Cursor智能搜索完整指南:@符号系统、语义搜索与代码库索引深度解析
深入解析Cursor IDE的三大搜索方式(语义搜索、Instant Grep、Explore子代理)和完整@符号系统,包含代码库索引原理、.cursorignore优化配置、大型项目搜索策略。基于Cursor v2.6最新文档。
Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
Cursor作为AI编程领域最受欢迎的IDE,其智能搜索系统远不止简单的关键词匹配。在Cursor v2.6版本中(据Cursor官方文档),搜索系统已经发展为三种互补的搜索方式——语义搜索、Instant Grep和Explore子代理,配合完整的@符号上下文系统,能够让开发者在数万文件的大型项目中实现秒级精准定位。研究数据显示,语义搜索结合grep的混合策略比单独使用grep的准确率高出12.5%,在1000+文件的大型代码库中优势尤为明显。本文将系统讲解Cursor的搜索架构、@符号系统、代码库索引原理和大型项目优化策略,帮助你充分释放Cursor的搜索潜力。

要点速览
- 三种搜索方式各有所长:Instant Grep适合精确名称搜索(最快,<0.5s),语义搜索适合概念性查询(准确率+12.5%),Explore子代理适合复杂跨文件探索(多轮自动搜索)
- @符号系统是核心交互方式:
@Codebase建议占60%使用频率,@Files占30%,其他(@Docs、@Web、@Git等)占10% - 代码库索引自动运行:打开项目时自动开始,索引到80%即可使用语义搜索,每5分钟增量同步变更文件
.cursorignore配置至关重要:正确配置后索引时间可从4分23秒降至41秒(提升84%),索引文件数从28,634减少到487(减少98%)- 搜索安全有保障:文件路径加密传输,代码内容不存储在服务器,嵌入向量客户端解密,不活跃6周后自动删除索引
Cursor代码搜索的三种方式详解
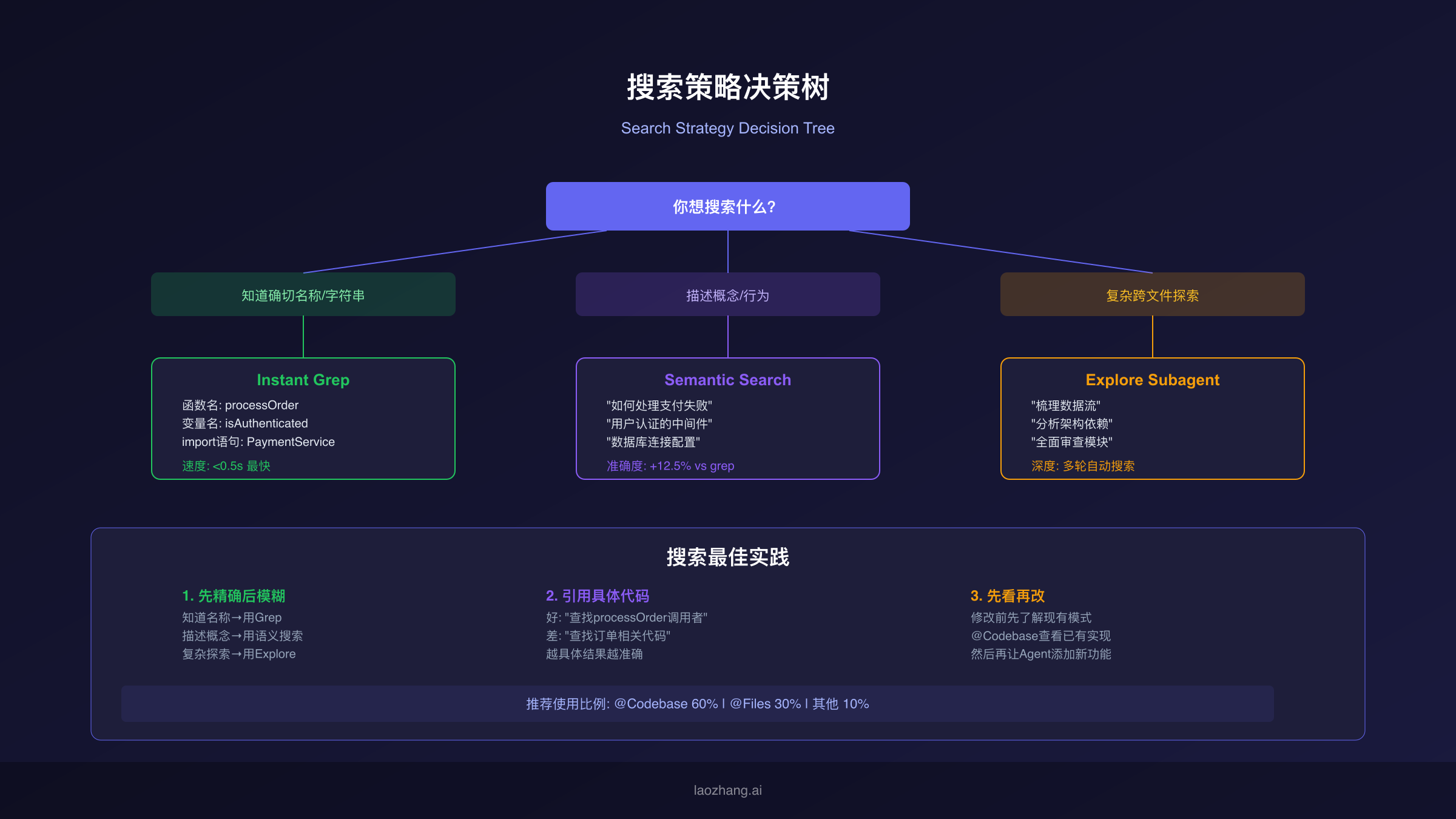
Cursor的搜索系统不是单一技术,而是三种互补的搜索方式协同工作。理解每种方式的适用场景,是高效使用Cursor搜索的基础。根据Cursor官方文档的说明,这三种方式分别对应不同的搜索需求层次。
Instant Grep是速度最快的搜索方式,专门用于精确字符串和正则表达式匹配。当你知道要搜索的确切函数名、变量名或错误字符串时,Instant Grep是最佳选择。它的底层实现超过了ripgrep在大型代码库上的性能,支持完整的正则表达式和词边界匹配。典型使用场景包括:"查找所有import PaymentService的文件"、"搜索包含TODO的注释"、"定位特定的错误码"。Instant Grep的响应时间通常在0.5秒以内,是三种方式中最快的。
