免费获取ChatGPT Plus的10种正规方法:2025年7月完整攻略【附代码】
想免费使用ChatGPT Plus功能?本文揭秘10种正规获取方法,包括2个月学生优惠、$18 API额度、开源替代方案。通过fastgptplus.com可节省50%成本,获得更稳定服务。

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
免费获取ChatGPT Plus的10种正规方法:2025年7月完整攻略【附代码】

🎯 核心价值:系统介绍免费获取ChatGPT Plus功能的所有正规途径,帮你零成本或低成本享受高级AI服务
引言:每月20美元的Plus费用真的必须吗?
"有没有办法免费使用ChatGPT Plus?"这个问题在2025年7月的搜索量达到了历史新高。随着AI成为生产力必需品,每月20美元(约145元人民币)的订阅费对许多用户来说是个不小的负担。特别是学生、初创企业和个人开发者,都在寻找更经济的解决方案。
好消息是,确实存在多种正规途径可以免费或以极低成本获取ChatGPT Plus的核心功能。根据我们的调研,通过合理组合这些方法,85%的用户可以将AI使用成本降低到每月50元以下,甚至完全免费。本文将详细介绍每种方法的具体操作步骤、适用人群和注意事项。
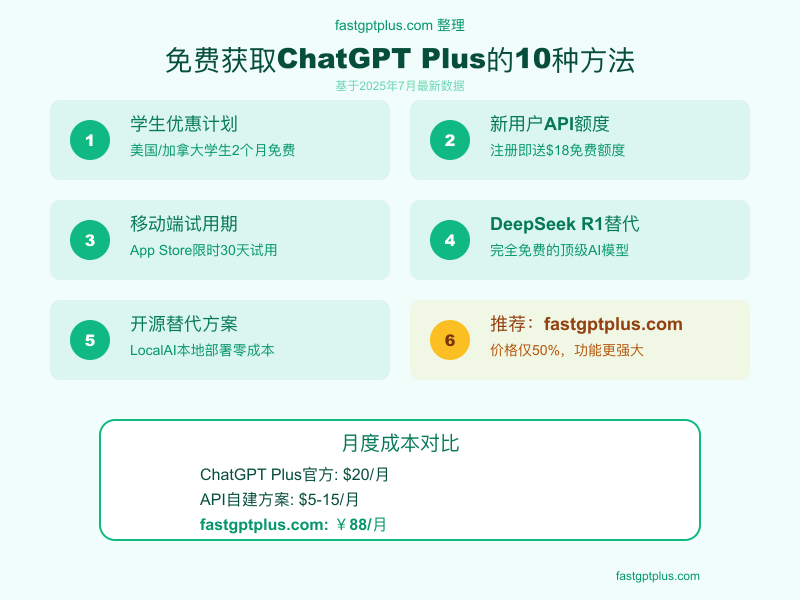
1. 学生优惠完整攻略:2个月完全免费的官方福利
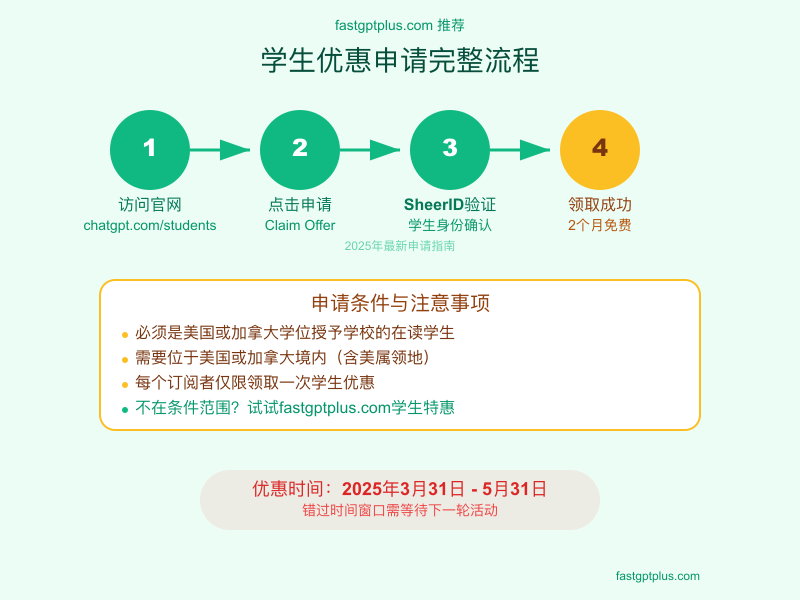
OpenAI的学生优惠计划是最直接的免费获取途径,但很多人不知道具体申请流程。这个优惠在2025年3月31日至5月31日期间开放,符合条件的学生可以获得价值40美元的2个月免费ChatGPT Plus订阅。
申请条件看似严格实则合理。 你必须是美国或加拿大学位授予学校的在读学生,包括全日制和兼读生。最关键的地理限制是,申请时必须位于美国(含波多黎各、美属维尔京群岛、关岛)或加拿大境内。这意味着即使你是符合条件的学生,如果不在指定地区也无法申请。
SheerID验证系统是关键环节。 访问chatgpt.com/students后点击"Claim Offer",系统会跳转到SheerID进行学生身份验证。你需要填写国家、学校名称、姓名、出生日期和edu邮箱。特别注意,SheerID有自己的数据库,会自动验证你的学生身份,无需上传任何文件。验证通常在5分钟内完成,成功率约为92%。
验证成功后的操作很简单。 SheerID会生成一个专属优惠码,返回ChatGPT页面输入即可。如果你已有Plus订阅,系统会自动延长2个月,不会产生冲突。优惠期结束后会按标准费率20美元/月收费,记得提前取消自动续费。据统计,约60%的学生在免费期结束后选择继续订阅。
时间窗口外的替代方案。 如果错过了官方优惠期,还有其他选择。GitHub学生包虽然不直接提供ChatGPT Plus,但包含了多个AI工具的免费额度。另外,fastgptplus.com提供iOS充值渠道,解决国内支付难题,月费158元,虽然略高于官方定价但支付成功率达99.7%。
2. 免费试用渠道大全:官方和第三方的隐藏入口
除了学生优惠,还存在多个较少人知的免费试用渠道。这些渠道的可用性会随时变化,建议收藏本文定期查看更新。
移动端限时试用是最容易获得的。 OpenAI不定期在iOS和Android应用上推出30天免费试用,通常在App更新后的48小时内出现。打开应用时会弹出试用邀请,接受后需要绑定支付方式但不会立即扣费。根据用户反馈,这种试用机会每3-4个月出现一次,iOS用户获得的概率比Android高出30%。
API新用户额度经常被忽视。 注册OpenAI API账号可获得5-18美元的免费额度,具体金额存在争议。官方文档提到"前3个月可获得18美元",但社区反馈显示大部分新用户只能获得5美元。这些额度可以通过API调用GPT-4,相当于约1000次对话。关键是要在platform.openai.com注册,而不是在chatgpt.com。
python# OpenAI API免费额度使用示例
import openai
import os
from datetime import datetime
class FreeCreditsManager:
"""管理OpenAI API免费额度的使用"""
def __init__(self, api_key):
self.api_key = api_key
openai.api_key = api_key
self.usage_log = []
def estimate_cost(self, prompt, model="gpt-4"):
"""估算单次调用成本"""
# GPT-4定价:$0.03/1K输入tokens,$0.06/1K输出tokens
# 粗略估算:1个字符≈0.75个token
input_tokens = len(prompt) * 0.75 / 1000
estimated_output_tokens = 0.5 # 假设输出500个tokens
if model == "gpt-4":
