DeepSeek 小红书创作指南:模型分工、Prompt 模板与发布前质检
不是让 DeepSeek 一键批量出稿,而是用对 deepseek-chat、deepseek-reasoner 和人工改写的分工。本文给出小红书创作流程、任务矩阵、Prompt 模板与发布前质检表。
Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
如果你已经试过用 DeepSeek 一次性生成整篇小红书笔记,大概率会遇到同一个问题:内容看上去完整,但发出去像模板,评论区一追问就露馅。问题通常不在于模型不够强,而在于你把它当成了“一键出稿器”。
这篇文章只解决一件事:DeepSeek 在小红书创作里到底该放在哪些环节,哪些内容必须人工接手。 当前 API 中的 deepseek-chat 与 deepseek-reasoner 都对应 DeepSeek-V3.2,支持 128K 上下文(DeepSeek API Docs,2026-03-19 19:49 CST 复核)。这意味着它很适合做选题判断、结构整理、改写润色和评论区预判,但不适合替你虚构真实经历、拍脑袋下结论,或者直接扮演一个有生活细节的小红书博主。
TL;DR
- 要快写标题、整理结构、把口语改顺,用
deepseek-chat。- 要做选题取舍、判断卖点顺序、预判评论区异议,用
deepseek-reasoner或在deepseek-chat上开启thinking。- 涉及个人经历、产品结论、截图事实、价格细节和平台敏感表达,必须人工复核。
- 真正决定小红书质量的,不是“能不能一次生成 1000 篇”,而是“有没有把 AI 输出改成你的判断和你的场景”。
- 如果一篇笔记同时出现“像模板、没有细节、结论太满、评论区一问就穿帮”这几类信号,不要直接发。

为什么 2025 年那套 DeepSeek 小红书写法,现在不够用了
旧教程最常见的写法,是把 DeepSeek 等同于“更懂中文的爆款生成器”,然后给你一堆模板,默认你只要多喂几个关键词,就能批量产出可发的笔记。这种方法在流量窗口期很吸引人,但放到今天已经不够用了,因为模型接口、平台语境和读者期待都变了。
先看模型侧。很多旧文还在用“R1 模式”这种静态说法,但官方现在给出的接口逻辑更清楚:你要么直接调用 deepseek-reasoner,要么在 deepseek-chat 上通过 thinking 参数开启思考模式(DeepSeek API Docs,2026-03-19 19:49 CST 复核)。这不是命名小修小补,而是在提醒你,不同任务应该用不同模式,而不是让一个统一 prompt 从标题一直写到发布文案。
再看平台侧。2025 年 2 月,36Kr 在报道小红书 AI 搜索产品“点点”时提到,小红书虽然接入了 DeepSeek,但对主站的大范围接入保持谨慎,原因就在于社区氛围、版权和内容真实性的平衡(36Kr 报道,2026-03-19 19:49 CST 复核)。这对创作者的含义很直接:你可以用 AI 提效,但不能把“像社区内容”理解成“用 AI 模仿社区语气就够了”。
