2025最全Cline配置Ollama教程:5步轻松搭建本地AI编程环境【实战指南】
【最新独家】全面解析Cline连接Ollama的5大配置方法,从安装到性能优化,一次性解决所有连接问题!无需云端API,小白也能10分钟内搞定本地AI编程环境!

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
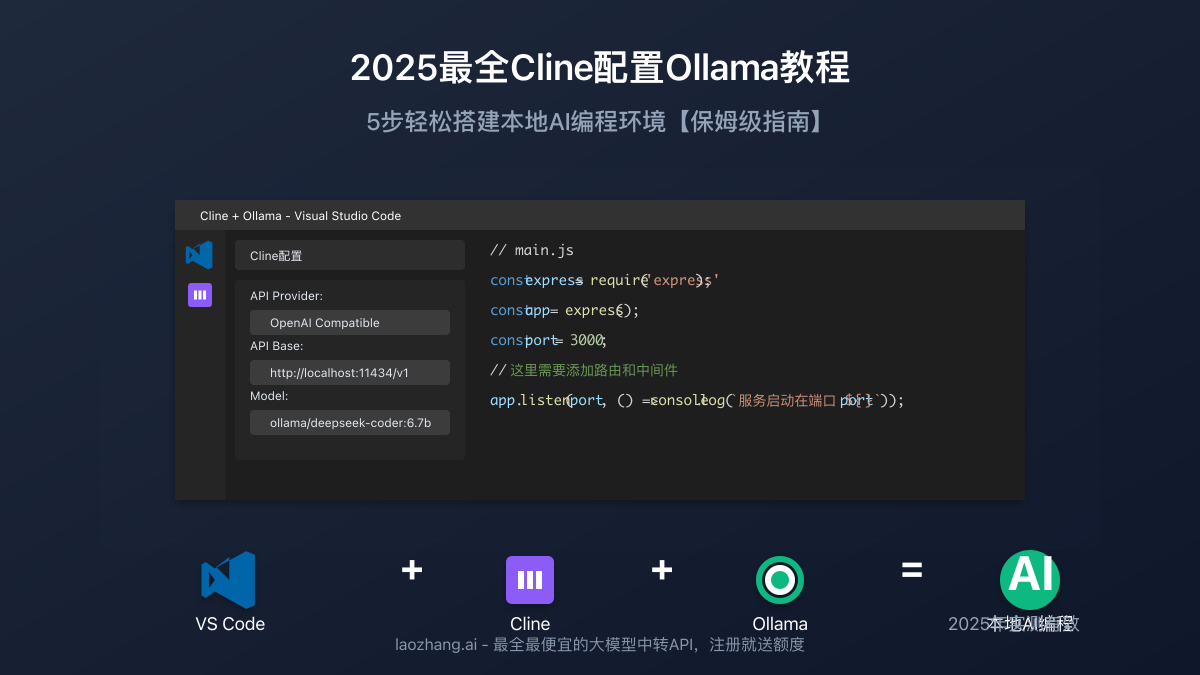
前言:为什么选择Cline+Ollama?
在当今AI辅助编程火热的背景下,选择一款既高效又经济的编程助手至关重要。Cline作为VSCode中备受好评的AI编程扩展,结合Ollama的本地大模型能力,为开发者提供了一种不依赖云服务、保护代码隐私的理想解决方案。
本地AI编程的优势:
- 代码完全在本地处理,确保企业敏感代码的安全性
- 无需支付昂贵的API调用费用,一次配置长期使用
- 离线环境也能使用,不依赖网络连接的稳定性
- 可自定义配置模型参数,满足个性化需求
如果您的硬件配置较低或追求更高质量的AI输出,也可以考虑使用laozhang.ai提供的中转API服务,价格低至官方的50%,支持多种顶级大模型。
第一步:安装Ollama
在配置Cline之前,我们需要先安装Ollama并下载相应的模型。
1.1 下载并安装Ollama
- 访问Ollama官网下载适合您操作系统的安装包
- macOS用户:直接拖拽到Applications文件夹
- Windows用户:运行安装程序并按提示完成安装
- Linux用户:运行以下命令
bash
curl -fsSL https://ollama.ai/install.sh | sh
1.2 验证安装
打开终端或命令提示符,输入以下命令验证Ollama是否安装成功:
bashollama --version
如果显示版本号,则表示安装成功。
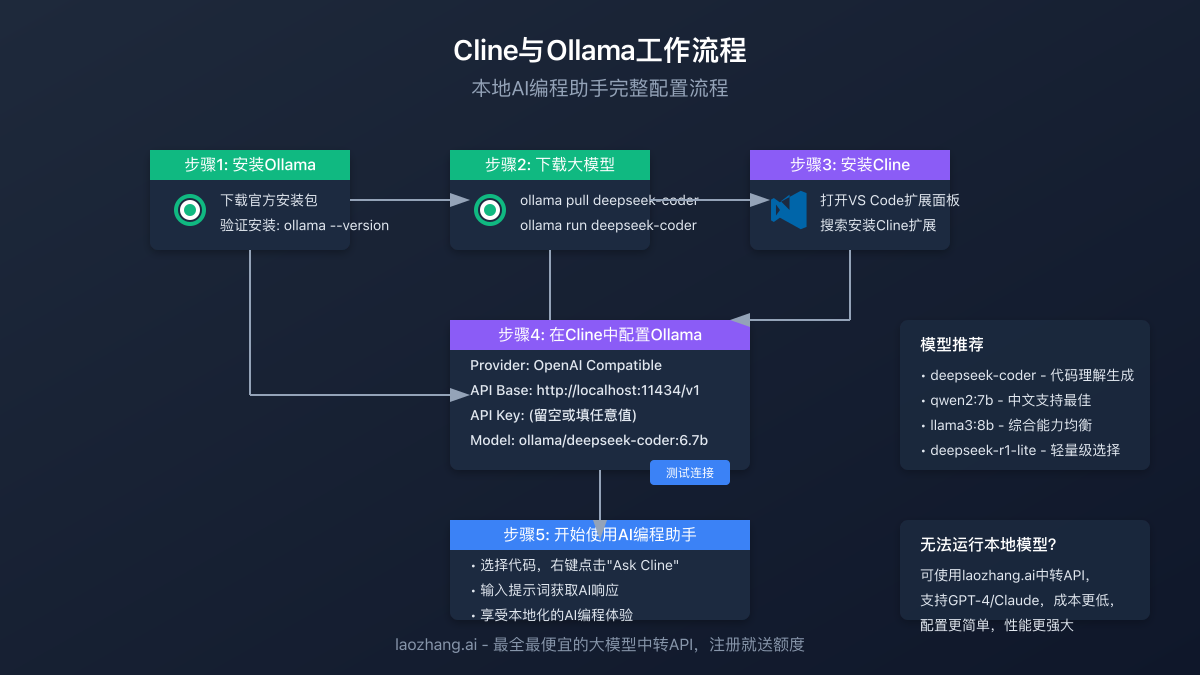
