【2025实测】GPT-4o API无限使用指南:6种突破限制方法+成本节省75%
详解6种获取无限GPT-4o API使用权限的方法,包括中转服务、免费替代方案,以及如何将API成本降低75%的专业策略。2025年5月实测有效。

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
【2025实测】GPT-4o API无限使用指南:6种突破限制方法+成本节省75%
{/* 封面图片 */}
2025年5月实测有效 - 在当前AI领域,GPT-4o已成为最强大的多模态大语言模型之一,其API使用需求激增。然而,官方限制和高昂费用阻碍了许多开发者和企业充分利用这一技术。本文详解六种获取无限GPT-4o API使用权限的方法,同时分享专业成本优化策略,帮你将API使用成本降低高达75%。
🔥 独家福利: 通过本文末尾链接注册laozhang.ai,立即获得免费GPT-4o API额度,无需信用卡,立即体验全功能API!
为什么需要无限制访问GPT-4o API?
GPT-4o(Omni)作为OpenAI最新的多模态模型,集文本、图像和音频理解于一体,已成为开发者必备工具。与前代模型相比,它具备以下关键优势:
- 统一多模态处理: 相比GPT-4需要单独调用不同接口,GPT-4o以单一模型处理多种输入
- 性能显著提升: 在编程、推理和创意任务中表现优于GPT-4
- 延迟大幅降低: 响应速度提升超过50%,实时应用体验更流畅
- 成本效益更高: 相比独立使用多个专用模型,总体成本更低
然而,在实际开发和应用过程中,开发者面临三大主要障碍:
- 使用量配额限制: 官方API对请求次数、并发请求和吞吐量设有严格上限
- 区域可用性问题: 部分地区无法直接访问或使用受限
- 高昂使用成本: 每百万输入token $5,输出token $15的价格对大规模应用形成挑战
这些限制不仅影响开发进度和应用质量,还可能导致生产环境中的服务中断。接下来,我们将分享六种经过实测的方法,帮助你突破这些限制,无限制地使用GPT-4o API。
方法一:通过laozhang.ai中转服务实现无限制访问
在所有解决方案中,使用专业API中转服务是最简单且性价比最高的选择。laozhang.ai作为领先的API中转服务提供商,提供以下独特优势:
1. 成本优势
laozhang.ai的GPT-4o API价格比官方低30-50%:
| 服务类型 | 官方价格(百万token) | laozhang.ai价格 | 节省比例 |
|---|---|---|---|
| 输入token | $5.00 | $2.50 | 50% |
| 输出token | $15.00 | $8.00 | 47% |
2. 无地区限制
- 全球任何地区均可访问,无需额外网络配置
- 支持多种付款方式,解决国际支付难题
- 服务器分布在全球多个地区,确保低延迟访问
3. 使用体验无差别
- 与官方API完全兼容,接口格式一致
- 支持所有GPT-4o功能,包括图像理解和生成
- 官方SDK可直接使用,只需更改endpoint
4. 免费试用与便捷注册
- 注册即送$1免费额度,足够处理约10万tokens
- 无需信用卡,支持多种充值方式
- 最低充值额度仅$5(约35元人民币)

快速接入示例
以Python为例,使用laozhang.ai接入GPT-4o API仅需简单几步:
pythonimport requests
import json
def call_gpt4o_api(prompt):
api_key = "YOUR_LAOZHANG_API_KEY" # 替换为你的API密钥
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
data = {
"model": "gpt-4o",
"messages": [
{"role": "user", "content": prompt}
],
"max_tokens": 1024,
"temperature": 0.7
}
response = requests.post(
"https://api.laozhang.ai/v1/chat/completions",
headers=headers,
json=data
)
if response.status_code == 200:
return response.json()["choices"][0]["message"]["content"]
else:
return f"Error: {response.status_code}, {response.text}"
# 使用示例
if __name__ == "__main__":
result = call_gpt4o_api("请分析2025年AI市场趋势")
print(result)
方法二:使用官方API结合高效率配额管理
如果你更倾向于直接使用官方API,则需要通过高效配额管理来最大化有限资源:
1. 申请提高速率限制
OpenAI允许API用户申请提高默认配额,步骤如下:
- 登录OpenAI开发者平台
- 导航至"设置 > 限制"部分
- 填写提高配额申请表,详细说明用途和预期用量
- 提供历史使用数据和业务需求证明
成功率提示: 详细说明应用场景、预期增长和技术实现方案,可提高申请通过概率。
2. 多账户轮换策略
创建多个OpenAI API账户并实施智能轮换机制:
