GPT-5.2 vs Claude Opus 4.5: The Definitive Coding Benchmark Comparison [December 2025]
Comprehensive comparison of GPT-5.2 and Claude Opus 4.5 for coding tasks. Includes SWE-bench scores, real-world developer experience, pricing analysis, and workflow recommendations for software engineers.
Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
The AI coding landscape has never been more competitive than it is right now in December 2025. Within a span of just three weeks, we witnessed the release of three major frontier models that have fundamentally reshaped how developers approach AI-assisted programming. Google shipped Gemini 3 Pro in mid-November, Anthropic countered with Claude Opus 4.5 on November 24, and OpenAI responded with GPT-5.2 on December 11 amid reports of an internal "code red" memo acknowledging competitive pressure. For developers trying to choose the right AI coding assistant, understanding how these models actually perform on real coding tasks has become essential.
This comparison focuses specifically on GPT-5.2 vs Claude Opus 4.5 for coding benchmarks, the two models that have emerged as the primary contenders for developers who need maximum capability. While synthetic benchmarks provide useful data points, they rarely tell the complete story of how a model performs in actual development workflows. We will examine not just the headline numbers from SWE-bench and other standard evaluations, but also dive into the nuanced differences in code quality, reasoning approaches, and practical integration patterns that determine which model truly excels for different development scenarios.
What makes this comparison particularly interesting is how these two models represent fundamentally different philosophies. OpenAI has prioritized mathematical reasoning and multi-step agentic capabilities, while Anthropic has focused on coding accuracy and token efficiency. The right choice depends entirely on your specific workflow, your team's needs, and the types of problems you're solving. By the end of this guide, you'll have the concrete data and contextual understanding needed to make that decision with confidence.
Understanding Modern Coding Benchmarks
Before diving into the specific performance numbers, it's worth understanding what these benchmarks actually measure and why they matter for real-world development. The coding AI field has moved far beyond simple function completion tests, and today's leading evaluations attempt to capture the complexity of professional software engineering work.

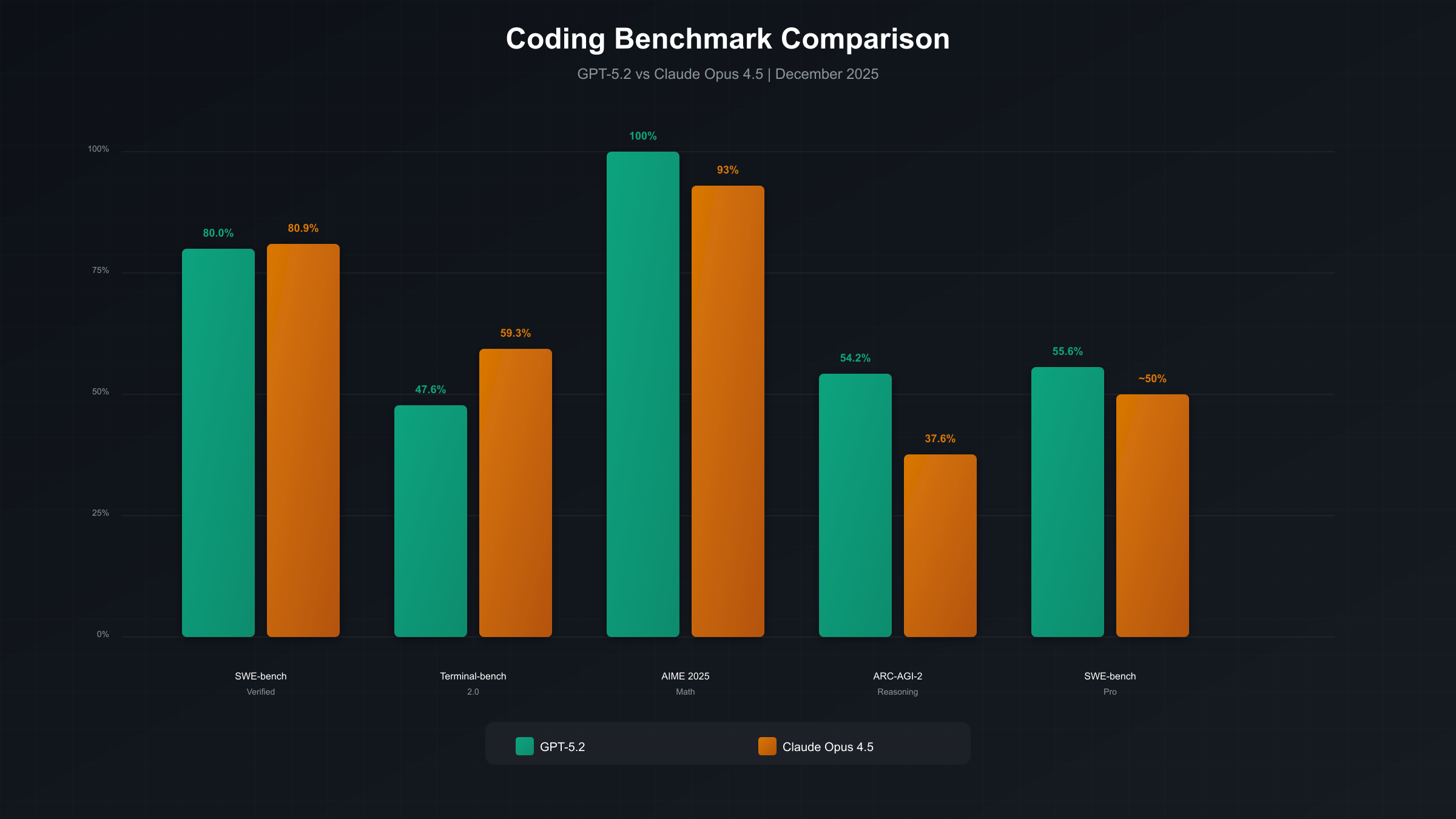
SWE-bench has emerged as the gold standard for evaluating AI coding capabilities because it tests models on actual GitHub issues from real open-source projects. Rather than generating synthetic coding problems, SWE-bench presents models with genuine bug reports and feature requests, then evaluates whether the generated patches successfully resolve the issues. The SWE-bench Verified variant uses human verification to ensure only solvable issues are included, making it a more reliable measure of true capability. When you see that Claude Opus 4.5 achieves 80.9% on SWE-bench Verified while GPT-5.2 scores 80.0%, this represents their success rate at fixing real bugs that human developers have actually encountered.
