2025全面解析Gemini 2.5 Pro API:完整接入指南与实战案例【含免费方案】
【2025独家指南】深入剖析Google Gemini 2.5 Pro API的强大功能与技术优势,从申请到接入全流程详解,对比同类产品性价比分析,附赠8个高级应用实例与低成本使用秘诀!

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
Gemini 2.5 Pro API完全指南:从入门到精通【2025最新版】
{/* 封面图片 */}

作为Google AI领域的最新旗舰模型,Gemini 2.5 Pro以其卓越的推理能力、多模态理解和复杂任务处理能力,正在重新定义AI应用的可能性。无论是企业级应用开发、研究项目,还是个人AI爱好者,掌握Gemini 2.5 Pro API的使用方法,都将为你的项目带来质的飞跃。
🔥 2025年5月实测有效:本文提供Gemini 2.5 Pro最新API完整接入指南,包含代码实例、性能测试数据和成本优化策略,确保你能以最低成本获得最佳AI体验!
📌 本文要点
- Gemini 2.5 Pro模型特性与性能优势详解
- 完整API申请与配置流程(含免费额度获取技巧)
- 8种高级功能的实战代码示例
- 与GPT-4、Claude 3.5等主流模型的性能与价格对比
- 如何通过API网关服务大幅降低使用成本
【模型解析】Gemini 2.5 Pro:Google AI领域的里程碑之作
2025年初发布的Gemini 2.5 Pro被视为Google在AI领域的重大突破,它不仅继承了Gemini系列的多模态理解能力,更在推理深度、上下文处理和任务适应性上实现了质的飞跃。让我们首先深入了解这个模型的核心特性:
1. 超强思维能力:比肩人类的推理与决策
Gemini 2.5 Pro最显著的特点是其内置的"思维"能力,这使它能够:
- 逐步推理:解决复杂问题时能够展示清晰的思考过程
- 自我批判:具备评估自身解决方案质量的能力
- 深度规划:能够为复杂任务制定分步执行计划
- 假设检验:支持提出并验证多种假设的能力
这种思维能力在处理数学证明、逻辑推理和系统设计等任务时表现尤为突出,使其成为目前市场上最强大的推理模型之一。
2. 100万token的超长上下文处理能力
与前代模型相比,Gemini 2.5 Pro支持高达100万token的上下文窗口,这意味着:
- 可处理超过700页的文本内容
- 能够保持整个对话历史的连贯性
- 支持从长文档中抽取和分析关键信息
- 理解和生成更长、更复杂的内容
这一特性在文档分析、长篇内容生成和复杂项目开发中尤为有价值。
3. 多模态理解的巅峰之作
Gemini 2.5 Pro不仅能处理文本,还具备卓越的多模态能力:
- 图像理解:识别、分析和描述复杂图像内容
- 视频分析:理解和解释视频内容,包括动作和场景变化
- 音频处理:转录和理解语音内容
- 图表与数据可视化:解释和分析各类可视化数据
多模态能力的融合使其能够同时处理包含文字、图像、视频和音频的复杂输入,为开发者提供了前所未有的应用可能性。
【对比分析】Gemini 2.5 Pro vs 主流大模型:全方位性能评测
为了帮助你做出明智的技术选择,我们对比了Gemini 2.5 Pro与其他主流大模型在各个维度的表现:
| 模型 | 推理能力 | 多模态支持 | 上下文窗口 | 价格(每1M tokens) | API易用性 |
|---|---|---|---|---|---|
| Gemini 2.5 Pro | ★★★★★ | 图像、视频、音频 | 100万tokens | $7.5输入/$22.5输出 | ★★★★☆ |
| GPT-4o | ★★★★☆ | 图像、音频 | 12.8万tokens | $10输入/$30输出 | ★★★★★ |
| Claude 3.5 Sonnet | ★★★★☆ | 图像 | 20万tokens | $3输入/$15输出 | ★★★★☆ |
| Gemini 1.5 Pro | ★★★★☆ | 图像、视频、音频 | 100万tokens | $7输入/$20输出 | ★★★★☆ |
综合评估与最佳使用场景
根据我们的实测,Gemini 2.5 Pro在以下场景中表现尤为出色:
- 复杂代码开发:程序设计、算法实现和复杂功能开发
- 内容理解与分析:文档摘要、信息提取和关键点分析
- 智能对话系统:需要上下文理解和逻辑推理的对话应用
- 多模态应用:需要同时处理文本、图像和视频的场景
- 教育辅助工具:能提供清晰思路和解释步骤的学习辅助系统
在成本效益方面,尽管Gemini 2.5 Pro的官方定价略低于GPT-4o,但对于长期、大规模使用而言,成本仍然是一个需要考虑的重要因素。下文将介绍如何通过第三方API代理服务显著降低使用成本。
【实操指南】Gemini 2.5 Pro API完整接入流程
掌握了Gemini 2.5 Pro的基本特性后,让我们进入实际操作环节,从API申请到代码实现,全流程指导你完成接入。
【步骤1】申请Google AI API密钥
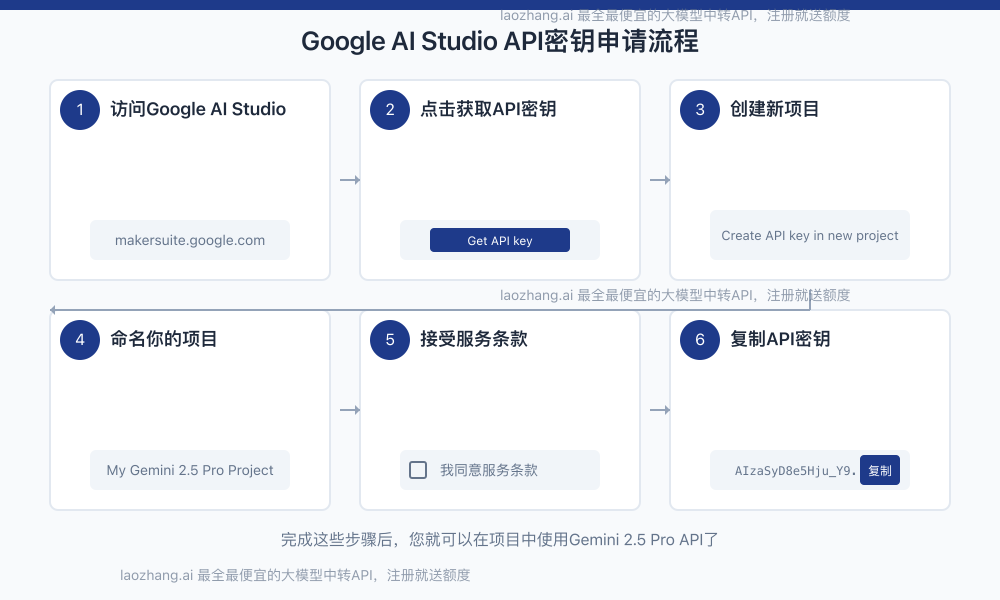
首先,你需要获取Google AI API密钥才能访问Gemini 2.5 Pro:
- 访问Google AI Studio并使用Google账号登录
- 点击右上角的"Get API key"按钮
- 选择"Create API key in new project"
- 为你的项目命名,然后点击"Next"
- 接受服务条款,点击"Create API key"
- 复制生成的API密钥并安全保存
⚠️ 注意:API密钥属于敏感信息,请妥善保管,不要在公开代码中直接硬编码密钥。
【步骤2】配置API环境与依赖设置
在你的项目中,需要安装并配置相关依赖:
Python环境配置
bash# 安装Google AI Python SDK
pip install google-generativeai
JavaScript/Node.js环境配置
