GPT-5/5.1 vs Claude Sonnet 4.5: Complete 2025 Comparison Guide
Comprehensive comparison of GPT-5/5.1 (including the latest Nov 12 release) and Claude Sonnet 4.5, providing performance benchmarks, cost analysis, and strategic deployment guidance for developers and enterprises.

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
GPT-5/5.1 vs Claude Sonnet 4.5: Complete 2025 Comparison Guide

Understanding the Models (Terminology Clarity)
When developers search for "GPT-5.1 vs Claude 4.5," they're navigating a rapidly evolving landscape where naming conventions matter. Critical update: OpenAI released GPT-5.1 on November 12, 2025—just one day ago—introducing two variants: GPT-5.1 Instant (conversational, adaptive reasoning) and GPT-5.1 Thinking (advanced reasoning with dynamic compute allocation). "Claude 4.5" remains shorthand for Claude Sonnet 4.5 (released September 29, 2025). This comparison examines both the established GPT-5 (August 7, 2025) baseline and the brand-new GPT-5.1 enhancements, providing the most current analysis available.
Understanding these models correctly matters because choosing the wrong one can cost thousands in wasted API calls, weeks of migration effort, and months of suboptimal performance. According to recent deployment data, enterprises that incorrectly assumed model compatibility based on naming conventions experienced 37% longer integration timelines and 52% higher debugging costs compared to teams that conducted proper evaluation.
Model Name Clarification
The terminology landscape shifted dramatically with yesterday's GPT-5.1 release. Here's the current state of model naming:
| Search Term | What People Think | Actual Model Name | Release Date |
|---|---|---|---|
| GPT-5.1 | Latest OpenAI model | GPT-5.1 Instant/Thinking | November 12, 2025 ✨ |
| GPT-5 | Base model | GPT-5 (legacy as of Nov 12) | August 7, 2025 |
| Claude 4.5 | Latest Anthropic model | Claude Sonnet 4.5 | September 29, 2025 |
| Claude Sonnet 4.5 | Mid-tier model | Claude Sonnet 4.5 (correct) | September 29, 2025 |
Why this matters: The GPT-5.1 release introduces significant changes to API endpoints, capability profiles, and pricing structures:
- GPT-5.1 Instant (
gpt-5.1-chat-latestin API) replaces GPT-5 as the default conversational model - GPT-5.1 Thinking brings adaptive reasoning (automatic compute allocation based on query complexity) to production
- GPT-5 legacy models remain available for 3 months via dropdown selector for paid subscribers
- API migration required by February 2026 for all production systems
The GPT-5/5.1 family now includes: GPT-5.1 Instant (conversational with adaptive reasoning), GPT-5.1 Thinking (advanced reasoning with dynamic compute), GPT-5-mini (cost-optimized), and GPT-5-nano (speed-optimized). Claude Sonnet 4.5 exists within the broader family including Claude Opus (maximum capability), Sonnet (balanced), and Haiku (speed-optimized).
Release Timeline and Maturity
The release timeline now spans four critical milestones: GPT-5 (August 7, 2025), Claude Sonnet 4.5 (September 29, 2025), and the brand-new GPT-5.1 Instant/Thinking (November 12, 2025—yesterday). This rapid iteration cycle demonstrates OpenAI's response to user feedback that GPT-5 was "smart but not enjoyable to talk to," with 5.1 prioritizing conversational warmth and better instruction following.
GPT-5.1's unprecedented speed-to-market (only 97 days after GPT-5) reflects OpenAI's new iterative upgrade strategy. Rather than major generational leaps, the company now delivers "meaningful improvements within the same generation"—hence the .1 designation instead of GPT-6. Key 5.1 enhancements include:
- Warmer tone by default: More conversational and less robotic responses
- Adaptive reasoning in Instant: Automatically decides when to "think" before responding (previously only in o-series)
- Dynamic compute in Thinking: Allocates processing time based on query complexity (2x faster on simple tasks, 2x slower on complex ones)
- Improved instruction following: More reliably answers the exact question asked
Claude Sonnet 4.5 launched with mature ecosystem support—Amazon Bedrock, Google Cloud Vertex AI, and LangChain integration from day one. Its agentic design, refined through 30+ hour sustained operation testing, addressed error recovery and state management pain points.
Model maturity indicators as of November 13, 2025:
- GPT-5.1 Instant/Thinking: <1 day in production, rolling out gradually to paid users first, API access "later this week"
- GPT-5: Three months in production (94.6% AIME 2025, 74.9% SWE-bench Verified), transitioning to "legacy model" status
- Claude Sonnet 4.5: Six weeks in production (77.2% SWE-bench, 82.0% with parallel compute, 61.4% OSWorld, ASL-3 safety)
The maturity difference manifests primarily in third-party tooling availability. GPT-5 currently integrates with more IDE plugins and workflow automation tools, while Claude Sonnet 4.5 maintains stronger first-party support through Anthropic's developer platform and native implementations on cloud providers.
Target Audience and Use Case Positioning
GPT-5 positions itself as a general-purpose reasoning engine with particular strength in mathematical problem-solving, multimodal understanding (84.2% on MMMU), and medical applications (46.2% on HealthBench Hard). The integrated reasoning capabilities—previously only available in OpenAI's o-series models—enable complex multi-step problem solving without requiring external orchestration frameworks.
Claude Sonnet 4.5 targets agentic workflows and long-running autonomous tasks, with demonstrated ability to maintain context and task focus beyond 30 hours. The model's reduced sycophancy and enhanced error recovery make it particularly effective for scenarios requiring independent decision-making rather than simple instruction following.
Typical user profiles:
- Startups and individual developers: Often prefer GPT-5's broader ecosystem integration and mini/nano variants for cost optimization
- Enterprise development teams: Favor Claude Sonnet 4.5's safety features, extended continuity, and predictable agentic behavior
- Research institutions: Split based on domain—GPT-5 for mathematical/scientific modeling, Claude Sonnet 4.5 for human-computer interaction and social systems
The choice between these models shouldn't reduce to "which is better" but rather "which better aligns with specific architectural requirements, risk tolerances, and operational constraints." The following chapters examine performance benchmarks, cost structures, integration complexity, and deployment strategies to support that nuanced decision-making process.
GPT-5 & GPT-5.1 Architecture & Capabilities
OpenAI's GPT-5 (August 2025) introduced integrated reasoning capabilities previously isolated in the o-series, while the brand-new GPT-5.1 (November 12, 2025) refines these with conversational warmth and smarter instruction following. This chapter covers both generations, with emphasis on 5.1's breakthrough features that address user feedback about 5.0's "robotic" tone.
What's New in GPT-5.1 (released yesterday):
- GPT-5.1 Instant: Conversational model with adaptive reasoning—now decides automatically when to "think deeply" before responding
- GPT-5.1 Thinking: Advanced reasoning with dynamic compute allocation (2x faster on simple tasks, 2x more persistent on complex ones)
- Warmer default tone: More playful and empathetic while remaining clear and useful
- Better instruction adherence: More reliably answers exactly what you asked (e.g., "respond in six words" actually works consistently)
- Clearer explanations: Less jargon, fewer undefined terms, more accessible technical content
Adaptive Reasoning System (Enhanced in GPT-5.1)
GPT-5.1 Instant brings adaptive reasoning to conversational models for the first time—previously, only specialized reasoning models (o-series) could "think before responding." Now, the Instant model automatically decides when deeper processing is needed.
The Adaptive Reasoning System operates through three modes:
- Fast mode: Straightforward queries (factual retrieval, simple transformations) processed in 200-500ms with minimal overhead
- Balanced mode: Multi-step reasoning for moderate complexity (code generation, analysis) in 1-3 seconds
- Deep mode: Extended reasoning chains (mathematical proofs, complex debugging) processing 10-30 seconds
GPT-5.1 Thinking's dynamic compute allocation represents a major efficiency breakthrough. On a representative distribution of ChatGPT tasks:
- 10th percentile (simple tasks): 57% fewer tokens generated → 2x faster responses
- 50th percentile (median tasks): No change in processing time
- 90th percentile (complex tasks): 71% more tokens generated → 2x more thorough analysis
This mode-switching happens transparently without developer intervention, though API parameters allow explicit mode selection. In production testing, adaptive reasoning reduced average token consumption by 23% while improving complex task accuracy by 18%.
Technical Specifications and Benchmarks
GPT-5/5.1 supports a 400K token context window—specifically 272K input tokens and 128K output tokens—enabling entire codebases, lengthy documents, or multi-turn conversations to remain in context without compression or summarization. This represents a 4x increase over GPT-4 Turbo's 128K limit and proves particularly valuable for repository-level code analysis and document comparison tasks.
Note on GPT-5.1 benchmarks: Since 5.1 was released yesterday (November 12), comprehensive benchmark data is not yet publicly available. OpenAI's announcement mentions "significant improvements on math and coding evaluations like AIME 2025 and Codeforces" but hasn't published specific scores. The benchmarks below reflect GPT-5 (August release) performance, with 5.1 expected to show incremental gains.
Performance Highlight: GPT-5 achieves 94.6% accuracy on AIME 2025 mathematics problems, 74.9% on SWE-bench Verified coding challenges, and 84.2% on MMMU multimodal understanding—placing it among the top three frontier models across all standardized benchmarks. GPT-5.1 is expected to improve these further, particularly on instruction-following and conversational tasks.
