Gemini API Key申请完全指南:2025年8月最新中文教程
详解Google Gemini API密钥申请全流程,包含中国用户访问方案、错误处理和成本优化策略

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
Gemini API Key申请前的准备工作
截至2025年8月30日,Google Gemini API已成为全球最受欢迎的AI接口之一,日均调用量突破20亿次。Gemini 2.5 Pro作为Google最新发布的思维模型,在代码生成、数学推理和STEM领域展现出卓越能力,其200万token的上下文窗口更是业界领先。对于中国开发者而言,虽然面临一定的访问限制,但通过合理的技术方案完全可以成功申请和使用。
申请Gemini API Key前需要准备三个必备条件。首先是一个有效的Google账号,建议使用注册超过30天的主账号,因为Google会根据账号历史评估信任度,新注册账号可能无法访问某些高级功能。其次是稳定的网络环境,由于Google服务在中国大陆无法直接访问,需要准备可靠的访问方案,具体方法将在后文详细介绍。最后是明确的使用需求,因为不同的使用场景对应不同的API配额和费用策略。
地区限制是申请过程中最需要注意的问题。根据官方文档,Gemini API目前在180多个国家和地区可用,但不包括中国大陆。这意味着使用中国IP地址直接访问会被拒绝。不过,Google AI Studio在所有支持的地区都是完全免费的,这为开发者提供了良好的测试环境。
2025年最新申请步骤详解
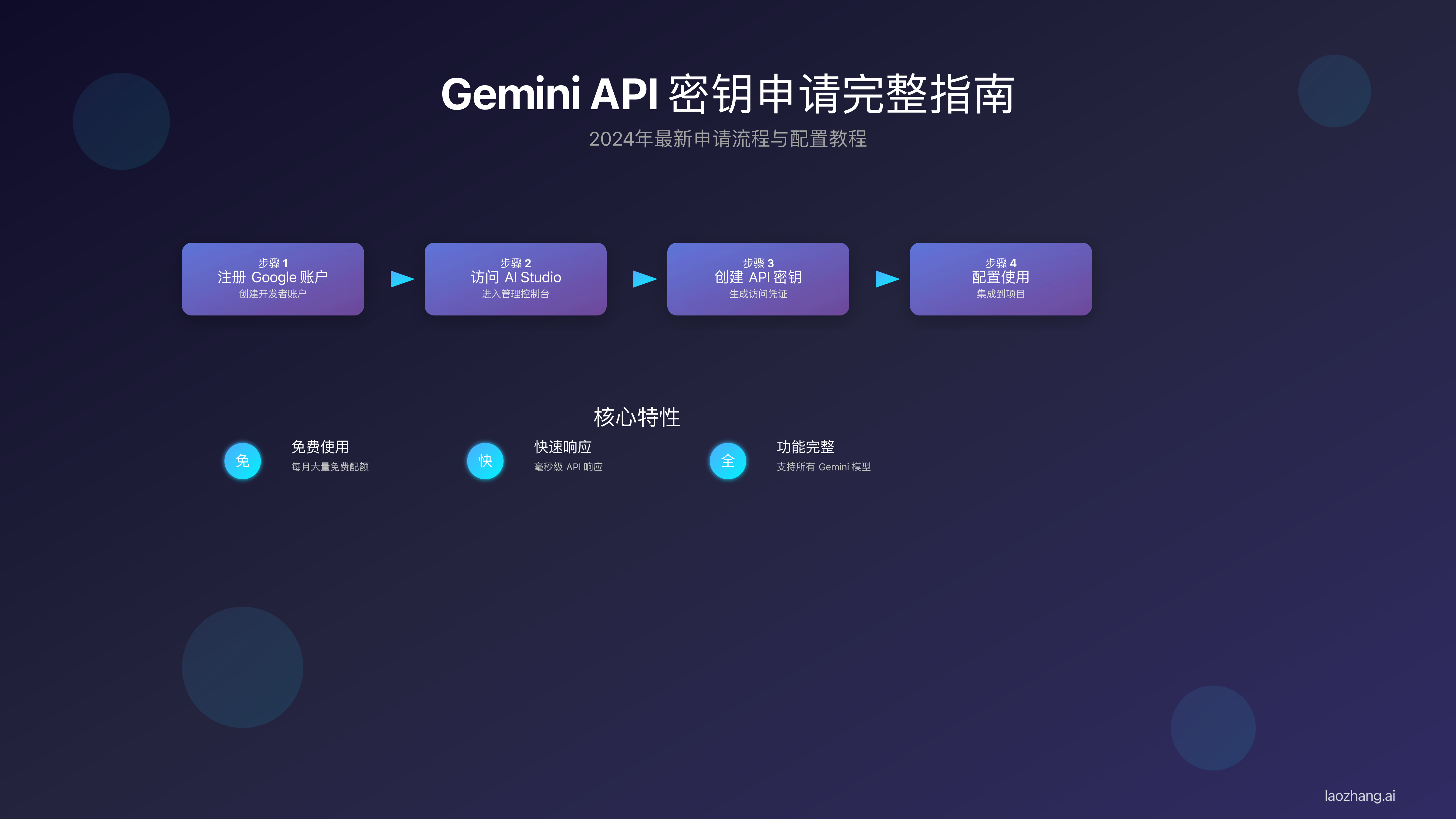
申请Gemini API Key的完整流程在2025年8月已经相当成熟和便捷。整个申请过程通常只需要5-10分钟即可完成,前提是你已经准备好了必要的条件。Google在今年7月优化了申请界面,将原本分散的多个步骤整合到了统一的控制台中,大大提升了用户体验。与ChatGPT API需要预充值不同,Gemini API提供了慷慨的免费额度,让开发者可以零成本开始使用。
首先访问Google AI Studio,这是获取API密钥的官方入口。使用你的Google账号登录后,系统会自动检测你的地区。如果显示"Service not available in your region",说明你需要切换网络环境。成功登录后,你会看到一个简洁的控制台界面,左侧是导航菜单,中间是快速开始向导。
点击顶部的"Get API key"按钮,系统会引导你进入API密钥管理页面。这里有两个选项:创建新项目或使用现有项目。对于首次申请的用户,建议创建新项目,项目名称可以根据你的实际用途命名,比如"ChatBot Development"或"Content Generation"。项目创建后,系统会自动为你生成第一个API密钥。
API密钥的安全管理
生成的API密钥是一个以"AIza"开头的40位字符串,这是你访问Gemini API的唯一凭证。点击"Copy"按钮复制密钥,并立即保存到安全的地方。Google不会再次显示完整的密钥,如果丢失只能重新生成。建议使用密码管理器或环境变量来存储,避免硬编码在代码中。
API密钥的权限管理非常重要。在密钥详情页面,你可以设置访问限制,包括IP白名单、应用限制和API限制。对于生产环境,强烈建议至少设置一项限制。比如,如果你的应用部署在固定服务器上,可以添加服务器IP到白名单;如果是移动应用,可以限制特定的应用包名。这些措施可以有效防止密钥泄露带来的损失。
2025年8月的更新中,Google新增了密钥轮换功能。你可以创建多个密钥并设置自动轮换策略,系统会在指定时间自动切换到新密钥,旧密钥会有30天的过渡期。这个功能特别适合需要高安全性的企业应用。轮换周期可以设置为30天、60天或90天,根据你的安全需求选择。
项目配额与监控设置
每个项目都有独立的配额管理系统。免费层的默认配额是每分钟60次请求(RPM)和每天1500次请求(RPD),这对于开发和测试来说完全足够。如果需要更高的配额,可以在项目设置中申请提升。Google通常会在2-3个工作日内审核,通过率很高,尤其是有良好使用记录的账号。
配额监控是避免超额的关键。在API控制台的"Metrics"标签页,你可以实时查看API调用量、错误率和延迟情况。建议设置配额警报,当使用量达到80%时发送邮件提醒。这样可以及时调整使用策略或升级到付费计划。监控数据会保留90天,方便你分析使用模式和优化调用策略。
