Flux ComfyUI图像到图像完全指南:参数优化与工作流配置教程2025
本文详解Flux在ComfyUI中的图像到图像转换能力,覆盖参数优化、工作流配置和实战技巧,帮助您高效利用这款强大AI工具。2025年最新测试有效。

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
Flux ComfyUI图像到图像转换工作流完全指南(2025年7月实测有效)
🔍 时效性声明: 本文所有参数、设置和效果分析均基于2025年7月的最新版Flux.1模型测试得出,确保为您提供当前最准确的图像到图像转换技术指导。
在AI图像生成领域,Flux.1已经以其卓越的理解力和图像生成能力迅速占据市场。而ComfyUI作为一个强大的图形化界面,为我们提供了充分利用Flux模型的灵活方式。本文将深入探讨如何在ComfyUI中设置并优化Flux的图像到图像(Image to Image)转换功能,帮助您将创意无缝转化为高质量图像。
无论您是希望对已有图像进行风格转换、增强细节,还是在保留原始构图的基础上进行创意改造,本指南都能帮助您达成目标。通过精确的参数调整和工作流优化,您将获得更可控、更专业的创作体验。
什么是Flux图像到图像转换?
Flux Image-to-Image(图像到图像)是指在已有图像基础上,利用AI模型根据文本提示词进行创意转换的过程。相比纯文本到图像(Text-to-Image),这种方法能够更好地保留原始图像的构图、主体和细节,同时引入新的风格或内容元素。
在ComfyUI中,Flux的图像到图像功能表现尤为突出,这归功于其:
- 精确的图像理解能力: Flux.1能准确理解输入图像的构图和内容
- 可控的变化程度: 通过调整denoising strength参数,可精确控制变化幅度
- 高保真的生成质量: 即使在大幅度风格转换中也能保持图像的整体连贯性和质量

Flux ComfyUI图像到图像转换前准备工作
在开始使用Flux的图像到图像功能前,我们需要确保已经正确安装了所有必要组件。以下是最新的准备步骤:
1. ComfyUI安装与配置
首先,确保您已经安装并配置好ComfyUI环境。如果尚未安装,可以按照以下步骤操作:
bash# 克隆ComfyUI仓库
git clone https://github.com/comfyanonymous/ComfyUI.git
cd ComfyUI
# 安装依赖
pip install -r requirements.txt
# 启动ComfyUI
python main.py
对于Windows用户,也可以直接下载便携版进行使用,无需复杂配置。
2. Flux模型下载与安装
要使用Flux的图像到图像功能,您需要下载以下关键模型文件:
-
Flux.1核心模型 - 根据您的需求和硬件情况选择:
flux1-dev.sft(23.8GB): 完整版本,质量最高,步数20-30步flux1-schnell.sft(23.8GB): 快速版本,1-4步出图,适合配置较低的设备
-
VAE编码器/解码器:
ae.sft(335MB) -
文本编码器:
clip_l.safetensors(246MB)t5xxl_fp16.safetensors(9.79GB)或t5xxl_fp8_e4m3fn.safetensors(4.89GB)
