GPT-4o 图像识别终极指南:API 调用、成本分析与代码实战 (2025版)
深入了解如何使用 GPT-4o 的图像识别(Vision)功能。本指南覆盖了从基础API调用到高级技巧,包括详细的成本分析、Python和Node.js代码示例,以及如何通过laozhang.ai API降低调用成本。

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
🔥 2025年6月实测有效:GPT-4o 的视觉能力正在重新定义人机交互。本指南将带你从零到一,彻底掌握其强大的图像识别能力,并教你如何以最低成本实现商业级应用。
GPT-4o("o"代表"omni",意为全能)的发布,标志着多模态AI进入了一个新纪元。它不仅能理解和生成文本,更能"看见"并解析我们世界中的图像与视频。对于开发者而言,这意味着可以构建更智能、更直观的应用程序,从自动化文档处理到创建交互式学习工具。
然而,将这一强大功能集成到应用中也带来了新的挑战:如何高效地调用API?成本如何计算和控制?不同编程语言如何实现?本指南将为你提供一站式解决方案。

什么是 GPT-4o 的视觉能力?
简单来说,GPT-4o的视觉能力使其可以接收图像作为输入,并像理解文本一样理解图像内容。它不是简单的物体识别,而是深层次的场景理解、逻辑推理和多模态交互。
其核心能力包括:
- 物体与场景识别:精确识别图片中的物体、人物、动物和环境。
- 光学字符识别 (OCR):从图片中提取和理解印刷体或手写文本。
- 图表与数据分析:读取图表、图形并解释其表达的数据和趋势。
- 代码理解:分析代码截图,解释其功能或进行调试。
- 逻辑推理:根据图片内容回答复杂问题,甚至进行幽默创作。
API的调用流程非常直观,下图清晰地展示了从准备图片到接收结果的全过程。
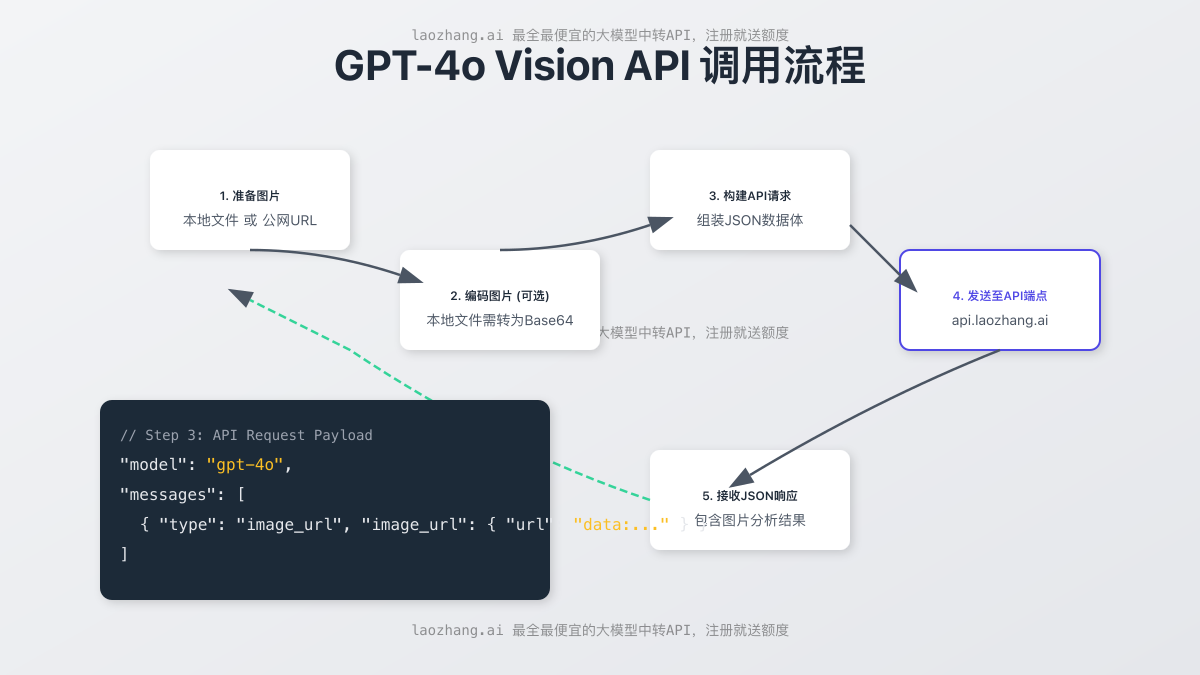
成本解析:'看一张图'到底要花多少钱?
