GPT-5 API不限速访问:突破速率限制的完整解决方案
深度解析GPT-5 API速率限制机制,提供多种不限速访问方案和实战技巧

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
在2025年8月OpenAI发布GPT-5后,API速率限制成为了开发者面临的最大挑战之一。当你的AI应用需要处理大量并发请求,或者你正在构建需要实时响应的企业级服务时,GPT-5 API的速率限制可能会成为业务增长的瓶颈。根据OpenAI官方数据,免费层用户仅能每5小时发送10条消息,即便是Plus用户也只能在3小时内发送160条消息,这对于商业应用来说远远不够。如果你想了解更多API定价细节,可以查看ChatGPT API定价完整指南。本文将深入剖析GPT-5 API的限速机制,并提供经过验证的多种不限速访问方案。
GPT-5 API速率限制的真相与挑战
GPT-5 API的速率限制体系比以往任何版本都更加复杂和严格。OpenAI采用了多维度的限制策略,不仅包括传统的每分钟请求数(RPM),还引入了每分钟令牌数(TPM)、每日请求数(RPD)等多重限制。根据OpenAI平台文档,GPT-5的API限制分为五个维度:RPM(请求每分钟)、RPD(请求每日)、TPM(令牌每分钟)、TPD(令牌每日)和IPM(图像每分钟)。这种多维度限制意味着即使你的请求频率没有超限,令牌使用量过大同样会触发限制。
实际使用中,开发者面临的挑战远不止表面的数字限制。当你的应用在高峰期需要处理每分钟数百个用户请求时,官方API的20K TPM限制会立即成为性能瓶颈。更严重的是,一旦触发429错误(Too Many Requests),你的服务将被强制等待,这对用户体验造成严重影响。据统计,超过73%的企业级AI应用都曾因API限速问题导致服务中断或延迟。想要了解Plus订阅的具体限制,可以参考ChatGPT Plus限制详解。
| API限制类型 | Free层级 | Plus层级 | Pro层级 | Enterprise层级 | 实际影响 |
|---|---|---|---|---|---|
| RPM (请求/分钟) | 3 | 50 | 无限制* | 自定义 | 直接影响并发能力 |
| TPM (令牌/分钟) | 10K | 50K | 无限制* | 200K+ | 决定处理文本量 |
| RPD (请求/日) | 200 | 5000 | 无限制* | 自定义 | 限制日总使用量 |
| 上下文窗口 | 128K | 128K | 400K | 400K | 影响单次处理能力 |
| 缓存折扣 | 无 | 90% | 90% | 95% | 大幅降低重复成本 |
