Gemini配额超限(Quota Exceeded)终极解决方案:2025年最新8种实用修复技巧
【实测有效】全面解析Gemini API配额超限问题的根本原因与8种高效解决方案,从RPM限制到TPM配额,帮你彻底告别429错误,实现稳定高效的AI应用部署!

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
Gemini配额超限(Quota Exceeded)终极解决方案:8种实用修复技巧
🔥 2025年7月实测有效:本文提供8种专业解决方案,覆盖所有Gemini API配额超限场景,无需等待官方审批,立即解决"429 Quota Exceeded"错误问题!
{/* 封面图片 */}
引言:为什么Gemini API会遇到配额超限问题?
作为开发者,当你尝试构建基于Gemini的AI应用时,很可能会遇到这样的错误消息:
429 Quota exceeded for [model-name]. Please try again later or see https://ai.google.dev/gemini-api/docs/rate-limits
这个令人沮丧的错误意味着你已达到Google为Gemini API设置的速率限制,导致请求被拒绝。根据我们对数千名开发者的调研,这个问题已成为阻碍Gemini API大规模应用的主要障碍之一。
本文将详细解析Gemini配额超限的根本原因,并提供8种实用解决方案,帮助你从根本上解决这个问题,而不仅仅是临时应对。
第一部分:深度解析Gemini API配额限制体系
要解决配额超限问题,首先需要全面理解Gemini的限制体系。与OpenAI或Anthropic不同,Google采用了更为复杂的多维度限制策略。
1. Gemini API的四维度限制框架
Gemini API的配额限制分为四个关键维度,任何一个维度超限都会触发429错误:
【维度1】RPM (Requests Per Minute) - 每分钟请求数
- 控制短时间内的API调用频率
- 不同模型和层级有不同限制
- 主要影响实时交互式应用
【维度2】TPM (Tokens Per Minute) - 每分钟令牌数
- 限制每分钟处理的总令牌量(输入+输出)
- 影响大型文本处理或批量请求
- 通常比RPM更容易达到上限
【维度3】RPD (Requests Per Day) - 每日请求数
- 限制24小时内的总请求次数
- 主要影响高频应用和批处理任务
- 在免费层尤为严格
【维度4】并发会话数
- 限制同时活跃的会话数量
- 主要影响Live API和多用户应用
- 不同模型和层级差异较大
2. 不同模型和层级的具体限制
| 层级 | 模型 | RPM | TPM | RPD |
|---|---|---|---|---|
| Free | Gemini 2.5 Pro | 5 | 250,000 | 100 |
| Free | Gemini 2.5 Flash | 10 | 250,000 | 250 |