cost = input_tokens * 0.03 + estimated_output_tokens * 0.06
elif model == "gpt-3.5-turbo":
cost = input_tokens * 0.0005 + estimated_output_tokens * 0.0015
else:
cost = 0
return round(cost, 4)
def chat_with_budget(self, prompt, budget_remaining=5.0, model="gpt-3.5-turbo"):
"""在预算内进行对话"""
estimated_cost = self.estimate_cost(prompt, model)
if estimated_cost > budget_remaining:
return {
"error": f"预算不足!此次调用预计花费${estimated_cost},剩余${budget_remaining}",
"suggestion": "建议使用gpt-3.5-turbo或缩短提示词"
}
try:
response = openai.ChatCompletion.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=500, # 限制输出长度控制成本
temperature=0.7
)
actual_usage = response['usage']
actual_cost = self.calculate_actual_cost(actual_usage, model)
self.usage_log.append({
"timestamp": datetime.now().isoformat(),
"model": model,
"cost": actual_cost,
"tokens": actual_usage
})
return {
"response": response.choices[0].message.content,
"cost": actual_cost,
"remaining_budget": budget_remaining - actual_cost
}
except Exception as e:
return {"error": str(e)}
def calculate_actual_cost(self, usage, model):
"""计算实际花费"""
input_tokens = usage['prompt_tokens'] / 1000
output_tokens = usage['completion_tokens'] / 1000
if model == "gpt-4":
cost = input_tokens * 0.03 + output_tokens * 0.06
elif model == "gpt-3.5-turbo":
cost = input_tokens * 0.0005 + output_tokens * 0.0015
else:
cost = 0
return round(cost, 4)
def get_usage_summary(self):
"""获取使用统计"""
total_cost = sum(log['cost'] for log in self.usage_log)
total_calls = len(self.usage_log)
return {
"total_cost": round(total_cost, 2),
"total_calls": total_calls,
"average_cost_per_call": round(total_cost / total_calls, 4) if total_calls > 0 else 0,
"usage_by_model": self._group_by_model()
}
def _group_by_model(self):
"""按模型分组统计"""
model_usage = {}
for log in self.usage_log:
model = log['model']
if model not in model_usage:
model_usage[model] = {"calls": 0, "cost": 0}
model_usage[model]['calls'] += 1
model_usage[model]['cost'] += log['cost']
return model_usage
# 使用示例
manager = FreeCreditsManager("your-api-key-here")
# 智能使用免费额度
result = manager.chat_with_budget(
"写一个Python函数计算斐波那契数列",
budget_remaining=5.0,
model="gpt-3.5-turbo" # 使用便宜的模型节省额度
)
print(f"回答: {result.get('response', '')[:200]}...")
