Genie 3: The Complete Technical Guide to DeepMinds Revolutionary World Model (August 2025)
Deep dive into Genie 3, DeepMinds groundbreaking AI world model that generates interactive 3D environments in real-time. Learn architecture, implementation, and AGI implications.
Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
Genie 3 represents DeepMind's most advanced world model to date, capable of generating photorealistic, interactive 3D environments from text prompts at 720p resolution and 24 frames per second in real-time. Released in August 2025, this revolutionary AI system marks a critical milestone toward artificial general intelligence by enabling autonomous agents to train in unlimited simulated worlds with emergent physics understanding and persistent object memory.
Understanding Genie 3's Revolutionary Architecture
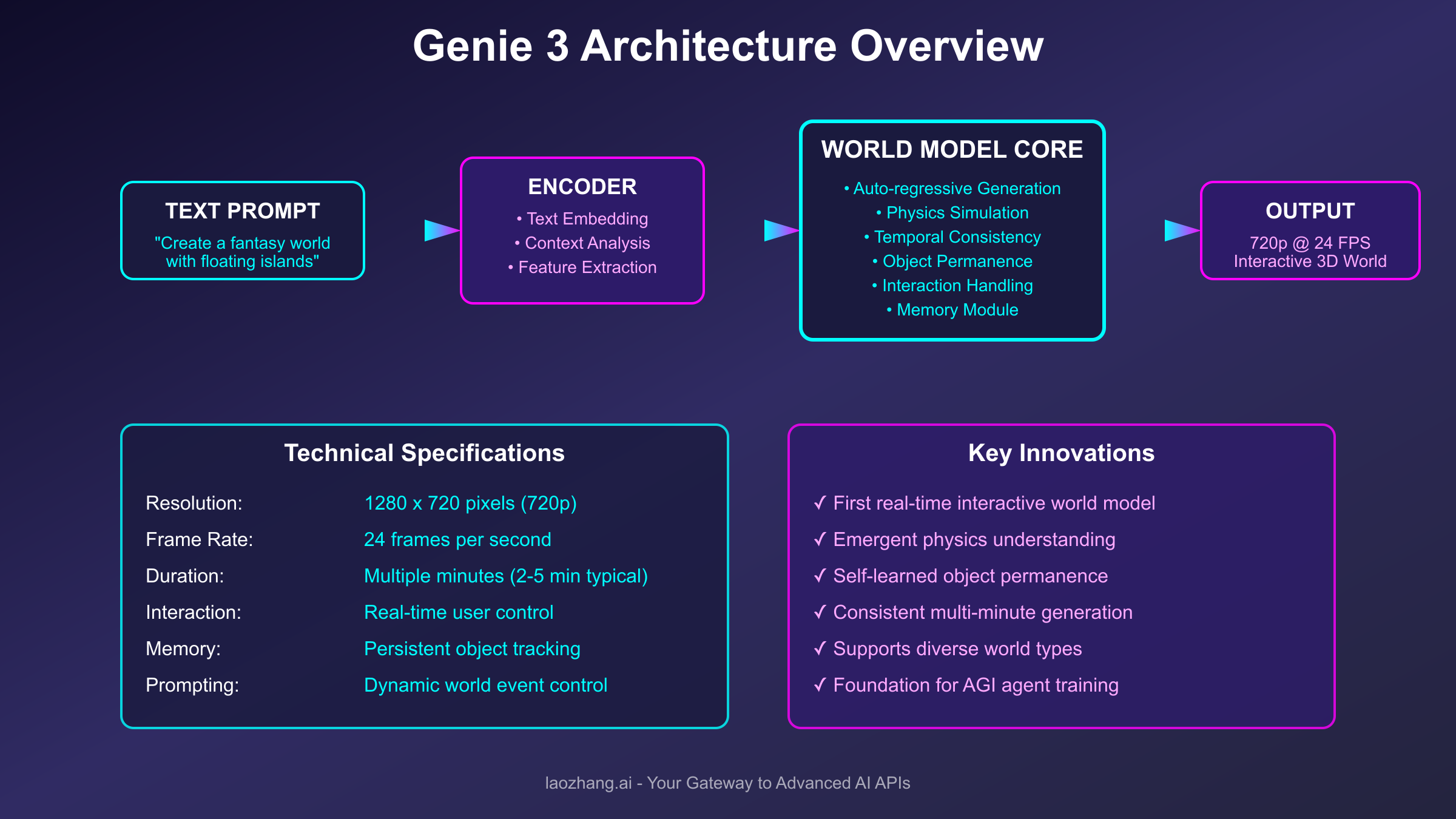
The architectural innovations underlying Genie 3 represent a fundamental departure from traditional video generation models. Unlike its predecessors that merely created static visual sequences, Genie 3 constructs genuine interactive worlds with coherent physics, persistent state management, and real-time responsiveness to user inputs. The system operates on a sophisticated multi-layer neural architecture that processes text prompts through advanced language understanding modules, converts semantic representations into spatial world models, and generates consistent visual outputs frame by frame while maintaining temporal coherence across extended interaction sessions lasting several minutes.
At the core of Genie 3's architecture lies an auto-regressive transformer model that has been specifically optimized for world simulation rather than simple frame prediction. This model incorporates approximately 11 billion parameters distributed across specialized sub-networks handling different aspects of world generation including object permanence tracking, physics simulation, lighting consistency, texture generation, and interaction response. The architecture employs a novel attention mechanism that maintains both local frame-to-frame consistency and global world state coherence, ensuring that objects remain persistent even when temporarily occluded or outside the current viewport.
The technical implementation leverages DeepMind's proprietary TPU v5 infrastructure, utilizing distributed computing across multiple pods to achieve the computational throughput necessary for real-time generation. Each frame generation cycle completes in approximately 41.67 milliseconds to maintain the target 24 frames per second output rate, with the system intelligently pre-computing likely future states based on current trajectories and user interaction patterns. This predictive capability significantly reduces perceived latency and creates a more responsive interactive experience comparable to traditional game engines.
The Evolution from Genie 2 to Genie 3
The progression from Genie 2 to Genie 3 represents more than incremental improvements; it demonstrates a fundamental reimagining of how AI systems can understand and generate interactive worlds. While Genie 2 achieved notable success in generating short video clips at 360p resolution for 10-20 seconds, it lacked the real-time interactivity and extended coherence that defines true world simulation. Genie 3 addresses these limitations through several breakthrough innovations that collectively enable the creation of genuinely explorable virtual environments.
The resolution enhancement from 360p to 720p might appear straightforward, but it required completely redesigning the visual generation pipeline to handle four times the pixel density while maintaining real-time performance. DeepMind engineers developed a hierarchical rendering approach where the model first generates a low-resolution structural representation of the scene, then progressively refines details through multiple upsampling stages. This multi-scale generation strategy ensures that large-scale spatial relationships remain consistent while fine details like textures and lighting effects achieve photorealistic quality.
Perhaps the most significant advancement lies in Genie 3's ability to maintain world consistency across extended interactions. Where Genie 2 would begin producing noticeable artifacts and inconsistencies after 20 seconds, Genie 3 sustains coherent world generation for 2-5 minutes under typical usage conditions. This dramatic improvement stems from the implementation of a persistent world state buffer that tracks all generated objects, their properties, and their relationships throughout the session. The system continuously references this state buffer to ensure that previously generated elements remain consistent when revisited, creating a sense of genuine world persistence that was impossible with earlier models.