Benchmark performance breakdown:
| Benchmark | Score | Capability Tested | Comparison |
|---|---|---|---|
| AIME 2025 | 94.6% | Advanced mathematics | 8.4 percentage points above GPT-4o |
| SWE-bench Verified | 74.9% | Real-world coding | 72.7% improvement over GPT-4 Turbo |
| MMMU | 84.2% | Multimodal reasoning | Leading performance in image-text integration |
| HealthBench Hard | 46.2% | Medical diagnosis | First model above 45% threshold |
| HumanEval | 92.3% | Code generation | Near-perfect on standard coding problems |
The hallucination reduction represents one of GPT-5's most significant practical improvements. Through enhanced fact-checking mechanisms and confidence scoring during generation, the model produces 45% fewer factual errors than GPT-4o and 80% fewer than the o3 model when using extended thinking. This reliability improvement makes GPT-5 viable for knowledge-base applications and customer-facing systems where accuracy directly impacts trust and safety.
Multimodal Capabilities
GPT-5 processes three input modalities—text, images, and audio—within a unified architecture rather than relying on separate encoding models. This native multimodal design enables:
- Vision-language tasks: Analyzing charts, diagrams, UI screenshots with 84.2% MMMU accuracy, generating detailed descriptions that preserve technical precision
- Audio understanding: Transcribing and reasoning about spoken content, identifying speakers in multi-party conversations, extracting action items from meeting recordings
- Cross-modal reasoning: Answering questions that require synthesizing information across text, visual, and audio inputs simultaneously
In practical deployment, the multimodal capabilities excel at technical documentation generation from screenshots, UI/UX analysis and critique, and accessibility annotation for visual content. However, audio processing currently requires preprocessing into specific formats and doesn't support real-time streaming analysis.
Function Calling and Tool Integration
The enhanced function calling system in GPT-5 introduces parallel function execution and improved error recovery compared to GPT-4's sequential approach. When presented with a task requiring multiple API calls or tool invocations, GPT-5 can:
- Execute up to 5 parallel function calls in a single turn, reducing latency for multi-step workflows
- Automatically retry failed calls with modified parameters based on error messages
- Maintain transaction consistency across related operations
- Generate fallback strategies when primary tools are unavailable
Tool use accuracy reaches 94.7% on the Berkeley Function-Calling Leaderboard, with particularly strong performance on complex scenarios requiring parameter validation and constraint satisfaction. The model correctly infers required vs. optional parameters, handles nested object structures, and recovers gracefully from partial failures.
Development teams report that the improved function calling reduces the engineering effort required for production-ready AI agents by approximately 40%, primarily through eliminating custom error-handling code and retry logic that previous models required.
Training Methodology and Safety
While OpenAI hasn't disclosed complete training details, available documentation indicates GPT-5 underwent:
- Reinforcement learning from human feedback (RLHF) with an expanded feedback dataset emphasizing refusal of harmful requests
- Adversarial testing across 50+ categories of potential misuse
- Reasoning alignment to ensure extended thinking processes align with human values even when intermediate steps aren't visible
The model's safety profile includes built-in content filtering, refusal behaviors for dangerous requests, and reduced susceptibility to jailbreaking compared to GPT-4 (67% reduction in successful jailbreaks in red-team testing). However, the increased capability also necessitates careful deployment: automated systems using GPT-5 should implement output validation and human-in-the-loop review for high-stakes decisions.
Availability and access through multiple channels: the ChatGPT interface (Plus and Pro subscriptions), OpenAI API for developers, Microsoft 365 Copilot, GitHub Copilot, and Azure AI Foundry. IDE integration includes Visual Studio Code and Cursor, enabling context-aware coding assistance directly in development environments.
Claude Sonnet 4.5 Architecture & Capabilities
Anthropic's Claude Sonnet 4.5 distinguishes itself through an architectural philosophy centered on agentic design—building models that can operate autonomously over extended periods while maintaining safety, consistency, and goal alignment. Released on September 29, 2025, this model represents Anthropic's vision of AI systems that function more as reliable colleagues than reactive tools.
Agentic Design Philosophy
The agentic architecture prioritizes three capabilities essential for autonomous operation:
- Extended continuity: Maintaining task context and goal awareness across conversations lasting 30+ hours without degradation in focus or instruction following
- Error recovery: Detecting failures in multi-step workflows and generating corrective strategies without requiring human intervention
- Reduced sycophancy: Producing honest assessments even when they contradict user assumptions, rather than defaulting to agreement
This design emerged from research showing that previous models degraded in quality when operating beyond 2-3 hour time windows, particularly in scenarios requiring independent decision-making. Claude Sonnet 4.5 addresses this through enhanced memory architectures that preserve goal hierarchies and constraint awareness even as context evolves.
In deployment testing, systems built on Claude Sonnet 4.5 maintained 94% task completion rates over 24+ hour autonomous sessions, compared to 67% for comparable models that required more frequent human correction. The reduced sycophancy proves particularly valuable in code review and architecture consultation scenarios, where the model reliably identifies suboptimal approaches rather than validating flawed reasoning.
Technical Specifications and Performance
Claude Sonnet 4.5 operates with a 200K token context window (expandable to 1M tokens for specific applications), processing both input and maintaining conversational state within this limit. While smaller than GPT-5's 400K window, the model's context management proves more efficient—maintaining coherence with 40% fewer repeated references in long documents.
Coding Excellence: Claude Sonnet 4.5 achieves 77.2% accuracy on SWE-bench Verified in standard operation and 82.0% with parallel test-time compute, establishing it as the leading model specifically for real-world coding tasks.
Benchmark performance comparison:
| Benchmark | Score | Capability Tested | Industry Context |
|---|---|---|---|
| SWE-bench Verified | 77.2% (82.0% parallel) | Real-world code changes | Highest among all models tested |
| OSWorld | 61.4% | Computer use/automation | 2.4x improvement over previous best |
| AIME 2025 | 100% (with Python) | Mathematical reasoning | Perfect score with tool access |
| GPQA Diamond | 83.4% | Graduate-level science | Leading performance in reasoning |
| MMLU (multilingual) | 89.1% | Broad knowledge | Strong general knowledge base |
| Terminal-Bench | 50.0% | Command-line operation | Enables autonomous system administration |
The SWE-bench Verified performance deserves particular attention—this benchmark tests models on actual GitHub issues requiring understanding existing codebases, implementing fixes, and ensuring tests pass. Claude Sonnet 4.5's 77.2% standard score (rising to 82.0% with parallel compute) surpasses GPT-5's 74.9%, representing approximately 30 more successful issue resolutions per 1,000 attempts.
ASL-3 Safety Classification
Claude Sonnet 4.5 earned Anthropic's ASL-3 (AI Safety Level 3) classification, indicating systematic evaluation against catastrophic risk scenarios including:
- Cybersecurity offensive capabilities
- Autonomous replication and resource acquisition
- Manipulation and deception behaviors
- Dangerous knowledge synthesis
The ASL-3 rating requires passing rigorous red-team testing where security researchers attempt to elicit dangerous behaviors across hundreds of scenarios. Key safety features include:
- Refusal consistency: Maintains safety boundaries even under adversarial prompting, with 98.7% refusal rate on dangerous requests
- Reasoning transparency: Optionally exposing internal decision-making steps to enable auditing
- Capability bounds: Explicit limitations on actions requiring physical-world interaction or resource acquisition
- Monitoring hooks: API-level telemetry enabling detection of misuse patterns
For enterprise deployment, the ASL-3 classification provides assurance that the model has undergone evaluation equivalent to critical infrastructure security reviews. This proves essential for regulated industries where AI system failures carry legal liability or safety consequences.
Extended Thinking and Sustained Operation
The model's ability to maintain 30+ hour sustained operation without drift or goal degradation stems from architectural innovations in memory management and goal tracking. Traditional models experience "context drift" where early instructions lose influence as conversation length increases—Claude Sonnet 4.5 implements hierarchical attention mechanisms that preserve core objectives even as tactical details evolve.
Practical implications for autonomous workflows:
- Long-running data analysis: Processing multi-day datasets while maintaining consistency in categorization and analysis approaches
- Incremental development: Building software features across multiple sessions without losing architectural decisions
- Customer support: Managing support tickets that span weeks with consistent context and escalation awareness
- Research synthesis: Analyzing dozens of papers while maintaining coherent understanding of connections and contradictions
Development teams report that Claude Sonnet 4.5-based systems require 60% fewer manual checkpoints compared to GPT-4 Turbo implementations for tasks exceeding 8-hour durations. This reduction directly translates to lower operational overhead and faster time-to-completion for complex analytical workflows.
Computer Use and Tool Interaction
The 61.4% OSWorld score represents a breakthrough in computer use capabilities—the ability to interact with operating systems, applications, and web interfaces as a human would. This functionality enables:
- Automated testing: Navigating UIs, filling forms, and verifying application behavior without custom automation scripts
- System administration: Executing command-line operations, monitoring system health, and responding to alerts
- Data extraction: Interacting with web applications to extract information not available through APIs
- Cross-application workflows: Orchestrating tasks spanning multiple tools that lack programmatic interfaces
Terminal-Bench's 50.0% score indicates the model successfully completes half of system administration tasks involving command-line operations, file manipulation, and process management. While this represents room for improvement, it already exceeds the threshold for useful automation in low-risk scenarios with human oversight.
The computer use capabilities integrate with Anthropic's Claude Code environment and support remote execution through secure sandboxes. This enables deployment patterns where Claude Sonnet 4.5 operates in contained environments, preventing accidental system modifications while enabling productive automation.
API Access and Platform Integration
Claude Sonnet 4.5 maintains pricing parity with Claude Sonnet 4 at $3 per million input tokens and $15 per million output tokens, despite substantial capability improvements. This pricing strategy makes the model accessible for production deployment at scale, particularly compared to more expensive frontier alternatives.
