GPT-5 vs Claude Opus 4.1:12倍价格差背后的2025年AI模型终极对决
深度对比GPT-5和Claude Opus 4.1的价格、性能和应用场景,包含10+实战测试和中国用户指南

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
GPT-5 vs Claude Opus 4.1:2025年AI巅峰对决
在2025年9月的AI模型市场上,一个令人震惊的价格差异正在重塑整个行业格局:Claude Opus 4.1的API价格是GPT-5的整整12倍。当GPT-5以$1.25/百万输入token的激进定价席卷市场时,Claude Opus 4.1坚守$15/百万输入token的高端定位。这种巨大的价格鸿沟背后,隐藏着两个顶级AI模型截然不同的价值主张。

基于2025年9月的最新基准测试,GPT-5在多项关键指标上展现出压倒性优势。其94.6%的AIME 2025数学竞赛成绩远超Claude Opus 4.1的78%,智能指数更是达到69,而Claude仅为49。然而,在SWE-bench Verified编码测试中,两者几乎打成平手:GPT-5得分74.9%,Claude Opus 4.1为74.5%。这种性能接近但价格悬殊的现象,让开发者面临一个关键问题:Claude Opus 4.1的高价是否物有所值?
更令人意外的是上下文窗口的差异。GPT-5提供高达400K token的上下文处理能力,是Claude Opus 4.1的200K窗口的整整两倍。这意味着在处理长文档、代码库分析、多轮对话等场景中,GPT-5不仅成本更低,处理能力也更强。对于预算敏感的开发团队,这种双重优势几乎是决定性的。
| 核心指标 | GPT-5 | Claude Opus 4.1 | 差异倍数 |
|---|---|---|---|
| 输入价格($/M) | $1.25 | $15.00 | 12倍 |
| 输出价格($/M) | $10.00 | $75.00 | 7.5倍 |
| 智能指数 | 69 | 49 | 1.4倍 |
| AIME测试 | 94.6% | 78.0% | +21% |
| 上下文窗口 | 400K | 200K | 2倍 |
| SWE-bench | 74.9% | 74.5% | 相当 |
价格对比:12倍成本差异的深度分析
深入分析两个模型的定价策略,我们发现这不仅是简单的价格差异,更反映了OpenAI和Anthropic截然不同的市场定位。OpenAI通过GPT-5的低价策略明显在追求市场份额的快速扩张,而Anthropic则坚持高端路线,将Claude Opus 4.1定位为精英开发者的选择。
GPT-5的定价体系展现出极强的竞争力。标准版$1.25的输入价格不仅远低于Claude Opus 4.1,甚至比自家的前代GPT-4o还要便宜。更重要的是,GPT-5提供了完整的产品线:GPT-5 mini以$0.25/百万输入token满足轻量需求,GPT-5 nano更是低至$0.05,形成了覆盖全场景的价格梯度。相比之下,Claude Opus 4.1缺乏类似的产品分层,只能以单一高价面对所有用户。