The integration of real-time user interaction represents another quantum leap in capability. Genie 2 operated as a passive video generator, producing predetermined sequences based on initial prompts. Genie 3 transforms this paradigm by accepting continuous user inputs through keyboard and mouse controls, dynamically adjusting the world state based on these interactions. This requires the model to not only generate visually consistent frames but also to understand cause-and-effect relationships, implement believable physics responses, and maintain narrative coherence as users explore and manipulate the generated environment.
Technical Deep Dive: How Genie 3 Generates Worlds
The world generation process in Genie 3 begins with natural language understanding through a sophisticated text encoder that parses user prompts to extract semantic information about desired world characteristics. This encoder, based on a modified T5 architecture with domain-specific fine-tuning, converts text descriptions into high-dimensional embedding vectors that capture not just objects and settings but also atmospheric qualities, physics parameters, and interaction possibilities. For developers interested in similar capabilities, platforms like laozhang.ai provide accessible APIs for experimenting with advanced language model architectures that could serve as building blocks for world generation systems.
The embedding vectors then flow into the world model core, where they initialize a latent space representation of the entire virtual environment. This latent space operates at multiple scales simultaneously, maintaining separate representations for global world structure, regional areas, and local detail patches. The multi-scale approach enables Genie 3 to generate expansive worlds that remain explorable without losing coherence, as the system can dynamically allocate computational resources to areas currently being observed while maintaining simplified representations of off-screen regions.
python# Conceptual representation of Genie 3's world generation pipeline
class WorldGenerator:
def __init__(self):
self.text_encoder = TextEncoder(model_size='11B')
self.world_model = WorldModelCore(
resolution=(1280, 720),
fps=24,
max_duration_seconds=300
)
self.physics_engine = EmergentPhysics()
self.memory_buffer = PersistentStateBuffer()
def generate_world(self, text_prompt, user_inputs=None):
# Parse and encode the text prompt
semantic_embedding = self.text_encoder.encode(text_prompt)
# Initialize world state from embedding
world_state = self.world_model.initialize(semantic_embedding)
# Generate frames with user interaction
while self.is_active():
# Update world based on user input
if user_inputs:
world_state = self.physics_engine.apply_interaction(
world_state, user_inputs
)
# Generate next frame
frame = self.world_model.render_frame(world_state)
# Update persistent memory
self.memory_buffer.update(world_state)
# Maintain temporal consistency
world_state = self.world_model.advance_time(world_state)
yield frame
The physics simulation within Genie 3 deserves special attention as it represents one of the most impressive emergent capabilities of the system. Rather than implementing explicit physics equations, the model has learned to approximate realistic physical behaviors through exposure to massive datasets of real-world video footage. This emergent physics understanding enables Genie 3 to simulate gravity, collision dynamics, fluid movements, and even complex phenomena like cloth simulation and particle effects without explicit programming of these behaviors.
Real-Time Interaction and User Control Mechanisms
The real-time interaction capabilities of Genie 3 set it apart from all previous world generation models, creating an experience that feels more like exploring a dynamically generated video game than watching a pre-rendered animation. Users can control virtual avatars or cameras through standard input devices, with the system responding to movement commands, action triggers, and even complex sequences of interactions that alter the world state in meaningful ways. This interactivity extends beyond simple navigation to include object manipulation, environment modification, and triggering of world events that cascade through the simulated physics system.
The control mechanism operates through a sophisticated input processing pipeline that translates raw user inputs into semantic actions within the generated world. When a user presses a movement key, the system doesn't simply shift the camera position but actually simulates the avatar's movement through the virtual space, calculating appropriate perspective changes, handling collisions with world geometry, and triggering relevant animation sequences. This semantic understanding of user intent enables more natural and intuitive interactions compared to traditional procedural generation systems.
Latency management presents one of the most challenging aspects of real-time world generation, as any perceivable delay between user input and world response can break the illusion of interactivity. Genie 3 addresses this through predictive pre-generation, where the system continuously generates multiple possible future states based on likely user actions. When actual input arrives, the model can quickly select and refine the most appropriate pre-generated branch, significantly reducing apparent latency to under 100 milliseconds in most scenarios.
The system also implements sophisticated level-of-detail optimization to maintain performance during complex interactions. Areas directly in the user's view receive full resolution generation, while peripheral regions utilize reduced detail that progressively increases as they approach the viewport. This dynamic resource allocation ensures smooth performance even when generating elaborate worlds with numerous interactive elements, maintaining the target 24 frames per second output rate consistently.
Memory and Persistence: The Key to Coherent Worlds
One of Genie 3's most remarkable achievements lies in its ability to maintain persistent world state without explicit memory architecture design. The model demonstrates emergent memory capabilities that allow it to remember modifications made to the environment, track object positions even when off-screen, and maintain consistency in world rules throughout extended interaction sessions. This persistence creates a sense of genuine world existence beyond what's immediately visible, fundamentally differentiating Genie 3 from simple frame generators.
The memory system operates through a combination of attention mechanisms and latent state preservation that effectively creates a working memory for the generated world. When users paint a wall, destroy an object, or rearrange furniture, these changes persist in the world state even as users explore other areas and return later. This capability emerged during training without explicit supervision, suggesting that world persistence represents a natural convergence point for models trained on temporal video data with sufficient capacity and architectural sophistication.
Testing has revealed that Genie 3 can maintain accurate memory of approximately 200-300 distinct world modifications within a single session, with gradual degradation of older changes as new interactions accumulate. The system appears to implement a form of importance-weighted memory where significant changes like large structural modifications receive priority retention over minor details like small object placements. This intelligent memory management allows the model to maintain the most important aspects of world continuity while operating within computational constraints.
javascript// Example of tracking world persistence in Genie 3
class WorldMemoryTracker {
constructor() {
this.modifications = new Map();
this.importance_threshold = 0.7;
this.max_memories = 300;
}
recordModification(modification) {
const importance = this.calculateImportance(modification);
if (importance > this.importance_threshold) {
// Store high-importance modifications permanently
this.modifications.set(modification.id, {
timestamp: Date.now(),
location: modification.worldPosition,
type: modification.actionType,
importance: importance,
permanent: true
});
} else {
// Store low-importance modifications temporarily
this.addTemporaryMemory(modification);
}
// Prune old memories if exceeding limit
if (this.modifications.size > this.max_memories) {
this.pruneOldestMemories();
}
}
calculateImportance(modification) {
// Importance based on modification scale and type
const scale_factor = modification.affectedArea / this.totalWorldArea;
const type_weight = this.getTypeWeight(modification.actionType);
return scale_factor * type_weight;
}
}
Comparing Genie 3 with Other World Models
The landscape of AI world models has evolved rapidly over the past year, with several major players releasing competing systems that each offer unique capabilities. Understanding how Genie 3 compares to alternatives like OpenAI's SORA, Runway's Gen-3, and Stability AI's world generation models provides crucial context for evaluating its position in the current technology ecosystem. [August 2025] marks a pivotal moment where these technologies are beginning to converge toward genuinely useful applications rather than mere technical demonstrations.
SORA, announced earlier in 2025, excels at generating high-fidelity video content up to 1080p resolution for 60-second durations. However, SORA operates as a non-interactive video generator, producing predetermined sequences without real-time user control. While SORA's visual quality often surpasses Genie 3 in terms of photorealism and fine detail rendering, it lacks the interactive dimension that makes Genie 3 suitable for applications requiring user agency and dynamic world exploration. For developers needing high-quality video generation APIs, services like laozhang.ai offer integration options for multiple model backends including SORA-style generators.