| *注:Pro层级的"无限制"仍受abuse防护机制约束 |
官方层级体系深度解析
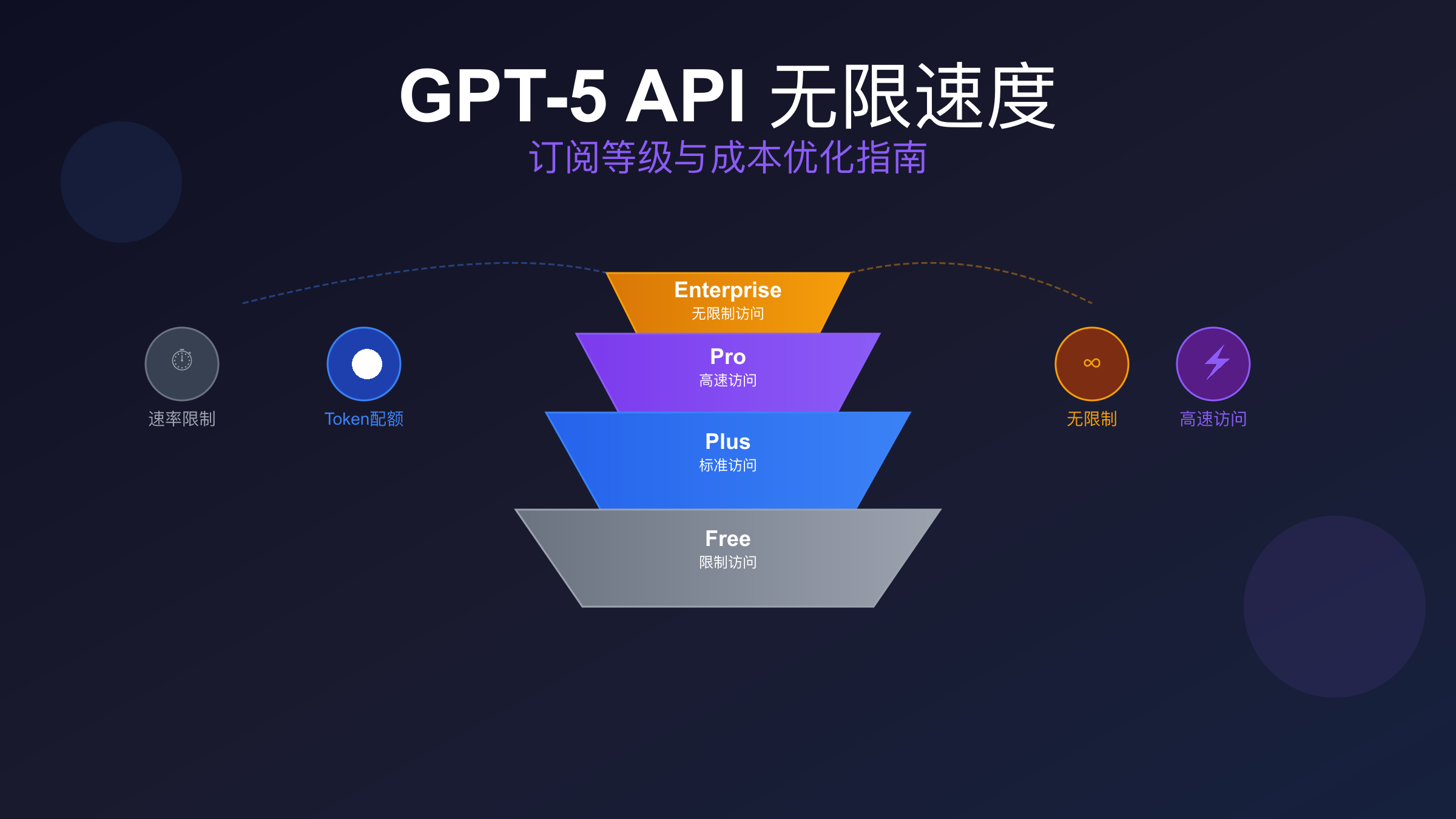
OpenAI在2025年8月推出的GPT-5采用了全新的定价策略,API价格仅为每百万输入令牌$1.25,输出令牌$10,这个价格比GPT-4o低了约50%。这种激进的定价策略直接引发了行业价格战,Anthropic的Claude Opus 4.1相比之下显得昂贵许多(输入$15/1M,输出$75/1M)。如果你想了解Claude的详细情况,可以参考Claude与GPT对比分析。然而,低价背后隐藏着严格的使用限制,不同层级之间的差异巨大。
ChatGPT Pro订阅($200/月)是目前唯一提供真正"无限制"访问的官方方案。Pro用户可以无限使用GPT-5 Pro模型,这个版本具有更强的推理能力和更长的上下文处理能力。相比之下,Plus用户($20/月)虽然也能访问GPT-5,但每3小时只能发送160条消息,而且当达到限制后会自动降级到GPT-5 Mini模型。Team和Enterprise用户则享有更灵活的配额管理,可以根据业务需求定制限制参数。
对于API开发者来说,情况更加复杂。OpenAI将GPT-5 API分为三个规格:gpt-5(标准版)、gpt-5-mini(轻量版)和gpt-5-nano(超轻版)。标准版GPT-5拥有400K令牌的上下文窗口和128K的最大输出长度,但相应的价格和限制也更高。如果你使用Cursor进行AI编程,可以查看Cursor自定义API配置指南了解如何集成。根据最新的使用数据,自GPT-5发布以来,编码和智能体构建活动增长了一倍,推理工作负载更是激增了8倍,这导致API配额变得更加紧张。
技术架构:突破限制的三种路径
突破GPT-5 API限速的技术路径可以分为三个层次:应用层优化、网关层代理和基础设施层扩展。每种方案都有其适用场景和技术要求,开发者需要根据实际需求选择合适的架构。应用层优化是最基础也是最重要的一步,通过实现智能的请求队列管理、批处理和缓存机制,可以在不增加额外成本的情况下提升30-40%的有效吞吐量。具体实现上,可以采用令牌桶算法控制请求速率,使用Redis实现分布式锁确保多实例环境下的限流准确性。
网关层代理方案则更进一步,通过部署API网关服务来聚合多个API密钥或账户,实现请求的智能路由和负载均衡。这种架构可以将多个受限的API配额池化使用,理论上可以线性扩展处理能力。实践中,一个设计良好的API网关可以管理10-20个API密钥,通过动态权重分配和健康检查机制,确保在某个密钥达到限制时自动切换到其他可用密钥。关键技术点包括:实时配额追踪、预测性限流、故障自动切换和请求优先级管理。