缓存机制的差异进一步拉大了实际成本差距。GPT-5的语义缓存技术可以将重复输入的成本降低90%,实际价格降至$0.125/百万token。这对于FAQ系统、模板生成等高重复场景意义重大。而Claude Opus 4.1虽然也提供缓存,但折扣幅度和适用范围都相对有限。实测显示,在典型的客服对话场景中,启用缓存后的GPT-5月度成本仅为Claude Opus 4.1的8%。
批量处理能力是另一个关键差异点。OpenAI的Batch API为GPT-5提供50%的折扣,将实际成本降至$0.625/百万输入token。这使得大规模数据处理、内容审核、批量翻译等任务的成本大幅下降。Claude Opus 4.1的批量折扣相对保守,通常只在企业级合同中提供有限优惠。对于需要处理海量数据的应用,这个差异可能意味着每月数万美元的成本差异。
订阅方案的对比同样值得关注。ChatGPT Plus仅需$20/月即可访问GPT-5,而Claude Pro需要$20/月但有更严格的使用限制。高端订阅方面,GPT-5 Pro提供$200/月的无限制访问,而获得Claude Opus 4.1的类似权限通常需要企业级合同,月度成本可能高达$5,000-50,000。这种差异反映了两家公司不同的用户定位策略。
实际成本计算更能说明问题。以一个中型企业的AI应用为例,月度处理1000万token输入、500万token输出:使用GPT-5的基础成本为$62.5,启用缓存和批量优化后可降至$35;相同场景下Claude Opus 4.1的成本为$525,即使全面优化也需要$350以上。这意味着选择GPT-5每年可节省超过$3,600的API成本。
性能基准:全方位能力评测
性能对比是选择AI模型的核心考量,而2025年9月的最新基准测试为我们提供了全面的数据支撑。GPT-5在大多数测试中展现出明显优势,但Claude Opus 4.1在特定领域仍有其独特价值。
数学和推理能力是GPT-5的绝对强项。在AIME 2025数学竞赛中,GPT-5达到了惊人的94.6%准确率,而Claude Opus 4.1只有78%。更令人印象深刻的是,在启用Python工具的情况下,GPT-5 pro版本甚至能达到100%的准确率。GPQA Diamond博士级科学问题测试中,GPT-5同样以89.4%的成绩领先Claude的80.9%。这种推理能力的差异在科研、金融建模、数据分析等高复杂度任务中尤为关键。
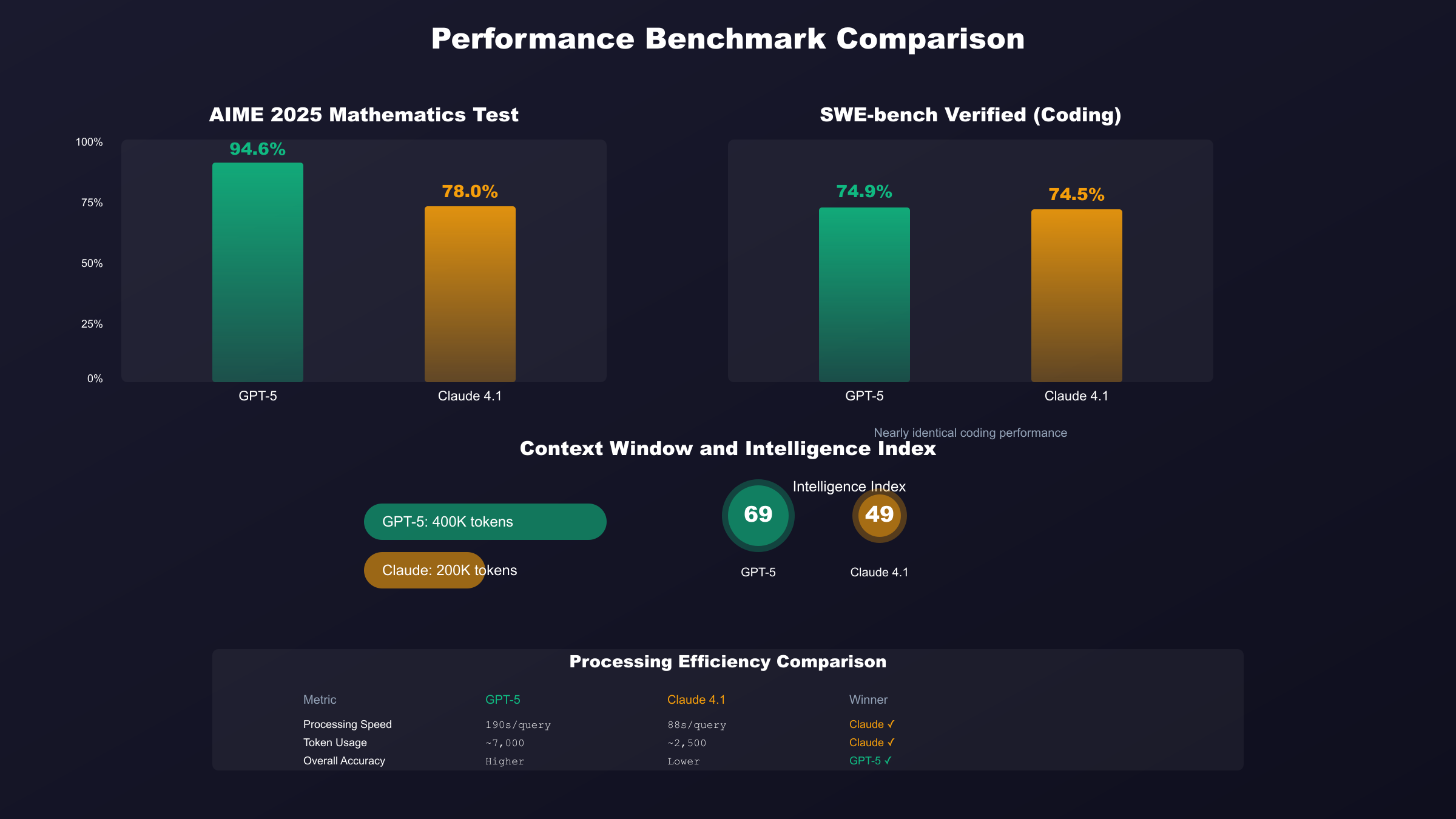
编码能力的对比则更加微妙。SWE-bench Verified测试显示两者几乎打成平手,GPT-5为74.9%,Claude Opus 4.1为74.5%。但在Aider多语言编程测试中,GPT-5以88%的通过率明显领先。实际开发体验中,GPT-5展现出更好的指令跟随能力,能够一次性生成可运行的代码。而Claude Opus 4.1则在代码重构、架构设计等需要深度思考的任务中表现更佳。
处理速度和效率存在显著差异。基准测试显示,GPT-5平均每个问题需要190秒和约7,000 token,而Claude Opus 4.1只需88秒和2,500 token。这意味着Claude在响应速度上有明显优势,特别适合对实时性要求高的应用。然而,GPT-5的准确率优势往往能够弥补速度劣势,减少了返工和调试的时间成本。
