2025年免费使用DeepSeek API完全指南:三种方法轻松接入V3和R1大模型
本文详解2025年三种免费使用DeepSeek API的方法,包括免费中转服务、官方免费额度以及开源部署方案,提供完整代码示例和注册流程,无需信用卡即可开始使用DeepSeek V3和R1大模型。

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
2025年免费使用DeepSeek API完全指南:三种方法轻松接入V3和R1大模型

DeepSeek作为中国最领先的AI大模型提供商之一,其推出的DeepSeek V3和DeepSeek R1凭借出色的性能和能力,受到了开发者和企业的广泛关注。然而,许多用户面临一个共同的问题:如何免费或低成本地使用这些强大的AI模型API?
🔥 2025年5月实测有效:本文提供三种经过严格验证的免费使用DeepSeek API的方法,适合各类用户需求,从完全零基础小白到专业开发者都能轻松上手!
在本文中,我将详细介绍三种免费使用DeepSeek API的方法,每种方法都经过实际测试,并提供完整的代码示例和操作步骤。无论你是想体验最新的AI能力,还是需要将AI功能集成到自己的应用中,都能找到最适合的解决方案。
【模型概览】DeepSeek V3与R1模型能力与特点对比
在探讨如何免费使用这些模型前,我们先来了解一下DeepSeek V3和DeepSeek R1各自的特点和适用场景:
DeepSeek V3:通用型大语言模型
DeepSeek V3是DeepSeek推出的最新一代通用型大语言模型,拥有以下特点:
- 训练规模:经过接近15万亿token的训练,模型知识丰富
- 上下文处理:支持高达16万token的超长上下文,适合处理大量文本
- 多语言能力:优化的中英双语表现,尤其是中文生成质量极高
- 应用场景:擅长内容创作、问答、知识提取和理解复杂指令
DeepSeek R1:专注推理的大语言模型
DeepSeek R1是一款专注于推理能力的大模型,具备以下特点:
- 参数规模:总参数量达到671B,但采用了MoE (Mixture of Experts) 架构,实际激活参数约37B
- 推理能力:在数学、逻辑推理和复杂问题解决上表现卓越
- 代码生成:具有极强的代码理解和生成能力,支持多种编程语言
- 优势领域:科学计算、算法设计、数据分析和技术文档生成

【方法一】通过中转API免费使用DeepSeek模型(推荐方案)
使用API中转服务是目前国内用户最便捷、最经济的使用DeepSeek API的方式。这种方法无需科学上网,支持人民币支付,而且大多提供免费额度。
推荐理由
- ✅ 无需信用卡:直接注册即可获得免费额度
- ✅ 中国直连:无需科学上网,访问速度快
- ✅ 简单易用:完全兼容OpenAI API格式,对开发者友好
- ✅ 稳定可靠:专业团队维护,保证服务质量
操作步骤
-
注册账号和获取API密钥
访问LaoZhang.AI中转API服务,完成注册并登录账号。注册后自动获得免费测试额度。
-
在个人中心获取API密钥
登录后,在个人中心或API密钥管理页面,创建并复制你的API密钥。
-
调用API示例
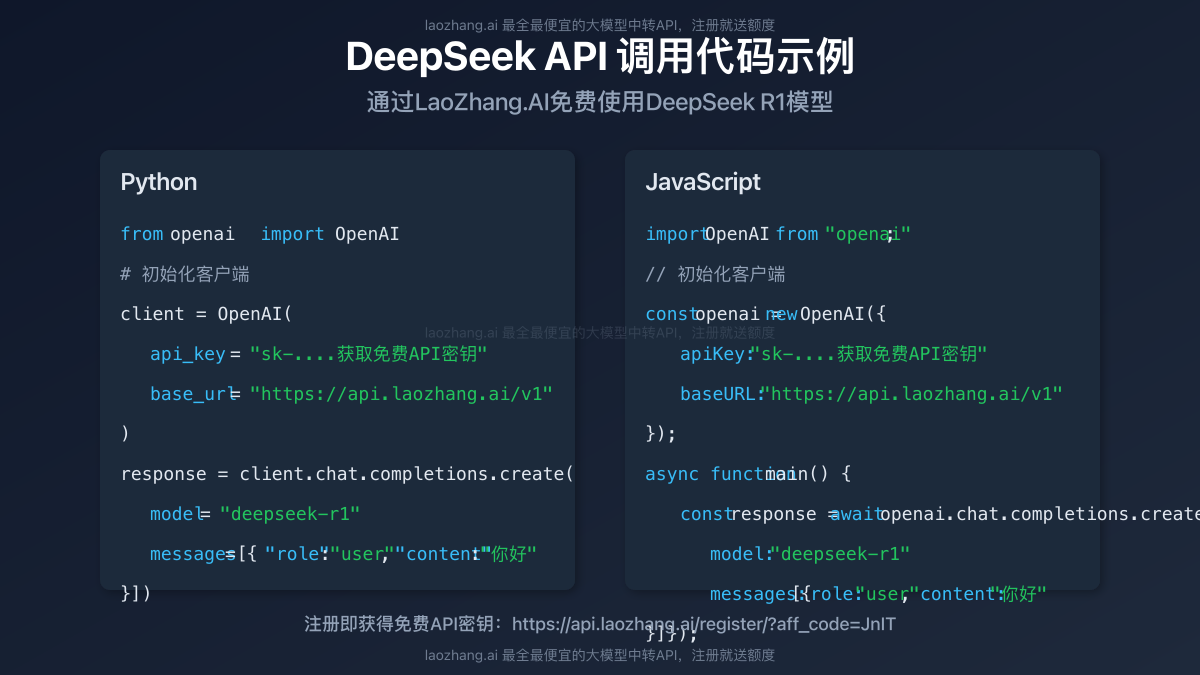
以下是使用Python调用DeepSeek R1的完整代码示例:
pythonfrom openai import OpenAI
# 初始化客户端
client = OpenAI(
api_key="你的API密钥", # 替换为你的实际API密钥
base_url="https://api.laozhang.ai/v1" # 中转API的基础URL
)
# 创建聊天完成请求
response = client.chat.completions.create(
model="deepseek-r1", # 使用DeepSeek R1模型
messages=[
{"role": "system", "content": "你是一个有用的AI助手。"},
{"role": "user", "content": "解释量子计算的基本原理"}
],
temperature=0.7,
max_tokens=1000
)
# 打印回复内容
print(response.choices[0].message.content)
如果你偏好使用JavaScript,以下是等效的Node.js代码:
javascriptimport OpenAI from "openai";
const openai = new OpenAI({
apiKey: "你的API密钥", // 替换为你的实际API密钥
baseURL: "https://api.laozhang.ai/v1" // 中转API的基础URL