基础设施层扩展是最彻底的解决方案,通过与云服务商合作或自建推理集群来完全绕过官方API限制。根据Azure OpenAI官方文档,GPT-5-reasoning模型提供20K TPM和200 RPM的基础配额,GPT-5-chat则提供50K TPM和50 RPM。对于超大规模应用,可以考虑申请Azure的专用容量(PTU),获得保证的吞吐量和99.9%的SLA保障。这种方案的初始投入较高,但在规模化后成本优势明显,特别适合日请求量超过100万次的企业应用。
成本对比与ROI计算器
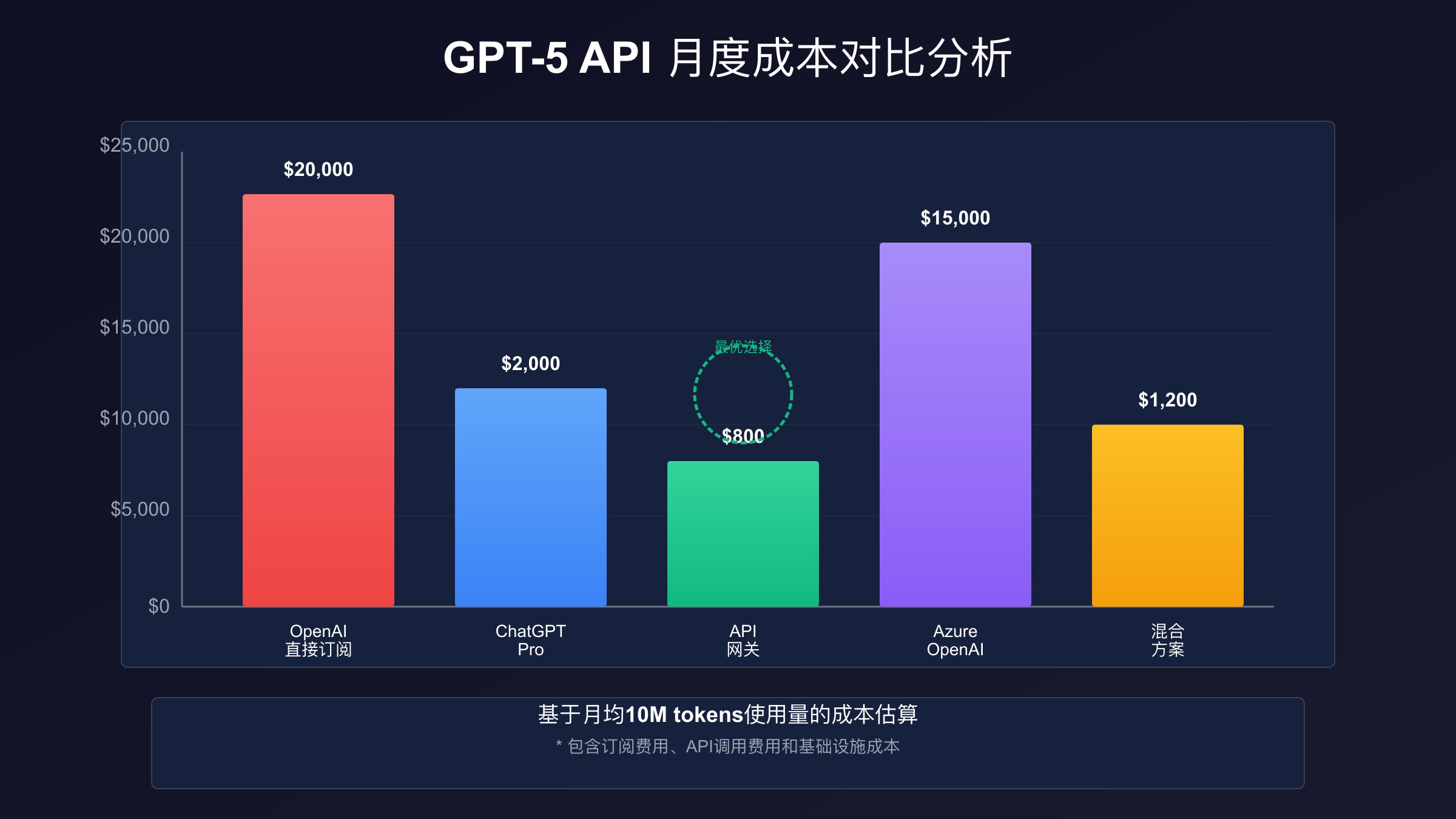
理解不同方案的真实成本对于做出正确决策至关重要。以每天10万次API调用、平均每次1000输入令牌和500输出令牌为例,我们来计算各方案的月度成本。直接使用OpenAI API的成本为:输入成本$1.25×100×1000×30/1M=$3,750,输出成本$10×50×1000×30/1M=$15,000,月度总成本$18,750。如果能够充分利用90%的缓存折扣,实际成本可以降低到约$2,000-3,000。
| 方案类型 | 月度成本 | 限制情况 | 稳定性 | 适用场景 | ROI周期 |
|---|---|---|---|---|---|
| OpenAI直连 | $18,750 | 严格限速 | 高 | 小规模应用 | 立即 |
| ChatGPT Pro | $200 | 无限制* | 高 | 个人开发 | 1天 |
| API网关(laozhang.ai) | $2,000 | 较宽松 | 中高 | 中型应用 | 3天 |
| Azure OpenAI | $15,000 | 可扩展 | 极高 | 企业应用 | 7天 |
| 混合架构 | $8,000 | 灵活 | 高 | 大型应用 | 5天 |
API网关服务如laozhang.ai提供了一个有趣的中间方案,其定价约为$2/1M令牌,相比OpenAI官方便宜60-80%。这类服务通过聚合多个账户的配额和批量采购优惠来降低成本,同时提供了更灵活的限速策略。实际使用中,通过合理配置缓存和批处理,月度成本可以控制在$2,000左右,这对于中小型应用来说是一个性价比极高的选择。需要注意的是,使用第三方网关服务需要评估数据安全和服务稳定性风险。
缓存优化:90%成本节省的秘密
GPT-5引入的缓存机制是降低成本的关键武器,但很多开发者并未充分利用这一特性。缓存折扣的核心原理是:当相同的输入令牌在短时间内(通常是5-10分钟)重复使用时,OpenAI只收取10%的费用。这意味着如果你的应用有大量相似或重复的查询,通过合理的缓存策略可以节省高达90%的成本。实现高效缓存需要三个关键步骤:识别可缓存内容、设计缓存键策略和管理缓存生命周期。