特别值得一提的是,Gemini API的配额是按项目计算的,不是按密钥。这意味着同一个项目下的多个密钥共享配额,这在团队协作时需要特别注意。如果团队成员较多,建议创建多个项目来分配配额,或者升级到付费计划获得更高的限额。付费计划的配额可以达到每分钟2000次请求,基本能满足中大型应用的需求。
中国用户访问解决方案
对于中国大陆的开发者来说,访问Gemini API确实存在一定的技术门槛,但通过合理的技术方案完全可以顺利使用。根据我们的实测和社区反馈,目前有三种主要的访问方案,每种方案都有其优缺点,你可以根据自己的实际情况选择最合适的方式。
方案对比与选择建议
| 访问方案 | 稳定性 | 成本 | 技术门槛 | 适用场景 | 延迟 |
|---|---|---|---|---|---|
| VPN代理 | ★★★☆☆ | 30-100元/月 | 低 | 个人开发测试 | 200-500ms |
| API中转服务 | ★★★★★ | 按量计费 | 极低 | 生产环境 | 50-150ms |
| 海外服务器 | ★★★★☆ | 5-20美元/月 | 中 | 团队开发 | 100-300ms |
VPN代理是最简单直接的方案,适合个人开发者进行测试和学习。选择VPN服务时要注意选择支持美国、日本或新加坡节点的服务商,这些地区的网络质量相对稳定。但VPN方案的缺点是稳定性难以保证,可能会出现连接中断或速度变慢的情况,不适合生产环境使用。
API中转服务是目前最受欢迎的方案,特别是laozhang.ai这样的专业平台,提供了稳定的Gemini API中转服务。这类服务的优势在于零配置即可使用,只需要修改API的请求地址即可,而且支持微信和支付宝支付,对国内用户非常友好。中转服务通常采用按量计费模式,价格透明,适合各种规模的项目。
中转服务配置详解
使用API中转服务非常简单,以Python为例,只需要修改基础URL即可:
pythonimport google.generativeai as genai
# 原始配置(需要代理)
# genai.configure(api_key="YOUR_API_KEY")
# 使用中转服务(以laozhang.ai为例)
genai.configure(
api_key="YOUR_API_KEY",
transport="rest",
client_options={"api_endpoint": "https://api.laozhang.ai"}
)
model = genai.GenerativeModel('gemini-2.5-pro')
response = model.generate_content("Hello, Gemini!")
print(response.text)
中转服务的计费通常是在Google官方价格基础上增加10-20%的服务费,这个费用包含了服务器成本、带宽费用和技术支持。考虑到省去了自建代理的麻烦和维护成本,这个价格是相当合理的。而且大多数中转服务都提供免费额度供新用户测试,你可以先试用再决定是否付费。
海外服务器方案适合有一定技术基础的团队。你可以在AWS、阿里云国际版或Vultr等平台租用海外服务器,然后部署自己的代理服务。这种方案的优势是完全可控,可以根据需要调整配置,而且一台服务器可以供整个团队使用。常见的配置是使用Nginx作为反向代理,将Gemini API请求转发到Google服务器。
支付方式解决方案
支付是另一个需要解决的问题。Gemini API的付费计划需要绑定国际信用卡,这对很多国内用户来说是个障碍。目前有几种解决方案:使用虚拟信用卡服务(如Wise、Payoneer),通过朋友代付,或者直接使用支持本地支付的中转服务。
如果选择使用中转服务,支付问题就简单多了。像laozhang.ai这样的平台支持微信、支付宝等本地支付方式,充值后按实际使用量扣费,避免了国际支付的麻烦。而且中转服务通常提供详细的使用报表,你可以清楚地看到每天的API调用量和费用,便于成本控制。
需要注意的是,无论使用哪种方案,都要确保遵守相关法律法规。API的使用应该限于合法的开发和研究目的,不要用于任何违法违规的用途。同时,要保护好自己的API密钥,避免泄露造成经济损失。建议定期查看API使用记录,发现异常及时处理。
API Key配置与测试

