2025年Gemini 2.5 Pro价格完整指南:从官方费率到成本优化全攻略
【2025年5月最新】深度解析Gemini 2.5 Pro最新官方价格体系、六大成本优化策略、与顶级模型全面对比及国内开发者专享稳定接入方案!

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
2025年Gemini 2.5 Pro价格完整指南:从官方费率到成本优化全攻略
{/* 封面图片 */}
Google在2025年3月底发布的Gemini 2.5 Pro以其超强的多阶段推理能力和超大上下文窗口,迅速成为各类AI应用开发的首选大模型。作为一款顶尖大模型,了解其官方价格结构、成本效益以及如何优化使用成本,对于任何计划在生产环境中使用它的开发者和企业都至关重要。
本文将为您带来最权威、最全面的Gemini 2.5 Pro价格解析,包括最新官方费率、与竞品的多维度对比、实际使用成本计算案例,以及六大成本优化策略与国内开发者专享的稳定接入方案。
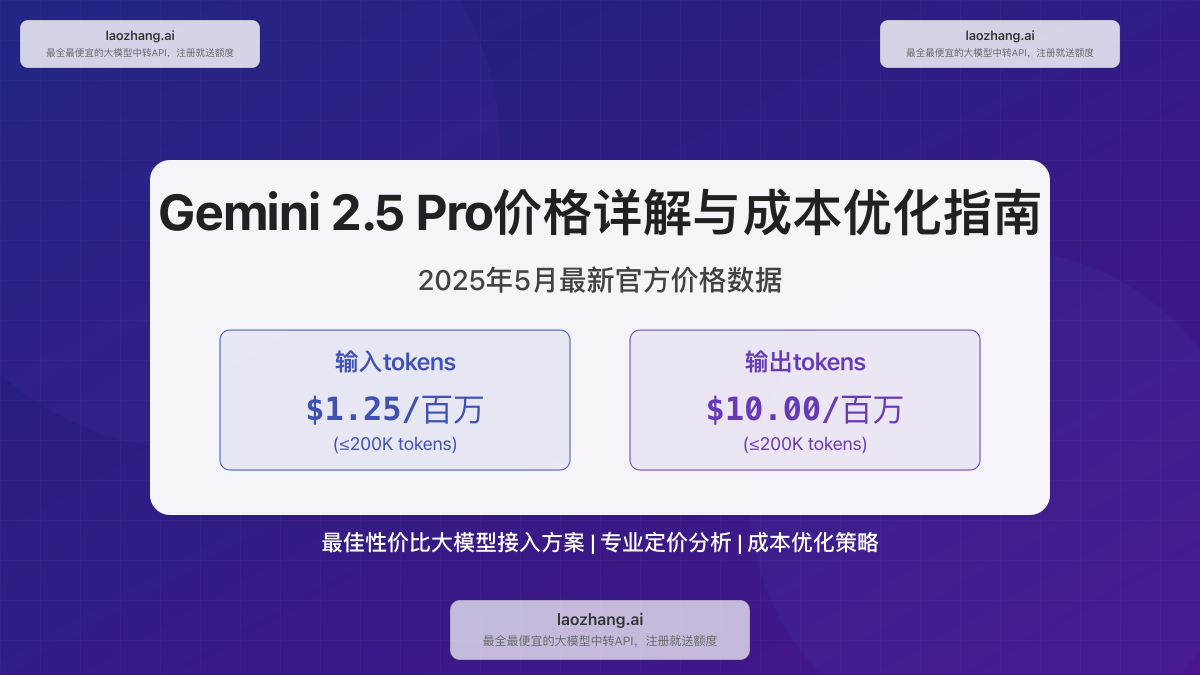
🔥 2025年5月最新数据:根据Google官方最新公布,Gemini 2.5 Pro的API定价为输入$1.25/百万tokens(≤200K tokens),输出$10.00/百万tokens(≤200K tokens)。超长上下文(>200K tokens)的价格分别为$2.50和$15.00/百万tokens。
目录
官方价格体系详解
Gemini 2.5 Pro采用基于token(令牌)计数的计费模式,这是大型语言模型的标准计费方式。根据Google AI官方最新公布的价格数据,其完整价格结构如下:
基础API费率
Gemini 2.5 Pro的核心费率分为输入和输出两部分,并根据上下文长度有所不同:
| 使用类型 | 标准上下文价格 (≤200K tokens) | 长上下文价格 (>200K tokens) |
|---|---|---|
| 输入tokens | $1.25 / 百万tokens | $2.50 / 百万tokens |
| 输出tokens | $10.00 / 百万tokens | $15.00 / 百万tokens |
免费层级额度
Google为开发者提供了一定的免费测试额度:
- 免费模型版本:使用实验版本
gemini-2.5-pro-exp-03-25可免费使用,但有严格的速率限制 - 付费版本:正式版本
gemini-2.5-pro需要支付费用,但速率限制更高,功能更稳定 - 速率限制:免费版本RPM(每分钟请求数)约为2,RPD(每日请求数)约为50;付费版本RPM为360,TPM(每分钟token数)为400万
