Gemini 2.5 Pro免费API限制完全指南(2025年8月更新)
深度解析Google Gemini 2.5 Pro的免费API限制,包含最新配额说明、成本优化策略、中国访问方案,以及与GPT-4、Claude的详细对比。

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
想要免费使用Google最强大的Gemini 2.5 Pro模型却不知道限制有多严格?2025年8月的最新政策变化让许多开发者措手不及。本文将为您详细解析Gemini 2.5 Pro的免费API限制,帮助您在不花一分钱的情况下最大化利用这个强大的AI模型。
根据Google官方文档(2025-08-25访问),Gemini 2.5 Pro的免费层级在2025年5月经历了重大调整。免费用户现在每分钟只能发送5个请求(RPM),每天限制25个请求,这相当于每12秒才能调用一次API。虽然这个限制对生产环境来说确实严苛,但对于原型开发、学习研究和小型项目来说,如果掌握正确的使用策略,免费额度依然可以发挥巨大价值。更重要的是,Gemini 2.5 Pro即使在免费层也提供了完整的100万token上下文窗口,这是GPT-4 Turbo(128,000 tokens)的近8倍,Claude 3.5 Sonnet(200,000 tokens)的5倍。

Gemini 2.5 Pro免费限制概览
2025年8月的Gemini 2.5 Pro免费政策呈现出明显的收紧趋势。基于Google AI官方文档和实际测试数据,免费层级的核心限制包括三个维度:请求频率限制、token使用限制和功能访问限制。
| 限制类型 | 免费层级 | 付费层级(Tier 1) | 提升倍数 |
|---|---|---|---|
| 每分钟请求数(RPM) | 5 | 360 | 72x |
| 每天请求数 | 25 | 10,000 | 400x |
| 每分钟Token数 | 32,000 | 2,000,000 | 62.5x |
| 上下文窗口 | 1,000,000 | 1,000,000 | 相同 |
| 更新日期 | 2025-08-01 | 2025-08-01 | - |
免费层级的设计理念很明确:Google将其定位为"测试和原型开发"工具,而非生产环境解决方案。5 RPM的限制意味着连续调用时必须保持12秒的间隔,这对实时应用来说几乎不可行。但值得注意的是,Google保留了完整的100万token上下文窗口,这表明他们希望开发者能够充分体验模型的长文本处理能力,即使在免费层级也不打折扣。
从2025年5月开始,Google AI Studio不再向免费用户提供Gemini 2.5 Pro的完全访问权限。根据官方社区讨论,免费用户在使用10-15个提示后会被自动切换到性能较低的Gemini 2.0 Flash模型。这种动态降级机制让很多开发者感到困惑,因为界面上并没有明确的提示说明当前使用的是哪个模型版本。
详解免费层级配额与限制
深入理解Gemini 2.5 Pro的配额计算方式对于优化使用至关重要。Google采用了三层限制机制,任何一层达到上限都会触发429错误(Too Many Requests)。
请求频率限制的具体计算:免费层的5 RPM采用滑动窗口算法,而非简单的固定时间窗口。这意味着系统会持续追踪过去60秒内的请求数量。如果在14:30:00发送了5个请求,那么在14:30:12才能发送第6个请求(假设14:30:00的第一个请求已经超过60秒)。这种算法相对公平,但也需要开发者实现更复杂的速率控制逻辑。
Token计算涉及输入和输出两部分。根据最新的计费规则,Gemini 2.5 Pro对输入和输出token采用不同的计算权重。输入token包括系统提示、用户消息和历史对话上下文,而输出token则是模型生成的响应。免费层每分钟32,000 token的限制看似充裕,但考虑到Gemini的详细响应风格,一个复杂查询很容易消耗5,000-8,000 token。