所以这篇文章不会继续教你“一条超级提示词搞定全部流程”。更稳的做法,是把 DeepSeek 当成协作者:让它负责快、宽、结构化的部分,把需要经验、证据和判断的部分留给你。
DeepSeek 现在适合做哪些小红书任务,哪些别直接交给它
如果你只记一个判断,请记这个:DeepSeek 在小红书里最强的不是代写,而是分工。 deepseek-chat 更适合快节奏的草拟、改写和格式整理;deepseek-reasoner 更适合处理“应该先讲什么”“读者会反驳什么”“这两个角度哪个更稳”之类的判断题。
官方文档还给了两个很实用的边界。第一,deepseek-chat 默认最大输出是 4K、上限 8K,而 deepseek-reasoner 默认 32K、最大 64K(DeepSeek API Docs,2026-03-19 19:49 CST 复核)。第二,思考模式会返回 reasoning_content,所以它更适合在“先想清楚再下笔”的环节使用,而不是拿去堆一大段最终文案。
真正决定效果的,不是你会不会写“请生成 10 篇爆款笔记”,而是你有没有先把任务拆开。下面这张图和表可以直接照着用。

| 创作环节 | 更适合谁 | 为什么 | 不要这样用 |
|---|---|---|---|
| 选题判断 | deepseek-reasoner | 需要比较多个角度、目标人群和反对意见 | 让模型直接拍板“这个一定会爆” |
| 标题草案 | deepseek-chat | 需要速度、变体和多版本试写 | 只保留第一轮标题,不做人审 |
| 正文骨架 | deepseek-chat + 人工 | 适合先把结构、段落顺序和核心点列出来 | 让模型凭空补真实细节 |
| 改写润色 | deepseek-chat | 擅长压缩、换口语、调整顺序 | 把“去 AI 腔”理解成“多加口头禅” |
| 评论区互动预判 | deepseek-reasoner | 适合模拟读者追问、挑刺和异议 | 直接拿推理链内容去发评论 |
| 发布前质检 | 人工 | 需要核实事实、经历、价格和平台敏感表达 | 把最后一轮检查也交给模型 |
如果你想直接套一条默认路线,单人创作者最稳的是“deepseek-reasoner 先定角度,再用 deepseek-chat 出 3 个标题和 1 版骨架,最后人工补经历与删空话”;团队周更更适合把栏目规范和禁写项做成固定前缀,让 deepseek-chat 反复改写,把 deepseek-reasoner 留给选题会前的判断;如果你做矩阵号或商业内容,应该先由人工定死真实性边界、敏感表达和评论区答法,再让模型生成变体,而不是反过来。
你会发现,最该人工接手的,恰好是最容易让账号翻车的部分:个人经验、产品结论、截图事实、价格口径、评论区被追问时能不能接得住。这也是为什么很多“看起来很顺”的 AI 初稿,一旦发出去就失真。
一套可执行的 4 步工作流:从选题到可发布初稿
第一步不是写 prompt,而是准备素材包。你至少要把这三类东西先整理出来:你自己的真实场景、想覆盖的目标读者问题、能证明结论的细节素材。素材可以是评论区高频问题、自己过去写过的笔记、产品使用截图、客户反馈、线下观察记录。没有这些,模型只能输出平均值。