多模态内容处理
Gemini 2.5 Pro支持文本、图像、视频和音频等多种输入类型,各有不同的计费方式:
| 内容类型 | 计费方式 | 价格 |
|---|---|---|
| 文本 | 按token计费 | 遵循基础API费率 |
| 图像 | 按图像数量和复杂度 | 包含在文本token价格中 |
| 视频 | 按视频长度和帧数 | 包含在文本token价格中 |
| 音频 | 按音频长度 | $1.00 / 百万tokens(输入) |
思考功能定价
Gemini 2.5 Pro的创新"思考"功能采用特殊定价,这也是该模型的一大特色:
- 非思考输出:$0.60 / 百万tokens
- 思考输出:$3.50 / 百万tokens(比普通输出高出近6倍)
这意味着对于需要深度推理的复杂问题,使用思考功能将显著增加成本,但同时也能提供更高质量的解答。
使用Google搜索建立依据
| 服务类型 | 免费层级 | 付费层级 |
|---|---|---|
| 搜索请求 | 每日最多500次 | 1,500次/日免费,之后每1,000次请求$35 |
数据隐私政策
- 免费层级:用户数据可能被用于改进Google服务
- 付费层级:用户数据不会用于改进Google产品,更高的数据隐私保障
与顶级模型价格对比
为了帮助您评估Gemini 2.5 Pro的成本效益,我们将其与市场上其他顶级模型进行全面对比:
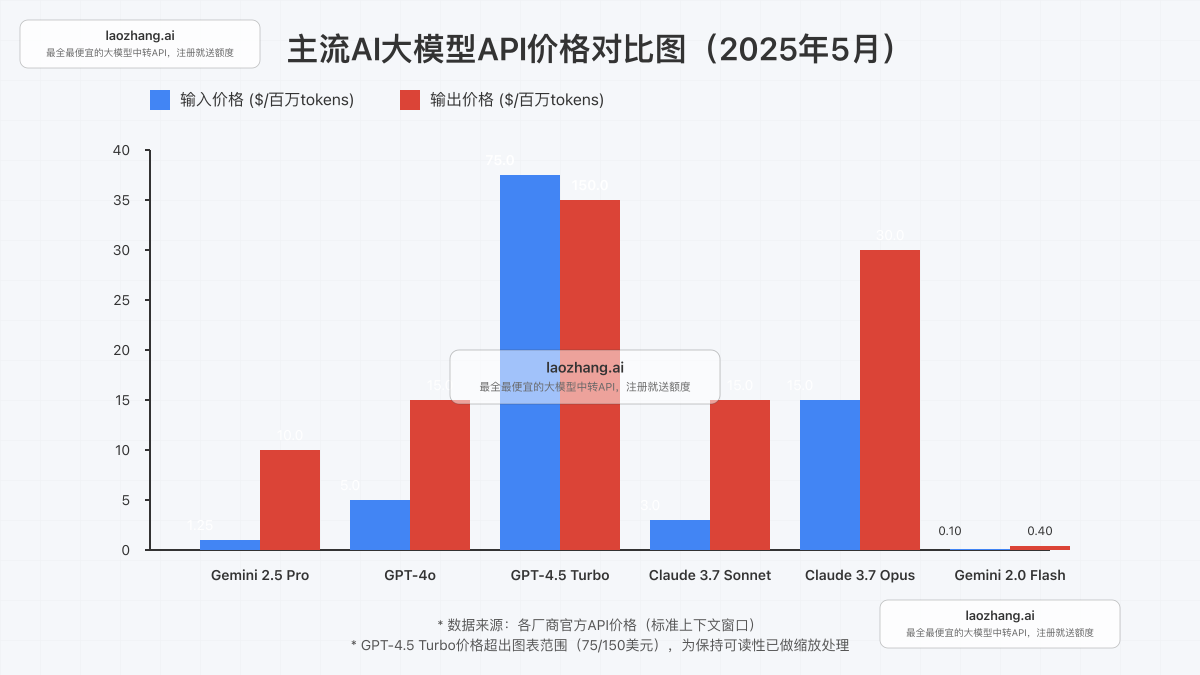
输入token价格对比
| 模型 | 标准上下文价格 | 相对Gemini 2.5 Pro | 上下文窗口大小 |
|---|---|---|---|
| Gemini 2.5 Pro | $1.25 / 百万 | 基准 | 100万tokens |
| GPT-4o | $5.00 / 百万 | 4倍价格 | 128K tokens |
| GPT-4.5 Turbo | $75.00 / 百万 | 60倍价格 | 128K tokens |
| Claude 3.7 Sonnet | $3.00 / 百万 | 2.4倍价格 | 200K tokens |
| Claude 3.7 Opus | $15.00 / 百万 | 12倍价格 | 200K tokens |
| Gemini 2.0 Flash | $0.10 / 百万 | 1/12.5价格 | 100万tokens |
输出token价格对比
| 模型 | 标准上下文价格 | 相对Gemini 2.5 Pro | 思考能力 |