第二步:选择并下载适合的模型
Ollama支持多种编程相关的大模型,选择合适的模型对于获得良好的编程体验至关重要。
2.1 推荐模型
根据您的硬件配置,可以选择以下模型:
-
入门级硬件(4-6GB显存/8GB系统内存):
llama3:8b-q4_0qwen:1.5-7b-q4_0deepseek-r1-lite
-
中端硬件(8-10GB显存/16GB系统内存):
deepseek-coder:6.7bqwen2:7bcodeqwen:7b
-
高端硬件(12-24GB显存/32GB系统内存):
deepseek-coder:33bqwen2:72b-q4_K_Mllama3:70b-q4_K_M
2.2 下载模型
这里我们以deepseek-coder为例,在终端执行:
bashollama pull deepseek-coder
下载完成后,可以测试模型运行情况:
bashollama run deepseek-coder
输入一些编程相关问题,检验模型效果。

第三步:安装Cline扩展
接下来,我们需要在VSCode中安装Cline扩展。
- 打开VSCode
- 点击左侧扩展图标(Extensions)
- 在搜索框中输入"Cline"
- 找到"Cline - AI Coding Assistant"并点击"Install"安装
- 安装完成后,VSCode右下角会显示Cline图标
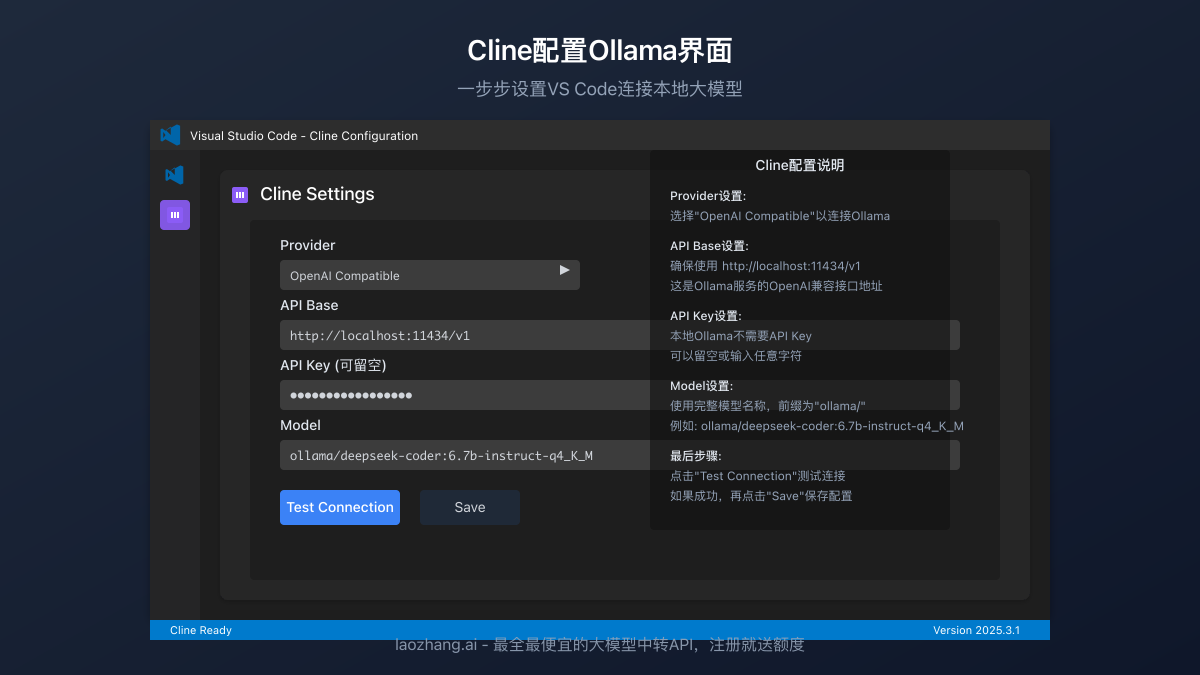
第四步:配置Cline连接Ollama
现在是关键的一步——配置Cline使其连接到本地运行的Ollama模型。
4.1 打开Cline设置
- 点击VSCode右下角的Cline图标
- 选择"Settings"选项
- 或者,可以使用快捷键
Ctrl+Shift+P(Windows/Linux)或Cmd+Shift+P(Mac)打开命令面板,然后输入"Cline: Open Settings"
4.2 配置Ollama连接