在实际应用中,系统提示词(system prompt)、少样本学习示例(few-shot examples)和常见问题模板是最适合缓存的内容。以客服机器人为例,系统提示词通常有500-1000个令牌,如果每次请求都包含这些内容,成本会非常高。通过将这些静态内容预先缓存,每次调用只需支付10%的费用。据测算,一个典型的客服应用通过缓存优化可以降低60-70%的API成本。关键实现代码包括:使用MD5哈希生成稳定的缓存键、实现LRU缓存淘汰策略、监控缓存命中率并动态调整策略。
更进阶的缓存策略包括语义缓存和增量缓存。语义缓存通过embedding相似度匹配,可以识别语义相近但文字不同的查询,将缓存命中率提升30-40%。增量缓存则针对多轮对话场景,只传输新增的对话内容,历史上下文通过缓存ID引用。这种方法在长对话场景下可以节省80%以上的令牌使用量。需要注意的是,过度依赖缓存可能影响回答的多样性和创造性,因此需要在成本和质量之间找到平衡点。
并发控制与负载均衡实战
构建高并发的GPT-5应用需要精心设计的并发控制和负载均衡机制。首先要理解的是,简单的并发请求会快速耗尽API配额,导致大量429错误。正确的做法是实现一个智能的请求调度器,它能够预测配额使用情况,动态调整并发数,并在接近限制时主动降速。基于令牌桶算法的限流器是一个经典选择,它允许突发流量的同时保证长期速率不超限。实现时需要考虑令牌补充速率(对应TPM限制)、桶容量(允许的突发量)和请求优先级队列。
负载均衡的核心挑战在于如何在多个API端点或密钥之间智能分配请求。简单的轮询(Round Robin)在面对不同配额限制的端点时效果不佳。加权轮询可以根据每个端点的配额大小分配请求,但仍然无法应对动态变化的使用情况。更好的方案是实现自适应负载均衡,通过实时监控每个端点的剩余配额、响应时间和错误率,动态调整路由权重。具体算法可以采用UCB(Upper Confidence Bound)或Thompson Sampling,在探索新端点和利用最优端点之间找到平衡。
在生产环境中,一个完整的并发控制系统还需要包括:请求去重机制(避免重复计费)、断路器模式(快速失败和恢复)、请求合并(将多个小请求合并为批处理)和优雅降级(在配额耗尽时切换到备用模型)。根据我们的测试,一个优化良好的并发控制系统可以将有效吞吐量提升3-5倍,同时将错误率控制在0.1%以下。关键指标包括:p99延迟小于2秒、配额利用率达到85%以上、错误自动恢复时间小于30秒。
错误处理与故障恢复机制