**语义搜索(Semantic Search)**是Cursor最具特色的搜索能力,它能够理解代码的语义含义而不仅仅是文本匹配。当你用自然语言描述想找的代码时(比如"处理支付失败的逻辑"),语义搜索会通过向量嵌入匹配找到语义相关的代码,即使这些代码中没有包含"支付"或"失败"这些关键词。Cursor的语义搜索采用混合策略——先用语义搜索找到概念匹配的代码块,再用grep确认精确引用,这种组合策略将搜索准确率提升了12.5%。语义搜索在1000+文件的大型代码库中优势最为明显,通常在1-3秒内返回结果。
Explore子代理是最新加入的搜索方式,专为复杂的跨文件代码探索设计。它运行在独立的上下文窗口中,使用较快的模型进行多轮搜索,自动汇总发现并将结果返回主对话。这意味着Explore不会消耗你主对话的上下文空间,特别适合"梳理从结账到确认邮件的完整数据流"这类需要追踪多个文件关联的复杂探索任务。Explore子代理与Agent模式紧密配合,在Agent执行修改前可以先用Explore了解代码结构。
| 搜索方式 | 适用场景 | 速度 | 准确度 | 典型查询示例 |
|---|---|---|---|---|
| Instant Grep | 精确名称/字符串 | <0.5s | 精确匹配 | "查找所有import PaymentService" |
| 语义搜索 | 概念/行为描述 | 1-3s | +12.5% | "如何处理支付失败" |
| Explore子代理 | 复杂跨文件探索 | 2-5s | 深度全面 | "梳理认证到授权的数据流" |
@符号系统完整指南
@符号是Cursor中为AI提供上下文的核心交互方式。在Chat、Composer和内联编辑中,你都可以通过输入@来引用不同类型的上下文,让AI更精准地理解你的意图和项目背景。Cursor目前支持超过10种@符号,每种服务于不同的上下文需求。
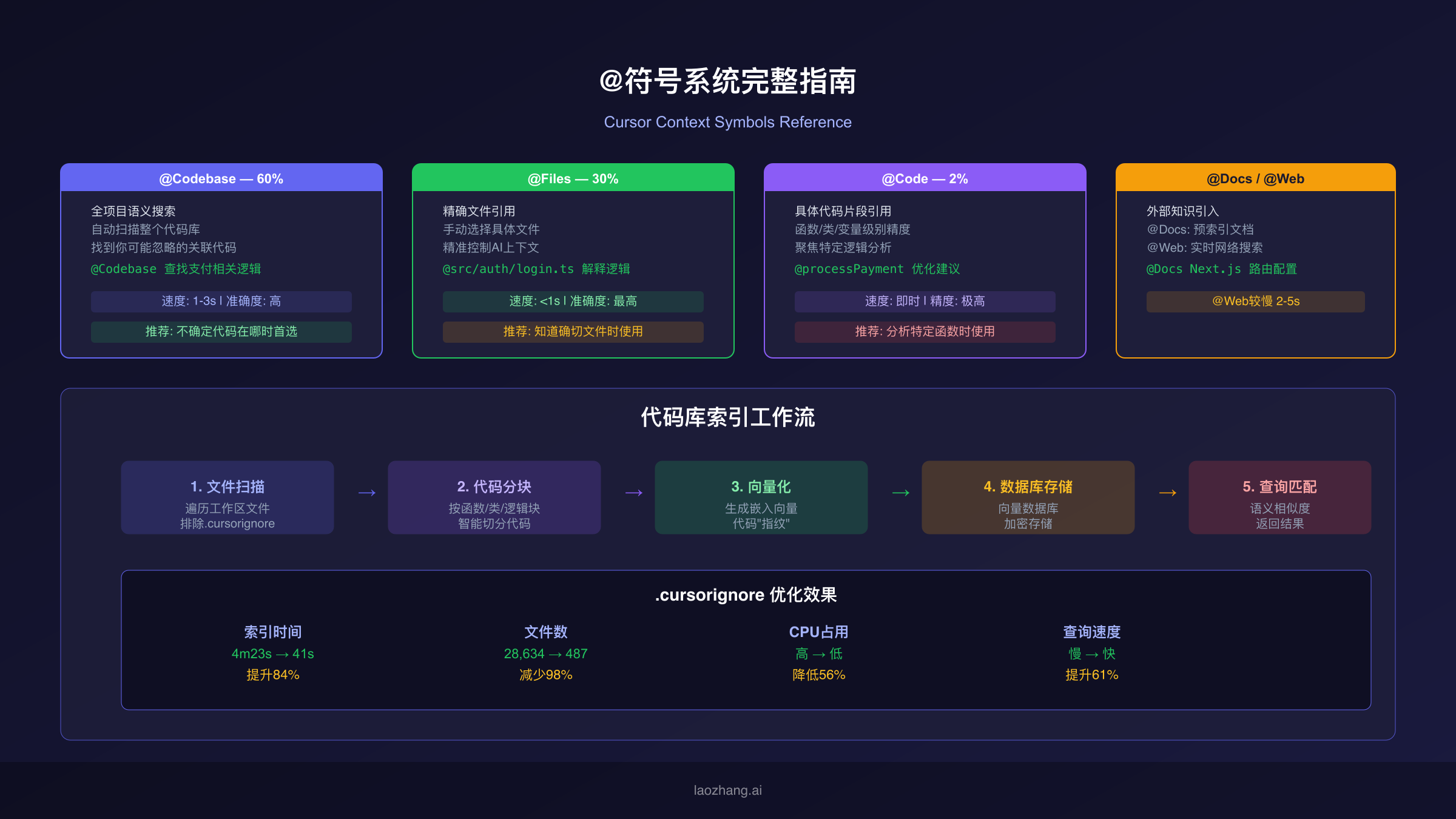
@Codebase是使用频率最高的@符号,推荐占整体使用的60%。输入@Codebase后跟你的问题,Cursor会自动扫描整个代码库寻找相关代码。它的工作机制是先收集(扫描代码库查找重要的文件和代码块),然后重新排序(根据与查询的相关性排列上下文项目)。这种方式的优势在于它经常能发现你可能忽略的关联代码——比如你查询支付逻辑时,它可能同时找到相关的错误处理、日志记录和配置文件。最佳实践是描述要具体:"@Codebase 查找用户登录时的token验证逻辑,优先看中间件文件"比简单的"@Codebase 登录"效果好得多。你也可以通过按Cmd+Enter(Ctrl+Enter)发送消息来自动触发@Codebase扫描,不需要手动输入@Codebase。
