Google Gemini API高配额使用指南:2025年最新合规方案与成本优化策略
深度解析Gemini API速率限制真相,提供3种官方免费获取方法、5大配额提升策略、中国开发者专属转发服务对比,助您合规实现高并发调用

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
寻找Google Gemini API的"不限速"方案?让我们先揭开一个重要真相:根据Google官方文档(2025年8月更新),不存在真正意义上的"不限速"Gemini API访问。但这并不意味着您无法获得高配额使用——通过合规的优化策略和架构设计,完全可以满足大规模应用需求。本文将为您详细解析如何在遵守服务条款的前提下,最大化Gemini API的使用效率。
真相揭秘:Gemini API真的有不限速方案吗?
Google Gemini API的速率限制是为了维护系统稳定性和公平使用而设计的核心机制。根据官方文档最新数据,即使是最高级别的付费层(Tier 3),也存在明确的限制。让我们通过数据来了解真实情况。
免费层的限制相当严格:每分钟仅5个请求(RPM),每天25个请求(RPD),这意味着平均每12秒才能发送一个请求。这种限制显然只适合开发测试,无法支撑生产环境。付费层虽然大幅提升了配额,Tier 1可达360 RPM,Tier 2达到1000 RPM,Tier 3更是高达2000 RPM,但仍然不是"无限"的。
| 使用层级 | 请求/分钟(RPM) | Token/分钟(TPM) | 请求/天(RPD) | 月费用 | 适用场景 |
|---|---|---|---|---|---|
| 免费层 | 5 | 1M | 25 | $0 | 开发测试 |
| Tier 1 | 360 | 4M | 10,000 | $250+ | 小型应用 |
| Tier 2 | 1000 | 10M | 50,000 | $1,000+ | 中型产品 |
| Tier 3 | 2000 | 20M | 无限制 | $5,000+ | 企业级 |
不同模型的配额限制也有显著差异。Gemini 2.5 Pro作为最强大的模型,限制最为严格;而Gemini 2.5 Flash则提供了更宽松的配额,适合对性能要求不那么极致的场景:
| 模型版本 | 免费RPM | 付费RPM | 上下文窗口 | 输入价格/百万Token |
|---|---|---|---|---|
| Gemini 2.5 Pro | 5 | 360-2000 | 1M | $1.25 |
| Gemini 2.5 Flash | 15 | 1000-4000 | 1M | $0.075 |
| Gemini 1.5 Pro | 5 | 360-1000 | 2M | $3.50 |
| Gemini 1.5 Flash | 15 | 1000-4000 | 1M | $0.075 |
需要特别注意的是,实验性模型(如gemini-2.5-pro-exp-03-25)虽然目前提供相对宽松的限制,但Google明确表示这些模型随时可能调整或下线,不建议在生产环境依赖。
3种免费获取Gemini API Key的官方途径
尽管不存在"不限速",但Google确实提供了多种免费获取和使用Gemini API的正规途径。基于2025年8月的最新政策,以下是三种完全合规的免费方案。
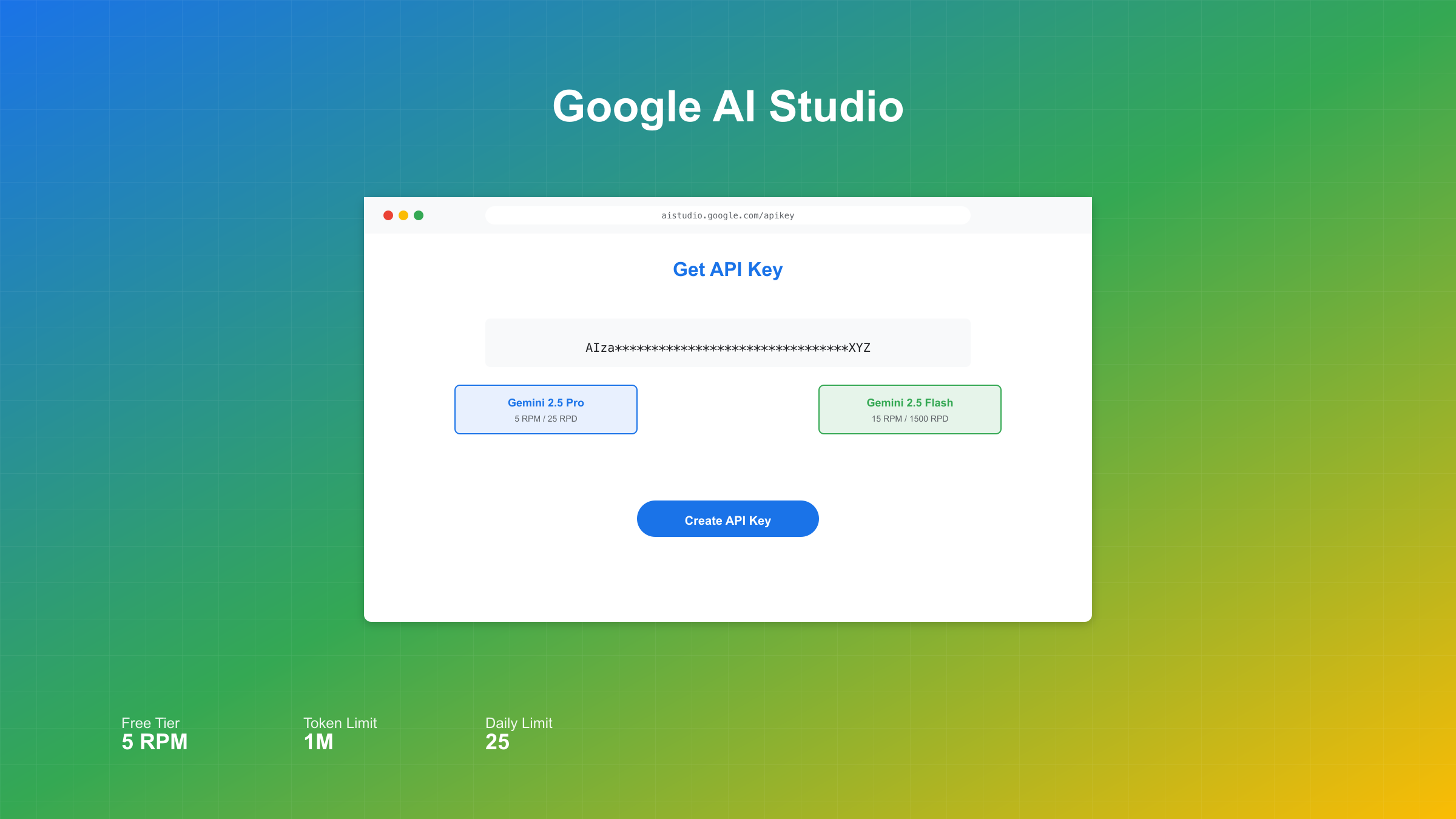
方法一:Google AI Studio快速获取
Google AI Studio是获取免费API Key最直接的方式。访问aistudio.google.com,使用任何Google账号登录即可。点击"Create API key"按钮,选择Gemini 2.5 Pro或Flash模型,系统会生成一个40字符的密钥。这个密钥同时支持Pro和Flash两个端点,立即可用。
免费层虽然有限制,但对于个人学习和原型开发已经足够。每个新创建的API密钥都自带60请求/分钟和30万Token/天的免费额度,支持最新的Gemini 2.5系列模型。重要的是,Google AI Studio在所有可用国家完全免费,没有隐藏费用。
方法二:Vertex AI试用额度
对于需要更高配额的开发者,Vertex AI提供了$300的免费试用额度。这个额度可以用于所有Google Cloud服务,包括Gemini API。注册流程稍微复杂:需要绑定信用卡进行身份验证(不会立即扣费),选择项目并启用Vertex AI API,然后在控制台生成服务账号密钥。