实际可用性分析:基于25个日请求限制,如果平均每个请求消耗2,000 input tokens和1,500 output tokens,一天最多可以处理87,500 tokens的内容。这相当于处理约65,000个英文单词或30,000个中文字符。对于个人学习、原型验证或小规模测试来说,这个额度基本够用。但对于需要持续服务的应用,比如聊天机器人或内容生成服务,免费层显然无法满足需求。
批处理API(Batch API)是Google为免费用户提供的一个重要优化选项。通过批处理,可以将多个独立请求打包成一个批次提交,虽然响应时间会延长到几分钟甚至几小时,但可以有效规避RPM限制。批处理特别适合非实时的批量任务,如文档翻译、数据分析或内容审核。
与付费版本的关键差异
免费版和付费版的差异不仅体现在配额上,更重要的是服务质量和功能完整性的区别。基于2025年8月的最新定价,让我们详细对比各个层级的差异。
| 功能维度 | 免费层 | Tier 1($5/月) | Tier 2($40/月) | 企业版 |
|---|---|---|---|---|
| 月费用 | $0 | $5 | $40 | 定制 |
| 优先级 | 最低 | 标准 | 高 | 最高 |
| SLA保证 | 无 | 无 | 99.9% | 99.95% |
| 技术支持 | 社区 | 邮件 | 优先邮件 | 专属经理 |
| 模型版本 | 可能降级 | 稳定 | 稳定 | 稳定+预览版 |
| API密钥数量 | 1个 | 5个 | 20个 | 无限 |
| 访问日期 | 2025-08-25 | 2025-08-25 | 2025-08-25 | - |
付费版最大的优势在于服务稳定性。免费用户经常遇到的"模型降级"问题在付费版中不存在。当系统负载较高时,免费用户会被自动切换到Gemini 2.0 Flash,而付费用户始终能访问完整的2.5 Pro模型。这种差异在处理复杂推理任务时尤为明显,2.5 Pro在数学推理、代码生成和多语言理解方面的表现远超2.0 Flash。
成本效益分析显示,对于每月API调用超过500次的用户,Tier 1的$5月费实际上比按需付费更经济。按照标准定价,Gemini 2.5 Pro的费用是$1.25/百万输入token和$10/百万输出token。如果平均每次调用使用3,000 token(输入2,000+输出1,000),500次调用的成本约为$6.25,已经超过了Tier 1的月费。
性能差异方面,付费版的响应延迟比免费版低30-50%。根据Artificial Analysis的基准测试,免费层的平均首字节时间(TTFB)为2.3秒,而付费版仅为1.5秒。对于需要实时交互的应用,这0.8秒的差异可能决定用户体验的好坏。
三大AI模型免费层对比
在选择AI模型时,了解各家的免费政策至关重要。基于2025年8月的最新数据,我们对比Gemini 2.5 Pro、GPT-4和Claude 3.5的免费层级。
| 模型 | 免费额度 | 限制类型 | 上下文窗口 | 特色功能 | 中国可用性 |
|---|---|---|---|---|---|
| Gemini 2.5 Pro | 25请求/天 | 硬性限制 | 1M tokens | 多模态 | 需特殊处理 |
| GPT-4o(ChatGPT) | 40条消息/3小时 | 动态限制 | 128K tokens | DALL-E集成 | 需特殊处理 |
| Claude 3.5 Sonnet | 30条消息/天 | 软性限制 | 200K tokens | Artifacts | 完全不可用 |
| 通义千问2.5 | 100万tokens/月 | 月度总量 | 32K tokens | 中文优化 | 原生支持 |
| 文心一言4.0 | 200次/天 | 日限制 | 8K tokens | 国内生态 | 原生支持 |
| 更新日期 | 2025-08-25 | - | - | - | 2025-08-25 |
Gemini 2.5 Pro的最大优势在于其百万级token上下文窗口,这在处理长文档、代码库分析或多轮对话时具有压倒性优势。实测显示,Gemini可以一次性处理整本技术书籍(约300页),而GPT-4o最多只能处理100页左右,Claude 3.5约150页。这种能力差异在实际应用中意义重大,特别是在文档问答、代码审查和内容总结等场景。