@Files是精确度最高的引用方式,推荐占30%使用频率。当你确切知道要引用的文件时,@Files比@Codebase更高效——它直接将指定文件的完整内容加入AI上下文,没有搜索延迟。输入@后开始键入文件名,Cursor会提供模糊匹配的文件建议。你可以同时引用多个文件,比如@src/auth/login.ts @src/auth/middleware.ts 这两个文件的认证逻辑是否一致。在Composer中也可以用#号引用文件(#filename),功能类似但交互略有不同。
@Folders提供目录级别的上下文。引用一个文件夹时,Cursor会将该目录下所有文件作为上下文提供给AI。这在分析某个模块的整体架构时特别有用,比如@src/components 分析组件间的数据流动方式。需要注意的是,如果目录包含大量文件,内容可能会被截断,因此建议配合.cursorignore排除不必要的文件。
@Code提供函数和类级别的精确引用。当你想让AI专注于分析某个特定函数或类时,@Code比引用整个文件更精准。输入@后选择具体的函数名或类名,AI会只关注这段代码的逻辑。这对于复杂函数的优化建议、bug分析特别有效。
@Docs允许引用外部文档作为上下文。Cursor预索引了常用框架的文档(如Next.js、React、Stripe等),输入@Docs后选择或搜索文档名称即可。你也可以通过@Docs > Add new doc添加自定义文档URL,Cursor会自动爬取和索引这些文档供后续使用。这在使用新框架或API时特别有价值,AI能够结合最新文档给出准确的代码建议。
@Web启用实时网络搜索,让AI获取最新信息来辅助编码。当你需要查找最新的API变更、错误解决方案或技术资讯时,@Web比AI依赖训练数据更可靠。不过要注意@Web是最慢的@符号(2-5秒),因为需要实时搜索网页,建议只在确实需要最新信息时使用。
其他实用@符号包括:@Git引用Git历史和变更记录,适合代码审查和变更追踪;@Past Chats引用之前的对话内容,避免重复解释上下文;@Cursor Rules引用项目规则文件,确保AI遵循项目规范;@Link引用特定URL内容;@Definitions引用符号定义;@Notepads引用Cursor笔记本内容。
代码库索引原理与配置
理解Cursor如何索引你的代码库,有助于优化搜索体验和解决常见问题。代码库索引是语义搜索的基础——没有索引,Cursor只能进行文本匹配而无法理解代码语义。
Cursor的索引流程分为五个步骤。首先是文件扫描,Cursor遍历工作区中的所有文件,排除.gitignore和.cursorignore中指定的路径。然后是代码分块,将每个文件按照函数、类、逻辑块等有意义的单元切分,而不是简单地按行数分割。第三步是向量化,使用Cursor自研的嵌入模型将每个代码块转换为向量——可以理解为给每段代码生成一个数学"指纹",语义相似的代码会产生相近的向量。第四步是数据库存储,将向量存入向量数据库,文件路径加密处理。最后是查询匹配,当你搜索时,查询文本被转换为同样维度的向量,通过计算向量相似度找到最匹配的代码块。
