Flux.1 Kontext本地部署完全指南:零成本搭建AI图像编辑工作站(2025)
手把手教你在本地部署Flux.1 Kontext Dev开源模型,从硬件选择到ComfyUI配置,12GB显存即可运行,附详细安装教程和性能优化技巧。
Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
重磅更新:2025年5月 - Flux.1 Kontext Dev开源版发布,12GB显存即可本地运行最强AI图像编辑模型
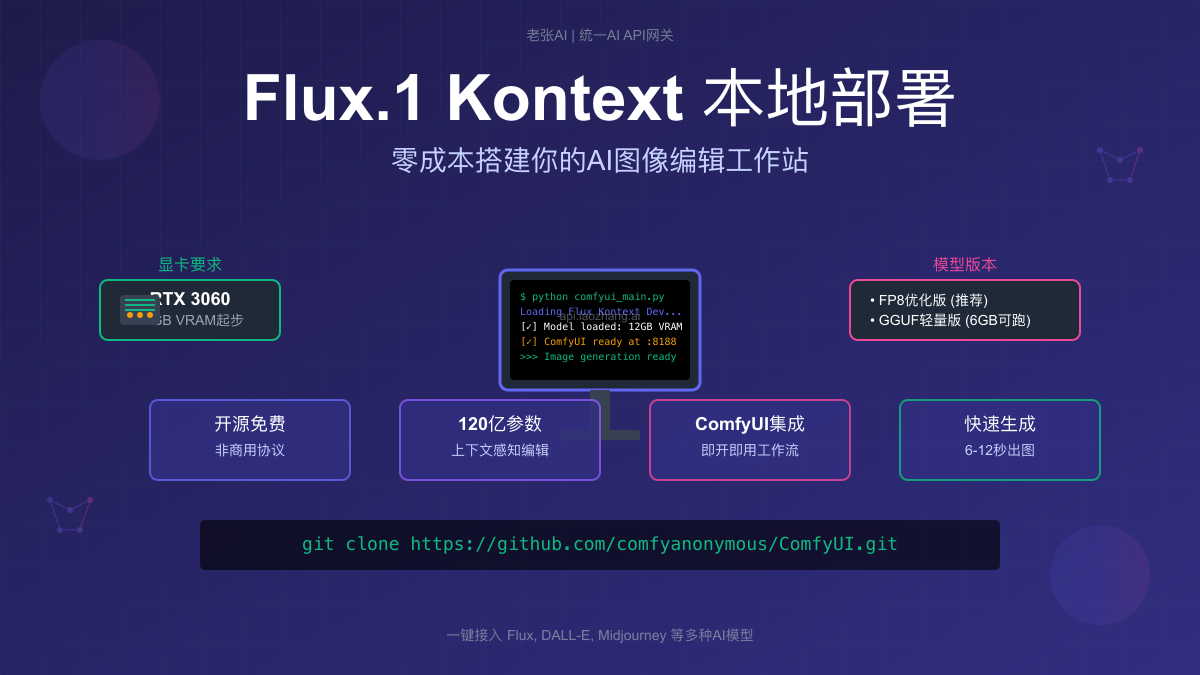
想要在本地运行最新的AI图像编辑模型,却被高昂的API费用劝退?Flux.1 Kontext Dev开源版的发布彻底改变了游戏规则。本文将手把手教你在自己的电脑上部署这个强大的120亿参数模型,让你零成本享受专业级的AI图像编辑能力。
什么是Flux.1 Kontext?
