DeepSeek部署指南:本地试玩、图形界面、局域网服务今天该选哪条路径
基于 2026-03-19 对 Ollama、DeepSeek-R1、Open WebUI、vLLM 与 LM Studio 官方文档的核验,重写 DeepSeek 部署路径选择:先判断要不要本地部署,再决定是走 CLI、桌面 GUI、浏览器界面还是本地 API 服务。
Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
如果你现在搜的是 “DeepSeek 部署”,真正容易把人带偏的,通常不是安装命令本身,而是第一步就走错了路径。有人只是想在自己电脑上离线跑一个 DeepSeek,会被旧教程直接推进 Docker 和 WebUI;也有人真正需要局域网 API,却被“本地部署优势”这种泛化开头拖着读完整篇。结果不是部署失败,就是把本来半小时能跑通的事情,折腾成一整天。
这也是为什么 2025 年很多看上去“很全”的文章今天已经不够用了。当前 Ollama 库里 deepseek-r1:latest 对应的是 8B、模型体积 5.2GB、标称上下文 128K(Ollama Library,2026-03-19 核验),但 Ollama 默认运行上下文并不是自动就按模型标称拉满;在显存小于 24 GiB 的机器上,默认值仍是 4k(Ollama Context Length,2026-03-19 核验)。你如果先把这类运行边界搞混,后面无论是 CLI、GUI 还是本地 API,体验都会失真。
所以这篇文章不再按“硬件准备 -> 安装工具 -> 下载模型 -> 慢慢排错”的旧顺序写,而是先解决三个更现实的问题:你到底该不该本地部署、该选 Ollama CLI、LM Studio、Open WebUI + Ollama 还是 vLLM,以及为什么很多教程写着 128K 和 reasoning,结果你本机跑出来却不是你以为的样子。如果你只想快速做决定,先看下面这段 TL;DR 和后文的 DeepSeek 本地部署路径决策矩阵。
TL;DR - DeepSeek 部署结论
- 只想最快把 DeepSeek 跑起来:先用
Ollama CLI,默认从deepseek-r1开始;当前latest对应8B、5.2GB(Ollama Library,2026-03-19 核验)。- 你想要桌面 GUI、本地文档问答、又不想先碰 Docker:优先看
LM Studio。它可以离线聊天、离线做文档问答,还能在localhost或局域网提供 OpenAI-compatible endpoints(LM Studio Docs,2026-03-19 核验)。- 你要浏览器界面、模型管理、多人使用或管理员后台:再接
Open WebUI。官方当前仍把 Docker 作为 most users 的推荐安装方式,但生产环境建议 pin 具体版本,不要长期浮动:main(Open WebUI Quick Start,2026-03-19 核验)。- 你需要的是本地 API 服务而不是聊天界面:直接看