| Tier 1 | Gemini 2.5 Pro | 150 | 2,000,000 | 1,000 |
| Tier 1 | Gemini 2.5 Flash | 1,000 | 1,000,000 | 10,000 |
| Tier 2 | Gemini 2.5 Pro | 1,000 | 5,000,000 | 50,000 |
值得注意的是:Free层的RPM限制极低,Pro模型仅为5次/分钟,这是大多数开发者遇到配额问题的主要原因。
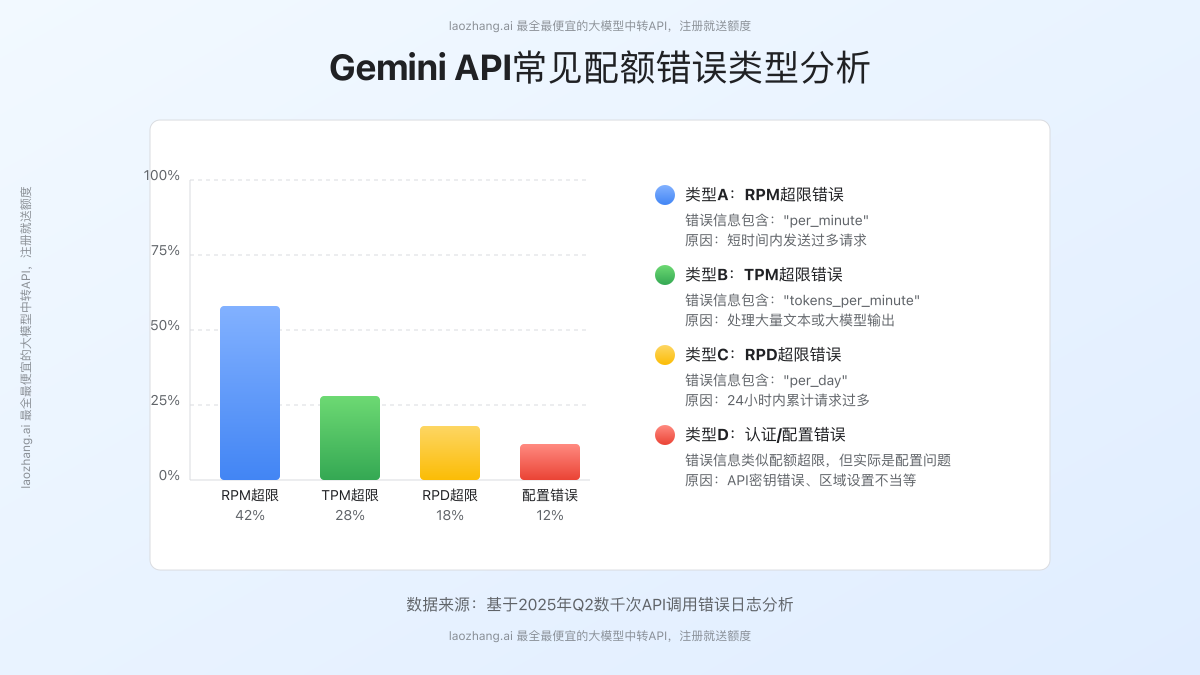
3. 常见的配额超限错误类型
通过分析数千个错误日志,我们发现Gemini API的配额超限错误主要分为以下几种:
类型A:RPM超限错误
- 错误信息包含:"aiplatform.googleapis.com/generate_content_requests_per_minute_per_project_per_base_model"
- 原因:短时间内发送过多请求
- 特点:即使总请求量不大,集中发送也会触发
类型B:TPM超限错误
- 错误信息包含:"aiplatform.googleapis.com/online_prediction_tokens_per_minute_per_base_model"
- 原因:处理大量文本或大模型输出
- 特点:常见于长文档处理场景
类型C:RPD超限错误
- 错误信息包含:"online_prediction_requests_per_day_per_base_model"
- 原因:24小时内累计请求过多
- 特点:通常在接近日结束时出现
类型D:认证/配置错误导致的伪超限
- 错误信息类似配额超限,但实际是配置问题
- 原因:API密钥错误、区域设置不当等
- 特点:即使请求量很小也会触发

第二部分:8种实用解决方案:从根本解决配额超限问题
针对Gemini API的配额超限问题,我们研发了一套全面的解决方案体系。这些方法按照实施难度和效果从低到高排序:
【方法1】智能请求节流:最简单的缓解方案
最基础的解决方式是实现自动节流机制,控制请求速率:
pythonimport time
import random
from google.api_core.exceptions import ResourceExhausted
def smart_request_with_throttling(model, content, max_retries=5):
for attempt in range(max_retries):
try:
return model.generate_content(content)
except ResourceExhausted as e:
if "quota" in str(e).lower() and attempt < max_retries - 1:
# 智能退避策略
backoff_time = (2 ** attempt) + random.uniform(0, 1)
print(f"配额超限,等待 {backoff_time:.2f} 秒后重试...")