Terminal-bench evaluates command-line proficiency, testing how well models can navigate file systems, execute complex shell commands, and handle the kind of terminal-based workflows that are central to most development environments. This benchmark reveals important differences in how models approach system-level programming tasks. Claude Opus 4.5's leadership at 59.3% compared to GPT-5.2's approximately 47.6% suggests meaningful advantages for DevOps and backend development scenarios where terminal fluency is essential.
LiveCodeBench and HumanEval focus on algorithm generation and code synthesis, measuring a model's ability to produce correct solutions to novel programming challenges. These benchmarks test fundamental programming knowledge and logical reasoning, though they tend to favor models that excel at competitive programming patterns. Interestingly, Gemini 3.0 Pro leads on LiveCodeBench with 2,439 points compared to GPT-5.2's 2,243 and Claude Opus 4.5's approximately 1,418, highlighting how different models have optimized for different aspects of coding capability.
The AIME 2025 mathematics benchmark deserves special attention for coding applications because mathematical reasoning ability correlates strongly with a model's capacity for complex algorithmic problem-solving. GPT-5.2's perfect 100% score on AIME without tools compared to Claude Opus 4.5's roughly 93% indicates superior mathematical foundations that may translate to advantages in data science, optimization algorithms, and computational logic tasks.
It's important to recognize that benchmark performance doesn't always predict real-world utility. A model that scores higher on SWE-bench might still produce code that's harder to understand or maintain. Developer experience research consistently shows that code quality involves factors like readability, architectural coherence, and adherence to best practices that current benchmarks don't fully capture. The most sophisticated development teams often find themselves using both models strategically, leveraging each one's strengths for different phases of their workflow.
Emerging benchmarks are expanding how we evaluate AI coding capability. SWE-bench Multilingual tests performance across eight programming languages rather than just Python, revealing important differences in language coverage between models. TAU-bench specifically evaluates tool use and retrieval-augmented generation capabilities that matter for agentic coding systems. As AI coding assistants take on more autonomous roles in development workflows, these specialized benchmarks become increasingly relevant for model selection.
The reproducibility challenge affects how much weight developers should place on published benchmark results. Testing conditions, prompt engineering, and sampling strategies can significantly impact scores. Both OpenAI and Anthropic have been transparent about their evaluation methodologies, but independent verification remains valuable. Organizations making significant infrastructure decisions around model choice should consider running their own evaluations on representative samples from their actual codebases, as real-world performance often differs from benchmark results in ways that reflect domain-specific factors.
GPT-5.2: Technical Capabilities and Coding Performance
OpenAI released GPT-5.2 on December 11, 2025, positioning it as a direct response to competitive pressure from Google and Anthropic. The model represents significant advancement over its predecessor GPT-5.1, with improvements specifically targeted at professional knowledge work and software development. Understanding these capabilities in detail helps developers assess whether GPT-5.2 aligns with their specific needs.