vLLM,别从 WebUI 起步。DeepSeek-R1 这类 reasoning 模型在 vLLM 下也要显式加--reasoning-parser deepseek_r1(vLLM Docs,2026-03-19 核验)。- 不要把模型标称上下文当成本机默认上下文:在 Ollama 里,
<24 GiB VRAM默认4k,24-48 GiB默认32k,>=48 GiB默认256k(Ollama Context Length,2026-03-19 核验)。- 不要把 macOS Docker Desktop 当 GPU 路线:Ollama 官方 FAQ 明确写到 Docker GPU acceleration 主要适用于 Linux 或 Windows + WSL2,macOS Docker Desktop 不支持 GPU passthrough(Ollama FAQ,2026-03-19 核验)。
- 如果你只是偶发调用,又不强依赖离线和隐私:继续用 API 可能更省,但下单前请 live-check DeepSeek 当前价格页。官方现在同时能看到
Models & Pricing与pricing-details-usd两种价格表面,口径并不完全一致(DeepSeek API Docs,2026-03-19 核验)。
今天做 DeepSeek 部署前,先判断你是不是应该本地跑
先说结论:不是每个搜“DeepSeek 部署”的人都应该做本地部署。你如果只是偶尔问几个问题、偶尔跑几段文本生成、对离线和数据本地化没有硬性要求,那么把时间花在装运行时、调上下文、看日志和清模型目录上,未必比直接调用 API 更划算。真正适合本地部署的人,通常至少满足下面三类场景之一:你要离线运行、你要把敏感文档留在本机,或者你要把模型放进自己的局域网和本地工具链里。
另一个经常被忽略的判断,是“你要的是模型,还是界面”。如果你只是想在终端里快速验证 DeepSeek-R1 能跑,Ollama CLI 已经足够。如果你真正需要的是浏览器聊天、账号管理和管理员后台,才轮到 Open WebUI。如果你更在意桌面 GUI、拖文档聊天和本地服务器开关,而不想先碰 Docker,LM Studio 会比很多旧教程默认推荐的 WebUI 路线更顺手。
还有一种人表面上在搜“本地部署”,实际上需求更像“本地 API 服务”。这类需求的关键不是聊天界面,而是稳定、兼容、方便接应用。这时候直接走 vLLM 或 LM Studio 的本地 server 会比“先装 WebUI,再想办法从 UI 退回 API”更省步骤。也就是说,DeepSeek 部署这件事,先分清你要的是 CLI、桌面 GUI、浏览器 UI 还是本地 API,成功率会高很多。
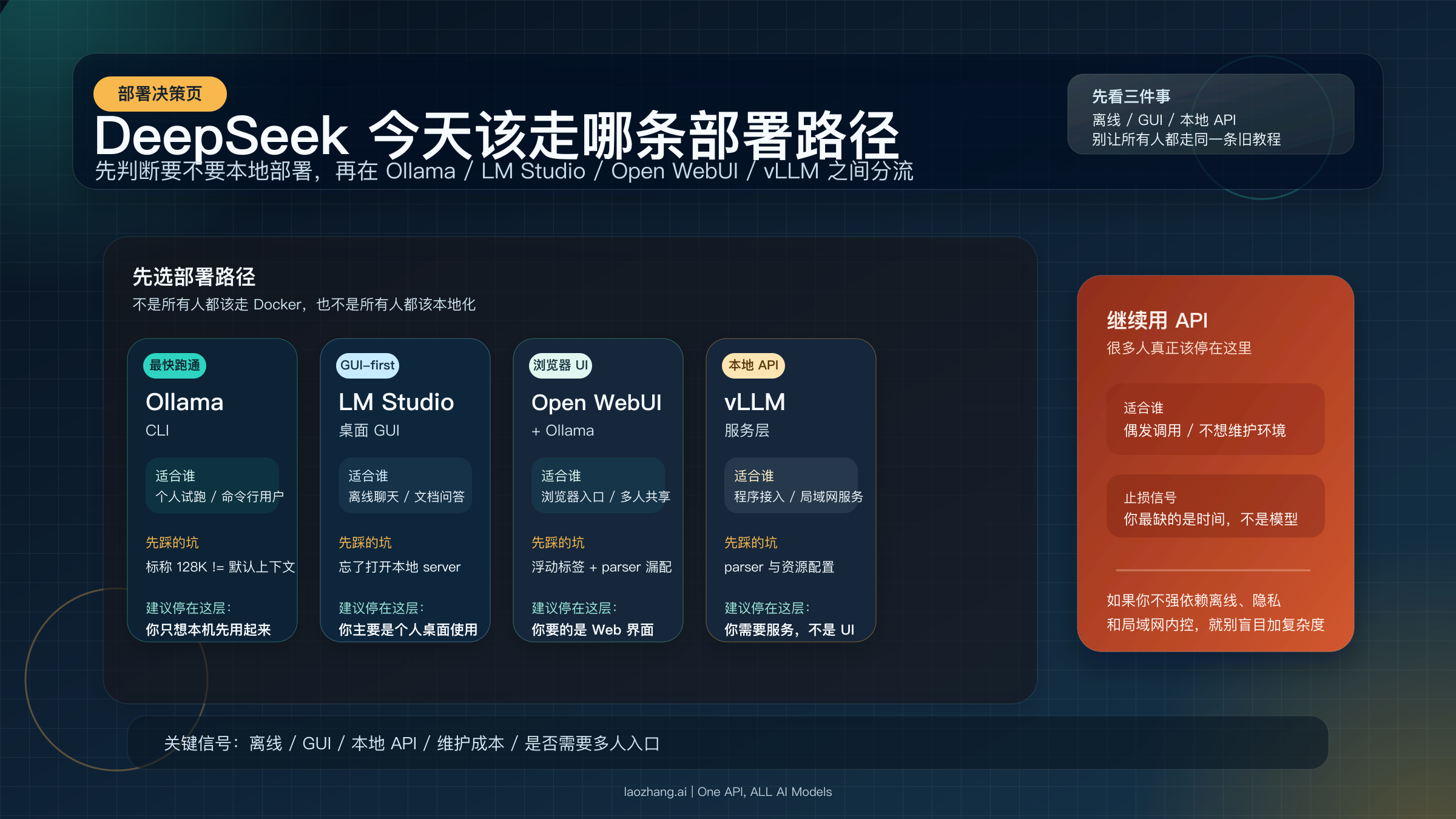
DeepSeek 本地部署路径决策矩阵:Ollama、LM Studio、Open WebUI、vLLM 怎么选
当前搜索结果里最常见的误导,就是把所有人都推进同一条链路。更好的判断方式,是先把路径选对,再去补细节。下面这张矩阵不是“工具介绍”,而是你今天真正该走哪条路。
对大多数个人用户来说,默认起点应该比很多旧教程轻。你不需要在第一步就决定 Docker、RAG、知识库和多用户权限;你只需要决定自己现在最想解决什么。如果你只是验证本机能跑,就先停在 CLI;如果你要 GUI,就选桌面 GUI 或浏览器 GUI;如果你要接程序,就直接选本地 API 服务。