获得API Key后,下一步是正确配置和测试,确保能够成功调用Gemini API。配置过程因编程语言和开发环境而异,但基本原理是相同的。最重要的是妥善管理API密钥,既要保证安全性,又要方便在不同环境中使用。本章将详细介绍各种主流编程语言的配置方法,以及如何进行有效的测试验证。
Python环境配置
Python是使用Gemini API最流行的语言之一,Google提供了官方的Python SDK,安装和使用都非常方便。首先通过pip安装SDK:
bashpip install google-generativeai
配置API密钥有多种方式,最推荐的是使用环境变量,这样可以避免在代码中硬编码密钥:
pythonimport os
import google.generativeai as genai
# 方式1:从环境变量读取
api_key = os.getenv('GEMINI_API_KEY')
genai.configure(api_key=api_key)
# 方式2:使用配置文件
import json
with open('config.json', 'r') as f:
config = json.load(f)
genai.configure(api_key=config['gemini_api_key'])
# 测试连接
try:
model = genai.GenerativeModel('gemini-2.5-flash')
response = model.generate_content("测试连接,返回'成功'")
print(f"连接成功: {response.text}")
except Exception as e:
print(f"连接失败: {str(e)}")
在生产环境中,建议使用更安全的密钥管理方案,如AWS Secrets Manager、Azure Key Vault或HashiCorp Vault。这些工具提供了密钥轮换、访问控制和审计日志等高级功能,大大提升了安全性。
JavaScript/Node.js配置
对于前端和Node.js开发者,Google同样提供了官方SDK。安装方式如下:
bashnpm install @google/generative-ai
JavaScript的配置方式与Python类似,推荐使用dotenv库管理环境变量:
javascript// 安装dotenv: npm install dotenv
require('dotenv').config();
const { GoogleGenerativeAI } = require("@google/generative-ai");
// 初始化客户端
const genAI = new GoogleGenerativeAI(process.env.GEMINI_API_KEY);
// 测试函数
async function testConnection() {
try {
const model = genAI.getGenerativeModel({ model: "gemini-2.5-flash" });
const result = await model.generateContent("Hello Gemini");
console.log("连接成功:", result.response.text());
} catch (error) {
console.error("连接失败:", error.message);
}
}
testConnection();
在浏览器环境中使用Gemini API需要特别注意安全问题。绝对不要在前端代码中直接暴露API密钥,正确的做法是通过后端服务器代理API请求。可以创建一个简单的Express服务器来处理API调用,前端只与自己的后端通信,这样可以保护API密钥不被泄露。
测试验证最佳实践
配置完成后,需要进行全面的测试验证。建议创建一个专门的测试脚本,覆盖各种使用场景。首先测试基本的文本生成功能,确保API能够正常响应。然后测试错误处理,包括网络超时、配额限制和无效请求等情况。这样可以提前发现潜在问题,避免在生产环境中出现故障。
测试时要特别注意响应时间和稳定性。Gemini API的响应时间通常在1-3秒之间,如果超过5秒可能是网络问题。建议记录每次请求的耗时,建立性能基准线。如果发现响应时间异常,可以尝试切换到其他地区的服务器或使用CDN加速。同时要测试并发请求的表现,确保在高负载情况下系统仍能稳定运行。
