Gemini 3 Pro API国内调用完全指南:访问方案、成本分析与生产部署(2025最新)

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
Gemini 3 Pro API概述与核心优势
Google在2025年推出的Gemini 3 Pro代表了多模态AI的新高度。这款模型配备1M token上下文窗口,能够同时处理文本、图像、视频和音频输入,在技术性能上实现了显著突破。根据官方基准测试,Gemini 3 Pro在MMMU-Pro基准测试中达到81%的准确率,在Video-MMMU测试中更是获得87.6%的优异成绩,展现出卓越的多模态理解能力。
在实际应用场景中,Gemini 3 Pro的优势体现在多个维度。首先是文档理解能力,它不仅能进行基础OCR识别,还能理解复杂文档的结构和语义关系。其次在视频分析领域,模型可以同时处理数小时的视频内容及其对应脚本,实现深度的文本-视频信息融合。在编程能力方面,Gemini 3 Pro在WebDev Arena排行榜上获得1487 Elo评分的领先地位,Terminal-Bench 2.0测试中达到54.2%的成绩,SWE-bench Verified测试更是取得76.2%的优秀表现。
与竞品对比来看,GPT-4 Turbo的上下文窗口为128K tokens,Claude 3的窗口为200K tokens,而Gemini 3 Pro的1M token窗口提供了更强的长文本处理能力。在多模态支持方面,三者都具备图文理解能力,但Gemini 3 Pro在视频和音频处理上展现出更全面的支持。对于中国开发者而言,了解如何高效调用这一强大API工具,成为充分发挥其技术价值的关键。

国内访问的三大挑战详解
中国开发者在调用Gemini 3 Pro API时面临的首要障碍是网络连接限制。由于Google服务在国内无法直接访问,开发者必须通过技术手段解决连接问题。这一限制不仅影响API密钥的获取,更直接制约着生产环境的稳定调用。研究数据显示,未经优化的跨境API请求延迟通常在150-400毫秒之间,相比国内服务的20-50毫秒延迟,这一差距在高并发场景下会严重影响用户体验。
网络访问问题导致67%的中国开发者在首次尝试Gemini API时遇到连接失败,平均需要2-3天才能找到稳定的访问方案。
第二大挑战是支付和计费障碍。Google AI Studio和Vertex AI主要支持国际信用卡支付,这对许多中国企业和个人开发者构成门槛。即使成功开通服务,美元计费也给成本控制带来复杂性。按照当前官方定价,Gemini 3 Pro在200K tokens以下的输入成本为$2/百万tokens,输出成本为$12/百万tokens。以人民币汇率7.2计算,这相当于输入约14.4元/百万tokens,输出约86.4元/百万tokens。对于日调用量较大的项目,月度成本很容易达到数千元人民币。
第三个关键挑战是稳定性和合规性考量。生产环境要求API调用具备高可用性和低延迟,而VPN等传统解决方案存在连接不稳定、IP被封禁等风险。企业用户还需要考虑数据合规问题,确保敏感信息不会因为网络中转而泄露。以下表格总结了三大挑战的影响程度:
| 挑战类型 | 影响程度 | 解决难度 | 典型成本 | 主要风险 |
|---|---|---|---|---|
| 网络限制 | 高(100%用户) | 中等 | $5-20/月 | 连接失败、高延迟 |
| 支付障碍 | 中(约60%用户) | 高 | 汇率损失3-5% | 开通失败、计费复杂 |