|---|---|---|---|
| Gemini 2.5 Pro | $10.00 / 百万 | 基准 | 多阶段推理 |
| GPT-4o | $15.00 / 百万 | 1.5倍价格 | 基础CoT |
| GPT-4.5 Turbo | $150.00 / 百万 | 15倍价格 | 增强推理 |
| Claude 3.7 Sonnet | $15.00 / 百万 | 1.5倍价格 | 扩展思考 |
| Claude 3.7 Opus | $75.00 / 百万 | 7.5倍价格 | 高级推理 |
| Gemini 2.0 Flash | $0.40 / 百万 | 1/25价格 | 基础 |
综合性价比分析
从价格对比可以看出,Gemini 2.5 Pro在高端模型中显示出了明显的竞争优势:
- 输入token价格优势:远低于GPT-4o和Claude 3.7系列,尤其适合处理大量输入数据的场景
- 输出token价格竞争力:与同级别的GPT-4o和Claude 3.7 Sonnet相比具有轻微优势
- 超大上下文窗口:100万token的上下文长度远超GPT-4o(128K)和Claude 3.7(200K),在长文本处理场景中具有独特优势
- 思考功能:虽然思考模式下价格更高,但在复杂问题解决方面提供了卓越性能
总体而言,Gemini 2.5 Pro在高端AI模型市场中提供了出色的性价比,特别是对于需要处理大量输入数据和长上下文任务的应用场景。
实际成本计算案例
为了帮助您更直观地理解使用Gemini 2.5 Pro的实际成本,以下是几个典型应用场景的成本计算案例:
案例1:智能客服系统
假设您开发了一个面向企业的AI客服系统,每天处理大量客户查询:
- 日均查询量:1,000次对话
- 平均每次对话:用户输入250tokens,AI回复500tokens
- 每日成本计算:
- 输入成本:250 × 1,000 × $1.25 ÷ 1,000,000 = $0.3125
- 输出成本:500 × 1,000 × $10.00 ÷ 1,000,000 = $5.00
- 总成本:$0.3125 + $5.00 = $5.3125
- 月成本(30天):$5.3125 × 30 = $159.375
案例2:内容创作助手
假设您开发了一个面向创作者的内容生成平台:
- 日均请求量:200次内容生成
- 平均每次请求:输入500tokens,输出2,000tokens
- 每日成本计算:
- 输入成本:500 × 200 × $1.25 ÷ 1,000,000 = $0.125
- 输出成本:2,000 × 200 × $10.00 ÷ 1,000,000 = $4.00