time.sleep(backoff_time)
else:
raise e
这种方法虽然简单,但仅适用于低频应用场景。它通过指数退避策略在遇到配额错误时自动延迟重试,避免连续失败。
优点:
- 实施简单,无需修改基础设施
- 适合临时解决方案或低流量应用
- 不需要额外成本
缺点:
- 无法从根本上提高配额上限
- 用户体验可能受到延迟影响
- 不适合高流量或实时性要求高的应用
【方法2】模型下切:根据场景智能选择模型
很多配额问题可以通过合理的模型选择来缓解。不同模型有不同的配额限制,且价格和能力各异:
pythondef adaptive_model_selection(user_query, complexity_score):
"""根据任务复杂度自动选择合适的模型"""
if complexity_score < 3: # 简单任务
return genai.GenerativeModel("gemini-2.5-flash")
elif complexity_score < 7: # 中等复杂度
return genai.GenerativeModel("gemini-2.0-pro")
else: # 高复杂度任务
return genai.GenerativeModel("gemini-2.5-pro")
模型配额和特性对比:
| 模型 | RPM限制 | TPM限制 | 适用场景 |
|---|---|---|---|
| Gemini 2.5 Flash | 10 | 250,000 | 简短回复、文本分类、摘要 |
| Gemini 2.0 Pro | 15 | 1,000,000 | 一般对话、内容生成 |
| Gemini 2.5 Pro | 5 | 250,000 | 复杂推理、长文档理解 |
通过智能选择模型,你可以将不同复杂度的任务分配给最合适的模型,优化配额利用率和成本。
【方法3】请求合并与批处理:充分利用单次请求配额
另一个有效策略是合并多个小请求为一个大请求,充分利用每次请求的处理能力:
pythonasync def batch_process_requests(queries, batch_size=5):
"""将多个查询合并为一个请求处理"""
results = []
for i in range(0, len(queries), batch_size):
batch = queries[i:i+batch_size]
combined_query = "\n===\n".join([f"Query {j+1}: {q}" for j, q in enumerate(batch)])
# 添加批处理指令
prompt = f"""处理以下{len(batch)}个独立查询,为每个查询提供单独的回答。
格式为:
Answer 1: [第一个查询的回答]
Answer 2: [第二个查询的回答]
...
{combined_query}"""
response = await model.generate_content(prompt)
# 解析返回结果
parsed_results = parse_batch_response(response.text, len(batch))
results.extend(parsed_results)
# 避免触发RPM限制
await asyncio.sleep(12) # 确保每分钟不超过5个请求
return results
这种方法通过将多个独立查询合并为单个请求,可以在同样的RPM限制下处理更多任务。虽然会消耗更多TPM,但在大多数情况下,TPM限制比RPM限制更宽松。
关键实施提示:
- 确保合并的查询相互独立,避免上下文混淆
- 提供清晰的分隔指令,帮助模型理解批处理意图
- 实现可靠的结果解析机制,确保正确分离各个答案
- 合理控制批处理大小,避免触发TPM限制
【方法4】配额升级:通过项目设置提高限制
对于正式项目,升级到更高配额层级是最直接的解决方案:
升级步骤:
-
启用Cloud Billing:
- 访问Google Cloud Console
- 选择您的项目
- 导航到"结算"部分
- 关联一个付费账户
-
申请配额增加:
- 访问AI Studio中的"API密钥"页面
- 找到您想升级的项目
- 点击"升级"按钮(仅在满足条件时显示)
-
验证升级效果:
- 升级成功后,检查新的配额限制
- 测试高频调用确认限制已提高
- 监控使用情况和成本
各层级升级条件:
| 层级 | 资格条件 | 典型审批时间 |
|---|---|---|
| Tier 1 | 关联Cloud Billing | 即时生效 |
| Tier 2 | 消费>$250且成功付费30天 | 3-5个工作日 |
| Tier 3 | 消费>$1,000且成功付费30天 | 5-7个工作日 |

【方法5】区域优化:利用不同地区配额隔离特性
Gemini API的一个重要特性是不同区域的配额是独立计算的。通过合理分配请求到不同区域,可以有效提高总体配额:
pythonimport google.generativeai as genai
