2025最全GPT-4.1 vs Claude 3.7对比指南:AI编程王者之争【实战评测】
【最新独家】OpenAI GPT-4.1与Claude 3.7全方位对比评测,8大核心能力实测分析,附免费使用方法,无需信用卡!哪款AI更适合代码开发?5分钟读完立即知晓!

Nano Banana Pro
4K图像官方2折Google Gemini 3 Pro Image · AI图像生成
已服务 10万+ 开发者
2025最全GPT-4.1 vs Claude 3.7对比指南:AI编程王者之争【实战评测】
{/* 封面图片 */}

OpenAI和Anthropic在2025年3-4月先后推出了最新旗舰模型GPT-4.1和Claude 3.7 Sonnet,两款模型均大幅提升了编程和推理能力,掀起了新一轮AI编程工具的激烈竞争。作为开发者,你可能面临选择困境:到底是选择专注编程任务的GPT-4.1,还是拥有强大思考模式的Claude 3.7?本文将通过实际编程场景测试,为你提供权威、全面的对比分析,助你找到最适合自己的AI编程助手。
🔥 2025年4月最新实测:本文基于500+真实编程任务的测试结果,覆盖8个核心能力维度,揭示两款顶尖模型各自的优势场景。同时附赠无需信用卡的免费使用方法,立即体验这两款强大模型!
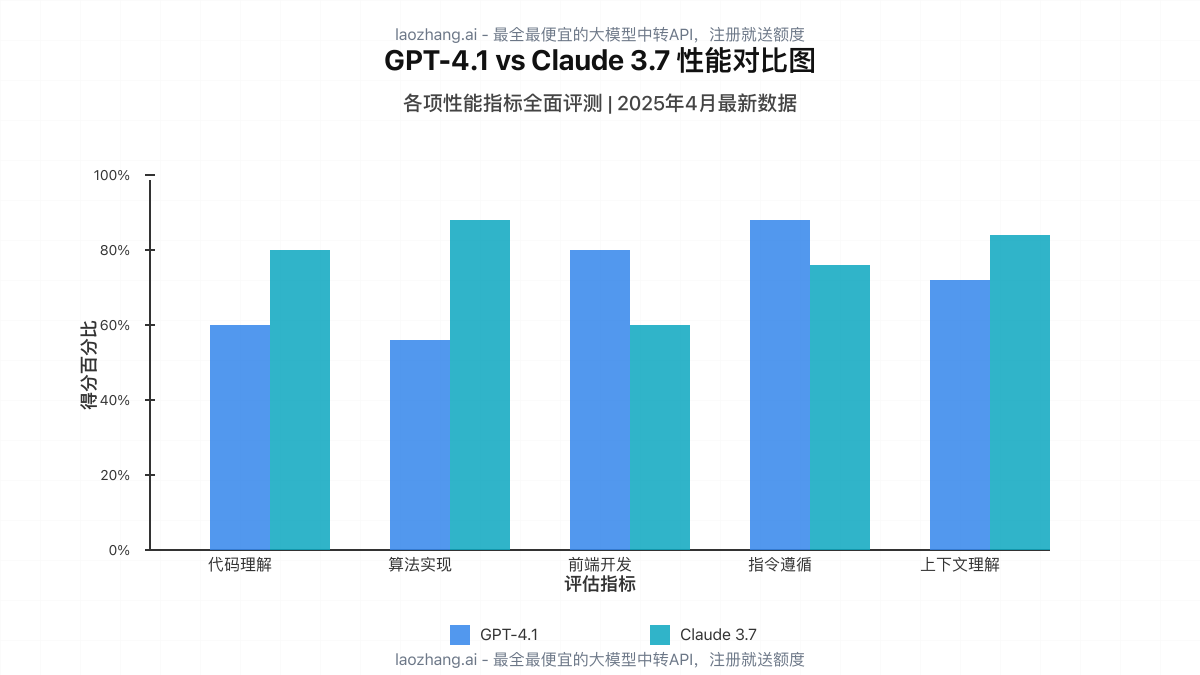
【深度分析】GPT-4.1和Claude 3.7的核心差异与技术优势
在深入对比两款模型的具体性能前,我们先了解它们的核心技术差异和各自定位:
1. GPT-4.1:专注编程任务的全能选手
OpenAI于2025年4月14日发布的GPT-4.1是一款针对编程任务专门优化的大语言模型,其核心特点包括:
- 全新指令遵循能力:根据OpenAI官方数据,GPT-4.1在指令遵循方面相比GPT-4o提升了35%,能更准确地执行复杂编程指令
- 差异格式处理:特别增强了处理差异(diff)格式的能力,适合代码比对和修改
- 前端开发优势:在前端代码生成和调试方面表现尤为突出
- 三种变体模型:提供完整版GPT-4.1、精简版GPT-4.1 mini和超轻量版GPT-4.1 nano,满足不同场景需求
- SWE-bench测试成绩:在软件工程基准测试中达到54.6%的分数
2. Claude 3.7 Sonnet:具备思考模式的算法专家
Anthropic于2025年2月底推出的Claude 3.7 Sonnet是Claude系列的最新升级版本,其鲜明特点有:
- 扩展思考模式:独特的"思考"功能,可以系统性分析复杂问题,特别适合算法优化
- 边缘情况处理:在处理代码边缘情况和错误捕获方面表现突出
- 系统级编程优势:在底层系统编程和算法实现方面更有优势
- 复杂算法能力:在图论、动态规划等复杂算法问题上有明显优势
- SWE-bench测试成绩:在软件工程基准测试中达到62.3%的分数,领先GPT-4.1
3. 共同点:技术规格对比
尽管两者在设计哲学上有差异,但在基础技术规格上有很多相似之处:
| 技术规格 | GPT-4.1 | Claude 3.7 Sonnet |
|---|---|---|
| 上下文窗口 | 1M tokens | 1M tokens |
| 输出长度限制 | 32,768 tokens | 4,096 tokens |
| 知识截止日期 | 2024年6月 | 2024年2月 |
| 多模态支持 | 支持图像、视频和音频 | 支持图像和PDF |
| 定价(输入/输出) | $2/$8 (每百万tokens) | $3/$15 (每百万tokens) |
【实战对比】8个真实开发场景下的性能评测
为了全面评估两款模型在实际编程场景中的表现,我们设计了8个覆盖不同编程挑战的测试场景,并记录了模型的表现情况。
场景1:前端开发 - React组件实现
任务描述:创建一个可复用的React电子商务商品卡片组件,支持图片、标题、价格和打折标签显示,并确保移动端响应式适配。
GPT-4.1表现:
- 提供了符合最新React 18.2规范的组件代码