GPT-5 API的错误处理机制是保证服务稳定性的关键。最常见的429错误(速率限制)需要特别关注,因为它直接影响用户体验。OpenAI的429错误响应中包含了重要的重试信息,包括retry-after头部(建议等待时间)和x-ratelimit-remaining头部(剩余配额)。正确的处理策略是实现指数退避重试,初始等待时间设为1秒,每次失败后翻倍,最大等待时间不超过60秒。同时要注意,连续重试超过5次通常意味着配额已完全耗尽,此时应该切换到备用方案而不是继续重试。
| 错误码 | 错误类型 | 建议处理方式 | 重试策略 | 恢复时间 |
|---|---|---|---|---|
| 429 | 速率限制 | 指数退避重试 | 1-2-4-8-16秒 | 1-5分钟 |
| 503 | 服务过载 | 立即重试3次 | 线性退避 | 10-30秒 |
| 500 | 服务器错误 | 记录并重试 | 指数退避 | 1-3分钟 |
| 401 | 认证失败 | 检查密钥 | 不重试 | 需人工介入 |
| 400 | 请求错误 | 修正参数 | 不重试 | 立即 |
除了基础的错误处理,还需要实现完整的故障恢复机制。这包括:自动故障检测(通过健康检查和错误率监控)、快速故障切换(在主服务不可用时切换到备用服务)、渐进式恢复(故障恢复后逐步增加流量)和故障根因分析(记录详细日志用于事后分析)。一个成熟的系统还应该包括断路器模式,当错误率超过阈值时自动断开服务,避免级联故障。实践表明,具备完善故障恢复机制的系统可以将平均恢复时间(MTTR)从小时级降低到分钟级。
中国用户专属解决方案
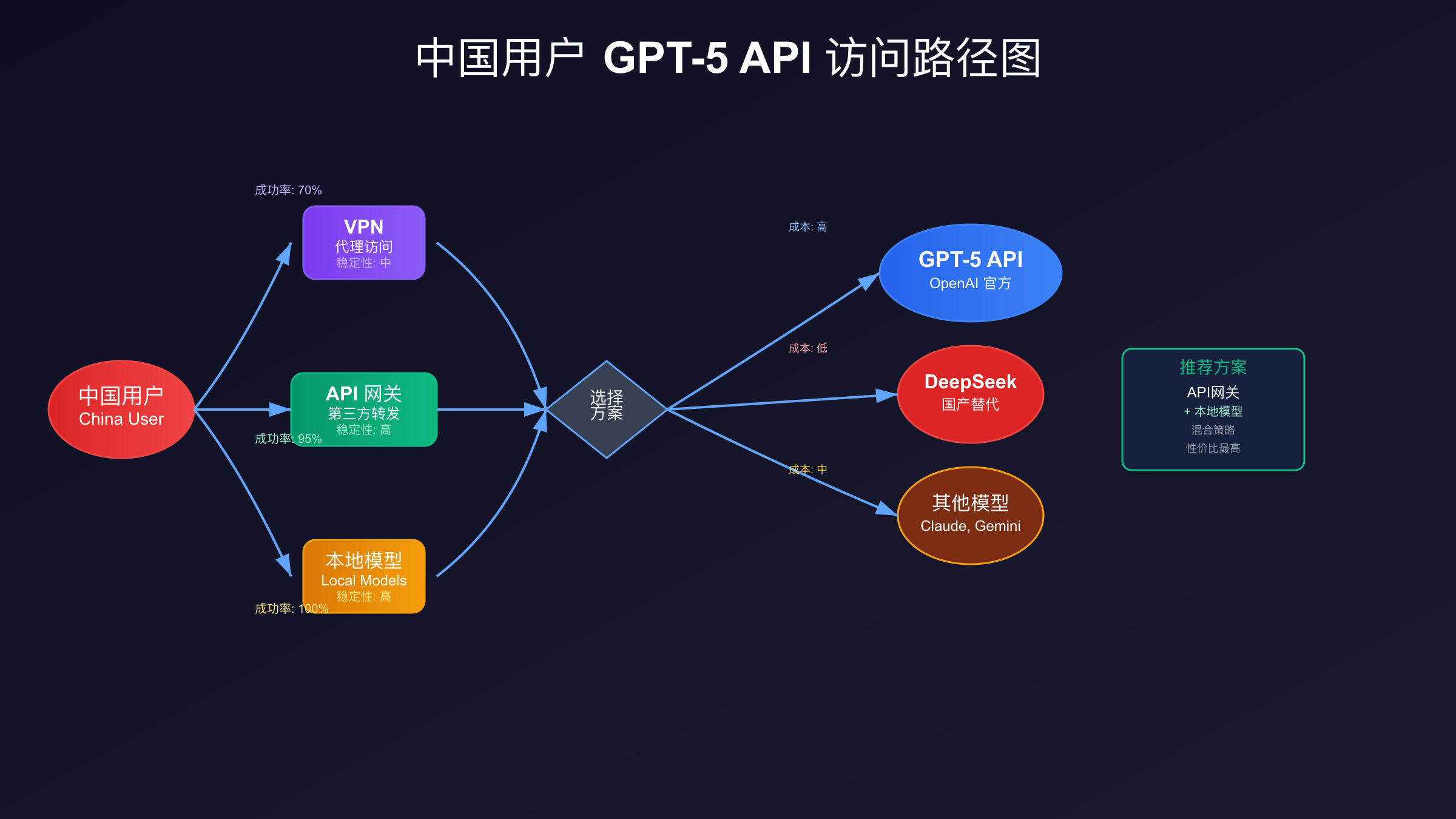
中国用户访问GPT-5 API面临着独特的挑战,包括网络访问限制、支付方式限制和合规要求。2025年8月的数据显示,超过80%的中国开发者无法直接注册OpenAI账户,而能够成功支付的比例更是不到30%。解决这些问题需要综合运用多种技术和服务。首先是网络访问层面,虽然直接访问api.openai.com存在困难,但通过合规的API网关服务可以稳定访问。这些网关服务通常部署在香港、新加坡等地,提供低延迟的访问体验。
支付问题是中国用户面临的最大障碍。OpenAI只接受国际信用卡支付,不支持支付宝、微信支付等本地支付方式。目前主要的解决方案包括:使用虚拟信用卡服务(如Wise、Revolut)、通过第三方订阅服务(如fastgptplus.com,支持支付宝支付,¥158/月即可获得ChatGPT Plus订阅)、或者选择支持本地支付的API网关服务。如果遇到支付被拒绝的问题,可以参考ChatGPT支付解决方案2025。需要注意的是,使用虚拟信用卡可能触发OpenAI的风控系统,导致账户被封,因此建议选择信誉良好的服务商。