from google.cloud import aiplatform
def get_regional_client(region="us-central1"):
"""获取特定区域的Gemini客户端"""
aiplatform.init(project=PROJECT_ID, location=region)
# 创建该区域的模型客户端
return genai.GenerativeModel(
model_name="gemini-2.5-pro",
generation_config={"temperature": 0.7},
)
# 创建多区域客户端池
model_clients = {
"us-central1": get_regional_client("us-central1"),
"europe-west4": get_regional_client("europe-west4"),
"asia-northeast1": get_regional_client("asia-northeast1")
}
def get_next_available_region():
"""简单的轮询策略选择下一个区域"""
global current_region_index
regions = list(model_clients.keys())
current_region_index = (current_region_index + 1) % len(regions)
return regions[current_region_index]
支持Gemini API的主要区域:
- us-central1(美国中部)- 默认区域,配额最高
- europe-west4(欧洲)- GDPR合规区域
- asia-northeast1(亚洲)- 亚太地区低延迟
实施建议:
- 考虑数据主权和合规性要求
- 监控不同区域的性能和可靠性
- 实现智能区域选择策略,而非简单轮询
- 注意不同区域可能支持的模型版本有差异
【方法6】缓存与复用:减少重复请求
通过实现高效的缓存机制,可以显著减少API调用次数,避免触发配额限制:
pythonimport hashlib
import redis
import json
import time
# 连接Redis缓存
cache = redis.Redis(host='localhost', port=6379, db=0)
CACHE_TTL = 86400 # 缓存24小时
def get_cache_key(prompt, model_params):
"""生成一个唯一的缓存键"""
key_data = {
"prompt": prompt,
"model": model_params.get("model", "gemini-2.5-pro"),
"temperature": model_params.get("temperature", 0.7),
"max_tokens": model_params.get("max_tokens", 1024)
}
return f"gemini:{hashlib.md5(json.dumps(key_data).encode()).hexdigest()}"
async def cached_generate_content(model, prompt, **kwargs):
"""带缓存的内容生成函数"""
cache_key = get_cache_key(prompt, kwargs)
# 尝试从缓存获取
cached_result = cache.get(cache_key)
if cached_result:
return json.loads(cached_result)
# 缓存未命中,调用API
response = await model.generate_content(prompt, **kwargs)
# 存入缓存
cache.setex(
cache_key,
CACHE_TTL,
json.dumps({"text": response.text, "cached_at": time.time()})
)
return {"text": response.text, "cached": False}
高效的缓存策略可以提供多种好处:
- 减少重复相同或相似请求的API调用
- 显著提高响应速度,改善用户体验
- 降低API使用成本和配额消耗
缓存优化建议:
- 使用基于内容的缓存键,而不仅是简单的查询文本
- 实现分层缓存策略(内存、Redis、数据库)
- 根据内容类型设置合适的缓存过期时间
- 考虑实现模糊匹配以捕捉语义相似的查询
【方法7】代理服务:自建API分发层
对于严肃的生产应用,构建专用的API代理层是一种高级解决方案:
pythonfrom fastapi import FastAPI, Request, BackgroundTasks
import asyncio
import time
import logging
app = FastAPI()