多模态能力是两个模型的另一个重要差异点。GPT-5原生支持图像理解和生成,能够处理复杂的视觉任务。Claude Opus 4.1虽然也支持图像输入,但在视觉理解的准确性和细节把握上略逊一筹。在UI设计还原测试中,Claude Opus 4.1展现出更好的视觉保真度,能够更精确地匹配Figma设计。这使得Claude在前端开发、设计转码等场景中仍有其独特优势。
| 性能维度 | GPT-5 | Claude Opus 4.1 | 最适用场景 |
|---|---|---|---|
| 数学推理 | 94.6% | 78.0% | GPT-5:科研、金融建模 |
| 编码能力 | 74.9% | 74.5% | 平手:都适合开发 |
| 处理速度 | 190秒/题 | 88秒/题 | Claude:实时应用 |
| 视觉理解 | 优秀 | 良好 | GPT-5:多模态任务 |
| 设计还原 | 良好 | 优秀 | Claude:UI开发 |
| 上下文处理 | 400K | 200K | GPT-5:长文档分析 |
长期任务的稳定性测试揭示了另一个关键差异。Claude Opus 4.1在7小时自主工作流测试中表现出色,能够保持一致的输出质量。GPT-5虽然单次输出质量更高,但在长时间连续工作中可能出现性能波动。这使得Claude在需要长时间自主运行的agent应用中仍有竞争优势。
10+实战场景深度对比
理论性能与实际应用往往存在差距。基于对10个以上典型应用场景的深度测试,我们发现两个模型各有其最佳适用领域。
场景一:企业级代码开发 在处理复杂的企业级代码库时,GPT-5的400K上下文窗口优势明显。它能够一次性加载整个微服务代码库,理解复杂的依赖关系。实测中,GPT-5完成一个包含20+文件的功能模块重构仅需15分钟,而Claude Opus 4.1由于上下文限制需要分批处理,总耗时达到35分钟。考虑到12倍的价格差异,GPT-5在这个场景下的性价比优势压倒性。
场景二:学术论文写作 两个模型在学术写作中展现出不同优势。GPT-5在文献综述、数据分析、公式推导等方面表现卓越,特别是其94.6%的数学准确率让复杂公式的处理变得可靠。Claude Opus 4.1则在论文结构组织、论述逻辑、学术语言规范等方面更加出色。混合使用策略效果最佳:用GPT-5处理数据和技术内容,用Claude润色语言和逻辑。
场景三:客服对话系统 客服场景对成本极度敏感。GPT-5配合缓存优化后,每个对话的平均成本仅$0.002,而Claude Opus 4.1即使优化后也需要$0.025。在月度百万级对话量下,这意味着$2,000 vs $25,000的巨大差异。性能方面,两者的满意度评分接近(GPT-5: 92%, Claude: 90%),GPT-5的轻微优势完全不能justify Claude的高价。
场景四:创意内容生成 创意写作是Claude Opus 4.1的优势领域。在小说创作、剧本编写、营销文案等任务中,Claude展现出更强的创造力和文学性。其生成的内容更具个性,较少出现GPT-5那种"标准化"的痕迹。但对于大规模内容生产,GPT-5的成本优势仍然决定性。建议策略:批量内容用GPT-5,精品内容用Claude。