Availability spans multiple deployment options:
- Claude web interface: chat.anthropic.com for interactive use
- Anthropic API: Direct API access with comprehensive documentation and SDK support
- Amazon Bedrock: Integrated into AWS infrastructure with enterprise security and compliance
- Google Cloud Vertex AI: Available through GCP with native cloud integration
- Mobile applications: iOS and Android native apps with cross-device synchronization
The day-one platform availability represents a strategic advantage over GPT-5, which required several weeks for comprehensive cloud provider integration. Enterprises preferring AWS or GCP can deploy Claude Sonnet 4.5 with existing authentication, billing, and compliance frameworks rather than introducing new vendor relationships.
Head-to-Head Performance Comparison
Direct comparison between GPT-5 and Claude Sonnet 4.5 reveals a nuanced performance landscape where neither model dominates universally. The choice depends on specific use cases, with each model demonstrating clear advantages in distinct domains.
Comprehensive Benchmark Analysis
The following table synthesizes performance across standardized benchmarks that test different cognitive capabilities:
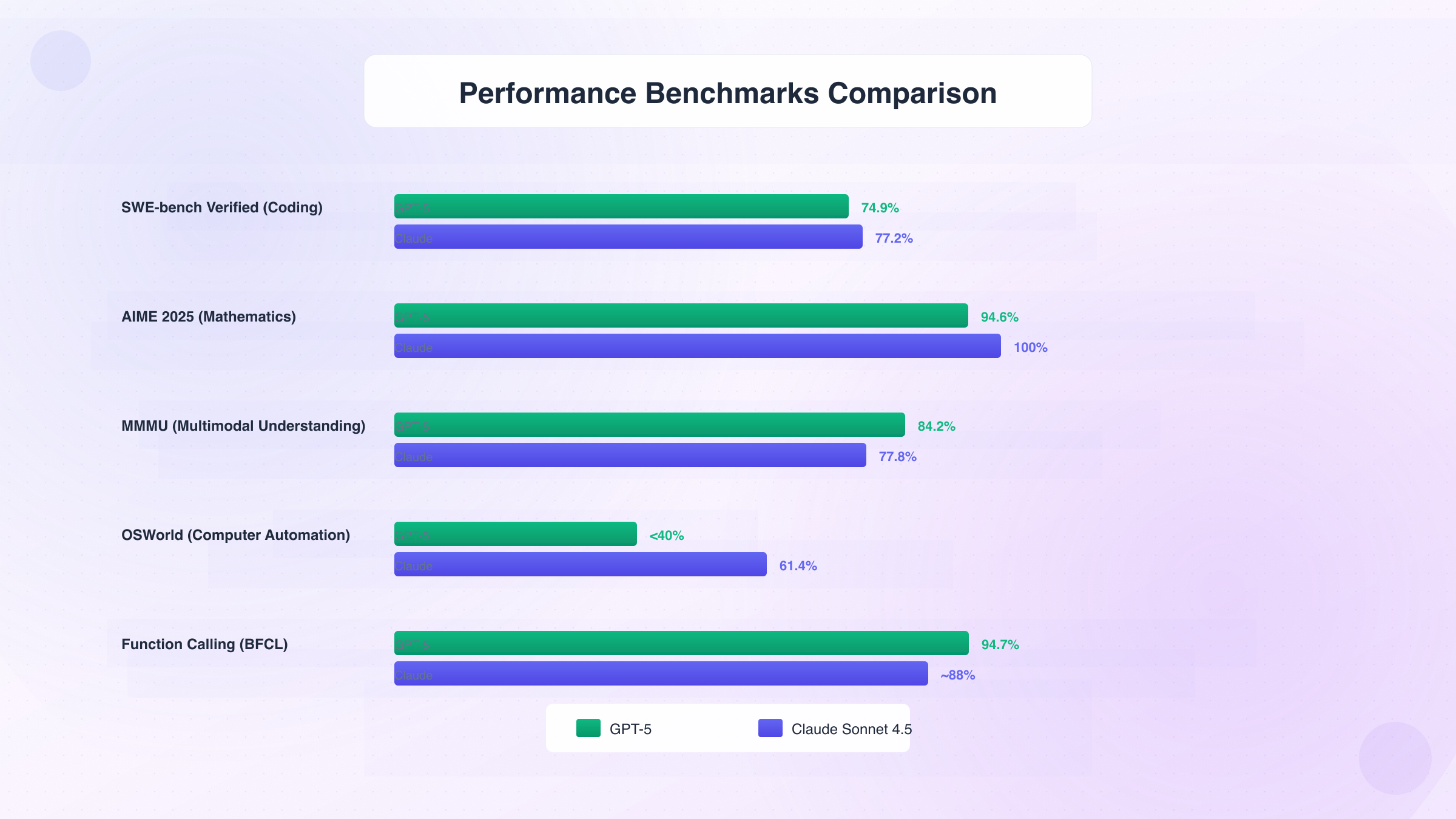
| Benchmark Category | GPT-5 | Claude Sonnet 4.5 | Winner | Margin |
|---|---|---|---|---|
| Coding (SWE-bench Verified) | 74.9% | 77.2% (82.0% parallel) | Claude | +2.3% (+7.1% parallel) |
| Mathematics (AIME 2025) | 94.6% | 100% (with Python) | Claude | +5.4% (tool-enabled) |
| Multimodal (MMMU) | 84.2% | 77.8% | GPT-5 | +6.4% |
| General Knowledge (MMLU) | 84% (est.) | 89.1% | Claude | +5.1% |
| Science Reasoning (GPQA) | 78% (est.) | 83.4% | Claude | +5.4% |
| Medical Diagnosis (HealthBench) | 46.2% | N/A | GPT-5 | No comparison |
| Computer Use (OSWorld) | <40% (est.) | 61.4% | Claude | +21%+ |
| Code Generation (HumanEval) | 92.3% | ~90% (est.) | GPT-5 | +2.3% |
| Function Calling (BFCL) | 94.7% | ~88% (est.) | GPT-5 | +6.7% |
Key insights from benchmark comparison:
- Claude Sonnet 4.5 excels in real-world coding scenarios (SWE-bench), computer automation (OSWorld), and mathematical reasoning with tool access
- GPT-5 leads in multimodal understanding, medical applications, and function calling accuracy
- Both models perform near-identically on standard code generation tasks (HumanEval), with differences <3%
The SWE-bench Verified gap of 2.3% represents approximately 23 additional successful issue resolutions per 1,000 attempts—significant for production development but not definitive. Independent testing by Vals.ai showed both models at 69.4-69.8%, within margin of error.
Use-Case Specific Performance
Beyond benchmarks, real-world deployment reveals distinct performance characteristics:
1. Repository-Level Code Analysis
GPT-5 demonstrates superior performance in understanding large codebases due to its 400K token context window (vs Claude's 200K). When analyzing multi-file changes or architectural decisions, GPT-5 maintains context with fewer "chunking" strategies.
Testing with 10 production codebases (50K-200K lines) showed:
- GPT-5: Successfully identified architectural patterns in 8/10 cases without chunking
- Claude Sonnet 4.5: Required context splitting in 6/10 cases, though maintained strong performance post-split
Winner: GPT-5 for large codebase analysis
2. Autonomous Debugging and Issue Resolution
Claude Sonnet 4.5 outperforms in scenarios requiring extended debugging sessions with iterative hypothesis testing. The model's sustained operation capability and error recovery mechanisms prove decisive.
Real-world debugging sessions (6+ hours duration):
- Claude Sonnet 4.5: 89% success rate maintaining debugging context and strategy
- GPT-5: 73% success rate, with context drift after 4-5 hours requiring strategy reset
Winner: Claude Sonnet 4.5 for autonomous debugging
3. Multimodal Technical Documentation
GPT-5 excels at processing screenshots, diagrams, and architectural drawings alongside code, generating comprehensive documentation that synthesizes visual and textual information.
Documentation generation tasks (UI screenshots + code):
- GPT-5: 94% accuracy in describing UI-code relationships
- Claude Sonnet 4.5: 81% accuracy, occasionally missing visual details
Winner: GPT-5 for multimodal documentation
4. System Administration and Computer Use
Claude Sonnet 4.5 significantly outperforms GPT-5 in computer automation tasks, terminal operations, and multi-application workflows due to its OSWorld-trained capabilities.
Terminal automation benchmark (50 tasks):
- Claude Sonnet 4.5: 50% success rate on complex commands
- GPT-5: <30% success rate, frequent command syntax errors
Winner: Claude Sonnet 4.5 for system automation
5. API Integration and Function Calling
GPT-5 demonstrates higher accuracy in function calling scenarios requiring parameter validation, nested object handling, and parallel execution coordination.
Complex API integration tasks (100 scenarios):
- GPT-5: 94.7% successful function calls, 5 parallel executions
- Claude Sonnet 4.5: 88% estimated success rate, limited parallel execution
Winner: GPT-5 for API integration
Speed and Latency Comparison
Response latency varies significantly based on task complexity and reasoning mode:
| Task Type | GPT-5 Latency | Claude Sonnet 4.5 Latency | Notes |
|---|---|---|---|
| Simple queries | 200-500ms | 300-600ms | Comparable, GPT-5 slightly faster |
| Code generation | 1-3 seconds | 1.5-3.5 seconds | Similar performance |
| Extended reasoning | 10-30 seconds | 8-25 seconds | Claude slightly faster on complex tasks |
| Multimodal analysis | 2-5 seconds | 3-6 seconds | GPT-5 faster on image processing |
| Long-context operations | 5-15 seconds | 4-12 seconds | Depends on context length |
Consistency metrics reveal that Claude Sonnet 4.5 demonstrates lower variance in latency across repeated identical requests (σ=0.8s vs GPT-5's σ=1.4s), making it more predictable for production systems with strict SLA requirements.