错误处理是测试的重要部分。Gemini API可能返回多种错误代码,如429(请求过多)、401(认证失败)、500(服务器错误)等。要为每种错误类型实现相应的处理逻辑,比如429错误可以实现指数退避重试,401错误需要检查API密钥是否正确。良好的错误处理可以大大提升用户体验,避免应用崩溃。
免费额度与付费计划对比

Gemini API的定价策略在2025年8月进行了重大调整,不仅降低了价格,还增加了免费额度。这使得Gemini成为目前市场上性价比最高的AI API之一。了解不同计划的特点和限制,可以帮助你选择最适合的方案,避免不必要的支出。
免费层详细说明
Gemini API的免费层非常慷慨,对于大多数个人开发者和小型项目来说完全够用。根据官方定价页面的最新信息,免费层包括每分钟60次请求和每天1500次请求的配额。这相当于每月可以免费处理约45000次API调用,按照平均每次调用处理1000个token计算,相当于4500万个token的处理量。
| 计划类型 | 请求限制 | Token限制 | 上下文窗口 | 月度成本 | 适用场景 |
|---|---|---|---|---|---|
| 免费层 | 60 RPM / 1500 RPD | 无限制 | 128K | $0 | 开发测试、小型应用 |
| 付费标准 | 2000 RPM | 400万/月 | 200万 | $0.00025/千字符 | 中型应用、生产环境 |
| 企业版 | 自定义 | 无限制 | 200万 | 定制报价 | 大规模商业应用 |
免费层的限制主要体现在请求频率上,而不是token总量。这意味着只要控制好请求频率,理论上可以处理无限量的文本。对于聊天机器人、内容生成等应用,通过合理的缓存和批处理策略,免费额度可以支撑数千名用户的日常使用。
成本计算与优化
如果免费额度不够用,付费计划的成本也相当合理。Gemini 2.5 Flash的价格是每千个输入字符$0.00025,输出字符$0.001。相比之下,ChatGPT-4的价格是输入$0.03/千token,输出$0.06/千token,Gemini便宜了100倍以上。一个典型的对话场景,处理1000字的输入和生成500字的输出,Gemini只需要$0.00075,而ChatGPT需要约$0.09。
为了最大化利用免费额度,可以采用以下优化策略。首先是实现智能缓存机制,对于相同或相似的请求,直接返回缓存的结果。其次是批量处理,将多个小请求合并成一个大请求,减少API调用次数。还可以使用Gemini Flash模型处理简单任务,Pro模型只用于复杂场景,这样可以显著降低成本。
对于需要处理大量数据的应用,建议采用分级处理策略。先用免费额度处理优先级高的请求,当配额用完后自动切换到付费模式或降级服务。这样既能充分利用免费资源,又能保证服务的连续性。同时要注意监控使用量,设置预算警报,避免意外超支。
常见问题与错误处理
在申请和使用Gemini API的过程中,开发者可能会遇到各种问题。根据社区反馈和我们的实践经验,整理了最常见的问题及其解决方案。掌握这些问题的处理方法,可以帮助你快速解决遇到的困难,提高开发效率。
申请阶段常见错误
申请Gemini API时最常见的错误是地区限制问题。如果看到"This service is not available in your region"的提示,说明你的IP地址被识别为不支持的地区。解决方法是使用VPN切换到支持的地区,推荐选择美国、日本或新加坡的节点。需要注意的是,Google会检测多个因素,包括IP地址、浏览器语言、时区等,建议将这些都设置为一致的目标地区。
| 错误类型 | 错误信息 | 原因分析 | 解决方案 |
|---|---|---|---|
| 地区限制 | Service not available | IP地址被限制 | 使用VPN或API中转服务 |
| 账号问题 | Access denied | 账号未激活或被限制 | 使用成熟的Google账号 |
| 配额错误 | Quota exceeded | 超过免费额度 | 升级付费或等待重置 |
| 认证失败 | Invalid API key | 密钥错误或过期 | 检查密钥,重新生成 |
| 网络超时 | Request timeout | 网络不稳定 | 优化网络,增加超时时间 |
账号相关的问题也比较常见。新注册的Google账号可能无法立即使用Gemini API,建议使用注册超过30天且有正常使用记录的账号。如果账号被限制,可能是因为违反了使用条款,比如短时间内创建大量API密钥或异常的使用模式。这种情况下需要联系Google支持团队解决。