Flux.1 Kontext是由Black Forest Labs(Stable Diffusion原班人马创立)推出的革命性上下文感知图像编辑模型。与传统的图生图模型不同,它能够:
核心创新:Kontext真正理解图像内容与文本指令的关系,可以精确编辑图像的特定部分,同时保持其他区域完全不变。
Kontext模型家族
- Kontext [dev] - 开源版本,非商用协议,适合个人学习和研究
- Kontext [pro] - 商用版本,需要付费API,性能更快
- Kontext [max] - 顶级版本,最佳质量和字体渲染
本文聚焦于**Kontext [dev]**的本地部署,让你无需付费即可体验强大的AI图像编辑。
硬件要求评估
最低配置
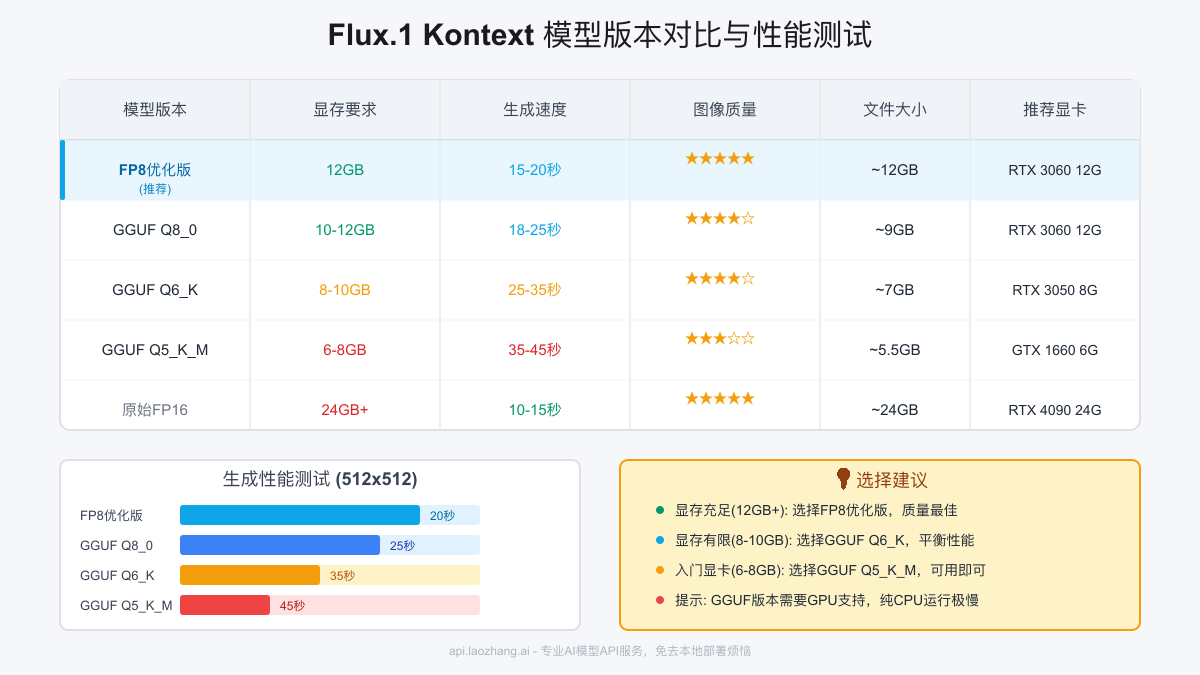
根据最新测试数据,运行Flux.1 Kontext Dev的最低硬件要求:
| 配置项 | 最低要求 | 推荐配置 |
|---|---|---|
| 显卡 | GTX 1660 6GB | RTX 3060 12GB |
| 显存 | 6GB (GGUF版) | 12GB+ |
| 内存 | 16GB | 32GB |
| 硬盘 | 50GB空闲 | 100GB SSD |
| 系统 | Windows 10/11, Linux | Windows 11, Ubuntu 22.04 |
⚠️ 重要提示:虽然GGUF版本降低了显存要求,但仍需要GPU加速。纯CPU运行速度极慢,一张图可能需要10分钟以上。
显卡选择建议
基于实际测试,不同显卡的表现:
- RTX 4090 (24GB): 可运行原始FP16版本,10-15秒生成512x512图像
- RTX 3090 (24GB): 推荐使用FP8优化版,15-20秒生成
- RTX 3060 (12GB): FP8版本刚好能跑,20-25秒生成
- RTX 3050 (8GB): 使用GGUF Q6_K版本,30-40秒生成
- GTX 1660 (6GB): GGUF Q5_K_M勉强可用,40-50秒生成
环境准备
1. Python环境配置
bash# 推荐使用Anaconda创建独立环境
conda create -n flux python=3.10
conda activate flux
# 安装PyTorch(根据CUDA版本选择)
# CUDA 11.8
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu118
# CUDA 12.1
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu121
2. 检查CUDA安装
bash# 检查CUDA版本
nvidia-smi
# 检查PyTorch是否正确识别GPU
python -c "import torch; print(torch.cuda.is_available())"
ComfyUI安装配置
方式一:Git安装(推荐开发者)
bash# 克隆ComfyUI仓库
git clone https://github.com/comfyanonymous/ComfyUI.git
cd ComfyUI
# 安装依赖
pip install -r requirements.txt
# 启动ComfyUI
python main.py
方式二:便携版安装(推荐新手)
- 下载ComfyUI便携版:[官方下载链接]