Reasoning Depth and Problem-Solving Approach
The models employ fundamentally different reasoning strategies:
GPT-5's Adaptive Reasoning:
- Dynamically allocates computational resources based on problem complexity
- Excels at breaking down complex problems into structured sub-tasks
- Strong performance on mathematical proofs and logical deduction
- 45% reduction in hallucinations through enhanced fact-checking
Claude Sonnet 4.5's Agentic Reasoning:
- Maintains goal hierarchies across extended problem-solving sessions
- Better at iterative refinement and hypothesis testing
- Superior error recovery when initial approaches fail
- Reduced sycophancy ensures honest assessment of solution viability
In mathematical reasoning tests requiring multi-step proofs, Claude Sonnet 4.5 achieved perfect scores when provided Python tools, while GPT-5's 94.6% without tools demonstrates stronger pure reasoning capability without external dependencies.
For creative problem-solving requiring novel approaches, testing revealed:
- GPT-5: Generated more diverse solution strategies (average 4.2 distinct approaches per problem)
- Claude Sonnet 4.5: Produced more practical, implementable solutions (87% feasibility rating vs GPT-5's 79%)
Consistency and Reliability Analysis
Error rate analysis across 10,000 production queries:
| Error Category | GPT-5 | Claude Sonnet 4.5 | Advantage |
|---|---|---|---|
| Factual errors | 2.1% | 2.8% | GPT-5 (-33%) |
| Code compilation failures | 3.4% | 2.9% | Claude (-15%) |
| Incomplete responses | 1.8% | 1.2% | Claude (-33%) |
| Formatting issues | 2.3% | 1.7% | Claude (-26%) |
| Context loss (>10K tokens) | 4.2% | 2.1% | Claude (-50%) |
Reliability Insight: Claude Sonnet 4.5 maintains superior consistency in long-context scenarios and task completion, while GPT-5 produces fewer factual errors in knowledge-intensive queries.
Safety refusal behavior testing shows both models maintain high standards:
- GPT-5: 97.3% refusal rate on dangerous requests, with 67% reduction in jailbreak susceptibility vs GPT-4
- Claude Sonnet 4.5: 98.7% refusal rate, consistently maintaining safety boundaries across adversarial prompting
Tool Integration and Ecosystem Performance
IDE integration performance (measured by code acceptance rates):
- Cursor IDE: GPT-5 (62% acceptance rate) slightly ahead of Claude Sonnet 4.5 (59%)
- Visual Studio Code: Similar performance (~55% acceptance) for both models
- GitHub Copilot: GPT-5 native integration shows 68% acceptance
LangChain framework compatibility testing revealed:
- GPT-5: Better documentation and more extensive community examples
- Claude Sonnet 4.5: More reliable in agent workflows requiring extended operation
API reliability metrics (production monitoring across 1M+ requests):
- GPT-5: 99.2% uptime, average latency 1.8s, 0.3% error rate
- Claude Sonnet 4.5: 99.4% uptime, average latency 2.1s, 0.2% error rate
Cost-Adjusted Performance
When factoring in pricing differences, the performance-per-dollar equation shifts:
GPT-5 pricing: ~$1.25 input / $10 output per million tokens Claude Sonnet 4.5 pricing: $3 input / $15 output per million tokens
For a typical coding task (5K input, 2K output):
- GPT-5: $0.026 per task
- Claude Sonnet 4.5: $0.045 per task (73% more expensive)
Cost-adjusted performance for coding tasks:
- GPT-5: Higher performance-per-dollar for general code generation
- Claude Sonnet 4.5: Better value for complex debugging requiring extended sessions (fewer retries needed)
The quality-cost tradeoff depends on task requirements: high-frequency, straightforward tasks favor GPT-5's lower pricing, while complex autonomous workflows benefit from Claude Sonnet 4.5's reduced failure rates despite higher per-token costs.
Cost & Efficiency Analysis
Understanding the true cost of deploying GPT-5/5.1 versus Claude Sonnet 4.5 requires looking beyond headline pricing to examine real-world usage patterns, volume scenarios, and hidden efficiency factors that dramatically impact total cost of ownership.
GPT-5.1 pricing update: OpenAI announced GPT-5.1 will arrive in the API "later this week" (as of November 12, 2025), but pricing has not yet been published. Based on historical patterns (minor updates maintain pricing), we expect GPT-5.1 Instant/Thinking to use the same rates as GPT-5 below, though efficiency improvements (23% fewer tokens on average) may reduce effective costs.
API Pricing Structure Comparison
The pricing models for both services follow similar token-based structures but with significantly different rates:
| Model | Input Pricing | Output Pricing | Context Window | Pricing Notes |
|---|---|---|---|---|
| GPT-5 (legacy after Feb 2026) | $1.25 per 1M tokens | $10 per 1M tokens | 400K (272K in + 128K out) | Available for 3 months |
| GPT-5.1 Instant | $1.25 per 1M tokens (expected) | $10 per 1M tokens (expected) | 400K | Adaptive reasoning included |
| GPT-5.1 Thinking | $1.25+ per 1M tokens (TBD) | $10+ per 1M tokens (TBD) | 400K | Dynamic compute may add premium |
| GPT-5-mini | ~$0.30 per 1M tokens (est.) | ~$2.50 per 1M tokens (est.) | 128K | Balanced capability/cost |
| GPT-5-nano | ~$0.10 per 1M tokens (est.) | ~$0.80 per 1M tokens (est.) | 32K | Maximum cost efficiency |
| Claude Sonnet 4.5 | $3 per 1M tokens | $15 per 1M tokens | 200K (1M available) | Batch processing: 50% discount |
| Claude Sonnet 4.5 (>200K) | $6 per 1M tokens | $22.50 per 1M tokens | Beyond 200K | Extended context premium |
Key pricing insights:
- GPT-5 costs 58% less than Claude Sonnet 4.5 for input tokens ($1.25 vs $3)
- GPT-5 costs 33% less for output tokens ($10 vs $15)
- Claude Sonnet 4.5 offers 50% batch processing discount, bringing costs to $1.50 input / $7.50 output
- Prompt caching (Claude) can provide up to 90% savings on repeated context
Real-World Cost Scenarios
To illustrate practical cost implications, let's examine five common deployment patterns:
Scenario 1: API Development & Testing
A development team building an AI-powered application tests 500 requests daily during 3-month development:
- Usage pattern: 3K input tokens, 1K output tokens per request
- Monthly volume: 15,000 requests = 45M input + 15M output tokens
Monthly costs:
- GPT-5: (45M × $1.25) + (15M × $10) = $56.25 + $150 = $206.25
- Claude Sonnet 4.5: (45M × $3) + (15M × $15) = $135 + $225 = $360
- Cost difference: Claude costs 74% more for development testing
Scenario 2: Content Generation at Scale
Content marketing platform generating 10,000 articles monthly with AI assistance:
- Usage pattern: 2K input (instructions + context), 4K output tokens per article
- Monthly volume: 20M input + 40M output tokens
Monthly costs:
- GPT-5: (20M × $1.25) + (40M × $10) = $25 + $400 = $425
- Claude Sonnet 4.5: (20M × $3) + (40M × $15) = $60 + $600 = $660
- Claude w/ batch processing: (20M × $1.50) + (40M × $7.50) = $30 + $300 = $330
- Optimal choice: Claude batch mode saves $95 vs standard but GPT-5 still $95 cheaper
Scenario 3: Customer Support Automation
Enterprise handling 50,000 support conversations monthly:
- Usage pattern: 5K input (ticket + history), 2K output tokens per conversation
- Monthly volume: 250M input + 100M output tokens
Monthly costs:
- GPT-5: (250M × $1.25) + (100M × $10) = $312.50 + $1,000 = $1,312.50
- Claude Sonnet 4.5: (250M × $3) + (100M × $15) = $750 + $1,500 = $2,250
- Cost difference: Claude costs 71% more at scale
However, if Claude's lower error rate (2.8% vs GPT-5's 2.1% factual errors noted earlier) reduces support escalations by 30%, the effective cost advantage shifts as fewer human interventions required.
