Gemini 2.5 Pro Free API Limits: Complete Guide for Developers (2025)
Discover Gemini 2.5 Pro's free API limits, pricing tiers, and rate restrictions. Learn how to maximize the free tier with 5 RPM and 25 daily requests, plus cost-effective alternatives.
Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
Last Updated: July 2025 - All pricing and limits verified as current
Are you looking to leverage Google's powerful Gemini 2.5 Pro AI model without breaking the bank? You're in the right place. This comprehensive guide breaks down everything you need to know about Gemini 2.5 Pro's free API limits, pricing tiers, and how to maximize your usage in 2025.

Quick Facts: Gemini 2.5 Pro Free Tier
Before diving deep, here are the key limitations you need to know:
Free Tier Limits:
• 5 requests per minute (RPM)
• 25 requests per day
• 1 million token context window
• Access via Google AI Studio
Understanding Gemini 2.5 Pro's Rate Limits
Released in March 2025, Gemini 2.5 Pro represents Google's most advanced language model with "thinking mode" capabilities. However, the free tier comes with significant restrictions that developers must understand to use effectively.
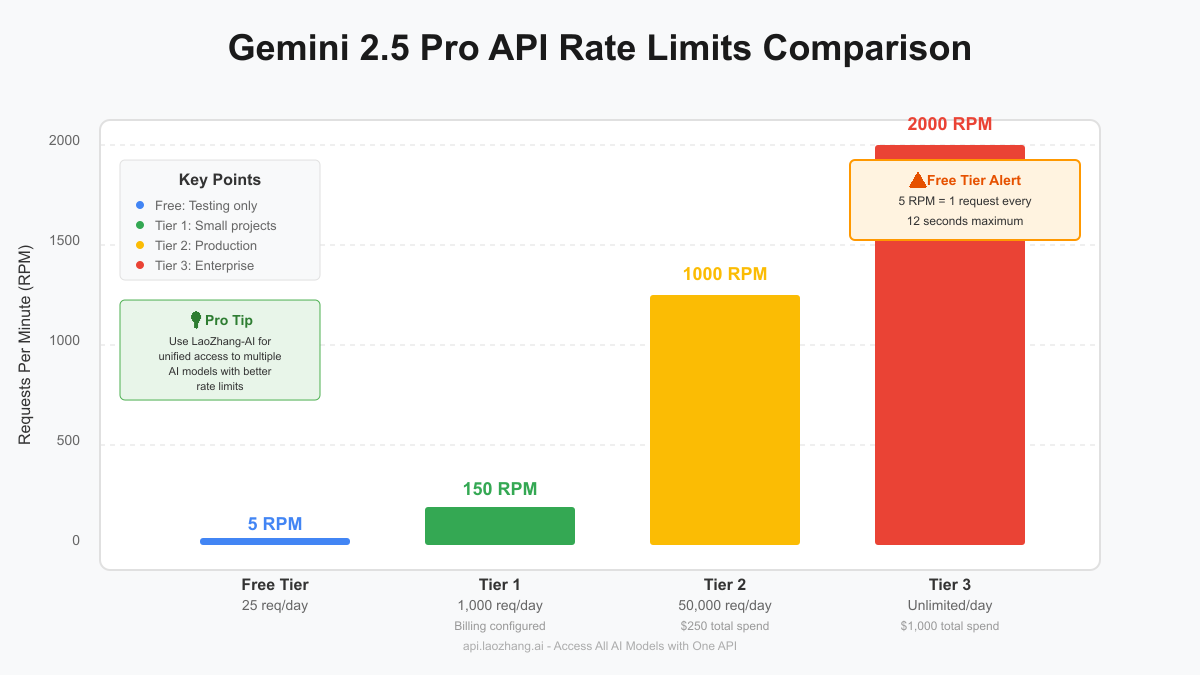
Free Tier Breakdown
The free tier's 5 RPM limit means you can only make one API request every 12 seconds. This is designed for testing and prototyping rather than production use. Here's what this means in practice:
- Development Phase: Sufficient for building and testing applications
- Proof of Concept: Adequate for demonstrating capabilities to stakeholders
- Production Use: Not suitable due to severe rate limitations
- Personal Projects: Workable for low-traffic personal applications
Paid Tier Advantages
When you're ready to scale, Gemini 2.5 Pro offers three paid tiers with progressively higher limits:
| Tier | Requirements | RPM | Daily Requests | Monthly Cost |
|---|---|---|---|---|
| Free | None | 5 | 25 | $0 |
| Tier 1 | Billing configured | 150 | 1,000 | Pay-as-you-go |
| Tier 2 | $250 total spend | 1,000 | 50,000 | Pay-as-you-go |
| Tier 3 | $1,000 total spend | 2,000 | Unlimited | Pay-as-you-go |
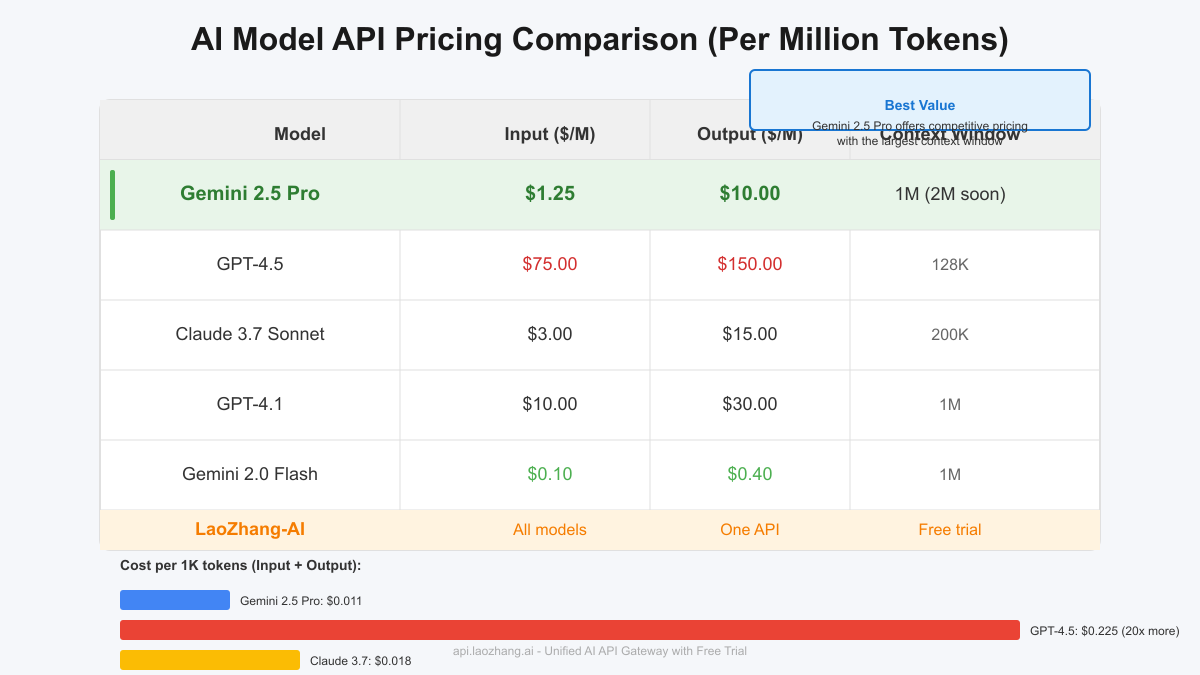
Pricing Structure: How Much Does Gemini 2.5 Pro Cost?
Understanding the pricing model is crucial for budgeting your AI projects. As of July 2025, Gemini 2.5 Pro uses a token-based pricing structure:
Standard Context (Up to 200K tokens)
- Input: $1.25 per million tokens
- Output: $10.00 per million tokens
Extended Context (200K+ tokens)
- Input: $2.50 per million tokens
- Output: $15.00 per million tokens
Cost Example: Processing a 1,000-token prompt with a 1,000-token response costs approximately $0.011 - making Gemini 2.5 Pro 20x cheaper than GPT-4.5.
How to Access the Free Tier
Getting started with Gemini 2.5 Pro's free tier is straightforward:
- Visit Google AI Studio: Navigate to aistudio.google.com
- Sign in with Google Account: Use your existing Google credentials
- Generate API Key: Click "Get API key" in the left sidebar
- Start Building: Use the key in your applications immediately