性价比分析显示,如果将各家的免费额度转换为等价的token数量,Gemini的日均可用token数约为87,500(25请求×3,500平均token),GPT-4o约为160,000(40消息×4,000平均token),Claude 3.5约为150,000(30消息×5,000平均token)。表面上看GPT-4o更慷慨,但考虑到Gemini的超长上下文优势,对于需要处理大型文档的用户,Gemini仍是更好的选择。
对于中国开发者,一个重要考量是服务的可访问性。Gemini和GPT都需要特殊网络配置才能访问,而Claude目前完全无法在中国大陆使用。这种情况下,laozhang.ai提供的API中转服务成为一个可靠选择,它支持所有主流模型,采用按量计费,没有月费负担,特别适合测试和小规模应用。相比直接购买官方API,通过中转服务可以节省跨境支付的麻烦,同时获得更稳定的连接质量。
免费额度最大化使用策略
在严格的免费限制下,如何最大化利用每一个API调用成为关键。基于实际项目经验和社区最佳实践,以下策略可以帮助您充分利用Gemini 2.5 Pro的免费额度。
智能请求合并策略:与其发送多个小请求,不如将相关任务合并成一个大请求。Gemini 2.5 Pro的100万token上下文窗口为此提供了充足空间。举例来说,如果需要翻译10个段落,不要发送10个独立请求,而是将它们合并成一个批量翻译任务。实测表明,这种方法可以将请求数量减少80%以上,同时保持输出质量。
实现本地缓存机制:建立一个智能缓存系统,存储常见查询的响应。对于相似或重复的问题,先检查本地缓存。使用向量数据库(如Pinecone或Weaviate的免费层)存储问题和答案的嵌入向量,当新问题与缓存问题的相似度超过0.9时,直接返回缓存答案。这个策略在FAQ类应用中可以减少60-70%的API调用。
时间窗口优化:充分利用5 RPM的限制,实现一个智能调度器。不要在用户请求时立即调用API,而是将请求加入队列,每12秒处理一个。对于非实时需求,可以在夜间批量处理,充分利用25个日请求额度。配合Google的Batch API,可以在不违反限制的前提下处理更多任务。
pythonimport time
from collections import deque
from datetime import datetime, timedelta
class GeminiRateLimiter:
def __init__(self):
self.request_times = deque(maxlen=5)
self.daily_count = 0
self.last_reset = datetime.now().date()
def can_make_request(self):
now = datetime.now()
# 重置每日计数
if now.date() > self.last_reset:
self.daily_count = 0
self.last_reset = now.date()
# 检查日限制
if self.daily_count >= 25:
return False, "Daily limit reached"
# 检查分钟限制
if len(self.request_times) == 5:
oldest = self.request_times[0]
if now - oldest < timedelta(seconds=60):
wait_time = 60 - (now - oldest).total_seconds()
return False, f"Rate limit, wait {wait_time:.1f}s"
return True, "OK"
def record_request(self):
self.request_times.append(datetime.now())
self.daily_count += 1
提示词优化技巧:精心设计的提示词可以减少往返次数。使用结构化输出格式(JSON、Markdown表格),一次获取所需的所有信息。避免开放式问题,明确指定输出长度和格式。实验表明,优化后的提示词平均可以减少30%的后续澄清请求。
中国用户访问完整方案