第二步用 deepseek-reasoner 做“判断”,而不是让它直接写整篇。你可以把 3 到 5 个候选题目、受众和卖点一次性丢进去,让它帮你判断哪个角度更适合当前账号,顺便预判读者最可能质疑什么。这个步骤的目标不是得到漂亮文案,而是得到更稳的写作顺序。
第三步再把判断结果交给 deepseek-chat,让它做标题草案、段落骨架和表达压缩。deepseek-chat 擅长把一堆信息快速整理成可写的结构,尤其适合做 3 到 5 个版本的标题、开头和结构草案。这个阶段你要反复限定它不要脑补经历,不要编造数字,不要代替你给出“绝对正确”的结论。
第四步一定是人工回写。也就是说,你要把自己的语气、经历、例子和删除动作加进去。真正能把账号从“像 AI”拉回“像一个人在说话”的,通常不是多写几句口头禅,而是删掉那些四平八稳但没信息量的句子,再补进你真正见过、做过、踩过坑的细节。
如果你有周更需求,这套流程还可以复用。因为 DeepSeek 的上下文缓存默认开启,你在重复使用固定写作规范、栏目说明或品牌语气时,命中部分会变便宜,返回中还能直接看到 prompt_cache_hit_tokens 和 prompt_cache_miss_tokens(DeepSeek API Docs,2026-03-19 19:49 CST 复核)。它更像一个长期使用的写作工作台,而不是一次性大促工具。
4 组真正够用的 Prompt 模板
这部分只给四组模板,因为对小红书来说,够用的模板比“更多模板”更重要。如果你需要更长的模板库,可以再看站内的DeepSeek 小红书 Prompt 模板整理;但真正开始写时,我建议先把下面四组用熟。
1. 选题判断模板:先决定写什么,再决定怎么写
text你现在是我的内容策划搭档,不直接写正文,只做判断。 我的账号定位:[一句话定位] 目标读者:[一句话描述] 我这周能写的 3 个题目: 1. [题目A] 2. [题目B] 3. [题目C] 请按以下格式输出: 1. 哪个题目最适合本周先写,原因是什么 2. 每个题目最容易踩的空话或套路化表达 3. 读者最可能追问的 3 个问题 4. 建议先讲什么,再讲什么,最后讲什么 不要直接生成正文,不要虚构案例。
2. 标题草案模板:要多版本,不要一稿定生死
text请基于下面这篇笔记的真实核心,输出 12 个中文标题草案。 笔记核心: - 读者是谁:[人群] - 这篇要解决什么问题:[问题] - 我真正的结论:[一句话] - 不想出现的风格:[例如:过度夸张、像广告、像鸡汤] 要求: 1. 分成 3 组风格:直接型、经验型、反常识型 2. 每个标题 14-22 字 3. 不使用“绝绝子”“闭眼冲”这类空泛词 4. 不承诺结果,不虚构数字
3. 正文骨架模板:先拿结构,再填细节
text请根据以下信息,为一篇小红书笔记生成正文骨架,不要写成完整终稿。 主题:[主题] 目标读者:[读者] 必须保留的真实信息: - [细节1] - [细节2] - [细节3] 请输出: 1. 开头两段应该先说什么 2. 正文分成 4 段,每段的核心任务是什么 3. 哪些位置必须由人工补真实经历 4. 哪些句子最容易写成模板腔,需要避免