| 路径 | 最适合谁 | 你先得到什么 | 你最先会踩的坑 | 建议停在哪一层 |
|---|---|---|---|---|
Ollama CLI | 只想最快跑通、愿意用终端的人 | 最少安装成本、本地 API、最快验证链路 | 以为模型标称 128K 就等于本机默认 128K | 只要你能接受命令行,就先停在这层 |
LM Studio | GUI-first、离线优先、想顺手做文档问答的人 | 桌面界面、模型下载管理、本地服务器、离线 RAG | 误把它当成“更漂亮的聊天壳”,却没用到本地 server | 只要你的需求是个人桌面使用,就没必要立刻升级到 WebUI |
Open WebUI + Ollama | 需要浏览器界面、模型管理、局域网多人入口的人 | Web 界面、管理员设置、模型私有化管理 | 直接用浮动标签、忘记 parser、把容器里的 localhost 当宿主机 | 只要你要的是聊天 UI,而不是更重的服务编排,就停在这层 |
vLLM | 要把 DeepSeek 变成更正规的本地 / 局域网推理服务的开发者 | 更明确的服务化入口、便于接应用和脚本 | 起步门槛更高,parser、模型与资源配置更容易出错 | 如果你只需要聊天,不要从这层起步 |
继续用 API | 偶发调用、不想维护本地环境、对离线无硬需求的人 | 最低维护成本、最快接入、没有本地运维负担 | 容易被“本地更专业”心理带偏,忽略自己其实不需要本地化 | 只要你不是强隐私 / 离线场景,就可以停在这里 |
如果你拿不准,最稳的默认判断其实很简单。个人用户先看 Ollama CLI,GUI-first 用户先看 LM Studio,浏览器 UI 和多人共享再看 Open WebUI,程序接入和局域网服务再看 vLLM。 这样分,比“所有人都先装 Docker”更接近真实场景。
如果你后续只想细看更窄的 Ollama + Open WebUI 路线,也可以继续读更专题化的DeepSeek本地部署完整指南。但在今天这篇里,更重要的是先把路径判断做对。
模型怎么选:不要从最大参数开始,而要从当前可验证的体积和上下文开始
旧教程最容易把模型选择写成“高端 / 中端 / 入门级”三档,但这对今天的 DeepSeek-R1 本地部署已经不够用了。当前更可靠的判断基准,是官方可见的模型体积、上下文和你的运行路径,而不是抽象性能想象。Ollama 库当前公开的 deepseek-r1 主要标签包括 1.5b / 7b / 8b / 14b / 32b / 70b / 671b,对应体积约 1.1GB / 4.7GB / 5.2GB / 9.0GB / 20GB / 43GB / 404GB;其中 8B 是当前 latest,671B 对应 160K context,其余主流蒸馏规格多为 128K(Ollama Library,2026-03-19 核验)。