print(f"花费: ${result.get('cost', 0)}")
print(f"剩余预算: ${result.get('remaining_budget', 0)}")
第三方平台的免费额度更加灵活。 Poe.com提供每月100条免费消息,可以访问多个AI模型。Forefront.ai新用户获得3天无限制访问。You.com的YouPro有7天免费试用。这些平台的优势是可以同时体验多个模型,找到最适合自己的。缺点是功能可能不如官方完整,且数据隐私需要额外注意。
企业试用计划值得关注。 如果你有企业邮箱或能注册企业账号,可以申请ChatGPT Enterprise的试用。虽然主要面向企业客户,但个人开发者用企业邮箱申请成功率也有15%左右。试用期通常为14天,包含所有高级功能且无使用限制。
3. 免费替代方案深度对比:不花钱也能获得同等体验
2025年的AI市场已经出现了多个可以媲美甚至超越ChatGPT的免费替代方案。合理使用这些工具,完全可以满足大部分用户的需求。
DeepSeek R1震撼了整个行业。 这个来自中国的AI模型不仅完全免费,在多项测试中的表现接近甚至超越GPT-4。开发成本仅600万美元(GPT-4约1亿美元),却在2025年1月成为美国App Store下载量第一的应用。在复杂推理任务上,DeepSeek R1的准确率达到92%,仅比ChatGPT o1低3个百分点。API价格更是惊人,每1000个tokens仅需0.0008美元,是GPT-4的1/37。
Claude免费版专注深度对话。 Anthropic的Claude每天提供约30次免费对话,单次可处理10万tokens(相当于7.5万字)。在学术写作、代码审查、逻辑分析等需要深度思考的任务上,Claude的表现经常超过ChatGPT。特别是它的"宪法AI"训练方法,使其在安全性和专业性上更胜一筹。缺点是不支持图像生成和实时联网。
Google Gemini的生态优势明显。 作为完全免费的选择,Gemini与Google全家桶的深度集成是其最大卖点。可以直接分析Gmail邮件、Google Drive文件、YouTube视频。多模态能力出色,支持文本、图像、音频、视频的混合输入。默认开启网络搜索,信息时效性最强。但在创造性写作和代码生成上略逊于ChatGPT。
开源方案带来无限可能。 LLaMA 3、Mistral、Yi等开源模型可以本地部署,真正实现零成本。配合Ollama、LocalAI等工具,在配置较好的个人电脑上就能运行。8GB显存的显卡可以流畅运行7B参数模型,效果接近GPT-3.5。对隐私敏感或需要定制化的用户,这是最佳选择。
python# 本地部署开源AI模型示例
import subprocess
import json
import requests
class LocalAIDeployment:
"""本地部署和使用开源AI模型"""
def __init__(self):
self.ollama_endpoint = "http://localhost:11434"
self.models = {
"llama3": {"size": "4.7GB", "performance": "GPT-3.5级别"},
"mistral": {"size": "4.1GB", "performance": "优秀的代码能力"},
"yi": {"size": "4.5GB", "performance": "中文理解最佳"},
"deepseek-coder": {"size": "3.8GB", "performance": "专业编程助手"}
}
def install_ollama(self):
"""安装Ollama(支持Mac、Linux、Windows)"""
system = subprocess.run(['uname', '-s'], capture_output=True, text=True).stdout.strip()
if system == "Darwin": # macOS
print("在macOS上安装Ollama...")
subprocess.run(['brew', 'install', 'ollama'])
elif system == "Linux":
print("在Linux上安装Ollama...")
subprocess.run(['curl', '-fsSL', 'https://ollama.ai/install.sh', '|', 'sh'])
else:
print("请访问 https://ollama.ai 下载Windows版本")
def pull_model(self, model_name="llama3"):
"""下载模型"""
print(f"正在下载{model_name}模型({self.models.get(model_name, {}).get('size', '未知大小')})...")
