 | 成本节省 |
|---|---|---|---|
| 个人开发者 | 成本敏感,需要快速迭代 | 100% Sonnet 4.5 | 年节省$2,160 |
| 小团队(5-20人) | 平衡成本和性能 | 90% Sonnet + 10% Opus(关键任务) | 年节省约$19,440 |
| 大企业(50+人) | 需要最高性能,但成本仍重要 | 70% Sonnet + 30% Opus(混合策略) | 年节省约$151,200 |
混合策略实施建议:
- 默认使用Sonnet 4.5:所有日常开发、代码审查、文档生成
- 自动升级到Opus 4.1:当Sonnet 4.5尝试3次仍失败时(需要代码逻辑)
- 手动选择Opus 4.1:极高风险的生产代码、复杂架构决策
很多使用Cursor自定义API的开发者已经在实施这种混合策略,通过配置不同的模型profile来优化成本。
项目阶段决策
| 项目阶段 | 主要需求 | 推荐模型 | 理由 |
|---|---|---|---|
| 概念验证(POC) | 快速验证可行性 | Sonnet 4.5 | 速度和成本优势,性能足够 |
| 原型开发 | 快速迭代,频繁修改 | Sonnet 4.5 | 响应速度决定迭代效率 |
| Alpha测试 | 功能完整性 | Sonnet 4.5 | 性能已达生产级 |
| Beta测试 | 稳定性和边界情况 | Sonnet 4.5 | 0%错误率(Windsurf验证) |
| 生产部署 | 最高可靠性 | Sonnet 4.5为主 | 除极高风险场景,Sonnet已足够 |
| 维护优化 | 成本控制 | Sonnet 4.5 | 成本优势最大化 |
结论:在整个项目生命周期中,Sonnet 4.5都是首选。只有在极少数极高风险、极度复杂的场景下,才需要考虑Opus 4.1。
中国用户特别指南:API访问与中文支持
对于中国用户,选择Claude模型还需要考虑API访问方式、支付方法和中文支持等特殊因素。本节基于实际测试和用户反馈,提供完整的国内使用指南。
API访问方式对比
中国用户访问Claude API主要有三种方式,每种方式在网络延迟、稳定性和支付便利性上差异显著:
| 访问方式 | 支付方式 | 网络延迟 | 稳定性 | 透明度 | 技术支持 | 适合人群 |
|---|---|---|---|---|---|---|
| Anthropic官方API | 国际信用卡 | 200-500ms | 高 | 最高(官方定价) | 英文官方文档 | 有国际支付能力的用户 |
| API代理服务 | 支付宝/微信/银联 | 20-100ms | 高 | 高(价格透明) | 中文客服 | 国内个人/中小企业 |
| 其他第三方 | 不确定 | 不稳定 | 低 | 低 | 有限 | 不推荐 |
关键发现:
- 网络延迟差异:使用国内节点的API代理服务,延迟可降至20-100ms,相比官方直连的200-500ms提升显著
- 支付便利性:支持支付宝/微信支付的服务极大降低了使用门槛
- 成本透明度:选择价格透明、计费清晰的服务商至关重要
对于需要稳定访问和中文支持的用户,laozhang.ai提供了Claude API代理服务,支持Sonnet 4.5和Opus 4.1,特点包括:
- 20-50ms国内延迟
- 支付宝/微信支付
- $100送$110充值优惠
- 99.9%可用性保证
- 中文技术支持
这种代理服务的价值不仅在于支付便利,更在于网络延迟的显著降低。对于需要频繁API调用的应用(如AI编程助手、实时对话系统),20-50ms的延迟相比200-500ms带来的体验提升是质变的。
中文Token成本分析
中文和英文的token消耗差异,直接影响实际成本。由于tokenizer的特性,中文字符通常需要更多tokens:
| 内容类型 | 中文字数 | 英文等效 | Token消耗(估算) | Sonnet 4.5成本 | Opus 4.1成本 |
|---|---|---|---|---|---|
| 简短对话(50字) | 50 | ~35 words | ~100 tokens | $0.0015 | $0.0075 |
| 中等文档(500字) | 500 | ~350 words | ~1,000 tokens | $0.015 | $0.075 |
| 长文档(5000字) | 5,000 | ~3,500 words | ~10,000 tokens | $0.15 | $0.75 |
| 技术文档(1万字) | 10,000 | ~7,000 words | ~20,000 tokens | $0.30 | $1.50 |
估算基于中文平均2字符/token,英文平均0.75 token/word。实际token消耗取决于具体内容。