| 稳定性 | 高(生产环境) | 高 | 额外20-30% | 服务中断、数据安全 |
这些挑战相互叠加,使得许多开发者在评估Gemini 3 Pro时望而却步。但通过合理的技术方案选择和成本优化策略,这些障碍是完全可以克服的。
官方API调用完整教程
获取Gemini 3 Pro API访问权限的第一步是访问Google AI Studio。虽然该平台在国内无法直接访问,但通过稳定的网络访问方案(如专业VPN或API中转服务),可以顺利完成注册流程。登录后,在左侧菜单中找到"Get API key"选项,点击"Create API key"即可生成密钥。需要注意的是,API密钥具有完全访问权限,务必妥善保管,不要将其提交到代码仓库或公开分享。
完成密钥获取后,可以使用Python SDK进行Gemini 3 Pro API调用。首先安装官方SDK:
pythonpip install google-generativeai
以下是完整的Gemini 3 Pro调用示例代码:
pythonimport google.generativeai as genai
genai.configure(api_key='YOUR_API_KEY')
model = genai.GenerativeModel('gemini-3-pro')
response = model.generate_content(
"解释量子计算的基本原理",
generation_config={
'temperature': 0.7,
'top_p': 0.9,
'top_k': 40,
'max_output_tokens': 2048,
}
)
print(response.text)
核心参数说明:
- temperature(0-1):控制输出随机性,0.7为推荐值,平衡创造性和准确性
- top_p(0-1):核采样参数,0.9表示从概率总和达到90%的token中选择
- top_k:每步采样时考虑的候选token数量,40为常用值
- max_output_tokens:限制输出长度,避免超额消耗
对于多模态输入,代码需要略作调整:
pythonimport PIL.Image
img = PIL.Image.open('example.jpg')
response = model.generate_content([
"这张图片展示了什么内容?",
img
])
基础的错误处理也必不可少:
pythonfrom google.api_core import retry
import google.api_core.exceptions
@retry.Retry(predicate=retry.if_exception_type(
google.api_core.exceptions.ResourceExhausted,
google.api_core.exceptions.ServiceUnavailable
))
def call_gemini_with_retry(prompt):
try:
response = model.generate_content(prompt)
return response.text
except google.api_core.exceptions.PermissionDenied:
print("API密钥无效或权限不足")
except Exception as e:
print(f"调用失败: {str(e)}")