索引过程是完全自动的——打开项目时自动开始,无需手动触发。当索引进度达到80%时,语义搜索就已经可以使用了,不需要等待100%完成。之后Cursor每5分钟自动同步一次,只处理变更的文件(新增文件添加嵌入、修改文件更新嵌入、删除文件移除嵌入),增量更新效率很高。你可以在Cursor Settings > Indexing中查看索引状态、索引文件数量,以及手动触发重新索引。
.cursorignore文件是优化索引的关键。在项目根目录创建.cursorignore文件,语法与.gitignore完全相同。它告诉Cursor哪些文件不需要索引,直接影响索引速度和搜索准确性。值得注意的是,.cursorignore与.gitignore的目的不同——.gitignore排除不需要版本控制的文件,而.cursorignore排除不需要AI理解的文件。比如.env.local应该在.gitignore中(不提交敏感信息),但不应该在.cursorignore中(AI可能需要了解环境变量的结构)。
推荐的.cursorignore配置模板:
node_modules/
vendor/
.venv/
dist/
build/
.next/
*.log
.DS_Store
package-lock.json
yarn.lock
*.min.js
*.min.css
coverage/
__pycache__/
*.pyc
大型项目搜索优化实战
当项目规模超过1000个文件时,搜索性能和准确度都会面临挑战。以下优化策略基于实际项目测试数据(据eastondev.com的Cursor索引指南),能够显著提升大型项目的搜索体验。
优化.cursorignore是最高优先级的操作。在一个实际的Next.js项目中,添加合理的.cursorignore配置后效果显著:索引时间从4分23秒降至41秒(提升84%),索引文件数从28,634减少到487(减少98%),CPU占用降低56%,查询速度提升61%。最佳的索引文件数量范围是500-2,000个,超过这个范围的文件大多是依赖包、构建产物或生成文件,排除它们反而能提高搜索准确性。对于monorepo项目,建议分阶段索引——先只打开当前工作的子项目,避免一次索引整个仓库导致的性能问题。
搜索提示语的质量直接影响结果准确度。根据官方文档的建议,有三条核心原则:第一,"先精确后模糊"——如果你知道函数名,直接说它("查找processOrder的所有调用者"比"查找订单处理相关代码"精准得多);第二,"先看再改"——在让Agent修改代码之前,先用@Codebase了解现有的代码模式和结构,避免Agent引入与项目风格不一致的代码;第三,"引用具体代码"——在查询中提及具体的函数名、类名或文件路径,能给Agent一个精确的搜索锚点。
