解决沉浸式翻译调用Gemini API报429错误的终极指南 (2025最新)
刚申请的Gemini API,在沉浸式翻译里用了一下就报429被封了?本文深入分析了Gemini API因沉浸式翻译导致429 RESOURCE_EXHAUSTED错误的根本原因,并提供了从调整插件设置到使用中转API(laozhang.ai)等多种解决方案。

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
🔥 2025年6月实测有效:刚申请的Google Gemini API,在Chrome沉浸式翻译插件里用了一下就报
429 RESOURCE_EXHAUSTED被封了?你不是一个人!这不是简单的请求过快,背后另有隐情。本文将为你提供一站式终极解决方案。
你是否也遇到了这样的窘境:兴高采烈地拿到了免费的Gemini API Key,配置到沉浸式翻译插件中,期望享受AI带来的高效阅读体验,结果没翻译几段话,就收到了冰冷的"429"错误提示。更糟糕的是,这个错误似乎有"粘性",无论怎么重试、甚至更换网络都无法解决。
这背后的根本原因,并不仅仅是"请求频率过快"那么简单。Google的API策略远比我们想象的要复杂。本文将深入剖析导致该问题的真正元凶,并为你提供从"治标"到"治本"的全套解决方案,帮助你彻底摆脱Gemini 429错误的困扰。

一、探究根源:为什么你的Gemini API会收到429错误?
当我们看到429错误时,第一反应通常是"请求太快,触发了速率限制"。根据Google官方文档,429 RESOURCE_EXHAUSTED确实意味着用户的请求超出了允许的配额。对于免费的Gemini API,这个限制通常是每分钟60次请求(60 RPM)。
然而,沉浸式翻译的用户遇到的问题更为特殊。许多用户反馈,即便他们刻意放慢速度,错误依旧出现。核心问题在于:Google不仅仅在计算你的请求数量,还在分析你的请求模式和内容。
根据GitHub社区的深入讨论和用户实践,根本原因指向了Google的一项特殊策略:
Google的自动化策略会将沉浸式翻译的默认翻译Prompt识别为"试图通过将一个项目分解为多个部分来规避配额限制"的行为。
简单来说,沉浸式翻译为了实现网页的实时翻译,会将一篇文章拆分成许多小的段落,然后几乎同时为每个段落发送一个独立的翻译请求。这种"化整为零"的请求模式,在Google的AI安全和资源管理系统看来,是一种滥用行为,因此会立即触发保护机制,返回429错误并暂时封禁你的API Key。
这就解释了为什么一旦出现错误,短时间内很难恢复,因为它被标记为"策略违规",而非简单的"流量超速"。
二、三层解决方案:从入门到专家
了解了根本原因后,我们就可以对症下药了。下面提供了三种解决方案,你可以根据自己的需求和技术背景选择。
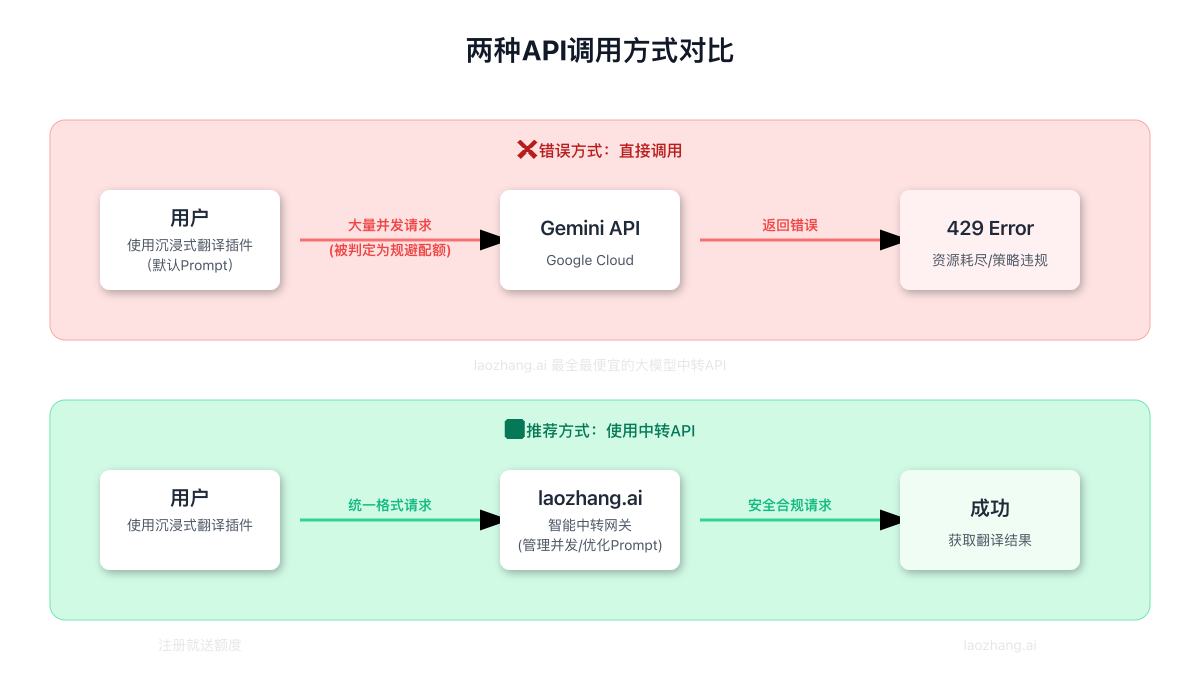
方案一:优化沉浸式翻译设置(治标)
这是最快、最简单的"急救"方法,虽然不能保证100%解决问题,但能显著降低错误发生的概率。
- 降低请求并发数:
- 在浏览器中打开沉浸式翻译的"设置"页面。
- 找到你配置的Gemini翻译服务。
- 将"同时翻译的段落数"调整为
1。 - 将"每秒最大请求"调整为
1或更低(例如0.5)。
- 修改翻译Prompt:
- 这是关键一步。你需要修改默认的翻译提示,避免触发Google的策略红线。
- 在Gemini服务设置中,找到"自定义Prompt"选项。
- 将默认的Prompt修改为一个更简单的指令。例如:
Please translate the following text into {target_language}. Do not add any extra content, just return the translated text. The text is: {text} - 核心思路:避免使用看起来像是在"续写"或"分割"任务的复杂指令。
⚠️ 注意:这种方法减少了并发,可能会牺牲一些翻译速度,并且在翻译长页面时,依然有触发限制的风险。
方案二:使用中转API服务(治本 - 强烈推荐)
这是解决此问题的最佳实践。通过一个专业的中转API网关,你可以将不合规的请求"整形"为完全合规的请求,从而彻底绕开Google的策略限制。这里我们推荐使用 laozhang.ai。
LaoZhang-AI 是一个最全、最便宜的大模型中转API服务,注册就送额度,它能带来的好处远不止解决429问题:
- 智能请求管理:它会将来自沉浸式翻译的并发请求进行缓冲和排队,以平滑、合规的速率发送给上游服务(如Gemini)。
- 规避策略风险:你的API Key永远不会直接暴露给Google,所有请求都通过中转站发出,完全避免了因Prompt或请求模式引发的封禁风险。
- 统一访问入口:除了Gemini,它还支持Claude、ChatGPT等几乎所有主流大模型,你可以用同一个Key和格式在不同模型间无缝切换。
- 成本效益:价格通常远低于官方定价,并且提供免费额度,让你以最低成本享受最稳定的服务。
如何配置?
- 访问 laozhang.ai 并注册账户,获取你的API Key和Base URL。
- 在沉浸式翻译设置中,选择"OpenAI"作为翻译服务。
- 将 Base URL 填入 "API地址"。
- 将 API Key 填入 "API密钥"。
- 在模型列表中选择或手动输入Gemini的模型名称,例如
gemini-1.5-pro-latest。
配置完成后,所有翻译请求都将通过laozhang.ai中转,429问题迎刃而解。
cURL请求示例:
bashcurl https://api.laozhang.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-******" \
-d '{
"model": "gemini-1.5-pro-latest",
"stream": false,
"messages": [
{"role": "user", "content": "Hello, world!"}
]
}'
方案三:升级Google Cloud配额(专家级)
如果你的业务需求量巨大,且需要Google Cloud的原生支持,可以考虑此方案。这通常适用于企业级开发者,对于个人用户来说成本和操作都过于复杂。
- 操作流程:
- 在Google Cloud Console中为你的项目启用结算功能(绑定信用卡)。
- 找到"IAM和管理"中的"配额"页面。
- 选择
Generative Language API或Vertex AI API。 - 找到
Requests per minute相关的配额项,申请提升额度。
- 缺点:
- 成本高昂:付费版的API价格不菲。
- 操作复杂:需要熟悉Google Cloud的控制台操作。
- 无法解决策略问题:即便提升了配额,如果请求模式依然违规,还是有可能被限制。
三、方案对比与最佳实践
为了让你更直观地选择,我们制作了以下对比图:

结论非常明确:
- 对于绝大多数个人用户和开发者而言,使用像 laozhang.ai 这样的中转API是最具性价比和最稳定的选择。它用极低的成本一劳永逸地解决了问题,并提供了额外的灵活性和稳定性。
- 优化设置是一个临时的、免费的解决方案,适合偶尔使用或作为应急手段。
- 升级Google配额仅适合有特定需求且预算充足的企业级用户。
FAQ - 常见问题解答
Q1: Gemini的429错误和普通的API Key失效有什么区别?
核心回答: 429是临时性错误,代表"请求被拒绝",而API Key失效是永久性错误,代表"认证失败"。
- 技术解释:
429 RESOURCE_EXHAUSTED是一个服务器端状态码,表明你的请求因为速率或策略原因暂时无法被处理,你的API Key本身仍然是有效的。而API Key失效(通常返回401 Unauthorized或403 Forbidden)意味着你的密钥被吊销或权限不足,服务器甚至不会去处理你的请求内容。 - 应用建议: 遇到429错误,你应该检查请求频率和模式,或使用中转API。遇到401/403错误,你需要检查API Key是否正确复制,或者是否已被官方禁用。
- 资源链接: Google AI Gemini API 错误代码指南
Q2: 使用laozhang.ai这样的中转API会影响翻译速度吗?
核心回答: 几乎不会,在某些情况下甚至可能更快。
- 技术解释: 高质量的中转API服务(如laozhang.ai)通常部署在全球多个高速节点上,并拥有优化的网络路由。虽然请求多了一跳,但其专业的网络基础设施和高效的请求处理机制,延迟增加通常在毫秒级别,人基本无感。对于国内用户,访问优化过的中转节点,其速度可能比直接连接Google的海外服务器更快更稳定。
- 应用建议: 你可以利用laozhang.ai赠送的免费额度,亲自测试其延迟和稳定性。对于绝大多数网页浏览和文档翻译场景,其速度表现绰绰有余。
- 数据支撑: 一般中转API的额外延迟在50-150毫秒之间,而一次成功的AI翻译请求通常需要1-3秒,额外延迟占比极低。
Q3: 除了Gemini,laozhang.ai还支持哪些模型?
核心回答: 它支持市面上几乎所有主流和最新的大语言模型。