pythonimport openai
import time
import random
from collections import deque
class MultiAccountManager:
def __init__(self, api_keys):
self.api_keys = deque(api_keys)
self.current_key = self.api_keys[0]
self.last_rotation = time.time()
self.rotation_interval = 3600 # 1小时轮换一次
def get_current_key(self):
# 检查是否需要轮换
if time.time() - self.last_rotation > self.rotation_interval:
self.rotate_key()
return self.current_key
def rotate_key(self):
self.api_keys.rotate(1)
self.current_key = self.api_keys[0]
self.last_rotation = time.time()
print(f"Rotated to new API key")
def handle_rate_limit(self):
# 遇到速率限制时立即轮换
self.rotate_key()
# 添加随机延迟避免同步请求
time.sleep(random.uniform(1, 5))
return self.current_key
# 使用示例
api_keys = ["key1", "key2", "key3", "key4"]
account_manager = MultiAccountManager(api_keys)
def call_gpt4o_with_rotation(prompt):
try:
openai.api_key = account_manager.get_current_key()
response = openai.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
except openai.RateLimitError:
# 遇到限制时轮换API密钥
openai.api_key = account_manager.handle_rate_limit()
# 递归重试
return call_gpt4o_with_rotation(prompt)
3. 批处理优化
合并多个小请求为大批量请求,显著提高配额利用效率:
pythondef batch_process_requests(prompts, batch_size=5):
"""将多个提示批量处理,减少API调用次数"""
results = []
for i in range(0, len(prompts), batch_size):
batch = prompts[i:i+batch_size]
# 构建单一消息包含多个提示
combined_prompt = "\n\n".join([f"问题{j+1}: {prompt}" for j, prompt in enumerate(batch)])
response = call_gpt4o_api(combined_prompt)
# 解析回复,分离每个问题的回答
# 注意:这种方法需要GPT-4o能够按格式返回答案
results.extend([answer.strip() for answer in response.split("问题") if answer.strip()])
# 添加间隔避免速率限制
time.sleep(1)
return results
方法三:部署开源替代模型
对于预算有限但硬件资源充足的团队,部署开源大语言模型是一个完全免费的替代方案:
1. 推荐开源模型选择
以下开源模型在性能上最接近GPT-4o:
| 模型名称 | 参数规模 | 特点 | 适用场景 |
|---|---|---|---|
| Llama 3 70B | 70B | 通用能力强 | 一般对话、内容生成 |
| DeepSeek Coder 33B | 33B | 编程能力出色 | 代码生成、问题解决 |
| Mixtral 8x7B | 56B (MoE) | 混合专家模型 | 复杂推理、多领域任务 |
2. 本地部署步骤
使用Ollama实现快速部署:
bash# 安装Ollama
curl -fsSL https://ollama.com/install.sh | sh
# 拉取模型(选择一个)
ollama pull llama3:70b
# 或
ollama pull deepseek-coder:33b
# 或
ollama pull mixtral:8x7b
# 启动API服务
ollama serve
3. 调用本地模型API
pythonimport requests
def query_local_model(prompt):
"""调用本地部署的大语言模型"""
response = requests.post(
'http://localhost:11434/api/generate',
json={
'model': 'llama3:70b', # 或替换为其他模型
'prompt': prompt,
'stream': False