DeepSeek 官方 Hugging Face model card 也确认,当前开源的 distilled checkpoints 覆盖 1.5B / 7B / 8B / 14B / 32B / 70B(Hugging Face DeepSeek-R1,2026-03-19 核验)。这意味着对大多数本地部署读者来说,真正值得优先考虑的并不是“满血版”,而是这些更现实的蒸馏路线。
| 你的目标 | 更稳的起步模型 | 为什么不是更大 |
|---|---|---|
| 先验证链路、旧笔记本或轻量机器 | 1.5B 或 7B | 下载快、失败成本低,适合先排系统和工具链问题 |
| 大多数个人本机部署 | 8B | 当前 latest 就是这条线,体积和能力更平衡 |
| 你明确需要更强本地推理 | 14B | 比 8B 更重,但还没到工作站级门槛 |
| 你已经有比较从容的本地资源 | 32B | 20GB 体积已经不是“随便试试看”的级别 |
| 你想追求极限而不是方便 | 70B 以上 | 43GB 到 404GB 已经脱离大多数个人电脑默认路径 |
这里有一个比“参数量大不大”更关键的提醒。模型标称上下文不等于你的默认运行上下文。 Ollama 当前默认规则是:<24 GiB VRAM 用 4k,24-48 GiB 用 32k,>=48 GiB 才到 256k(Ollama Context Length,2026-03-19 核验)。所以很多人明明拉了一个写着 128K 的模型,却觉得长对话表现不对,问题往往不在模型本身,而在运行时上下文还没调到目标值。
如果你使用的是 DeepSeek-R1 而不是普通 chat 模型,还要顺手把采样习惯改一下。DeepSeek 官方 model card 当前建议把 temperature 放在 0.5-0.7 区间,推荐值是 0.6,同时尽量避免 system prompt(Hugging Face DeepSeek-R1,2026-03-19 核验)。这和很多旧教程通用写法里那种“temperature 0.7 + system prompt 固定模板”并不一样。如果你主要做推理题、代码分析或多步问题,按官方建议走会更稳。
如果你还没分清楚自己到底该长期用 R1 还是别的 DeepSeek 路线,可以再对照看一下DeepSeek R1 与 V3 的区别。但只从本地部署角度说,先把 8B 或 14B 跑顺,比一开始冲更大规格更有实际意义。
最快跑通的两条路:Ollama CLI 和 LM Studio
如果你的目标是“今天先跑起来”,最值得优先看的其实是这两条路径,因为它们都能在不引入太多额外复杂度的前提下,让你尽快判断本机是不是适合继续本地化。
如果你选 Ollama CLI,重点不是命令多炫,而是链路最短。 当前官方首页和文档仍把 Ollama 作为本地运行开源模型的主入口,Linux 安装可直接用安装脚本,macOS 与 Windows 则走官方下载包(Ollama,2026-03-19 核验)。你真正需要的最小动作往往只有两步:
bashollama run deepseek-r1 ollama ps
第一条命令把当前 latest 的 8B 拉起来,第二条命令用来确认模型当前实际怎么跑、上下文是不是你以为的配置(Ollama Context Length,2026-03-19 核验)。如果你确定自己要更长上下文,再去显式设置:
bashOLLAMA_CONTEXT_LENGTH=64000 ollama serve
这条路线的价值,在于它能最快告诉你两件事:你的机器能不能把 DeepSeek-R1 跑起来,以及你究竟是在模型问题上受限,还是在运行时配置上受限。很多用户真正需要的,并不是“完整本地 AI 平台”,而是这两个判断。
如果你选 LM Studio,核心优势不是“界面更好看”,而是它对 GUI-first 用户更少阻力。 LM Studio 官方文档当前明确写到,它可以 entirely offline 运行,下载好的模型、文档对话和 local server 都能在本地完成;请求 stays local,不需要把内容发出设备(LM Studio Offline Operation,2026-03-19 核验)。这对“我想离线聊天、拖文档、顺手开个本地接口”的用户特别友好。
更关键的是,LM Studio 不是只能点界面。官方开发者文档已经给出 OpenAI-compatible endpoints 示例,默认本地地址就是 http://localhost:1234/v1/chat/completions(LM Studio Docs,2026-03-19 核验)。也就是说,你完全可以先用 GUI 下载和试模型,再按需打开本地 server,让其他工具用熟悉的 OpenAI 风格接口去接它。这条路特别适合那些“不想先学 Docker,但又想要本地 GUI + 本地接口”的读者。
如果你现在的真实需求只是“一个人、本机、今天就能开始用”,那这两条路径大概率已经够了。此时继续往 WebUI 或 vLLM 升级,并不会自动让体验变好,只会让运维面变大。
需要图形界面或本地 API 时:Open WebUI 与 vLLM 分别适合谁
很多文章把 Open WebUI 和 vLLM 写在同一层,其实它们解决的是两类问题。Open WebUI 更接近“给人用的界面”;vLLM 更接近“给程序和服务用的推理入口”。这两个工具可以连在一起,但不应该在第一步就混成一件事。
如果你要的是浏览器界面、模型管理和多人入口,优先看 Open WebUI。 Open WebUI 当前 quick start 明确写着,Docker 是对大多数用户 officially supported and recommended 的安装方式(Open WebUI Quick Start,2026-03-19 核验)。它还强调了三个对部署判断非常重要的边界:第一个账号会拿到 admin 权限、数据默认本地存储、模型默认私有,只有明确共享给组或公开后,其他人才能看到(Open WebUI Quick Start,2026-03-19 核验)。这意味着它不是一个单纯“聊天皮肤”,而是一个真正带权限和实例边界的 UI 层。
如果你只是在本机快速试跑,使用官方提供的带 Ollama 的容器变体很省事;但如果你要长期运行,官方也明确建议不要长期停留在浮动标签,而要 pin 具体 release version,保证部署稳定和可复现(Open WebUI Quick Start,2026-03-19 核验)。这正是很多旧教程没讲透的地方。它们会直接把 :main 写成长期默认值,结果用户一旦拿去当稳定环境,就会遇到复现和升级漂移问题。