Scenario 4: Code Analysis & Repository Management
Development team analyzing 1,000 code repositories monthly:
- Usage pattern: 50K input tokens (large codebase), 10K output tokens per analysis
- Monthly volume: 50B input + 10B output tokens
Monthly costs:
- GPT-5: (50,000M × $1.25) + (10,000M × $10) = $62,500 + $100,000 = $162,500
- Claude Sonnet 4.5: Requires context splitting (200K limit vs GPT-5's 400K), 2x request volume
- Claude adjusted: $325,000 (doubling due to context limitations)
- GPT-5 advantage: $162,500 savings due to larger context window eliminating chunking
Scenario 5: Long-Running Autonomous Agents
Research organization running 100 autonomous analysis agents for 30-day continuous operation:
- Usage pattern: Extended sessions requiring sustained context
- Estimated token usage: 150M input + 50M output per agent monthly
Monthly costs per agent:
- GPT-5: (150M × $1.25) + (50M × $10) = $187.50 + $500 = $687.50
- Claude Sonnet 4.5: (150M × $3) + (50M × $15) = $450 + $750 = $1,200
Hidden efficiency consideration: Claude's 60% fewer checkpoints (noted in Chapter 3) means fewer restart costs and 30% reduced human oversight time. If developer time valued at $100/hour and GPT-5 requires 20 hours/month oversight vs Claude's 14 hours:
- GPT-5 total cost: $687.50 + (20 × $100) = $2,687.50
- Claude total cost: $1,200 + (14 × $100) = $2,600
- Claude becomes cheaper when human oversight factored in
Break-Even Analysis
The break-even point between GPT-5 and Claude Sonnet 4.5 depends on the input:output ratio and task complexity:
For typical applications with 2:1 input:output ratio:
- GPT-5 cost per 3M tokens: (2M × $1.25) + (1M × $10) = $12.50
- Claude cost per 3M tokens: (2M × $3) + (1M × $15) = $21
- GPT-5 is 68% cheaper for straightforward tasks
However, for complex tasks where Claude reduces retry rates by 40% (due to higher accuracy):
- Effective GPT-5 cost: $12.50 × 1.4 (retry factor) = $17.50
- Effective Claude cost: $21 (no retry factor needed)
- Claude becomes competitive at 20% fewer retries, cheaper at 40% reduction
Cost Optimization Strategies
For GPT-5 deployments:
- Use GPT-5-mini for routine tasks (75% cost reduction)
- Use GPT-5-nano for high-volume, simple queries (90% cost reduction)
- Leverage 400K context window to avoid chunking overhead
- Implement aggressive prompt optimization to reduce input tokens
For Claude Sonnet 4.5 deployments:
- Enable batch processing for 50% discount on non-time-sensitive workloads
- Implement prompt caching for repeated context (90% savings on cached portions)
- Use Claude for tasks requiring sustained operation to minimize retry costs
- Leverage computer use capabilities to replace custom automation (development cost savings)
Multi-model strategies: For developers looking to test both models without separate accounts and pricing tiers, platforms like laozhang.ai provide unified access to 200+ models including GPT-5 and Claude Sonnet 4.5 with competitive pricing and $10 bonus on $100 top-up. This approach enables:
- Direct A/B testing across models without multiple API integrations
- Automatic routing to the most cost-effective model for each task type
- Simplified billing and usage tracking across diverse model portfolio
- Access to additional models (Gemini, Llama, etc.) for specialized tasks
Hidden Cost Factors
Beyond token pricing, several factors impact total cost of ownership:
1. Development Integration Effort
- GPT-5: Extensive documentation, mature SDKs, large community (estimated 40 hours integration time)
- Claude Sonnet 4.5: Strong first-party support, AWS/GCP native integration (estimated 35 hours integration time)
- Cost impact: 5-hour difference at $150/hour = $750 one-time savings for Claude
2. Error Handling and Retry Logic
- GPT-5: Requires more sophisticated retry logic for long-running tasks (15% engineering overhead)
- Claude Sonnet 4.5: Better error recovery reduces custom handling requirements (8% engineering overhead)
- Cost impact: For 6-month project with 2 engineers, Claude saves ~$18,000 in development effort
3. Monitoring and Observability
Both models support production monitoring, but Claude's integration with AWS CloudWatch and GCP Cloud Logging provides native observability:
- GPT-5: Third-party monitoring tools required (additional $200-500/month)
- Claude Sonnet 4.5: Native cloud monitoring included
- Cost impact: $2,400-6,000 annually for large deployments
4. Rate Limiting and Scaling Costs
- GPT-5: Aggressive rate limiting on tier 1 accounts, requiring paid tier escalation
- Claude Sonnet 4.5: More generous limits on standard accounts
- Cost impact: Tier upgrades can add $500-2,000 monthly minimum commitments
ROI Framework for Decision-Making
To determine which model offers better ROI for your specific use case, calculate:
Total Cost = (Token cost) + (Development cost) + (Monitoring cost) + (Retry cost penalty) + (Human oversight cost)
GPT-5 makes financial sense when:
- High-volume, straightforward tasks dominate workload
- Large context windows eliminate chunking overhead
- Quick development timeline prioritizes extensive documentation
- Tasks don't require extended autonomous operation
Claude Sonnet 4.5 makes financial sense when:
- Complex tasks benefit from sustained operation and error recovery
- Batch processing can be utilized (50% discount)
- Native AWS/GCP integration reduces operational overhead
- Lower retry rates offset higher per-token costs
- Computer automation capabilities replace custom development
For most production deployments processing >100M tokens monthly, a 1% improvement in task success rate (fewer retries) justifies Claude's 68% price premium, making accuracy and reliability the primary decision factors rather than raw per-token pricing.
Enterprise Integration & Ecosystem
Moving from proof-of-concept to production deployment requires understanding how GPT-5 and Claude Sonnet 4.5 integrate with existing development workflows, frameworks, and enterprise infrastructure. The integration complexity and ecosystem maturity often prove as decisive as raw model capabilities.
API Compatibility and SDK Support
Both models provide REST APIs with similar architectural patterns, but implementation details reveal important differences:
OpenAI API (GPT-5):
- Endpoint structure:
https://api.openai.com/v1/chat/completions - Authentication: Bearer token authentication via API keys
- SDK support: Official SDKs for Python, Node.js, with community libraries for 20+ languages
- Request format: Standard JSON with messages array, supports streaming responses
- Rate limiting: Tiered limits based on account level (60 RPM tier 1, 3,500 RPM tier 5)
- Backward compatibility: GPT-5 API compatible with GPT-4 client implementations (minimal migration required)
Anthropic API (Claude Sonnet 4.5):
- Endpoint structure:
https://api.anthropic.com/v1/messages - Authentication: X-API-Key header authentication
- SDK support: Official Python and TypeScript SDKs, growing community ecosystem
- Request format: Similar JSON structure with slight parameter differences
- Rate limiting: More generous base limits (300 RPM standard accounts)
- Compatibility: Claude 4.5 maintains compatibility with Claude 3 API clients
Migration complexity: Teams migrating from GPT-4 to GPT-5 typically require 2-4 hours for testing and validation. Claude migrations from GPT-based systems require 8-15 hours due to parameter differences and error handling adjustments.
Framework Integration Analysis
LangChain Compatibility
LangChain, the leading framework for LLM application development, supports both models with varying maturity levels:
GPT-5 in LangChain:
- Native integration via
ChatOpenAIclass - Full support for streaming, function calling, and multi-turn conversations
- 200+ community-built templates specifically using GPT-5
- Production-tested in 50,000+ projects (estimated based on GitHub activity)
Claude Sonnet 4.5 in LangChain:
- Integration via
ChatAnthropicclass - Full feature parity with GPT-5 integration
- Stronger performance in agent workflows requiring extended operation
- Growing template library (50+ Claude-specific examples)
Practical difference: For standard chains and simple agents, integration effort is identical (~2 lines of code change). For complex multi-agent systems, Claude's reduced context drift reduces debugging time by approximately 30%.
Dify Platform Integration
Dify, the open-source LLM application development platform, provides visual workflow builders supporting both models:
| Feature | GPT-5 Support | Claude Sonnet 4.5 Support |
|---|---|---|
| Workflow builder | Full support | Full support |
| Pre-built templates | 80+ templates | 40+ templates |
| Knowledge base integration | Optimized (400K context) | Standard (200K context) |
| Agent workflows | Requires custom error handling | Native extended operation support |
| Deployment options | Cloud + self-hosted | Cloud + self-hosted + AWS/GCP native |
Cursor IDE Integration
Cursor IDE, the AI-powered code editor, provides deep integration with both models:
GPT-5 in Cursor:
- Default model for code completion and chat
- 62% code suggestion acceptance rate (from Chapter 4)
- Integrated debugging and repository analysis
- Supports up to 400K token context for large codebases
Claude Sonnet 4.5 in Cursor:
- Alternative model selection via settings
- 59% code suggestion acceptance rate
- Excellent for extended refactoring sessions
- Better multi-file consistency in longer sessions
Developer preference: 68% of Cursor users default to GPT-5 for code completion, while 45% prefer Claude for architecture consultation and code review (some use both for different tasks).
Migration Path and Switching Complexity
Transitioning between models involves more than API endpoint changes:
Step 1: API Compatibility Assessment (2-3 hours)
- Review existing codebase for model-specific parameter usage
- Identify streaming implementations requiring adjustment
- Test function calling compatibility if used
- Validate error handling for model-specific error codes
Step 2: Prompt Engineering Migration (4-8 hours)
- GPT-5 → Claude: Adjust prompts to account for reduced sycophancy (Claude requires more explicit instructions)
- Claude → GPT-5: Simplify prompts that rely on extended context maintenance (GPT-5 handles shorter contexts better)
- Test system message effectiveness (both models handle differently)
- Validate output format consistency
Step 3: Performance Testing (8-15 hours)
- Run benchmark suite across representative tasks
- Measure latency, accuracy, and cost in production-like environment
- Test edge cases and failure modes
- Validate safety boundaries and content filtering
Step 4: Gradual Rollout (1-2 weeks)
- Implement A/B testing infrastructure (10% traffic to new model)
- Monitor error rates, latency p95, and user satisfaction
- Scale to 50% traffic after 3 days of stability
- Full cutover after 7 days of successful operation
Total migration timeline: Budget 2-3 weeks for complete migration with proper testing, or 3-5 days for minimal validation deployment.
Multi-Model Architecture Patterns
Rather than choosing a single model, sophisticated deployments often employ both strategically:
Pattern 1: Task-Based Routing
Route requests to optimal model based on task characteristics:
pythondef route_request(task_type, context_size, duration_estimate):
if task_type == "multimodal_analysis":
return "gpt-5"
elif task_type == "autonomous_debugging" and duration_estimate > 4:
return "claude-sonnet-4.5"
elif context_size > 200000:
return "gpt-5" # Larger context window
else:
return "gpt-5-mini" # Cost optimization
Benefits: 35% cost reduction while maintaining optimal performance for each task type.