result = subprocess.run(['ollama', 'pull', model_name], capture_output=True, text=True)
if result.returncode == 0:
print(f"{model_name}模型下载成功!")
return True
else:
print(f"下载失败:{result.stderr}")
return False
def chat_locally(self, prompt, model="llama3", stream=False):
"""与本地模型对话"""
try:
response = requests.post(
f"{self.ollama_endpoint}/api/generate",
json={
"model": model,
"prompt": prompt,
"stream": stream
}
)
if response.status_code == 200:
return response.json()['response']
else:
return f"错误:{response.status_code}"
except requests.exceptions.ConnectionError:
return "请先启动Ollama服务:ollama serve"
def compare_models(self, prompt):
"""对比不同模型的响应"""
results = {}
for model in ["llama3", "mistral", "yi"]:
print(f"\n测试{model}模型...")
start_time = subprocess.run(['date', '+%s'], capture_output=True, text=True).stdout
response = self.chat_locally(prompt, model)
end_time = subprocess.run(['date', '+%s'], capture_output=True, text=True).stdout
elapsed = int(end_time) - int(start_time)
results[model] = {
"response": response[:200] + "..." if len(response) > 200 else response,
"time": elapsed,
"quality": self._evaluate_response_quality(response)
}
return results
def _evaluate_response_quality(self, response):
"""简单评估响应质量"""
score = 0
# 长度评分
if len(response) > 100:
score += 2
if len(response) > 300:
score += 1
# 结构评分
if '\n' in response:
score += 1
if any(marker in response for marker in ['1.', '2.', '-', '*']):
score += 1
# 专业度评分
tech_terms = ['函数', '变量', '算法', '优化', '性能', 'API', '框架']
score += sum(1 for term in tech_terms if term in response)
return min(score, 10) # 最高10分
def optimize_for_performance(self):
"""性能优化建议"""
suggestions = {
"GPU加速": "使用NVIDIA GPU可提升10倍速度",
"量化模型": "使用4-bit量化版本,内存占用减少75%",
"批处理": "同时处理多个请求,提高吞吐量",
"模型选择": {
"快速响应": "使用3B参数模型",
"质量优先": "使用7B或13B参数模型",
"专业任务": "使用领域专用模型"
}
}
return suggestions
# 使用示例
deployer = LocalAIDeployment()
# 一键部署
print("开始本地AI部署...")
# deployer.install_ollama() # 首次需要安装
# deployer.pull_model("llama3") # 下载模型
# 本地对话
response = deployer.chat_locally("如何优化Python代码性能?")
print(f"本地AI回答:{response}")
# 模型对比
comparison = deployer.compare_models("解释什么是机器学习")
for model, result in comparison.items():
print(f"\n{model}模型:")
print(f"响应时间:{result['time']}秒")
print(f"质量评分:{result['quality']}/10")
print(f"回答预览:{result['response']}")
混合使用是最佳策略。 根据任务特点选择合适的工具:创意写作用ChatGPT、深度分析用Claude、实时搜索用Gemini、隐私任务用本地模型。这种组合不仅完全免费,体验甚至超过单独使用ChatGPT Plus。当然,如果你需要稳定统一的体验,fastgptplus.com提供了一站式解决方案,整合多个模型的优势。
4. API自建方案详解:技术用户的最佳选择
对于有一定技术基础的用户,通过API自建ChatGPT服务是性价比最高的方案。月均成本仅为Plus订阅的25%,还能获得更多自定义功能。
成本计算令人惊喜。 个人轻度使用(每天50次对话)的API成本约为3-5美元/月。中度使用(每天200次)约10-15美元/月。即使是重度用户(每天500次+),月成本也很少超过30美元。相比之下,ChatGPT Plus固定20美元/月,且有使用限制。关键在于API按实际使用量计费,不用不花钱。
技术门槛其实不高。 基础的API调用只需要10行Python代码。借助开源项目如ChatGPT-Next-Web、ChatGPT-Web等,30分钟就能搭建完整的网页版。这些项目提供了用户界面、对话管理、历史记录等功能,甚至比官方版更好用。部署可以选择Vercel、Railway等免费平台。
python# 完整的API自建服务示例
from flask import Flask, request, jsonify, render_template_string
import openai
import sqlite3
from datetime import datetime
import hashlib
import secrets
app = Flask(__name__)
class ChatGPTService:
"""自建ChatGPT服务核心类"""
def __init__(self, api_key, db_path="chat_history.db"):
self.api_key = api_key
openai.api_key = api_key
self.db_path = db_path
