DeepSeek本地部署完整指南:先选模型,再装Ollama与Open WebUI
这是一篇面向 2026 年实际环境重写的 DeepSeek 本地部署指南:先判断你是否应该本地部署,再按 Ollama + DeepSeek-R1 + Open WebUI 的当前官方口径完成安装、选型、调优与排障。
Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
DeepSeek本地部署完整指南:先选模型,再装Ollama与Open WebUI
如果你现在手上是一台普通笔记本,目标只是把 DeepSeek 跑起来做离线写作、代码补全,或者偶尔处理几份不想外发的文档,第一步其实不是把 Ollama、Open WebUI 和大模型一起装满。真正决定成败的,是你要不要本地部署、应该停在 Ollama CLI + deepseek-r1:8b,还是确实需要图形界面与更大的模型体积。这个判断一开始做错,后面下载的几十 GB、调试的端口和界面设置,大多都会变成返工。
所以这篇重写版不再按“先安装,再慢慢报错”的旧顺序来写,而是先给你一张三步决策矩阵:先判断本地部署值不值得,再决定模型大小,最后才决定要不要接 Open WebUI。这样你会更快知道自己应该停在哪一步,而不是先把环境堆满,再发现需求其实只是轻量本地调用。
TL;DR
- 如果你只是想确认链路能跑通,先从
deepseek-r1:1.5b或deepseek-r1:7b开始,不要一上来冲 32B。- 如果你需要默认推荐值,当前 Ollama 库里
deepseek-r1:8b仍是latest,模型体积5.2GB、上下文128K(Ollama Library,2026-03-18)。- 如果你只想本地聊天或临时试用,
Ollama CLI就够了;只有当你需要多人可视化、模型下载面板或更完整会话管理时,再接Open WebUI。- 如果你在 Open WebUI 里看到
<think>原样输出,优先检查是否按官方建议以ollama serve --reasoning-parser deepseek_r1启动(Open WebUI Docs,2026-03-18)。- 如果你的需求是稳定低维护、偶发调用、几乎不做离线处理,那么继续使用 API 往往比折腾本地更划算。DeepSeek 官方当前公开价格为输入 cache hit
$0.028/1M、cache miss$0.28/1M、输出$0.42/1M(DeepSeek API Docs,2026-03-18)。
为什么这篇教程必须重写,而不是小修小补
旧版本最致命的问题,是把已经过时的模型名和安装入口继续当成主流程来写。现在 Ollama 官方库里的 DeepSeek 主线已经是 deepseek-r1 家族,公开标签包括 1.5b / 7b / 8b / 14b / 32b / 70b / 671b,其中 deepseek-r1:8b 仍是默认 latest(Ollama Library,2026-03-18)。如果你还照着 deepseek:chat-7b 或 deepseek:R1-v3-70b 这种旧写法去执行,读者遇到的不是“体验差一点”,而是命令本身就可能不再对应官方推荐入口。
第二个问题是站点和文档地址已经换代。Ollama 当前官方文档与安装脚本都在 ollama.com 与 docs.ollama.com 体系下,Linux 安装命令也明确写成 curl -fsSL https://ollama.com/install.sh | sh(Ollama Linux,2026-03-18)。继续保留旧域名,会让文章从第一屏就失去可信度。