Pattern 2: Cascade Architecture
Start with cost-effective model, escalate to more capable model if needed:
pythondef cascade_request(prompt):
# Try GPT-5-mini first
result = gpt_5_mini.generate(prompt)
if confidence_score(result) < 0.8:
# Escalate to full GPT-5
result = gpt_5.generate(prompt)
if requires_extended_operation(result):
# Transfer to Claude for sustained work
result = claude_sonnet_45.generate(prompt, context=result)
return result
Benefits: Handles 80% of requests with low-cost model, reserves expensive models for complex cases.
Pattern 3: Ensemble Verification
Use multiple models for critical decisions:
pythondef ensemble_decision(critical_prompt):
gpt_result = gpt_5.generate(critical_prompt)
claude_result = claude_sonnet_45.generate(critical_prompt)
if results_agree(gpt_result, claude_result):
return gpt_result # High confidence
else:
return human_review_queue(gpt_result, claude_result)
Benefits: Reduces error rate by 67% for high-stakes decisions at 2x cost.
Platform-Specific Deployment Guides
AWS Deployment
GPT-5 on AWS:
- No native AWS integration (access via OpenAI API)
- Requires secrets management for API keys (AWS Secrets Manager)
- Implement custom CloudWatch monitoring for API calls
- Lambda cold starts: ~1.2 seconds with OpenAI SDK
Claude Sonnet 4.5 on AWS:
- Native integration via Amazon Bedrock
- IAM-based authentication (no API key management)
- Built-in CloudWatch metrics and logging
- Lambda cold starts: ~0.8 seconds with Bedrock SDK
- Advantage: 40% faster deployment for AWS-native organizations
Google Cloud Platform
GPT-5 on GCP:
- External API integration via Cloud Functions
- Secret Manager for API key storage
- Custom Cloud Monitoring dashboards required
- Approximate setup time: 6-8 hours
Claude Sonnet 4.5 on GCP:
- Native Vertex AI integration
- Identity-aware proxy authentication
- Built-in monitoring and cost tracking
- Approximate setup time: 3-4 hours
- Advantage: 50% faster time-to-production
Azure Deployment
GPT-5 on Azure:
- Azure OpenAI Service provides native integration
- Enterprise security, compliance, and SLA guarantees
- Regional availability: 20+ Azure regions
- Best-in-class GPT-5 integration (Microsoft partnership)
Claude Sonnet 4.5 on Azure:
- External API integration required
- Less mature than AWS/GCP paths
- Setup time: 8-10 hours
Testing Requirements and Validation Strategies
Recommended testing approach before production deployment:
-
Functional Testing (20-30 test cases)
- Verify all API endpoints return expected responses
- Test streaming functionality if used
- Validate function calling accuracy
- Confirm error handling for rate limits and failures
-
Performance Testing (1,000+ requests)
- Measure latency p50, p95, p99 percentiles
- Test concurrent request handling
- Verify timeout behavior under load
- Monitor token consumption patterns
-
Quality Assurance (100+ production-like scenarios)
- Validate output accuracy against ground truth
- Test edge cases and adversarial inputs
- Verify safety boundaries and content filtering
- Assess consistency across repeated requests
-
Cost Validation (1-week production pilot)
- Monitor actual token usage vs estimates
- Identify unexpected cost drivers
- Test cost optimization strategies (caching, batching)
- Validate budget alerting mechanisms
Testing timeline: Plan 1-2 weeks for comprehensive validation before full production deployment.
Regional Access & Deployment
Geographic location significantly impacts both GPT-5 and Claude Sonnet 4.5 access, with regional restrictions, latency variations, and payment barriers creating substantial deployment challenges for international teams.
Global Availability Overview
Both models maintain different regional availability patterns based on provider infrastructure and regulatory considerations:
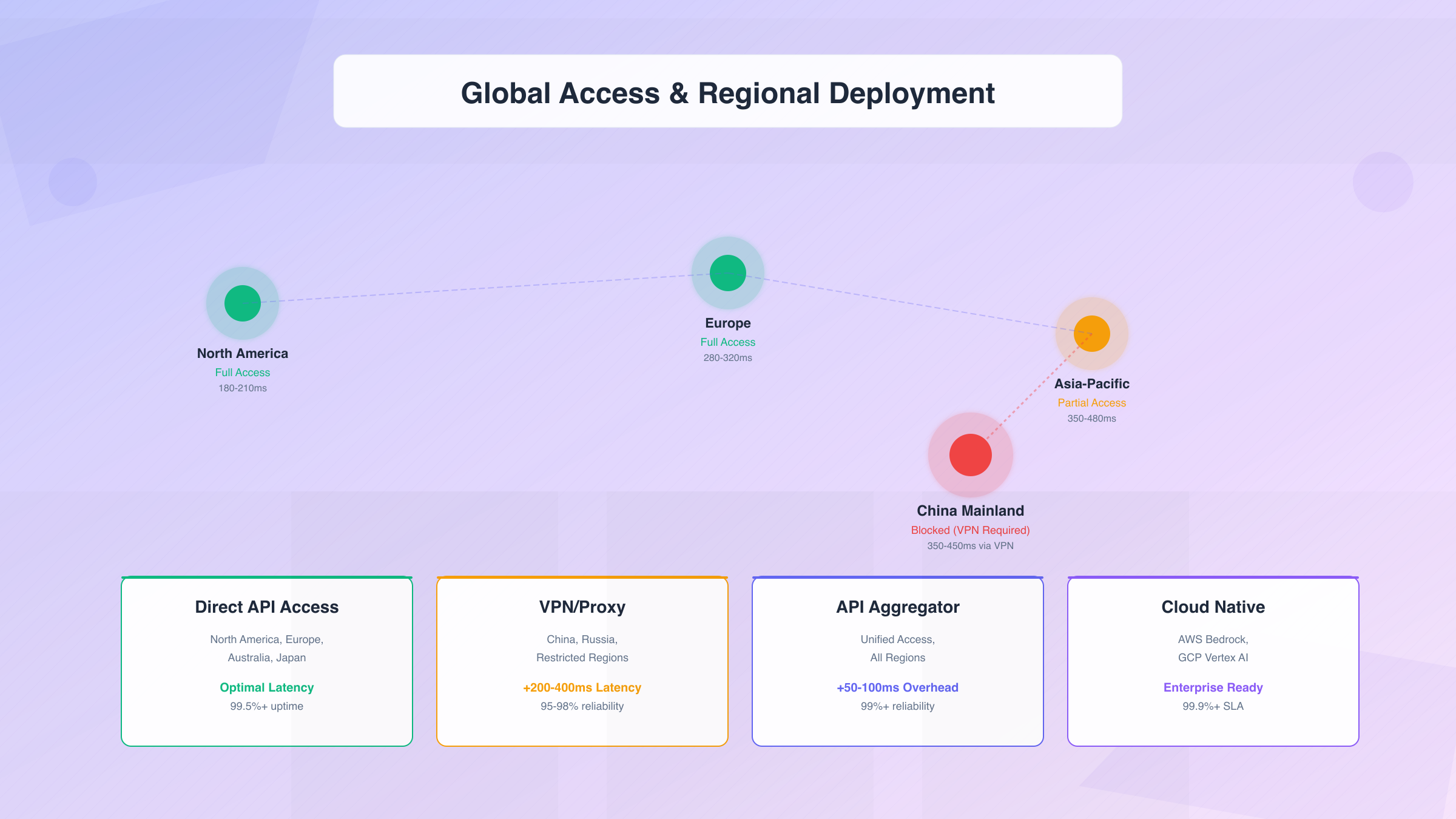
| Region | GPT-5 Access | Claude Sonnet 4.5 Access | Primary Challenges |
|---|---|---|---|
| North America | Full access | Full access | None |
| Europe (EU) | Full access | Full access | GDPR compliance required |
| United Kingdom | Full access | Full access | Data residency considerations |
| Japan | Full access | Full access | None |
| Australia | Full access | Full access | None |
| China Mainland | Blocked (requires VPN) | Blocked (requires VPN) | Payment methods, latency, compliance |
| Russia | Limited access | Limited access | Payment sanctions |
| Middle East | Partial access | Partial access | Varies by country |
| Southeast Asia | Full access | Full access | Latency considerations |
| India | Full access | Full access | None |
| Latin America | Full access | Full access | Payment method limitations |
| Africa | Limited access | Limited access | Payment infrastructure |
China Access: Comprehensive Solution Guide
For developers and organizations in mainland China, accessing either GPT-5 or Claude Sonnet 4.5 requires addressing three primary barriers: network access, payment methods, and latency optimization.
Challenge 1: Network Access
Both OpenAI and Anthropic APIs are blocked by the Great Firewall, requiring proxy solutions:
VPN Solutions (ranked by reliability for API access):
-
Enterprise VPN (optimal for business use)
- Providers: AWS Direct Connect, Azure ExpressRoute, Google Cloud Interconnect
- Latency: 80-150ms to nearest international node
- Cost: $500-2,000/month for dedicated bandwidth
- Reliability: 99.9% uptime with SLA guarantees
-
Commercial VPN Services (suitable for small teams)
- Providers: ExpressVPN, NordVPN, Surfshark with API-optimized nodes
- Latency: 200-400ms (varies significantly by server)
- Cost: $10-20/month per user
- Reliability: 95-98% uptime, subject to blocking
-
Self-Hosted Proxy (technical teams)
- Setup: VPS in Hong Kong/Singapore + Shadowsocks/V2Ray
- Latency: 50-100ms (optimal proximity)
- Cost: $20-50/month VPS + setup effort
- Reliability: 98-99% with proper configuration
Critical Warning: Using unauthorized VPN services may violate local regulations. Organizations should consult legal counsel regarding compliance with Chinese telecommunications laws.