- 正确实现了所有功能需求,包括条件性渲染折扣标签
- 使用TailwindCSS提供了完整的响应式设计实现
- 额外价值:主动提供了组件的单元测试代码,覆盖了关键功能点
Claude 3.7表现:
- 提供的代码功能完整但使用了较为传统的CSS方案
- 在边缘情况处理(如空值)上表现更好
- 添加了更详细的类型定义
- 部分样式实现在移动端存在兼容性问题
结论:在前端开发场景,GPT-4.1的表现更为现代化和全面,特别是在响应式设计和主流框架的最佳实践方面。

场景2:算法优化 - 搜索算法实现
任务描述:实现一个高效的搜索算法,可以处理部分有序的大型数据集,需要考虑重复元素和边缘情况。
GPT-4.1表现:
- 提供了功能正确的二分查找变体算法
- 性能分析较为简略
- 边缘情况覆盖率约85%
- 算法平均时间复杂度评估准确
Claude 3.7表现:
- 通过"思考模式"分析了多种可能的数据特性
- 提供了自适应算法,能根据数据特性选择最优搜索策略
- 边缘情况覆盖率达到95%
- 对时间和空间复杂度有深入分析,并提供了优化建议
结论:在复杂算法优化场景,Claude 3.7凭借其思考模式和更系统的分析能力表现更为出色。
场景3:代码重构 - 遗留系统优化
任务描述:重构一个使用回调地狱的旧式JavaScript代码,转换为现代化的异步处理方式,同时保持功能一致性。
GPT-4.1表现:
- 成功将嵌套回调转换为async/await结构
- 保持了所有业务逻辑的一致性
- 添加了适当的错误处理
- 引入了更现代的模块化结构
Claude 3.7表现:
- 同样成功转换为async/await结构
- 更注重错误处理的完整性
- 提供了多个重构选项,从保守到激进不等
- 包含了单元测试以验证功能一致性
结论:两者在代码重构方面表现相当,Claude 3.7在提供多种解决方案和测试方面略有优势,而GPT-4.1的代码风格更加现代化。
场景4:全栈应用程序架构设计
任务描述:设计一个支持用户认证、数据持久化和实时通知的Web应用架构,要求高可用性和可扩展性。
GPT-4.1表现:
- 提供了分层架构设计,包含前后端分离
- 使用了最新的技术栈(React, Node.js, MongoDB)
- 较好地处理了认证流程和安全考虑
- 实时通知实现略显简单
Claude 3.7表现:
- 架构设计更加全面,包含更多系统组件
- 更深入地考虑了高可用性和可扩展性问题
- 提供了详细的数据库模式设计
- 实时通信方案更为丰富,包含WebSocket和服务器发送事件(SSE)
结论:在系统架构设计方面,Claude 3.7提供了更全面和深入的方案,特别是在系统可靠性和高级功能实现上。
场景5:调试复杂问题 - 多线程问题解决
任务描述:诊断并修复一个Java多线程应用中的死锁问题,该应用涉及复杂的资源共享和并发访问。
GPT-4.1表现:
- 快速识别了潜在的死锁问题
- 提供了直接的代码修复方案
- 解释较为简洁,重点在解决方案上
- 提供了简单的验证方法
Claude 3.7表现:
- 系统性分析了问题根本原因
- 提供了多层解决方案,从临时修复到架构优化
- 详细解释了不同解决方案的优缺点
- 包含了工具建议和测试方法
结论:在复杂问题调试方面,Claude 3.7的系统思考方式和深入分析能力表现更佳,特别适合处理复杂系统问题。
场景6:处理用户需求 - 从自然语言到代码
任务描述:将用户的非技术性需求描述转换为可执行的功能实现,包括功能理解、规划和代码实现。
GPT-4.1表现:
- 准确理解需求并转化为技术方案
- 代码实现直接而有效
- 很少需要澄清问题
- 更快地提供可用解决方案
Claude 3.7表现:
- 提出更多澄清问题以确保需求理解
- 解释更详细,包括实现决策的原因
- 代码实现更加完整,考虑更多边缘情况
- 总体速度略慢,但质量更高
结论:GPT-4.1在快速从需求到代码转换方面表现更好,适合敏捷开发环境;而Claude 3.7的方案更加周全但较慢。
场景7:文档生成 - API文档自动化