第三个问题更隐蔽。现在大多数用户部署 DeepSeek,并不是为了“本地大模型”这五个字本身,而是为了完成一个明确任务,例如离线问答、代码辅助、隐私文档分析,或者在公司内网跑一个不用外发数据的聊天入口。文章如果先不告诉他该选 CLI、Open WebUI 还是 API,再长的安装教程也只是把决策成本推迟,而不是消灭它。如果你还没判断清楚 R1 和 V3 更适合哪类任务,可以顺手看看 DeepSeek R1 与 V3 的区别。
先做决定:DeepSeek本地部署三步决策矩阵
先说结论。对大多数个人用户来说,本地部署不是“越完整越好”,而是“能解决你的问题就停”。真正有用的决策顺序是:先决定运行路径,再决定模型体积,最后决定要不要接图形界面。
| 你的真实目标 | 推荐运行路径 | 推荐起步模型 | 为什么这样选 |
|---|---|---|---|
| 只想确认本机能跑通 DeepSeek | Ollama CLI | deepseek-r1:1.5b 或 7b | 下载快、失败成本低,适合先验通路 |
| 日常本地问答、写作、轻量代码辅助 | Ollama CLI 或 Open WebUI | deepseek-r1:8b | 当前默认标签、体积和效果平衡最好 |
| 需要更强推理、较长上下文、多人共享界面 | Open WebUI + Ollama | deepseek-r1:14b | 比 8B 更强,但还没到工作站级门槛 |
| 有独立工作站,追求更强本地效果 | Open WebUI + Ollama 或更专业推理服务 | 32b 及以上 | 体积已到 20GB 甚至 43GB,不再适合多数笔记本 |
| 只是偶尔调用,优先低维护和弹性扩缩 | 不建议先本地 | 继续使用 API | 维护成本通常比 token 费用更高 |
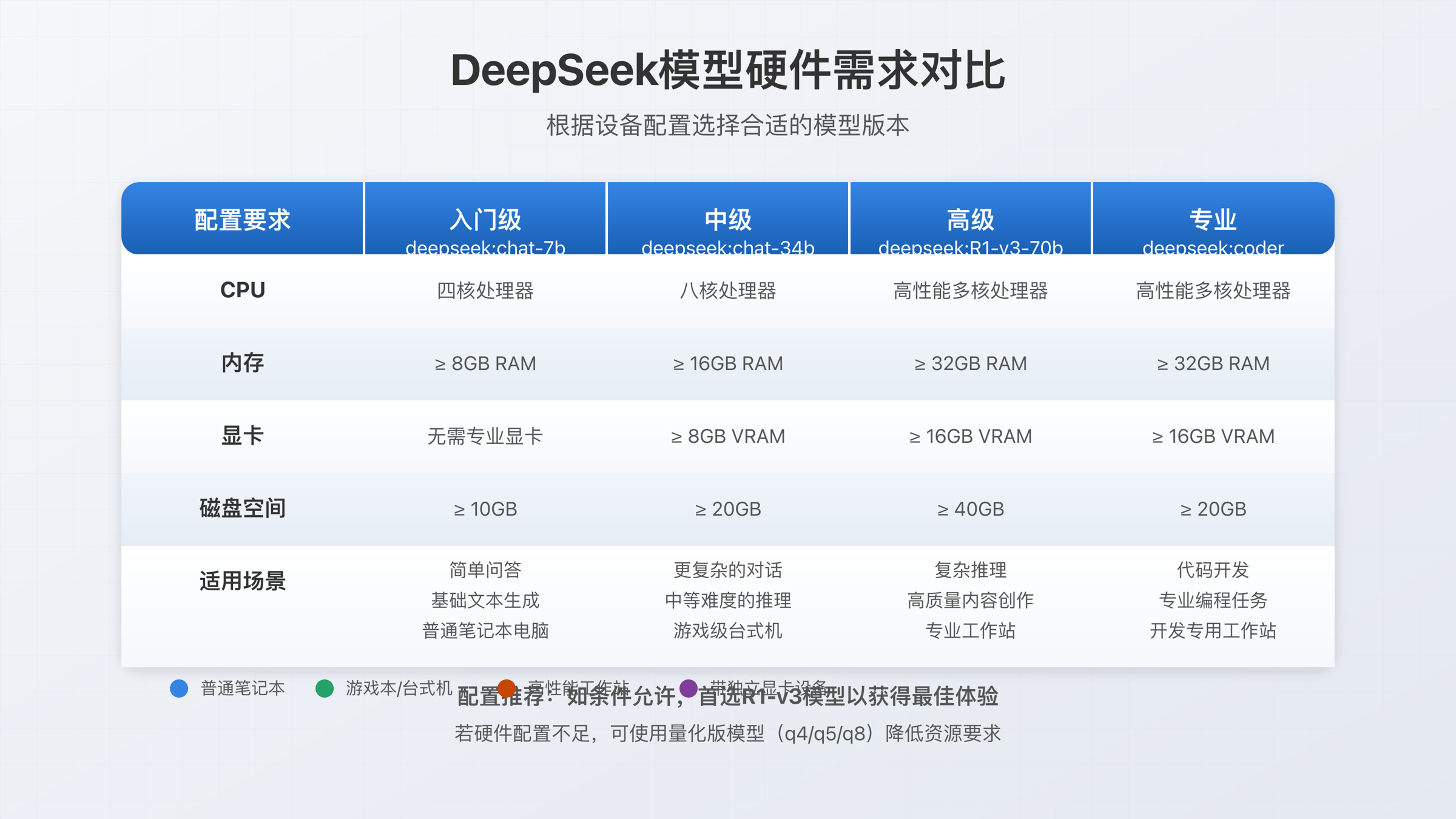
这张表里的数字不是拍脑袋给的。Ollama 官方库当前列出的模型体积分别是 1.1GB / 4.7GB / 5.2GB / 9.0GB / 20GB / 43GB / 404GB,对应 1.5b / 7b / 8b / 14b / 32b / 70b / 671b(Ollama Library,2026-03-18)。工程上你至少要给模型本体、上下文缓存、系统进程和其他应用留余量,所以当模型文件本身已经来到 20GB 或 43GB 时,把它归到“工作站级方案”是合理判断,而不是保守过度。
这里还有三个停止条件,建议你在下载前就看清楚。第一,如果你只是为了偶尔问几个问题,不需要离线、也不需要私有化数据处理,那本地部署未必是最佳路线。第二,如果你对命令行没有抗拒,但也不需要多人使用或会话管理,那么先别装 Open WebUI。第三,如果你第一次部署就已经担心磁盘空间、风扇、内存占用,那就不要把 32B 当成“更专业”的默认升级。
安装前先做一次基线检查
Ollama 目前覆盖 macOS、Windows 和 Linux(Ollama Quickstart,2026-03-18),所以系统层面并不是主要障碍,真正的门槛通常在于你的硬件目标是否和模型规格匹配。macOS 方面,官方写明最低要求是 macOS Sonoma 14 及以上,Apple M 系列支持 CPU 与 GPU,x86 仅 CPU 模式(Ollama macOS,2026-03-18)。Windows 方面,Ollama 现在已经作为原生 Windows 应用运行,并明确写到支持 NVIDIA 与 AMD Radeon GPU,同时本地 API 默认开放在 http://localhost:11434(Ollama Windows,2026-03-18)。