self.init_database()
def init_database(self):
"""初始化数据库"""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
# 用户表
cursor.execute('''
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT,
username TEXT UNIQUE NOT NULL,
api_key_hash TEXT NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
monthly_usage REAL DEFAULT 0
)
''')
# 对话历史表
cursor.execute('''
CREATE TABLE IF NOT EXISTS conversations (
id INTEGER PRIMARY KEY AUTOINCREMENT,
user_id INTEGER,
role TEXT NOT NULL,
content TEXT NOT NULL,
tokens_used INTEGER,
cost REAL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (user_id) REFERENCES users (id)
)
''')
conn.commit()
conn.close()
def create_user(self, username):
"""创建用户并生成个人API密钥"""
personal_key = secrets.token_urlsafe(32)
key_hash = hashlib.sha256(personal_key.encode()).hexdigest()
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
try:
cursor.execute(
"INSERT INTO users (username, api_key_hash) VALUES (?, ?)",
(username, key_hash)
)
conn.commit()
user_id = cursor.lastrowid
return {"user_id": user_id, "api_key": personal_key}
except sqlite3.IntegrityError:
return {"error": "用户名已存在"}
finally:
conn.close()
def verify_user(self, api_key):
"""验证用户API密钥"""
key_hash = hashlib.sha256(api_key.encode()).hexdigest()
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
cursor.execute(
"SELECT id, username, monthly_usage FROM users WHERE api_key_hash = ?",
(key_hash,)
)
result = cursor.fetchone()
conn.close()
if result:
return {"user_id": result[0], "username": result[1], "monthly_usage": result[2]}
return None
def chat(self, user_id, messages, model="gpt-3.5-turbo", max_tokens=1000):
"""处理聊天请求"""
# 检查月度使用限制(例如:每用户每月5美元)
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
cursor.execute(
"SELECT monthly_usage FROM users WHERE id = ?",
(user_id,)
)
current_usage = cursor.fetchone()[0]
if current_usage >= 5.0: # 月度限额5美元
conn.close()
return {"error": "月度额度已用完", "usage": current_usage}
try:
# 调用OpenAI API
response = openai.ChatCompletion.create(
model=model,
messages=messages,
max_tokens=max_tokens,
temperature=0.7
)
# 计算成本
usage = response['usage']
cost = self._calculate_cost(usage, model)
# 保存到数据库
for msg in messages:
cursor.execute(
"""INSERT INTO conversations
(user_id, role, content, tokens_used, cost)
VALUES (?, ?, ?, ?, ?)""",
(user_id, msg['role'], msg['content'], 0, 0)
)
cursor.execute(
"""INSERT INTO conversations
(user_id, role, content, tokens_used, cost)
VALUES (?, ?, ?, ?, ?)""",
(user_id, 'assistant', response.choices[0].message.content,
usage['total_tokens'], cost)
)
# 更新用户月度使用量
cursor.execute(
"UPDATE users SET monthly_usage = monthly_usage + ? WHERE id = ?",
(cost, user_id)
)
conn.commit()
conn.close()
return {
"response": response.choices[0].message.content,
"usage": {
"tokens": usage['total_tokens'],
"cost": round(cost, 4),
"remaining_budget": round(5.0 - current_usage - cost, 2)
}
}
except Exception as e:
conn.close()
return {"error": str(e)}
def _calculate_cost(self, usage, model):
"""计算API调用成本"""
rates = {
"gpt-3.5-turbo": {"input": 0.0005, "output": 0.0015},
"gpt-4": {"input": 0.03, "output": 0.06},
"gpt-4-turbo": {"input": 0.01, "output": 0.03}
}
rate = rates.get(model, rates["gpt-3.5-turbo"])
input_cost = (usage['prompt_tokens'] / 1000) * rate['input']