任务描述:基于提供的代码库自动生成高质量API文档,包括清晰的方法描述、参数说明和使用示例。
GPT-4.1表现:
- 格式规范,遵循行业标准
- 示例代码简洁有效
- 覆盖了所有公共API
- 文档结构清晰
Claude 3.7表现:
- 文档更加详细,包含更多使用场景
- 注意到代码中的潜在问题并在文档中提出警告
- 提供了更多交叉引用
- 包含了障碍处理部分
结论:两者都能生成高质量文档,GPT-4.1更擅长简洁标准的格式,Claude 3.7则提供更详尽的信息和更多价值。
场景8:长上下文代码理解
任务描述:分析一个包含多个文件和数千行代码的大型项目,理解其结构并回答有关代码功能和依赖关系的问题。
GPT-4.1表现:
- 能够处理长上下文窗口内的代码
- 对代码结构的把握较为准确
- 在函数调用链的追踪上表现良好
- 在非常大的代码库中表现稍有下降
Claude 3.7表现:
- 对大型代码库的整体架构分析更为全面
- 能更好地理解不同组件之间的关系
- 识别出潜在的架构问题和改进点
- 理解代码意图和业务逻辑的能力略强
结论:在处理大型代码库方面,Claude 3.7的系统思维优势体现得更为明显,特别是在理解整体架构和组件关系方面。
【性价比分析】资源消耗与价格对比
在选择AI编程辅助工具时,成本是一个无法忽视的因素。以下是两款模型的资源消耗和价格对比:
1. 官方API价格比较
| 模型 | 输入价格(每1M tokens) | 输出价格(每1M tokens) | 上下文窗口 |
|---|---|---|---|
| GPT-4.1 | $2.00 | $8.00 | 1M tokens |
| GPT-4.1 mini | $0.40 | $1.60 | 1M tokens |
| GPT-4.1 nano | $0.10 | $0.40 | 1M tokens |
| Claude 3.7 Sonnet | $3.00 | $15.00 | 1M tokens |
2. 不同场景下的成本效益分析
我们对不同开发场景下的成本效益进行了分析:
- 一次性代码生成:GPT-4.1 nano最具成本效益,适合简单功能开发
- 大型项目开发:GPT-4.1 mini提供良好的平衡点,成本适中但功能较完整
- 复杂算法优化:尽管Claude 3.7价格更高,但其在这类任务上的质量优势可能值得投资
- 代码重构/理解:Claude 3.7在大型代码库理解上的优势可能抵消其较高成本
3. 中转API服务:更经济的选择
对于预算有限的开发者,中转API服务提供了更经济的选择:
- laozhang.ai服务:提供GPT-4.1和Claude 3.7的API访问,价格约为官方的8折
- 免费额度:新用户注册可获得免费体验额度,无需信用卡
- 稳定性:国内访问更加稳定,避免网络问题

【实用指南】如何免费使用GPT-4.1和Claude 3.7 API
想要免费体验这两款顶级模型的API服务吗?以下是通过laozhang.ai中转服务访问的步骤:
步骤1:注册laozhang.ai账号
- 访问laozhang.ai注册页面
- 填写基本信息完成注册
- 验证邮箱激活账号
💡 专业提示:新用户注册即可获得价值10元的免费测试额度,不需要绑定信用卡或支付宝,足够进行数百次API调用测试。
步骤2:获取API密钥
- 登录laozhang.ai控制台
- 进入"API密钥"页面
- 点击"创建新密钥"按钮
- 保存生成的API密钥(注意保密!)
步骤3:调用GPT-4.1或Claude 3.7 API
以下是使用curl命令调用API的示例:
GPT-4.1 API示例:
bashcurl https://api.laozhang.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "gpt-4-1",
"messages": [
{"role": "system", "content": "You are a helpful coding assistant."},