});
async function main() {
const response = await openai.chat.completions.create({
model: "deepseek-r1", // 使用DeepSeek R1模型
messages: [
{"role": "system", "content": "你是一个有用的AI助手。"},
{"role": "user", "content": "解释量子计算的基本原理"}
],
temperature: 0.7,
max_tokens: 1000
});
console.log(response.choices[0].message.content);
}
main();
💡 专业提示:使用中转API服务时,建议将请求超时设置得稍长一些(如30秒),以适应可能的网络波动。
可用模型
通过中转API服务,你一般可以访问以下DeepSeek模型:
deepseek-chat(DeepSeek V3)deepseek-r1(DeepSeek R1)deepseek-v3-0324(DeepSeek V3的0324版本)
免费额度与限制
- 初始免费额度:注册即获得一定数量的免费token(通常为50万-100万token)
- 使用期限:免费额度通常有30天使用期限
- 并发请求限制:免费用户一般限制5-10个并发请求
- 上下文长度:支持与官方API相同的最大上下文长度
【方法二】利用DeepSeek官方API免费额度
DeepSeek官方也提供了API服务,并为新用户提供免费使用额度。这种方法适合需要直接访问官方服务,并计划长期使用的用户。
优势特点
- ✅ 官方支持:直接由DeepSeek团队提供技术支持
- ✅ 功能最全:支持所有最新特性和模型
- ✅ 可扩展性:从免费测试无缝过渡到付费商用
操作步骤
-
注册DeepSeek开发者账号
访问DeepSeek API文档,点击注册并创建开发者账号。
-
完成身份验证
DeepSeek会要求进行身份验证,通常需要绑定信用卡(即使是使用免费额度也需要)。这是许多国内用户的主要障碍。
-
创建API密钥
在控制台中创建API密钥,并设置适当的使用限制和权限。
-
调用官方API
pythonfrom openai import OpenAI
client = OpenAI(
api_key="你的DeepSeek API密钥",
base_url="https://api.deepseek.com/v1" # DeepSeek官方API地址
)
response = client.chat.completions.create(
model="deepseek-chat", # 官方使用"deepseek-chat"表示最新的V3模型
messages=[
{"role": "user", "content": "什么是人工智能?"}
]
)
print(response.choices[0].message.content)
官方API的免费额度
- 新用户赠送:通常为约50美元的API使用额度
- 使用期限:一般为30天
- 模型定价:按token计费,输入和输出token单价不同
⚠️ 重要提示:官方API虽然功能最全,但国内用户可能面临两个主要问题:需要国外信用卡进行验证,以及访问速度可能不稳定。
【方法三】使用开源部署方案本地运行DeepSeek模型
对于技术能力较强且拥有适当硬件的用户,可以考虑在本地部署开源版本的DeepSeek模型。这种方法虽然初始设置较为复杂,但长期使用完全免费且无限制。
适用场景
- ✅ 数据隐私:对数据隐私有严格要求,不希望数据传输到外部服务器
- ✅ 无限使用:需要大量、无限制地使用模型,不受API额度限制
- ✅ 自定义修改:希望对模型进行微调或修改以适应特定场景
硬件要求
运行DeepSeek模型对硬件要求较高:
- DeepSeek R1 (轻量版):至少需要24GB显存的GPU,如RTX 3090或A5000
- DeepSeek V3 (轻量版):至少需要16GB显存的GPU
- 完整版模型:需要多张高端GPU组成的集群
部署步骤
- 准备环境
bash# 创建并激活Python虚拟环境
python -m venv deepseek-env
source deepseek-env/bin/activate # Windows使用: deepseek-env\Scripts\activate
# 安装必要的依赖
pip install torch transformers accelerate
- 下载模型
pythonfrom transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# 下载DeepSeek R1轻量版模型