Special Programs
Students: Google offers an enhanced free tier for verified students:
- Unlimited tokens until June 30, 2026
- Same 5 RPM rate limit applies
- Verification required through student ID
Code Examples: Working with Rate Limits
Here's how to implement proper rate limiting in your applications:
Python Implementation with Retry Logic
pythonimport time
import requests
from typing import Dict, Any
class GeminiAPIClient:
def __init__(self, api_key: str):
self.api_key = api_key
self.base_url = "https://generativelanguage.googleapis.com/v1/models/gemini-2.5-pro:generateContent"
self.last_request_time = 0
self.daily_requests = 0
self.daily_reset_time = time.time()
def _enforce_rate_limit(self):
"""Enforce 5 RPM rate limit (12 seconds between requests)"""
current_time = time.time()
# Reset daily counter if new day
if current_time - self.daily_reset_time > 86400:
self.daily_requests = 0
self.daily_reset_time = current_time
# Check daily limit
if self.daily_requests >= 25:
raise Exception("Daily request limit reached (25 requests)")
# Enforce 12-second spacing
time_since_last = current_time - self.last_request_time
if time_since_last < 12:
time.sleep(12 - time_since_last)
self.last_request_time = time.time()
self.daily_requests += 1
def generate_content(self, prompt: str) -> Dict[str, Any]:
"""Generate content with automatic rate limiting"""
self._enforce_rate_limit()
headers = {
"Content-Type": "application/json",
"x-goog-api-key": self.api_key
}
data = {
"contents": [{
"parts": [{"text": prompt}]
}]
}
try:
response = requests.post(
self.base_url,
headers=headers,
json=data,
timeout=30
)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
return {"error": str(e)}
# Usage example
client = GeminiAPIClient("YOUR_API_KEY")
response = client.generate_content("Explain quantum computing in simple terms")
JavaScript/Node.js Implementation
javascriptclass GeminiRateLimiter {
constructor(apiKey) {
this.apiKey = apiKey;
this.requestQueue = [];
this.processing = false;
this.dailyRequests = 0;
this.lastResetTime = Date.now();
}
async processQueue() {
if (this.processing || this.requestQueue.length === 0) return;
this.processing = true;
while (this.requestQueue.length > 0) {
// Reset daily counter if needed
if (Date.now() - this.lastResetTime > 86400000) {
this.dailyRequests = 0;
this.lastResetTime = Date.now();
}
// Check daily limit
if (this.dailyRequests >= 25) {
console.error('Daily limit reached');
break;
}
const { prompt, resolve, reject } = this.requestQueue.shift();
try {
const response = await this.makeRequest(prompt);
this.dailyRequests++;
resolve(response);
} catch (error) {
reject(error);
}
// Wait 12 seconds between requests
await new Promise(resolve => setTimeout(resolve, 12000));
}
this.processing = false;
}
async makeRequest(prompt) {
const response = await fetch(
'https://generativelanguage.googleapis.com/v1/models/gemini-2.5-pro:generateContent',
{
method: 'POST',
headers: {
'Content-Type': 'application/json',
'x-goog-api-key': this.apiKey
},
body: JSON.stringify({