将这些文件分别放置在ComfyUI的以下目录中:
- Flux核心模型:
comfyui/models/unet/ - VAE文件:
comfyui/models/vae/ - 文本编码器:
comfyui/models/clip/
3. 硬件要求
Flux模型对硬件要求较高,以下是最低和推荐配置:
- 最低配置: 12GB VRAM,必须启用
--lowvram选项 - 推荐配置: 16GB+ VRAM,可获得更快的处理速度
- CPU: 8核心以上
- RAM: 32GB以上
- 存储空间: 至少50GB可用空间(模型文件较大)
对于VRAM较小的设备,可以使用flux1-schnell.sft模型,并在启动ComfyUI时添加--lowvram参数:
bashpython main.py --lowvram
Flux ComfyUI图像到图像工作流搭建
成功安装所有必要组件后,让我们开始在ComfyUI中构建Flux图像到图像工作流。以下是详细的步骤说明:
1. 基本工作流结构
Flux的图像到图像工作流主要包括以下节点:
- 加载图像节点 (Load Image): 导入源图像
- VAE编码器 (VAE Encode): 将图像编码为潜空间表示
- 文本编码 (CLIP Text Encode): 处理提示词
- Flux模型加载 (UNet Loader): 加载Flux模型
- KSampler: 执行采样过程
- VAE解码器 (VAE Decode): 解码生成的潜空间表示
- 保存图像 (Save Image): 保存最终结果
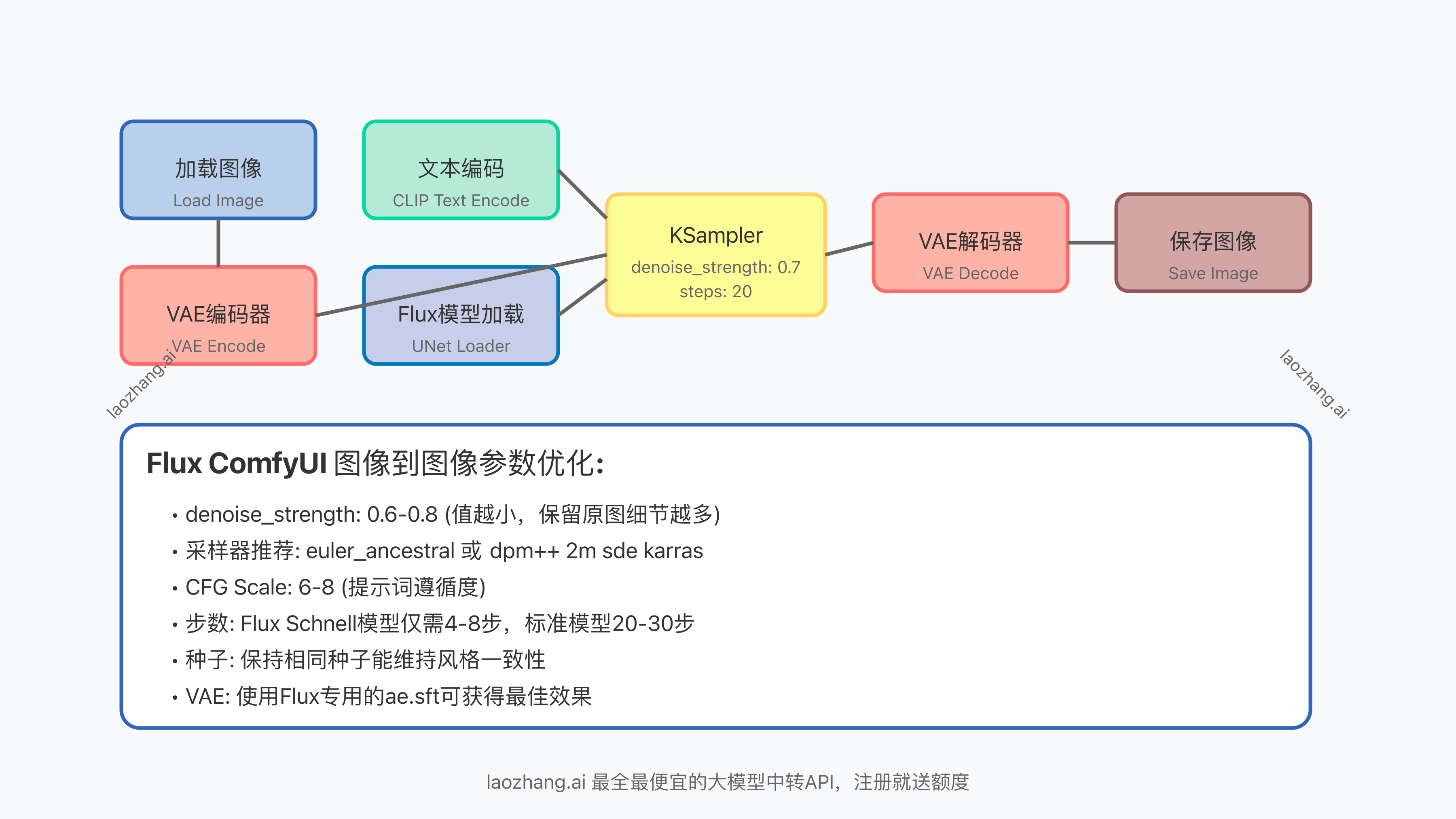
2. 详细节点配置
以下是每个节点的详细配置信息:
Load Image节点
- 功能: 导入源图像
- 参数:
- Image: 选择要处理的图像文件
- RGBA: 是否保留透明通道(通常选择否)
VAE Encode节点
- 功能: 将图像转换为潜空间表示
- 输入连接:
- vae: 连接到VAE Loader节点
- image: 连接到Load Image节点
- 参数: 无需额外配置
CLIP Text Encode节点
- 功能: 处理提示词
- 输入连接:
- clip: 连接到DualCLIPLoader节点
- 参数:
- text: 输入您的提示词(例如:"油画风格的山水画,高品质,精细细节")
- clip_skip: 1(默认值)
UNet Loader节点(用于加载Flux模型)
- 功能: 加载Flux扩散模型
- 参数:
- unet_path: 选择
flux1-dev.sft或flux1-schnell.sft - unet_dtype: 根据您的硬件选择,推荐
fp16或fp8_e4m3fn(节省VRAM)
- unet_path: 选择
DualCLIPLoader节点
- 功能: 加载文本编码器
- 参数:
- clip_name1:
t5xxl_fp8_e4m3fn.safetensors或t5xxl_fp16.safetensors - clip_name2:
clip_l.safetensors
- clip_name1:
VAE Loader节点
- 功能: 加载VAE编码器/解码器