4. 去 AI 腔改写模板:不是更花,而是更像你
text下面是一篇小红书初稿,请帮我做“去 AI 腔”改写。 改写规则: 1. 删除空泛总结句 2. 避免一段里出现两个以上抽象形容词 3. 保留信息密度,但改成更像人口语 4. 如果某处缺少真实细节,请直接标注“这里需要人工补细节” 5. 不要编造经历,不要新增不可验证的数字 初稿: [粘贴正文]
这四组模板组合起来,基本已经覆盖了小红书创作中最有价值的环节。真正的提升不是“模型输出更像网红”,而是你能更快地筛掉烂角度、压缩空话,并把自己的判断放到该放的位置。
成本怎么算,什么时候值得开思考模式
如果你是为了小红书创作接入 DeepSeek API,先记住一组足够实用的数字就行:输入缓存命中 $0.028 / 1M、输入缓存未命中 $0.28 / 1M、输出 $0.42 / 1M(DeepSeek API Docs,2026-03-19 19:49 CST 复核)。换句话说,单篇笔记的 API 成本通常不是瓶颈,真正贵的是你没有素材、没有判断、还把低质量初稿来回重写三轮。
这里给你一个简化估算。假设你在“单篇笔记”里用了 8K 输入和 4K 输出,而且输入都按未命中计算,那么一次完整草拟的成本大约是 $0.00392。如果你一周写 10 篇,粗算也只是几美分级别。对于大多数创作者来说,API 费远低于返工成本。
| 场景 | 粗略 token 假设 | 估算成本 |
|---|---|---|
| 20 个标题草案 | 输入 3K + 输出 1.2K | 约 $0.0013 |
| 1 篇正文骨架 + 初稿 | 输入 8K + 输出 4K | 约 $0.0039 |
| 10 篇周更笔记草拟 | 输入 80K + 输出 40K | 约 $0.0392 |
如果你是单人创作者,最省事的组合通常是“deepseek-reasoner 只在选题判断时开一次,后面都切回 deepseek-chat”。如果你是团队协作,反而更应该把固定栏目说明、语气规范和禁写项做成稳定前缀,让缓存命中逐步把重复改写成本压下来。这样省下来的不是 API 费,而是编辑来回返工的时间。
那什么时候值得开思考模式?我的建议很简单:只有在你需要取舍时再开。 比如你要在三个选题之间做判断、你担心评论区会从哪个角度质疑、你想先排卖点顺序,这时 deepseek-reasoner 更划算,因为它能把思考过程和最终结论拆开,帮你先想清楚再写。
相反,如果你只是想把一句口语整理顺、把段落改短、把结构换一种顺序,直接用 deepseek-chat 更合适。小红书内容的难点往往不在“推理不够深”,而在“口吻不够真”。深想模式解决的是判断题,不是人格问题。
如果你通过第三方 OpenAI-compatible 网关接入 DeepSeek,也建议先确认三件事:模型别名是不是还是 deepseek-chat / deepseek-reasoner,计费字段是否保留缓存命中与未命中区分,以及返回里能否看到缓存统计。这里不建议默认依赖任何第三方文案说明,直接以官方接口文档和自己的请求结果为准。