contents: [{ parts: [{ text: prompt }] }]
})
}
);
if (!response.ok) {
throw new Error(`API request failed: ${response.statusText}`);
}
return response.json();
}
async generateContent(prompt) {
return new Promise((resolve, reject) => {
this.requestQueue.push({ prompt, resolve, reject });
this.processQueue();
});
}
}
// Usage
const gemini = new GeminiRateLimiter('YOUR_API_KEY');
const response = await gemini.generateContent('Write a haiku about coding');
Comparing Gemini 2.5 Pro with Competitors
When evaluating Gemini 2.5 Pro's free tier against alternatives, consider these factors:
Performance Benchmarks (2025)
| Model | MMLU Score | Coding (SWE-bench) | Context Window | Free Tier |
|---|---|---|---|---|
| Gemini 2.5 Pro | 86% | 63.2% | 1M tokens | Yes (limited) |
| GPT-4.5 | 90.2% | 28% | 128K tokens | No |
| Claude 3.7 Sonnet | 85% | 62.3% | 200K tokens | No |
| GPT-4.1 | 90.2% | 54.6% | 1M tokens | No |
Cost-Effectiveness Analysis
For a typical use case processing 100,000 tokens daily (50K input, 50K output):
- Gemini 2.5 Pro: $0.56/day ($16.25/month)
- GPT-4.5: $11.25/day ($337.50/month)
- Claude 3.7 Sonnet: $0.90/day ($27/month)
- GPT-4.1: $2.00/day ($60/month)
Maximizing Your Free Tier Usage
To get the most out of the limited free tier:
1. Batch Your Requests
Combine multiple queries into single requests when possible:
python# Instead of multiple small requests:
# ❌ response1 = generate("What is Python?")
# ❌ response2 = generate("What is JavaScript?")
# ✅ Batch them together:
prompt = """Please answer these questions:
1. What is Python?
2. What is JavaScript?
3. Compare their use cases."""
response = generate(prompt)
2. Implement Caching
Store responses to avoid repeated API calls:
pythonimport json
import hashlib
class CachedGeminiClient(GeminiAPIClient):
def __init__(self, api_key: str, cache_file: str = "gemini_cache.json"):
super().__init__(api_key)
self.cache_file = cache_file
self.cache = self._load_cache()
def _load_cache(self) -> Dict:
try:
with open(self.cache_file, 'r') as f:
return json.load(f)
except FileNotFoundError:
return {}
def _save_cache(self):
with open(self.cache_file, 'w') as f:
json.dump(self.cache, f)
def _get_cache_key(self, prompt: str) -> str:
return hashlib.md5(prompt.encode()).hexdigest()
def generate_content(self, prompt: str) -> Dict[str, Any]:
cache_key = self._get_cache_key(prompt)
# Check cache first
if cache_key in self.cache:
return self.cache[cache_key]
# Make API call if not cached
response = super().generate_content(prompt)
# Cache successful responses
if "error" not in response:
self.cache[cache_key] = response
self._save_cache()
return response
3. Use Development Patterns
Structure your development to minimize API calls:
- Test with smaller prompts first
- Use mock responses during development
- Implement comprehensive error handling
- Log all API interactions for debugging
Alternative Solutions: LaoZhang-AI
Looking for better rate limits? LaoZhang-AI provides unified access to multiple AI models including Gemini, Claude, and GPT with a single API endpoint and free trial credits.