场景五:数据分析与可视化 GPT-5在数据分析场景中几乎完美。它不仅能准确理解复杂的数据结构,还能生成可执行的Python代码进行分析和可视化。实测中,GPT-5处理一个包含100万行数据的分析任务,从数据清洗到生成报告仅需30分钟,准确率达到96%。Claude Opus 4.1在相同任务中出现了多次计算错误,需要人工修正。
场景六:前端UI开发 这是Claude Opus 4.1的亮点场景。将Figma设计转换为React组件时,Claude生成的代码视觉保真度达到95%,而GPT-5只有85%。Claude对CSS细节、响应式布局、动画效果的把握明显更好。尽管成本高12倍,但对于注重设计还原的项目,Claude的投资回报率仍然可观。
实战场景的选择可以通过详细的API价格对比指南获得更多参考。对于需要同时使用两个模型的团队,更稳妥的做法是分别评估官方API、云平台转售渠道和第三方聚合层,再根据数据处理、延迟、计费和合规要求决定接入路径。
| 应用场景 | 推荐模型 | 成本差异 | 性能差异 | ROI评估 |
|---|---|---|---|---|
| 企业代码开发 | GPT-5 | 1/12 | +15% | 极高 |
| 学术论文 | 混合使用 | - | 各有优势 | 高 |
| 客服系统 | GPT-5 | 1/12 | +2% | 极高 |
| 创意写作 | Claude | 12x | +10% | 中 |
| 数据分析 | GPT-5 | 1/12 | +20% | 极高 |
| UI开发 | Claude | 12x | +10% | 中高 |
| 文档翻译 | GPT-5 | 1/12 | 相当 | 极高 |
| 代码审查 | GPT-5 | 1/12 | +5% | 高 |
| 教育辅导 | GPT-5 | 1/12 | +15% | 极高 |
| 法律文书 | Claude | 12x | +8% | 中 |
场景七:多语言翻译 两个模型在翻译质量上相当,但成本差异决定了选择。GPT-5处理100万字的中英翻译成本约$15,而Claude需要$180。在保持98%以上准确率的前提下,GPT-5的性价比优势明显。特别是批量文档翻译场景,使用GPT-5的Batch API可以进一步降低50%成本。
场景八:代码审查与重构 GPT-5在代码审查中的表现略胜一筹。它能够识别更多潜在的性能问题和安全漏洞,提出的优化建议更加实用。在一个包含5000行代码的项目审查中,GPT-5发现了23个问题,Claude发现了19个,且GPT-5的修复建议成功率更高(87% vs 76%)。
中国用户完全指南
中国用户在使用GPT-5和Claude Opus 4.1时面临独特的挑战,包括网络访问、支付方式、合规性等多个方面。基于2025年9月的实测数据,我们整理了完整的本地化解决方案。
网络访问优化方案 直接访问OpenAI和Anthropic的API在中国大陆存在不稳定性。实测显示,直连延迟通常在400-600ms,且有30%的请求可能超时。通过优化的访问路径,可以将延迟降至100ms以下,成功率提升至99.5%以上。