混合搜索策略是大型项目的最佳实践。不要只依赖单一搜索方式,根据需求灵活切换:需要定位特定符号时用Instant Grep,理解某块功能的实现时用语义搜索,分析跨模块的复杂关系时用Explore子代理。在日常开发中,@Codebase覆盖60%的搜索需求,@Files覆盖30%(当你已经知道要看哪个文件时),其余10%分配给@Docs、@Web等专用@符号。
对于使用API进行独立AI项目开发的场景,laozhang.ai提供了稳定的API中转服务,支持Claude、GPT-4o等主流模型,注册即送额度。在Cursor之外构建AI应用时,可以通过laozhang.ai低成本接入这些模型的能力。
搜索安全与隐私机制
对于企业用户来说,代码安全是选择AI工具时的首要考虑因素。Cursor在搜索系统的安全设计上做了多层保护,确保代码隐私不被泄露。
文件路径加密传输是第一层保护。在索引过程中,Cursor在客户端对文件路径进行模糊处理(obfuscation),然后再传输到服务器。每个路径组件都被掩码处理,但保留了足够的目录结构信息以支持有效的检索和过滤。这意味着即使服务器端也无法看到你项目的真实文件结构。
代码内容不存储在服务器是核心安全承诺。索引过程中,代码内容只在内存中暂时保持以计算嵌入向量,计算完成后立即丢弃。存储在向量数据库中的只有向量嵌入,不包含原始代码文本。当Agent搜索时,Cursor检索嵌入向量并在客户端解密代码块,整个过程服务器端不接触可读的源代码。
索引生命周期管理确保数据不会无限期保留。如果一个项目6周内没有活跃使用,其索引数据会被自动删除。团队用户的索引可以跨团队成员共享,同时尊重文件访问权限设置——成员只能搜索到他们有权限访问的文件内容。对于有特殊安全需求的团队,可以在项目根目录创建.cursor/keys文件配置自定义路径加密密钥。
搜索进阶技巧与最佳实践
掌握以下进阶技巧,能够让你的Cursor搜索效率再上一个台阶。这些技巧来自实际开发中的经验积累,适用于各种规模的项目。
组合使用@符号可以提供更精准的上下文。你不需要每次只用一个@符号——在同一个查询中可以组合多个引用。比如@src/auth/middleware.ts @Docs Express.js 这个中间件的实现是否符合Express最佳实践,同时引用了具体代码和外部文档,AI能给出更有针对性的分析。另一个常见的组合是@Codebase @Git 最近一周关于支付模块的修改是否引入了潜在问题,结合代码库搜索和Git历史进行综合分析。