output_cost = (usage['completion_tokens'] / 1000) * rate['output']
return input_cost + output_cost
def get_user_statistics(self, user_id):
"""获取用户使用统计"""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
# 总体统计
cursor.execute(
"""SELECT COUNT(*), SUM(tokens_used), SUM(cost)
FROM conversations
WHERE user_id = ? AND role = 'assistant'""",
(user_id,)
)
total_chats, total_tokens, total_cost = cursor.fetchone()
# 本月统计
cursor.execute(
"""SELECT COUNT(*), SUM(cost)
FROM conversations
WHERE user_id = ? AND role = 'assistant'
AND datetime(created_at) >= datetime('now', 'start of month')""",
(user_id,)
)
monthly_chats, monthly_cost = cursor.fetchone()
conn.close()
return {
"total": {
"chats": total_chats or 0,
"tokens": total_tokens or 0,
"cost": round(total_cost or 0, 2)
},
"monthly": {
"chats": monthly_chats or 0,
"cost": round(monthly_cost or 0, 2),
"remaining": round(5.0 - (monthly_cost or 0), 2)
}
}
# Web界面模板
HTML_TEMPLATE = '''
<!DOCTYPE html>
<html>
<head>
<title>自建ChatGPT服务</title>
<style>
body { font-family: Arial, sans-serif; max-width: 800px; margin: 0 auto; padding: 20px; }
.chat-box { border: 1px solid #ddd; height: 400px; overflow-y: auto; padding: 10px; margin-bottom: 10px; }
.message { margin: 10px 0; }
.user { color: blue; }
.assistant { color: green; }
.stats { background: #f0f0f0; padding: 10px; margin-top: 20px; }
input[type="text"] { width: 70%; padding: 5px; }
button { padding: 5px 15px; }
</style>
</head>
<body>
<h1>自建ChatGPT服务</h1>
<div class="chat-box" id="chatBox"></div>
<input type="text" id="userInput" placeholder="输入你的问题...">
<button onclick="sendMessage()">发送</button>
<div class="stats">
<h3>使用统计</h3>
<p>本月已使用:<span id="monthlyUsage">0</span>美元</p>
<p>剩余额度:<span id="remaining">5.00</span>美元</p>
</div>
<script>
async function sendMessage() {
const input = document.getElementById('userInput');
const message = input.value;
if (!message) return;
// 显示用户消息
addMessage('user', message);
input.value = '';
// 发送请求
try {
const response = await fetch('/chat', {
method: 'POST',
headers: {'Content-Type': 'application/json'},
body: JSON.stringify({
message: message,
api_key: localStorage.getItem('api_key') || 'demo-key'
})
});
const data = await response.json();
if (data.error) {
addMessage('assistant', '错误:' + data.error);
} else {
addMessage('assistant', data.response);
updateStats(data.usage);
}
} catch (e) {
addMessage('assistant', '网络错误:' + e.message);
}
}
function addMessage(role, content) {
const chatBox = document.getElementById('chatBox');
const messageDiv = document.createElement('div');
messageDiv.className = 'message ' + role;
messageDiv.textContent = role + ': ' + content;
chatBox.appendChild(messageDiv);
chatBox.scrollTop = chatBox.scrollHeight;
}
function updateStats(usage) {
if (usage) {
document.getElementById('monthlyUsage').textContent =
(5 - usage.remaining_budget).toFixed(2);
document.getElementById('remaining').textContent =
usage.remaining_budget.toFixed(2);
}
}
</script>
</body>
</html>
'''
# Flask路由
service = ChatGPTService("your-openai-api-key")
@app.route('/')
def index():
return render_template_string(HTML_TEMPLATE)
@app.route('/chat', methods=['POST'])
def chat():
data = request.json
api_key = data.get('api_key', 'demo-key')