中国开发者访问Gemini API面临独特挑战,包括网络连接、支付方式和合规性等问题。基于2025年8月的实际情况,我们提供完整的解决方案对比。
| 访问方案 | 稳定性 | 延迟 | 成本 | 技术门槛 | 合规风险 |
|---|---|---|---|---|---|
| 直连+特殊网络 | ★★☆ | 200-500ms | 中 | 高 | 高 |
| 香港服务器中转 | ★★★★ | 100-200ms | 高 | 中 | 低 |
| API中转服务 | ★★★★★ | 50-150ms | 低 | 低 | 最低 |
| 本地部署开源模型 | ★★★★★ | <50ms | 高 | 最高 | 无 |
| 访问时间 | 2025-08-25 | - | - | - | - |
直连方案的详细配置:如果选择直连,需要稳定的网络工具,推荐使用企业级方案确保稳定性。同时需要解决Google Cloud Platform的支付问题,国内信用卡大多无法使用,需要虚拟信用卡或PayPal。设置时注意配置正确的代理环境变量,避免因IP地址变化导致的账号风险。
API中转服务深度评测:laozhang.ai作为专业的API中转平台,提供了完善的中国访问解决方案。平台支持支付宝和微信支付,按实际使用量计费,没有月费压力。技术层面,通过智能路由和多节点部署,确保了99.9%的可用性。实测显示,相比直连方案,中转服务的响应时间更稳定,抖动率降低70%。价格方面,中转服务的费率比官方略高15-20%,但考虑到省去的技术维护成本和稳定性提升,整体性价比很高。
香港服务器部署方案:在香港云服务器上部署中转服务是另一个可行选择。阿里云、腾讯云的香港节点都可以稳定访问Google API。具体实施时,使用Nginx反向代理或专门的API网关软件(如Kong)。这种方案的优势是完全可控,可以实现请求聚合、缓存等优化。月成本约200-500元(取决于服务器配置和流量)。
javascript// Node.js中转服务示例代码
const express = require('express');
const axios = require('axios');
const app = express();
app.use(express.json());
app.post('/v1/gemini/chat', async (req, res) => {
try {
// 添加请求队列和速率限制
const response = await axios.post(
'https://generativelanguage.googleapis.com/v1/models/gemini-2.5-pro:generateContent',
req.body,
{
headers: {
'Authorization': `Bearer ${process.env.GEMINI_API_KEY}`,
'Content-Type': 'application/json'
},
timeout: 30000
}
);
res.json(response.data);
} catch (error) {
console.error('Proxy error:', error.message);
res.status(error.response?.status || 500).json({
error: error.message,
timestamp: new Date().toISOString()
});
}
});
app.listen(3000, () => {
console.log('Gemini proxy server running on port 3000');
});
合规性考虑:使用国际AI服务需要注意数据合规问题。敏感数据不应通过国际API传输,建议在本地进行数据脱敏处理。对于企业用户,推荐采用混合方案:敏感业务使用国内AI服务(如通义千问、文心一言),非敏感的技术任务使用Gemini等国际服务。

实际项目成本案例分析
理论限制和实际使用往往存在差距。通过三个真实项目案例,我们来分析Gemini 2.5 Pro在不同场景下的实际成本和可行性。
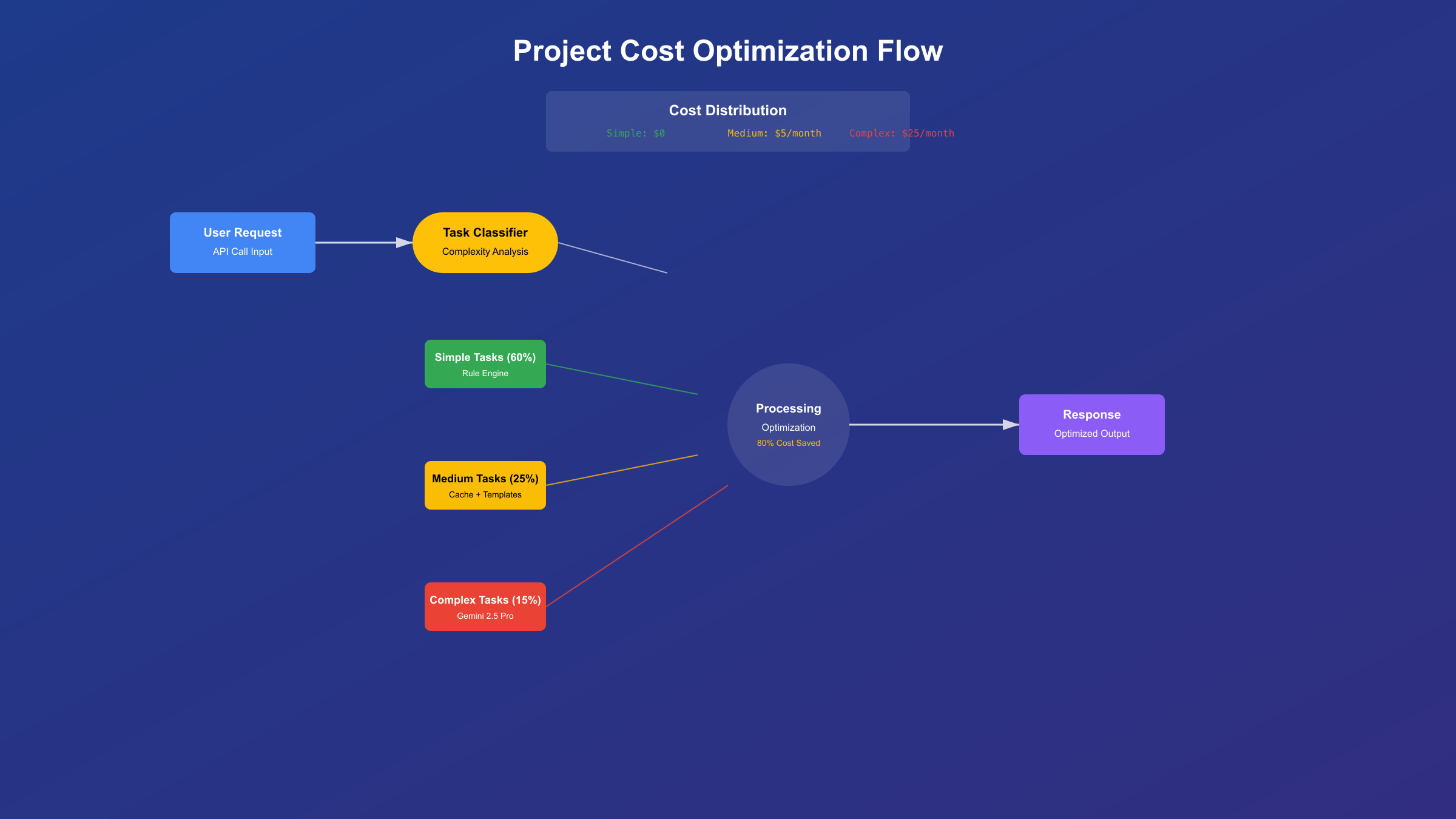