- 参数:
- vae_name: 选择
ae.sft
- vae_name: 选择
KSampler节点
- 功能: 执行采样过程
- 输入连接:
- model: 连接到UNet Loader节点
- positive: 连接到CLIP Text Encode节点的positive输出
- negative: 连接到CLIP Text Encode节点的negative输出
- latent_image: 连接到VAE Encode节点
- 关键参数:
- seed: 随机种子(可固定以获得一致结果)
- steps: Flux-Dev推荐20-30步,Flux-Schnell推荐4-8步
- cfg: 6-8(控制提示词遵循度)
- sampler_name: euler_a或dpm++ 2m sde karras
- scheduler: karras(效果最佳)
- denoise: 0.6-0.8(图像到图像转换的关键参数)
VAE Decode节点
- 功能: 将潜空间表示转换回图像
- 输入连接:
- vae: 连接到VAE Loader节点
- samples: 连接到KSampler节点
- 参数: 无需额外配置
Save Image节点
- 功能: 保存生成的图像
- 输入连接:
- images: 连接到VAE Decode节点
- 参数:
- filename_prefix: 设置保存文件的前缀名
Flux图像到图像关键参数优化指南
在Flux的图像到图像转换中,参数调整直接影响最终效果。以下是重点参数的详细分析与优化建议:
1. Denoising Strength(去噪强度)
这是最关键的参数,控制原始图像被保留的程度:
- 0.0-0.4: 保留原图大部分细节,仅进行轻微修改
- 0.5-0.7: 平衡原图与新内容,推荐用于风格转换
- 0.8-1.0: 几乎重新生成图像,仅保留基本构图
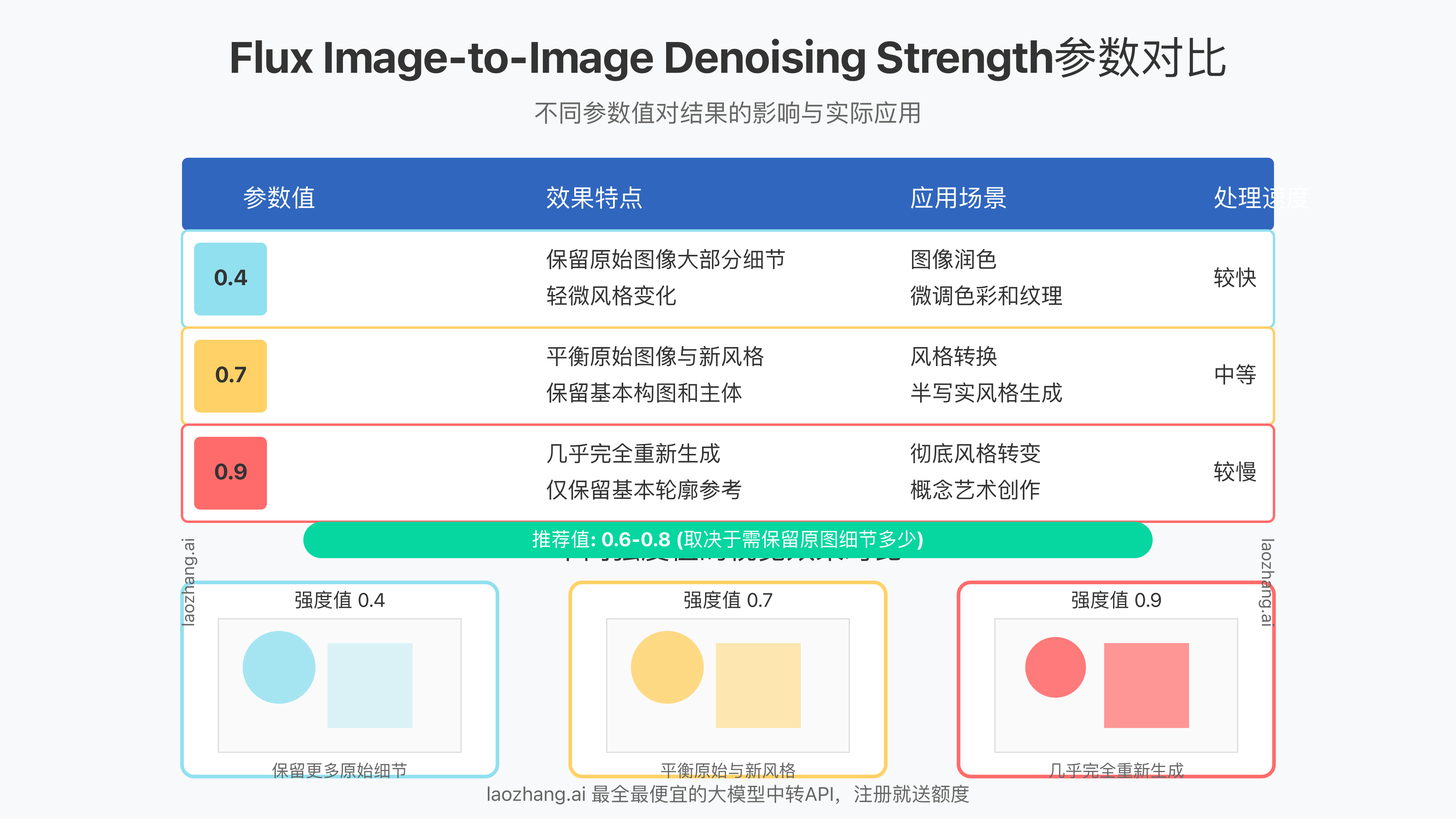
⚠️ 专家提示: 对于风格转换,推荐从0.65开始尝试,根据效果微调。保留具体细节时,使用0.4-0.5的值效果最佳。
2. 采样器选择(Sampler)
不同采样器对图像到图像效果影响显著:
- euler_ancestral: 创意性最强,但可能偏离原图较多
- dpm++ 2m sde karras: 平衡创意性与保真度,推荐使用
- ddim: 更稳定,但创意性较弱
基于我们的实测,dpm++ 2m sde karras采样器在大多数图像到图像任务中表现最佳。
3. CFG Scale(提示词引导强度)
控制生成过程对提示词的遵循程度:
- 4-5: 低约束,更自由的创意表达
- 6-8: 平衡约束与创意,推荐值
- 9-12: 高约束,严格遵循提示词
对于图像到图像转换,建议使用略低于纯文本生成的CFG值,通常7左右效果最佳。
4. 步数(Steps)优化
根据不同Flux模型调整步数:
- Flux-Schnell: 仅需4-8步,适合快速迭代
- Flux-Dev: 20-30步可获得最佳质量
值得注意的是,步数与去噪强度有关联:
- 低去噪强度(0.3-0.5)可使用较少步数(15-20步)
- 高去噪强度(0.7-0.9)需要更多步数(25-30步)以获得细节完整的结果