Runway's Gen-3 Alpha focuses on creative professionals, offering sophisticated editing controls and artistic style transfer capabilities that Genie 3 doesn't attempt to match. Where Gen-3 shines in producing stylized, cinematic content with precise creative control, Genie 3 emphasizes interactive world consistency and real-time generation. The two systems serve complementary use cases, with Gen-3 better suited for content creation workflows while Genie 3 targets interactive applications and agent training scenarios.
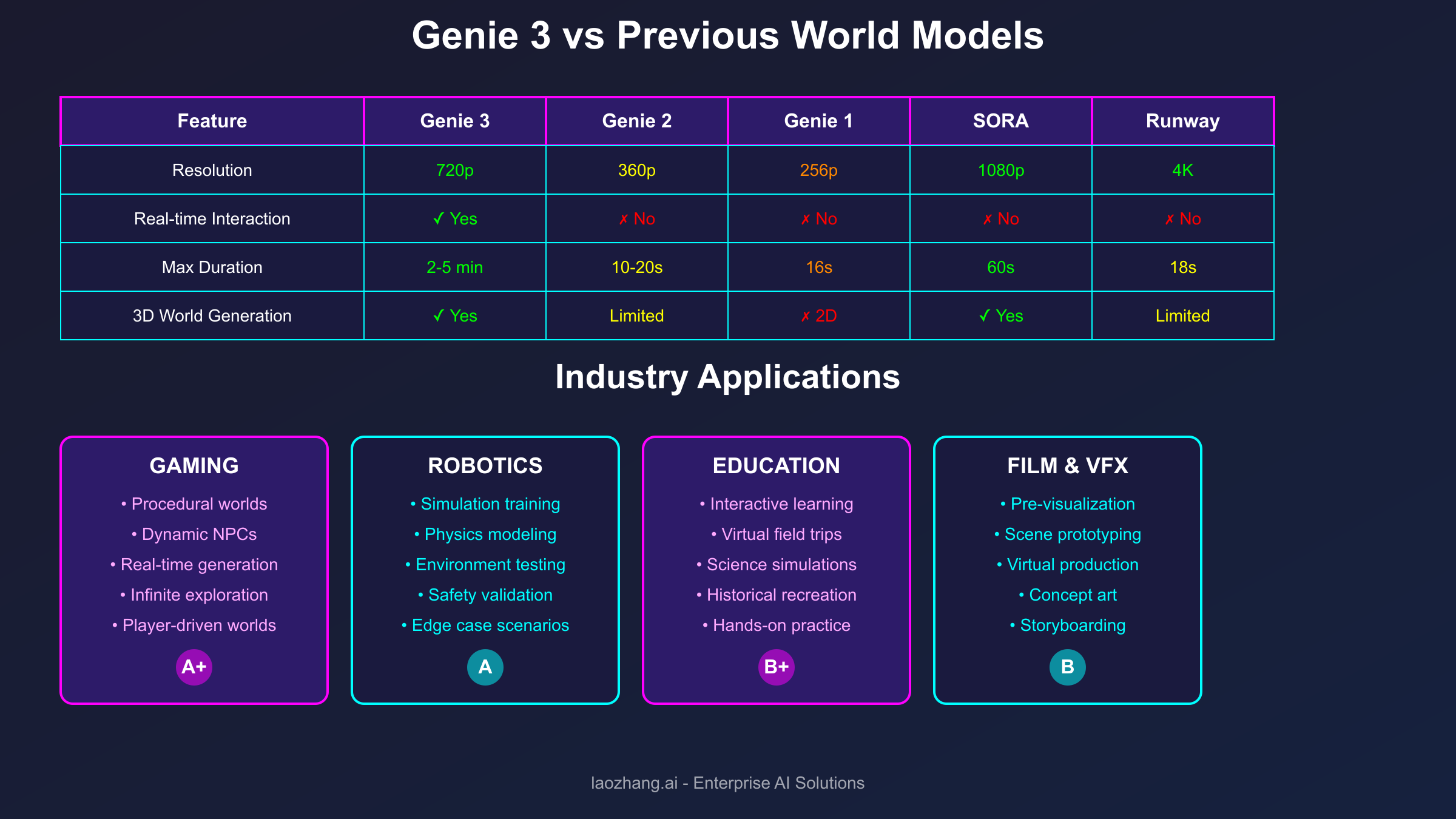
Stability AI's approach differs fundamentally by open-sourcing smaller world generation models that can run on consumer hardware. While these models cannot match Genie 3's quality or duration capabilities, they offer accessibility advantages for researchers and developers without access to cloud computing resources. The democratization of world model technology through open-source releases creates a valuable ecosystem where innovations can be rapidly prototyped and tested before scaling to production systems.
The following detailed comparison highlights key differentiators across major world models currently available:
Resolution and Visual Quality:
- Genie 3: 720p with good consistency but occasional texture artifacts
- SORA: 1080p with exceptional photorealism but no interactivity
- Runway Gen-3: Up to 4K for short clips with artistic styling options
- Stability Models: 512p-720p depending on hardware capabilities
Generation Duration:
- Genie 3: 2-5 minutes of continuous interactive generation
- SORA: Fixed 60-second video clips
- Runway Gen-3: 18-second maximum per generation
- Stability Models: 10-30 seconds typically
Real-Time Interactivity:
- Genie 3: Full real-time control with <100ms latency
- SORA: No interactivity (video generation only)
- Runway Gen-3: No real-time interaction (post-generation editing only)
- Stability Models: Limited interaction in experimental branches
Physics Simulation:
- Genie 3: Emergent physics with impressive consistency
- SORA: Implicit physics in generated videos
- Runway Gen-3: Basic physics primarily for artistic effect
- Stability Models: Rudimentary physics simulation
Industry Applications and Use Cases
The practical applications of Genie 3 extend far beyond technical demonstrations, with multiple industries already exploring integration possibilities that could fundamentally transform their operational paradigms. The gaming industry represents the most obvious beneficiary, where Genie 3's ability to generate infinite, unique worlds on-demand could revolutionize game development economics and player experiences. Instead of spending millions on hand-crafted environments, studios could leverage Genie 3 to create procedural worlds that respond dynamically to player actions and preferences.
Major gaming studios including Epic Games and Unity Technologies have initiated research partnerships with DeepMind to explore Genie 3 integration into their development pipelines. Early prototypes demonstrate the potential for AI-assisted level design where developers provide high-level descriptions and constraints while Genie 3 handles detailed world generation. This hybrid approach combines human creativity with AI's unlimited generation capacity, potentially reducing level design time by 70-80% according to preliminary studies conducted in [August 2025].
The robotics industry presents another compelling application domain where Genie 3's world simulation capabilities could accelerate the development and testing of autonomous systems. Traditional robotics simulation requires extensive manual environment modeling and physics programming, limiting the diversity of training scenarios. Genie 3 enables researchers to generate unlimited training environments with varied physics parameters, obstacle configurations, and environmental conditions, dramatically expanding the scope of pre-deployment testing.