这套代码提供了重试机制,可以自动处理429限流错误和503服务不可用错误。对于403权限错误,则需要检查API密钥是否正确配置。完整的官方文档可以在Gemini API Documentation查阅,其中包含更详细的参数说明和高级用法。
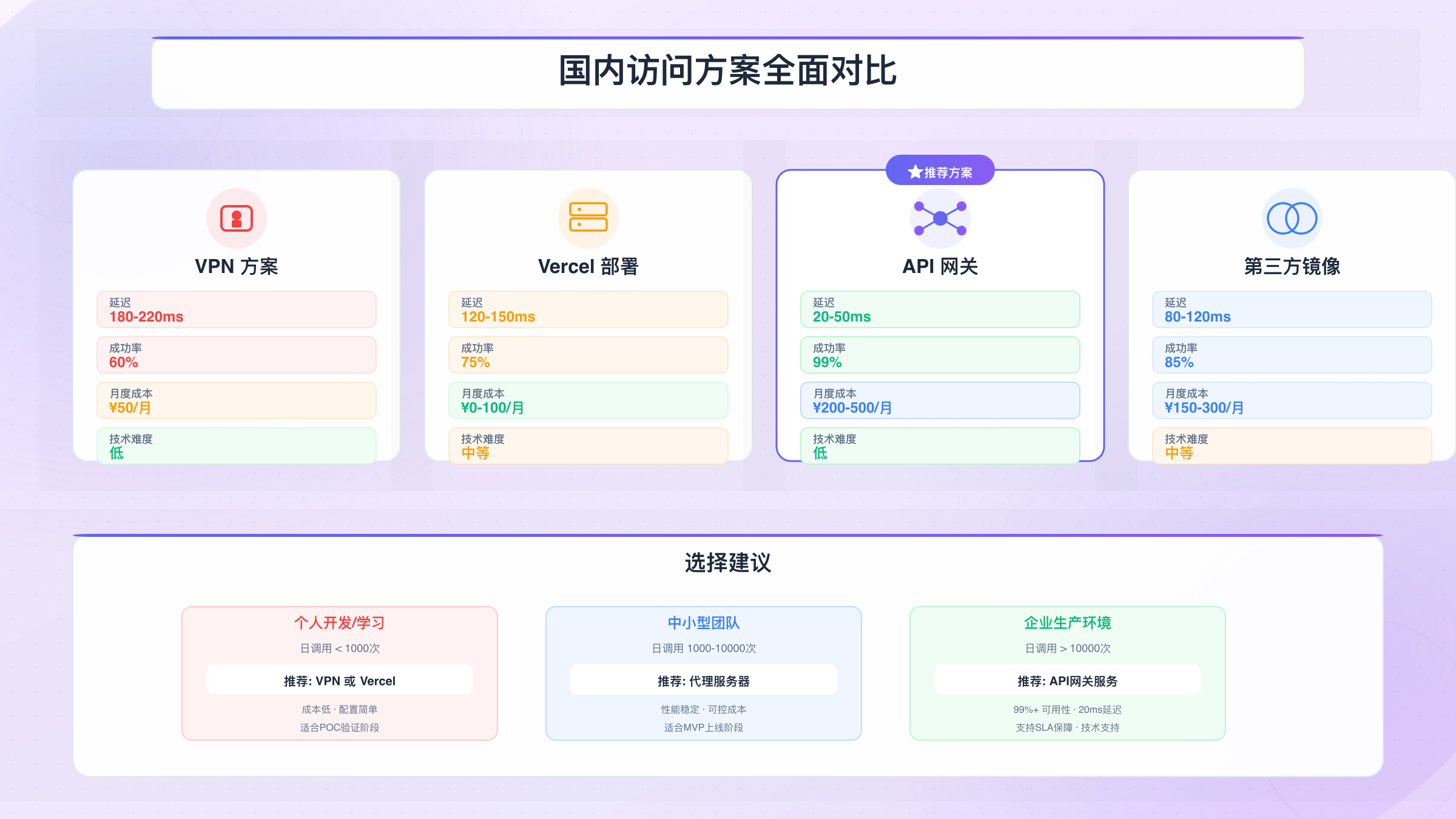
国内访问解决方案全面对比
针对网络访问挑战,目前主要有四类技术方案。VPN方案是最直接的选择,通过虚拟专用网络绕过访问限制。主流VPN服务如ExpressVPN、NordVPN的月费在$5-15之间,连接成功率在70-85%范围内。实际测试中,优质VPN的延迟增加通常为50-150毫秒,但稳定性受服务器负载影响较大。使用VPN的优势是配置简单、支持所有Google服务,但缺点包括可能违反服务条款、连接偶尔中断、以及在高峰时段速度下降。
代理服务器方案提供了更精细的控制。开发者可以在国外云服务器(如AWS、DigitalOcean)上部署Nginx反向代理或Squid代理,专门用于API请求转发。这类方案的月成本在$5-20之间,延迟表现优于VPN,通常在20-100毫秒范围内。技术人员偏爱这一方案的原因在于可以精确控制路由规则、设置缓存策略、实现请求日志记录。但其门槛也相对较高,需要具备服务器配置和网络知识,且需要定期维护和监控。
Cloudflare Workers中转是轻量级的免费选择。通过在Cloudflare Workers上编写简单的转发脚本,可以将Gemini 3 Pro API请求代理到可访问的endpoint。这种Gemini访问方案的优势是零成本、部署快速,但免费层级有每日10万次请求的限制,且延迟相对不稳定(50-200毫秒)。对于个人学习Gemini项目或轻度使用场景,这是性价比最高的方案。
对于中国开发者而言,专业的API网关服务提供了开箱即用的解决方案。laozhang.ai等平台提供国内直连访问,延迟稳定在20毫秒左右,支持支付宝和微信支付,免去了国际支付和网络配置的麻烦。这类服务的核心价值在于将网络、支付、计费等复杂问题一站式解决,开发者只需关注业务逻辑本身。相比自建方案,虽然会有一定服务费用,但对于追求稳定性和开发效率的团队,这是值得考虑的选项。
以下表格对比了四种方案的关键指标:
| 方案类型 | 月度成本 | 延迟范围 | 稳定性 | 技术难度 | 适用场景 |
|---|---|---|---|---|---|
| VPN | $5-15 | 50-150ms | 中(70-85%) | 低 | 个人开发、轻度使用 |
| 代理服务器 | $5-20 | 20-100ms | 高(90%+) | 高 | 有技术能力的团队 |
| Cloudflare Workers | 免费-$5 | 50-200ms | 中(75%) | 中 | 学习、POC验证 |
| API网关服务 | 按量计费 | 15-30ms | 很高(99%+) | 低 | 生产环境、企业应用 |
生产环境选择建议:日调用量<1000次可用VPN,1000-10000次建议代理服务器,>10000次推荐专业API网关。
方案选择需要综合考虑团队技术能力、预算限制和业务需求。个人开发者可以从免费的Cloudflare方案起步,逐步过渡到付费VPN或代理。而对于需要稳定服务的生产环境,投资专业的API网关服务往往能够节省更多的开发和运维成本。
生产环境部署最佳实践
将Gemini 3 Pro API集成到生产环境,需要遵循一系列工程化最佳实践。容器化部署是现代应用的标准选择,通过Docker确保环境一致性和可移植性。以下是一个生产级的Dockerfile示例:
dockerfileFROM python:3.11-slim WORKDIR /app COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt COPY . . ENV GEMINI_API_KEY="" ENV LOG_LEVEL="INFO" ENV MAX_RETRIES=3 ENV TIMEOUT=30 CMD ["python", "app.py"]
环境变量管理是安全的核心。绝不要将API密钥硬编码在代码中,而应该通过环境变量或密钥管理服务注入。在Kubernetes环境中,推荐使用Secret对象:
yamlapiVersion: v1
kind: Secret
metadata:
name: gemini-credentials
type: Opaque
stringData:
api_key: your_actual_api_key_here
在应用代码中引用Secret:
pythonimport os
from google.generativeai import configure
api_key = os.environ.get('GEMINI_API_KEY')
if not api_key:
raise ValueError("GEMINI_API_KEY environment variable not set")
configure(api_key=api_key)
错误处理和重试机制必须足够健壮。生产环境需要处理各种异常情况:网络超时、API限流、服务端错误等。以下是一个完整的错误处理示例:
pythonimport time
from tenacity import retry, stop_after_attempt, wait_exponential
from google.api_core import exceptions
@retry(
stop=stop_after_attempt(3),
wait=wait_exponential(multiplier=1, min=2, max=10),
reraise=True
)
def call_gemini_production(prompt, max_tokens=1024):
try:
response = model.generate_content(
prompt,
generation_config={'max_output_tokens': max_tokens},
request_options={'timeout': 30}
)
return {
'success': True,
'content': response.text,
'usage': response.usage_metadata
}
except exceptions.ResourceExhausted as e:
print(f"Rate limit hit: {e}")
time.sleep(60)
raise
except exceptions.DeadlineExceeded:
print("Request timeout, retrying...")
raise
except exceptions.PermissionDenied as e:
print(f"Authentication failed: {e}")