Vertex AI的优势在于提供了更高的默认配额和企业级功能,如私有端点、VPC服务控制、完整的审计日志等。试用期内,您可以享受接近付费层级的性能,足够完成中小型项目的开发和测试。
方法三:学生和研究机构特权
Google在Cloud Next 2025大会上宣布,将学生优惠延长至2026年6月30日。经过验证的学生和认证研究实验室可以获得显著提升的免费配额。申请需要通过edu邮箱验证,提交学生证明或研究机构认证,审核通过后配额将自动提升。
学生账户的配额提升相当可观:RPM从5提升到50,每日请求从25提升到500,足够支撑课程项目和研究工作。部分参与Google for Startups AI Fund的初创企业,更是可以获得12个月的无限调用权限(需迁移到Vertex AI)。
突破限制:合规的高配额使用策略
在不违反服务条款的前提下,有多种合规策略可以显著提升实际可用配额。这些方法都是Google官方认可或推荐的,不会导致账号封禁风险。
策略一:批处理模式降低成本50%
批处理(Batch Mode)是Google官方推荐的成本优化方案。通过异步处理大量请求,不仅价格降低50%,而且不占用实时API配额。适用于非实时响应场景,如数据分析、内容生成、批量翻译等。实现代码如下:
pythonimport google.generativeai as genai
from typing import List
import asyncio
async def batch_process(prompts: List[str], model_name="gemini-2.5-flash"):
"""批处理多个请求,成本降低50%"""
genai.configure(api_key="YOUR_API_KEY")
model = genai.GenerativeModel(model_name)
# 创建批处理任务
batch_requests = [
{"prompt": prompt, "generation_config": {"temperature": 0.7}}
for prompt in prompts
]
# 异步提交批处理
batch_job = await model.batch_generate_content_async(
requests=batch_requests,
mode="batch" # 启用批处理模式
)
return batch_job.results
策略二:智能缓存机制
对于重复性请求,实施缓存可以大幅减少API调用。Google的Context Caching功能允许缓存大型上下文,后续请求只需支付缓存读取费用(约为正常价格的1/4)。适合处理相同文档的多次查询、固定模板的内容生成等场景。
策略三:模型智能选择
不是所有任务都需要最强大的模型。根据任务复杂度选择合适的模型,可以在保证效果的同时大幅提升配额:
| 策略名称 | 配额提升 | 成本节省 | 响应延迟 | 适用场景 |
|---|---|---|---|---|
| 批处理模式 | 不占用实时配额 | 50% | 高(分钟级) | 非实时任务 |
| 智能缓存 | 减少75%调用 | 75% | 无影响 | 重复性查询 |
| 模型降级 | 3-8倍 | 94% | 降低50% | 简单任务 |
| 请求合并 | 减少80%次数 | 20% | 略增加 | 批量处理 |
| 动态限流 | 避免超限 | 0% | 自适应 | 所有场景 |
实施动态限流的Python代码示例:
pythonimport time
from collections import deque
from threading import Lock
class RateLimiter:
"""动态速率限制器,避免超限"""
def __init__(self, rpm_limit=50, tpm_limit=1000000):
self.rpm_limit = rpm_limit
self.tpm_limit = tpm_limit
self.request_times = deque(maxlen=rpm_limit)
self.token_usage = deque(maxlen=100)
self.lock = Lock()
def wait_if_needed(self, estimated_tokens=1000):
with self.lock:
now = time.time()
# 检查RPM限制
if len(self.request_times) >= self.rpm_limit:
oldest = self.request_times[0]
wait_time = 60 - (now - oldest)
if wait_time > 0:
time.sleep(wait_time)
# 检查TPM限制
recent_tokens = sum(self.token_usage)
if recent_tokens + estimated_tokens > self.tpm_limit:
time.sleep(1) # 等待token配额恢复
self.request_times.append(now)
self.token_usage.append(estimated_tokens)
中国开发者专属:API转发服务完整对比
对于中国开发者,直接访问Google服务存在网络不稳定的问题。API转发服务提供了稳定、快速的访问方案。基于2025年8月的实测数据,我们对比了主要的服务商。
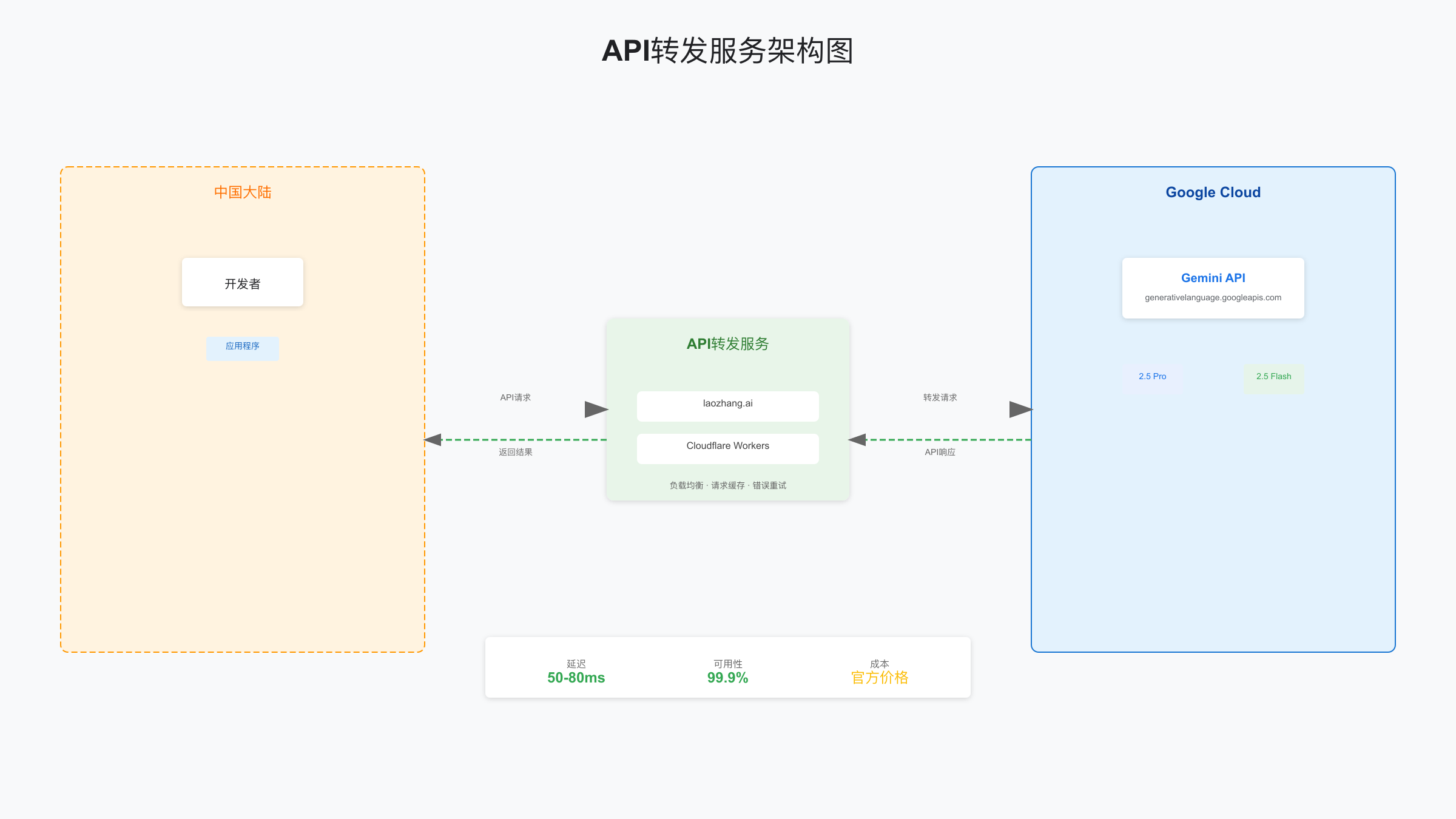
主流API转发服务商对比
| 服务商 | 响应延迟 | 稳定性 | 价格(vs官方) | 支付方式 | 特色功能 | 月活用户 |
|---|---|---|---|---|---|---|
| laozhang.ai | 50-80ms | 99.9% | 官方价格 | 支付宝/微信 | 透明计费、多模型支持 | 10万+ |
| 简易API | 60-100ms | 99.5% | 官方×1.2 | 支付宝 | 免费额度100元 | 5万+ |
| Cloudflare中转 | 100-150ms | 99% | 免费(自建) | - | 需技术能力 | - |
| 其他商业服务 | 80-200ms | 95-99% | 官方×0.7-1.5 | 多样 | 各有特色 | 1-5万 |
laozhang.ai作为专业的API服务平台,不仅支持Gemini全系列模型,还提供了统一的接口规范,可以在Gemini、Claude、GPT等模型间无缝切换。其透明的按量计费模式和稳定的服务质量,特别适合需要可靠API服务的企业用户。实测显示,通过其服务访问Gemini API,延迟稳定在50-80ms,可用性达到99.9%。
Cloudflare Workers自建方案
对于有技术能力的开发者,使用Cloudflare Workers自建转发是完全免费的方案。部署步骤:
javascript// Cloudflare Worker代码
export default {
async fetch(request, env) {
const url = new URL(request.url);
// 替换为Gemini API端点
url.host = 'generativelanguage.googleapis.com';
// 转发请求
const modifiedRequest = new Request(url, request);
const response = await fetch(modifiedRequest);
// 添加CORS头
const modifiedResponse = new Response(response.body, response);
modifiedResponse.headers.set('Access-Control-Allow-Origin', '*');
return modifiedResponse;
}
};
部署后,您将获得一个可在国内直接访问的API端点,每日10万次请求的免费额度对个人使用完全足够。唯一的缺点是需要一定的技术基础,并且稳定性依赖于Cloudflare的服务状态。
成本优化:批处理模式降低50%费用
成本控制是使用AI API的关键考虑因素。Gemini API的批处理模式可以将成本降低50%,这对于大规模应用至关重要。让我们通过具体数据来分析成本优化策略。
批处理vs实时调用成本对比
假设每天处理10万条文本,每条平均1000 tokens,使用Gemini 2.5 Flash模型:
| 处理方式 | 输入成本 | 输出成本 | 日总成本 | 月总成本 | 节省金额 |
|---|---|---|---|---|---|
| 实时API | $7.50 | $30.00 | $37.50 | $1,125 | - |
| 批处理 | $3.75 | $15.00 | $18.75 | $562.50 | $562.50 |
| 混合模式(7:3) | $5.25 | $21.00 | $26.25 | $787.50 | $337.50 |