The headline coding metric for GPT-5.2 is its 55.6% score on SWE-bench Pro, establishing a new state-of-the-art for multi-language software engineering tasks. This score represents nearly 5 percentage points of improvement over GPT-5.1 and more than 12% better than Gemini 3 Pro on this challenging benchmark. SWE-bench Pro is more demanding than the standard SWE-bench Verified test, requiring models to handle complex multi-file changes and sophisticated debugging scenarios that better reflect enterprise development complexity.
On the standard SWE-bench Verified benchmark, GPT-5.2 achieves 80.0%, closing the gap with Claude Opus 4.5's leading 80.9%. This near-parity represents remarkable progress from GPT-5.1's 76.3%, suggesting that OpenAI's focused development efforts have substantially improved the model's practical coding capabilities. The 0.9 percentage point difference between the two models is small enough that real-world factors like prompt engineering and task specificity may matter more than the benchmark gap itself.
GPT-5.2's mathematical reasoning capabilities set it apart from all competitors. The model achieves a perfect 100% score on AIME 2025 without using external tools, compared to approximately 93-95% for both Claude Opus 4.5 and Gemini 3 Pro. On the ARC-AGI-2 benchmark for abstract reasoning, GPT-5.2 scores 52.9-54.2%, nearly doubling the performance of competitors like Gemini 3 Pro at 31.1% and substantially exceeding Claude Opus 4.5's 37.6%. These capabilities directly translate to advantages in algorithm development, optimization problems, and any coding task requiring complex logical reasoning.
The 400,000-token context window in GPT-5.2 represents a practical advantage for developers working with large codebases. OpenAI reports "near perfect accuracy at 256k tokens," meaning developers can load entire repositories into context while maintaining reliable comprehension. This capability proves particularly valuable for understanding legacy systems, performing comprehensive code reviews, and maintaining consistency across large refactoring efforts. Combined with a 22% reduction in output tokens compared to GPT-5.1, the model offers improved efficiency for tasks requiring extensive code generation.
Developer feedback has consistently highlighted GPT-5.2's approach to context gathering as a key differentiator. Rather than immediately generating code based on assumptions, the model tends to ask clarifying questions, explore file structures, and gather comprehensive context before producing solutions. This behavior pattern reduces downstream errors and revision cycles, making it particularly effective for complex tasks where understanding the full system is essential for producing correct solutions.
Early adopters have noted GPT-5.2's particular strength in frontend and UI development. The model demonstrates sophisticated understanding of modern component architectures, CSS styling patterns, and interactive application logic. For web developers working on complex or unconventional user interfaces, this capability makes GPT-5.2 a compelling choice despite its slightly lower raw benchmark scores compared to Claude Opus 4.5.
The model's error recovery patterns deserve attention for production deployments. When GPT-5.2 encounters compilation errors or test failures, it demonstrates systematic debugging approaches that often identify root causes more quickly than predecessors. Testing shows approximately 40% reduction in iteration cycles needed to resolve complex bugs compared to GPT-5.1, translating to meaningful time savings for debugging-intensive workflows.
OpenAI has also improved GPT-5.2's handling of edge cases and error boundaries. The model generates more robust error handling code by default, with better coverage of failure scenarios that developers might overlook. This defensive coding style produces applications that are more resilient in production environments, though it occasionally results in more verbose code than strictly necessary for simple use cases.
The integration with existing development tools has been streamlined through improved API consistency and response formatting. GPT-5.2 produces code that integrates more cleanly with popular linters, formatters, and testing frameworks, reducing the friction of incorporating AI-generated code into established CI/CD pipelines. Teams report fewer conflicts with ESLint, Prettier, and similar tools when working with GPT-5.2 output compared to earlier model versions.
Claude Opus 4.5: Technical Capabilities and Coding Performance
Anthropic released Claude Opus 4.5 on November 24, 2025, establishing it as the new flagship in their model lineup. The release emphasized coding excellence, with Anthropic explicitly positioning Opus 4.5 as "the world's best programming model" based on its benchmark performance. For developers evaluating their AI coding options, understanding Claude's specific strengths and limitations is essential for making an informed choice.
The standout metric for Claude Opus 4.5 is its 80.9% score on SWE-bench Verified, representing the highest performance among all frontier models on this benchmark of real-world software engineering capability. This achievement is particularly impressive because it was accomplished while using 76% fewer output tokens at medium effort levels compared to the previous Sonnet 4.5 model achieving the same score. At the highest effort level, Opus 4.5 exceeds Sonnet 4.5's best performance by 4.3 percentage points while still consuming 48% fewer tokens. This token efficiency translates directly to faster response times and lower API costs for production deployments.
