How to Use Custom API Keys in Cursor: Setup, Limits, and BYOK Decision Guide
An updated Cursor custom API key guide based on official docs verified on 2026-03-18. Learn when BYOK is worth it, what changes in billing and privacy, and how to configure OpenAI, Anthropic, Gemini, and Azure correctly.

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
Most older Cursor custom API key guides are now weak in exactly the places that matter. They still explain where the setting lives, but they do not explain what changed in Cursor's provider support, which features still rely on Cursor-owned models, or when bringing your own key is actually worth the extra billing and admin work.
That gap matters because "use your own key" is no longer an automatic upgrade. For some developers, it gives cleaner provider billing and better governance. For others, it adds friction without solving the problem they really have. If you do not sort that out first, you can end up with a more complex setup and no practical improvement in your day-to-day workflow.
This guide is written against the current official docs and provider setup pages available on 2026-03-18. The goal is simple: help you make the right BYOK decision, then help you configure the right path without carrying 2025 assumptions into a 2026 workflow.
TL;DR
- Cursor custom API keys are now documented for OpenAI, Anthropic, Gemini, Azure, AWS Bedrock, and OpenAI-compatible providers(Cursor API Keys, verified 2026-03-18).
- BYOK is best when you need direct provider billing, provider choice, Azure governance, or gateway control. It is not automatically the best option for every Cursor user.
- OpenAI custom keys inside Cursor currently support standard OpenAI models, not reasoning models or GPT-5(Cursor API Keys, verified 2026-03-18).
- Even with a custom key enabled, some features such as Tab Completion and Apply from Chat still use Cursor's own models(Cursor API Keys, verified 2026-03-18).
- The most reliable setup pattern is: choose the billing path first, collect the right credentials second, then configure Cursor's Models page once.
What Changed Since the Old 2025 Setup Guides
The first thing to understand is that the "four providers and a verify button" mental model is no longer complete. Current Cursor docs describe custom key support for OpenAI, Anthropic, Gemini, Azure, AWS Bedrock, and OpenAI-compatible endpoints(Cursor API Keys, verified 2026-03-18). That alone makes many older tutorials incomplete before you even reach the troubleshooting section.
The second change is more important than the provider list itself. Cursor now documents that OpenAI custom API keys inside Cursor support standard OpenAI models, but not reasoning models or GPT-5(Cursor API Keys, verified 2026-03-18). If you read an older article that recommends "just paste your OpenAI key and use the entire OpenAI lineup," you should treat that advice as outdated. That is not a small detail. It changes whether BYOK is even the right route for your team.
The third change is how billing and plan choice should be evaluated.
Cursor's current public pricing still frames the individual ladder around Pro at
$20/month, Pro+ at $60/month, Ultra at $200/month, and Teams at
$40/user/month(Cursor Pricing; Cursor Teams Pricing, verified 2026-03-18).
That means the real question is no longer "Can Cursor use my own key?"
The real question is "Is my problem better solved by Cursor's included usage, or by
moving cost and model control back to the provider side?"
Finally, the privacy and feature story is more nuanced than older blog posts admit. Cursor's API key docs and privacy/security docs need to be read together. The API key setting changes who bills for eligible model usage, but Cursor also documents backend prompt handling and a Privacy Mode where code is kept only in memory to serve the request and deleted after each request(Cursor Privacy & Security, verified 2026-03-18). That means BYOK is a billing and model-selection choice first. It is not a magic switch that turns Cursor into a fully direct, backend-free relay.
If you want the broader context around how Cursor fits into current AI coding tool choices, this is the same kind of product-boundary shift discussed in Cursor vs Cline 对比指南. The difference is that this article is focused on the specific setup and decision logic for custom keys inside Cursor itself.
The First Decision: Should You Use Cursor Usage or Your Own Key?
Most guides start with configuration. That is backwards. The better way to approach Cursor BYOK is to decide which billing and control model you actually want, then configure the provider that matches that choice.
If your top priority is the lowest operational friction, staying on Cursor-managed usage is often the better default. You keep one subscription relationship, one app-level setup, and fewer provider-side dashboards to reconcile. That is especially true if your team is still learning how much AI-assisted coding it will actually do, or if your real issue is usage predictability rather than provider freedom.