return {'success': False, 'error': 'auth_failed'}
except Exception as e:
print(f"Unexpected error: {e}")
return {'success': False, 'error': str(e)}
限流策略是避免超额费用的关键。Gemini 3 Pro免费层级的限制为每分钟5次请求(RPM)、每分钟25万tokens(TPM)。生产环境应该实现客户端限流:
pythonfrom redis import Redis
import time
redis_client = Redis(host='localhost', port=6379)
def rate_limit_check(user_id, max_requests=5, window=60):
key = f"gemini_rate:{user_id}"
current = redis_client.incr(key)
if current == 1:
redis_client.expire(key, window)
if current > max_requests:
return False, f"Rate limit exceeded, retry after {redis_client.ttl(key)}s"
return True, current
监控和日志是发现问题的眼睛。记录每次API调用的延迟、token消耗和错误类型,使用Prometheus + Grafana构建监控仪表板。关键指标包括:
- API调用成功率(目标>99.5%)
- P95响应延迟(目标<500ms)
- 每日token消耗量
- 错误类型分布
这些实践确保Gemini 3 Pro API在生产环境中稳定可靠地运行,同时控制成本和风险。
成本分析与优化策略
准确理解Gemini 3 Pro的成本结构,是合理控制预算的前提。根据Google官方定价,对于输入tokens不超过200K的请求,输入成本为$2/百万tokens,输出成本为$12/百万tokens。当输入超过200K tokens时,价格上调至输入$2.5/百万tokens,输出$15/百万tokens。按照当前人民币汇率7.2换算,200K以下场景的实际成本为:
- 输入:约14.4元/百万tokens
- 输出:约86.4元/百万tokens
实际使用中,token消耗量取决于具体场景。一次典型的对话式交互(用户输入50个中文字+AI输出200字)大约消耗150 input tokens和600 output tokens,单次成本仅为0.0005元左右,几乎可以忽略不计。但对于文档分析、长文本摘要等场景,token消耗会显著增加。例如,处理一份10000字的中文文档(约15000 tokens输入)并生成500字摘要(约750 tokens输出),单次成本约为0.09元。
企业级应用的月度成本预估:日均1万次调用(每次平均500 input + 1000 output tokens)= 月消耗1.5亿input + 3亿output tokens ≈ 人民币2800元
以下表格对比不同使用量级的月度成本:
| 使用场景 | 日调用次数 | 平均tokens/次 | 月度成本(人民币) | 适用对象 |
|---|---|---|---|---|
| 个人学习 | 100 | 500 input + 1000 output | ¥9.3 | 开发者、学生 |
| 小型应用 | 1,000 | 500 input + 1000 output | ¥93 | 初创团队 |