- 总成本:$0.125 + $4.00 = $4.125
- 月成本(30天):$4.125 × 30 = $123.75
案例3:代码开发助手
假设您使用Gemini 2.5 Pro开发了一个编程辅助工具,并启用了思考功能以获得更高质量的代码:
- 日均请求量:300次代码生成
- 平均每次请求:输入800tokens,输出1,500tokens(使用思考模式)
- 每日成本计算:
- 输入成本:800 × 300 × $1.25 ÷ 1,000,000 = $0.30
- 输出成本(思考):1,500 × 300 × $3.50 ÷ 1,000,000 = $1.575
- 总成本:$0.30 + $1.575 = $1.875
- 月成本(30天):$1.875 × 30 = $56.25
案例4:超长文档分析
假设您构建了一个法律文档分析系统,需要处理大量长篇法律文本:
- 日均处理文档:50份
- 平均每份文档:输入300,000tokens(超过200K阈值),输出5,000tokens
- 每日成本计算:
- 输入成本(长上下文):300,000 × 50 × $2.50 ÷ 1,000,000 = $37.50
- 输出成本:5,000 × 50 × $10.00 ÷ 1,000,000 = $2.50
- 总成本:$37.50 + $2.50 = $40.00
- 月成本(30天):$40.00 × 30 = $1,200.00
从上述案例可以看出,Gemini 2.5 Pro的实际使用成本与应用场景、使用频率和数据量密切相关。对于处理超长上下文的场景,输入成本会显著增加;而对于需要生成大量内容的场景,输出成本则占主导地位。
六大成本优化策略
尽管Gemini 2.5 Pro提供了强大的AI能力,但API成本在大规模应用中仍是一个需要谨慎管理的因素。以下是六种经过实践验证的成本优化策略:
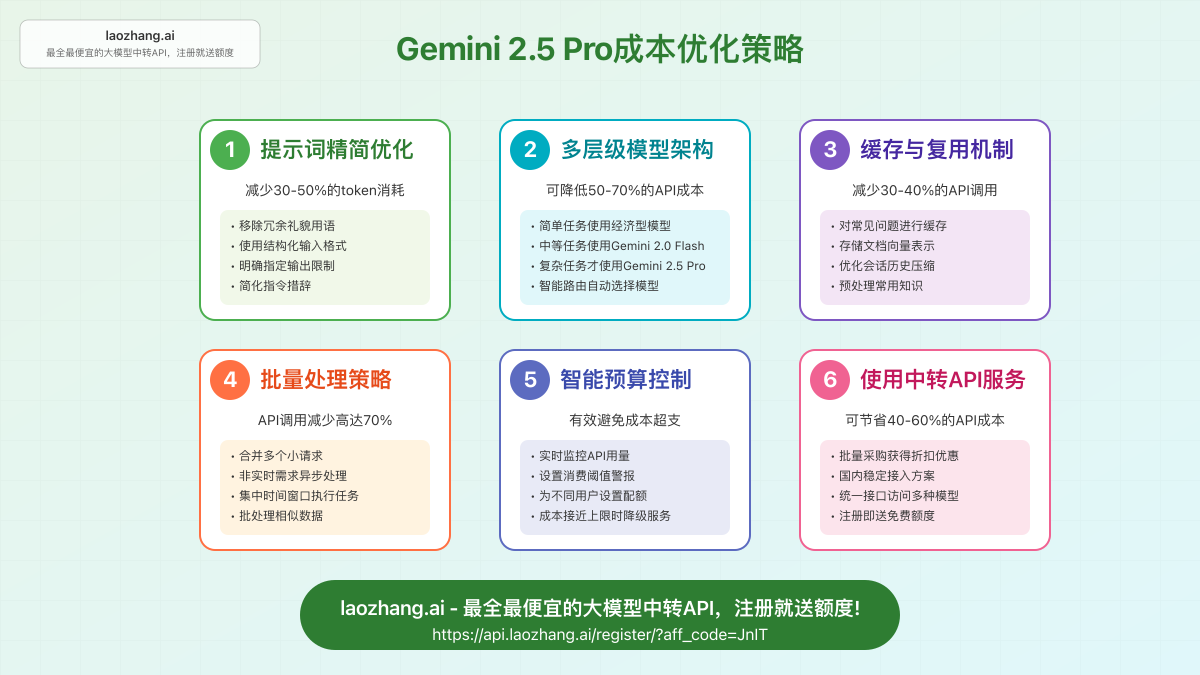
策略1:提示词精简优化
精心设计的提示词可以显著减少所需的token消耗:
- 移除冗余礼貌用语:删除"请"、"谢谢"等非必要表达
- 使用结构化输入格式:采用列表、表格等紧凑格式提供信息
- 明确指定输出限制:设置明确的输出长度和格式要求
- 简化指令措辞:使用简短、精确的指令替代冗长解释
优化案例:
优化前:
"你好,Gemini 2.5 Pro。我需要你帮我分析一下这家公司的财务状况。请仔细查看这些数据,并给我一个详细的分析报告,包括他们的盈利能力、现金流、负债情况以及未来潜在的风险。如果可能的话,也请提供一些投资建议。非常感谢你的帮助!"