If your top priority is direct provider billing, internal chargeback, or model governance, BYOK becomes much more attractive. You can place cost exactly where it belongs, tie usage to the provider account you already manage, and reduce the number of "Why is this invoice here instead of there?" moments inside procurement and finance. That is where direct OpenAI, Anthropic, Gemini, or Azure configuration starts to make sense.
If your team is more mature, the choice widens again. Azure may be the right answer when enterprise procurement, policy controls, or regional deployment requirements matter more than setup simplicity. An OpenAI-compatible endpoint may be the right answer when you need one gateway for multiple providers or want to standardize custom routing behavior. And if you already know you prefer more explicit model and gateway control, it is worth also comparing this path with Cline 自定义 API 配置指南, because some teams decide that Cursor stays the daily IDE while a second tool handles the more custom provider layer.
Here is the shortest decision table I can recommend without losing important nuance:
| Your real constraint | Best default choice | Why it fits | Hidden trade-off |
|---|---|---|---|
| You want the fastest setup and one predictable software bill | Cursor included usage | Lowest admin friction; easiest to roll out to a team | Less direct provider-side visibility |
| You want provider invoices and provider-owned keys | Direct provider BYOK | Clear billing ownership and cleaner internal cost allocation | More dashboards, quotas, and troubleshooting |
| You need enterprise governance, deployment naming, or Azure procurement alignment | Azure OpenAI | Better fit for governance-heavy environments | Most setup overhead |
| You want one endpoint that can front multiple providers | OpenAI-compatible endpoint | Centralizes provider routing behind one compatible API | Compatibility varies by gateway |
| You are already standardized on AWS infrastructure | AWS Bedrock path | Aligns with existing cloud controls and procurement | Credential flow is different from simple API-key providers |
The practical test is simple. If you cannot state in one sentence why your team needs BYOK, you probably should not default to it. The decision should be driven by billing ownership, governance, provider access, or gateway strategy. It should not be driven by vague hope that "custom keys are more powerful."
If what you really need is a better understanding of plan ceilings and overage behavior before making that decision, read Cursor 使用限制指南 first. That article is the better companion when the confusion is about included usage rather than provider setup.

What BYOK Changes, and What It Does Not
Once you enable your own key in Cursor, three things change immediately. Billing responsibility changes for eligible provider usage. Your available provider path changes. And your troubleshooting surface changes because now you are debugging both Cursor's app configuration and the provider account behind it.
What does not change is just as important. Cursor documents that some features still use Cursor-owned models, including Tab Completion and Apply from Chat(Cursor API Keys, verified 2026-03-18). So if you switch to BYOK and then assume every AI behavior in the product is now billed to your provider, you can misread both cost and feature behavior. That is one of the most common expectation failures around this topic.
Privacy expectations also need to be handled precisely. Cursor's privacy/security docs state that in Privacy Mode, code is not stored by Cursor, is kept only in memory to serve the request, and is deleted after each request (Cursor Privacy & Security, verified 2026-03-18). That is useful and important. But it is not the same as saying "nothing ever goes through Cursor." Cursor also documents backend handling and prompt assembly behavior, so the right mental model is: BYOK changes who is billed for eligible model calls and which provider is used, while Cursor still remains part of the product pipeline(Cursor Privacy & Security, verified 2026-03-18).
This is why I do not recommend selling BYOK as a pure privacy feature. If your organization has a serious compliance question, treat it as a policy and architecture review, not as a checkbox in a blog post. The key setting may be part of the solution, but it is rarely the whole answer.
The same caution applies to cost. Direct provider billing can be better for visibility and control, but it does not make cost disappear. It just moves the cost surface. That can be exactly what a mature team wants. It can also be exactly what a solo developer does not want.
A better way to think about it is this: Cursor usage is an application-layer commercial model. BYOK is a provider-layer commercial model. You should choose based on which layer you want to manage every month.
Preflight Checklist Before You Open Cursor
Most setup failures happen before the key is pasted. They happen because the wrong credential was created, the wrong provider path was chosen, or the user assumes all providers behave like OpenAI. Spend two minutes here and you will save much more than two minutes later.
- Decide which billing owner you want. If the answer is "my Cursor subscription," stop and use included usage. If the answer is "my provider account" or "my Azure subscription," continue.