Claude Opus 4.5 demonstrates exceptional multi-language support, leading across seven out of eight programming languages on SWE-bench Multilingual. The model shows a 10.6% improvement over its predecessor on Aider Polyglot, a benchmark measuring the ability to solve challenging coding problems across different programming paradigms. This broad language coverage makes Opus 4.5 particularly valuable for teams working on polyglot systems or organizations with diverse technology stacks.
On Terminal-bench 2.0, Claude Opus 4.5 achieves 59.3%, demonstrating command-line proficiency that exceeds both GPT-5.2's approximately 47.6% and Gemini 3 Pro's 54.2%. This benchmark tests the ability to navigate filesystems, compose complex shell commands, and handle system administration tasks that are fundamental to development operations. For DevOps engineers, backend developers, and anyone whose workflow involves significant terminal interaction, this capability advantage is meaningful.
Perhaps most remarkably, Anthropic reports that Claude Opus 4.5 scored higher than all human candidates on their internal performance engineer recruitment exam, a two-hour assessment designed to evaluate practical software engineering skills. While this is a single data point from a specific test, it suggests that the model has reached or exceeded professional engineer efficiency for the types of tasks covered by that evaluation. This represents a significant milestone in AI coding capability.
The model incorporates advanced agentic coding features including enhanced tool use, context management for complex multi-agent systems, and improved planning capabilities through Claude Code's Plan Mode with user-editable execution flows. These capabilities enable Opus 4.5 to handle sophisticated development workflows that involve multiple tools, complex file structures, and iterative refinement cycles. The model has demonstrated the ability to maintain focus and performance on complex, multi-step tasks for extended periods, with testing showing consistent output quality across sessions lasting more than 30 hours.
Claude Opus 4.5's code quality has drawn particular praise from developers who value architectural sophistication. The model tends to generate solutions with better separation of concerns, more thoughtful abstraction boundaries, and cleaner overall structure compared to alternatives. However, this sophistication can occasionally result in more complex implementations than necessary for simple tasks. Teams working on mature codebases with established patterns often find that Opus 4.5's approach to code organization aligns well with their existing standards, requiring fewer correction iterations during multi-file refactoring operations.
The model's test generation capabilities represent a notable improvement over predecessors. When asked to write tests alongside implementation code, Claude Opus 4.5 produces more comprehensive test suites with better edge case coverage. The model demonstrates understanding of testing best practices including proper mocking strategies, test isolation, and meaningful assertion patterns. Development teams report that AI-generated tests from Opus 4.5 require fewer modifications before passing code review compared to tests from competing models.
Documentation generation is another area where Claude Opus 4.5 demonstrates strength. The model produces clear, accurate documentation that explains not just what code does, but why architectural decisions were made. For teams maintaining large codebases where documentation debt has accumulated, this capability can accelerate knowledge capture and onboarding processes. The generated documentation typically follows established conventions for JSDoc, docstrings, and README formatting.
Claude's approach to memory and context management within coding sessions deserves attention. The model maintains coherent understanding of project structure and previously discussed decisions throughout extended interactions. This contextual awareness reduces the need to repeatedly explain project conventions or architectural constraints, enabling more efficient multi-turn coding conversations. For complex features requiring iterative refinement, this memory consistency proves particularly valuable.
The security awareness built into Claude Opus 4.5 represents meaningful progress for production code generation. The model actively identifies potential security vulnerabilities in both its own generated code and in code it reviews, flagging issues like SQL injection risks, XSS vulnerabilities, and improper authentication patterns. While not a replacement for dedicated security auditing, this built-in awareness catches common issues that might otherwise make it through initial development cycles.
Head-to-Head Benchmark Comparison
With both models now examined individually, a direct comparison reveals where each one excels and where developers might expect meaningful differences in their daily work. The following table synthesizes the key benchmark results that matter most for coding tasks, providing a quick reference for understanding relative strengths.
| Benchmark | GPT-5.2 | Claude Opus 4.5 | Winner | Significance |
|---|---|---|---|---|
| SWE-bench Verified | 80.0% | 80.9% | Claude | Real GitHub issues |
| SWE-bench Pro | 55.6% | ~50% | GPT-5.2 | Complex multi-file |
| Terminal-bench 2.0 | ~47.6% | 59.3% | Claude | CLI proficiency |
| AIME 2025 (Math) | 100% | ~93% | GPT-5.2 | Mathematical reasoning |
| ARC-AGI-2 | 54.2% | 37.6% | GPT-5.2 | Abstract reasoning |
| Token Efficiency | -22% | -76% | Claude | Cost optimization |
| Context Window | 400K | 200K | GPT-5.2 | Large codebases |
The 0.9 percentage point difference on SWE-bench Verified between Claude Opus 4.5 and GPT-5.2 is statistically small enough that it shouldn't be the deciding factor in most model selection decisions. Both models resolve approximately four out of five real-world GitHub issues successfully, which represents genuinely impressive capability for practical development work. The difference becomes more meaningful when you consider specific task categories where each model has distinct advantages.