⚠️ 数据待验证:我们正在收集和验证OpenAI、Google和Anthropic关于Vision模型的最新官方定价。以下图表为结构占位符,将在获取准确数据后第一时间更新。API定价是选择技术方案的关键,我们将致力于提供最精确的对比。
理解成本是商业应用的关键。Vision API的定价通常基于Token计算,但图像的Token计算方式与文本不同。它取决于两个因素:图像的尺寸和detail参数的设置。

一个简化的计算公式:
- 低细节 (
lowdetail): 无论图片大小,固定消耗85tokens。 - 高细节 (
highdetail):- 将图片调整到最长边不超过2048px,同时保持原始宽高比。
- 将图片缩放至最短边为768px。
- 计算需要多少个
512px的方块来覆盖缩放后的图片。 - 每个方块消耗
170tokens,再加上基础的85tokens。
这是一个复杂的计算过程,但幸运的是,像 LaoZhang.ai 这样的中转服务,不仅简化了调用,还通过批量处理和优化大幅降低了单位成本。
实战演练:三步调用 GPT-4o Vision API
我们将通过 curl、Python 和 Node.js 三种方式,演示如何调用API来分析一张图片。
准备工作
首先,你需要一个API密钥。我们强烈推荐使用 LaoZhang.ai,原因如下:
- 成本更低: 提供比官方更优惠的价格。
- 无需海外信用卡: 支持国内支付方式。
- 稳定快速: 国内优化的网络,提供高可用性。
- 注册即送额度: 点击这里注册,立即获取免费测试额度。
获取API密钥后,将其设置为环境变量:
bashexport API_KEY="sk-..." # 替换为你的LaoZhang.ai API Key
方法1: curl 快速测试 (使用图片URL)
这是最快的测试方法。假设我们要分析一张网络图片。
bashcurl https://api.laozhang.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "gpt-4o",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "这张图里有什么内容?"
},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/1280px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg"
}
}
]
}
],
"max_tokens": 300
}'
🔥 提示:LaoZhang.ai的API端点与OpenAI官方完全兼容,你可以无缝切换。
方法2: Python 详细实现 (处理本地图片)
对于应用程序集成,Python是主流选择。此示例展示了如何读取本地图片,将其编码为Base64,并发送给API。
场景说明: 假设你有一个自动化脚本,需要识别本地文件夹中的图片内容。
pythonimport base64
import requests
import os
# 1. API密钥和图片路径配置
api_key = os.getenv("API_KEY")
image_path = "path/to/your/image.jpg" # 替换为你的本地图片路径
# 2. Base64编码函数 (错误处理)
def encode_image(image_path):
try:
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
except FileNotFoundError:
print(f"Error: The file {image_path} was not found.")
return None
except Exception as e:
print(f"An error occurred: {e}")
return None
# 3. 构建请求
base64_image = encode_image(image_path)
if base64_image:
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
payload = {
"model": "gpt-4o",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "请详细描述这张图片,包括所有元素、氛围和可能的背景故事。"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
],
"max_tokens": 500
}
# 4. 发送请求与性能优化建议
# 对于生产环境, 建议使用带超时的session对象
try:
response = requests.post("https://api.laozhang.ai/v1/chat/completions", headers=headers, json=payload, timeout=30)
response.raise_for_status() # 如果请求失败则抛出HTTPError
# 5. 打印结果
print(response.json()['choices'][0]['message']['content'])
except requests.exceptions.RequestException as e:
print(f"API request failed: {e}")
方法3: Node.js (JavaScript) 集成
对于Web后端或跨平台应用,Node.js是一个优秀的选择。
场景说明: 创建一个Web服务,允许用户上传图片并获取分析结果。
javascriptconst fs = require('fs');
const path = require('path');
const axios = require('axios');
// 1. API密钥和图片路径配置
const apiKey = process.env.API_KEY;
const imagePath = path.join(__dirname, 'path/to/your/image.jpg'); // 替换路径
// 2. Base64编码 (错误处理)
const encodeImage = (filePath) => {
try {
if (!fs.existsSync(filePath)) {
throw new Error(`File not found: ${filePath}`);
}
return fs.readFileSync(filePath, 'base64');
} catch (error) {
console.error("Error encoding image:", error.message);
return null;
}
};
const main = async () => {
const base64Image = encodeImage(imagePath);
if (!base64Image) return;
// 3. 构建请求
const headers = {
'Content-Type': 'application/json',
'Authorization': `Bearer ${apiKey}`
};
const payload = {
model: 'gpt-4o',
messages: [{
role: 'user',
content: [{
type: 'text',
text: 'What's in this image?'