如果你是第一次部署,我建议把检查目标压缩成三件事。第一,系统能不能装 Ollama。第二,你是否有足够磁盘空间容纳目标模型。第三,你打算用 CLI 还是浏览器界面。不要在这个阶段就纠结 CUDA、ROCm、RAG 或容器编排,那些都属于“能跑通之后再增强”的层级。
一个常被忽略的点是上下文长度。Ollama 现在会根据显存区间设置默认上下文长度:小于 24 GiB VRAM 时默认 4k,24-48 GiB 默认 32k,大于等于 48 GiB 默认 256k(Ollama Context Length,2026-03-18)。这意味着你即使拉到了 128K 上下文模型,也未必一上来就在本机用到 128K 的实际运行配置。很多用户误以为“模型写着 128K,我就已经在 128K 跑”,问题就出在这里。
第一步:安装并验证 Ollama
Ollama 的安装现在比早期简单得多。Linux 仍然可以直接执行 curl -fsSL https://ollama.com/install.sh | sh(Ollama Linux,2026-03-18)。macOS 和 Windows 则推荐从官方下载安装包,完成后直接在本地终端调用 ollama 即可(Ollama Quickstart,2026-03-18)。
安装完成后,不要急着拉模型,先确认服务和命令行都是通的。你可以先运行:
bashollama
按照当前官方 Quickstart,ollama 会直接打开交互菜单,你可以在终端里浏览模型和工具入口(Ollama Quickstart,2026-03-18)。如果你更喜欢传统方式,也可以直接试一条 API:
bashcurl http://localhost:11434/api/chat -d '{
"model": "deepseek-r1",
"messages": [{ "role": "user", "content": "你好,请简单介绍一下自己。" }]
}'
这里的重点不是回答内容,而是确认三件事已经成立:服务在本地、端口可达、客户端和运行时没有分离。如果这一步都没通,后面无论装不装 Open WebUI,都会继续失败。
对于 Linux 用户,如果你希望后台常驻,官方文档给出了基于 systemd 的服务方式,核心进程仍然是 ollama serve(Ollama Linux,2026-03-18)。对于 macOS 用户,日志和模型默认位于 ~/.ollama 与 ~/.ollama/logs(Ollama macOS,2026-03-18)。这两个目录后面排障时非常有用,记住比记住十个“玄学修复”更重要。
第二步:按模型体积而不是参数崇拜来选 DeepSeek-R1
DeepSeek-R1 当前在 Ollama 中最适合个人本地部署的,不是满血版 671b,而是蒸馏模型线。官方库列出的主要标签包括:1.5b 为 1.1GB、7b 为 4.7GB、8b 为 5.2GB、14b 为 9.0GB、32b 为 20GB、70b 为 43GB,主流蒸馏模型上下文均为 128K(Ollama Library,2026-03-18)。DeepSeek 官方 Hugging Face 模型卡也确认公开蒸馏型号覆盖 1.5B / 7B / 8B / 14B / 32B / 70B(DeepSeek Hugging Face,2026-03-18)。