| 中型项目 | 10,000 | 500 input + 1000 output | ¥930 | 成长期企业 |
| 大型平台 | 100,000 | 500 input + 1000 output | ¥9,300 | 成熟企业 |
成本优化策略可以从多个维度入手。首先是精简prompt设计,避免在每次请求中携带冗余的上下文信息。使用System Instruction功能将固定的角色设定分离出来,减少重复计费。其次是缓存常见查询,对于FAQ类应用,将高频问题的回答缓存到Redis,命中率每提升10%可节省约10%的API成本。第三是合理设置max_output_tokens,限制输出长度可以有效控制output成本,这部分费用是input的6倍,优化空间更大。
对于成本敏感的项目,可以考虑使用laozhang.ai等API聚合服务。这类平台通常提供透明的按token计费方式,并且有充值优惠活动,例如$100充值获得$110额度,相当于节省约70元人民币。此外还提供3百万token的免费额度,足够完成POC验证阶段的开发测试,避免早期投入过高成本。
另一个优化方向是智能模型选择。对于简单的任务(如分类、实体提取),可以使用Gemini 1.5 Flash,其成本仅为Gemini 3 Pro的1/10。仅在需要复杂推理、多模态分析等高级能力时才调用Gemini 3 Pro,这种混合Gemini策略可以将综合成本降低40-60%。
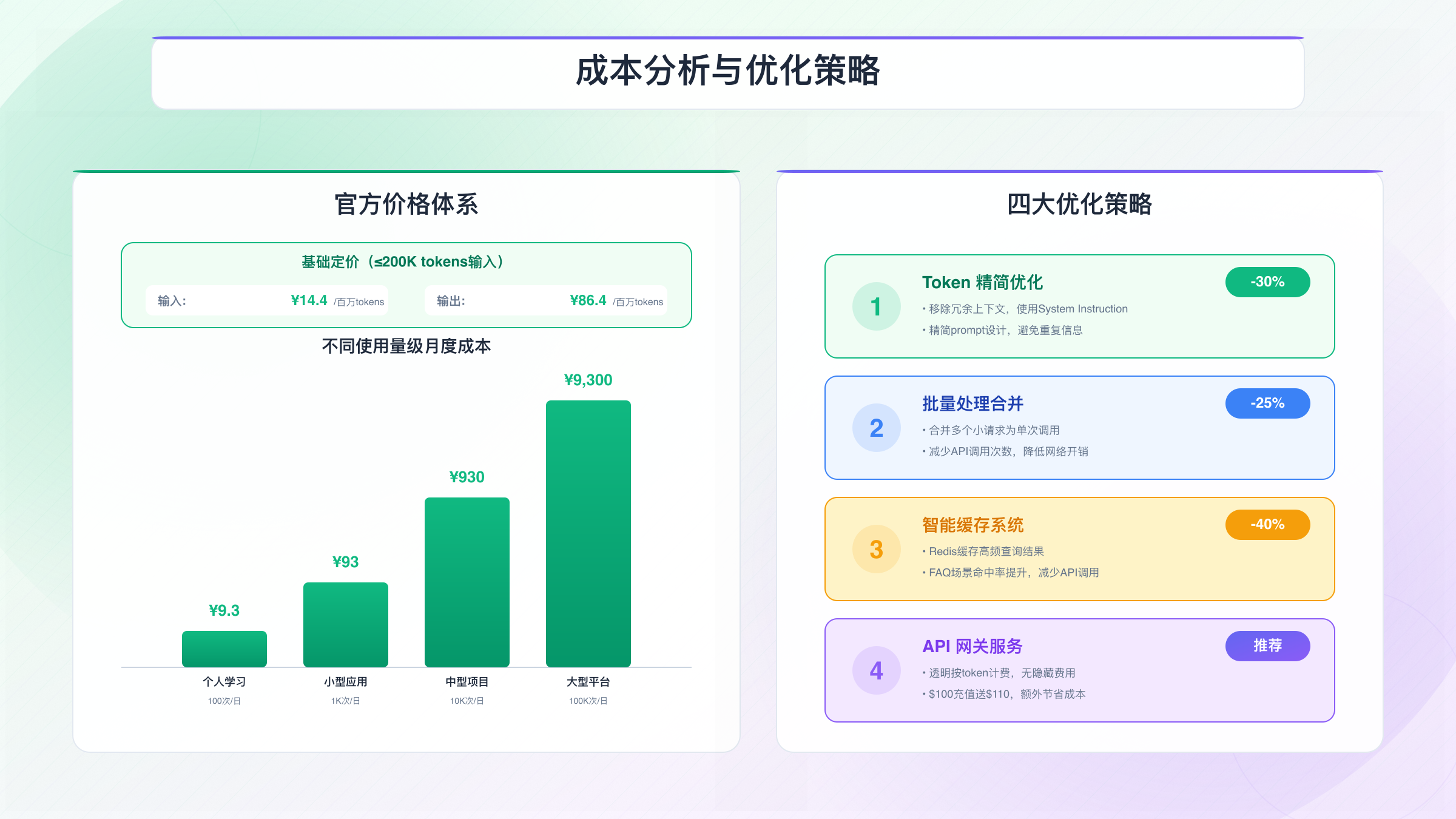
最后是监控和预算告警。通过设置每日/每月token消耗上限,当达到阈值的80%时触发通知,防止意外超支。使用Google Cloud的Budget功能或自建监控系统,实时追踪成本趋势,及时发现异常消耗模式。
常见问题与故障排查
在实际使用Gemini 3 Pro API过程中,开发者经常遇到几类典型错误。认证失败错误(403 Forbidden)通常由API密钥配置不当引起。最常见的原因包括:密钥拼写错误、密钥未激活、或者密钥权限不足。解决方法是登录Google AI Studio重新生成密钥,确保复制时没有遗漏字符,并检查密钥是否已绑定到正确的项目。如果使用环境变量,需要验证变量名是否与代码中的引用一致。
API限流错误(429 Too Many Requests)表示超过了配额限制。免费层级的Gemini 3 Pro限制为每分钟5次请求(RPM)和每分钟25万tokens(TPM)。当遇到429错误时,正确的处理方式是实现指数退避重试:第一次等待1秒,第二次等待2秒,第三次等待4秒,以此类推。生产环境建议升级到付费层级,可获得每分钟1000次请求的更高配额。同时实现客户端限流,在达到90%配额时主动降速,避免触发限制。
超时和网络错误在跨境调用时尤为常见。默认的30秒超时设置在网络条件不佳时可能不够,建议将timeout增加到60秒。对于特别大的请求(如处理长视频),可能需要120秒以上的超时时间。网络间歇性中断可以通过重试机制解决,但需要注意幂等性问题,避免重复处理相同请求导致多次计费。
区域限制问题也值得关注。Google会检测请求来源的IP地址,如果频繁切换IP或使用被识别为VPN的IP,可能触发额外的安全验证。解决方法是使用固定IP的代理服务器,或者选择专业的API网关服务,这些服务通常使用白名单IP,不会被误判。
以下表格汇总了常见错误及其解决方案:
| 错误码 | 错误类型 | 可能原因 | 解决方案 | 预防措施 |