- Confirm the provider account is actually ready. That means billing, credits, region access, and account state are valid on the provider side before Cursor ever tries to verify the key.
- Collect the right credential format. OpenAI uses project-oriented API keys in its Platform/Projects workflow (OpenAI Help Center, verified 2026-03-18). Anthropic uses Console-based API key auth for its API (Anthropic API docs, verified 2026-03-18). Gemini keys come from Google AI Studio (Google AI for Developers, verified 2026-03-18). Azure OpenAI requires more than a key: you also need the endpoint and deployment name (Microsoft Learn Azure OpenAI Quickstart, verified 2026-03-18).
- Decide whether you need a simple provider key or a more customized endpoint. If you need gateway logic, model normalization, or aggregated providers, you are already in OpenAI-compatible-endpoint territory. Treat that as a separate architecture choice, not as a minor toggle.
There is one more subtle preflight question that many older guides skip: do you actually need a provider that Cursor can use through this custom-key path? OpenAI is the clearest example. If your main goal is a reasoning-heavy OpenAI setup inside Cursor, the current OpenAI custom-key limitation matters immediately because GPT-5 and reasoning models are not part of that path(Cursor API Keys, verified 2026-03-18). That is not a "later troubleshooting" problem. That is a "wrong route selected" problem.
If your workflow is already Claude-heavy, it can also help to review Cursor Claude 指南 before you commit to a provider path. That guide is not about BYOK specifically, but it is useful for understanding the broader Claude-in-Cursor workflow around this configuration decision.
How to Configure OpenAI, Anthropic, Gemini, and Azure in Cursor
The shared app flow is straightforward.
Cursor documents custom keys under Settings > Models(Cursor API Keys, verified
2026-03-18).
What changes from provider to provider is not the location inside Cursor.
It is the credential type, the billing surface, and the caveats you need to remember
after verification succeeds.
OpenAI
For OpenAI, start by creating or retrieving the right project-scoped API key from the
OpenAI Platform rather than assuming an old user-level pattern
(OpenAI Help Center, verified 2026-03-18).
Then open Cursor, go to Settings > Models, paste the key into the OpenAI section, and
verify it.
The part that matters most is what happens after verification. OpenAI custom keys in Cursor currently support standard OpenAI models, not reasoning models or GPT-5(Cursor API Keys, verified 2026-03-18). So if your main goal is access to the newest reasoning path, BYOK through OpenAI may not be the route you actually want. This is exactly why the decision framework belongs before the setup steps.
In practice, OpenAI BYOK is strongest when you want direct OpenAI billing, already manage OpenAI projects internally, or need a standard-model path that sits cleanly inside your existing provider reporting. It is weaker when your primary expectation is "all OpenAI things, exactly as advertised, through my own key." That expectation is broader than the current Cursor custom-key support.
Anthropic
Anthropic is conceptually simpler.
Anthropic's API flow is built around API-key authentication through the Console and API
docs at Anthropic Console(Anthropic API docs, verified 2026-03-18).
Inside Cursor, the workflow is the same pattern as other providers: open Settings > Models, paste the Anthropic key, verify it, then enable the model path you want to use.
Anthropic BYOK makes the most sense when you want direct Anthropic billing or already run part of your internal development tooling against Claude through the provider account. The benefit here is not that Anthropic is uniquely easier to configure. The benefit is that it keeps your AI spend aligned with the provider you already rely on.
Where teams sometimes go wrong is assuming Anthropic BYOK solves every control question by itself. It does not. It solves billing ownership and provider choice. If you also need organization-wide workflow rules, approval patterns, or multi-tool governance, that is a separate operating decision on top of the key itself.
Gemini
Google's Gemini setup starts in Google AI Studio, where the Gemini API key flow is
documented and managed at Google AI Studio(Google AI for Developers,
verified 2026-03-18).
Once you have that key, the Cursor side is again the same overall pattern: paste the key
under the provider section in Settings > Models, verify it, and select the supported
models you want enabled.
Gemini BYOK is usually attractive when your team is already standardizing around Google's AI tooling or when you want Gemini usage to sit clearly inside Google-side billing and quotas. The biggest mistake is treating Gemini setup as just another checkbox in a four-provider tutorial. It should be chosen because the Google-side account, quota model, or organizational standard actually helps your workflow.