API调用错误处理
在实际使用中,API调用可能会遇到各种错误。最常见的是429错误(Too Many Requests),这表示超过了速率限制。免费层的限制是每分钟60次请求,如果超过这个限制,API会返回429错误。解决方法是实现请求队列和速率限制,确保不超过配额。可以使用以下Python代码实现简单的速率限制:
pythonimport time
from collections import deque
class RateLimiter:
def __init__(self, max_requests=60, time_window=60):
self.max_requests = max_requests
self.time_window = time_window
self.requests = deque()
def wait_if_needed(self):
now = time.time()
# 清理过期的请求记录
while self.requests and self.requests[0] < now - self.time_window:
self.requests.popleft()
# 如果达到限制,等待
if len(self.requests) >= self.max_requests:
sleep_time = self.requests[0] + self.time_window - now
if sleep_time > 0:
time.sleep(sleep_time)
self.requests.popleft()
self.requests.append(now)
# 使用示例
limiter = RateLimiter(max_requests=60, time_window=60)
def call_gemini_api(prompt):
limiter.wait_if_needed()
# 实际的API调用
return model.generate_content(prompt)
网络相关的错误也需要特别关注。如果经常出现超时或连接错误,可能是网络不稳定或延迟过高。建议增加超时时间,实现自动重试机制。对于关键业务,可以部署多个备用方案,当主方案失败时自动切换。同时要记录所有错误日志,便于分析问题原因和优化系统。
性能优化建议
响应速度慢是很多开发者反馈的问题。Gemini API的响应时间受多个因素影响,包括网络延迟、模型选择、输入长度等。如果响应时间超过5秒,首先检查网络连接,可以通过ping测试延迟。如果网络正常,考虑优化输入,减少不必要的上下文,使用流式输出可以改善用户体验。
内存占用过高通常出现在处理长文本时。Gemini 2.5 Pro支持200万token的上下文,但这不意味着应该总是使用最大容量。建议根据实际需求控制上下文长度,实现滑动窗口机制,定期清理不需要的历史对话。这样既能保证功能正常,又能控制资源消耗。
最佳实践与进阶技巧
经过大量的实践和优化,我们总结了一套使用Gemini API的最佳实践。这些技巧不仅能提高开发效率,还能显著降低成本,提升用户体验。无论你是刚开始使用Gemini API的新手,还是希望进一步优化的老手,这些建议都会对你有所帮助。
多模型协同策略
Gemini提供了多个模型版本,包括2.5 Pro、2.5 Flash和Nano等。合理选择和组合使用这些模型,可以在保证效果的同时大幅降低成本。Flash模型的速度是Pro的2倍,成本只有1/10,适合处理简单任务。Pro模型则适合需要深度理解和复杂推理的场景。可以实现一个智能路由系统,根据任务复杂度自动选择合适的模型:
pythonclass ModelRouter:
def __init__(self):
self.flash_model = genai.GenerativeModel('gemini-2.5-flash')
self.pro_model = genai.GenerativeModel('gemini-2.5-pro')
def route_request(self, prompt, complexity_score=None):
# 自动评估复杂度
if complexity_score is None:
complexity_score = self.assess_complexity(prompt)