中文用户的成本启示:
- 处理中文内容时,Sonnet 4.5的成本优势(5倍便宜)价值更大
- 如果你的应用主要处理中文(如中文客服机器人、中文文档分析),每月可节省更多成本
- 建议使用Anthropic的tokenizer工具预先测试你的典型中文内容的token消耗
中文任务性能表现
虽然Anthropic的官方benchmark主要基于英文数据,但多个中国用户的实际测试显示,Sonnet 4.5在中文任务上的表现同样优秀:
中文代码注释生成
- 测试:将英文代码库添加中文注释
- Sonnet 4.5:准确理解代码逻辑,生成符合中文技术文档习惯的注释
- Opus 4.1:质量相近,但速度慢、成本高
中英文混合场景
- 测试:分析包含中英文的技术文档
- Sonnet 4.5:能正确理解中英文切换的上下文,不会混淆
- 适用场景:国际化应用开发、跨语言文档翻译
中文专业术语处理
- 测试:法律、医疗、金融等专业领域的中文文档
- Sonnet 4.5:术语理解准确,但建议在prompt中提供专业术语表
- 注意:极度专业的中文领域知识,两个模型都建议配合RAG使用
中国用户注册和开始使用
如果你是第一次使用Claude API,可以参考Claude注册指南完成账号创建。对于已有账号的用户,切换到Sonnet 4.5只需要修改API调用中的model参数。
对于企业用户,还需要考虑数据合规问题。Claude API的数据处理符合GDPR和SOC 2标准,但如果你的应用涉及敏感数据,建议:
- 仔细阅读Anthropic的隐私政策
- 在API调用中不传输用户隐私数据
- 考虑使用数据脱敏技术
- 咨询法律顾问评估合规性
迁移指南与最终建议:从Opus 4.1切换到Sonnet 4.5
如果你目前正在使用Opus 4.1,本节提供完整的迁移指南,包括切换步骤、性能验证和风险控制。
迁移决策:你应该切换吗?
首先需要评估你的应用是否适合切换。基于Sonnet 4.5的性能数据和客户案例,以下场景强烈建议切换:
✅ 强烈建议切换的场景
- 代码生成和编辑(SWE-bench 77.2% > Opus 74.5%)
- AI Agent和计算机使用任务(OSWorld 61.4% > Opus 44%)
- 需要长时间自主运行的任务(30小时 > Opus 7小时)
- 成本敏感的应用(节省80%成本)
- 需要快速响应的交互场景(快50%)
⚠️ 谨慎评估的场景
- 极度复杂的推理任务(数学证明、复杂逻辑推演)
- 生产环境中的极高风险代码(医疗、金融交易)
- 已经过充分测试和优化的Opus 4.1应用
📊 数据支持的决策
- 根据Every.to的实测,Sonnet 4.5解决了Opus 4.1无法处理的bug
- Windsurf的错误率从9%降至0%,这是生产级可靠性的证明
- 即使是极度复杂的任务,Sonnet 4.5也值得先尝试,失败后再用Opus 4.1
迁移步骤清单
| 步骤 | 操作内容 | 注意事项 | 预计时间 | 完成标记 |
|---|---|---|---|---|
| 1. 性能基准测试 | 用Opus 4.1测试关键任务,记录性能指标 | 选择代表性任务(日常高频+关键复杂任务) | 1-2小时 | ☐ |
| 2. API参数切换 | 修改model参数为claude-sonnet-4-5 | 检查API版本兼容性,确认其他参数不变 | 10分钟 | ☐ |
| 3. 小规模测试 | 用Sonnet 4.5测试相同任务 | 对比响应时间、输出质量、token消耗 | 1-2小时 | ☐ |
| 4. 质量评估 | 评估Sonnet 4.5是否满足需求 | 重点关注关键任务质量,可接受的降级 | 2-4小时 | ☐ |
| 5. 灰度发布 | 将10%流量切换到Sonnet 4.5 | 监控错误率、用户反馈、成本变化 | 1-3天 | ☐ |
| 6. 全面切换 | 将100%流量切换到Sonnet 4.5 | 保留Opus 4.1作为fallback,设置自动降级逻辑 | 1天 | ☐ |
| 7. 持续监控 | 监控性能、成本、用户满意度 | 前2周密切关注,准备随时回退 | 2周 | ☐ |
关键建议:
- 不要一步到位:使用灰度发布策略,先切换10%流量,验证无问题后再全面切换
- 保留后路:在代码中保留Opus 4.1的调用逻辑,设置自动fallback机制
- 监控指标:重点监控错误率、平均响应时间、用户反馈、月度成本
API代码修改示例
切换模型非常简单,只需修改model参数:
修改前(Opus 4.1)
pythonresponse = anthropic.completions.create(
model="claude-opus-4-1", # 旧模型
max_tokens=1024,