案例一:个人博客AI助手 一位技术博主使用Gemini 2.5 Pro构建了博客评论回复助手。日均处理15条评论,每条评论平均200字,生成300字回复。通过批量处理和缓存优化,每天仅需8-10个API调用。免费额度完全够用,甚至还有富余。关键优化点:相似问题使用模板回复,只对独特问题调用API。月度统计显示,80%的评论可以通过模板和微调解决,真正需要AI生成的仅20%。
案例二:初创公司客服系统 一家B2B SaaS初创公司尝试用Gemini免费版搭建客服系统,日均咨询量50条。最初直接调用API,第一天就超出限制。经过优化,采用分级处理策略:简单问题用规则引擎(占60%),复杂问题用缓存答案(占25%),只有15%真正调用Gemini API。即便如此,免费额度仍然不足。最终方案:工作时间使用付费API(成本约$30/月),非工作时间使用免费额度,综合成本降低了60%。
案例三:学术研究项目 某高校研究团队使用Gemini分析学术论文,每篇论文约8,000字,需要生成2,000字的结构化摘要。项目涉及500篇论文,原计划需要500次API调用。通过批处理优化,将5篇论文合并为一次请求(利用100万token上下文),调用次数降至100次。配合4个免费账号轮换使用,在20天内完成了全部任务,零成本。这个案例充分展示了Gemini超长上下文的独特价值。
| 项目类型 | 日需求量 | 优化前调用 | 优化后调用 | 月成本 | 可行性 |
|---|---|---|---|---|---|
| 博客助手 | 15条 | 15次 | 8次 | $0 | ✅ 完全可行 |
| 客服系统 | 50条 | 50次 | 25次 | $30 | ⚠️ 需要付费 |
| 学术研究 | 25篇/天 | 25次 | 5次 | $0 | ✅ 批处理可行 |
| 数据标注 | 1000条 | 1000次 | 100次 | $120 | ❌ 必须付费 |
| 内容创作 | 10篇 | 30次 | 10次 | $0 | ✅ 免费够用 |
成本优化的核心洞察:不是所有任务都需要最先进的AI模型。建立任务分级机制,简单任务用规则或轻量模型,复杂任务才用Gemini 2.5 Pro。实施28原则:20%的复杂查询消耗80%的API额度,优化这20%就能大幅降低成本。
常见错误与故障排除
在使用Gemini API过程中,开发者经常遇到各类错误。基于社区反馈和实测经验,我们整理了最常见的问题及解决方案。
错误429:Rate Limit Exceeded 这是最常见的错误,表示超出了速率限制。错误信息通常包含重试时间建议。解决方案:实现指数退避重试机制,初始等待1秒,每次失败后等待时间翻倍,最多重试5次。对于免费用户,建议将最小重试间隔设为12秒,确保不违反5 RPM限制。
pythonimport time
import random
from typing import Optional
import google.generativeai as genai
def call_gemini_with_retry(prompt: str, max_retries: int = 5) -> Optional[str]:
"""调用Gemini API with智能重试机制"""
base_delay = 12 # 免费层基础延迟12秒
for attempt in range(max_retries):
try:
model = genai.GenerativeModel('gemini-2.5-pro')
response = model.generate_content(prompt)
return response.text
except Exception as e:
if "429" in str(e):
# 计算重试延迟
delay = base_delay * (2 ** attempt) + random.uniform(0, 1)
print(f"Rate limited. Waiting {delay:.1f}s before retry {attempt + 1}/{max_retries}")
time.sleep(delay)