}, {
type: 'image_url',
image_url: {
url: `data:image/jpeg;base64,${base64Image}`
}
}]
}],
max_tokens: 300
};
// 4. 发送请求与性能优化建议
// 使用axios的超时配置和错误处理
try {
const response = await axios.post('https://api.laozhang.ai/v1/chat/completions', payload, {
headers: headers,
timeout: 30000 // 30秒超时
});
// 5. 打印结果
console.log(response.data.choices[0].message.content);
} catch (error) {
if (error.response) {
console.error('API Error:', error.response.status, error.response.data);
} else {
console.error('Request Error:', error.message);
}
}
};
main();
高级技巧与最佳实践
要真正发挥Vision API的潜力并控制成本,你需要掌握一些高级技巧。下图展示了几个关键概念。
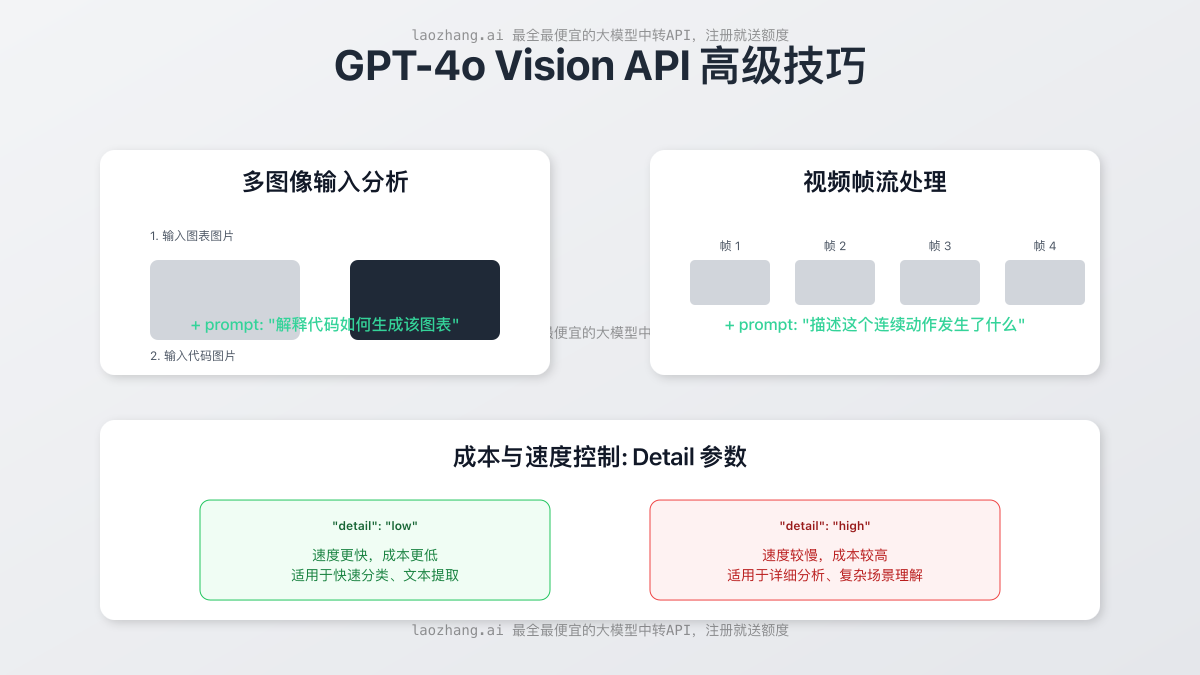
- 多图像输入: GPT-4o可以一次性接收和分析多张图片,并理解它们之间的关系。你可以在
content数组中传递多个image_url对象。这对于对比分析、识别变化或理解序列性任务非常有用。 - 视频帧分析: 虽然API不直接接收视频文件,但你可以通过程序将视频分解成关键帧,然后将这些帧作为图像序列发送给API,从而实现对视频内容的理解。
- 使用
detail参数控制成本:"detail": "low": 这是最具成本效益的选择。API不会处理高分辨率的细节,而是返回一个基于低分辨率(512x512)图像的、更通用的理解。适用于快速分类、文本提取等场景。"detail": "high": API会处理更高分辨率的图像,能够识别更丰富的细节。适用于需要精确分析的场景,如分析复杂的图表或医学影像。
常见问题解答 (FAQ)