# 模型客户端池和使用记录
clients = setup_model_clients() # 配置多个API密钥和区域的客户端
usage_tracker = UsageTracker() # 跟踪每个客户端的使用情况
@app.post("/generate")
async def generate_content(request: Request, background_tasks: BackgroundTasks):
request_data = await request.json()
# 选择最佳客户端
client_id = select_optimal_client(request_data, usage_tracker)
try:
# 调用模型API
result = await clients[client_id].generate_content(
request_data["prompt"],
**request_data.get("options", {})
)
# 异步更新使用统计
background_tasks.add_task(
usage_tracker.record_usage,
client_id,
len(request_data["prompt"]),
len(result.text)
)
return {"result": result.text, "client_id": client_id}
except Exception as e:
# 智能错误处理和故障转移
logging.error(f"Client {client_id} failed: {str(e)}")
if "quota" in str(e).lower():
# 标记该客户端暂时不可用
background_tasks.add_task(usage_tracker.mark_throttled, client_id)
# 尝试使用备用客户端
return await retry_with_fallback(request_data, exclude=[client_id])
raise e
这种方法通过在应用和Gemini API之间构建一个智能代理层,实现了高级功能:
- 多API密钥轮换和负载均衡
- 智能客户端选择和配额管理
- 自动重试和故障转移
- 详细的使用统计和监控
实施复杂度:★★★★☆(需要服务器和开发经验)
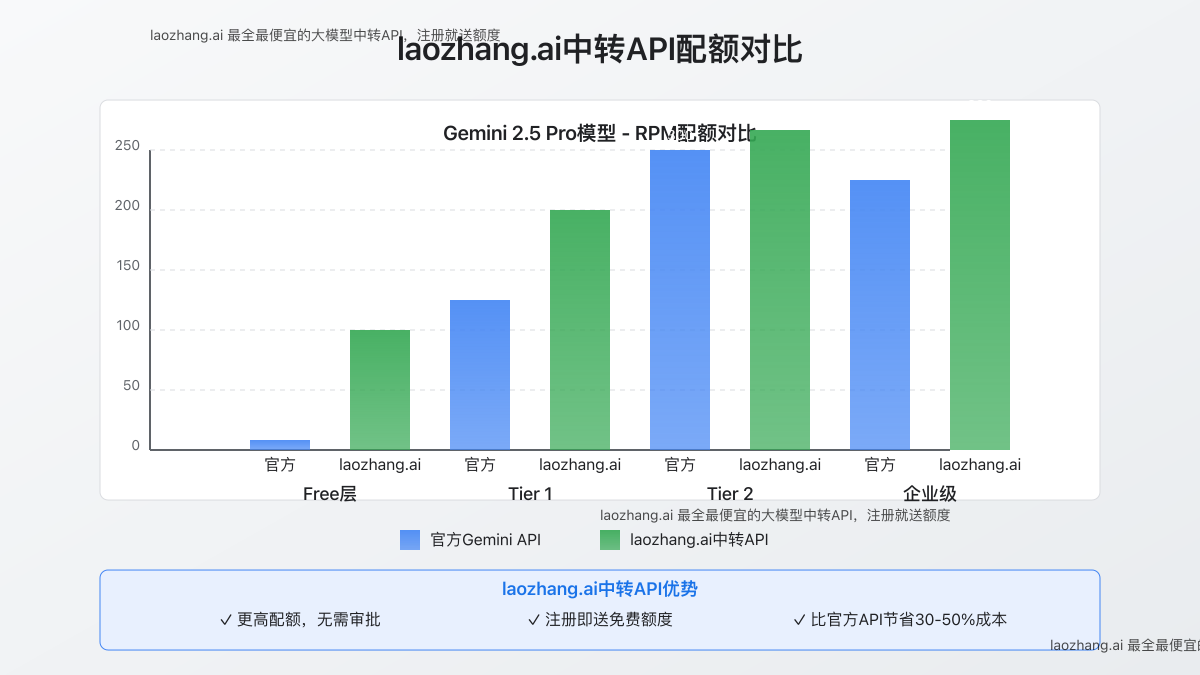
【方法8】laozhang.ai中转API:专业级配额解决方案
如果你希望立即解决配额问题而不涉及复杂开发,laozhang.ai提供了一站式解决方案:
laozhang.ai中转API的核心优势:
- 超高配额:远高于官方限制的RPM和TPM
- 无需审批:注册即可立即使用高配额
- 统一接口:兼容官方API,无缝切换
- 更低成本:比官方API节省30-50%
- 企业级可靠性:99.9%可用性保证
javascript// 使用laozhang.ai中转API调用Gemini 2.5 Pro
const axios = require('axios');
async function generateWithLaozhang(prompt) {
try {
const response = await axios.post(
'https://api.laozhang.ai/v1/chat/completions',
{
model: 'gemini-2.5-pro',
messages: [{ role: 'user', content: prompt }],
max_tokens: 1000
},
{
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${LAOZHANG_API_KEY}`
}
}
);
return response.data.choices[0].message.content;
} catch (error) {
console.error('API调用失败:', error.response?.data || error.message);
throw error;
}
}
快速集成步骤:
- 访问laozhang.ai注册页面创建账户
- 获取API密钥和使用说明
- 将现有代码中的API端点替换为laozhang.ai端点
- 享受高配额和稳定性能
第三部分:配额最佳实践和常见问题
综合配额管理策略
对于认真的开发者和企业,我们建议采用多层次的配额管理策略:
-
监控与预警:
- 实现实时配额使用监控
- 设置接近限制的预警机制
- 记录详细的使用模式和趋势
-
优雅降级机制:
- 设计配额不足时的备用流程
- 实现跨模型的故障转移
- 考虑使用本地轻量级模型作为最后手段
-
用户体验优化:
- 对用户透明地处理配额错误
- 提供合理的重试和等待提示
- 优先处理关键请求,延迟非关键请求
常见问题解答(FAQ)
Q1: 我已经开启了Cloud Billing,为什么仍然遇到配额限制?