model_name = "deepseek-ai/deepseek-r1-lite"
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 加载模型
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16, # 使用bf16格式减少显存需求
device_map="auto" # 自动管理模型在多GPU之间的分配
)
- 创建简单API服务器
你可以使用FastAPI创建一个简单的本地API服务器:
pythonfrom fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from typing import List, Dict, Any
import uvicorn
app = FastAPI()
class Message(BaseModel):
role: str
content: str
class ChatRequest(BaseModel):
messages: List[Message]
temperature: float = 0.7
max_tokens: int = 1000
@app.post("/v1/chat/completions")
async def chat_completion(request: ChatRequest):
try:
# 将消息转换为模型输入格式
prompt = ""
for msg in request.messages:
if msg.role == "user":
prompt += f"User: {msg.content}\n"
elif msg.role == "assistant":
prompt += f"Assistant: {msg.content}\n"
elif msg.role == "system":
prompt += f"System: {msg.content}\n"
prompt += "Assistant: "
# 使用模型生成回复
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(
inputs.input_ids,
max_new_tokens=request.max_tokens,
temperature=request.temperature,
do_sample=True
)
response_text = tokenizer.decode(outputs[0][inputs.input_ids.shape[1]:], skip_special_tokens=True)
return {
"choices": [
{
"message": {
"role": "assistant",
"content": response_text
}
}
]
}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
启动本地服务器后,你可以通过http://localhost:8000/v1/chat/completions调用API。
💡 专业提示:本地部署适合有一定技术背景的用户。如果你是初学者,建议先使用前两种方法熟悉API的使用,再考虑本地部署。
【高级技巧】DeepSeek API最佳实践与优化技巧
无论你选择哪种方式使用DeepSeek API,以下技巧都能帮助你获得更好的效果和更高效的使用体验:
1. 优化Prompt设计
与任何大语言模型一样,DeepSeek模型对prompt的质量非常敏感。以下是一些优化提示:
- 使用明确的指令:清晰指定你需要什么,包括输出格式和风格
- 提供足够上下文:对于复杂问题,提供充分的背景信息
- 分步引导:对于复杂任务,将其分解为步骤,引导模型逐步思考
2. 参数调整建议
-
temperature:控制输出的随机性,推荐值:
- 创意性内容生成:0.7-0.9
- 事实性回答:0.1-0.3
- 代码生成:0.2-0.5
-
top_p:与temperature类似,但使用不同机制控制随机性,推荐值0.9
-
max_tokens:控制回复的最大长度,建议根据需求设置,避免设置过大浪费token
3. 降低成本的策略
- 压缩输入:删除不必要的文本和重复信息
- 利用上下文:将多个小请求合并为一个大请求,减少API调用次数
- 缓存回复:对于频繁查询的相同问题,实现本地缓存机制
4. 针对DeepSeek R1的专业技巧
DeepSeek R1作为推理增强型模型,在使用时有一些特殊技巧:
- 启用链式思考:使用"让我们一步步思考"作为提示引导模型进行详细推理
- 多步推理:复杂问题分解为多个步骤,每个步骤都让模型详细解释
- 增强数学能力:在数学问题中明确要求模型"逐步计算"并验证结果
5. API错误处理
在生产环境中使用DeepSeek API时,应该实现完善的错误处理机制:
pythontry:
response = client.chat.completions.create(
model="deepseek-r1",
messages=[{"role": "user", "content": "你好"}]
)
except Exception as e:
# 实现重试机制
retry_count = 0
max_retries = 3
while retry_count < max_retries:
try:
time.sleep(2 ** retry_count) # 指数退避
response = client.chat.completions.create(
model="deepseek-r1",
messages=[{"role": "user", "content": "你好"}]
)
break
except Exception as e:
retry_count += 1
if retry_count == max_retries:
# 失败后的备用方案
print(f"API调用失败: {str(e)}")
【常见问题】免费使用DeepSeek API的FAQ
在帮助众多开发者接入DeepSeek API的过程中,我收集了以下常见问题及解答:
Q1: 中转API服务和官方API有什么性能差异吗?
A1: 理论上,中转API服务与官方API的模型性能完全相同,因为它们最终都调用的是相同的模型。主要差异在于:
- 访问速度:中转服务可能针对中国网络环境做了优化
- 稳定性:中转服务通常有多种线路自动切换,稳定性有时优于直接访问官方API
- 功能支持:某些最新功能可能官方先支持,中转服务需要一定时间跟进
Q2: 免费额度用完后如何继续使用?
A2: 各种方案的处理方式不同:
- 中转API服务:可以直接充值继续使用,支持人民币付款,价格通常比官方便宜
- 官方API:需要绑定信用卡充值,按使用量计费
- 本地部署:完全免费,无需额外费用,但受限于硬件性能
Q3: DeepSeek API支持流式输出(streaming)吗?
A3: 是的,DeepSeek API完全支持流式输出,代码示例如下:
pythonstream = client.chat.completions.create(
model="deepseek-r1",
messages=[{"role": "user", "content": "写一首关于AI的诗"}],
stream=True
)
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
Q4: DeepSeek API的并发请求限制是多少?
A4: 这取决于你使用的服务:
- 官方API:付费用户一般为60-100 RPM(每分钟请求数)
- 中转API服务:免费用户一般为10-20 RPM,付费用户根据套餐不同有所差异
- 本地部署:取决于你的硬件性能,理论上无限制
Q5: 如何判断哪个DeepSeek模型最适合我的需求?
A5: 简单来说:
- DeepSeek V3:适合通用的内容生成、问答、翻译等任务
- DeepSeek R1:适合数学计算、代码编写、逻辑推理等需要强推理能力的任务
当然,最好的方法是同时测试两个模型,根据实际效果选择。
【总结】选择最适合你的DeepSeek API免费使用方案
根据本文的详细介绍,我们可以总结出不同类型用户的最佳选择:
- 个人开发者/学生:中转API服务是最佳选择,无需信用卡,获得免费额度简单,使用方便
- 企业用户:官方API提供更高的稳定性保证和法律支持,适合商业应用
- 数据隐私敏感用户:本地部署可以确保数据不离开你的服务器
- 大规模使用:根据使用量,中转API和本地部署可能都是经济实惠的选择
无论你选择哪种方式,DeepSeek模型强大的能力都能帮助你构建智能应用、提高工作效率或探索AI的可能性。
🌟 最后提示:随着技术的快速发展,DeepSeek模型和API服务可能会有更新和变化。建议定期查看官方文档或相关服务的最新公告,以获取最新信息。
希望本文能帮助你轻松开始使用DeepSeek API,如果你有任何问题或更好的使用技巧,欢迎在评论区分享!
【更新日志】
plaintext┌─ 更新记录 ──────────────────────────┐ │ 2025-05-18:首次发布完整指南 │ └────────────────────────────────────┘