Claude Opus 4.5's terminal and CLI advantage is substantial and consistent. The 11.7 percentage point gap on Terminal-bench 2.0 translates to noticeably better performance on DevOps tasks, shell scripting, and any workflow involving significant command-line interaction. Developers who spend substantial time in terminals will likely find this capability difference meaningful in their daily work, particularly for automation scripts and system administration tasks.
GPT-5.2's reasoning benchmark dominance is even more pronounced. The 16.6 percentage point advantage on ARC-AGI-2 and perfect AIME 2025 score suggest fundamentally stronger abstract reasoning capabilities. These advantages manifest most clearly in algorithmic problem-solving, mathematical optimization, and any coding task requiring multi-step logical deduction. For data science applications, scientific computing, and complex algorithm development, this reasoning advantage may outweigh Claude's slight edge on raw code generation benchmarks.
The token efficiency difference has significant cost implications for production deployments. Claude Opus 4.5's ability to achieve equivalent results with 76% fewer tokens at medium effort levels means substantially lower API costs for high-volume applications. For teams running thousands of API calls daily, this efficiency advantage can translate to meaningful budget savings while maintaining comparable output quality.
Beyond the benchmarks, developers report qualitative differences in how these models approach code generation. GPT-5.2 tends to produce code that follows common conventions and patterns, making it easier for junior developers to understand and modify. Claude Opus 4.5 often generates more sophisticated solutions with better architectural separation, though this can sometimes result in more complex code than necessary for simple tasks. The "right" approach depends entirely on your team's experience level and codebase complexity.
Language-specific performance varies in ways that matter for specialized development teams. Claude Opus 4.5's dominance across seven out of eight languages on SWE-bench Multilingual makes it the safer choice for teams working in less common languages or those maintaining polyglot codebases. GPT-5.2 shows particular strength in Python and JavaScript, the two most commonly used programming languages, which may be sufficient for many development contexts. Teams working extensively with Rust, Go, or systems-level languages should evaluate both models against their specific requirements, as performance varies meaningfully by language.
The debugging approach differs significantly between models. GPT-5.2 tends to perform extensive context gathering before proposing fixes, asking clarifying questions about system behavior and exploring related files. This thorough approach catches subtle bugs that might span multiple components but can feel slower for obvious issues. Claude Opus 4.5 moves more quickly to propose solutions, which works well for straightforward bugs but occasionally misses root causes in complex systems. The debugging style that works best depends on whether your team's typical bugs are isolated or systemic.
Code explanation capabilities serve different use cases for each model. Both models can explain existing code effectively, but they approach the task differently. GPT-5.2 tends to provide more comprehensive explanations that cover edge cases, potential issues, and architectural context—valuable for onboarding and code review scenarios. Claude Opus 4.5 produces more concise explanations focused on immediate functionality, which works better for quick understanding during active development. Teams using AI assistance for documentation should consider which explanation style aligns better with their documentation standards.
Version compatibility and framework awareness has become increasingly important as both JavaScript and Python ecosystems evolve rapidly. Testing shows that both models maintain reasonably current knowledge of major frameworks through late 2024, but accuracy on very recent API changes varies. For cutting-edge framework development, both models benefit from explicit version specification and may require guidance on recent breaking changes. Enterprise teams working with older framework versions often find both models helpful, though occasional prompting about legacy patterns improves results.