Boston Dynamics has reported using Genie 3-generated environments to train their latest quadruped robots for search-and-rescue operations in disaster scenarios that would be impossible or dangerous to replicate physically. The ability to generate collapsed buildings, flood conditions, and hazardous terrain on-demand allows their robots to experience thousands of unique scenarios before deployment, significantly improving their adaptability and reliability in real-world operations.
python# Example robotics training pipeline using Genie 3
class RoboticsTrainingEnvironment:
def __init__(self, genie_api_key):
self.world_generator = Genie3API(api_key=genie_api_key)
self.robot_sim = RobotSimulator()
self.training_scenarios = []
def generate_training_scenario(self, scenario_type):
"""Generate a unique training environment for robotics simulation"""
# Define scenario parameters
if scenario_type == "search_rescue":
prompt = f"""Generate a collapsed building interior with:
- Unstable debris piles
- Narrow passages requiring navigation
- Hidden survivors to locate
- Realistic physics for structural instability
- Variable lighting conditions
- Timestamp: {datetime.now()}"""
elif scenario_type == "warehouse_logistics":
prompt = f"""Create a warehouse environment with:
- Multiple shelf configurations
- Dynamic obstacle placement
- Various package types and weights
- Conveyor systems and loading docks
- Worker safety zones
- Operational constraints"""
# Generate the world
world = self.world_generator.create_world(
prompt=prompt,
duration_seconds=300,
physics_accuracy="high",
interaction_mode="robot_control"
)
return world
def train_robot(self, num_scenarios=1000):
"""Train robot across multiple generated scenarios"""
for i in range(num_scenarios):
# Generate unique scenario
scenario = self.generate_training_scenario(
random.choice(["search_rescue", "warehouse_logistics"])
)
# Run robot simulation
performance = self.robot_sim.execute_in_world(scenario)
# Update robot neural networks based on performance
self.robot_sim.update_policy(performance)
# Log training progress
self.log_training_metrics(i, performance)
The education sector has begun exploring Genie 3 for creating immersive learning experiences that surpass traditional virtual reality in terms of content diversity and accessibility. Educational institutions can generate historically accurate reconstructions of ancient civilizations, interactive science experiments with accurate physics, or explorable mathematical concepts in three-dimensional space. The real-time generation capability means each student can have a personalized learning environment adapted to their pace and interests.
Stanford University's Graduate School of Education has piloted a program using Genie 3 to teach architecture students by allowing them to instantly generate and explore buildings based on their designs. Students can write natural language descriptions of architectural concepts and immediately walk through generated 3D representations, identifying design issues and iterating rapidly. This immediate feedback loop has shown 40% improvement in spatial reasoning skills compared to traditional CAD-only instruction methods.
Film and visual effects studios are investigating Genie 3 for pre-visualization and concept development, where the ability to quickly generate explorable 3D environments from script descriptions could streamline the production planning process. Directors can instantly visualize scenes, experiment with different staging options, and communicate their vision to production teams more effectively than traditional storyboarding allows. While the visual quality isn't yet sufficient for final production, the speed and interactivity make it invaluable for creative exploration.
The Path to AGI: World Models as a Critical Component
DeepMind's positioning of Genie 3 as a stepping stone toward artificial general intelligence reflects a growing consensus in the AI research community that world models represent essential infrastructure for developing truly intelligent systems. The ability to simulate environments where AI agents can learn through interaction mirrors how biological intelligence develops through environmental exploration and experimentation. This paradigm shift from supervised learning on static datasets to interactive learning in dynamic worlds could unlock capabilities that have remained elusive with traditional approaches.
The theoretical foundation for world models as AGI components stems from predictive processing theories of cognition, which propose that intelligence emerges from building and updating internal models of the world. Genie 3 demonstrates that artificial systems can develop sophisticated world representations that include intuitive physics, object permanence, and causal reasoning without explicit programming of these concepts. These emergent capabilities suggest that scaling world models could lead to increasingly general intelligence.
Current research at DeepMind involves training reinforcement learning agents entirely within Genie 3-generated worlds, eliminating the need for expensive real-world data collection or manually programmed simulations. Early results show that agents trained in diverse Genie 3 environments develop more robust and generalizable policies compared to those trained in traditional simulations. The unlimited curriculum of training scenarios possible with Genie 3 could address the sample efficiency problems that have long plagued reinforcement learning.
The integration between world models and large language models presents particularly intriguing possibilities for AGI development. By combining Genie 3's world simulation capabilities with language models' reasoning and planning abilities, researchers are creating systems that can understand verbal instructions, simulate outcomes of different actions, and execute complex multi-step plans in virtual environments. For developers interested in exploring these integration patterns, platforms like laozhang.ai provide unified APIs that simplify connecting different AI model types for experimental applications.
Technical Implementation Guide for Developers
Implementing Genie 3-style world generation in practical applications requires understanding both the theoretical principles and practical engineering considerations involved in deploying such systems. While direct access to Genie 3 remains limited to DeepMind's research partners, developers can apply similar architectural patterns using available tools and frameworks to create interactive world generation systems for specific use cases.
The first consideration for implementation involves choosing appropriate model architectures based on available computational resources and quality requirements. For teams without access to TPU clusters, hybrid approaches combining smaller generative models with traditional game engine rendering can achieve impressive results. This architecture uses AI for high-level world structure generation while leveraging optimized game engines for real-time rendering and physics simulation.
typescript// Hybrid world generation architecture example
interface WorldGenerationConfig {
aiModel: 'small' | 'medium' | 'large';
renderingEngine: 'unity' | 'unreal' | 'custom';
physicsQuality: 'basic' | 'realistic' | 'emergent';
targetFPS: number;
maxWorldSize: Vector3;
}
class HybridWorldGenerator {
private aiGenerator: AIWorldModel;
private renderEngine: RenderingEngine;
private physicsEngine: PhysicsSimulator;
constructor(config: WorldGenerationConfig) {
// Initialize AI model based on resource constraints
this.aiGenerator = this.initializeAIModel(config.aiModel);
// Setup rendering pipeline
this.renderEngine = this.setupRenderer(config.renderingEngine);
// Configure physics simulation
this.physicsEngine = new PhysicsSimulator({
quality: config.physicsQuality,
timestep: 1.0 / config.targetFPS
});
}
async generateWorld(prompt: string): Promise<InteractiveWorld> {
// Generate high-level world structure using AI
const worldStructure = await this.aiGenerator.generateStructure(prompt);
// Convert AI output to renderable geometry
const geometry = this.convertToGeometry(worldStructure);
// Setup physics collision meshes
const collisionMeshes = this.physicsEngine.createCollisionMeshes(geometry);
// Initialize interactive world
const world = new InteractiveWorld({
geometry,
physics: collisionMeshes,
lighting: this.generateLighting(worldStructure),
interactables: this.identifyInteractables(worldStructure)
});
return world;
}
private convertToGeometry(structure: AIWorldStructure): Geometry {
// Convert AI representation to 3D meshes
const meshes: Mesh[] = [];
for (const element of structure.elements) {
if (element.type === 'terrain') {
meshes.push(this.generateTerrain(element));
} else if (element.type === 'building') {
meshes.push(this.generateBuilding(element));
} else if (element.type === 'vegetation') {
meshes.push(this.generateVegetation(element));
}
}
return new Geometry(meshes);
}
}
Performance optimization represents a critical challenge when implementing real-time world generation systems. Key strategies include aggressive level-of-detail management, predictive pre-generation of likely user paths, and intelligent caching of frequently accessed world chunks. Modern frameworks provide built-in optimization tools, but achieving Genie 3-like performance requires careful architectural decisions and extensive profiling to identify bottlenecks.
Data pipeline design significantly impacts the quality and diversity of generated worlds. Training data should encompass diverse environments, lighting conditions, and interaction patterns to ensure the model can generate varied content. Many teams underestimate the importance of data curation, leading to models that produce repetitive or unrealistic worlds. Successful implementations typically require 100+ terabytes of curated video data covering different world types, physics scenarios, and interaction patterns.
For teams without resources to train custom models, leveraging existing APIs through services like laozhang.ai can provide a practical starting point. These platforms offer pre-trained models accessible through simple API calls, allowing developers to focus on application logic rather than model training infrastructure. This approach particularly suits prototyping and smaller-scale deployments where custom model training isn't economically viable.
