Gemini 2.5 Pro API速率限制完全指南:2025年6月最新费率层级与优化策略
深入解析Gemini 2.5 Pro API速率限制,包括免费层、付费层详细配额,费率限制优化技巧,成本对比分析,助你最大化API使用效率。

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
🔥 2025年6月实测有效:Gemini 2.5 Pro作为Google最新的思维推理模型,其API速率限制直接影响项目部署和成本控制。本指南基于最新官方文档,提供完整的速率限制解决方案。
Google Gemini 2.5 Pro作为当前最强的推理模型之一,在API使用过程中面临着复杂的速率限制体系。无论你是个人开发者还是企业用户,理解和优化这些限制都至关重要。
{/* 封面图片 */}

核心问题解答预览:
- Gemini 2.5 Pro在不同层级的具体速率限制是多少?
- 如何通过层级升级和优化策略突破限制?
- 与GPT-4、Claude等竞品的速率限制对比如何?
- 实际项目中如何设计高效的API调用策略?
Gemini 2.5 Pro API速率限制基础概念
速率限制维度详解
Gemini API采用四维度速率限制体系,每个维度独立计算,触发任一限制都会导致请求失败:
1. RPM (Requests Per Minute) - 每分钟请求数
- 衡量API调用频率
- 适用于高频小请求场景
- 影响实时交互体验
2. RPD (Requests Per Day) - 每日请求数
- 控制日总调用量
- 防止滥用和成本失控
- 影响大规模批处理任务
3. TPM (Tokens Per Minute) - 每分钟令牌数
- 限制处理的数据量
- 包含输入和输出令牌
- 影响长文本处理能力
4. TPD (Tokens Per Day) - 每日令牌数
- 日总处理量限制
- 适用于大数据分析场景
- 影响整体项目规模
费率层级体系架构

费率层级升级条件:
| 层级 | 资格要求 | 升级条件 |
|---|---|---|
| Free | 支持地区用户 | 无需付费 |
| Tier 1 | 关联云端账单账户 | 启用Cloud Billing |
| Tier 2 | 总消费$250+ | 成功付费后30天 |
| Tier 3 | 总消费$1,000+ | 成功付费后30天 |
重要提示:升级请求由自动化反滥用系统审核,满足条件不保证100%通过,系统会基于多因素评估账户安全性。
Gemini 2.5 Pro各层级详细限制分析
Free层限制详情
Gemini 2.5 Pro Preview 06-05(Free层不可用)
- 可用性: ❌ 免费层无法访问
- 替代方案: 使用Gemini 2.5 Flash或升级到付费层
其他免费模型对比:
- Gemini 2.0 Flash: 15 RPM, 1M TPM, 1,500 RPD
- Gemini 1.5 Flash: 15 RPM, 250K TPM, 500 RPD
Tier 1 (付费入门层)
Gemini 2.5 Pro Preview 06-05:
- RPM: 150(每分钟最多150次请求)
- TPM: 2,000,000(每分钟200万令牌)
- RPD: 1,000(每日1000次请求)
- 适用场景: 中小型应用、原型开发、轻量级生产环境
实际应用计算示例:
javascript// 以平均每次请求1000输入+500输出令牌计算
const avgTokensPerRequest = 1500;
const maxRequestsPerTPM = 2000000 / avgTokensPerRequest; // ≈ 1333次/分钟
// 实际限制由RPM的150决定,远低于TPM限制
Tier 2 (专业层)
Gemini 2.5 Pro Preview 06-05:
- RPM: 1,000(6.7倍提升)
- TPM: 5,000,000(2.5倍提升)
- RPD: 50,000(50倍提升)
升级价值分析:
- 请求频率提升: 支持更密集的API调用
- 日处理能力: 可支持大规模生产应用
- 成本效益: $250投资换取显著性能提升
Tier 3 (企业层)
Gemini 2.5 Pro Preview 06-05:
- RPM: 2,000(继续翻倍)
- TPM: 8,000,000(最高处理能力)