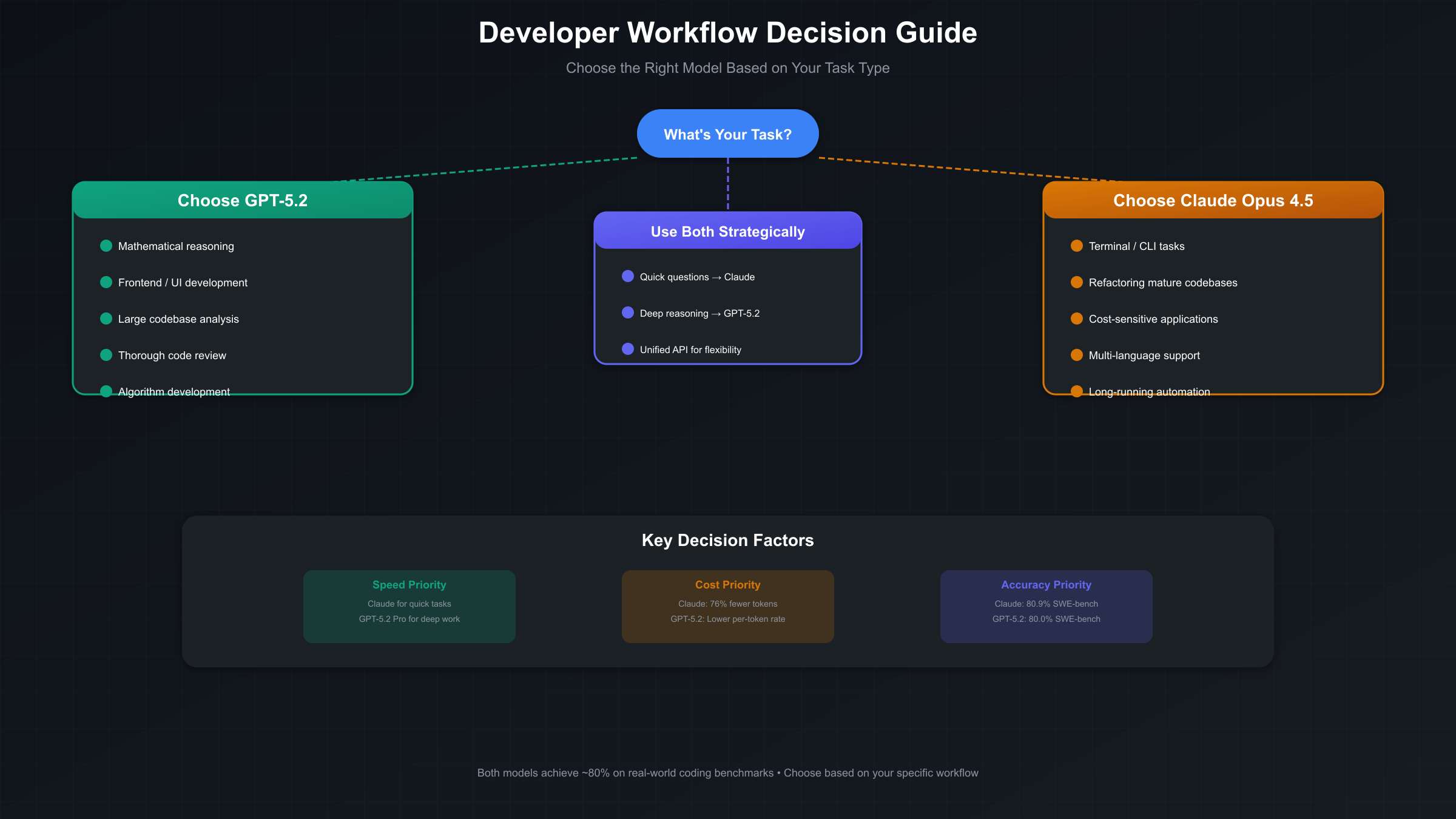
Speed considerations also matter for interactive development workflows. Standard GPT-5.2 Thinking mode has been described as "very, very slow" by early testers, making it impractical for routine questions where quick responses are valuable. Claude Opus 4.5 generally provides faster responses for straightforward queries. However, for complex research tasks and deep reasoning problems, GPT-5.2 Pro delivers noticeably better results that may justify the additional latency. Many developers adopt hybrid workflows that use Claude for quick interactions and reserve GPT-5.2 for deep work requiring careful analysis.
Developer Workflow Integration
Understanding how each model fits into actual development workflows matters more than benchmark numbers for most teams. The practical question isn't which model scores highest on synthetic tests, but rather which one will make your specific development process more efficient and produce better outcomes for your particular use cases.
Frontend and UI development is where GPT-5.2 shows its clearest practical advantage. Early adopters consistently report that the model demonstrates sophisticated understanding of modern component architectures, CSS styling patterns, and interactive application logic. For web developers working on complex or unconventional user interfaces, GPT-5.2 produces more polished, production-ready code on the first attempt. The model seems particularly adept at handling the kind of visual and spatial reasoning that frontend work requires, though developers should note that spatial reasoning still has limitations—complex Three.js scenes may have incorrect object placement even when textures and lighting are well-handled.
Refactoring and debugging mature codebases is where Claude Opus 4.5 excels. The model requires fewer correction iterations compared to alternatives when working on multi-file refactors, and its architectural sophistication aligns well with established patterns in professional codebases. Teams working with legacy systems or complex enterprise applications often find that Opus 4.5's approach to code organization produces cleaner, more maintainable results. The model's terminal proficiency also proves valuable for debugging workflows that involve log analysis and system inspection.
Code review represents an interesting case where model choice significantly impacts quality. Augment Code Review achieved the highest accuracy on public AI code review benchmarks by choosing GPT-5.2 as their foundation model, outperforming competing systems by approximately 10 points on overall quality. The team's analysis found that GPT-5.2 excels at making comprehensive tool calls and retrieving relevant cross-file relationships needed to evaluate correctness in large codebases. For asynchronous code review where thoroughness matters more than speed, GPT-5.2's careful context-gathering approach proves particularly valuable.