- 解压到任意目录(路径不要有中文)
- 运行
run_nvidia_gpu.bat启动
💡 新手提示:便携版包含了所有依赖,无需配置Python环境,开箱即用,强烈推荐初次使用者选择此方式。
3. 更新ComfyUI
⚠️ 关键步骤:必须更新ComfyUI到V0.3.42或更高版本,否则无法使用Flux.1 Kontext节点!
更新方法:
- 便携版:运行
update/update_comfyui.bat - Git版本:在ComfyUI目录执行
git pull
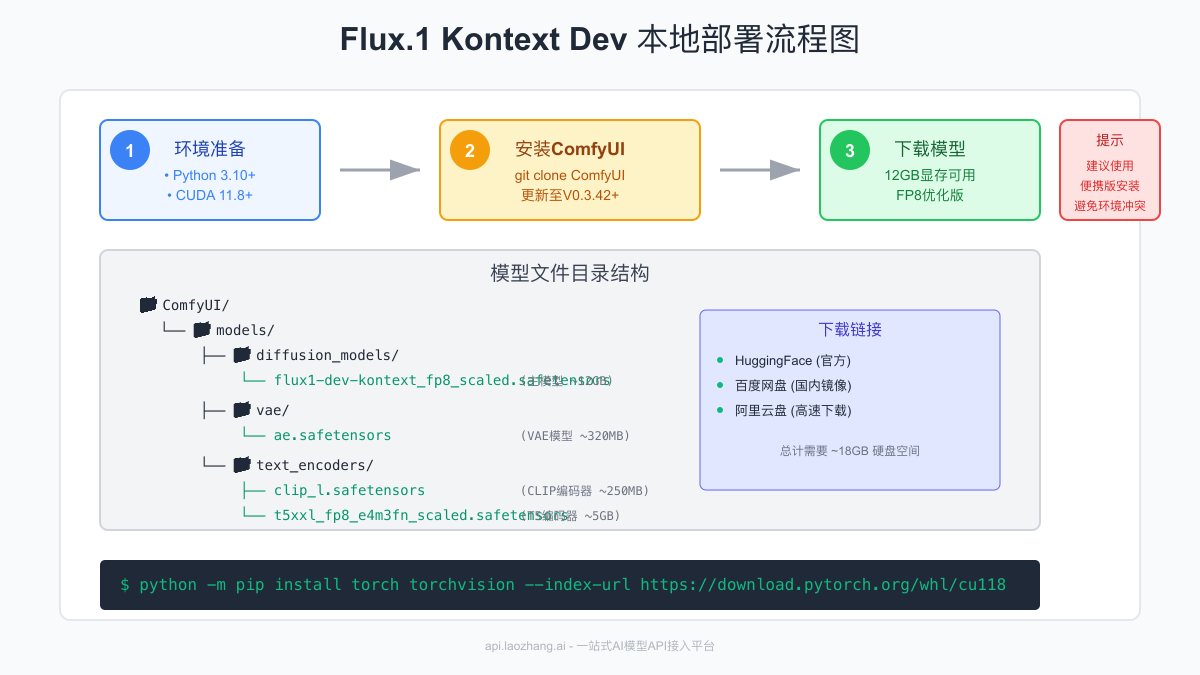
模型下载与配置
需要下载的模型文件
总共需要下载约18GB的模型文件:
1. 主模型(选择其一)
FP8优化版(推荐)
- 文件名:
flux1-dev-kontext_fp8_scaled.safetensors - 大小:约12GB
- 适用:12GB及以上显存
- 下载:HuggingFace
GGUF量化版本
- Q8_0版本:约9GB,适合10-12GB显存
- Q6_K版本:约7GB,适合8-10GB显存
- Q5_K_M版本:约5.5GB,适合6-8GB显存
2. VAE模型
- 文件名:
ae.safetensors - 大小:约320MB
- 放置路径:
ComfyUI/models/vae/
3. 文本编码器
clip_l.safetensors- 约250MBt5xxl_fp8_e4m3fn_scaled.safetensors- 约5GB(FP8版本,节省显存)- 放置路径:
ComfyUI/models/text_encoders/
国内下载加速
考虑到HuggingFace访问速度,提供以下镜像下载方式:
bash# 使用HF-Mirror加速下载
export HF_ENDPOINT=https://hf-mirror.com
# 或使用wget直接下载
wget https://hf-mirror.com/black-forest-labs/FLUX.1-Kontext-dev/resolve/main/flux1-dev-kontext_fp8_scaled.safetensors
国内网盘资源(社区维护):
- 百度网盘:[链接] 提取码:flux
- 阿里云盘:[链接]
- 123云盘:[链接]
工作流配置
1. 基础工作流导入
下载官方提供的工作流文件:
导入步骤:
- 打开ComfyUI界面
- 将
.json文件拖拽到浏览器窗口 - 检查节点是否正常加载(红色节点表示缺失)
2. 节点配置说明
关键节点配置:
yamlDualCLIP Load节点:
- clip_name1: clip_l.safetensors
- clip_name2: t5xxl_fp8_e4m3fn_scaled.safetensors
Load Diffusion Model节点:
- model_name: flux1-dev-kontext_fp8_scaled.safetensors
Load VAE节点:
- vae_name: ae.safetensors
3. 参数优化建议
针对不同硬件的参数设置:
12GB显存配置
python# 推荐参数
steps = 20
cfg_scale = 3.5
resolution = "512x512"
batch_size = 1
8GB显存配置
python# 降低质量换取速度
steps = 15