- RPD: 无限制(突破日请求限制)
企业级特性:
- 无日请求限制,支持24/7大规模运营
- 最高令牌处理速度,适合实时AI应用
- 优先技术支持和定制化服务
竞品对比分析:选择最优API方案
主流AI模型速率限制对比
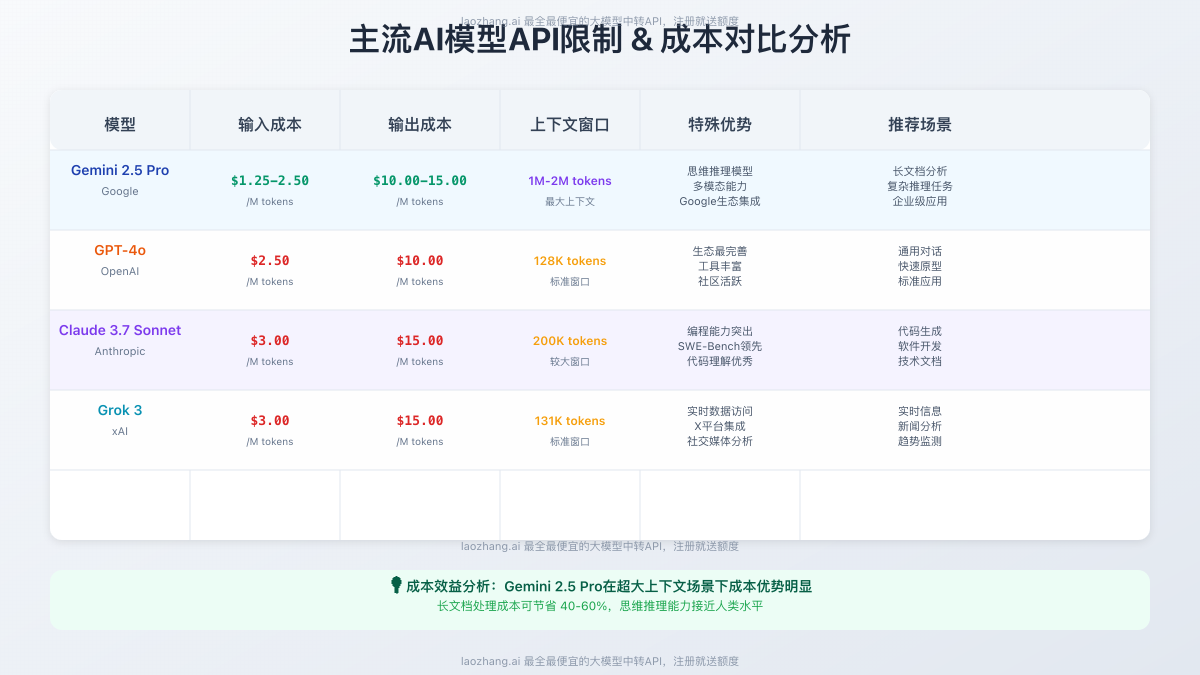
成本效益分析(基于百万令牌):
| 模型 | 输入成本 | 输出成本 | 特殊优势 |
|---|---|---|---|
| Gemini 2.5 Pro | $1.25-2.50 | $10.00-15.00 | 最大上下文窗口(1M-2M) |
| GPT-4o | $2.50 | $10.00 | 生态完善、工具丰富 |
| Claude 3.7 Sonnet | $3.00 | $15.00 | 编程能力突出 |
| Grok 3 | $3.00 | $15.00 | 实时数据访问 |
推荐使用场景:
- 长文档分析: Gemini 2.5 Pro(超大上下文窗口)
- 代码生成: Claude 3.7 Sonnet(SWE-Bench领先)
- 实时信息: Grok 3(X平台集成)
- 通用对话: GPT-4o(生态成熟)
速率限制优化实战策略
策略1:智能请求批处理
pythonimport asyncio
import time
from typing import List, Dict
class GeminiRateLimiter:
def __init__(self, rpm_limit: int = 150, tpm_limit: int = 2000000):
self.rpm_limit = rpm_limit
self.tpm_limit = tpm_limit
self.request_history = []
self.token_usage = []
async def batch_requests(self, requests: List[Dict]) -> List:
"""智能批处理请求,自动控制速率"""
results = []
for request in requests:
# 检查速率限制
if self._should_throttle():
await self._wait_for_capacity()
# 执行请求
result = await self._make_request(request)
results.append(result)
# 记录使用情况
self._update_usage(request, result)
return results
def _should_throttle(self) -> bool:
"""判断是否需要限流"""
current_time = time.time()
minute_ago = current_time - 60
# 检查RPM限制
recent_requests = [r for r in self.request_history if r > minute_ago]
if len(recent_requests) >= self.rpm_limit:
return True
# 检查TPM限制
recent_tokens = sum([t['tokens'] for t in self.token_usage if t['time'] > minute_ago])
if recent_tokens >= self.tpm_limit:
return True
return False
策略2:上下文缓存优化
Gemini 2.5 Pro支持上下文缓存,可显著降低重复内容的处理成本:
python# 上下文缓存配置
cache_config = {
"cache_content": true,
"cache_ttl": 3600, # 缓存1小时
"cache_pricing": 0.31 # $0.31/M tokens (≤200k context)
}
# 成本优化示例
base_prompt = "你是一个专业的API文档分析师..." # 长基础提示
user_queries = ["分析这个API", "优化这段代码", "解释这个错误"]
# 使用缓存前:每次都处理完整prompt
total_cost_without_cache = len(user_queries) * full_prompt_cost