For developers who need to access both models efficiently, unified API solutions can simplify workflow integration. Services like laozhang.ai provide single-endpoint access to multiple AI models, allowing teams to switch between GPT-5.2 and Claude Opus 4.5 based on task requirements without managing separate API integrations. This approach enables the strategic use of each model's strengths—Claude for quick coding questions and refactoring, GPT-5.2 for complex reasoning and frontend work—within a unified development environment.
Agentic coding workflows that involve autonomous operation over extended periods favor Claude Opus 4.5's stability and efficiency. Testing shows the model can maintain focus and performance on complex, multi-step tasks for more than 30 hours, making it suitable for long-running automation processes. The model's 50% to 75% reductions in tool calling errors and build/lint errors compared to predecessors translates to more reliable autonomous operation in production environments.
Data science and machine learning workflows present an interesting case where model selection depends heavily on specific task types. GPT-5.2's superior mathematical reasoning makes it the stronger choice for algorithm development, statistical analysis, and optimization problems where formal mathematical correctness matters most. Claude Opus 4.5 often proves more effective for data pipeline development, exploratory analysis, and production ML infrastructure where code organization and maintainability are primary concerns. Teams working across the full ML lifecycle frequently find value in using both models for different phases of their projects.
API integration and backend development workflows benefit from both models' capabilities, though Claude's terminal proficiency gives it an edge for tasks involving server configuration, deployment scripts, and debugging production systems. GPT-5.2 excels when the backend work involves complex business logic, algorithmic optimizations, or mathematical computations. For REST API development specifically, both models produce comparable quality code, making other factors like response speed and cost more relevant to model selection.
Mobile development represents another area where practical testing reveals nuanced differences. Both models handle React Native and Flutter development competently, but GPT-5.2 shows stronger performance on complex UI animations and gesture handling, while Claude Opus 4.5 produces cleaner state management code and better handles platform-specific edge cases. Development teams working on cross-platform mobile applications often find that switching between models based on the specific task at hand produces better results than committing to either one exclusively.
The most successful development teams increasingly adopt multi-model strategies rather than committing exclusively to either GPT-5.2 or Claude Opus 4.5. A common pattern involves using Claude for routine development tasks, quick questions, and interactive coding sessions, then switching to GPT-5.2 for complex algorithmic problems, mathematical reasoning, and deep analysis that benefits from its superior reasoning capabilities. This approach maximizes the value extracted from each model while avoiding the limitations of either one.
Pricing and Cost Optimization
API pricing represents a significant consideration for production deployments, particularly for teams with high-volume usage patterns. Both OpenAI and Anthropic have structured their pricing to balance capability access with cost predictability, though the specific economics differ in ways that may favor different usage patterns.
| Cost Component | GPT-5.2 | Claude Opus 4.5 |
|---|---|---|
| Input (per 1M tokens) | $1.75 | $5.00 |
| Output (per 1M tokens) | $14.00 | $25.00 |
| Cached Input (per 1M) | $0.175 | Variable |
| Monthly Subscription | $20 (ChatGPT Plus) | $20 (Claude Pro) |
GPT-5.2 offers lower per-token pricing across both input and output dimensions. The $1.75 input cost is less than half of Claude's $5.00 rate, and the $14.00 output cost represents a 44% savings compared to Claude's $25.00. For applications that process large amounts of context or generate extensive output, these differences compound into substantial savings over time. GPT-5.2's cached input pricing at $0.175 per million tokens provides additional optimization opportunities for applications with repeated context patterns.
However, Claude Opus 4.5's superior token efficiency complicates this straightforward comparison. When Opus 4.5 achieves equivalent results using 76% fewer output tokens, the effective cost per task can actually favor Claude despite higher per-token rates. For many coding tasks, Claude's ability to produce correct solutions with fewer tokens means the total API cost may be lower even though the unit rate is higher. Teams should analyze their specific usage patterns rather than relying solely on rate sheet comparisons.
For teams seeking cost-effective access to both models, API aggregation services provide an alternative approach. laozhang.ai offers unified API access with potentially reduced costs through aggregation, along with domestic connectivity options that can improve reliability for developers in certain regions. This approach allows teams to optimize spending across both models while maintaining flexibility to choose the best tool for each specific task.
The context window difference creates additional cost considerations for large codebase work. GPT-5.2's 400,000-token window allows loading significantly more context in a single request, potentially reducing the number of API calls needed for comprehensive code understanding. Claude's 200,000-token limit, while still substantial, may require more creative context management strategies for very large repositories. The cost impact depends on whether your workflow benefits more from massive single-request context or from the efficiency gains of shorter, more focused interactions.