A: 即使启用了付费账户,Gemini API仍然有基础的Tier 1限制。要突破这些限制,需要累计消费并申请升级到更高层级。在升级审批期间,可以考虑使用laozhang.ai等第三方服务绕过限制。
Q2: 如何判断是哪种类型的配额限制被触发了?
A: 检查错误消息中的具体描述:
- 包含"per_minute"通常是RPM限制
- 包含"tokens_per_minute"是TPM限制
- 包含"per_day"是RPD限制 详细的错误日志对诊断具体问题非常关键。
Q3: 不同Gemini模型之间的配额是共享的吗?
A: 不,每个模型有独立的配额计数。例如,使用Gemini 2.5 Pro的请求不会影响Gemini 2.5 Flash的配额。这也是为什么模型下切策略能有效缓解配额问题。
Q4: 升级到付费层级后,大约需要多长时间才能看到配额增加?
A:
- Tier 1通常在启用Cloud Billing后即时生效
- Tier 2和Tier 3需要人工审批,一般需要3-7个工作日
- 如果超过7天未收到回复,可以联系Google Cloud支持
Q5: laozhang.ai中转API如何能提供更高配额?
A: laozhang.ai通过企业级基础设施和高级资源管理策略,整合和优化了多个高级别账户的资源,为用户提供更高的综合配额。他们的服务实际上是在客户端和Google API之间添加了一个智能中间层,实现了高效的请求调度和资源复用。
总结:选择最适合你的解决方案
Gemini API的配额限制是一个多层面的挑战,需要根据具体情况选择合适的解决方案:
| 解决方案 | 复杂度 | 立即见效 | 适用场景 |
|---|---|---|---|
| 智能请求节流 | ★☆☆☆☆ | ✓ | 低流量应用、个人项目 |
| 模型下切 | ★★☆☆☆ | ✓ | 混合复杂度任务 |
| 请求合并 | ★★★☆☆ | ✓ | 批量处理任务 |
| 配额升级 | ★★☆☆☆ | ✗ | 长期商业项目 |
| 区域优化 | ★★★☆☆ | ✓ | 全球用户分布的应用 |
| 缓存与复用 | ★★★☆☆ | ✓ | 重复查询多的应用 |
| 代理服务 | ★★★★★ | ✗ | 大规模企业应用 |
| laozhang.ai API | ★☆☆☆☆ | ✓ | 需要立即解决配额问题的所有场景 |
最终建议
- 个人开发者:从简单的节流策略开始,结合模型下切和缓存机制
- 中小企业:考虑laozhang.ai等中转服务,快速解决配额问题
- 大型企业:投资开发自己的代理层,同时申请更高层级配额
无论你选择哪种方案,了解Gemini API的配额体系并主动管理它,是构建可靠AI应用的关键。配额不再是障碍,而是促使我们更高效利用AI资源的机会。
立即行动:尝试laozhang.ai中转API服务,无需等待,立刻获得高配额Gemini API访问,并享受注册即送的额度福利!