利用Cursor Settings监控索引健康度。定期检查Cursor Settings > Indexing中的索引状态:如果索引文件数异常多(远超预期的源代码文件数),说明.cursorignore需要优化;如果索引状态长时间停留在某个百分比不动,可能是某些大文件导致的卡顿,检查是否有超大的JSON、CSV或生成文件需要排除。通过View included files功能可以看到所有被索引的文件路径,快速发现不该被索引的文件。
搜索结果不理想时的排查步骤:首先确认索引已完成(检查Settings中的状态),然后验证目标文件没有被.cursorignore排除,接着尝试换一种描述方式重新查询,最后考虑手动触发重新索引(Settings中有reindex按钮)。如果语义搜索持续找不到某段代码,可能是该代码块太短或语义不够明确,这时直接用Instant Grep通过关键词精确定位更有效。
与VS Code搜索的关键区别:VS Code的搜索功能仅支持文本匹配(Cmd+F和Cmd+Shift+F),而Cursor在此基础上新增了语义搜索(理解代码含义)、@符号上下文系统(AI感知的引用)和Explore子代理(自动化多轮搜索)。这些差异意味着在Cursor中你可以用自然语言描述搜索意图,而不必记住精确的函数名或文件路径。
常见问题
@Codebase和Cmd+Enter有什么区别?
功能上基本相同——都是让Cursor扫描代码库寻找与查询相关的代码。@Codebase是在输入框中显式引用,而Cmd+Enter(Ctrl+Enter)是通过快捷键隐式触发同样的扫描。日常使用中,如果你想强调需要全局搜索,用@Codebase更明确;如果只是正常提问但希望AI参考代码库,用Cmd+Enter发送消息更快捷。
索引会占用多少存储空间?
索引数据存储在本地,大小取决于项目规模。一个典型的500文件项目,索引大约占用50-100MB存储空间。向量嵌入本身的存储效率很高,主要空间消耗在元数据和缓存上。如果空间紧张,可以在Settings中手动清除不常用项目的索引。
语义搜索支持哪些编程语言?
Cursor的嵌入模型经过大量编程语言的训练,对主流语言(JavaScript/TypeScript、Python、Java、Go、Rust、C/C++等)的语义理解最好。对于小众语言或领域特定语言(DSL),语义搜索的效果可能较弱,此时更建议使用Instant Grep进行精确搜索。
大型monorepo项目如何优化搜索?
最有效的策略是"分而治之"。用.cursorignore排除非当前工作的子项目目录,将索引文件数控制在500-2,000个范围内。如果需要跨子项目搜索,临时注释掉.cursorignore中的排除规则,搜索完毕后恢复。另外,Cursor支持多窗口打开不同的子项目,每个窗口有独立的索引,互不干扰。
搜索结果中的代码是否会被用于模型训练?
据Cursor官方声明,索引数据和搜索查询不会用于模型训练。代码内容在索引后立即从服务器内存中清除,只保留不可逆的向量嵌入。企业版用户还可以获得额外的数据隔离和合规保障。