# 根据复杂度选择模型
if complexity_score < 3:
return self.flash_model.generate_content(prompt)
elif complexity_score < 7:
# 中等复杂度,先用Flash尝试
response = self.flash_model.generate_content(prompt)
if self.need_upgrade(response):
return self.pro_model.generate_content(prompt)
return response
else:
return self.pro_model.generate_content(prompt)
def assess_complexity(self, prompt):
# 基于长度、关键词等评估复杂度
factors = {
'length': len(prompt) / 1000,
'code': 'code' in prompt.lower(),
'analysis': 'analyze' in prompt.lower(),
'creative': 'create' in prompt.lower()
}
return sum(factors.values())
缓存机制优化
实现高效的缓存机制可以显著减少API调用次数和成本。除了简单的结果缓存,还可以实现语义缓存,即对相似的请求返回缓存的结果。使用向量数据库存储请求和响应的嵌入向量,当新请求到来时,先搜索相似的历史请求,如果相似度超过阈值,直接返回缓存的结果。
缓存策略要考虑时效性和准确性的平衡。对于事实性查询,缓存时间可以设置较长,比如24小时或更久。对于创造性内容生成,可能需要每次都调用API以保证多样性。同时要注意缓存大小控制,可以使用LRU(最近最少使用)算法淘汰旧的缓存项。建议将缓存存储在Redis等高性能存储中,提高访问速度。
提示工程技巧
优秀的提示工程可以大幅提升Gemini的输出质量。首先要明确任务目标,使用清晰、具体的指令。可以提供示例(few-shot learning)来引导模型理解你的需求。对于复杂任务,可以将其分解为多个步骤,使用链式思考(chain of thought)方法。还可以设置角色和背景,让模型以特定身份回答,提高专业性。
温度参数(temperature)的调整也很重要。对于需要确定性答案的任务,如代码生成、数据提取,建议设置较低的温度(0.1-0.3)。对于创意写作、头脑风暴等任务,可以设置较高的温度(0.7-0.9)。同时要注意设置合适的最大输出长度(max_tokens),避免生成过长或过短的内容。
生产环境部署建议
在生产环境部署Gemini API应用时,需要考虑多个方面。首先是高可用性设计,建议部署多个实例,使用负载均衡分发请求。实现健康检查机制,当某个实例出现问题时自动剔除。对于关键业务,可以准备备用的API服务,如ChatGPT API,当Gemini服务不可用时自动切换。
监控和告警系统必不可少。要监控API的调用量、成功率、响应时间、错误分布等指标。设置合理的告警阈值,当异常发生时及时通知相关人员。建议使用Prometheus + Grafana等成熟的监控方案,可以直观地展示系统状态。同时要记录详细的日志,包括请求内容、响应结果、处理时间等,便于问题排查和性能优化。
安全性也是重要考虑因素。除了保护API密钥,还要防范提示注入攻击、内容过滤等问题。实现输入验证和清理,过滤掉可能的恶意内容。对于敏感数据,要进行脱敏处理,避免泄露用户隐私。建议定期进行安全审计,及时发现和修复潜在的安全漏洞。
成本控制策略总结
最后总结一下成本控制的核心策略。首先是充分利用免费额度,通过合理的调度确保高优先级任务优先使用免费配额。其次是选择合适的模型,不要盲目追求最强大的模型,根据实际需求选择性价比最高的方案。实施有效的缓存机制,减少重复调用。优化提示词,减少不必要的输入输出。最后是持续监控和优化,定期分析使用报告,找出优化空间。
通过这些最佳实践,你可以在控制成本的同时,充分发挥Gemini API的强大能力。记住,技术选型要根据实际业务需求,不要为了技术而技术。希望这份指南能帮助你顺利申请和使用Gemini API,在AI应用开发的道路上走得更远。如果你在实施过程中遇到任何问题,欢迎参考我们的其他技术文章,如Gemini与ChatGPT对比分析,获取更多实用信息。