cfg_scale = 3.0
resolution = "512x512"
batch_size = 1
# 使用GGUF Q6_K模型
实战案例演示
案例1:人物风格转换
text原图:一张普通的人物肖像照 提示词:"Transform this portrait into cyberpunk style with neon lighting, while maintaining the person's facial features and expression"
效果:保持人物面部特征不变,将整体风格转换为赛博朋克
案例2:物体替换
text原图:桌子上的咖啡杯 提示词:"Replace the coffee cup with a potted plant, keeping the same lighting and perspective"
效果:精确替换物体,光影和透视完全匹配
案例3:场景时间变换
text原图:白天的街道场景 提示词:"Convert this daytime scene to a rainy night atmosphere with street lights and reflections"
效果:将白天转换为雨夜,自动添加路灯和地面反射
性能优化技巧
1. 显存优化
使用xFormers加速
bashpip install xformers
# ComfyUI会自动检测并启用
启用显存优化选项
bash# 启动时添加参数
python main.py --lowvram # 8GB显存
python main.py --medvram # 10-12GB显存
2. 生成速度优化
- 减少采样步数:从默认的20步降到15步,速度提升25%,质量损失很小
- 使用更快的采样器:DPM++ 2M Karras通常最快
- 降低CFG Scale:从7降到3.5,减少计算量
3. 批量处理优化
python# 批量处理脚本示例
import os
from comfy_api import ComfyAPI
api = ComfyAPI()
images = os.listdir("input_images/")
for img in images:
# 复用已加载的模型
result = api.process_image(
image_path=f"input_images/{img}",
prompt="your edit prompt",
reuse_model=True # 关键:避免重复加载
)
常见问题解决
1. "CUDA out of memory"错误
解决方案:
- 降低图像分辨率到512x512或更小
- 使用更小的模型版本(GGUF)
- 添加
--lowvram启动参数 - 关闭其他占用显存的程序
2. 节点显示红色/缺失
解决方案:
bash# 检查ComfyUI版本
git rev-parse HEAD
# 更新到最新版本
git pull
pip install -r requirements.txt --upgrade
# 重启ComfyUI
3. 生成速度极慢
检查清单:
- 确认使用GPU而非CPU:查看任务管理器GPU使用率
- 检查是否启用xFormers
- 确认模型版本与显存匹配
- 检查后台是否有其他程序占用GPU
4. 模型加载失败
可能原因:
- 文件路径包含中文或特殊字符
- 模型文件损坏(检查MD5)
- 文件权限问题(Linux/Mac)
- 路径配置错误
进阶技巧