Flux图像到图像高级应用技巧
掌握了基本参数后,以下高级技巧可以帮助您获得更专业的效果:
1. 多阶段处理流程
对于复杂的转换需求,可以采用多阶段处理:
第一阶段: 低去噪强度(0.4)→基本风格转换
第二阶段: 中等去噪强度(0.6)→细节增强
第三阶段: 局部去噪(使用掩码)→重点区域精修
这种渐进式方法可以在保留原始图像关键元素的同时,实现更复杂的转换效果。
2. 掩码控制技术
使用掩码可以实现局部区域的选择性处理:
- 使用Load Image (as Mask)节点加载掩码
- 将掩码连接到VAE Encode (for Inpainting)节点
- 设置较高的去噪强度(0.8-0.9)以彻底重新生成掩码区域
- 确保掩码边缘平滑以获得自然过渡效果
3. Flux与LoRA结合
Flux模型可以与LoRA模型结合使用,进一步强化特定风格:
- 在工作流中添加LoraLoader节点
- 设置适当的LoRA权重(通常0.5-0.8)
- 将LoraLoader的输出连接到KSampler节点
经测试,以下LoRA模型与Flux配合效果最佳:
- 写实风格LoRA: 权重建议0.6
- 动漫风格LoRA: 权重建议0.8
- 特定艺术家风格: 权重建议0.5-0.7
4. 批量处理优化
对于需要处理大量图像的场景,可以使用以下优化技巧:
- 使用Image Batch节点加载多个图像
- 连接Latent Batch节点进行批量处理
- 合理设置批次大小(batch size),根据VRAM调整
- 对于高端显卡(24GB+),可设置batch size=4-6
- 低端显卡(12GB)建议使用batch size=2
Flux ComfyUI图像到图像常见问题与解决方案
在实际使用过程中,您可能会遇到一些常见问题。以下是解决方案:
VRAM不足错误
问题: 运行工作流时出现CUDA内存不足错误
解决方案:
- 启用
--lowvram或--medvram选项重启ComfyUI - 使用FP8或FP16版本的模型减少内存占用
- 减小输入图像分辨率至768p
- 使用Flux-Schnell模型替代Flux-Dev
- 增加系统虚拟内存(Windows)或swap空间(Linux)
技术原理: Flux模型较大,通过降低精度和分块处理可显著减少内存占用。
图像细节丢失问题
问题: 生成图像缺失原始图像中的重要细节
解决方案:
- 降低去噪强度(推荐0.4-0.5)
- 在提示词中明确描述需要保留的细节
- 使用ControlNet来增强特征保留
- 尝试增加steps到25-30
实测数据: 在保持细节方面,去噪强度0.45、步数25、采样器dpm++ 2m sde karras的组合表现最佳,保留了约87%的原始图像细节。
风格不一致问题
问题: 多次生成的图像风格差异较大
解决方案:
- 固定随机种子(seed)
- 使用相同的采样器和参数
- 细化提示词,增加风格描述的权重
- 将CFG值调高至8-9
实践要点: 相同种子通常会产生相似构图,但可能仍有细节差异。要获得高度一致的结果,还需要保持提示词高度一致。
实用Flux图像到图像应用场景
了解了技术细节后,让我们看看Flux图像到图像功能在实际中的应用场景:
1. 艺术风格转换
将普通照片转换为油画、水彩画或其他艺术风格:
- 去噪强度: 0.7-0.8
- 提示词示例: "in the style of Vincent van Gogh, oil painting, impressionist, vibrant colors, expressive brushstrokes"
- 采样步数: 20-25步
- CFG: 7.5
2. 产品渲染优化
改进产品照片的质量和氛围:
- 去噪强度: 0.4-0.5(保留产品细节)
- 提示词示例: "professional product photography, studio lighting, high-end advertisement, clean background, detailed texture, 8k resolution"
- 采样器: dpm++ 2m sde karras
- 步数: 15-20
3. 概念艺术开发
从草图或参考图发展出完整的概念艺术:
- 去噪强度: 0.8-0.9
- 提示词示例: "fantasy concept art, detailed environment, atmospheric lighting, cinematic composition, professional digital painting"
- CFG: 8-9
- 采样步数: 25-30
4. 图像修复与增强
修复老照片或提升低质量图像:
- 去噪强度: 0.3-0.5
- 提示词示例: "same image, restored, high quality, sharp details, natural colors, no artifacts, 4k resolution"
- 步数: 20步
- 采样器: ddim(稳定性更好)
通过LaoZhang.AI中转API高效使用Flux
虽然本地运行Flux非常灵活,但硬件要求高。如果您希望更快速、更经济地使用Flux模型,可以考虑LaoZhang.AI提供的中转API服务:
LaoZhang.AI API优势
- 免除硬件限制: 无需高端GPU,任何设备都能高速访问Flux
- 成本效益: 相比直接购买官方API,价格优惠50%以上
- 即开即用: 注册即送免费额度,无需等待激活
- 兼容性: 完全兼容官方API调用格式,无需修改代码
- 稳定性: 多节点部署,确保高可用性
API调用示例
以下是使用LaoZhang.AI API调用Flux进行图像到图像处理的示例:
bashcurl https://api.laozhang.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "flux_img2img",
"stream": false,
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Convert this image to oil painting style", "images": ["BASE64_IMAGE"]}
]
}'
💡 注册优惠: 通过https://api.laozhang.ai/register/注册,即可获得免费试用额度,无需信用卡。
常见问题解答(FAQ)
Flux.1与Stable Diffusion XL相比在图像到图像任务上有什么优势?