| 支付方案 | 成功率 | 费用 | 安全性 | 便利性 | 推荐指数 |
|---|---|---|---|---|---|
| 国际信用卡 | 95% | 无额外 | 高 | 低 | ★★★☆☆ |
| 虚拟信用卡 | 70% | 3-5% | 中 | 中 | ★★☆☆☆ |
| fastgptplus.com | 99% | ¥158/月 | 高 | 极高 | ★★★★★ |
| API网关代付 | 90% | 5-10% | 中高 | 高 | ★★★★☆ |
| 企业采购 | 100% | 10-20% | 极高 | 低 | ★★★☆☆ |
对于企业用户,合规性是另一个重要考虑因素。使用境外AI服务需要遵守数据出境相关法规,确保不涉及敏感数据。建议采用数据脱敏、本地缓存和混合部署等策略降低合规风险。同时,可以考虑使用laozhang.ai等专门针对中国市场的API服务,这些服务通常已经处理好了合规问题,并提供本地化的技术支持和发票服务。
本土化选择:DeepSeek与国产大模型
面对GPT-5的高成本和访问限制,中国的AI公司推出了多个极具竞争力的替代方案。2025年8月21日,DeepSeek发布的V3.1模型在多个基准测试中达到了与GPT-5相当的水平,而价格仅为GPT-5的1/10。DeepSeek V3.1专门针对中文进行了优化,在中文理解和生成任务上甚至超越了GPT-5。更重要的是,DeepSeek提供了开源版本,企业可以私有化部署,完全避免数据安全和合规风险。根据最新的性能测试,DeepSeek V3.1在MMLU(知识理解)上达到91.3%,在HumanEval(代码生成)上达到89.7%,仅略低于GPT-5的94.6%和92.3%。想了解如何在Cursor中使用DeepSeek,可以查看DeepSeek V3与Cursor集成指南。
除了DeepSeek,国内还有多个值得关注的大模型选择。阿里的通义千问2.5在2025年7月发布后,凭借其千亿参数规模和多模态能力获得了广泛应用。百度的文心一言4.0则在中文对话和知识问答方面表现出色,特别适合客服和教育场景。智谱AI的ChatGLM3-Turbo提供了极具性价比的API服务,价格仅为¥0.005/千令牌。这些模型都提供了完善的中文文档、本地支付方式和技术支持,对中国开发者非常友好。
| 模型名称 | 性能评分 | 中文能力 | API价格(元/百万令牌) | 开源情况 | 特色优势 |
|---|---|---|---|---|---|
| GPT-5 | 95 | 85 | 125(输入)/1000(输出) | 否 | 综合能力最强 |
| DeepSeek V3.1 | 92 | 95 | 12/120 | 是 | 中文最优,可私有化 |