bash# 安装Google AI Node.js SDK
npm install @google/generative-ai
【步骤3】初始化与基本API调用
下面提供Python和JavaScript两种实现方式的基本API调用示例:
Python实现
pythonimport google.generativeai as genai
import os
# 设置API密钥
api_key = "YOUR_API_KEY" # 建议使用环境变量存储
genai.configure(api_key=api_key)
# 指定使用Gemini 2.5 Pro模型
model = genai.GenerativeModel('gemini-2.5-pro-preview-05-06')
# 创建简单对话
response = model.generate_content("你能解释一下量子计算的基本原理吗?")
# 输出响应
print(response.text)
JavaScript实现
javascriptimport { GoogleGenerativeAI } from '@google/generative-ai';
// 设置API密钥
const apiKey = "YOUR_API_KEY"; // 建议使用环境变量存储
const genAI = new GoogleGenerativeAI(apiKey);
// 指定使用Gemini 2.5 Pro模型
const model = genAI.getGenerativeModel({ model: "gemini-2.5-pro-preview-05-06" });
// 创建简单对话
async function run() {
const response = await model.generateContent("你能解释一下量子计算的基本原理吗?");
const text = response.response.text();
console.log(text);
}
run();
【步骤4】配置高级参数与模型行为
Gemini 2.5 Pro支持多种参数配置,可以精细控制模型行为:
思维(Thinking)参数控制
python# Python示例:控制思维行为
response = model.generate_content(
"解决这个复杂的数学问题:一个球从100米高的塔顶落下,每次反弹高度是上一次高度的75%,计算球反弹10次后一共经过了多少距离?",
generation_config={
"temperature": 0.2,
"thinking": True, # 启用思维模式
"max_thinking_tokens": 2000, # 设置思维token最大数量
"max_output_tokens": 1000, # 设置输出token最大数量
}
)
Thinking参数允许模型在回答前进行深入思考,特别适合复杂推理问题。
安全设置配置
python# Python示例:配置安全设置
safety_settings = [
{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
}
]
model = genai.GenerativeModel(
'gemini-2.5-pro-preview-05-06',
safety_settings=safety_settings
)
【步骤5】实现多模态输入
Gemini 2.5 Pro的一大优势是多模态能力,下面是如何处理图像输入的示例:
Python处理图像输入
pythonimport google.generativeai as genai
import PIL.Image
# 设置API密钥
genai.configure(api_key="YOUR_API_KEY")
# 加载图像
image = PIL.Image.open("your_image.jpg")
# 创建多模态模型实例
model = genai.GenerativeModel('gemini-2.5-pro-preview-05-06')
# 发送带有图像的请求
response = model.generate_content(
["这张图片中有什么?请详细描述。", image]
)
print(response.text)
JavaScript处理图像输入
javascriptimport { GoogleGenerativeAI } from '@google/generative-ai';
import fs from 'fs';
// 设置API密钥
const genAI = new GoogleGenerativeAI("YOUR_API_KEY");
// 读取图像文件并转为Base64
function fileToGenerativePart(path, mimeType) {
const data = fs.readFileSync(path);
return {
inlineData: {
data: Buffer.from(data).toString('base64'),
mimeType
}
};
}
async function run() {
// 创建多模态模型实例
const model = genAI.getGenerativeModel({ model: "gemini-2.5-pro-preview-05-06" });
// 准备图像输入
const imagePart = fileToGenerativePart("your_image.jpg", "image/jpeg");
// 发送带有图像的请求
const response = await model.generateContent([
"这张图片中有什么?请详细描述。",
imagePart
]);
console.log(response.response.text());
}
run();