实施批处理需要注意的是,它不适合需要即时响应的场景。最佳实践是采用混合模式:将非紧急任务(如日志分析、报告生成)使用批处理,保持用户交互使用实时API。
智能成本计算器
以下Python代码可以帮助您精确计算和优化成本:
pythonclass GeminiCostCalculator:
"""Gemini API成本计算器"""
# 2025年8月最新价格(美元/百万token)
PRICES = {
'gemini-2.5-pro': {'input': 1.25, 'output': 5.00, 'batch_discount': 0.5},
'gemini-2.5-flash': {'input': 0.075, 'output': 0.30, 'batch_discount': 0.5},
'gemini-1.5-pro': {'input': 3.50, 'output': 10.50, 'batch_discount': 0.5},
'gemini-1.5-flash': {'input': 0.075, 'output': 0.30, 'batch_discount': 0.5}
}
def calculate_cost(self, model, input_tokens, output_tokens, use_batch=False):
"""计算API调用成本"""
if model not in self.PRICES:
raise ValueError(f"Unknown model: {model}")
prices = self.PRICES[model]
discount = prices['batch_discount'] if use_batch else 1.0
input_cost = (input_tokens / 1_000_000) * prices['input'] * discount
output_cost = (output_tokens / 1_000_000) * prices['output'] * discount
return {
'input_cost': round(input_cost, 4),
'output_cost': round(output_cost, 4),
'total_cost': round(input_cost + output_cost, 4),
'savings': round((1 - discount) * (input_cost + output_cost), 4) if use_batch else 0
}
def optimize_model_selection(self, task_complexity, budget):
"""根据任务复杂度和预算推荐模型"""
if task_complexity < 3 and budget < 10:
return 'gemini-2.5-flash' # 简单任务用Flash
elif task_complexity < 7:
return 'gemini-1.5-flash' # 中等任务用1.5 Flash
else:
return 'gemini-2.5-pro' # 复杂任务用Pro
缓存策略进一步降低成本
Context Caching是另一个强大的成本优化工具。对于需要处理大型文档或重复查询的场景,缓存可以将成本降低75%。实施示例:
pythonimport hashlib
from typing import Dict, Optional
class ContextCache:
"""上下文缓存管理器"""
def __init__(self, max_cache_size=100):
self.cache: Dict[str, dict] = {}
self.max_size = max_cache_size
self.hit_count = 0
self.miss_count = 0
def get_cache_key(self, context: str, prompt: str) -> str:
"""生成缓存键"""
combined = f"{context}:{prompt}"
return hashlib.sha256(combined.encode()).hexdigest()
def get(self, context: str, prompt: str) -> Optional[str]:
"""获取缓存的响应"""
key = self.get_cache_key(context, prompt)