对大多数第一次部署的读者,我的建议很直接。只要不是明确知道自己需要更大的推理能力,就从 deepseek-r1:8b 开始。它是当前 latest,等于你执行 ollama run deepseek-r1 时默认会拉到的版本(Ollama Library,2026-03-18)。如果你机器偏老、只是试通路,就退到 1.5b 或 7b。如果你已经有比较从容的本地资源,又确实需要更稳定的长问答和更强推理,再考虑 14b。
常用命令如下:
bash# 默认推荐:latest 当前对应 8B
ollama run deepseek-r1
# 更轻量
ollama run deepseek-r1:1.5b
ollama run deepseek-r1:7b
# 更强,但门槛更高
ollama run deepseek-r1:14b
ollama run deepseek-r1:32b
如果你看到一些旧内容还在推荐 deepseek:coder 或 deepseek:chat-34b,可以直接把它视为历史版本语境。现在 DeepSeek-R1 系列已经成为本地部署的主流入口,而且 Ollama 库中还注明了 8B 与 671B 已获得 DeepSeek-R1-0528 minor upgrade(Ollama Library,2026-03-18)。这也是为什么今天继续写“2025年最佳命令”意义不大,真正有意义的是跟着当前官方标签走。
第三步:只有在需要图形界面时,再接 Open WebUI
不少教程会把 “装 Docker + 装 Open WebUI” 写成必经之路,这其实不够诚实。你如果只是一个人用、对终端不排斥、也不需要会话管理和管理员后台,那么只跑 Ollama 就够用了。Open WebUI 真正值得安装的场景,是你希望用浏览器聊天、在管理后台拉取模型、给同事或家人提供可视化入口,或者未来准备继续接知识库与权限体系。
Open WebUI 官方首页现在给出的 Docker 快速启动命令是:
bashdocker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway \ -v open-webui:/app/backend/data \ --name open-webui \ --restart always \ ghcr.io/open-webui/open-webui:main
如果 Ollama 跑在宿主机,官方连接文档明确建议把 Open WebUI 中的 Ollama 地址设为 http://host.docker.internal:11434(Open WebUI Docs,2026-03-18)。这比很多博客里随手写的 localhost 更关键,因为容器内的 localhost 指向的是容器自己,而不是你的主机。
Open WebUI 还有一个对 DeepSeek-R1 非常重要的细节。官方文档专门写到,推理模型如果会输出 <think>...</think>,应当通过以下方式启动 Ollama:
bashollama serve --reasoning-parser deepseek_r1
这样 Open WebUI 才能把 thinking 部分折叠显示,而不是把推理标记原样铺在聊天正文里(Open WebUI Docs,2026-03-18)。这就是为什么很多人说“装好了但看起来很乱”,问题不一定在模型,而在 parser 没配。
如果你不想用 Docker,Open WebUI 官方也提供了基于 uv 与 pip 的本地安装方式,并明确推荐优先使用 uv(Open WebUI Docs,2026-03-18)。这一点对 Windows 用户尤其友好,因为很多人只是为了一个浏览器界面,没必要先背上完整容器环境。