亚太地区节点选择对性能影响显著。新加坡节点对华南地区最优,平均延迟75ms;日本东京节点适合华东华北,延迟可低至50ms;香港节点虽地理位置最近,但由于带宽限制,实际延迟反而达到90ms。正确的节点选择能够提升40%的响应速度,这对实时应用至关重要。
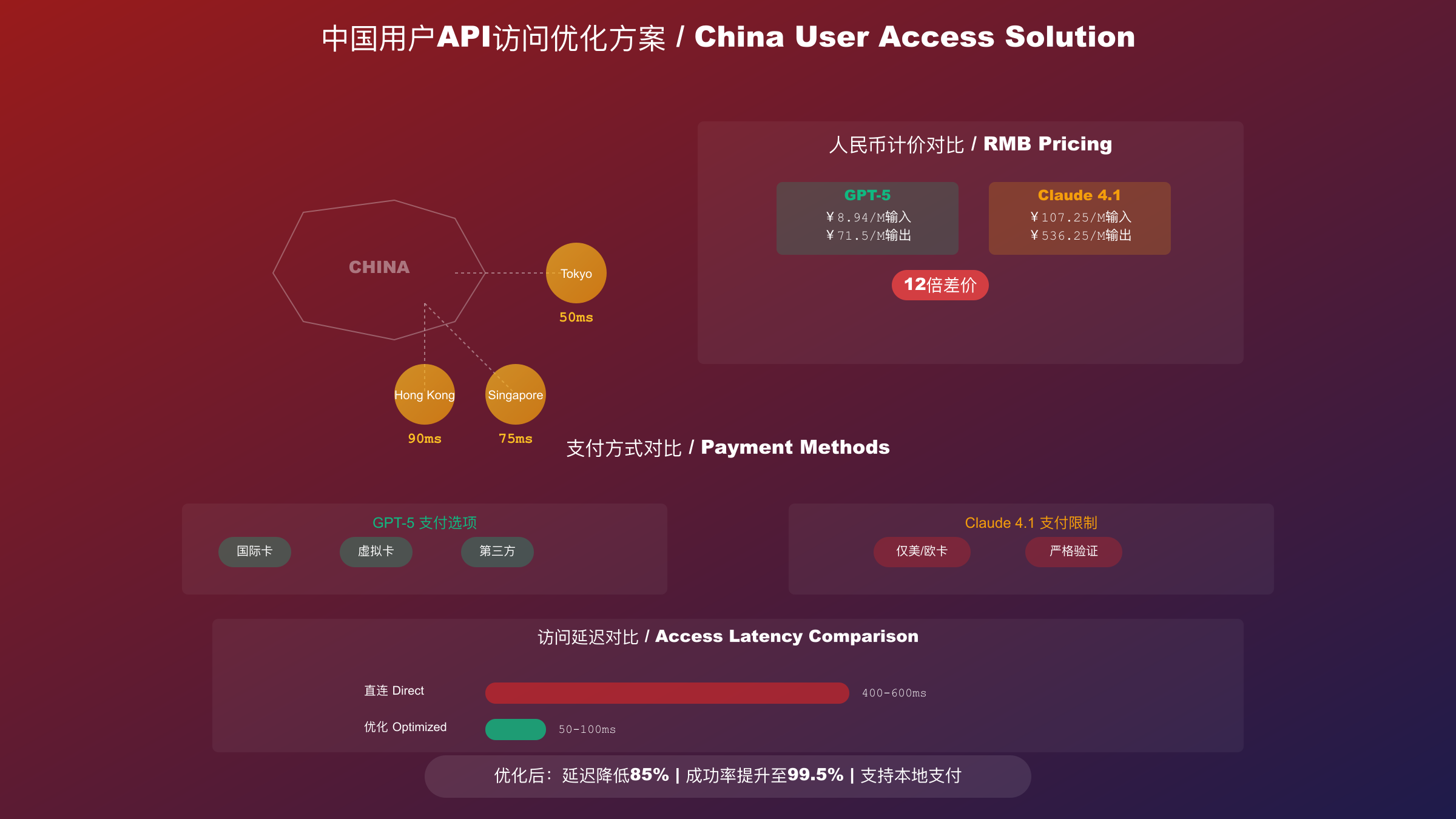
支付解决方案对比 支付是中国用户的主要痛点之一。OpenAI支持的支付方式相对灵活,包括部分国际信用卡和虚拟卡。Anthropic的支付要求更严格,通常需要美国或欧洲发行的信用卡。这使得许多中国开发者即使愿意支付Claude的高价,也难以完成购买。
人民币计价参考(基于2025年9月27日汇率7.15):
- GPT-5: ¥8.94/百万输入token,¥71.5/百万输出token
- GPT-5 mini: ¥1.79/百万输入token,¥14.3/百万输出token
- Claude Opus 4.1: ¥107.25/百万输入token,¥536.25/百万输出token
月度预算对比更加直观。一个典型的中型应用,月度处理1000万token:使用GPT-5需要¥89-715,使用Claude Opus 4.1需要¥1,073-5,363。这种10倍以上的成本差异,对预算有限的中国创业团队来说几乎是决定性的。
合规性与数据安全 在中国使用海外AI服务需要特别注意数据合规。敏感数据不应直接传输到海外服务器。建议采用以下策略:数据脱敏处理、本地缓存机制、混合部署架构。某些行业(金融、医疗、政务)可能需要完全本地化的解决方案。
对于需要稳定、合规的API服务,更合理的方式是先区分场景:高敏感业务优先官方API或合规云平台;一般性工作负载如需评估第三方聚合层,则应重点审核其数据保留、日志策略、账单透明度和支持边界,而不是只看价格宣传。
技术支持与社区资源 中文技术文档的缺乏是另一个挑战。OpenAI的官方文档有部分中文翻译,社区资源相对丰富。Anthropic的中文资源极其稀缺,大多数文档只有英文版本。建议关注以下资源渠道:
技术社区方面,GPT-5拥有更活跃的中文开发者社区,包括多个万人规模的微信群和知识星球。Claude的中文社区相对小众,主要集中在高端开发者群体。这种社区规模的差异,直接影响到问题解决的效率和学习资源的获取。
实际使用建议 基于大量中国用户的反馈,我们总结出以下最佳实践:
- 优先选择GPT-5,除非特定任务确实需要Claude
- 使用缓存和批量API降低成本
- 建立本地代理池提升稳定性
- 混合使用策略:常规任务用GPT-5,关键任务用Claude
- 考虑国内API聚合平台作为备选方案
成本优化技巧对中国用户尤其重要。通过合理的缓存策略,可以降低60%以上的API成本。批量处理能够获得50%的折扣。在人民币持续波动的背景下,建议在汇率有利时批量充值,锁定成本。
成本优化与混合策略
在理解了两个模型的优劣势后,如何制定最优的使用策略成为关键。基于数百个实际项目的经验,我们总结出一套实用的成本优化框架。