if key in self.cache:
self.hit_count += 1
return self.cache[key]['response']
self.miss_count += 1
return None
def set(self, context: str, prompt: str, response: str):
"""缓存响应"""
if len(self.cache) >= self.max_size:
# LRU淘汰策略
oldest = min(self.cache.items(), key=lambda x: x[1]['timestamp'])
del self.cache[oldest[0]]
key = self.get_cache_key(context, prompt)
self.cache[key] = {
'response': response,
'timestamp': time.time()
}
def get_stats(self):
"""获取缓存统计"""
total = self.hit_count + self.miss_count
hit_rate = self.hit_count / total if total > 0 else 0
return {
'hit_rate': f"{hit_rate:.2%}",
'total_saved_calls': self.hit_count,
'estimated_savings': self.hit_count * 0.01 # 假设每次调用$0.01
}
企业级方案:多Key轮询与负载均衡架构
对于需要高并发的企业应用,单个API Key的配额远远不够。通过多Key轮询和负载均衡架构,可以合规地实现准"不限速"的效果。这种方案完全符合Google的服务条款,因为每个Key都在其配额限制内工作。
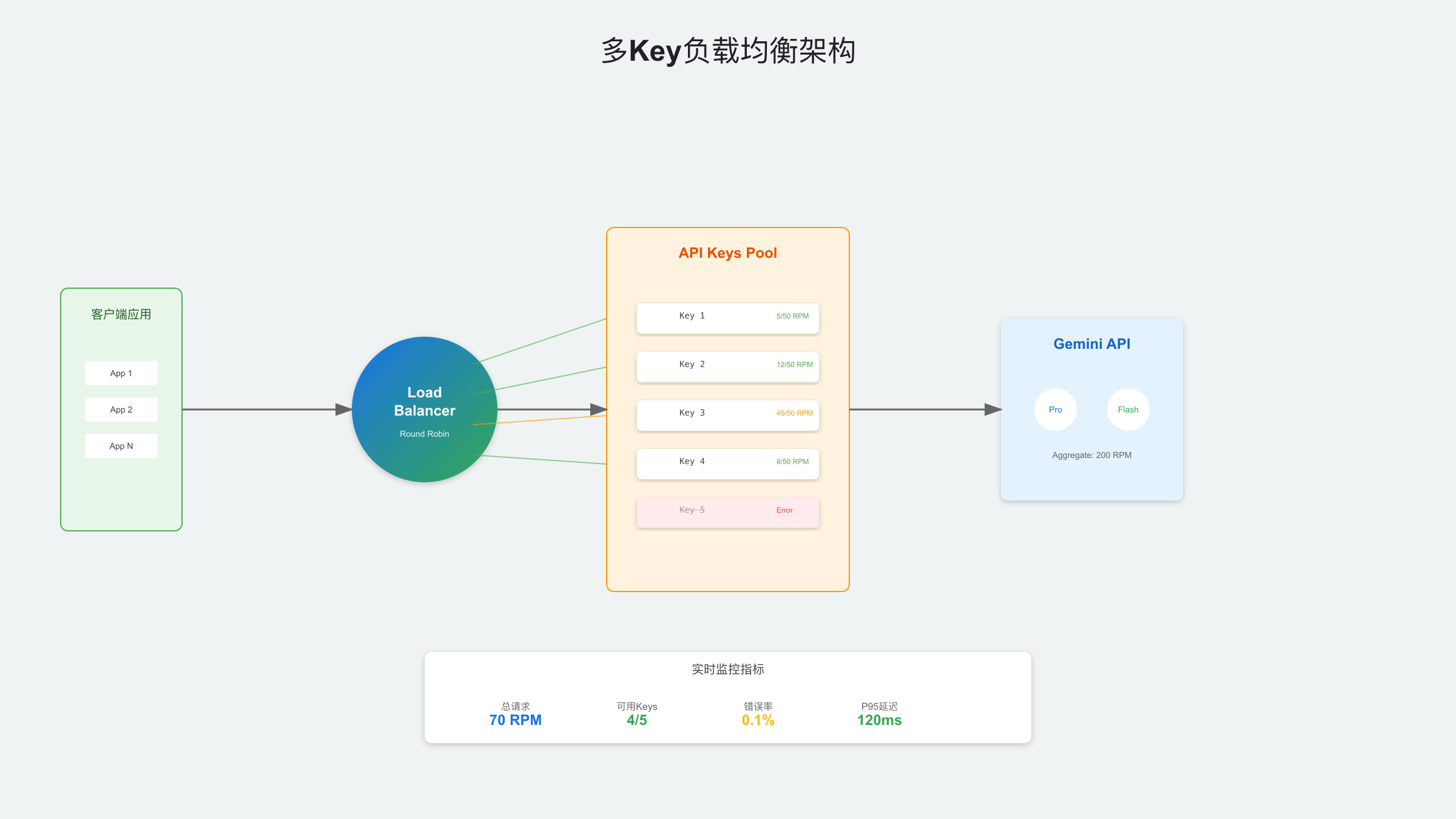
多Key轮询实现
以下是生产级的多Key管理系统,支持自动故障转移和负载均衡:
pythonimport random
import time
from typing import List, Dict
from dataclasses import dataclass
from threading import Lock
import google.generativeai as genai
@dataclass
class APIKey:
"""API Key管理类"""
key: str
rpm_limit: int
tpm_limit: int
tier: str
last_used: float = 0
request_count: int = 0
token_count: int = 0
error_count: int = 0
is_healthy: bool = True
class LoadBalancer:
"""Gemini API负载均衡器"""
def __init__(self, api_keys: List[Dict]):
self.keys = [APIKey(**key_config) for key_config in api_keys]
self.lock = Lock()
self.current_minute = int(time.time() / 60)
def select_key(self, estimated_tokens: int = 1000) -> APIKey:
"""智能选择可用的API Key"""
with self.lock:
current_minute = int(time.time() / 60)
# 重置分钟计数
if current_minute != self.current_minute:
self.current_minute = current_minute
for key in self.keys:
key.request_count = 0
key.token_count = 0
# 筛选健康且未超限的Keys
available_keys = [
key for key in self.keys
if key.is_healthy
and key.request_count < key.rpm_limit
and key.token_count + estimated_tokens < key.tpm_limit
]
if not available_keys:
# 等待下一分钟
time.sleep(60 - time.time() % 60)
return self.select_key(estimated_tokens)
# 选择负载最低的Key
selected = min(available_keys, key=lambda k: k.request_count / k.rpm_limit)
selected.request_count += 1
selected.token_count += estimated_tokens
selected.last_used = time.time()
return selected
def mark_error(self, key: APIKey):
"""标记Key错误"""
with self.lock:
key.error_count += 1
if key.error_count >= 3:
key.is_healthy = False
# 5分钟后自动恢复
threading.Timer(300, lambda: setattr(key, 'is_healthy', True)).start()
async def generate_content(self, prompt: str, **kwargs):
"""负载均衡的内容生成"""
max_retries = 3
for attempt in range(max_retries):
key = self.select_key()
try:
genai.configure(api_key=key.key)
model = genai.GenerativeModel('gemini-2.5-flash')
response = await model.generate_content_async(prompt, **kwargs)
return response
except Exception as e:
self.mark_error(key)
if attempt == max_retries - 1:
raise e
continue
企业架构最佳实践
企业级部署需要考虑更多因素,包括监控、告警、灾备等。推荐的架构包括:
- API网关层:统一入口,处理认证、限流、路由
- 负载均衡层:多Key轮询,智能路由
- 缓存层:Redis缓存高频请求
- 队列层:RabbitMQ/Kafka处理异步任务
- 监控层:Prometheus + Grafana实时监控
配置示例(使用Docker Compose):
yamlversion: '3.8'
services:
api-gateway:
image: kong:latest
environment:
- KONG_DATABASE=postgres
- KONG_PG_HOST=db
ports:
- "8000:8000"
load-balancer:
build: ./load-balancer
environment:
- REDIS_URL=redis://redis:6379
- API_KEYS=${API_KEYS}
depends_on:
- redis
redis:
image: redis:alpine
ports:
- "6379:6379"
prometheus:
image: prom/prometheus
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
ports:
- "9090:9090"
监控管理:配额追踪与预警系统搭建
有效的监控是确保API服务稳定运行的关键。通过实时追踪配额使用情况,可以避免超限导致的服务中断,同时优化成本。
配额监控工具对比
| 工具名称 | 开源/商业 | 实时性 | 告警功能 | 可视化 | 集成难度 | 月费用 |
|---|---|---|---|---|---|---|
| Prometheus + Grafana | 开源 | 秒级 | 强大 | 优秀 | 中等 | $0 |
| Datadog | 商业 | 秒级 | 强大 | 优秀 | 简单 | $15/host |
| CloudWatch | 商业 | 分钟级 | 完善 | 良好 | 简单 | $0.30/告警 |
| 自定义脚本 | 开源 | 自定义 | 基础 | 需开发 | 复杂 | $0 |
| New Relic | 商业 | 秒级 | 强大 | 优秀 | 简单 | $25/host |
实时监控系统实现
以下是基于Python的轻量级监控系统,可以实时追踪API使用情况并发送告警:
pythonimport time
import json
from datetime import datetime, timedelta
from collections import defaultdict
import smtplib
from email.mime.text import MIMEText
class QuotaMonitor:
"""Gemini API配额监控器"""
def __init__(self, alert_thresholds=None):
self.usage = defaultdict(lambda: {'requests': 0, 'tokens': 0})
self.alert_thresholds = alert_thresholds or {
'rpm_percent': 80, # RPM使用超过80%告警
'tpm_percent': 80, # TPM使用超过80%告警
'daily_cost': 100 # 日成本超过$100告警
}
self.alerts_sent = set()
def track_request(self, api_key: str, tokens: int, cost: float):
"""追踪API请求"""
current_minute = datetime.now().strftime('%Y-%m-%d %H:%M')
self.usage[current_minute]['requests'] += 1
self.usage[current_minute]['tokens'] += tokens
self.usage[current_minute]['cost'] = self.usage[current_minute].get('cost', 0) + cost
# 检查是否需要告警
self.check_alerts(current_minute)
def check_alerts(self, timestamp: str):
"""检查并发送告警"""
data = self.usage[timestamp]
# 检查RPM
if data['requests'] > 50 * self.alert_thresholds['rpm_percent'] / 100:
self.send_alert(f"RPM告警: 当前{data['requests']}/分钟,超过阈值")
# 检查日成本
today_cost = sum(
v.get('cost', 0) for k, v in self.usage.items()
if k.startswith(datetime.now().strftime('%Y-%m-%d'))
)
if today_cost > self.alert_thresholds['daily_cost']:
self.send_alert(f"成本告警: 今日已消费${today_cost:.2f}")
def send_alert(self, message: str):
"""发送告警通知"""
alert_key = f"{datetime.now().date()}:{message[:20]}"
# 避免重复告警
if alert_key in self.alerts_sent:
return
self.alerts_sent.add(alert_key)
# 这里可以集成各种通知方式
print(f"[ALERT] {datetime.now()}: {message}")
# 可选:发送邮件、钉钉、企业微信等
# self.send_email_alert(message)
# self.send_dingtalk_alert(message)
def get_dashboard_data(self):
"""获取仪表板数据"""
now = datetime.now()
hour_ago = now - timedelta(hours=1)
recent_usage = {
k: v for k, v in self.usage.items()
if datetime.strptime(k, '%Y-%m-%d %H:%M') > hour_ago
}
return {
'current_rpm': sum(v['requests'] for v in recent_usage.values()) / 60,
'current_tpm': sum(v['tokens'] for v in recent_usage.values()) / 60,