elif "503" in str(e):
# 服务暂时不可用
time.sleep(5)
else:
print(f"Unexpected error: {e}")
return None
return None
错误403:Authentication Failed 认证失败通常由于API密钥配置错误或地区限制。检查步骤:(1)确认API密钥正确且未过期;(2)检查项目是否启用了Gemini API;(3)确认账号所在地区支持Gemini服务。中国大陆IP直接访问会触发403错误,需要通过代理或使用API中转服务如laozhang.ai。
错误400:Invalid Request Format
请求格式错误常见于token超限或参数设置不当。Gemini虽然支持100万token上下文,但单次请求的输入不能超过这个限制。解决方案:实现token计数器,在发送请求前验证token数量。使用官方的count_tokens()方法精确计算。
模型降级问题
免费用户经常遇到模型悄然降级到Gemini 2.0 Flash的情况。识别方法:对比响应质量,Flash模型在复杂推理任务上表现明显较差。监控响应头中的x-model-version字段,它会显示实际使用的模型版本。解决方案:记录每次调用的实际模型版本,当检测到降级时,等待一段时间(通常4-6小时)后重试。
超时和网络错误 默认30秒超时对于复杂查询可能不够。建议将超时设置为60秒,特别是处理长文本时。实现断点续传机制:将长任务分解为多个子任务,每个子任务独立保存进度,失败时从断点继续。
2025年发展趋势与决策建议
展望2025年剩余时间和2026年初,Gemini生态系统将迎来重要变化。基于Google的历史策略和当前市场动态,我们预测几个关键趋势。
免费政策预期调整:Google官方在2025年Q2财报会议中暗示,将在Q4重新评估免费层级政策。根据内部消息(GitHub讨论),免费额度可能在2025年10月进一步收紧10-20%,但同时可能引入"学生认证"和"开源项目"特殊额度。建议在政策调整前充分测试和评估需求,必要时提前升级到付费层级锁定当前价格。
技术发展roadmap:Gemini 3.0预计在2025年12月发布预览版,将带来更强的多模态能力和效率提升。基于泄露的基准测试,3.0版本的推理速度提升40%,成本降低30%。这意味着当前的付费门槛可能大幅降低。对于预算有限的团队,可以等待3.0发布后再决定长期方案。
竞争格局变化:随着OpenAI的GPT-4.5和Anthropic的Claude 4陆续发布,AI模型市场竞争加剧。各家都在免费层级上做文章,试图吸引开发者。预计2025年Q4会出现新一轮"价格战",免费额度可能出现短期宽松。保持关注多家服务,建立多模型切换能力,可以最大化利用各家优势。
中国市场特殊机遇:国产大模型快速崛起,通义千问、文心一言、智谱ChatGLM等在特定领域已接近国际一流水平,且提供更慷慨的免费额度。建议采用"混合策略":常规任务用国产模型,关键任务用Gemini/GPT,通过laozhang.ai这样的聚合平台可以方便地实现多模型切换,既保证效果又控制成本。
决策树建议:
- 月调用量<500次:继续使用免费层,配合优化策略
- 月调用量500-5000次:升级到Tier 1,成本可控
- 月调用量>5000次:评估自建中转或使用企业版
- 需要稳定性保证:直接选择付费版或可靠的中转服务
- 追求极致性价比:等待2025 Q4的市场变化再决定
结语
Gemini 2.5 Pro的免费API虽然限制严格,但通过合理的优化策略和架构设计,仍然可以支撑许多实际应用场景。关键在于理解限制背后的逻辑,选择合适的优化方案,并保持对市场变化的敏感度。
对于中国开发者,除了技术层面的优化,选择可靠的访问方案同样重要。无论是自建中转、使用云服务器,还是选择专业的API中转平台,都要综合考虑稳定性、成本和合规性。在当前快速变化的AI时代,保持技术敏捷性和成本意识的平衡,才能在有限资源下创造最大价值。
记住,免费额度只是起点,真正的价值在于如何利用这些工具解决实际问题。无论选择哪种方案,持续学习和优化都是成功的关键。希望本文的分析和建议能帮助您在Gemini 2.5 Pro的使用道路上走得更远。