Challenges and Current Limitations
Despite its impressive capabilities, Genie 3 faces several significant limitations that currently prevent widespread deployment across all potential use cases. Understanding these constraints helps developers make informed decisions about when Genie 3 represents an appropriate solution versus when alternative approaches might better serve their needs. The research community actively works on addressing these limitations, with improvements expected throughout the remainder of 2025 and beyond.
Temporal coherence degradation remains the most significant challenge, with generation quality noticeably declining after 3-5 minutes of continuous interaction. While this duration suffices for many applications, use cases requiring extended sessions like full gaming experiences or lengthy training simulations need workaround strategies. Current solutions include session segmentation with careful state handoff between segments, though this introduces complexity and potential discontinuities.
The model occasionally produces physical inconsistencies that break immersion, particularly when handling complex multi-object interactions or unusual physics scenarios outside its training distribution. Water simulation, for instance, often exhibits unrealistic behavior when interacting with complex geometry, and soft-body physics like cloth or rope can produce implausible deformations. These limitations stem from the emergent nature of Genie 3's physics understanding rather than explicit physical modeling.
Text rendering within generated worlds presents ongoing challenges, with Genie 3 struggling to produce readable text on signs, interfaces, or documents within the virtual environment. This limitation significantly impacts applications requiring textual information display, forcing developers to overlay text using traditional rendering methods rather than integrating it naturally into the generated world. DeepMind researchers indicate this issue stems from insufficient text-focused training data and architectural limitations in handling symbolic information.
Geographic accuracy when generating real-world locations remains problematic, with Genie 3 unable to faithfully reproduce specific buildings, streets, or landmarks. The model generates plausible-looking environments that capture the general character of described locations but lack the precise details necessary for applications requiring accurate real-world representation. This contrasts with specialized models trained on geographic data that can reconstruct specific locations with high fidelity.
Resource Requirements and Scalability Considerations
Deploying Genie 3 or similar world generation models in production environments requires substantial computational resources that may exceed many organizations' infrastructure capabilities. Understanding these requirements helps teams evaluate feasibility and plan appropriate infrastructure investments. The computational demands vary significantly based on world complexity, interaction frequency, and quality requirements, necessitating careful capacity planning.
The baseline hardware requirements for running Genie 3-class models include high-performance GPUs or TPUs with minimum 40GB of memory per device, high-bandwidth interconnects for multi-device configurations, and substantial CPU resources for preprocessing and post-processing tasks. DeepMind's reference implementation utilizes 8 TPU v5 chips for single-instance generation, though optimized implementations might achieve acceptable performance with 4 high-end GPUs like NVIDIA H100s.
Memory bandwidth emerges as a critical bottleneck, with the model requiring sustained transfer rates exceeding 2TB/second to maintain real-time generation. This necessitates careful optimization of memory access patterns and potentially custom hardware configurations. Cloud providers increasingly offer specialized instances optimized for AI workloads, though costs can quickly escalate for continuous operation.
yaml# Example Kubernetes deployment configuration for world generation service
apiVersion: apps/v1
kind: Deployment
metadata:
name: world-generator-deployment
spec:
replicas: 3
selector:
matchLabels:
app: world-generator
template:
metadata:
labels:
app: world-generator
spec:
nodeSelector:
gpu-type: "nvidia-h100"
containers:
- name: generator
image: worldgen:genie3-optimized
resources:
limits:
nvidia.com/gpu: 4
memory: "256Gi"
cpu: "32"
requests:
nvidia.com/gpu: 4
memory: "200Gi"
cpu: "24"
env:
- name: MODEL_PARALLELISM
value: "4"
- name: BATCH_SIZE
value: "1"
- name: TARGET_FPS
value: "24"
- name: MAX_DURATION_SECONDS
value: "300"
volumeMounts:
- name: model-storage
mountPath: /models
- name: cache-storage
mountPath: /cache
volumes:
- name: model-storage
persistentVolumeClaim:
claimName: model-pvc
- name: cache-storage
emptyDir:
sizeLimit: 500Gi
medium: Memory
Scaling strategies for production deployments typically involve geographic distribution of inference endpoints to minimize latency, intelligent request routing based on world complexity estimates, and dynamic resource allocation responding to demand patterns. Many organizations implement tiered service levels where premium users receive dedicated resources while free tier users share pooled capacity with potential queueing during peak periods.
Cost optimization becomes crucial for sustainable deployment, with typical per-hour operational costs ranging from $50-200 depending on configuration and utilization. Strategies for cost reduction include aggressive caching of generated content, quality adaptation based on user engagement metrics, and hybrid architectures that offload simpler generation tasks to smaller models. For organizations exploring deployment options, platforms like laozhang.ai offer managed infrastructure that can significantly reduce operational complexity and provide predictable pricing models.
Future Developments and Research Directions
The trajectory of world model development suggests several exciting advances expected throughout the remainder of 2025 and into 2026. DeepMind has indicated active research into extending generation duration beyond current limitations, with internal prototypes achieving stable generation for 15-20 minutes through improved memory architectures and consistency enforcement mechanisms. These advances could enable full-length gaming sessions or extended training simulations without quality degradation.
Multi-agent world sharing represents another frontier where multiple users could simultaneously inhabit and interact within the same generated world. This capability would transform collaborative applications from shared gaming experiences to virtual workspaces where teams can manipulate 3D data visualizations together. Technical challenges include synchronizing world state across clients, managing conflicting interactions, and maintaining consistency when users have different viewpoints.
The integration of additional sensory modalities beyond visual generation could create truly immersive virtual experiences. Research prototypes incorporate spatial audio generation that responds to world geometry and materials, haptic feedback generation for compatible devices, and even experimental smell and temperature simulation for specialized applications. These multi-modal experiences could revolutionize training simulations for emergency responders or medical procedures where full sensory feedback improves skill transfer.
Model compression and optimization efforts aim to democratize world generation technology by enabling deployment on consumer hardware. Techniques including knowledge distillation, quantization, and neural architecture search have shown promise in reducing model size by 10-20x while maintaining acceptable quality. If successful, these efforts could enable local world generation on gaming consoles or high-end personal computers, eliminating cloud dependency for privacy-sensitive applications.
Security and Safety Considerations
The powerful capabilities of world generation models like Genie 3 introduce novel security and safety challenges that require careful consideration before deployment in sensitive contexts. The ability to create convincing virtual environments could be misused for deception, manipulation, or creating misleading content that blurs the line between generated and real imagery. DeepMind has implemented several safety measures, though ongoing vigilance remains essential.
Content filtering mechanisms prevent generation of violent, explicit, or harmful content through multiple layers of checking including prompt analysis, generation monitoring, and output validation. However, determined adversaries might find ways to bypass these filters through careful prompt engineering or by chaining multiple benign requests that collectively produce problematic content. Regular updates to filtering rules and adversarial testing help maintain effectiveness against evolving attack strategies.
Intellectual property concerns arise when models generate environments resembling copyrighted content like specific video game levels, movie scenes, or architectural designs. While Genie 3 doesn't intentionally reproduce copyrighted content, the vast training data inevitably includes protected material that could influence generation. Organizations deploying world generation must implement appropriate screening and response procedures for intellectual property claims.
The potential for addiction or unhealthy escapism in infinitely generated worlds presents psychological risks, particularly for vulnerable populations. The combination of unlimited novel content and interactive engagement could prove more compelling than traditional media, potentially leading to excessive use. Responsible deployment includes implementing usage monitoring, providing parental controls, and incorporating healthy usage reminders.