在Cline设置界面中,填写以下配置信息:
- Provider:选择"Ollama"
- API Base:填写
http://localhost:11434/api(默认Ollama API地址) - API Key:对于Ollama可以留空或填入任意值
- Model:填写您已下载的模型名称,如
deepseek-coder
4.3 测试连接
点击"Test Connection"按钮验证连接是否成功。如果配置正确,将显示成功消息。
第五步:性能优化与使用技巧
为了获得最佳体验,可以对Ollama和Cline进行一些性能优化。
5.1 Ollama性能优化
可以通过设置环境变量优化Ollama的性能:
bash# 调整上下文窗口大小
export OLLAMA_CONTEXT_SIZE=16384
# 优化GPU内存使用(数值根据您的GPU而定)
export OLLAMA_GPU_LAYERS=43
通过自定义Modelfile也可以提升模型能力:
FROM deepseek-coder
PARAMETER temperature 0.2
PARAMETER top_p 0.9
PARAMETER context_length 16384
5.2 Cline设置优化
在VSCode的settings.json中添加以下配置可优化Cline性能:
json"cline.settings.contextStrategy": "local",
"cline.settings.localContextSize": 16384,
"cline.settings.generationParameters": {
"temperature": 0.2,
"maxTokens": 4096
}

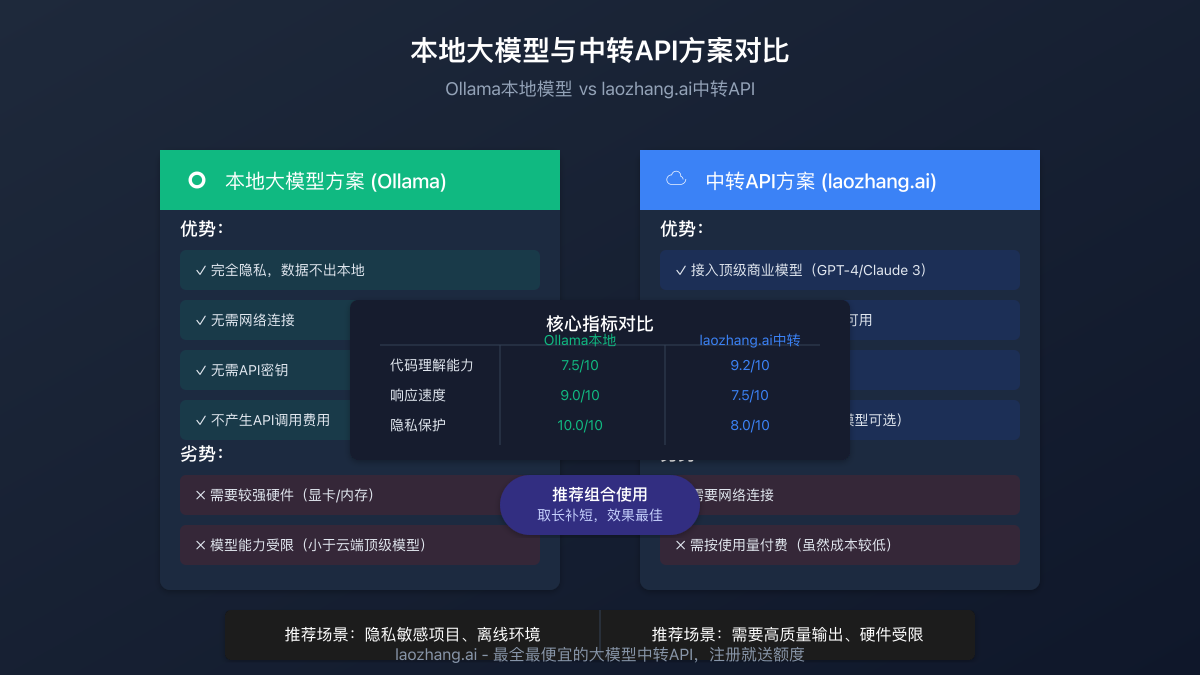
本地模型与中转API对比
| 方案 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|
