Claude 3.7 Sonnet vs GPT-4.1: Ultimate AI Model Comparison 2025
Comprehensive analysis comparing Anthropic Claude 3.7 Sonnet and OpenAI GPT-4.1 models: token context windows, output capabilities, benchmark performance, pricing, and ideal use cases. Tested in May 2025.

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
Claude 3.7 Sonnet vs GPT-4.1: Ultimate AI Model Comparison 2025

🔥 Tested in May 2025: This article provides a comprehensive comparison between Anthropic's Claude 3.7 Sonnet and OpenAI's GPT-4.1 models, covering context windows, output capabilities, benchmark performance, pricing, and ideal use cases, helping you choose the best advanced AI model for your specific needs.
The two AI giants OpenAI and Anthropic released their flagship model updates in 2025, bringing unprecedented AI capabilities to developers and enterprise users. Claude 3.7 Sonnet was launched in February 2025, while OpenAI released GPT-4.1 in April. These top-tier models each have their strengths, and understanding their differences is essential for choosing the right tool.
This article will dive deep into the key metrics, performance differences, and specialized use cases for both models, helping you understand when to choose Claude 3.7 Sonnet and when to prioritize GPT-4.1 in the 2025 AI landscape.
Model Overview: Key Specifications Comparison
First, let's understand the differences between these two models through their basic specifications:
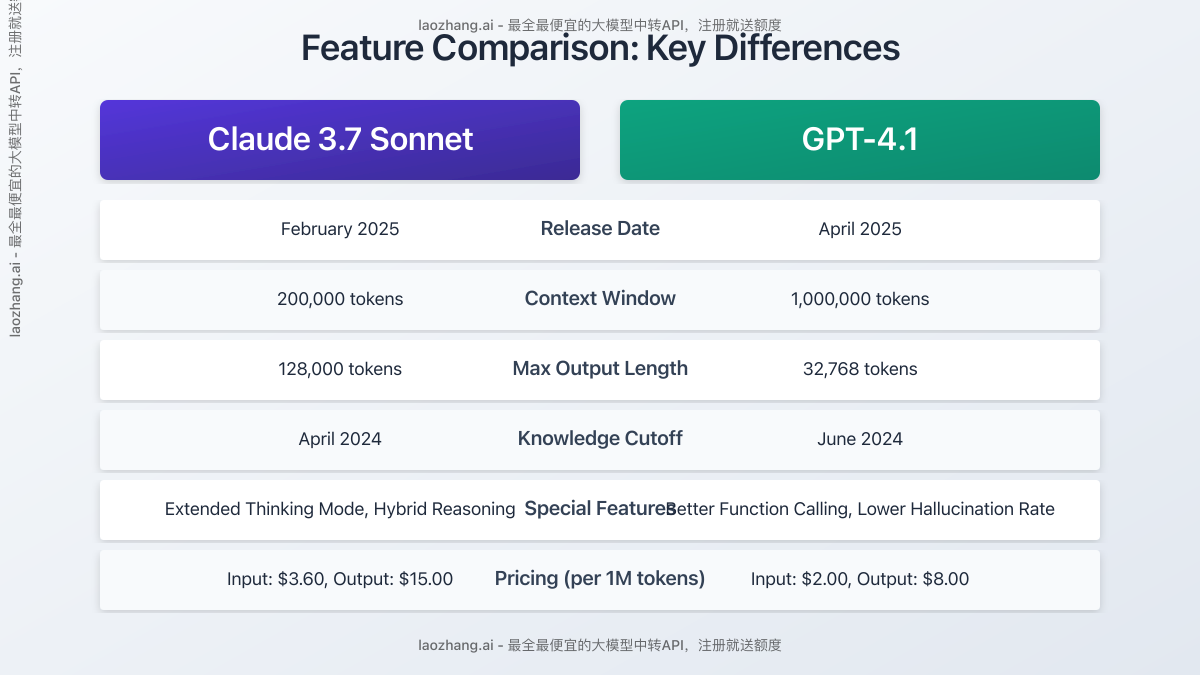
Context Window
- Claude 3.7 Sonnet: 200,000 tokens
- GPT-4.1: 1,000,000 tokens
The context window size is one of the most significant differences between these two models. GPT-4.1 provides an impressive 1 million token context window, five times that of Claude 3.7 Sonnet. This means GPT-4.1 can process approximately 800,000 words of text simultaneously (roughly equivalent to 3-4 books) without forgetting information from earlier inputs.