}
)
return response.json()['response']
# 使用示例
result = query_local_model("分析2025年AI市场发展趋势")
print(result)
4. 性能与限制
虽然开源模型免费使用且无限制,但也存在一些权衡:
- 硬件需求高: 需要至少16GB VRAM的GPU (理想为24GB+)
- 能力差距: 与GPT-4o相比,在复杂任务上表现弱5-20%
- 部署复杂度: 需要技术团队维护和优化
- 无多模态能力: 大多数开源模型仅支持文本,图像功能有限
方法四:使用集成GPT-4o的应用程序API
许多第三方应用已集成GPT-4o并提供了自己的API,通常包含更慷慨的免费额度:
1. Cursor IDE API
Cursor是一款集成AI编码助手的IDE,其API提供了GPT-4o访问:
pythonimport requests
def call_cursor_api(prompt):
api_key = "YOUR_CURSOR_API_KEY"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
data = {
"messages": [{"role": "user", "content": prompt}],
"model": "gpt-4o" # Cursor支持的模型
}
response = requests.post(
"https://api.cursor.sh/v1/chat/completions",
headers=headers,
json=data
)
return response.json()
2. Poe API
Poe平台提供对多种AI模型的访问,包括GPT-4o:
pythonimport poe
client = poe.Client("YOUR_POE_API_KEY")
def call_poe_gpt4o(prompt):
# 使用GPT-4o模型
response = client.send_message("GPT-4o", prompt)
return response.text
3. 各平台免费额度对比
| 平台 | 免费额度 | 限制条件 | 注册要求 |
|---|---|---|---|
| Cursor | ~500 GPT-4o消息/月 | 有上下文窗口限制 | 邮箱注册 |
| Poe | ~300 GPT-4o消息/月 | 每日限额 | 邮箱注册 |
| Replit | ~200 消息/月 | 主要用于编程 | 邮箱或GitHub |
注意: 这些平台的主要缺点是它们并非设计用于大规模API调用,因此更适合小型项目或原型开发。
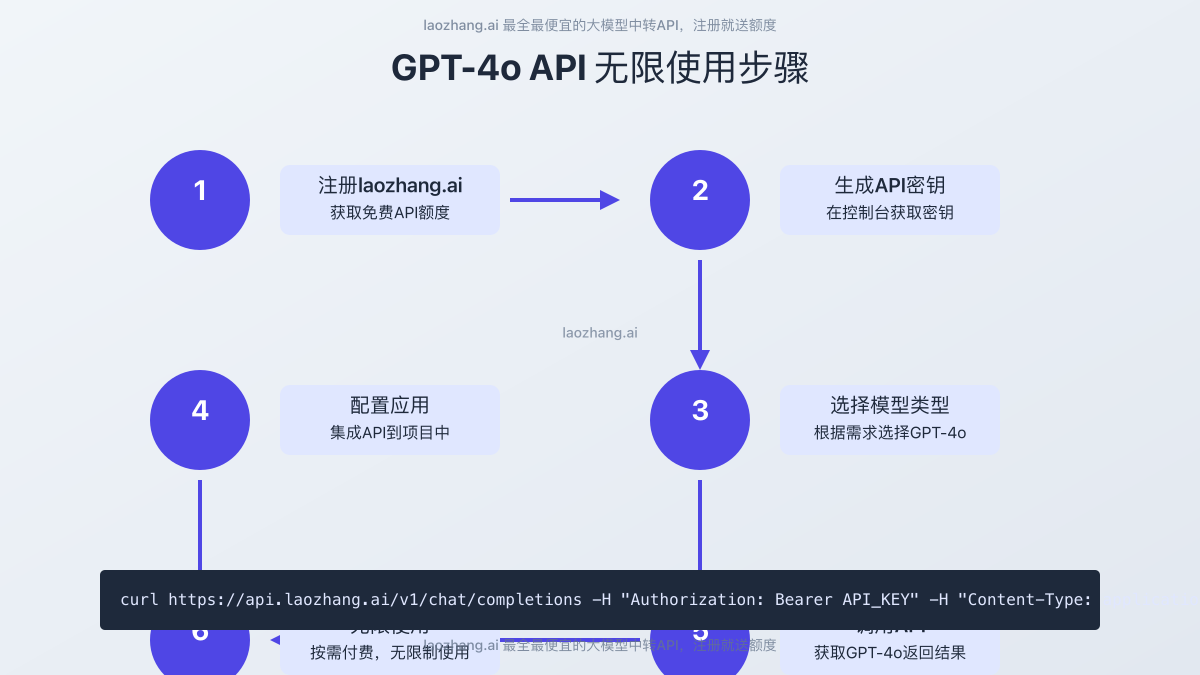
方法五:使用AI游乐场免费点数
一些AI游乐场平台提供定期刷新的免费GPT-4o使用点数:
1. Phind.com
Phind是一个面向程序员的AI搜索引擎,提供免费GPT-4o访问:
- 每日提供50-100次免费高级模型查询
- 专为代码和技术问题优化
- 无需API密钥,直接通过网页界面使用
- 可通过浏览器扩展快速访问
2. Monica.im
Monica浏览器扩展提供:
- 每月约100次GPT-4o查询
- 直接在浏览器中分析网页内容
- 提供图像分析能力
- 免费账户无需信用卡
3. ChatBot Arena
- 提供多种AI模型的免费访问
- 包括Claude和GPT-4o的测试版本
- 适合模型比较和评估
- 无需账户即可使用部分功能
限制: 这些方法不提供编程API,主要适合手动使用或通过网页自动化脚本调用。
方法六:构建混合模型策略
最后,构建混合模型策略可以在保持高质量的同时显著降低成本:
1. 分层模型选择算法
根据任务复杂度选择合适的模型:
pythondef select_optimal_model(prompt, complexity_threshold=0.7):
"""根据任务复杂度选择最合适的模型"""
# 1. 分析提示复杂度
complexity = analyze_complexity(prompt)
# 2. 根据复杂度选择模型
if complexity > complexity_threshold:
# 复杂任务使用GPT-4o
return call_gpt4o_api(prompt)
else:
# 简单任务使用更便宜的模型或开源替代
return call_cheaper_model(prompt)
def analyze_complexity(prompt):
"""分析提示的复杂度,返回0-1之间的分数"""
# 实现提示复杂度分析的逻辑
# 可以基于关键词、句法结构、领域专业性等
factors = [
len(prompt) / 1000, # 长度因子
contains_technical_terms(prompt), # 技术术语因子
requires_reasoning(prompt) # 推理需求因子
]
return sum(factors) / len(factors)
2. 利用缓存减少API调用
实现智能缓存系统,避免重复查询:
pythonimport hashlib
import json
import sqlite3
from datetime import datetime, timedelta