对 DeepSeek-R1 来说,Open WebUI 还有一个必须前置的细节。官方 Starting with Ollama 文档专门提醒:如果你在用会输出 <think>...</think> 的 reasoning 模型,比如 DeepSeek-R1,就要按下面这种方式启动 Ollama:
bashollama serve --reasoning-parser deepseek_r1
这样 thinking blocks 才会被分离出来,以折叠形式显示在 Open WebUI 里(Open WebUI Starting with Ollama,2026-03-19 核验)。很多人把“界面里全是 <think>”误判成模型有问题,实际上只是 parser 没配。
如果你要的是更明确的本地 / 局域网推理服务,就直接看 vLLM。 vLLM 官方 reasoning outputs 文档当前对 DeepSeek-R1 给出的 quickstart 很直接:要服务 reasoning 模型,就显式加 --reasoning-parser deepseek_r1(vLLM Docs,2026-03-19 核验)。例如:
bashvllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B \ --reasoning-parser deepseek_r1
你当然可以把 vLLM 接进前端,但如果你的目标是本地 API、程序接入、局域网服务,直接从服务层起步会更顺。反过来,如果你只是想要浏览器聊天或给自己一个可视化模型下载界面,那就不要先上 vLLM。它的复杂度不是拿来奖励“更专业”感的,而是为真正的服务化场景付出的运维成本。
最容易踩的 4 个坑:上下文、reasoning parser、Docker GPU、模型目录
第一坑是把模型标称上下文当成本机默认上下文。这个误会会直接影响你对模型质量的判断。你看到 128K,不代表本机就已经按 128K 在跑;在很多机器上,默认仍可能是 4k 或 32k(Ollama Context Length,2026-03-19 核验)。如果你的症状是“长对话记性差”“贴长文档表现不如预期”,先看上下文,不要先换模型。
第二坑是 reasoning parser。DeepSeek-R1 这类模型本来就会输出思考内容,但如果你没有按 Open WebUI 或 vLLM 当前文档给出的方式加 deepseek_r1 parser,界面和接口的表现就会显得很乱(Open WebUI Starting with Ollama,2026-03-19 核验;vLLM Docs,2026-03-19 核验)。这个问题不是可选优化,而是 reasoning 模型体验是否正常的基本条件。