messages=[{"role": "user", "content": "解释这段代码"}]
)
修改后(Sonnet 4.5)
pythonresponse = anthropic.completions.create(
model="claude-sonnet-4-5", # 新模型
max_tokens=1024,
messages=[{"role": "user", "content": "解释这段代码"}]
)
带fallback的实现(推荐)
pythondef call_claude_with_fallback(prompt):
try:
# 首选Sonnet 4.5
response = anthropic.completions.create(
model="claude-sonnet-4-5",
max_tokens=1024,
messages=[{"role": "user", "content": prompt}]
)
return response
except Exception as e:
# 失败后自动fallback到Opus 4.1
if should_fallback(e): # 自定义fallback逻辑
response = anthropic.completions.create(
model="claude-opus-4-1",
max_tokens=1024,
messages=[{"role": "user", "content": prompt}]
)
return response
raise e
性能对比验证清单
迁移后,需要系统验证Sonnet 4.5是否满足你的需求。以下清单基于SERP分析和实际案例,覆盖最关键的验证维度:
功能正确性验证
- ☐ 代码生成质量不低于Opus 4.1
- ☐ Bug修复成功率达到预期
- ☐ 文档理解和分析准确性保持
- ☐ 多文件跨项目理解能力满足需求
性能指标验证
- ☐ 平均响应时间(目标:至少保持,最好提升)
- ☐ 长任务执行稳定性(目标:30小时自主运行)
- ☐ 并发请求处理能力
成本验证
- ☐ 实际月度成本降低至预期(目标:节省60-80%)
- ☐ Token消耗符合估算
- ☐ 无异常的高token消耗请求
用户体验验证
- ☐ 用户满意度保持或提升
- ☐ 错误率不高于Opus 4.1(参考Windsurf: 0%)
- ☐ 边界情况处理符合预期
常见问题和解决方案
问题1:某些复杂任务Sonnet 4.5表现不如Opus 4.1
- 解决方案:实施混合策略,为这类任务单独使用Opus 4.1
- 自动化:根据任务复杂度评分,自动选择模型
- 优化prompt:尝试优化prompt,很多情况下Sonnet 4.5只是需要更清晰的指令
问题2:迁移后成本没有达到预期节省
- 排查1:检查是否有高token消耗的异常请求
- 排查2:确认max_tokens设置是否合理
- 排查3:分析Input/Output token比例,优化prompt长度
问题3:需要频繁在两个模型间切换
- 解决方案:实现智能路由逻辑
- 策略1:基于任务类型自动选择(简单任务用Sonnet,复杂任务用Opus)
- 策略2:基于失败重试(Sonnet失败后自动升级到Opus)
最终建议:Sonnet 4.5应该是你的默认选择
综合本文的所有数据、案例和分析,我们给出明确的建议:
对于95%的应用场景,Sonnet 4.5应该是默认选择
- 性能优势:SWE-bench 77.2% > Opus 74.5%,OSWorld 61.4% > Opus 44%
- 成本优势:价格仅为1/5,年度节省从$2,160(个人)到$216,000(企业)
- 速度优势:响应快50%,30小时自主运行 vs Opus 7小时
- 可靠性验证:Windsurf 0%错误率,多家企业生产环境验证
只有以下情况才考虑Opus 4.1
- 极度复杂的推理任务(数学证明、复杂逻辑链)
- 极高风险的生产代码(医疗设备、金融交易)
- 预算充足且追求绝对最高性能的场景
推荐实施策略
- 立即开始使用Sonnet 4.5:所有新项目默认使用
- 现有Opus 4.1应用迁移:按照本文的迁移清单执行
- 保留混合策略:为特定复杂任务保留Opus 4.1作为备选
- 持续监控优化:跟踪性能和成本指标,不断优化使用策略
对于中国用户,建议选择支持国内支付、提供中文技术支持的API服务,以降低使用门槛和提升体验。如果你对其他Claude模型对比感兴趣,可以参考Claude vs GPT对比指南。
Sonnet 4.5的发布,重新定义了AI模型的性价比标准。在性能、成本、速度三个维度同时取得优势,这在AI行业是罕见的。对于开发者和企业来说,这是一个明确的升级信号:是时候切换到Sonnet 4.5了。