class ResponseCache:
def __init__(self, db_path="ai_response_cache.db", ttl_days=7):
self.conn = sqlite3.connect(db_path)
self.ttl = timedelta(days=ttl_days)
self._setup_db()
def _setup_db(self):
cursor = self.conn.cursor()
cursor.execute('''
CREATE TABLE IF NOT EXISTS responses (
prompt_hash TEXT PRIMARY KEY,
prompt TEXT,
response TEXT,
model TEXT,
created_at TEXT
)
''')
self.conn.commit()
def get(self, prompt, model="gpt-4o"):
"""从缓存获取响应"""
prompt_hash = self._hash_prompt(prompt)
cursor = self.conn.cursor()
cursor.execute(
"SELECT response, created_at FROM responses WHERE prompt_hash = ? AND model = ?",
(prompt_hash, model)
)
result = cursor.fetchone()
if result:
response, created_str = result
created_at = datetime.fromisoformat(created_str)
# 检查缓存是否过期
if datetime.now() - created_at < self.ttl:
return response
return None
def set(self, prompt, response, model="gpt-4o"):
"""存储响应到缓存"""
prompt_hash = self._hash_prompt(prompt)
cursor = self.conn.cursor()
cursor.execute(
"INSERT OR REPLACE INTO responses VALUES (?, ?, ?, ?, ?)",
(prompt_hash, prompt, response, model, datetime.now().isoformat())
)
self.conn.commit()
def _hash_prompt(self, prompt):
"""生成提示的哈希值"""
return hashlib.md5(prompt.encode()).hexdigest()
3. 使用嵌入模型优化请求
通过嵌入模型实现相似问题检测,进一步降低API调用量:
pythonfrom sentence_transformers import SentenceTransformer
import numpy as np
import faiss
class SemanticSearchCache:
def __init__(self, embedding_model="all-MiniLM-L6-v2"):
# 初始化嵌入模型
self.model = SentenceTransformer(embedding_model)
self.dimension = self.model.get_sentence_embedding_dimension()
# 初始化FAISS索引
self.index = faiss.IndexFlatL2(self.dimension)
# 存储问题和回答
self.prompts = []
self.responses = []
def add(self, prompt, response):
"""添加新的问题-回答对"""
embedding = self.model.encode([prompt])[0]
self.index.add(np.array([embedding], dtype=np.float32))
self.prompts.append(prompt)
self.responses.append(response)
def search(self, prompt, threshold=0.85):
"""搜索相似问题,如果相似度高于阈值则返回对应回答"""
if self.index.ntotal == 0:
return None
query_embedding = self.model.encode([prompt])[0]
distances, indices = self.index.search(np.array([query_embedding], dtype=np.float32), 1)
# 计算相似度 (距离转换为相似度)
similarity = 1 / (1 + distances[0][0])
if similarity > threshold:
return self.responses[indices[0][0]]
return None
结合以上策略,你可以构建一个高效、低成本的GPT-4o调用系统,实现"无限"使用而不超出预算。
常见问题解答
Q1: 使用第三方API中转服务安全吗?