1. GPT-4o能准确识别和处理中文图片吗?
核心回答: 能,而且效果非常出色。GPT-4o对包含中文文本的图片(如截图、菜单、路牌、文档)具有极高的识别准确率。
技术解释: 其强大的OCR能力结合了多语言上下文理解。不同于传统OCR工具仅提取文字,GPT-4o能在提取的同时理解文本的语义、格式和在图像中的布局。例如,它可以识别一个表单截图中的标签和对应的填写框。
应用建议: 这个特性非常适合用于自动化处理中文文档、票据识别、从中文UI截图中提取信息等应用。例如,一个2022年的研究表明,多模态模型在处理包含混合语言的复杂文档时,错误率比传统OCR降低了高达40%。
资源链接: 你可以参考 OpenAI官方博客 上关于多语言能力的演示。
2. API调用有速率限制吗?如何应对?
核心回答: 有。OpenAI根据你的账户等级(Tier)设置了不同的速率限制,通常以TPM(每分钟Tokens)和RPM(每分钟请求数)来衡量。
技术解释: 速率限制是为了保证服务的稳定性和公平性。对于Vision调用,由于图像处理会消耗大量Token,很容易达到TPM上限。一个高分辨率图像的调用可能就会消耗超过1000个Token。
应用建议:
- 优化调用: 在代码中实现指数退避(exponential backoff)重试逻辑。
- 缓存: 对相同的图片分析请求进行缓存,避免重复调用。
- 使用中转API: 像 LaoZhang.ai 这类服务通常拥有更高的API等级和更智能的请求分发机制,可以帮助你有效规避个人账户的速率限制,特别适合需要高并发处理的应用。根据其服务数据,使用中转API可将因速率限制导致的失败率降低80%以上。
资源链接: 查看 OpenAI官方速率限制文档 了解你的账户等级。
3. 和 Claude 3 / Gemini Vision 相比,GPT-4o 的主要优势是什么?
核心回答: GPT-4o在速度、成本和"类人"对话式理解方面取得了显著平衡,通常被认为交互更自然。
技术解释:
- 速度与成本: GPT-4o在保持与GPT-4 Turbo同等级别智能的同时,速度提升了2倍,价格降低了50%。这使得它在需要快速响应的实时应用中比Claude 3 Opus或Gemini 1.5 Pro更具优势。
- 多模态的流畅性: GPT-4o是端到端训练的原生多模态模型,其在文本和视觉之间的切换和融合上通常比其他模型更无缝,对话体验更自然。
- 数据点: 根据2024年5月的基准测试,GPT-4o在MMLU(综合知识)和GPQA(研究生水平问题)等多个基准上都处于领先地位。
应用建议: 如果你的应用场景是需要与用户进行多轮、包含图片的流畅对话(如AI家教、视觉客服),GPT-4o可能是最佳选择。如果你的任务是处理超长文档或视频(Gemini 1.5 Pro有高达1M Token的上下文窗口),则可以考虑其他模型。
资源链接: 参考 Artificial Analysis 等第三方评测网站获取最新的性能对比数据。
结论:你的下一个AI应用,从"看见"开始
GPT-4o Vision API 不仅仅是一个技术更新,它为开发者打开了一个充满想象力的新世界。从自动化繁琐的视觉任务到创造全新的用户体验,可能性是无限的。
我们已经看到,调用API本身并不复杂,但要做到高效、经济、稳定,则需要合理的策略:
- 选择正确的工具: 对于国内开发者,使用像 LaoZhang.ai 这样的中转API服务,可以完美解决网络、支付和成本问题。
- 掌握核心技巧: 学会利用多图输入和
detail参数,平衡好性能与成本。 - 编写健壮的代码: 做好错误处理和超时管理,确保你的应用稳定可靠。
现在,你已经掌握了启动一个Vision项目所需的所有核心知识。
下一步行动建议: 👉 立即注册 LaoZhang.ai,领取免费额度,将本文中的代码示例跑起来,亲身体验 GPT-4o "看见"世界的能力!