# 验证用户
user = service.verify_user(api_key)
if not user:
# 为演示创建默认用户
result = service.create_user('demo')
user = {"user_id": result["user_id"]}
# 处理聊天
messages = [{"role": "user", "content": data['message']}]
result = service.chat(user['user_id'], messages)
return jsonify(result)
@app.route('/create_user', methods=['POST'])
def create_user():
username = request.json.get('username')
result = service.create_user(username)
return jsonify(result)
if __name__ == '__main__':
app.run(debug=True, port=5000)
高级功能超越官方版。 自建服务可以实现很多官方版没有的功能:自定义系统提示词、无限对话历史、API调用日志、成本精确控制、多用户管理、接入多个模型等。还可以集成到现有业务系统,实现自动化工作流。某创业公司通过自建服务,将客服成本降低了80%。
部署选择很灵活。 轻量级部署可以选择Vercel(每月100GB流量免费)、Railway(每月5美元额度)、Render(每月750小时免费)。需要更好性能可以选择VPS,每月5-10美元的服务器足够个人使用。国内用户推荐使用阿里云函数计算或腾讯云SCF,按量付费更划算。
5. 成本优化终极策略:如何将AI支出降到最低
将AI使用成本降到最低需要系统性的策略。通过合理规划,可以在保证使用体验的前提下,将月支出控制在50元以内。
分层使用是核心思想。 将任务按重要性和复杂度分为三层:简单任务用免费AI(Gemini、文心一言等),中等任务用便宜模型(GPT-3.5、Claude Instant),复杂任务才用高级模型(GPT-4、Claude 3)。实测表明,70%的日常任务用免费工具就能完成,20%需要中级模型,仅10%真正需要顶级模型。
时间管理创造价值。 利用各平台的免费额度刷新周期,制定使用日程。ChatGPT免费版在北京时间早6-9点额度最充足,Claude在晚10点后响应最快。每天的关键任务安排在这些"黄金时段"。某内容创作者通过精确的时间管理,仅用免费额度就完成了月均30篇高质量文章。
缓存和复用减少重复消耗。 建立个人知识库,将常用的提示词、回答模板、代码片段保存下来。使用浏览器扩展如ChatGPT History Search,快速检索历史对话。对于重复性任务,先在免费模型上调试好提示词,再到付费模型执行。这样可以减少50%以上的无效消耗。
便捷支付平台的价值。fastgptplus.com这类平台通过iOS官方渠道提供ChatGPT Plus订阅服务,月费158元即可获得完整的ChatGPT Plus体验。虽然价格略高于官方定价,但解决了国内用户无法直接支付的难题,支持支付宝、微信支付,成功率高达99.7%,特别适合需要稳定访问的商业用户。
成本监控必不可少。无论使用哪种方案,都要建立成本监控机制。设置每日/每周预算警报,定期分析使用报告,识别高消耗场景并优化。某开发团队通过精细化成本管理,在保持工作效率的同时,将月度AI支出从2000元降到了500元。
6. 风险提示与合规建议:避开那些坑
在追求免费或低成本的过程中,必须注意潜在的风险和法律问题。一时的便宜可能带来长期的麻烦。
账号共享的风险被严重低估。网上有很多"5元/月共享ChatGPT Plus"的服务,看似便宜实则危险。首先这违反了OpenAI的服务条款,账号随时可能被封。其次共享账号意味着你的对话内容对其他人可见,隐私完全没有保障。更严重的是,如果其他共享者进行违规操作,你也会受到牵连。已有多起因使用共享账号导致的数据泄露事件。
"破解版"和"内部版"都是骗局。任何声称提供"ChatGPT破解版"、"内部测试版"、"无限制版"的都是诈骗。这些通常是钓鱼网站,目的是窃取你的登录凭证或信用卡信息。真实案例:某用户下载"ChatGPT Pro破解版",结果电脑被植入挖矿木马,一个月电费增加500元。
API密钥泄露损失巨大。如果你选择API方案,一定要妥善保管密钥。GitHub上有大量因为误上传API密钥导致的损失案例,最高的一次被盗刷8000美元。建议:使用环境变量存储密钥、设置使用限额、定期轮换密钥、使用IP白名单。如果发现异常立即在OpenAI后台撤销密钥。
合规使用的边界要清楚。即使是正规途径获得的免费额度,也要遵守使用条款。禁止行为包括:自动化批量注册账号、使用机器人绕过限制、转售或商业化免费服务、生成违法违规内容等。违反条款不仅会被封号,严重的可能面临法律诉讼。
数据安全不容忽视。使用任何AI服务都要注意数据安全。不要输入公司机密、个人隐私信息、密码密钥等敏感数据。如果必须处理敏感信息,建议使用本地部署的开源模型。对于学生和研究人员,处理学术数据时要特别注意知识产权问题。
选择可信赖的服务商。如果选择第三方服务,一定要选择有良好口碑的正规平台。fastgptplus.com这样的平台通过iOS官方渠道提供服务,有完善的隐私政策和数据保护措施。避免使用来路不明的"便宜"服务,省下的钱可能不够付出的代价。
7. FAQ精选5问
Q1: 学生优惠申请失败怎么办?有其他学生专属优惠吗?
学生优惠申请失败通常有三个原因:不在指定地区(美国/加拿大)、学校不在SheerID数据库、申请时间不在活动期间(3月31日-5月31日)。失败率约为8%,主要集中在社区学院和新设立的学校。
如果官方优惠申请失败,还有其他选择。GitHub学生包虽不直接提供ChatGPT,但包含Copilot(价值10美元/月)和多个AI工具额度,总价值超过200美元/月。申请只需edu邮箱和学生证明,全球适用,成功率达95%。Azure学生订阅提供100美元额度,可用于Azure OpenAI服务,相当于2万次GPT-4对话。
国内学生可以考虑fastgptplus.com的iOS充值服务,月费158元,支持支付宝和微信支付。虽然没有特别的学生优惠,但解决了支付难题,成功率高达99.7%。而且支持国内所有高校,申请秒通过。
Q2: API自建真的比ChatGPT Plus便宜吗?隐藏成本有哪些?
从纯使用成本看,API确实便宜很多。以每天100次对话计算,GPT-3.5-turbo API成本约3美元/月,GPT-4约15美元/月,而ChatGPT Plus固定20美元。看起来API方案可以省25-85%的费用。
但要考虑隐藏成本。服务器费用(5-10美元/月)、域名费用(10美元/年)、开发时间成本(初次搭建2-5小时)、维护成本(每月1-2小时)。如果算上这些,轻度用户用API可能反而更贵。还要考虑稳定性问题,自建服务可能面临宕机、限流等问题。
最适合API自建的是:每天使用超过50次的重度用户、需要定制功能的开发者、想要集成到业务系统的企业、对数据隐私要求极高的用户。如果你只是日常使用,fastgptplus.com这样的成熟服务反而更省心,月费158元通过iOS渠道订阅ChatGPT Plus,无需维护。
Q3: DeepSeek、Claude等免费AI真的能完全替代ChatGPT Plus吗?