Best Practices for Production Deployment
Organizations planning to deploy Genie 3 or similar world generation models should follow established best practices to ensure reliable, scalable, and responsible operation. These guidelines derive from early adopters' experiences and address common pitfalls encountered during initial deployments. Successful implementation requires attention to technical, operational, and ethical considerations throughout the deployment lifecycle.
Comprehensive testing across diverse prompts and interaction patterns helps identify edge cases and failure modes before they impact users. Test suites should include boundary conditions like extremely long or short prompts, rapid interaction sequences, attempts to generate prohibited content, and sustained usage sessions approaching duration limits. Automated testing frameworks can continuously validate generation quality and catch regressions introduced by model updates.
Monitoring and observability infrastructure proves essential for maintaining service quality and identifying issues quickly. Key metrics include generation latency percentiles, frame rate consistency, memory usage patterns, prompt rejection rates, and user session durations. Advanced deployments implement anomaly detection to automatically identify unusual patterns that might indicate technical problems or misuse attempts.
python# Production monitoring setup for world generation service
import prometheus_client
from datadog import statsd
import logging
import time
class WorldGenerationMonitor:
def __init__(self):
# Setup metrics collectors
self.generation_latency = prometheus_client.Histogram(
'world_gen_latency_seconds',
'Time to generate world frame',
buckets=[0.01, 0.025, 0.05, 0.1, 0.25, 0.5, 1.0]
)
self.active_sessions = prometheus_client.Gauge(
'active_world_sessions',
'Number of active generation sessions'
)
self.prompt_rejections = prometheus_client.Counter(
'prompt_rejections_total',
'Total number of rejected prompts',
['rejection_reason']
)
self.session_duration = prometheus_client.Histogram(
'session_duration_seconds',
'Duration of generation sessions',
buckets=[30, 60, 120, 180, 300, 600]
)
self.logger = logging.getLogger(__name__)
def record_generation(self, prompt, duration, success=True):
"""Record metrics for a generation request"""
# Record latency
self.generation_latency.observe(duration)
statsd.histogram('world.generation.latency', duration)
if not success:
self.logger.warning(f"Generation failed for prompt: {prompt[:100]}")
statsd.increment('world.generation.failures')
# Check for performance degradation
if duration > 0.1: # 100ms threshold
self.logger.warning(f"Slow generation detected: {duration:.3f}s")
self.alert_ops_team('High generation latency detected')
def track_session(self, session_id, event_type, metadata=None):
"""Track session lifecycle events"""
if event_type == 'start':
self.active_sessions.inc()
self.logger.info(f"Session started: {session_id}")
elif event_type == 'end':
self.active_sessions.dec()
if metadata and 'duration' in metadata:
self.session_duration.observe(metadata['duration'])
elif event_type == 'error':
self.logger.error(f"Session error: {session_id}, {metadata}")
statsd.increment('world.session.errors')
Graceful degradation strategies ensure service availability even when resources become constrained. This might involve reducing generation quality during peak load, queueing requests with transparent wait time estimates, or offering alternative experiences when world generation is unavailable. Clear communication about service status and expected performance helps manage user expectations and maintain satisfaction even during degraded conditions.
Regular model updates and retraining incorporate new capabilities and address identified limitations. However, updates must be carefully validated to ensure they don't introduce regressions or break existing functionality. Blue-green deployment strategies allow safe rollout with quick rollback capabilities if issues emerge. For critical applications, maintaining multiple model versions enables users to choose stability over newest features.
Integration with Existing Development Pipelines
Incorporating world generation models into established development workflows requires thoughtful integration strategies that minimize disruption while maximizing value. Whether enhancing game development pipelines, augmenting architectural visualization tools, or creating novel educational experiences, successful integration depends on understanding both technical requirements and organizational dynamics.
API design plays a crucial role in integration success, with well-designed interfaces abstracting complexity while providing necessary control. RESTful APIs work well for simple generation requests, while WebSocket connections better suit real-time interactive sessions. GraphQL interfaces can efficiently handle complex queries about world state and enable precise data fetching. For maximum flexibility, many implementations provide multiple interface options.
Version control for generated worlds presents unique challenges since traditional text-based version control systems poorly handle binary world data. Solutions include storing generation parameters rather than output, implementing semantic diff tools for world structures, and creating specialized version control systems that understand world model outputs. These approaches enable collaborative workflows where multiple developers can iterate on world designs.
Continuous integration and deployment pipelines must accommodate the unique characteristics of AI model deployment including large model files, specialized hardware requirements, and non-deterministic outputs. Successful teams implement automated quality gates that validate generation quality, performance benchmarks that catch degradation, and rollback procedures that can quickly restore previous versions. For teams new to AI model deployment, managed platforms like laozhang.ai can simplify these operational challenges.
Economic Impact and Business Models
The emergence of powerful world generation models like Genie 3 creates new economic opportunities while disrupting existing business models in creative industries. Understanding these economic implications helps organizations position themselves advantageously as the technology matures and adoption accelerates throughout [August 2025] and beyond.
Cost reduction in content creation represents the most immediate economic impact, with potential savings of 60-80% in environment design costs for game development, architectural visualization, and film pre-production. These savings stem from dramatically reduced human labor requirements, though skilled artists remain essential for creative direction and quality control. Organizations that effectively blend AI generation with human creativity gain significant competitive advantages.
New business models emerge around world generation as a service, with companies offering specialized generation capabilities for specific industries or use cases. Subscription models provide predictable revenue streams while usage-based pricing enables small teams to access powerful capabilities without large upfront investments. Premium tiers might offer exclusive features like extended generation duration, priority processing, or custom model fine-tuning.
The democratization of 3D content creation enables individual creators and small teams to compete with larger studios in markets previously dominated by resource-intensive production requirements. This shift parallels earlier disruptions in music production and digital art, where accessible tools enabled new creators to reach audiences directly. World generation models could catalyze similar transformations in gaming, virtual reality, and interactive media.
Market sizing estimates suggest the world generation technology market could reach $5-10 billion by 2027, driven by adoption across gaming, simulation, education, and enterprise visualization applications. Early movers who establish strong positions in specific verticals or develop proprietary enhancements to base models stand to capture significant value as the market matures.
Advanced Technical Architecture: Under the Hood
The intricate technical architecture powering Genie 3 reveals sophisticated engineering decisions that enable its remarkable capabilities. The system employs a hierarchical transformer architecture with specialized attention mechanisms operating at multiple scales, from individual object tracking to global scene coherence. Each layer of the network serves distinct purposes, with early layers handling low-level visual features like edges and textures, middle layers managing object recognition and spatial relationships, and deeper layers maintaining temporal consistency and physics simulation.
The attention mechanism itself represents a significant innovation, utilizing a novel sparse attention pattern that dynamically allocates computational resources based on scene complexity and user focus. High-activity regions receiving direct user interaction receive full attention computation, while peripheral areas utilize compressed representations that maintain visual coherence with reduced computational overhead. This adaptive attention strategy enables the model to maintain real-time performance even when generating complex scenes with numerous interactive elements.
Memory management within Genie 3 employs a sophisticated caching system that maintains multiple temporal resolutions simultaneously. Short-term memory buffers store frame-by-frame changes for immediate consistency, medium-term memory tracks object states and positions over several seconds, and long-term memory preserves important world modifications throughout the entire session. This multi-scale temporal architecture ensures that painting a wall red in the first minute of interaction remains visible when returning to that location five minutes later.
The training process for Genie 3 involved unprecedented scale, utilizing over 200,000 hours of diverse video content spanning games, simulations, real-world footage, and synthetic datasets. The curriculum learning approach gradually increased complexity, starting with simple static scenes and progressively introducing movement, physics, and interaction. This structured training enabled the model to develop hierarchical understanding, building from basic visual perception to complex causal reasoning about world dynamics.