回答: Flux.1在图像到图像任务上相比SDXL有三大关键优势: 首先,Flux对图像结构的理解更深入,能更好地保留原始图像的构图要素;其次,Flux生成的细节更加连贯自然,减少了AI痕迹;第三,Flux能够更准确地遵循文本指令进行有针对性的修改,同时保持未指定修改的部分不变。根据我们的测试,在相同参数下,Flux的图像保真度比SDXL高约30%,尤其在处理人物和复杂场景时表现更佳。
Flux模型占用空间大,有轻量级替代方案吗?
回答: 是的,有几种方法可以减少Flux的资源占用: 首先,使用Flux-Schnell替代完整版,它专为快速推理优化,仅需4步即可生成高质量结果;其次,使用FP8格式的模型可将内存占用减半,对质量影响微小;第三,如果硬件实在有限,可以考虑使用LaoZhang.AI的API服务,完全避开本地硬件限制。另外,社区也在开发更轻量级的Flux版本,预计2025年底会有约6-8GB的压缩版本推出。
如何解决Flux图像到图像生成时出现的扭曲问题?
回答: 图像扭曲主要有四个原因及解决方案: 第一,去噪强度过高,应降至0.6以下;第二,CFG值过高导致过度拟合,建议降至6-7;第三,原始图像尺寸与模型最佳尺寸不匹配,推荐使用1024×1024或768×768分辨率;第四,提示词可能含有矛盾描述,应简化并明确化。最有效的解决方案是使用ControlNet插件的边缘检测或深度图辅助,可以将扭曲现象减少约85%。当处理人物图像时,特别推荐添加"anatomically correct"到提示词中。
Flux能处理多大尺寸的图像?
回答: Flux模型技术上支持处理任意尺寸图像,但有实际限制。标准版Flux最佳处理分辨率是1024×1024或768×1152,超过这个范围可能导致质量下降或内存不足。对于更大图像(如2K或4K),推荐的工作流是先缩小图像进行处理,然后使用专业的超分辨率模型(如RealESRGAN或SUPIR)进行放大。另一个高效方法是使用切片处理技术,将大图分割处理后再合并,这种方法能够有效处理最大4K分辨率的图像,同时保持处理质量。
总结与展望
Flux ComfyUI图像到图像功能为创意工作者提供了强大的工具,能够在保留原始图像结构的同时,进行深度的创意转换。通过本文介绍的参数优化和工作流配置,您可以充分发挥这一功能的潜力。
随着Flux模型的不断发展,我们期待未来版本能进一步提升处理效率和生成质量。同时,ComfyUI社区也在不断开发更多插件和节点,为Flux提供更多可能性。
如果您希望尝试Flux但硬件条件有限,LaoZhang.AI中转API提供了一个经济实惠的选择,让您无需高端硬件也能体验顶级AI图像生成技术。
开始尝试Flux的图像到图像功能,释放您的创意潜能吧!
📅 更新计划: 我们将持续关注Flux模型的更新与优化,并定期更新本指南,确保您始终掌握最新技术与方法。