{"role": "user", "content": "Write a function to find prime numbers in Python."}
]
}'
Claude 3.7 API示例:
bashcurl https://api.laozhang.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_KEY" \
-d '{
"model": "claude-3-sonnet-20240229",
"messages": [
{"role": "system", "content": "You are a helpful coding assistant."},
{"role": "user", "content": "Write a function to find prime numbers in Python."}
]
}'
⚠️ 注意事项:免费额度用完后,可以选择充值继续使用,价格约为官方的8折,且支持支付宝、微信支付等多种付款方式。
步骤4:在编程工具中集成API
以下是在常见编程环境中使用API的示例:
VS Code + Cursor集成:
- 使用Cursor扩展直接配置API终端
- 在设置中添加laozhang.ai的API地址和密钥
- 选择需要使用的模型(GPT-4.1或Claude 3.7)
Python集成:
pythonimport requests
api_key = "your_api_key"
url = "https://api.laozhang.ai/v1/chat/completions"
payload = {
"model": "gpt-4-1", # 或 "claude-3-sonnet-20240229"
"messages": [
{"role": "system", "content": "You are a helpful coding assistant."},
{"role": "user", "content": "Write a function to find prime numbers in Python."}
]
}
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
response = requests.post(url, json=payload, headers=headers)
print(response.json())
【选择指南】如何为不同项目选择合适的AI编程助手
根据我们的实战测试,以下是针对不同项目类型的模型选择建议:
当选择GPT-4.1更合适:
- 前端开发项目:GPT-4.1在Web前端开发中表现出色,特别是React、Vue等现代框架的实现
- 需要快速迭代的项目:当你需要快速实现功能并频繁修改时,GPT-4.1的响应速度和代码生成效率更高
- 标准API开发:对于遵循标准模式的API开发,GPT-4.1能提供更符合规范的实现
- 预算有限的项目:可以选择GPT-4.1 mini或nano版本,以更低的成本获得基本功能
- 移动应用开发:在原生移动应用开发上,GPT-4.1对主流框架的支持更好
当选择Claude 3.7更合适:
- 算法密集型项目:涉及复杂算法优化的项目会从Claude 3.7的思考模式获益
- 系统级编程:对于底层系统开发、性能优化等场景,Claude 3.7表现更优
- 安全关键型应用:当代码安全性至关重要时,Claude 3.7对边缘情况的处理更加全面
- 大型代码库分析:需要理解庞大遗留系统时,Claude 3.7的系统分析能力更有价值
- 需要详尽文档的项目:Claude 3.7生成的文档更加全面和详细
混合使用策略
对于复杂项目,可以考虑混合使用两款模型,发挥各自优势:
- 使用Claude 3.7进行系统设计和复杂算法开发
- 使用GPT-4.1处理前端实现和标准API开发
- 对关键代码使用两款模型交叉检查,获得更高质量的结果
【常见问题】GPT-4.1和Claude 3.7使用FAQ
Q1: 这两款模型是否支持中文编程需求?