Maximum Output Length
- Claude 3.7 Sonnet: 128,000 tokens
- GPT-4.1: 32,768 tokens
Although GPT-4.1 has a larger context window, Claude 3.7 Sonnet has the advantage in single-output length, capable of generating about 4 times the text volume of GPT-4.1. This makes Claude particularly well-suited for tasks requiring lengthy content generation, such as detailed reports, long articles, or complex code bases.
Knowledge Cutoff Date
- Claude 3.7 Sonnet: April 2024
- GPT-4.1: June 2024
GPT-4.1 has slightly more recent training data, up to June 2024, two months later than Claude 3.7 Sonnet, making it potentially more accurate when dealing with events and information from April to June 2024.
Release Date
- Claude 3.7 Sonnet: February 2025
- GPT-4.1: April 2025
Performance Benchmarks: Who Comes Out On Top?
The two models perform differently across various task types. Let's look at some key benchmark results:
Coding Capabilities
SWE-Bench Verified benchmark (measuring ability to solve real engineering problems):
- Claude 3.7 Sonnet: 58.2%
- GPT-4.1: 54.6%
TAU-bench (testing frontend development capabilities):
- Claude 3.7 Sonnet: Leading
- GPT-4.1: Slightly behind
Code Review Performance
Based on tests with 200 real PRs (Pull Requests):
- GPT-4.1: Performed better in 55% of cases
- Claude 3.7 Sonnet: Performed better in 45% of cases
GPT-4.1's advantages in code review include:
- More accurate bug detection
- Fewer unnecessary suggestions
- Greater focus on critical issues rather than style concerns
Reasoning and Factual Accuracy
- Claude 3.7 Sonnet: Excels in complex reasoning, with the new extended thinking mode demonstrating step-by-step reasoning processes
- GPT-4.1: Improved by 10.5% over GPT-4o in MultiChallenge tests, with lower hallucination rates
Instruction Following Ability
- GPT-4.1: Better performance in multi-step instruction-following tasks
- Claude 3.7 Sonnet: Better at understanding ambiguous instructions
Special Features and Technical Highlights
Both models have their unique functional advantages:
Claude 3.7 Sonnet's Unique Features
- Extended Thinking Mode: Claude 3.7 Sonnet introduces the market's first hybrid reasoning model, capable of displaying step-by-step thinking processes, making complex reasoning more transparent
- Powerful Code Generation: Particularly outstanding in frontend development and UI implementation
- More Detailed Explanations: Provides deeper educational responses, suitable for learning and guidance scenarios
GPT-4.1's Unique Features
- Massive Context Processing: The 1 million token context window enables analysis of extremely large amounts of data
- Lower Hallucination Rate: Improved factual accuracy, particularly suitable for tasks requiring high accuracy
- Better Function Calling: Stronger API integration and JSON mode capabilities
- Better Pricing: Overall usage cost lower than Claude 3.7 Sonnet
Pricing and Cost Analysis
Price differences are an important consideration when choosing a model:
| Pricing (per million tokens) | Claude 3.7 Sonnet | GPT-4.1 | GPT-4.1 Price Advantage |
|---|---|---|---|
| Input | $3.60 | $2.00 | About 44% cheaper |
| Output | $15.00 | $8.00 | About 47% cheaper |
GPT-4.1 also offers a 75% discount for input caching, further reducing the cost of repeated queries.