第三坑是把 Docker 当成跨平台 GPU 万能入口。Ollama FAQ 当前写得很清楚:Docker 里的 GPU acceleration 主要面向 Linux 或 Windows + WSL2,macOS Docker Desktop 因为没有 GPU passthrough 和 emulation,不是这条路线(Ollama FAQ,2026-03-19 核验)。所以如果你在 Mac 上的真实需求只是个人本地使用,很多时候 Ollama app 或 LM Studio 比 Docker 更符合实际。
第四坑是模型目录和数据目录不清楚,结果磁盘越跑越乱。Ollama 当前默认模型目录分别是:macOS 的 ~/.ollama/models、Linux 的 /usr/share/ollama/.ollama/models、Windows 的 C:\Users\%username%\.ollama\models;如果你要改目录,可以通过 OLLAMA_MODELS 指向新位置(Ollama FAQ,2026-03-19 核验)。这不是一个“高级技巧”,而是本地部署持续使用时迟早会碰到的维护问题。你如果不想后面再回头搬家,最好一开始就想清楚自己要把模型放哪里。
什么时候不该继续折腾本地部署,直接用 API 反而更省
本地部署最容易让人沉迷的地方,是它会制造一种“我已经投入这么多了,再加一层也没关系”的错觉。但真实世界里,很多人不是输在不会装,而是输在没有及时停。你如果只是偶发调用、不想维护环境、也不把离线和本地数据当刚需,那么继续往上加 WebUI、容器、服务编排,不一定是升级,反而可能是在把时间花到错误的问题上。
这里最有用的判断,不是“本地是不是更高级”,而是“维护成本和收益是不是对得上”。DeepSeek 官方当前仍在公开多个价格表面,Models & Pricing 与 pricing-details-usd 的数值并不完全一致,所以更稳的做法不是背某个单价,而是在真正开通前 live-check 当前价格页(DeepSeek API Docs,2026-03-19 核验)。对轻量或偶发使用者来说,真正贵的往往不是 token,而是自己搭环境、盯版本、清理模型目录和处理异常的时间。
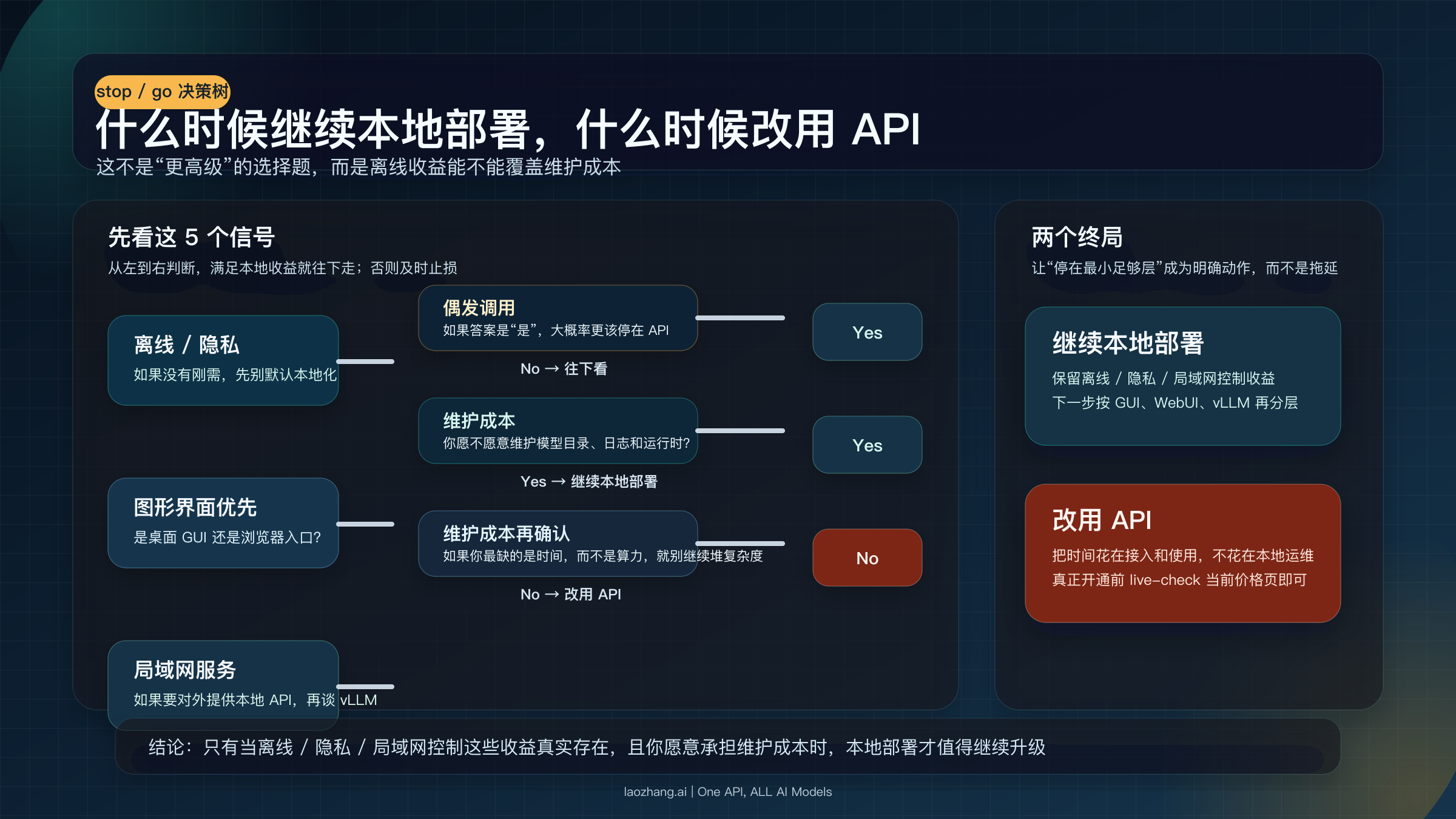
| 你的信号 | 更建议继续本地部署 | 更建议改用 API |
|---|---|---|
| 是否强依赖离线 / 本地隐私 | 是 | 否 |
| 你要的是 GUI 还是服务 | GUI 或本地服务都想长期保留 | 只是偶尔调用 |
| 你能不能接受维护本地模型和运行时 | 能 | 不能 |
| 你是否需要团队 / 局域网内控 | 是 | 否 |
| 你最缺的是算力还是时间 | 时间没那么紧,愿意维护 | 时间更宝贵,不想运维 |
如果你读到这里,已经意识到自己其实只是想要“一个能顺手调用 DeepSeek 的入口”,那停在 API 并不丢人,反而更专业。部署路径的正确性,不是看你工具装了多少,而是看你有没有停在最小足够那一层。只有当离线、隐私、本地文档处理或局域网控制这些收益真正重要时,本地部署才值得继续往上走。
如果你最后决定不做本地化,而是想把 DeepSeek 接进已有聊天客户端,可以直接去看NextChat 接入 DeepSeek 完整指南。很多用户真正需要的,其实不是“部署”,而是“可用”。
常见问题
现在本地部署 DeepSeek,默认应该先拉哪个模型?