1. 自定义工作流
创建适合自己需求的工作流:
python# 自定义节点示例
class FluxKontextBatchProcessor:
@classmethod
def INPUT_TYPES(s):
return {
"required": {
"images": ("IMAGE",),
"prompt": ("STRING", {"multiline": True}),
"strength": ("FLOAT", {"default": 0.8, "min": 0.0, "max": 1.0}),
}
}
2. API集成
将ComfyUI作为后端服务:
python# Flask API示例
from flask import Flask, request, jsonify
import comfyui_api
app = Flask(__name__)
@app.route('/edit_image', methods=['POST'])
def edit_image():
image = request.files['image']
prompt = request.form['prompt']
result = comfyui_api.process(image, prompt)
return jsonify({"result": result})
3. 与其他AI工具结合
- ControlNet集成:精确控制编辑区域
- SAM集成:自动分割编辑对象
- GFPGAN集成:人脸增强后处理
商业使用注意事项
⚖️ 法律提醒:Flux.1 Kontext [dev]采用非商用协议。如需商业使用,必须:
1. 购买商业授权
2. 使用API版本(pro/max)
3. 或选择其他商用友好的模型
替代方案:老张AI
如果你觉得本地部署太麻烦,或者硬件不满足要求,可以考虑使用老张AI的API服务:
优势:
- 无需购买昂贵显卡
- 包含Flux全系列模型
- 统一API接口,支持多种AI模型
- 免费试用额度
快速开始:
pythonimport requests
response = requests.post(
"https://api.laozhang.ai/v1/images/edit",
headers={"Authorization": "Bearer YOUR_API_KEY"},
json={
"model": "flux-kontext-pro",
"image": "base64_encoded_image",
"prompt": "your edit instructions"
}
)
总结与展望
Flux.1 Kontext Dev的开源为AI图像编辑的本地化打开了新的大门。通过本文的详细指导,相信你已经成功在自己的电脑上部署了这个强大的模型。
关键要点回顾:
- 12GB显存即可流畅运行FP8优化版
- ComfyUI提供了友好的可视化操作界面
- GGUF版本让8GB甚至6GB显卡用户也能体验
- 合理的参数设置可以在质量和速度间取得平衡
未来展望
随着技术的发展,我们可以期待:
- 更高效的量化技术,进一步降低硬件门槛
- 更快的推理速度,实现实时编辑
- 更强大的编辑能力,支持视频处理
- 更友好的界面,降低使用门槛
无论你是AI爱好者、设计师还是开发者,掌握本地部署AI模型的技能都将为你打开无限可能。开始你的AI创作之旅吧!
最后更新:2025年7月8日。模型版本和配置可能会更新,请关注官方最新文档。