| Ollama本地模型 | 完全隐私、无需网络、无API费用 | 硬件要求高、模型能力有限 | 隐私敏感项目、离线环境 |
| laozhang.ai中转API | 顶级模型接入、无硬件要求、多样模型选择 | 需要网络连接、按使用量付费 | 需要高质量输出、硬件受限 |
常见问题解答
Q1: Ollama模型能力与云端模型相比如何?
A: 本地模型能力取决于模型大小和硬件性能,通常7B-13B参数的模型已能满足基本编程需求,但在复杂任务上仍不及GPT-4或Claude 3等顶级商业模型。如需高级能力,可考虑laozhang.ai中转API服务。
Q2: 我的电脑配置较低,无法运行大模型怎么办?
A: 可以尝试量化版本的小模型如llama3:8b-q4_0,或使用laozhang.ai中转API服务,无需本地计算资源即可访问高性能模型。
Q3: 如何解决Ollama启动后占用内存过高的问题?
A: 可以在不使用时通过命令pkill ollama关闭Ollama服务,或选择较小的模型,也可以调整OLLAMA_GPU_LAYERS环境变量减少GPU内存占用。
Q4: Cline提示"无法连接到服务器"怎么办?
A: 确保Ollama服务正在运行,可以通过终端执行ollama serve启动服务;检查API Base是否正确设置为http://localhost:11434/api;防火墙设置可能阻止连接,请检查相关设置。
结语
通过本教程的五个步骤,您已经成功配置了Cline+Ollama的本地AI编程环境。这套组合不仅保护了代码隐私,还为您提供了高效的编程辅助体验,同时避免了昂贵的API调用费用。
如果您在使用过程中遇到任何问题,或者本地硬件无法满足运行大模型的需求,欢迎尝试laozhang.ai提供的中转API服务,价格低至官方的50%,支持Claude 3、GPT-4等多种顶级大模型。
记得关注我们的更新,我们将持续分享更多AI编程相关的教程和技巧!
本文最后更新于2025年4月7日