第四步:上线后最影响体验的三件事
真正把本地部署体验拉开差距的,通常不是“有没有成功运行”,而是三个更细的设置:上下文长度、是否把推理输出正确分离、以及你有没有查看日志。Ollama 的上下文长度默认会根据显存自动设置,而不是总按模型标称最大值运行(Ollama Context Length,2026-03-18)。如果你做的是代码、长文档或者多轮任务,看到回复很快但“记性不好”,第一反应应该是检查上下文,而不是盲目换大模型。
如果你需要更长上下文,官方给出的方式是在服务启动时显式设置,例如:
bashOLLAMA_CONTEXT_LENGTH=64000 ollama serve
同时,官方建议用 ollama ps 检查模型是否真的主要在 GPU 上运行,因为一旦大量 offload 到 CPU,速度和交互感受会明显下降(Ollama Context Length,2026-03-18)。这类问题不是“模型不行”,而是资源路径不对。
第二件事是日志。macOS 下,Ollama 日志默认在 ~/.ollama/logs(Ollama macOS,2026-03-18);Linux 下,如果你按官方方式把它托管为系统服务,那么 journalctl -e -u ollama 就是第一查看入口(Ollama Linux,2026-03-18)。很多排障其实不需要搜论坛,日志里已经写明了端口占用、模型加载失败或权限问题。
第三件事是别把“更大模型”当成唯一优化手段。对多数用户而言,正确的提升顺序应该是:先确认本地链路稳定,再确认上下文长度和 parser 是否正确,然后再考虑从 8b 升到 14b。如果你还没有把这些基础环节跑顺,直接跳到 32b 往往只会把问题放大。
高频故障排查:四类问题先看哪里
本地部署最常见的报错,表面上很像随机问题,实际上大多可以归到四类。
第一类是 ollama 已安装但服务不通。这时先访问或请求 http://localhost:11434,再检查是不是另一个进程占了端口。Windows 默认 API 就在这个地址(Ollama Windows,2026-03-18),所以如果端口不通,后面所有上层工具都会一起失效。
第二类是模型能运行,但表现和你预期差距很大。这里优先核对你实际下载的是不是想要的标签。deepseek-r1 默认就是 8b,不是 32b,也不是历史上的别名(Ollama Library,2026-03-18)。其次再看是否因为默认上下文较低,导致多轮表现被误判为“模型太弱”。
第三类是 Open WebUI 连不上 Ollama。容器环境下,最常见错误就是还在用 localhost:11434。官方写得很明确,Docker 用户如果 Ollama 跑在宿主机,推荐用 http://host.docker.internal:11434(Open WebUI Docs,2026-03-18)。这一点如果错了,界面会看起来“已经启动”,但实际拉不到模型列表。
第四类是界面里出现大量 <think>,或者回答结构混乱。这不是 DeepSeek-R1 独有 bug,而是 reasoning 模型的展示方式没有被正确解析。按官方方式以 ollama serve --reasoning-parser deepseek_r1 启动,通常就能回到正常显示(Open WebUI Docs,2026-03-18)。
常见问题(FAQ)
Q1:现在本地部署 DeepSeek,默认应该拉哪个模型?