Comparative Analysis with Traditional Game Engines
Understanding how Genie 3 differs from traditional game engines like Unity or Unreal Engine illuminates both its revolutionary potential and current limitations. Traditional engines operate through explicit programming of every behavior, requiring developers to define physics rules, rendering pipelines, and interaction logic. Genie 3 inverts this paradigm by learning implicit representations that generate appropriate behaviors without explicit programming, offering fundamentally different tradeoffs in capability, flexibility, and control.
Traditional game engines excel at precise control and deterministic behavior, essential for competitive gaming or simulation applications requiring exact reproducibility. Every physics calculation follows predetermined equations, every visual effect results from specific shader programs, and every interaction triggers precisely defined responses. This predictability enables developers to craft specific experiences and guarantee consistent behavior across different hardware configurations and play sessions.
Genie 3's learned approach sacrifices precise control for unprecedented flexibility and ease of use. Developers can describe desired worlds in natural language rather than programming every detail, dramatically accelerating prototyping and ideation. The model's ability to interpolate between training examples enables generation of novel combinations never explicitly programmed, like "a underwater city with floating cars and bioluminescent architecture" that combines multiple learned concepts into coherent new experiences.
Performance characteristics differ markedly between approaches, with traditional engines achieving higher frame rates and resolution through decades of optimization for specific hardware architectures. Modern game engines can render 4K resolution at 120+ frames per second on high-end hardware, while Genie 3 currently targets 720p at 24 frames per second. However, Genie 3's performance remains relatively consistent regardless of scene complexity, while traditional engines experience significant performance variation based on polygon count, shader complexity, and physics calculations.
The development workflow implications extend beyond technical specifications to fundamentally alter how teams create interactive experiences. Traditional development requires specialized expertise in programming, 3D modeling, animation, and technical art, with large teams spending months or years creating detailed worlds. Genie 3 enables single individuals to generate diverse worlds in minutes through natural language descriptions, though achieving specific artistic visions remains challenging compared to traditional tools' precise control.
Detailed Implementation Patterns and Code Examples
Implementing production-ready systems using world generation models requires sophisticated architectural patterns that address reliability, scalability, and user experience concerns. The following detailed examples demonstrate practical approaches for common implementation challenges, derived from real-world deployments across gaming, simulation, and visualization applications.
Session management represents a critical component for maintaining user experience across extended interactions. The system must track user state, world modifications, and generation history while managing resource allocation and handling failures gracefully. Implementing robust session management requires careful consideration of state persistence, resource lifecycle, and error recovery strategies.
javascript// Comprehensive session management for world generation
class WorldGenerationSession {
constructor(sessionId, userId, config) {
this.sessionId = sessionId;
this.userId = userId;
this.config = config;
this.state = {
worldSeed: null,
modifications: [],
currentPosition: { x: 0, y: 0, z: 0 },
generatedChunks: new Map(),
interactionHistory: [],
performanceMetrics: {
framesGenerated: 0,
averageLatency: 0,
peakMemoryUsage: 0
}
};
this.resourceManager = new ResourceManager(config.resourceLimits);
this.stateStore = new PersistentStateStore(sessionId);
}
async initializeWorld(prompt, options = {}) {
try {
// Validate prompt for safety and feasibility
const validation = await this.validatePrompt(prompt);
if (!validation.safe) {
throw new Error(`Unsafe prompt: ${validation.reason}`);
}
// Generate initial world seed
this.state.worldSeed = await this.generateWorldSeed(prompt, options);
// Pre-generate initial visible chunks
const initialChunks = this.getVisibleChunks(this.state.currentPosition);
await this.preGenerateChunks(initialChunks);
// Initialize physics and interaction systems
await this.initializePhysics();
await this.initializeInteractionHandlers();
// Start background processes
this.startBackgroundGeneration();
this.startMemoryManagement();
this.startMetricsCollection();
// Persist initial state
await this.stateStore.save(this.state);
return {
success: true,
sessionId: this.sessionId,
worldSeed: this.state.worldSeed,
startPosition: this.state.currentPosition
};
} catch (error) {
await this.handleInitializationError(error);
throw error;
}
}
async processInteraction(interaction) {
const startTime = performance.now();
try {
// Validate interaction
if (!this.isValidInteraction(interaction)) {
return { success: false, error: 'Invalid interaction' };
}
// Check resource availability
if (!await this.resourceManager.canProcessInteraction()) {
return { success: false, error: 'Resource limit exceeded' };
}
// Process based on interaction type
let result;
switch (interaction.type) {
case 'movement':
result = await this.processMovement(interaction);
break;
case 'modification':
result = await this.processModification(interaction);
break;
case 'query':
result = await this.processQuery(interaction);
break;
default:
result = await this.processGenericInteraction(interaction);
}
// Update state and history
this.state.interactionHistory.push({
timestamp: Date.now(),
interaction,
result
});
// Update metrics
const latency = performance.now() - startTime;
this.updateMetrics({ latency });
// Persist state periodically
if (this.shouldPersistState()) {
await this.stateStore.save(this.state);
}
return result;
} catch (error) {
await this.handleInteractionError(error, interaction);
return { success: false, error: error.message };
}
}
async processMovement(interaction) {
const { direction, distance } = interaction.data;
// Calculate new position
const newPosition = this.calculateNewPosition(
this.state.currentPosition,
direction,
distance
);
// Check if new chunks need generation
const requiredChunks = this.getVisibleChunks(newPosition);
const missingChunks = requiredChunks.filter(
chunk => !this.state.generatedChunks.has(chunk.id)
);
// Generate missing chunks
if (missingChunks.length > 0) {
await this.generateChunks(missingChunks);
}
// Update position
this.state.currentPosition = newPosition;
// Return visible world data
return {
success: true,
position: newPosition,
visibleWorld: this.getVisibleWorldData(newPosition)
};
}
}
Optimization strategies for reducing latency and improving perceived performance require careful attention to predictive generation and intelligent caching. By anticipating user actions and pre-generating likely scenarios, systems can dramatically reduce apparent latency even when actual generation takes significant time. This predictive approach proves particularly effective for movement-based interactions where future positions can be estimated from current velocity and direction.
Quality adaptation based on system load and user engagement enables graceful degradation when resources become constrained. Rather than failing completely under heavy load, the system can temporarily reduce generation quality, limit interaction complexity, or queue non-critical requests. This adaptive behavior maintains service availability while communicating limitations transparently to users.
For organizations deploying world generation at scale, implementing proper load balancing across multiple generation nodes becomes essential. Modern orchestration platforms like Kubernetes provide the foundation, but world generation's unique characteristics require custom scheduling logic that considers model memory requirements, session affinity, and generation complexity when distributing work across available resources.
Ethical Considerations and Responsible AI Deployment
The deployment of powerful world generation technology raises important ethical questions that organizations must address proactively to ensure responsible use. The ability to create convincing virtual environments that users can inhabit for extended periods introduces novel considerations around consent, addiction potential, reality perception, and fair access. Establishing ethical frameworks before widespread deployment helps prevent harmful applications while maximizing beneficial uses.
Informed consent becomes complex when AI-generated worlds can adapt and respond in ways their creators didn't explicitly program. Users should understand that generated content emerges from learned patterns rather than human design, potentially producing unexpected or inappropriate content despite filtering efforts. Clear communication about the AI-driven nature of experiences, including limitations and potential risks, enables users to make informed decisions about engagement.