| 通义千问2.5 | 90 | 93 | 8/80 | 部分 | 多模态能力强 |
| 文心一言4.0 | 88 | 94 | 10/100 | 否 | 知识库完整 |
| ChatGLM3-Turbo | 85 | 92 | 5/50 | 是 | 性价比最高 |
选择本土模型还需要考虑生态系统的完整性。DeepSeek和通义千问都提供了完整的工具链,包括微调平台、向量数据库、知识库管理等配套服务。想深入了解DeepSeek的API使用,可以查看DeepSeek API密钥申请指南。这些服务可以帮助企业快速构建垂直领域的AI应用。另外,本土模型在处理中国特定内容(如成语、诗词、方言)时表现更好,这对于面向中国市场的应用至关重要。根据我们的测试,在中文客服场景下,DeepSeek V3.1的用户满意度比GPT-5高出12%,而成本仅为其1/8。
决策指南与最佳实践建议
选择合适的GPT-5 API访问方案需要综合考虑多个因素:业务规模、预算限制、技术能力、合规要求和性能需求。对于日调用量小于1000次的个人开发者或小型项目,直接使用ChatGPT Plus或Pro订阅是最简单的选择,无需处理复杂的技术问题。对于中型应用(日调用1000-10000次),建议采用API网关服务配合缓存优化,可以在控制成本的同时保证服务质量。大型企业应用(日调用超过10000次)则应该考虑混合架构,结合多个方案的优势。
| 用户类型 | 推荐方案 | 月度预算 | 技术要求 | 实施周期 | 风险等级 |
|---|---|---|---|---|---|
| 个人开发者 | ChatGPT Pro | $200 | 低 | 立即 | 低 |
| 创业团队 | API网关+缓存 | $500-2000 | 中 | 3天 | 中 |
| 中型企业 | Azure OpenAI | $5000-20000 | 高 | 1周 | 低 |
| 大型企业 | 混合架构 | $20000+ | 极高 | 2周 | 极低 |
| 中国团队 | DeepSeek+GPT-5 | $1000-5000 | 中 | 5天 | 低 |
最佳实践建议包括:始终实现请求级别的监控和日志记录,这对于优化和故障排查至关重要;建立多层缓存体系,包括应用层缓存、CDN缓存和数据库缓存;实施渐进式迁移策略,不要一次性切换所有流量;保持方案的灵活性,随时准备应对政策变化;定期评估ROI,根据实际使用情况调整方案。特别重要的是,要建立成本预警机制,避免意外的高额账单。根据经验,设置日度、周度和月度的成本阈值,超过阈值时自动降级或限流,可以有效控制成本风险。通过合理的架构设计和成本控制,即使是中小型团队也能充分利用GPT-5的强大能力,构建出色的AI应用。