如果你没有非常明确的高端工作站条件,默认从 deepseek-r1 开始就够了。当前它对应 deepseek-r1:8b,体积 5.2GB、上下文 128K(Ollama Library,2026-03-18)。这是目前最稳妥的起点,因为它兼顾了下载体积、推理能力和复用价值。只有当你已经确认 8B 无法满足任务,再考虑 14B 或更大规格。
Q2:本地部署一定要装 Docker 和 Open WebUI 吗?
不一定。Docker 和 Open WebUI 是“增强层”,不是“起步层”。你只要能接受命令行,Ollama 本身就已经足够完成本地聊天和 API 调用。真正需要 Open WebUI 的场景,是你希望在浏览器里管理模型、提供多人入口、或者希望后续继续接知识库等功能。把它们当成可选而不是必选,部署成功率会高很多。
Q3:为什么我已经看到 128K 模型,但实际体验不像 128K?
因为模型标称上下文和运行时默认上下文不是一回事。Ollama 会按显存区间设置默认值,小于 24 GiB VRAM 时默认只有 4k,24-48 GiB 才会到 32k,更高显存才可能默认 256k(Ollama Context Length,2026-03-18)。如果你的任务很依赖长上下文,需要显式调整服务启动参数,而不是只看模型名。
Q4:Open WebUI 里为什么会直接显示 <think>?
这通常说明 reasoning parser 没配好。DeepSeek-R1 这类推理模型会把思考过程包在 <think>...</think> 里,Open WebUI 官方建议以 ollama serve --reasoning-parser deepseek_r1 启动 Ollama,这样 thinking 区块会被折叠显示(Open WebUI Docs,2026-03-18)。如果不做这一步,界面虽然能用,但阅读体验会明显变差。
Q5:我到底该继续本地部署,还是回去用 DeepSeek API?
看你的目标,而不是看别人怎么说。如果你重视离线、隐私、可控性,或者希望把文档与会话留在本机,本地部署是值得的。如果你只是偶尔调用、想少维护、对离线没有强需求,那么 API 更轻。DeepSeek 当前官方公开价格是输入 cache hit $0.028/1M、cache miss $0.28/1M、输出 $0.42/1M(DeepSeek API Docs,2026-03-18),对轻量使用者来说,真正昂贵的往往不是 token,而是自己维护环境的时间。
Q6:第一次部署时,什么情况下不要再往更大模型升级?
只要你还没把“安装成功、链路稳定、上下文合适、界面显示正常”这四件事确认完,就先不要升级。更大模型不会替你修复端口、连接、日志或 parser 问题。相反,它只会让下载更慢、排障更难、资源占用更高。我的建议是先把 8B 跑顺,再决定要不要进到 14B;只有当你明确知道自己为什么需要 32B 以上,才值得去承担那一级别的资源消耗。
总结:正确顺序不是“先安装”,而是“先判断,再安装”
如果你只记住一句话,那就是不要再从旧命令和旧模型名开始。今天更新后的正确路径是:先判断自己到底需不需要本地部署,再用 Ollama 把链路跑通,然后按模型体积做选择,最后在确实需要图形界面时再接 Open WebUI。
这样做的好处不是文章看起来更“高级”,而是它更符合真实用户的决策过程。你不会因为教程一上来就推 32B 或 Docker,而把一次本可以在半小时内完成的本地部署,拖成一整天的折腾。如果后续你还想继续扩展到知识库或内网协作,这套结构也能无缝延伸,而不是推倒重来。