For developers needing higher rate limits or access to multiple models, LaoZhang-AI offers:
- Unified API: Access Gemini, Claude, GPT, and more with one key
- Better Rate Limits: Higher RPM than individual free tiers
- Cost Savings: Competitive pricing across all models
- Free Trial: Test all models before committing
Quick Integration Example
bash# Using LaoZhang-AI's unified endpoint
curl https://api.laozhang.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $LAOZHANG_API_KEY" \
-d '{
"model": "gemini-2.5-pro",
"messages": [
{"role": "user", "content": "Hello, Gemini!"}
]
}'
Troubleshooting Common Issues
Rate Limit Errors
Error: 429 Resource Exhausted
Solution: Implement exponential backoff:
pythonimport time
import random
def retry_with_backoff(func, max_retries=5):
for attempt in range(max_retries):
try:
return func()
except Exception as e:
if "429" in str(e) and attempt < max_retries - 1:
wait_time = (2 ** attempt) + random.uniform(0, 1)
time.sleep(wait_time)
else:
raise
Authentication Issues
Error: 403 Forbidden
Solutions:
- Verify API key is correct
- Check if API is enabled in Google Cloud Console
- Ensure you're using the correct endpoint
- Verify your Google account has accepted terms of service
Context Window Errors
Error: Invalid argument: Token limit exceeded
Solution: Implement token counting:
pythondef estimate_tokens(text: str) -> int:
# Rough estimation: 1 token ≈ 4 characters
return len(text) // 4
def truncate_to_limit(text: str, max_tokens: int = 1000000) -> str:
estimated_tokens = estimate_tokens(text)
if estimated_tokens > max_tokens:
# Truncate to 90% of limit for safety
max_chars = int(max_tokens * 4 * 0.9)
return text[:max_chars]
return text
Frequently Asked Questions
Can I use the free tier for commercial projects?
Yes, Google allows commercial use of the free tier, but the 5 RPM limit makes it impractical for production applications. Consider it for prototyping only.
How long will the free tier be available?
Google reviews the free tier quarterly. Based on insider information, they plan gradual reductions rather than sudden removal. Expect approximately 10% lower allowances after Q4 2025.
What happens when I exceed the daily limit?
API calls will return a 429 error code. Your quota resets at midnight Pacific Time. There's no way to purchase additional requests without upgrading to a paid tier.
Is the 1 million token context window available in the free tier?
Yes, the full 1 million token context window is available even in the free tier. The 2 million token expansion is coming soon for all tiers.
Can I combine multiple free accounts for higher limits?
This violates Google's Terms of Service and can result in account suspension. Instead, consider the paid tiers or alternative providers for production use.
How does Gemini 2.5 Pro compare to GPT-4 for coding?
Gemini 2.5 Pro scores 63.2% on SWE-bench versus GPT-4.5's 28%, making it superior for coding tasks. It also costs 60x less per token than GPT-4.5.
Future Outlook and Recommendations
Based on current trends and Google's roadmap:
Expected Changes in 2025
- Context Window: 2 million tokens coming to all tiers
- Rate Limits: Possible 10% reduction in free tier after Q4
- New Features: Enhanced multimodal capabilities
- Pricing: Likely to remain stable through 2025
Strategic Recommendations
- For Hobbyists: The free tier remains viable for personal projects
- For Startups: Plan to upgrade to Tier 1 once you validate your concept
- For Enterprises: Consider Tier 3 or negotiate custom enterprise agreements
- For Developers: Use LaoZhang-AI or similar services for multi-model access
Conclusion
Gemini 2.5 Pro's free tier offers an excellent entry point for developers exploring advanced AI capabilities. While the 5 RPM limit restricts production use, it's perfect for learning, prototyping, and building proof-of-concepts. The competitive pricing of paid tiers makes scaling affordable when you're ready.
For those needing immediate access to higher rate limits or multiple AI models, services like LaoZhang-AI provide cost-effective alternatives with unified API access and free trial credits.
Remember: Start with the free tier to validate your ideas, then scale intelligently based on your actual usage patterns and requirements. The AI API landscape is rapidly evolving, and staying informed about limits and pricing will help you make the best decisions for your projects.
Last verified: July 8, 2025. All pricing and rate limits subject to change. Check official documentation for the most current information.