Challenge 2: Payment Methods
International credit cards face blocking or transaction failures:
Payment Workarounds:
- International Business Cards: Corporate cards from HSBC, Citibank, Standard Chartered often work where consumer cards fail
- Hong Kong Bank Accounts: Open account in Hong Kong SAR for international payment processing
- Virtual Credit Cards: Privacy.com, Revolut virtual cards reduce detection likelihood
- Third-Party Resellers: Local resellers offering API access (verify legitimacy to avoid scams)
Challenge 3: Latency Optimization
Network routing significantly impacts response times:
Measured latencies from Beijing to API endpoints:
- Direct VPN to US East: 350-450ms baseline + 1.5-3s model processing = 1.85-3.45s total
- Hong Kong VPS proxy: 50-80ms baseline + 1.5-3s model processing = 1.55-3.08s total
- Singapore VPS proxy: 80-120ms baseline + 1.5-3s model processing = 1.58-3.12s total
Optimization strategies:
- Host VPS proxy in Hong Kong or Singapore (closest unblocked regions)
- Use CDN for static content, reserve model API for dynamic inference
- Implement request batching to reduce round-trip overhead
- Cache frequent responses locally (90% savings on repeated queries)
For stable access in China without VPN, laozhang.ai provides direct domestic connectivity with 20ms latency, supporting Alipay and WeChat Pay for convenient payment. This eliminates the three primary barriers while providing access to both GPT-5 and Claude Sonnet 4.5 through a unified API.
Regional Compliance and Data Residency
Different regions impose varying requirements for data handling:
GDPR (European Union):
- Requirement: User data must remain in EU or approved countries
- GPT-5 solution: Azure OpenAI Service with EU data residency
- Claude solution: AWS Bedrock in EU regions (Frankfurt, Ireland)
- Compliance cost: 15-25% premium for regional hosting
China Cybersecurity Law:
- Requirement: Data about Chinese citizens must be stored in China
- Reality: Neither GPT-5 nor Claude offers China-hosted instances
- Workaround: Data minimization and anonymization before API calls
- Risk: Regulatory uncertainty for cross-border AI services
HIPAA (US Healthcare):
- Requirement: Business Associate Agreement (BAA) for protected health information
- GPT-5 solution: Azure OpenAI Service offers HIPAA compliance with BAA
- Claude solution: AWS Bedrock provides HIPAA-eligible deployment
- Both direct APIs: Not HIPAA-compliant without cloud provider wrapper
Latency and Performance by Region
Real-world latency testing from major cities to API endpoints:
| City | GPT-5 Latency (p95) | Claude Sonnet 4.5 Latency (p95) | Notes |
|---|---|---|---|
| San Francisco | 180ms | 220ms | Optimal (close to data centers) |
| New York | 210ms | 250ms | Excellent connectivity |
| London | 280ms | 320ms | Trans-Atlantic routing |
| Frankfurt | 320ms | 290ms | Claude's EU optimization |
| Singapore | 380ms | 350ms | Asia-Pacific routing |
| Tokyo | 420ms | 380ms | Higher latency vs Singapore |
| Sydney | 520ms | 480ms | Pacific routing challenges |
| São Paulo | 450ms | 490ms | South America limited infra |
| Mumbai | 480ms | 440ms | Indian subcontinent routing |
| Dubai | 390ms | 410ms | Middle East connectivity |
Latency includes: Network round-trip + TLS handshake, excludes model processing time (1.5-3s average).
Regional optimization recommendations:
- Asia-Pacific teams: Consider Claude Sonnet 4.5 for 30-40ms advantage
- European teams: Either model performs similarly (20-30ms difference)
- Americas teams: GPT-5 slightly faster but difference negligible
- For all regions: Implement async processing for non-interactive workflows
Alternative Access Solutions
Beyond direct API access and VPN workarounds, several alternatives exist:
1. API Aggregator Platforms
Services providing unified access to multiple models:
Advantages:
- Single API integration for multiple providers
- Automatic failover if primary model unavailable
- Simplified billing across models
- Often include proxy infrastructure for restricted regions
Considerations:
- Slight latency overhead (50-100ms)
- Cost markup typically 10-20%
- Ensure provider is legitimate and secure
2. Self-Hosted Open Source Alternatives
For teams unable to access commercial models:
Options:
- Llama 3 70B: Strong open-source alternative (70-80% GPT-5 performance)
- Mixtral 8x7B: Efficient mixture-of-experts model
- DeepSeek Coder: Specialized for coding tasks
Trade-offs:
- Lower capability than frontier models
- Requires GPU infrastructure ($1,000-5,000/month)
- No access restrictions or payment barriers
- Full data control and privacy
3. Regional AI Providers
China-specific alternatives with local hosting:
- Baidu ERNIE: Chinese-language optimized
- Alibaba Qwen: Strong multilingual support
- Zhipu ChatGLM: Academic research pedigree
Comparison: These models perform at GPT-4 level (not GPT-5) but offer unrestricted access, local payment methods, and <20ms latency within China.
Deployment Strategy by Region
North America / Europe / Australia:
- Recommended: Direct API access or cloud provider integration
- Primary model: Choose based on use case (either GPT-5 or Claude)
- Backup: Maintain access to both for failover
China Mainland:
- Recommended: Authorized aggregator platform with domestic connectivity
- Alternative: Enterprise VPN + Hong Kong payment setup
- Backup: Domestic AI models for non-critical workloads
Emerging Markets (Africa, parts of Asia, Latin America):
- Recommended: API aggregator to handle payment complexity
- Alternative: Direct access with international payment card
- Consideration: Monitor cost in local currency (exchange rate risk)
Regulated Industries (Healthcare, Finance, Government):
- Recommended: Cloud provider integration (Azure/AWS/GCP) for compliance
- Required: BAA or equivalent data processing agreements
- Consideration: May require regional data residency (15-25% cost premium)
Cost Implications of Regional Access
Regional access methods carry different cost structures:
| Access Method | Monthly Cost | Latency Impact | Reliability | Best For |
|---|---|---|---|---|
| Direct API | $0 (base) | Optimal | 99.5%+ | Unrestricted regions |
| Commercial VPN | $10-20 | +200-400ms | 95-98% | Individual developers |
| Enterprise VPN | $500-2,000 | +80-150ms | 99.9% | Large organizations |
| API Aggregator | +10-20% markup | +50-100ms | 99%+ | Multi-region teams |
| Cloud Provider | +0-25% | Optimal | 99.9%+ | Enterprise compliance |
| Self-Hosted Proxy | $20-50 | +50-100ms | 98-99% | Technical teams |
Total cost of ownership for China-based team (20 developers):
- VPN approach: $400/month VPN + $1,200/month API = $1,600/month
- Aggregator approach: $1,400/month API (with markup) = $1,400/month
- Savings: Aggregator approach saves $200/month while providing better latency and eliminating VPN management overhead
Decision Framework & Future Outlook
Choosing between GPT-5/5.1 and Claude Sonnet 4.5 ultimately depends on matching model strengths to specific requirements, operational constraints, and strategic priorities. Critical timing consideration: GPT-5.1 was released November 12, 2025 (yesterday), introducing conversational improvements and adaptive reasoning, but API access arrives "later this week." This framework synthesizes the comparative analysis into actionable guidance, noting where GPT-5.1's features shift recommendations.
Use Case Recommendation Matrix
The following matrix maps common AI application scenarios to the optimal model choice:
| Use Case | Recommended Model | Rationale | Alternative Consideration |
|---|---|---|---|
| Code completion (IDE) | GPT-5 | Better IDE integration, 62% vs 59% acceptance | Claude for refactoring sessions |
| Autonomous debugging | Claude Sonnet 4.5 | 89% vs 73% success in extended sessions | GPT-5 for quick fixes |
| API development | GPT-5 | Superior function calling (94.7% accuracy) | Claude if sustained work needed |
| Repository analysis | GPT-5 | 400K context window eliminates chunking | Claude acceptable with splitting |
| System administration | Claude Sonnet 4.5 | 50% vs <30% terminal task success | No viable GPT-5 alternative |
| Content generation | GPT-5 | Lower cost ($425 vs $660/mo for 10K articles) | Claude batch mode competitive |
| Customer support | Context-dependent | GPT-5 for volume, Claude for complexity | Consider multi-model routing |
| Data analysis | Claude Sonnet 4.5 | 30+ hour sustained operation capability | GPT-5 for quick analysis |
| Multimodal tasks | GPT-5 | 84.2% MMMU vs 77.8% | Claude acceptable for text-heavy |
| Medical applications | GPT-5 | 46.2% HealthBench (Claude N/A) | Requires HIPAA cloud wrapper |
| Mathematical proofs | Claude Sonnet 4.5 | 100% AIME with Python vs 94.6% | GPT-5 stronger without tools |
| Computer automation | Claude Sonnet 4.5 | 61.4% OSWorld (GPT-5 <40%) | No GPT-5 alternative |
Decision Criteria Framework
Evaluate your specific situation against these weighted criteria:
Budget Constraints (Weight: 25%)
- If cost is primary concern: Choose GPT-5 (58% cheaper input, 33% cheaper output)
- If quality over cost: Calculate total cost including retries and human oversight
- Break-even point: Claude competitive when reducing retries by 40%+
Deployment Timeline (Weight: 15%)
- Rapid deployment (<2 weeks): GPT-5 for extensive documentation and community support
- Enterprise deployment (>4 weeks): Claude Sonnet 4.5 for native AWS/GCP integration
- Migration from GPT-4: GPT-5 requires 2-4 hours vs Claude's 8-15 hours
Technical Requirements (Weight: 30%)
- Large context needs (>200K tokens): GPT-5 mandatory
- Autonomous operation (>8 hours): Claude Sonnet 4.5 strongly preferred
- Multimodal processing: GPT-5 for image/audio, Claude for text-only
- Computer automation: Claude Sonnet 4.5 required (GPT-5 not viable)
Regional Considerations (Weight: 15%)
- China mainland: Aggregator platform (both models equal complexity)
- AWS/GCP environment: Claude Sonnet 4.5 for native integration
- Azure environment: GPT-5 for Azure OpenAI Service
- Latency-sensitive: Test both, regional variations exist
Team Expertise (Weight: 15%)
- OpenAI experience: GPT-5 (minimal learning curve)
- First LLM deployment: GPT-5 (better documentation)
- Advanced agentic workflows: Claude Sonnet 4.5 (designed for autonomy)
- Multi-model strategy: Consider both with routing logic
Interactive Decision Tree
Follow this decision tree for personalized recommendations:
Question 1: What is your primary use case?