If you are configuring Cursor from a region or network environment where account access, availability, or purchase path is part of the friction, you may also want to compare the broader operational advice in Cursor 中国区使用指南. That article is not a substitute for official provider setup, but it can help frame the operational reality around using Cursor across different environments.
Azure OpenAI
Azure OpenAI is where older "complete guides" usually become dangerously shallow. Microsoft's quickstart makes clear that Azure OpenAI setup is not just "paste a key." You also need the endpoint and the deployment name that maps to the model you actually deployed(Microsoft Learn Azure OpenAI Quickstart, verified 2026-03-18). If you want the canonical setup reference, start from Microsoft Learn Azure OpenAI Quickstart. That is why Azure belongs in its own category in the decision table.
If your organization needs Azure-native procurement, policy layering, or region-aware governance, Azure can be the right answer even though it is more work to configure. If you do not need those things, Azure is often unnecessary complexity. This is one of the cleanest examples of why "supports Azure" is not enough information for an article like this. You need the decision logic, not just the existence proof.
Operationally, Azure is the path where naming mismatches create the most user confusion. When verification succeeds but the expected model behavior is still wrong, the root cause is often not the key. It is the deployment mapping. Treat Azure like an enterprise integration, not like a consumer API key field.
A quick note on AWS Bedrock
Cursor's current docs include AWS Bedrock in the supported provider landscape (Cursor API Keys, verified 2026-03-18). I am not expanding Bedrock into a full step-by-step section here because the user intent for this slug is still primarily "custom API key" guidance, and Bedrock flows are more credential-and-cloud-account oriented than "single secret key in one field." But if your company is already AWS-first, Bedrock should be part of your provider evaluation, not treated as an afterthought.
When to Use OpenAI-Compatible Endpoints and Custom Models
This is the part many setup guides oversimplify. They say "you can also use OpenAI-compatible providers" and move on. That is technically true. It is not strategically helpful.
An OpenAI-compatible endpoint is worth considering when you want one entry point that can front multiple providers, when you want a custom gateway layer, or when your team already operates an internal model router. Cursor docs explicitly include OpenAI-compatible providers in the custom-key story (Cursor API Keys, verified 2026-03-18). That makes this a legitimate path, not a hack.
But it is still a path with trade-offs. Compatibility at the API shape level is not always the same thing as complete behavior parity. Model IDs, verification behavior, and feature support can drift from what a user expects if they assume every compatible endpoint behaves exactly like the first-party provider. This is why I recommend choosing an OpenAI-compatible endpoint only when you actually need gateway logic or provider normalization, not just because it sounds more flexible.
The strongest use case is organizational, not personal. If a team wants one managed entry point for multiple model vendors, or wants to control how provider traffic is routed, a compatible gateway can be a rational architecture choice. If one solo developer just wants to "make Cursor cheaper somehow," it is often the wrong place to add complexity.
A good rule is this: if you need a custom model ID, a custom base URL, and separate operational ownership, write those down before you start. If you cannot explain the mapping from provider, endpoint, and model ID on paper, you are not ready to debug it in Cursor.
Troubleshooting the Setup Without Guessing
The hardest failures are not always the loudest ones. Sometimes verification fails, which is obvious. More often, verification passes and the experience still feels wrong because the user expected a different model path, different billing behavior, or different privacy boundary.