发布前质检:出现这 7 个信号时,不要直接发
很多人把质检理解成“检查错别字”,这对小红书远远不够。小红书真正的风险点不是文字有没有错,而是内容一旦进入评论区追问,你能不能接得住。凡是接不住的问题,通常都不是排版问题,而是写作过程把不该交给模型的部分也交出去了。
我自己的判断标准是:一篇 AI 辅助笔记,如果在发布前已经露出明显的模板感、经历感缺失或结论过满,那就别靠“加几个表情”和“改两句口语”硬救。这类稿子最好的处理方式,是退回到素材和结构层重来。
下面这张图可以直接当发布前决策树使用。你不需要每次都逐字对照,但至少要知道自己在哪个节点该停下来。
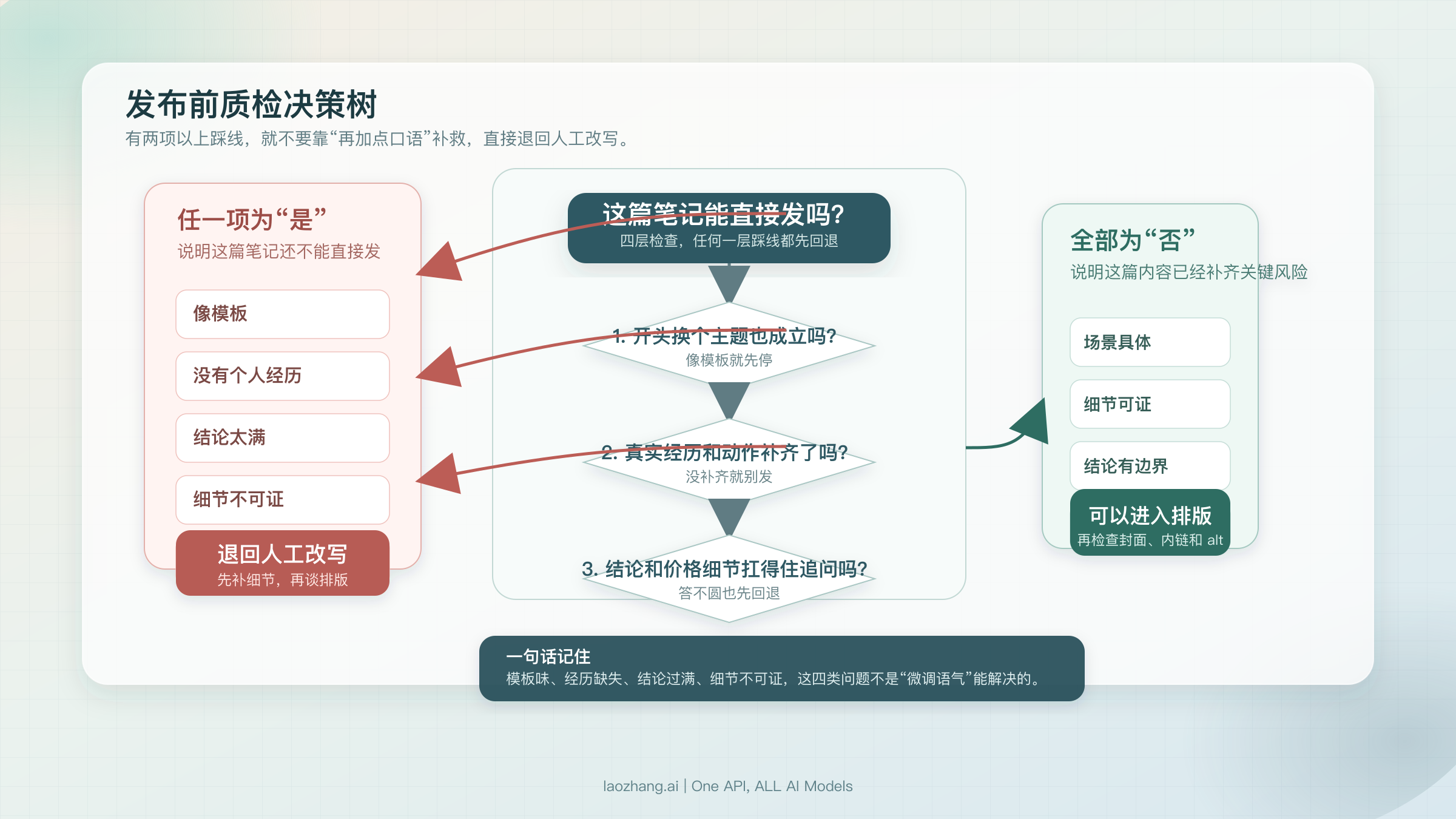
如果你在发布前检查时,出现下面 7 个信号中的 2 项以上,我建议直接退回人工改写:
- 开头换个主题也成立,说明这不是你的场景,只是模板开场。
- 全文没有一处真实经历、真实动作或真实观察,说明模型只在输出平均答案。
- 结论特别满,但没有任何证据、截图、体验或边界条件支撑。
- 所有段落都很顺,却没有一句能让读者记住你是谁、你为什么这么判断。
- 一问细节就穿帮,比如价格、功能、时间、渠道、体验顺序讲不圆。
- 过度模仿“小红书腔”,结果出现堆叠口头禅、密集感叹句和虚高情绪。
- 你自己读完都觉得“像是对的,但不像我会说的话”。
一个很实用的动作,是在发之前自己追问三次:“这句话如果有人问我‘你怎么知道’,我能答出来吗?” 只要有两三处答不出来,就不要发。小红书不是考试作文,读者会顺着评论区把你的细节挖出来。
常见问题 FAQ
DeepSeek 适合直接生成整篇小红书笔记吗?
可以生成初稿,但不建议直接发布。更稳的方式是让它先做结构、标题和改写,再由你补进真实经历、截图依据和最后的结论。整篇一把梭通常效率高,但返工率也高。
deepseek-chat 和 deepseek-reasoner 该怎么选?
如果任务核心是“快写、改写、整理表达”,选 deepseek-chat。如果任务核心是“比较、判断、预判异议”,选 deepseek-reasoner 或开启 thinking。最简单的区分方式就是看它是在回答“怎么说”,还是在回答“为什么这么排”。
小红书内容一定要模仿平台流行语才会更像真人吗?
不一定。很多 AI 腔恰恰是因为过度模仿平台流行语,导致每篇都像同一个人在说话。比起堆口头禅,更重要的是把你的场景、动作和判断写出来。
周更账号有必要接 API 吗?
如果你每周只写一两篇,官方网页端就够用。如果你已经形成固定栏目、经常复用写作规范,或者要做批量改写和团队协作,API 会更适合,因为缓存、结构化输入和多轮工作流都更好管。
怎样判断一篇 AI 辅助内容是不是已经可以发了?
最简单的办法是连做 3 步。先看“任务分配矩阵”,确认该人工负责的部分没有偷懒交给模型;再看文中每一个关键判断,你是不是都能拿出经历、截图或来源去支撑;最后模拟评论区追问三轮,确认别人问“你怎么知道”“这个价格现在还对吗”“你自己是不是这么做的”时,你都答得出来。三步里只要有一步过不了,这篇稿子就还只是一个看起来完整的草稿,不是可发布稿。