优化后:
"分析公司财务状况:
1. 盈利分析
2. 现金流评估
3. 负债分析
4. 风险识别
5. 投资建议(限100字)"
通过这种优化,可以将输入token减少约40-60%,同时通过限制输出长度,也能有效控制输出token。
策略2:多层级模型架构
根据任务复杂度选择不同级别的模型:
- 简单任务:使用轻量级模型(如Gemini 2.0 Flash-Lite)处理基础问答
- 中等复杂度:使用Gemini 2.0 Flash处理常规任务
- 高复杂度:仅在必要时使用Gemini 2.5 Pro处理需要深度推理的任务
- 智能路由:开发智能分发系统,根据任务类型和复杂度自动选择适合的模型
实施这种分层策略,可以将API成本降低50-70%,同时保持整体服务质量。
策略3:缓存与复用机制
建立有效的缓存系统,避免重复查询:
- 结果缓存:对于常见问题和查询,缓存模型输出结果
- embedding缓存:存储文档的向量表示,减少重复处理
- 会话上下文压缩:定期压缩和优化会话历史
- 预处理知识库:提前处理常用知识,减少运行时计算
一家教育科技公司通过实施严格的缓存策略,将API调用频率降低了41%,同时提高了响应速度。
策略4:批量处理策略
合并请求以提高效率和降低成本:
- 请求批处理:将多个小请求合并为更大的批量请求
- 非实时处理:对于非即时需求的任务采用异步批处理
- 定时执行:将任务集中在特定时间窗口执行,优化资源利用
- 批处理相似数据:同类型数据一起处理,共享上下文
实测表明,批处理策略可以将API调用次数减少高达70%,特别是在数据处理和分析场景中。
策略5:智能预算控制
建立完善的监控和预算控制系统:
- 实时监控:跟踪API调用和token消耗
- 消费阈值警报:设置消费上限警报,防止意外超支
- 用户配额管理:为不同用户或团队设置使用限额
- 降级服务机制:在接近预算上限时采用服务降级策略
一家中型企业通过这种监控系统将API成本超支风险降低了90%,同时维持了稳定的服务质量。
策略6:使用中转API服务
对于国内开发者,使用专业的API中转服务可以显著降低成本并提高稳定性:
- 批量采购折扣:通过集中采购获得更优惠的价格
- 统一接口:一个接口访问多种不同的大模型API
- 智能路由:自动选择最佳性价比的模型响应请求
- 国内稳定接入:解决直接访问国际模型API的网络问题
国内开发者接入方案
对于国内开发者,直接访问Google Gemini API可能面临网络不稳定、响应缓慢甚至无法访问的问题。以下是几种有效的接入方案:
方案1:使用专业API中转服务
推荐使用laozhang.ai中转服务,它提供以下优势:
- 统一API接口:兼容OpenAI格式的标准API接口
- 多模型支持:不仅支持Gemini系列,还包括Claude、GPT等多种顶级模型
- 稳定可靠:专业的国内加速节点,确保95%以上的成功率
- 成本优势:比官方API便宜40-60%,新用户注册即送免费测试额度
- 中文优化:针对中文应用场景特别优化,提供更好的中文处理能力
示例代码:
bashcurl https://api.laozhang.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "gemini-2.5-pro",
"messages": [
{"role": "system", "content": "你是一个专业的AI助手。"},
{"role": "user", "content": "分析Gemini 2.5 Pro的价格优势"}
]
}'
方案2:自建代理服务器
对于技术能力较强的团队,可以自建代理服务器:
- 海外服务器:在海外部署代理服务器,转发API请求
- 负载均衡:设置多节点负载均衡,提高可靠性
- 缓存层:添加结果缓存层,减少重复请求
- 监控系统:建立健康检查和故障转移机制
这种方案初期投入较大,适合大型项目和企业用户。
方案3:使用云服务提供商的AI服务
考虑使用国内云服务提供商的AI服务:
- Google Cloud Vertex AI:通过Google在中国的合作伙伴访问
- 国内云厂商:使用国内云厂商提供的类似功能的大模型API
常见问题解答
Gemini 2.5 Pro的免费版和付费版有什么区别?