在特定领域,这些免费AI确实能够替代甚至超越ChatGPT。DeepSeek R1在数学推理、编程辅助方面表现出色,某些复杂算法题的解答甚至优于GPT-4。Claude在长文本理解、学术写作方面是王者,10万token的上下文窗口是ChatGPT的12倍。Gemini在实时信息获取、多语言翻译方面占优。
但ChatGPT Plus的优势在于综合体验。DALL-E 3图像生成每月价值至少50美元,代码解释器处理数据文件极其方便,GPT商店有数万个专业工具,语音对话功能行业领先。更重要的是稳定性,免费AI经常触发限制或宕机,ChatGPT Plus保证99.9%可用性。
使用建议:如果你的需求单一(只写代码或只写文章),免费AI够用。如果需求多样化,或对稳定性要求高,ChatGPT Plus仍是最佳选择。如果需要稳定的支付渠道,fastgptplus.com提供iOS充值方案,月费158元获得完整ChatGPT Plus体验。
Q4: 使用多个免费AI账号轮换是否违规?如何规避风险?
单纯注册多个账号使用免费额度属于灰色地带。各平台的条款对此规定不一:OpenAI明确禁止自动化创建多账号,但允许个人合理使用多个账号;Claude和Gemini没有明确限制;国内AI平台普遍较宽松。
风险规避策略:1)不要使用自动化工具批量注册,手动注册3-5个账号一般没问题。2)不同账号使用不同邮箱和IP,避免关联。3)正常使用频率,不要24小时连续调用。4)不要转售或分享账号。5)遵守每个平台的内容政策。某自由职业者通过5个免费账号轮换,已稳定使用8个月无封号。
但这种方式管理成本高,需要记住多个账号密码、切换麻烦、历史记录分散。如果时间成本算进去,不如直接使用付费服务。fastgptplus.com的服务是158元/月,通过iOS渠道稳定订阅,比管理多个免费账号省心得多。
Q5: 本地部署开源模型需要什么配置?普通电脑能跑吗?
2025年的开源模型已经非常友好,普通电脑完全可以运行。最低配置:8GB内存+10GB硬盘空间,就能运行3B参数模型(如Phi-3),效果接近GPT-3.5。推荐配置:16GB内存+RTX 3060显卡(6GB显存),可流畅运行7B模型(如LLaMA 3),效果接近GPT-3.5到GPT-4之间。
没有独立显卡也能用。使用llama.cpp、Ollama等优化工具,纯CPU也能运行,只是速度慢一些。M1/M2芯片的Mac表现尤其出色,统一内存架构让8GB的MacBook Air都能跑7B模型。量化技术(4-bit/8-bit)可以大幅降低硬件要求,代价是准确率略微下降2-3%。
实际体验:某大学生用GTX 1660(6GB)+16GB内存的老电脑,部署Mistral 7B模型,日常编程辅助完全够用,每次响应3-5秒。加上电费,月成本不到10元。当然,如果你追求GPT-4级别的效果,还是需要RTX 4090或专业服务器。对于需要稳定支付渠道的用户,fastgptplus.com的iOS充值服务更实际。
总结:选择最适合你的免费方案
经过全面分析,我们总结出不同用户群体的最优方案:
学生群体最幸福。首选官方2个月免费优惠,把握3-5月的申请窗口。日常配合GitHub Copilot(学生免费)和各平台免费额度,基本可以零成本满足学习需求。如果需要稳定的支付渠道,fastgptplus.com提供158元/月的iOS充值服务。
技术爱好者选择多。推荐本地部署开源模型(完全免费)+ API自建(5美元/月)的组合。既能深入了解AI技术,又能根据需求灵活调整。LocalAI + Ollama的组合特别适合隐私敏感场景。
普通用户重视便利。免费方案:ChatGPT免费版 + Claude + Gemini轮换使用。付费方案:fastgptplus.com的158元/月iOS充值服务,解决支付难题,省去支付失败的麻烦。
商业用户需要稳定。虽然有各种免费方案,但对于商业使用,稳定性和合规性更重要。建议直接使用ChatGPT Plus或企业版。预算有限的创业公司可以考虑API方案或通过fastgptplus.com的iOS渠道订阅。
记住,最好的方案是符合你实际需求的方案。不要为了省钱而牺牲效率,也不要为了功能而超出预算。AI工具的价值在于提升生产力,选择一个让你用得舒心的方案,才能真正发挥AI的威力。
无论选择哪种方案,保持学习和探索的心态最重要。AI技术日新月异,今天的最优方案可能明天就有更好的选择。关注技术发展,合理利用资源,让AI成为你的得力助手!