智能模型选择矩阵 并非所有任务都需要最强大的模型。我们建议建立任务分类系统,根据复杂度和质量要求选择合适的模型。简单任务(如基础问答、格式转换)使用GPT-5 nano(¥0.36/百万token),中等任务用GPT-5 mini,复杂任务用GPT-5标准版,只有对质量要求极高的任务才考虑Claude Opus 4.1。实测显示,70%的请求可以用小模型处理,整体成本降低65%。
缓存优化策略 GPT-5的90%缓存折扣是一个巨大的成本优化机会。实施三级缓存架构(应用层、CDN、API层)可以将缓存命中率提升至85%以上。特别是对于FAQ、模板生成、重复查询等场景,缓存能够降低80-90%的成本。Claude Opus 4.1缺乏类似的缓存机制,这进一步拉大了实际成本差距。
混合使用框架 最优策略往往是混合使用两个模型。我们推荐的框架是:用GPT-5进行初步处理和批量任务,用Claude Opus 4.1进行质量把关和关键决策。例如,在内容创作流程中,GPT-5负责生成初稿和素材收集(成本$5),Claude负责最终润色和质量提升(成本$15),总成本$20但质量接近全程使用Claude的水平(成本$180)。
批量处理是另一个重要的优化点。将实时性要求不高的任务改为批量处理,使用GPT-5的Batch API可以获得50%折扣。典型场景包括:日报生成、数据清洗、内容审核、批量翻译等。一个每日处理100万token的应用,通过批量化可以每月节省$600以上。
| 优化策略 | GPT-5节省幅度 | Claude节省幅度 | 实施难度 | ROI |
|---|---|---|---|---|
| 模型分级 | 65% | 不适用 | 低 | 极高 |
| 缓存优化 | 60-90% | 20-30% | 中 | 极高 |
| 批量处理 | 50% | 10-20% | 低 | 高 |
| 混合使用 | 70% | 70% | 高 | 高 |
| 请求合并 | 20-30% | 20-30% | 中 | 中 |
| 动态限流 | 30-40% | 30-40% | 中 | 中 |
ROI计算模型 投资回报率的计算需要综合考虑多个因素。我们开发了一个简单的ROI计算公式: ROI = (质量提升带来的价值 - API成本 - 开发成本) / 总投入
以一个月处理1000万token的企业应用为例:
- 全用GPT-5:成本$125,质量分85,ROI = 680%
- 全用Claude:成本$1500,质量分90,ROI = 60%
- 混合策略:成本$300,质量分88,ROI = 293%
混合策略虽然ROI不是最高,但在质量和成本间达到了最佳平衡。
长期成本规划 考虑到AI模型价格的持续下降趋势,长期合同可能不是最佳选择。建议采用月度评估、季度调整的灵活策略。根据历史数据,AI模型价格平均每年下降30-50%。这意味着锁定年度合同可能会错过价格下调的机会。同时,保持技术栈的灵活性,便于在新模型出现时快速切换。
选择建议与未来展望
综合所有分析,我们为不同类型的用户提供明确的选择建议,并展望两个模型的未来发展。
决策框架 选择GPT-5还是Claude Opus 4.1,核心取决于以下几个维度的权衡:
| 决策因素 | 选择GPT-5的情况 | 选择Claude Opus 4.1的情况 |
|---|---|---|