Best Use Cases: When to Choose Which Model?
Based on their respective strengths, these two models are suitable for different use cases:

Scenarios Suitable for Claude 3.7 Sonnet
- Complex Coding Challenges: When first-principles solutions to complex programming problems are needed
- Long-Form Content Generation: When generating text exceeding 32K tokens
- Educational and Learning Scenarios: When detailed step-by-step explanations and reasoning processes are required
- Frontend Development Tasks: UI implementation and web development projects
- Projects Requiring Visible Reasoning: Leveraging its unique extended thinking mode
Scenarios Suitable for GPT-4.1
- Code Review and Debugging: More accurately identifying bugs and improvements
- Large-Scale Document Analysis: Processing massive amounts of text data (such as entire codebases)
- Fact-Sensitive Tasks: Work requiring high accuracy and low hallucination rates
- API Integration Projects: Better function calling and JSON processing capabilities
- Cost-Sensitive Enterprise Applications: Limited budget but need high-performance AI
How to Leverage Both Models' Advantages?
💡 Pro Tip: Using API transit services allows convenient access to both models, flexibly choosing the most suitable AI based on specific tasks. laozhang.ai provides the most comprehensive and affordable large model transit API service, with free credits upon registration.
Through API transit services, you can combine the advantages of both models in the same project:
bashcurl https://api.laozhang.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "claude-3-7-sonnet", # can be replaced with "gpt-4.1"
"stream": false,
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Analyze the bugs in the following code and provide fix solutions."}
]
}'
Frequently Asked Questions (FAQ)
Which model is better for everyday use?
Answer: For most everyday tasks, GPT-4.1 offers better value, especially considering its lower price and large context window. Claude 3.7 Sonnet is more suitable for advanced use cases requiring lengthy outputs and complex reasoning processes.
What is Claude 3.7 Sonnet's "Extended Thinking Mode"?
Answer: This is an ability that allows the model to demonstrate its step-by-step reasoning process, enabling users to see how the AI reaches its conclusions. This is valuable for educational purposes, solving complex problems, and scenarios requiring transparent decision-making.
What are the differences between GPT-4.1 and Claude 3.7 Sonnet in multimodal processing?
Answer: Both models support image understanding capabilities, but still have certain limitations in handling video, audio, and complex charts. A more comprehensive multimodal comparison requires specialized testing and evaluation.
Which is more developer-friendly?
Answer: OpenAI's API documentation and developer tools are generally considered more mature, but Anthropic is rapidly improving its developer experience. GPT-4.1's function calling capabilities give it an advantage in certain API integration scenarios.
Which model excels in processing non-English content?
Answer: Both models support multiple languages and perform similarly with non-English content. For advanced tasks in specific languages, targeted testing is recommended.
Summary and Outlook
Claude 3.7 Sonnet and GPT-4.1 represent the highest level of large language models in 2025, each exhibiting excellent performance in different areas. Overall:
- Claude 3.7 Sonnet excels in complex coding challenges, long-form output, visible reasoning processes, and frontend development, but comes at a higher price
- GPT-4.1 offers better value in most general scenarios with its larger context window, lower price, better code review capabilities, and lower hallucination rate
The best strategy is to choose the most suitable model based on specific task requirements, or even combine the strengths of both in the same workflow. Through API transit services like laozhang.ai, you can conveniently access both top-tier AI models without having to register for multiple services separately.
With the rapid development of AI technology, we can expect Anthropic and OpenAI to continue improving their models, narrowing gaps and making breakthroughs in more specialized domains. Whichever model you choose, they both represent the most powerful AI capabilities available today and will bring tremendous value to your projects.
Final Tip: Technology choices should always be based on your specific needs, budget constraints, and project requirements. Through trial and testing, you can find the AI partner that best suits your unique use case.
Note: Data in this article is based on model versions and public information as of May 2025 and may change as models are updated.