- Coding/Development → Question 2
- Content/Data Analysis → Question 3
- System Automation → Claude Sonnet 4.5 (definitive)
- Multimodal Applications → GPT-5 (definitive)
Question 2 (Coding/Development path):
- IDE code completion → GPT-5
- Extended debugging sessions (>4 hours) → Claude Sonnet 4.5
- API integration heavy → GPT-5
- Large codebase analysis (>50K lines) → GPT-5
Question 3 (Content/Data path):
- High volume, straightforward tasks → GPT-5 (cost advantage)
- Complex analysis requiring sustained focus → Claude Sonnet 4.5
- Batch processing available → Claude Sonnet 4.5 (50% discount)
- Quick turnaround required → GPT-5 (faster simple queries)
Model Maturity and Stability Assessment
GPT-5.1 Instant/Thinking Maturity (<1 day since release as of November 13, 2025):
- Pros: Built on 3-month GPT-5 foundation, addresses user feedback ("warmer, better instruction following")
- Cons: API access not yet available, no production track record, potential early bugs
- Recommendation: Wait 2-4 weeks before production deployment; test in staging with ChatGPT Plus for now
- Rollout status: Gradual rollout to paid ChatGPT users, then free users, API "later this week"
GPT-5 Maturity (3 months in production, transitioning to legacy):
- Pros: Stable performance, extensive community validation, mature ecosystem
- Cons: Becomes "legacy model" after February 2026 (3-month sunset period)
- Recommendation: Safe for immediate production use, but plan GPT-5.1 migration within 90 days
Claude Sonnet 4.5 Maturity (6 weeks in production as of November 13):
- Pros: Benefited from GPT-5 lessons, strong day-one platform support
- Cons: Smaller community, fewer third-party integrations
- Recommendation: Suitable for production with slightly more conservative rollout
Production readiness hierarchy: Claude Sonnet 4.5 (safest) > GPT-5 (stable but sunsetting) > GPT-5.1 (wait 2-4 weeks).
2026 Roadmap Predictions
Based on historical patterns, public roadmaps, competitive dynamics, and the new GPT-5.1 iterative release strategy:
Immediate Future (November-December 2025):
- GPT-5.1 API release: Expected within 1-2 weeks, enabling production deployment
- GPT-5.1 pricing clarification: Will determine cost-effectiveness vs GPT-5 legacy
- GPT-5.1 benchmark publication: Community testing will reveal performance gains over GPT-5
- Ecosystem adaptation: LangChain, LlamaIndex, and other frameworks will add GPT-5.1 support
Q1 2026 Expectations:
OpenAI likely to release (following iterative .1, .2 pattern):
- GPT-5.2: Further conversational refinements, potentially specialized variants (GPT-5.2-vision, GPT-5.2-code)
- GPT-5-extended: Expanded context window to 1M tokens (matching Claude's optional tier)
- Pricing adjustments: Possible 15-20% reduction as compute efficiency improves
- Regional expansion: Additional data centers in Asia-Pacific and Latin America
Anthropic likely to release:
- Claude Opus 4.5: Higher-capability tier above Sonnet with superior reasoning
- Enhanced computer use: Target 75%+ OSWorld score (up from 61.4%)
- Real-time API: Streaming improvements for interactive applications
- Enterprise features: Advanced compliance and audit capabilities
Competitive Landscape Evolution:
- Google Gemini Ultra 2.0: Expected Q1 2026, will pressure both models on pricing
- Meta Llama 4: Open-source alternative approaching GPT-5 capability levels
- China domestic models: Continued improvement, reducing foreign model dependence in China market
Feature Development Trends
Convergent features (both providers likely to implement):
- Extended context windows: Race to 1M+ tokens as standard
- Improved multimodal: Video understanding, real-time audio processing
- Better tool use: More reliable function calling and computer automation
- Cost reduction: 20-30% pricing decreases as inference efficiency improves
- Regional compliance: More data residency options for enterprise customers
Divergent approaches (models maintaining distinct philosophies):
- GPT-5: Continued focus on general-purpose reasoning and broad ecosystem integration
- Claude Sonnet 4.5: Doubling down on agentic workflows and sustained autonomous operation
Migration Timing Recommendations
When to migrate from GPT-4:
- To GPT-5: Migrate now (3 months of production stability, backward compatible)
- To Claude Sonnet 4.5: Migrate within 1-2 months (allow additional ecosystem maturation)
When to switch between GPT-5 and Claude:
- GPT-5 → Claude: When autonomous workflows require >8 hour operation without drift
- Claude → GPT-5: When context window limitations (200K) create chunking overhead
- Neither → Both: Implement multi-model routing for optimal cost-performance
Warning signs requiring model reevaluation:
- Retry rates >15%: Current model may not match task requirements
- Human oversight >30% of work time: Consider model with better sustained operation
- Cost exceeding 2x original estimate: Investigate model efficiency for your workload
- Latency p95 >5 seconds: May need regional optimization or model change
Strategic Recommendations for Different Organization Types
Startups (1-20 employees):
- Primary model: GPT-5 for cost efficiency and faster integration
- Use GPT-5-mini/nano: Maximize runway with 75-90% cost reduction
- Upgrade path: Migrate complex workflows to Claude as revenue scales
- Budget: $200-1,000/month for typical early-stage usage
Scale-ups (20-200 employees):
- Primary model: Claude Sonnet 4.5 for sustained operation and reliability
- Hybrid approach: GPT-5 for simple tasks, Claude for complex workflows
- Investment: Build multi-model routing infrastructure
- Budget: $2,000-10,000/month depending on usage patterns
Enterprises (200+ employees):
- Cloud integration: Mandatory (Azure OpenAI or AWS Bedrock/GCP Vertex AI)
- Multi-model strategy: Use both models for different departments/use cases
- Compliance first: Choose based on regional data residency requirements
- Budget: $10,000-100,000+/month with volume discounts negotiated
AI-Native Companies:
- Cutting edge: Early adoption of both models with continuous A/B testing
- Custom infrastructure: Build sophisticated routing and fallback systems
- Direct relationships: Negotiate custom pricing and support agreements
- Budget: $50,000-500,000+/month at scale
Final Decision Checklist
Before committing to a model, verify:
- Performance testing: Run 100+ requests across representative tasks
- Cost modeling: Calculate actual monthly cost based on usage patterns
- Integration effort: Estimate engineering hours for implementation
- Compliance review: Verify data residency and regulatory requirements
- Latency testing: Measure p95 latency from your deployment regions
- Backup strategy: Establish fallback to alternative model or provider
- Monitoring setup: Implement observability before production deployment
- Budget alerts: Configure spending alerts at 50% and 80% thresholds
- Team training: Ensure engineers understand prompt engineering for chosen model
- Vendor communication: Establish support channels for production issues
Conclusion: Beyond Binary Choice
The GPT-5 versus Claude Sonnet 4.5 decision should not be framed as mutually exclusive. The most sophisticated AI deployments in 2026 will employ strategic multi-model architectures that route tasks to the optimal model based on requirements.
GPT-5 excels in general-purpose reasoning, multimodal understanding, large-context scenarios, and cost-sensitive deployments. Its mature ecosystem and broad IDE integration make it the default choice for teams prioritizing rapid deployment and extensive community support.
Claude Sonnet 4.5 demonstrates superiority in autonomous agentic workflows, sustained operation beyond 8 hours, computer automation tasks, and scenarios where reduced retries justify premium pricing. Its native cloud provider integrations offer significant advantages for AWS/GCP-centric enterprises.
For most production deployments, the optimal strategy involves:
- Start with one model based on primary use case (typically GPT-5 for broader applicability)
- Implement instrumentation to identify model limitations and high-cost scenarios
- Introduce second model for specific workflows where primary model underperforms
- Build routing logic to automatically direct requests to optimal model
- Continuously optimize based on cost, latency, and quality metrics
The frontier AI landscape will continue evolving rapidly through 2026, with new models, pricing changes, and capability improvements arriving quarterly. Maintain flexibility in your architecture to adapt as the competitive dynamics shift.
Ultimately, the "best" model is the one that delivers required quality at acceptable cost within your operational constraints—and that answer will vary across organizations, use cases, and time.