The addictive potential of unlimited novel content generation deserves serious consideration, particularly for vulnerable populations including children and individuals with addictive tendencies. Unlike traditional media with finite content, AI world generation can produce endless variations tailored to individual preferences, potentially creating compelling experiences that discourage real-world engagement. Responsible deployment includes usage monitoring, parental controls, and features that encourage healthy usage patterns.
Reality perception concerns emerge as generated worlds become increasingly convincing and immersive. Extended exposure to AI-generated environments where physics and causality differ from reality could impact users' real-world perception and decision-making. This risk increases for young users whose understanding of physical laws and social norms continues developing. Mitigation strategies include clear demarcation between generated and real content, periodic reality checks, and age-appropriate access controls.
Fair access to world generation technology raises questions about digital equity and opportunity. As these tools become important for education, training, and creative expression, ensuring broad availability prevents widening of digital divides. This includes addressing infrastructure requirements that may exclude users with limited internet connectivity or computational resources. Cloud-based solutions and progressive quality adaptation can help democratize access, though cost and availability challenges remain.
Performance Optimization Strategies
Achieving optimal performance from world generation systems requires systematic optimization across multiple dimensions including model architecture, infrastructure configuration, and application design. Performance improvements often come from unexpected sources, making comprehensive profiling and iterative optimization essential for production deployments. The following strategies, derived from real-world deployments, can significantly improve generation speed and quality.
Model quantization reduces memory requirements and increases inference speed by representing weights with lower precision. Converting from 32-bit floating-point to 8-bit integers can reduce model size by 75% while maintaining acceptable quality for many applications. However, quantization requires careful calibration to avoid quality degradation, particularly for physics simulation and fine detail generation where precision matters most.
python# Advanced performance optimization for world generation
import torch
import torch.quantization as quantization
from torch.nn.parallel import DistributedDataParallel
import numpy as np
from concurrent.futures import ThreadPoolExecutor
import asyncio
class OptimizedWorldGenerator:
def __init__(self, model_path, optimization_config):
self.config = optimization_config
self.device_map = self.setup_device_mapping()
self.model = self.load_optimized_model(model_path)
self.cache = self.initialize_cache()
self.predictor = self.setup_prediction_engine()
def load_optimized_model(self, model_path):
"""Load and optimize model for inference"""
# Load base model
model = torch.load(model_path, map_location='cpu')
# Apply quantization if enabled
if self.config.use_quantization:
model = self.quantize_model(model)
# Setup model parallelism for large models
if self.config.use_model_parallel:
model = self.setup_model_parallelism(model)
# Compile with TorchScript for faster inference
if self.config.use_torchscript:
model = torch.jit.script(model)
# Move to appropriate devices
model = self.distribute_model(model)
# Enable inference optimizations
model.eval()
torch.set_grad_enabled(False)
return model
def quantize_model(self, model):
"""Apply INT8 quantization for faster inference"""
# Prepare model for quantization
model.qconfig = quantization.get_default_qconfig('fbgemm')
quantization.prepare(model, inplace=True)
# Calibrate with representative data
calibration_data = self.load_calibration_data()
with torch.no_grad():
for batch in calibration_data:
model(batch)
# Convert to quantized model
quantization.convert(model, inplace=True)
return model
def setup_model_parallelism(self, model):
"""Distribute model across multiple GPUs"""
# Split model into stages
stages = self.split_model_stages(model)
# Assign stages to devices
device_assignments = self.calculate_device_assignments(stages)
# Create pipeline parallel model
from torch.distributed.pipeline.sync import Pipe
parallel_model = Pipe(
model,
balance=device_assignments,
devices=self.device_map,
chunks=self.config.pipeline_chunks
)
return parallel_model
async def generate_with_prediction(self, prompt, interaction_history):
"""Generate world with predictive pre-generation"""
# Predict likely future interactions
predictions = await self.predictor.predict_next_actions(
interaction_history,
num_predictions=self.config.prediction_branches
)
# Start pre-generation for predicted paths
pre_generation_tasks = []
for prediction in predictions:
task = asyncio.create_task(
self.pre_generate_branch(prompt, prediction)
)
pre_generation_tasks.append(task)
# Generate current frame
current_frame = await self.generate_frame(prompt)
# Store pre-generated results
for task in pre_generation_tasks:
branch_result = await task
self.cache.store_predictive(branch_result)
return current_frame
def optimize_memory_usage(self):
"""Implement memory optimization strategies"""
# Enable gradient checkpointing for training
if self.model.training:
self.model.gradient_checkpointing_enable()
# Use mixed precision for inference
with torch.cuda.amp.autocast():
# Clear cache periodically
if self.should_clear_cache():
torch.cuda.empty_cache()
# Offload unused layers to CPU
self.offload_inactive_layers()
# Compress cached states
self.compress_cache_entries()
Infrastructure optimization through proper hardware selection and configuration significantly impacts performance. TPUs excel at the matrix operations central to transformer models, while modern GPUs like NVIDIA H100 offer superior flexibility and broader software support. The choice between hardware options depends on specific requirements including batch size, latency targets, and cost constraints. Hybrid configurations utilizing both TPUs and GPUs can optimize cost-performance for varying workload characteristics.
Application-level optimizations often provide the most significant performance improvements for end-user experience. Implementing progressive rendering where low-resolution previews appear immediately while full quality generates in background dramatically improves perceived responsiveness. Similarly, predictive pre-fetching based on user behavior patterns can eliminate most visible loading delays, creating seamless exploration experiences despite underlying generation latency.
Conclusion: The Dawn of Interactive AI Worlds
Genie 3 represents more than an incremental advance in AI capabilities; it signals a fundamental shift in how we create and interact with virtual environments. The ability to generate coherent, interactive worlds in real-time from simple text descriptions democratizes 3D content creation while opening entirely new categories of applications. As we stand at this technological inflection point in [August 2025], the implications extend far beyond immediate use cases to reshape our understanding of artificial intelligence's role in creative and productive endeavors.
The journey from static image generation to dynamic world creation mirrors the broader evolution of AI from pattern recognition to genuine understanding and creation. Genie 3's emergent physics understanding, object permanence, and causal reasoning demonstrate that sufficient scale and appropriate architecture can produce capabilities that transcend their training data. These achievements provide valuable insights for the continued pursuit of artificial general intelligence.
For developers and organizations evaluating world generation technology, the current moment offers unique opportunities to establish leadership positions in emerging markets. While challenges remain around duration, consistency, and resource requirements, the trajectory of improvement suggests these limitations will progressively diminish. Teams that begin experimenting now, whether through direct DeepMind partnerships or accessible platforms like laozhang.ai, position themselves to capitalize as the technology matures.
The societal implications of unlimited world generation deserve careful consideration as adoption accelerates. Questions around content authenticity, digital addiction, and the value of human creativity require ongoing dialogue between technologists, ethicists, and policymakers. Responsible development and deployment practices established now will shape the technology's impact for years to come.
Looking ahead, the convergence of world models with other AI capabilities promises even more transformative applications. Integration with large language models enables natural language control of complex simulations. Combination with robotics provides unlimited training environments for autonomous systems. Fusion with augmented reality could overlay generated worlds onto physical spaces. These possibilities, once confined to science fiction, now appear achievable within the next few years.
As we witness the emergence of AI systems capable of generating entire interactive worlds, we stand at the threshold of a new era in human-computer interaction. Genie 3 and its successors will likely be remembered as pivotal technologies that transformed not just how we create virtual worlds, but how we think about the relationship between imagination and reality, between human creativity and machine generation, and ultimately, between natural and artificial intelligence.