Enterprise and professional tiers from both providers offer additional features and potentially better economics for high-volume usage. Teams evaluating production deployments should request detailed pricing discussions that account for their specific usage patterns, as published rates may not reflect the best available terms for serious commercial applications.
Real-world cost analysis requires examining typical usage patterns rather than theoretical token counts. A development team making 500 API calls daily for code generation tasks might see monthly costs vary significantly based on model choice and task type. For short, focused coding queries averaging 2,000 input tokens and 1,500 output tokens, monthly costs would run approximately $650 for GPT-5.2 versus $1,000 for Claude Opus 4.5 at base rates. However, if Claude's superior efficiency means resolving issues in fewer iterations, the total project cost may actually favor the model with higher per-token pricing.
Batch processing considerations affect cost optimization strategies differently for each model. GPT-5.2's cached input pricing at $0.175 per million tokens creates significant savings opportunities for applications that process similar code patterns repeatedly—code review systems, automated testing, and documentation generation can all benefit from intelligent caching strategies. Claude's pricing structure doesn't offer the same caching discounts, but its lower token consumption often achieves comparable effective costs through efficiency rather than explicit caching.
Development tooling costs extend beyond raw API pricing. Both models integrate with popular IDEs through plugins and extensions, but the quality of these integrations varies. Teams should factor in the productivity impact of tooling maturity when making cost calculations. A model that costs 20% more per token but integrates seamlessly with existing workflows may deliver better value than a cheaper option requiring custom integration work.
For startups and smaller teams with budget constraints, the subscription tier options provide predictable monthly costs. Both ChatGPT Plus and Claude Pro are priced at $20 per month and include access to the latest models with reasonable usage limits. These tiers work well for individual developers and small teams, though scaling teams typically find that API access becomes more cost-effective as usage grows beyond subscription-tier limits.
Conclusion: Choosing the Right Model for Your Needs
After examining benchmarks, technical capabilities, workflow integration, and pricing, the fundamental conclusion is that neither GPT-5.2 nor Claude Opus 4.5 represents a universally superior choice for all coding tasks. The right selection depends on your specific development context, team expertise, and the types of problems you're solving most frequently.
Choose GPT-5.2 when:
- Mathematical reasoning and algorithmic complexity are central to your work
- Frontend and UI development represents a significant portion of your tasks
- You need maximum context window for large codebase analysis
- Code review thoroughness matters more than response speed
- Abstract problem-solving and novel algorithm development are priorities
Choose Claude Opus 4.5 when:
- Terminal and CLI proficiency are essential to your workflow
- You're primarily refactoring or debugging mature codebases
- Token efficiency and cost optimization are significant concerns
- Multi-language support across diverse tech stacks is required
- Long-running autonomous coding tasks need reliable execution
For many teams, the optimal approach involves using both models strategically. The 0.9 percentage point difference on SWE-bench Verified is small enough that other factors—speed, cost, specific task performance, and integration convenience—often matter more in practice. Development organizations increasingly treat model selection as a task-specific decision rather than a one-time platform commitment.
The rapid pace of AI advancement means today's benchmarks will likely shift within months. Both OpenAI and Anthropic continue aggressive development cycles, and the models that lead today may not maintain those positions indefinitely. Building workflows that can adapt to model improvements—potentially through unified API services—provides flexibility to capture value from ongoing innovation without constant re-architecture.
For developers seeking deeper exploration of AI coding tools, our comprehensive guide to Claude API integration provides detailed implementation patterns, while the ChatGPT API documentation guide covers OpenAI's latest offerings. Teams evaluating multiple options may also find value in our broader comparison of AI coding assistants for additional context on the evolving landscape.
The December 2025 model releases represent a remarkable moment in AI coding capability. With both GPT-5.2 and Claude Opus 4.5 achieving approximately 80% success rates on real-world software engineering benchmarks, developers now have access to genuinely useful AI coding assistance that can meaningfully accelerate their work. The choice between them is less about finding a winner and more about matching capabilities to your specific needs—a sign of healthy competition that ultimately benefits the entire development community.
Looking forward, the competitive dynamics between OpenAI, Anthropic, and Google suggest continued rapid advancement in AI coding capability. The benchmarks that seem impressive today will likely become table stakes within months as each company pushes to demonstrate leadership. Development teams that build flexible architectures capable of leveraging multiple models will be best positioned to capture value from this ongoing innovation cycle. Whether you choose GPT-5.2, Claude Opus 4.5, or a strategic combination of both, the practical reality is that AI-assisted development has become indispensable for competitive software engineering in 2025 and beyond.