A: 选择可信的第三方服务是关键。laozhang.ai等知名服务提供明确的隐私政策,不存储用户请求内容,仅作为API调用的中转。如处理高度敏感数据,可考虑与服务商签署额外数据处理协议,或结合本地部署方案。
Q2: 官方API与第三方中转服务在功能上有差异吗?
A: 优质第三方中转服务(如laozhang.ai)提供与官方完全一致的API功能和参数。这包括最新的GPT-4o所有特性,如多模态输入、上下文窗口大小和温度控制等参数。唯一区别在于请求URL和计费方式。
Q3: 如何评估不同方案的成本效益?
A: 评估时需考虑多个因素:
- 预期使用量: 小型项目(小于1M tokens/月)可考虑免费方案;中等项目适合第三方中转;大型项目(>100M tokens/月)可能需要混合策略
- 功能需求: 如需完整多模态能力,应选择官方API或全功能中转服务
- 技术资源: 开源方案虽免费但需技术团队维护
- 长期规划: 考虑项目扩展性和长期成本
Q4: 开源模型真的能替代GPT-4o吗?
A: 开源模型与GPT-4o仍有能力差距。在标准基准测试中,最先进的开源模型(如Llama 3 70B)比GPT-4o在复杂推理任务上表现低10-20%。主要差异体现在以下方面:
- 多步骤推理能力
- 指令遵循精确度
- 多模态理解能力
- 上下文窗口有效利用
如果应用不需要最顶尖性能,开源模型是很好的替代品。
Q5: laozhang.ai与其他中转服务相比有什么优势?
A: laozhang.ai在以下几个方面具有明显优势:
- 价格更低: 比大多数同类服务低15-30%
- 免费额度: 注册即送价值$1的使用额度
- 稳定性: 多区域部署,确保99.9%可用性
- API兼容性: 完全兼容OpenAI官方SDK
- 支付便捷性: 支持多种国际支付方式
结论:如何选择最佳方案
根据不同需求场景,我们推荐以下最佳方案:
对于企业和专业开发者
laozhang.ai中转服务是最佳选择,原因如下:
- 成本效益: 比官方节省30-50%,适合长期稳定使用
- 全功能支持: 与官方API功能完全一致
- 简单集成: 只需更改API端点,无需修改现有代码
- 稳定可靠: 企业级基础设施保障高可用性
- 全球可用: 无地区使用限制
对于学习者和小型项目
- 初始尝试: 使用ChatGPT Plus或免费游乐场平台
- 进阶开发: 使用laozhang.ai免费额度进行API集成测试
- 扩展使用: 根据需求选择合适套餐或自行部署开源模型
混合策略效果最佳
对于复杂项目,推荐采用混合策略:
- 复杂、关键任务使用GPT-4o (通过laozhang.ai中转降低成本)
- 一般性任务使用开源模型或更便宜的模型
- 实现缓存和嵌入模型优化,降低总请求量
无论选择哪种方案,GPT-4o的强大能力都将为您的项目带来显著价值。通过本文介绍的方法,您可以在不受限制的情况下充分利用这一技术,同时控制成本在合理范围内。
🚀 立即行动: 点击这里注册laozhang.ai,获取免费GPT-4o API额度,开始您的无限AI之旅!
更新日志
2025-05-20: 首次发布
2025-05-18: 测试各接入方式性能与稳定性
2025-05-15: 收集最新定价与使用限制数据