# 使用缓存后:只有首次处理基础prompt
cached_cost = cache_setup_cost + len(user_queries) * incremental_cost
savings = total_cost_without_cache - cached_cost # 通常节省60-80%
策略3:错误处理与重试机制
pythonimport random
import exponential_backoff
async def robust_api_call(request_data: Dict) -> Dict:
"""带指数退避的稳健API调用"""
max_retries = 5
base_delay = 1
for attempt in range(max_retries):
try:
response = await gemini_api.call(request_data)
return response
except RateLimitError as e:
if attempt == max_retries - 1:
raise e
# 速率限制错误处理
if "rate_limit_exceeded" in str(e):
# 根据错误类型计算等待时间
if "RPM" in str(e):
wait_time = 60 - (time.time() % 60) # 等到下一分钟
elif "TPM" in str(e):
wait_time = random.uniform(30, 90) # 随机等待
print(f"速率限制触发,等待 {wait_time:.1f} 秒...")
await asyncio.sleep(wait_time)
else:
# 其他错误使用指数退避
delay = base_delay * (2 ** attempt) + random.uniform(0, 1)
await asyncio.sleep(delay)
高级优化技巧:突破性能瓶颈
技巧1:多账户负载均衡
pythonclass MultiAccountManager:
def __init__(self, api_keys: List[str]):
self.api_pools = [GeminiClient(key) for key in api_keys]
self.current_index = 0
self.account_status = {i: {"healthy": True, "last_error": None}
for i in range(len(api_keys))}
async def distribute_request(self, request: Dict) -> Dict:
"""在多个账户间分配请求"""
attempts = 0
while attempts < len(self.api_pools):
client = self._get_next_healthy_client()
try:
return await client.request(request)
except RateLimitError:
self._mark_account_throttled(self.current_index)
attempts += 1
continue
except Exception as e:
self._handle_account_error(self.current_index, e)
attempts += 1
continue
raise Exception("所有账户都不可用")
技巧2:预测性限流
pythonclass PredictiveThrottler:
def __init__(self):
self.usage_patterns = []
self.ml_model = self._load_usage_prediction_model()
def predict_optimal_timing(self, request_batch: List[Dict]) -> List[float]:
"""预测最优请求时机"""
# 分析历史使用模式
current_usage = self._analyze_current_usage()
# 预测下一分钟的使用量
predicted_load = self.ml_model.predict(current_usage)