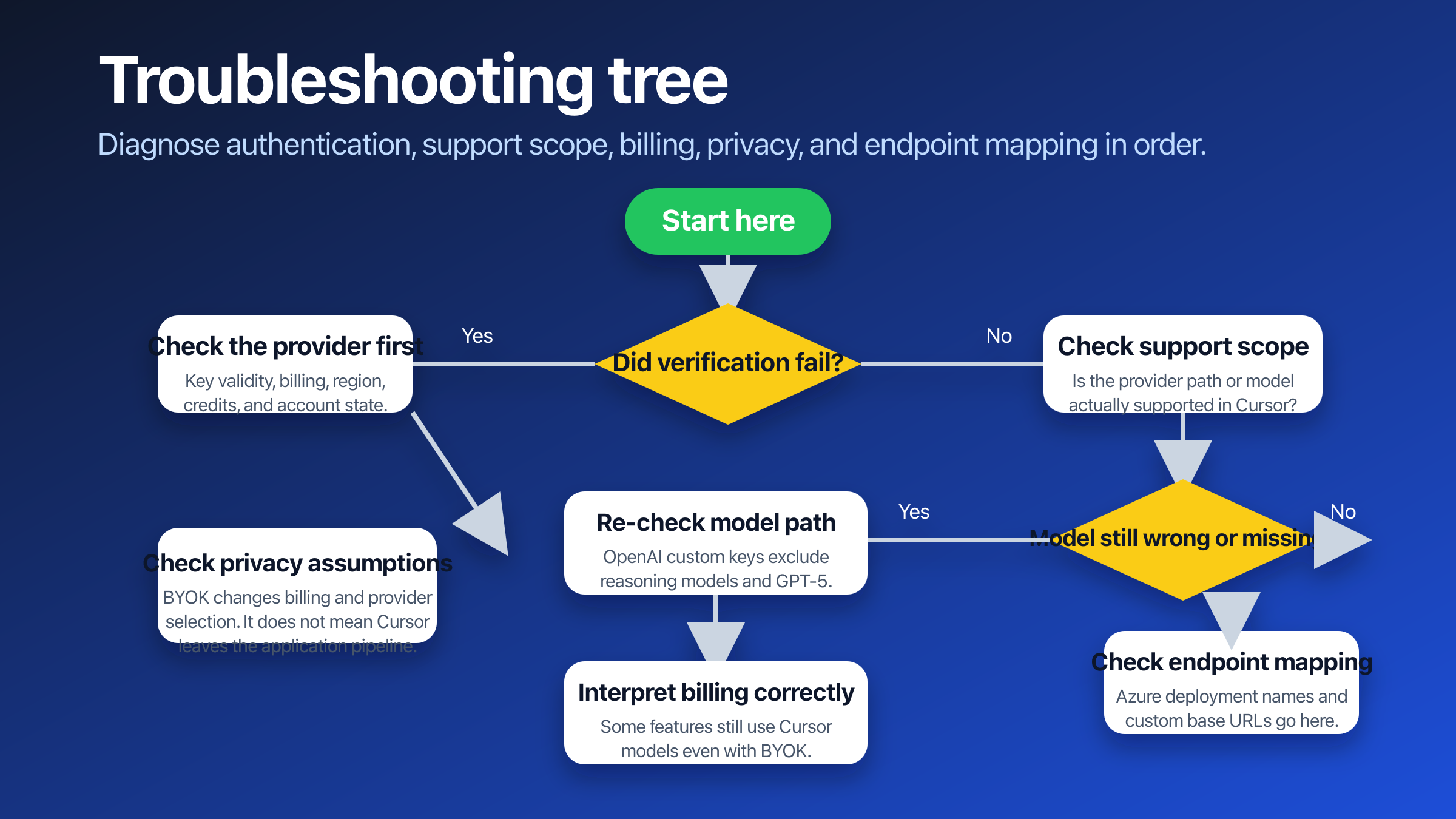
Use this troubleshooting order instead of random trial and error:
- If verification fails immediately, check the provider account before Cursor. Confirm the key is valid, the provider account is active, and billing or credits are in place. The app cannot verify a provider account that is not ready.
- If verification passes but the model you expected is missing, check whether the path is actually supported in Cursor. This matters most with OpenAI, where the current custom-key path excludes reasoning models and GPT-5(Cursor API Keys, verified 2026-03-18).
- If you expected every feature to bill the provider and that is not happening, revisit feature coverage. Cursor documents that Tab Completion and Apply from Chat still use Cursor-owned models (Cursor API Keys, verified 2026-03-18).
- If your privacy expectation was "my key means nothing touches Cursor," revisit the privacy model. Cursor documents both backend handling and Privacy Mode behavior, which is more nuanced than a pure direct-to-provider assumption(Cursor Privacy & Security, verified 2026-03-18).
- If an OpenAI-compatible or Azure setup verifies but behaves incorrectly, inspect the endpoint and model naming layer next. In these paths, the issue is often mapping, not authentication.