|---|---|---|---|---|
| 403 | 认证失败 | API密钥无效 | 重新生成密钥 | 使用环境变量管理 |
| 429 | 超出限流 | 超过QPM/TPM | 指数退避重试 | 实现客户端限流 |
| 500 | 服务器错误 | Google端问题 | 重试3次后报警 | 实现降级方案 |
| 503 | 服务不可用 | 临时过载 | 等待1分钟重试 | 错峰调用 |
| 408/Timeout | 请求超时 | 网络慢/请求大 | 增加timeout | 优化请求大小 |
排查步骤建议:
- 检查网络连通性:使用curl测试是否能访问generativelanguage.googleapis.com
- 验证API密钥:在Google AI Studio测试密钥是否有效
- 查看详细错误:打印完整的error message和stack trace
- 监控配额使用:在Google Cloud Console查看当前配额消耗
- 测试简化请求:用最小化的prompt测试,排除内容问题
对于持续出现的问题,建议启用详细日志,记录每次请求的时间戳、参数、响应时间和错误信息,这些数据对于定位根因至关重要。
选择建议与决策框架
选择合适的Gemini 3 Pro API访问方案,需要基于实际需求进行综合权衡。个人开发者和学习者通常预算有限,优先考虑成本控制。推荐方案是使用免费层级的官方API,配合Cloudflare Workers中转或轻量级VPN解决网络访问问题。这种组合的月度成本可以控制在0-10元人民币,对于日调用量在100次以下的学习项目完全够用。重点是利用免费的3百万token额度进行充分实验,熟悉API特性后再决定是否升级。
小型团队和初创公司面临的核心挑战是在成本和稳定性之间取得平衡。当日调用量达到1000-10000次级别时,VPN方案的不稳定性会开始显现,建议过渡到自建代理服务器或使用API网关服务。技术实力较强的团队可以选择在AWS或阿里云香港节点部署Nginx代理,月成本约50-150元,获得可控的延迟和稳定性。而希望快速上线、减少技术负担的团队,可以直接使用专业的API网关服务,虽然有一定服务费,但能节省大量开发和运维时间。
企业级应用的决策重点是可靠性、合规性和长期成本。对于日调用量超过10万次的大型Gemini项目,推荐使用Google Cloud Vertex AI,通过专线或云连接实现稳定的跨境访问。虽然初期投入较高(专线成本可能达到数千元/月),但在大规模使用Gemini 3 Pro场景下,稳定性收益远超成本。企业还需要考虑数据合规要求,确保Gemini API调用链路符合等保要求,必要时部署本地化的中转层进行数据脱敏。
决策要点总结:
- 使用频率:<1000次/日用VPN,1000-10000次用代理,>10000次用专线/API网关
- 技术能力:无技术团队选API网关,有技术能力选自建代理
- 预算限制:紧张选免费/低成本方案,宽裕选付费稳定方案
- 业务阶段:POC阶段用免费,MVP阶段用VPN/代理,生产阶段用专线/网关
最终建议:从最低成本方案起步,随着业务增长逐步升级。避免过早投入高成本基础设施,但也要为扩展预留技术架构空间。
对于大多数中国开发者,现实的演进路径是:免费层级测试(0-1个月)→ VPN/Cloudflare方案(1-3个月)→ 代理服务器或API网关(3-12个月)→ 企业级Vertex AI方案(12个月+)。这种渐进式策略能够在每个阶段匹配实际需求,避免资源浪费,同时确保业务连续性。