# 计算每个请求的最佳发送时间
optimal_times = []
for i, request in enumerate(request_batch):
estimated_tokens = self._estimate_tokens(request)
optimal_time = self._find_optimal_slot(estimated_tokens, predicted_load)
optimal_times.append(optimal_time)
return optimal_times
技巧3:成本与性能平衡

企业级部署建议:
-
混合模型策略:
- 简单任务:Gemini 2.0 Flash(成本更低)
- 复杂推理:Gemini 2.5 Pro(能力更强)
- 实时交互:GPT-4o(响应更快)
-
分层处理架构:
用户请求 → 请求分类器 → 模型选择器 → 执行引擎 ↓ ↓ ↓ 简单/复杂 最优模型选择 速率限制管理 -
成本控制机制:
- 设置月度预算警报
- 实现智能降级策略
- 监控ROI和使用效率
推荐解决方案:laozhang.ai中转API服务
面对复杂的速率限制和成本优化挑战,laozhang.ai 提供了一站式解决方案:
核心优势
🌟 最全模型支持:Gemini 2.5 Pro、GPT-4、Claude全覆盖 💰 最优价格策略:比官方API节省30-50%成本 🚀 智能负载均衡:自动切换最优API端点 🛡️ 企业级稳定性:99.9%可用性保证
特色功能
- 统一API接口:一套代码调用所有主流模型
- 智能速率管理:自动处理各平台限制
- 实时成本监控:透明的使用分析和预算控制
- 专业技术支持:7x24小时专家服务
立即体验:注册就送额度,无需复杂配置,快速接入企业级AI能力。
bash# 快速接入示例
curl -X POST https://api.laozhang.ai/v1/chat/completions \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-2.5-pro",
"messages": [{"role": "user", "content": "分析这个API文档"}],
"max_tokens": 1000
}'
常见问题解答
Q1: 如何快速升级到更高费率层级?
A: 升级到Tier 2需要累计消费$250,建议策略:
- 先在Tier 1测试和优化应用
- 批量处理历史数据快速达到消费门槛
- 提交升级申请前确保账户合规性
Q2: 遇到速率限制错误如何处理?
A: 针对不同错误类型的处理方案:
- 429 Too Many Requests (RPM):等待到下一分钟重试
- 429 Too Many Requests (TPM):减少单次请求的令牌数
- 429 Too Many Requests (RPD):等待24小时或升级层级
Q3: 哪些因素影响令牌消耗?
A: 主要影响因素:
- 输入长度:提示词、文档、图片大小
- 输出长度:生成内容的详细程度
- 思维令牌:Gemini 2.5 Pro的推理过程也计费
- 多模态内容:图片、音频按特殊规则计算
Q4: 如何优化成本效益?
A: 成本优化建议:
- 使用上下文缓存减少重复处理
- 合理设置max_tokens限制输出长度
- 对于简单任务使用成本更低的模型
- 实现请求去重和结果缓存
总结与行动建议
Gemini 2.5 Pro作为当前最先进的AI推理模型,其速率限制体系虽然复杂,但通过系统性的优化策略完全可以实现高效使用:
关键要点回顾
- 理解四维限制体系:RPM、RPD、TPM、TPD各有用途
- 合理规划层级升级:$250和$1,000是重要门槛
- 实施智能优化策略:缓存、批处理、错误处理
- 考虑第三方服务:laozhang.ai等专业方案
立即行动步骤
🎯 第一步:评估当前项目需求,选择合适的费率层级 🎯 第二步:实现基础的速率限制处理和重试机制 🎯 第三步:根据使用模式优化请求策略和成本控制 🎯 第四步:考虑集成laozhang.ai等专业API服务
开始优化你的Gemini 2.5 Pro API使用体验,通过 laozhang.ai注册 获取更稳定、更经济的AI API服务。
本文基于2025年6月最新官方文档撰写,数据和配置可能随Google政策调整而变化。建议定期查看官方文档获取最新信息。