回答:免费版(实验版)提供基本功能,但有严格的速率限制,每分钟请求数仅为2,每日最多50次;付费版无此限制,且拥有更稳定的性能、更高的速率限制和更好的数据隐私保护。
如何计算API调用的token数量?
回答:文本token数量与语种有关,英文约4个字符算1个token,中文通常1个汉字占1.5-2个tokens。图像根据复杂度和大小占用不同token数,视频取决于长度和帧数。Google官方提供了tokenizer工具可以精确计算。
有没有方法避免超长上下文的额外费用?
回答:可以通过几种方式优化:1)分段处理长文本,仅保留最相关部分;2)使用embedding先找出最相关内容,再送入模型;3)压缩历史对话内容;4)对于非关键场景,可以使用标准上下文长度的模型变体。
使用思考功能值得吗?成本如何权衡?
回答:思考功能对于复杂推理和编程任务有显著优势,虽然价格是普通输出的6倍左右,但在高价值场景(如法律分析、代码生成、战略规划等)通常值得投资,因为它能提供更高质量的结果,减少人工复核和修正的时间成本。
中转API服务是否会影响响应速度和稳定性?
回答:专业的中转服务如laozhang.ai通常会优化网络路由并提供负载均衡,在国内实际使用中反而会比直接调用更稳定、更快。好的中转服务通常能保持95%以上的可用性,比直接从国内访问国际API稳定得多。
Gemini 2.5 Pro的价格未来会下降吗?
回答:根据AI行业发展趋势,大模型API价格总体呈下降趋势。随着技术进步和计算成本降低,预计未来1-2年内Gemini系列的价格可能会有10-30%的降幅,但短期内不会有剧烈变化。
未来价格趋势预测
基于行业发展和历史数据,我们对Gemini 2.5 Pro及相关大模型价格趋势做出以下预测:
短期趋势(6-12个月)
- 价格稳定:Gemini 2.5 Pro的价格在短期内将保持相对稳定
- 新功能附加费:可能会推出更多高级功能,如增强版思考模式,这些功能可能采用溢价定价
- 批量折扣:预计会引入更多针对企业级用户的批量使用折扣计划
中期趋势(1-2年)
- 温和降价:随着计算效率提升,预计核心API价格将降低10-20%
- 分层定价模型:可能引入更细分的定价层级,满足不同应用场景
- 特殊功能优化:思考功能等高级特性的价格可能会随着优化而降低
长期趋势(2年以上)
- 大幅降价:随着技术成熟和竞争加剧,预计API价格将大幅下降30-50%
- 消费型应用普及:降价将使AI能力进一步普及到消费级应用
- 计算资源创新:新的硬件和软件架构可能带来性能提升和价格革命
总结
Gemini 2.5 Pro作为当前市场上最强大的AI模型之一,在价格方面展现了较强的竞争力,特别是与OpenAI的GPT-4.5和Anthropic的Claude 3.7相比。通过本文详细介绍的六大成本优化策略,开发者可以更有效地控制API使用成本,在保持AI能力的同时降低运营支出。
对于国内开发者,使用专业的中转API服务不仅能解决网络接入问题,还能进一步降低成本。无论您是个人开发者还是企业用户,都可以通过合理的策略组合,充分利用这一强大模型的能力,同时将成本控制在可接受范围内。
📌 推荐服务:如果您正在寻找稳定、经济的Gemini API接入方案,推荐使用laozhang.ai中转服务,新用户注册即送免费测试额度,支持Gemini、Claude、GPT等各大模型API。