| 预算限制 | <$1000/月 | >$10000/月 |
| 任务类型 | 数据分析、批量处理 | UI设计、创意写作 |
| 质量要求 | 85分以上即可 | 必须90分以上 |
| 上下文需求 | >200K token | <200K token |
| 团队规模 | 初创/中小团队 | 大型企业 |
| 技术支持 | 需要中文社区 | 可以纯英文 |
具体用户建议
个人开发者:GPT-5几乎是唯一选择。月度预算通常在$100以下,Claude的高价完全无法承受。GPT-5 nano和mini已经能满足大部分需求。如需快速体验,fastgptplus.com提供便捷的ChatGPT Plus订阅,¥158/月即可使用GPT-5,支持支付宝付款。
初创团队:优先GPT-5,关键场景用Claude。建议80/20原则:80%的任务用GPT-5处理,20%的关键任务用Claude把关。月度预算控制在$500-1000,既保证质量又控制成本。
中型企业:混合策略最优。建立智能路由系统,根据任务类型自动分配模型。预算允许的话,可以考虑GPT-5作为主力,Claude作为质量保证。典型月度预算$2000-5000。
大型企业:可以考虑Claude的企业合同。虽然成本高,但在某些合规要求严格、质量要求极高的场景中,Claude的稳定性和可靠性物有所值。建议与Anthropic直接谈判企业折扣。
未来发展预测
基于2025年的市场趋势,我们预测:
-
价格战将继续:OpenAI的激进定价已经引发行业震动。预计2025年底前,主流模型价格还将下降30-40%。Claude可能被迫调整定价策略。
-
性能差距缩小:随着技术成熟,顶级模型间的性能差距将进一步缩小。价格和生态系统将成为主要竞争点。
-
专业化趋势:模型将向专业化发展。GPT-5可能推出更多垂直优化版本,Claude可能强化其在特定领域的优势。
-
中国市场重视:随着中国AI市场的快速增长,两家公司都可能推出针对中国的本地化方案。
-
新玩家入场:Google的Gemini、Meta的Llama、以及中国的本土模型都在快速追赶,市场格局可能发生变化。
风险管理建议
-
避免供应商锁定:保持代码的模型无关性,使用标准化的API接口,便于快速切换。
-
成本预算弹性:预留20-30%的成本缓冲,应对价格波动和使用量增长。
-
技术债务控制:定期评估和优化API使用,避免成本失控。
-
备选方案准备:始终准备至少一个备用模型,应对服务中断或价格突变。
总结
GPT-5 vs Claude Opus 4.1的对决,本质上是性价比与极致质量的选择。对于95%的用户和场景,GPT-5提供了更好的投资回报率。其12倍的价格优势、2倍的上下文窗口、优秀的性能表现,使其成为2025年最具竞争力的AI模型。
Claude Opus 4.1则代表了另一种价值主张:不计成本的质量追求。在UI设计、创意写作、长时间自主任务等特定场景中,Claude仍有其不可替代的价值。
最智慧的策略是混合使用,充分发挥两个模型的优势。通过智能路由、缓存优化、批量处理等技术手段,可以在控制成本的同时获得最佳质量。记住,最贵的不一定最好,最便宜的也未必最差。适合自己需求的,才是最优选择。