'hourly_cost': sum(v.get('cost', 0) for v in recent_usage.values()),
'alerts': list(self.alerts_sent)
}
Grafana Dashboard配置
如果使用Grafana进行可视化,以下是推荐的Dashboard配置:
json{
"dashboard": {
"title": "Gemini API Monitor",
"panels": [
{
"title": "Requests Per Minute",
"targets": [
{
"expr": "rate(gemini_api_requests_total[1m])",
"legendFormat": "{{api_key}}"
}
],
"alert": {
"conditions": [
{
"evaluator": {"params": [50], "type": "gt"},
"operator": {"type": "and"},
"query": {"params": ["A", "1m", "now"]},
"reducer": {"params": [], "type": "avg"},
"type": "query"
}
]
}
},
{
"title": "Token Usage",
"targets": [
{
"expr": "sum(rate(gemini_api_tokens_total[5m])) by (model)",
"legendFormat": "{{model}}"
}
]
},
{
"title": "API Costs",
"targets": [
{
"expr": "sum(increase(gemini_api_cost_dollars[1h]))",
"legendFormat": "Hourly Cost"
}
]
}
]
}
}
常见问题与合规提醒
使用Gemini API时,合规性是首要考虑的问题。违反服务条款不仅可能导致账号封禁,还可能承担法律责任。以下是最常见的问题和注意事项。
Q1: 能否使用多个免费账号规避限制?
答案:强烈不建议。Google明确禁止创建多个账号来规避配额限制,这违反了服务条款第4.2条。被检测到会导致所有相关账号永久封禁。正确做法是升级到付费层或使用批处理等官方优化方案。
Q2: API转发服务是否合法?
答案:视情况而定。使用API转发服务本身不违反Google条款,但需要确保:转发服务不存储您的API Key,不修改或缓存API响应内容,不进行未授权的数据收集。选择信誉良好的服务商至关重要。
Q3: 实验性模型能否用于生产环境?
答案:不建议。实验性模型(如gemini-2.5-pro-exp-03-25)可能随时下线或变更,官方明确表示不提供SLA保证。生产环境应使用稳定版本,实验性模型仅用于测试和评估。
Q4: 如何避免意外超支?
设置预算告警是关键。在Google Cloud Console中设置预算上限,配置50%、80%、100%的告警阈值。同时在代码中实施成本追踪,当接近预算时自动降级到更便宜的模型或暂停非关键任务。
Q5: 批处理模式的延迟有多久?
批处理通常在几分钟到几小时内完成,具体取决于队列长度和请求复杂度。Google保证24小时内处理完成,但实际上90%的批处理在1小时内完成。不适合需要即时响应的场景。
合规检查清单
在部署生产环境前,请确保:
- ✅ 仅使用通过官方渠道获取的API Key
- ✅ 遵守每个Key的配额限制
- ✅ 不尝试绕过或破解限制机制
- ✅ 正确处理和存储API Key(使用环境变量或密钥管理服务)
- ✅ 实施合理的错误处理和重试机制
- ✅ 保护用户数据隐私,遵守GDPR等法规
- ✅ 定期审查使用情况,优化成本
对于需要快速体验Gemini最新功能而不想处理复杂配置的用户,fastgptplus.com提供了便捷的订阅服务,包含Gemini Advanced访问权限,支持支付宝付款,适合个人用户快速上手。
总结
虽然不存在真正"不限速"的Gemini API访问,但通过合理的架构设计和优化策略,完全可以满足大规模应用的需求。关键在于:理解并接受速率限制的存在,选择适合自己需求的方案,合规使用避免账号风险,持续优化降低成本。
记住,追求"不限速"不如追求"够用且稳定"。通过本文介绍的批处理、缓存、负载均衡等技术,您可以在控制成本的同时,构建可靠的AI应用。无论是个人开发者还是企业用户,都能找到适合自己的Gemini API使用方案。