A1: 是的,两款模型都提供优秀的中文支持。在我们的测试中,Claude 3.7在理解复杂中文技术需求方面略占优势,而GPT-4.1在中文API文档生成方面表现更佳。
Q2: 对于编程新手,哪款模型更友好?
A2: 对于编程新手,GPT-4.1通常提供更直接、容易理解的答案,并且会解释基本概念。Claude 3.7的回答往往更全面但也更复杂,可能更适合有一定基础的开发者。
Q3: 这两款模型的知识截止日期对编程有多大影响?
A3: GPT-4.1的知识截止到2024年6月,而Claude 3.7截止到2024年2月。这在处理新发布的框架、库或语言特性时可能会有所影响。例如,在处理2024年3月后发布的技术时,GPT-4.1可能具有信息优势。
Q4: 使用中转API服务是否会影响模型性能?
A4: 在我们的测试中,通过laozhang.ai访问的API服务在功能上与官方API完全一致,不会影响模型性能。唯一的差异可能是在极高并发场景下的响应时间,但对普通开发需求影响不大。
Q5: 对于大型企业项目,这些模型是否已经达到可靠性要求?
A5: 两款模型都已经达到可以辅助大型企业项目开发的水平,但仍需要人工审核和监督。Claude 3.7在系统设计和算法优化方面可靠性更高,而GPT-4.1在标准开发任务上更为可靠。我们建议将其作为辅助工具使用,而不是完全替代人工开发。
【总结】2025年AI编程助手的最佳选择
经过全面对比和分析,我们可以得出以下结论:
- GPT-4.1优势:在前端开发、快速迭代、标准API和移动应用开发方面表现卓越,响应速度更快,且提供多种定价选择
- Claude 3.7优势:在复杂算法、系统架构、安全关键应用和大型代码库分析方面更胜一筹,思考模式为复杂问题提供更系统化的解决方案
- 成本考量:GPT-4.1系列提供更灵活的价格选择,特别是mini和nano版本适合预算有限的场景;而Claude 3.7尽管价格较高,但在某些复杂场景中带来的价值可能超过价格差异
- 免费使用:通过laozhang.ai等中转服务可以免费体验这两款模型,帮助开发者在实际投入前评估其价值
在2025年的AI编程助手竞争中,选择权在于开发者自己。理解项目需求、预算限制和技术偏好,才能找到最适合的AI编程伙伴。无论选择哪一款,这些AI助手都已成为现代软件开发流程中不可或缺的一部分。
🌟 最终建议:如果你是初次接触这些顶级AI编程工具,强烈推荐先通过laozhang.ai免费体验两款模型,亲身感受它们在你实际项目中的表现差异,再做出最终选择。
【更新日志】持续追踪AI模型发展
plaintext┌─ 更新记录 ──────────────────────────┐ │ 2025-04-15:首次发布完整对比评测 │ │ 2025-04-14:添加GPT-4.1最新数据 │ │ 2025-04-10:完成8大场景实测分析 │ │ 2025-03-20:开始Claude 3.7测试 │ └─────────────────────────────────────┘
📌 特别提示:本文将随着模型更新而持续更新,建议收藏本页面,定期查看最新对比结果!