This order works because it follows the actual dependency chain. Identity comes before capability. Capability comes before billing interpretation. Billing interpretation comes before policy interpretation. And only after those do you get into custom endpoint edge cases.
If you prefer a simpler operational rule, use this one: first decide whether the problem is authentication, support scope, billing ownership, or endpoint mapping. Do not debug all four at the same time. That is how ten-minute fixes become ninety-minute rabbit holes.
Frequently Asked Questions
Q1: Does using my own API key make Cursor cheaper?
Not automatically.
It changes who receives the bill.
That can lower cost in some situations, especially when your organization already manages
provider spend centrally or negotiates usage on the provider side.
But for many individuals, a Cursor plan is still the simpler commercial model because it
removes provider-by-provider admin overhead.
Cursor's current pricing still spans Pro at $20/month, Pro+ at $60/month, Ultra at
$200/month, and Teams at $40/user/month(Cursor Pricing; Cursor Teams Pricing,
verified 2026-03-18).
So the right comparison is not "subscription bad, provider key good."
The right comparison is "which billing layer do I want to manage every month?"
Q2: If I enable BYOK, do my requests stop touching Cursor?
Do not assume that. Cursor's privacy/security docs describe Privacy Mode as code being kept only in memory to serve the request and deleted after each request, which is important(Cursor Privacy & Security, verified 2026-03-18). But those same docs also describe backend handling and prompt construction behavior. So the safest operational interpretation is that BYOK changes provider billing and model selection for supported paths, while Cursor still remains part of the application flow. If this is a compliance decision rather than a convenience decision, read the official privacy docs with your security team instead of relying on any one blog post.
Q3: Why does my OpenAI key not unlock every OpenAI model in Cursor?
Because Cursor documents a narrower support boundary for OpenAI custom keys than many users expect. The current docs state that OpenAI custom API keys support standard models, not reasoning models or GPT-5(Cursor API Keys, verified 2026-03-18). So if your mental model was "my provider account equals full provider catalog," Cursor's product behavior will feel inconsistent. It is not random. It is a documented limitation of the custom-key path as of 2026-03-18. If that limitation blocks your use case, the solution is usually to change paths, not to keep clicking Verify.
Q4: Which path is better for teams: direct provider key, Azure, or Cursor plans?
The answer depends on which system your team wants to manage. Cursor plans are usually better when the goal is fast rollout, lighter admin burden, and one application-layer commercial relationship. Direct provider keys are better when the goal is provider-owned billing and more precise internal cost attribution. Azure is better when procurement, cloud governance, or deployment-level control matters more than setup speed(Microsoft Learn Azure OpenAI Quickstart, verified 2026-03-18). If your team cannot name a concrete governance reason for Azure, do not choose Azure just because it sounds more enterprise-ready.
Q5: Do all Cursor features use my key once I enable it?
No. This is one of the most important clarifications in the official docs. Cursor explicitly documents that Tab Completion and Apply from Chat still use Cursor-owned models(Cursor API Keys, verified 2026-03-18). That means a successful custom-key setup does not redefine every AI feature in the app. It redefines supported provider-backed usage paths. This distinction matters for both billing interpretation and user expectations. If your team is auditing usage or trying to compare invoices, make sure everyone shares the same feature-coverage model first.
Q6: When should I use an OpenAI-compatible gateway instead of a first-party provider key?
Use a gateway only when the gateway solves a real architecture problem. Good reasons include central routing, one endpoint for multiple providers, internal model normalization, or a provider-access strategy that your team has already chosen. Weak reasons include vague cost hope or a desire to avoid understanding provider-side account setup. Cursor does support OpenAI-compatible providers in its custom-key docs (Cursor API Keys, verified 2026-03-18). But support at that level does not remove the need to manage model IDs, compatibility assumptions, and endpoint ownership carefully. If the problem you have is simple, a first-party provider key is usually the cleaner path.
Final Recommendation
If you only remember one sentence from this article, remember this one: use Cursor BYOK when you need provider-side ownership, not just because it feels more "advanced."
The best implementation pattern is also the least glamorous one.
Pick the billing layer first.
Pick the provider second.
Collect the exact credential format third.
Then configure Settings > Models once, with the current support boundaries in mind.
That order will save you more time than any screenshot-heavy setup guide ever will.