如果你没有明确的高端工作站条件,默认从 deepseek-r1 开始最稳。当前它在 Ollama 里对应 8B、5.2GB、128K 标称上下文(Ollama Library,2026-03-19 核验)。这条线的好处是:它足够代表当前主流本地部署体验,又不会像更大规格那样把资源门槛直接拉满。只有当你已经确认 8B 不够,再考虑 14B 或更大。
LM Studio 和 Open WebUI 看起来都像 GUI,我该先选谁?
先看你要的是“桌面个人使用”还是“浏览器实例与管理”。如果你只想本机图形界面、文档问答、本地 server,LM Studio 更轻,也更适合 GUI-first 用户。它可以离线运行 downloaded LLM、文档问答和 local server(LM Studio Offline Operation,2026-03-19 核验)。如果你要的是浏览器访问、管理员设置、模型共享边界和更明显的实例管理,再去看 Open WebUI 更合理。
为什么我已经拉了 128K 模型,实际体验还是不像长上下文?
因为模型标称上下文和运行时默认上下文不是一回事。Ollama 默认会根据显存区间给上下文设一个更保守的值,在很多机器上默认只有 4k 或 32k,不是自动就跑到模型写的 128K(Ollama Context Length,2026-03-19 核验)。如果你做的是长文档或长对话任务,这一步不核对,后面所有“模型不够强”的判断都可能偏掉。
Open WebUI 或 vLLM 下出现 <think> 很乱,是不是模型坏了?
通常不是模型坏了,而是 reasoning parser 没配。Open WebUI 和 vLLM 当前文档都把 deepseek_r1 parser 写成 DeepSeek-R1 reasoning 输出的关键配置(Open WebUI Starting with Ollama,2026-03-19 核验;vLLM Docs,2026-03-19 核验)。如果你没显式加它,thinking 内容就容易直接混到最终答案显示里,读起来当然会显得混乱。
我在 macOS 上,是不是应该优先 Docker 部署?
如果你只是个人本机使用,通常不是。Ollama FAQ 已经明确写到,Docker 里的 GPU acceleration 不适用于 macOS Docker Desktop(Ollama FAQ,2026-03-19 核验)。所以对 Mac 用户来说,更常见也更现实的路径,往往是 Ollama app 或 LM Studio,而不是先把 Docker 当 GPU 部署主路线。
什么情况下我应该直接放弃本地部署,回去用 API?
当你不强依赖离线、不会把敏感数据留在本机、也不准备长期维护本地模型目录和运行时环境时,就可以认真考虑停在 API。很多人以为本地部署天然更高级,但对偶发使用者来说,真正更贵的通常不是调用费,而是维护时间。只要你把这笔时间成本算进去,就会发现“继续用 API”在很多场景下反而是更干净的答案。
如果你只想记住一句话,请记住这句:DeepSeek 部署真正该先做的,不是安装,而是分流。先判断你要不要本地部署,再判断你要的是 CLI、桌面 GUI、浏览器 UI 还是本地 API,最后才去装对应的工具。 顺序对了,部署这件事会简单很多。